目錄
一.食物分類案例
1..整合訓練集測試集文檔
2.導入相關的庫
3.設置圖片數據的格式轉換
3.數據處理
4.數據打包
5.定義卷積神經網絡
6.創建模型
7.訓練和測試方法定義
8.損失函數和優化器
9.訓練模型,測試準確率
10.測試模型
之前我們DataLoader加載的Minist手寫數字集是已經封裝處理好的數據,所以我們可以直接使用,現在我們學習如何使用DataLoader加載本地數據
一.食物分類案例
1..整合訓練集測試集文檔
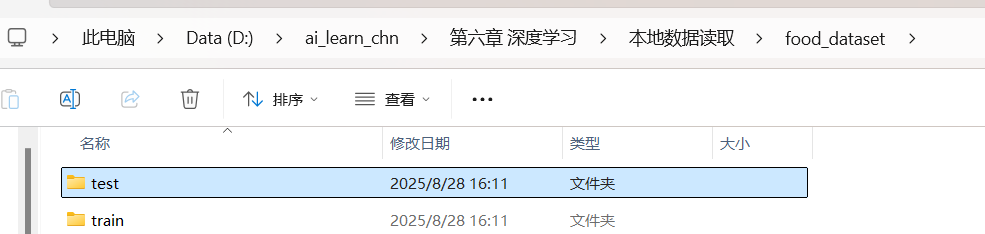

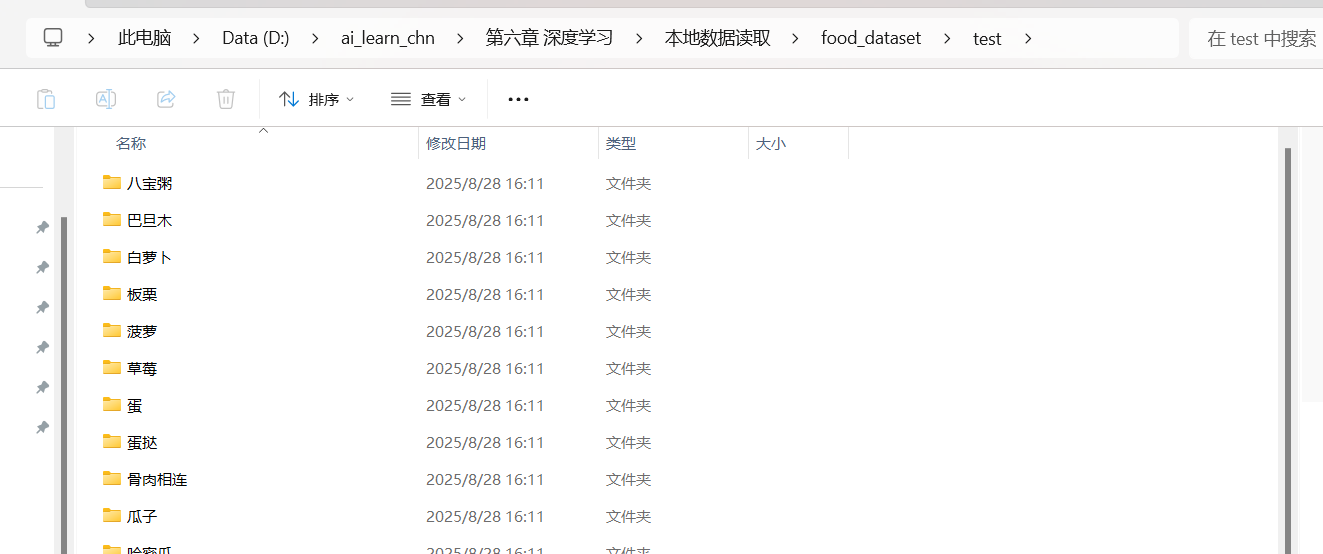
我們可以看到在food_dataset文件夾有訓練集和測試集兩個文件夾分別存放不同食物文件夾共20種食物的照片
為了方便后面模型的對數據的讀取和訓練,我們將每個圖片的地址和標簽(標簽可以自己定義)以空格分開都寫在一個txt文件中,形如:
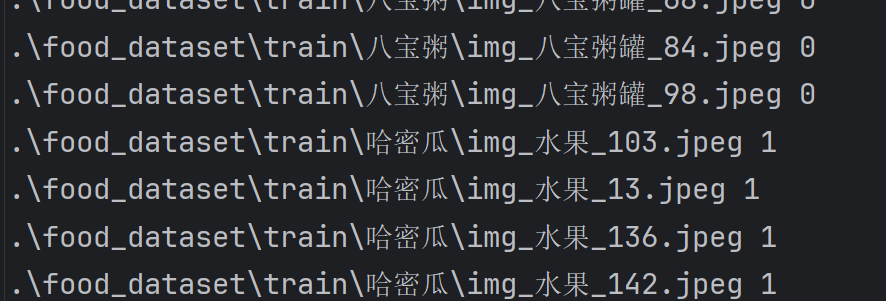
定義一個函數用來完成填寫txt文件
需要注意的是os.walk()函數實在path里面漫步進入文件后還會出來進入下一個文件夾
第一次循環進入到train文件中directories為各食物名稱列表,len不為0,賦值給dirs方便后面命名標簽值
![]()
第二次循環時,root已經進入到第一個食物文件夾,遍歷該文件夾內的所有食物照片得到路徑,對root進行split()方便我們得到食物名now_dir[-1]后,再用dirs.index(now_dir[-1])獲取該食物在dires中的下標值作為標簽,最后將路徑與標簽寫入文件
![]()
遍歷完一個食物文件后順便在字典中保存對應的食物和其標簽
import os
dire={}
def train_test_file(root,dir):f_out=open(dir+'.txt','w')path=os.path.join(root,dir)for root,directories,files in os.walk(path):if len(directories)!=0:dirs=directorieselse:now_dir=root.split('\\')for file in files:path=os.path.join(root,file)f_out.write(path+' '+str(dirs.index(now_dir[-1]))+'\n')dire[dirs.index(now_dir[-1])]=now_dir[-1]f_out.close()最后就是調用該函數,傳入相關路徑即可得到對應train.txt和test.txt
root=r'.\food_dataset'
train_dir='train'
test_dir='test'
train_test_file(root,train_dir)
train_test_file(root,test_dir)
2.導入相關的庫
import torch
from torch.utils.data import Dataset,DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms3.設置圖片數據的格式轉換
用字典來保存訓練集和測試集的相應格式轉換
