【人工智能學習之MMdeploy部署踩坑總結】
- 報錯1:TRTNet: device must be a GPU!
- 報錯2:Failed to create Net backend: tensorrt
- 報錯3:Failed to load library libonnxruntime_providers_shared.so
- 1. 確認庫文件是否存在
- 2. 重新安裝 ONNX Runtime
- 3. 檢查系統依賴
- 4. 驗證安裝
- 報錯4:libcudnn.so.9: cannot open shared object file: No such file or directory
- 1. 確認 Conda 環境內的 CuDNN 路徑
- 2. 設置環境變量(臨時生效)
- 3. 永久配置環境變量(虛擬環境內)
- 4. 檢查 CuDNN 版本兼容性(關鍵!)
- 5. 驗證環境
- 報錯5:Inconsistency detected by ld.so: dl-version.c: 205: _dl_check_map_versions: Assertion `needed != NULL' failed!
- 報錯6:mismatched data type FLOAT vs HALF
- 版本對應表
以下是我在使用mmdeploy部署時踩過的坑,在此分享幫助大家,歡迎補充和指正。
報錯1:TRTNet: device must be a GPU!
是說用tenserRT推理必須使用gpu,你應該在代碼中選擇的是cpu,需要改成cuda。注意!是:“cuda”,不是"gpu"寫gpu是無效的。
列如:
self.recognizer = VideoRecognizer(model_path=onnx_path, device_name='cuda', device_id=int(gpu_id))報錯2:Failed to create Net backend: tensorrt
是因為沒設置tensorrt環境變量,需要將trt路徑寫入到.bashrc中:
echo "export LD_LIBRARY_PATH=/root/TensorRT-8.6.1.6/lib:/root/cudnn/lib:$LD_LIBRARY_PATH" >> ~/.bashrc && \
source ~/.bashrc
報錯3:Failed to load library libonnxruntime_providers_shared.so
完整的詳細報錯為:
[mmdeploy] [error] [ort_net.cpp:205] unhandled exception when creating ORTNet: /onnxruntime_src/onnxruntime/core/session/provider_bridge_ort.cc:1080 void onnxruntime::ProviderSharedLibrary::Ensure() [ONNXRuntimeError] : 1 : FAIL : Failed to load library libonnxruntime_providers_shared.so with error: libonnxruntime_providers_shared.so: cannot open shared object file: No such file or directory
是系統找不到 libonnxruntime_providers_shared.so 這個共享庫文件,這通常與 ONNX Runtime 的安裝不完整或環境配置問題有關。
1. 確認庫文件是否存在
首先檢查系統中是否實際存在 libonnxruntime_providers_shared.so:
# 在系統中搜索該文件
sudo find / -name "libonnxruntime_providers_shared.so" 2>/dev/null
- 如果找到該文件(例如路徑為
/path/to/libonnxruntime_providers_shared.so),需要將其所在目錄添加到系統庫路徑:# 臨時生效(當前終端) export LD_LIBRARY_PATH=/path/to/directory-containing-the-file:$LD_LIBRARY_PATH# 永久生效(添加到 ~/.bashrc 或 ~/.zshrc) echo "export LD_LIBRARY_PATH=/path/to/directory-containing-the-file:\$LD_LIBRARY_PATH" >> ~/.bashrc source ~/.bashrc
2. 重新安裝 ONNX Runtime
如果未找到該文件,說明 onnxruntime-gpu 安裝不完整,重新安裝:
# 先卸載現有版本
pip uninstall -y onnxruntime-gpu# 安裝與 mmdeploy 兼容的版本
pip install onnxruntime-gpu
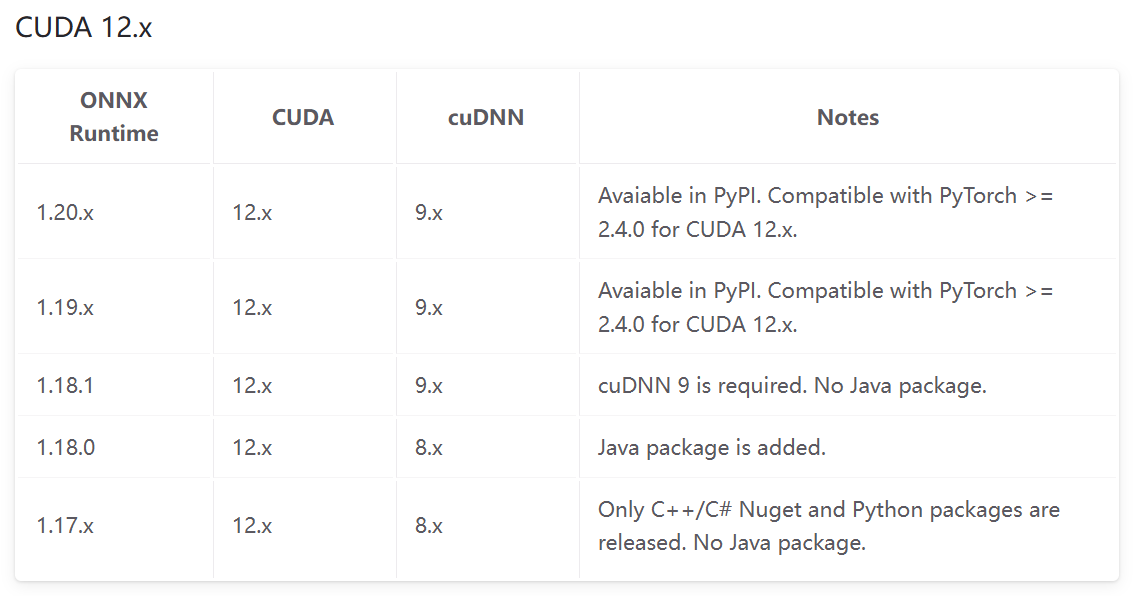
注意:mmdeploy 對 ONNX Runtime 版本有一定兼容性要求,過新的版本(如 1.18.0)可能存在適配問題,降低版本通常能解決此類庫缺失問題。
3. 檢查系統依賴
libonnxruntime_providers_shared.so 可能依賴系統級的 CUDA 或 CUDNN 庫,確保:
- 系統已安裝與
onnxruntime-gpu 1.16.0兼容的 CUDA(推薦 11.6+)和 CUDNN(推薦 8.4+) - CUDA 和 CUDNN 的路徑已正確添加到環境變量(如
LD_LIBRARY_PATH包含/usr/local/cuda/lib64等)
4. 驗證安裝
重新安裝后,通過以下命令驗證 ONNX Runtime 是否正常工作:
import onnxruntime as ort
print("ONNX Runtime 版本:", ort.__version__)
print("可用執行 providers:", ort.get_available_providers())
如果輸出包含 ['CUDAExecutionProvider', 'CPUExecutionProvider'],說明安裝成功,此時再嘗試運行 mmdeploy 相關代碼即可。
如果以上步驟仍未解決,可能需要檢查 mmdeploy 與 ONNX Runtime 的編譯/安裝匹配性(例如是否使用源碼編譯 mmdeploy 時指定了正確的 ONNX Runtime 路徑)。
報錯4:libcudnn.so.9: cannot open shared object file: No such file or directory
完整的詳細報錯為:
[mmdeploy] [error] [ort_net.cpp:205] unhandled exception when creating ORTNet: /onnxruntime_src/onnxruntime/core/session/provider_bridge_ort.cc:1131 onnxruntime::Provider& onnxruntime::ProviderLibrary::Get() [ONNXRuntimeError] : 1 : FAIL : Failed to load library libonnxruntime_providers_cuda.so with error: libcudnn.so.9: cannot open shared object file: No such file or directory [mmdeploy] [error] [net_module.cpp:54] Failed to create Net backend: onnxruntime
報錯核心是系統找不到 libcudnn.so.9,這是 CuDNN 庫的問題,結合你用 Conda 虛擬環境(mmdeploy_zhr),按以下步驟解決:
1. 確認 Conda 環境內的 CuDNN 路徑
先找到虛擬環境中 CuDNN 庫的位置:
# 激活環境(確保已激活 mmdeploy_zhr)
conda activate mmdeploy# 查找 libcudnn.so.9 所在目錄
find $CONDA_PREFIX -name "libcudnn.so.9"
正常情況下,會輸出類似:
/root/miniconda3/envs/mmdeploy_zhr/lib/libcudnn.so.9
記住這個路徑的父目錄(比如上面的路徑,父目錄是 /root/miniconda3/envs/mmdeploy_zhr/lib )。
2. 設置環境變量(臨時生效)
在運行腳本前,手動設置 LD_LIBRARY_PATH 包含 CuDNN 庫路徑:
# 替換成你實際的 CuDNN 庫父目錄
export LD_LIBRARY_PATH=/root/miniconda3/envs/mmdeploy/lib:$LD_LIBRARY_PATH# 再次運行腳本
python onnx_run.py
如果臨時設置后不報錯,說明環境變量配置有效,繼續看步驟 3 永久配置。
3. 永久配置環境變量(虛擬環境內)
為了讓虛擬環境每次激活時自動加載 CuDNN 路徑,在 Conda 環境中配置:
# 激活環境
conda activate mmdeploy_zhr# 添加環境變量到虛擬環境的 activate.d 目錄
echo "export LD_LIBRARY_PATH=$CONDA_PREFIX/lib:\$LD_LIBRARY_PATH" >> $CONDA_PREFIX/etc/conda/activate.d/cudnn.sh# 添加取消環境變量到 deactivate.d 目錄(可選,退出環境時清理)
echo "unset LD_LIBRARY_PATH" >> $CONDA_PREFIX/etc/conda/deactivate.d/cudnn.sh# 重新激活環境使配置生效
conda deactivate
conda activate mmdeploy_zhr
這樣每次激活 mmdeploy_zhr 環境時,LD_LIBRARY_PATH 會自動包含 CuDNN 庫路徑,無需每次手動設置。
4. 檢查 CuDNN 版本兼容性(關鍵!)
你的報錯里是 libcudnn.so.9,說明當前環境用的是 CuDNN 9.x,但要注意:
- ONNX Runtime GPU 版本(尤其是舊版,如你之前用的 1.15.1)對 CuDNN 9.x 兼容性可能不佳,容易出現段錯誤。
- 建議降級 CuDNN 到 8.x 版本(更穩定,適配大多數框架):
安裝后重新運行# 先卸載當前 CuDNN conda uninstall -y cudnn# 安裝 CuDNN 8.9(適配 CUDA 11/12,兼容性好) conda install -y -c nvidia cudnn=8.9.2find $CONDA_PREFIX -name "libcudnn.so.8"確認路徑,再回到步驟 2/3 配置環境變量。
5. 驗證環境
完成上述步驟后,通過以下命令驗證:
# 激活環境
conda activate mmdeploy_zhr# 檢查 CuDNN 庫是否能被找到
ldd $CONDA_PREFIX/lib/libonnxruntime_providers_cuda.so | grep cudnn
如果輸出類似:
libcudnn.so.8 => /root/miniconda3/envs/mmdeploy_zhr/lib/libcudnn.so.8 (0x00007f...)
說明 CuDNN 路徑已正確配置,再運行 onnx_run.py 應該能解決 libcudnn.so.9 找不到的問題。
總結:核心是讓系統找到 CuDNN 庫文件,優先通過 Conda 環境配置 LD_LIBRARY_PATH,并檢查 CuDNN 版本(推薦 8.x)與 ONNX Runtime、mmdeploy 的兼容性,避免因版本過高導致段錯誤。
報錯5:Inconsistency detected by ld.so: dl-version.c: 205: _dl_check_map_versions: Assertion `needed != NULL’ failed!
是動態鏈接器(ld.so)檢測到庫版本不兼容 的錯誤,通常是因為不同庫對系統底層依賴(如 glibc、CUDA 庫)的版本要求沖突,或虛擬環境內的庫與系統全局庫混用導致。
一般重裝就可以解決。最可能的原因是 CUDA 版本 與 ONNX Runtime 版本 不兼容導致的。
報錯6:mismatched data type FLOAT vs HALF
是模型的數據類型和輸入的數據類型不匹配,要么增加前處理,要么重新導出所需數據類型的模型。
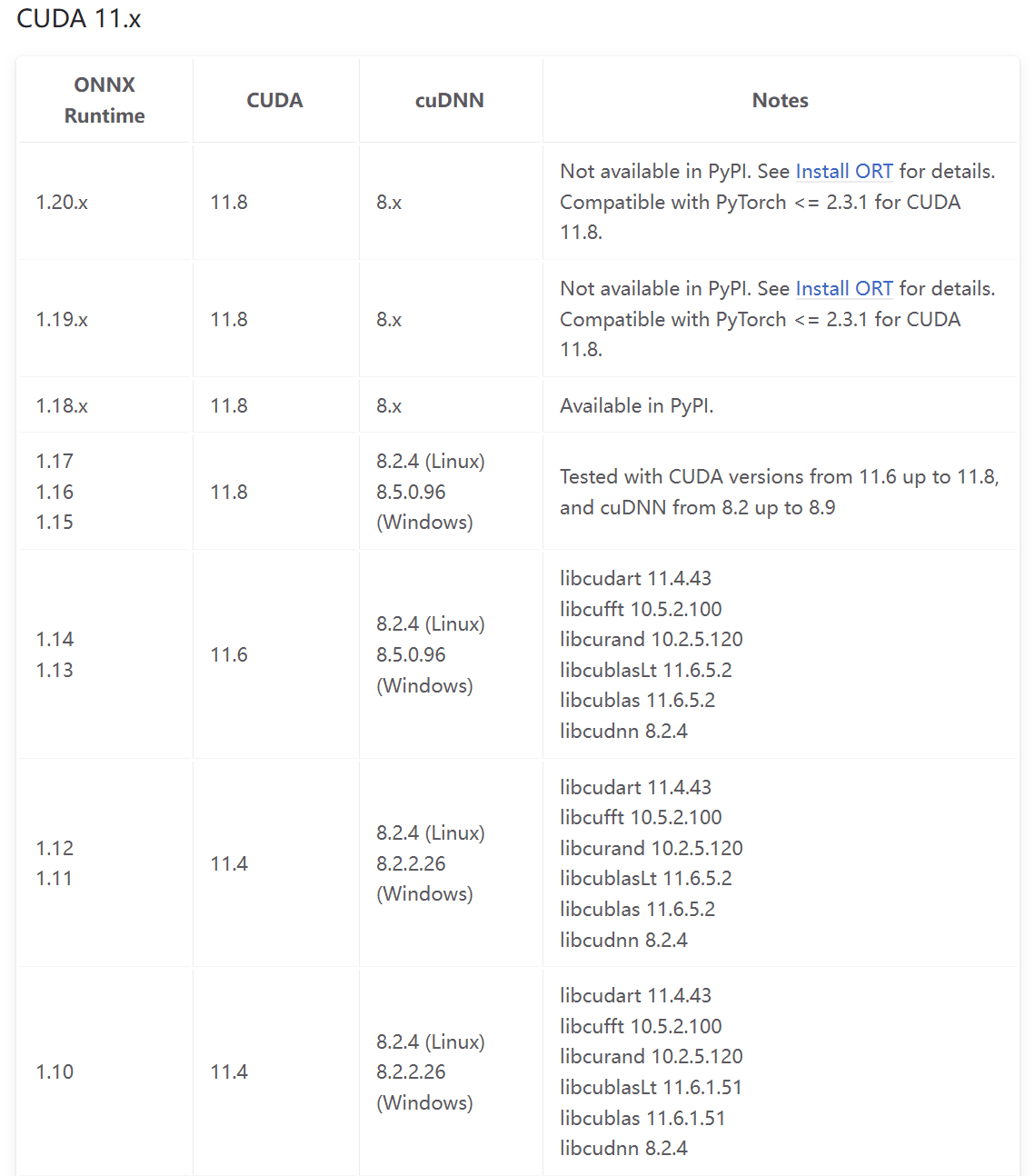
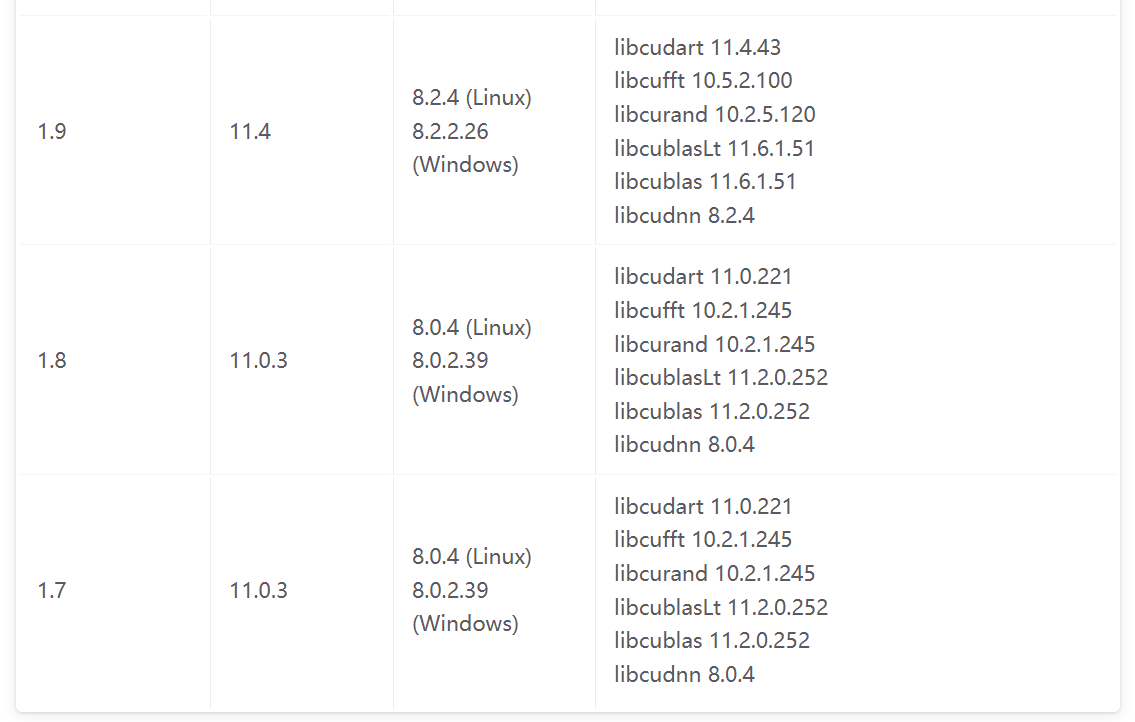
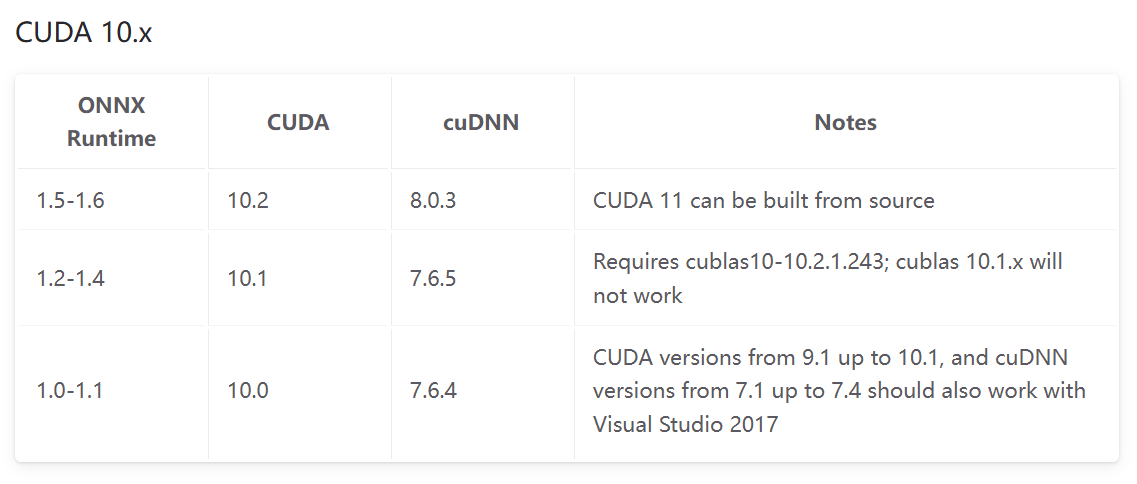
版本對應表
以下是官網的版本對應表:








 -- 架構篇)

![[Dify 專欄] 如何通過 Prompt 在 Dify 中模擬 Persona:即便沒有專屬配置,也能讓 AI 扮演角色](http://pic.xiahunao.cn/[Dify 專欄] 如何通過 Prompt 在 Dify 中模擬 Persona:即便沒有專屬配置,也能讓 AI 扮演角色)



)



—— 神經網絡實驗)
)