transforms.Compose()是將一些格式的轉換組合在一起相當于一個容器
由于每個照片的大小都可能不同會影響到后面全連接層的展開輸入總個數,所以這里必須統一大小
還需要將數據轉化為Tensor張量類型
data_transforms={'train':transforms.Compose([transforms.Resize([256,256]),transforms.ToTensor()]),'valid':transforms.Compose([transforms.Resize([256,256]),transforms.ToTensor()])
}3.數據處理
由于我們使用的是自己的數據,所以我們必須要讓我們的數據集可以通過[]即索引來獲取,這樣DataLoader才能拿到數據并打包
定義一個類來實現上述要求,傳入文件路徑和上述的圖片數據轉換方式即可
在初始化方法__inint__中,完成一些共享空間self賦值后,我們將傳入文件中的路徑和標簽分別保存在存儲路徑和存儲標簽的列表中
__len__方法也是必不可少的,DataLoader打包數據前會先檢查總數據的大小長度夠不夠再完成打包
__getitem__則是我們通過索引獲取信息的關鍵方法,只要使用索引就會調用該方法,我們在該方法中通過傳進來的索引我們可以通過之前的存儲列表獲取圖片的路徑和標簽,并用PIL庫的Image.open()方法讀取圖片后根據初始化時傳進來的轉化格式進行轉換,標簽則用torch.from_numpy()方法也轉化為tensor張量,最后返回圖片數據和標簽
class food_dataset(Dataset):#能通過索引的方式返回圖片數據和標簽結果def __init__(self,file_path,transform=None):self.file_path=file_pathself.imgs_paths=[]self.labels=[]self.transform=transformwith open(self.file_path) as f:samples=[x.strip().split(' ') for x in f.readlines()]for img_path,label in samples:self.imgs_paths.append(img_path)self.labels.append(label)def __len__(self):return len(self.imgs_paths)def __getitem__(self, idx):image=Image.open(self.imgs_paths[idx])if self.transform:image=self.transform(image)label=self.labels[idx]label=torch.from_numpy(np.array(label,dtype=np.int64))#label也轉化為tensorreturn image,label創建該類的對象,傳入訓練集和測試集的路徑得到可以被DataLoader打包的數據
train_data=food_dataset(file_path='./train.txt',transform=data_transforms['train'])
test_data=food_dataset(file_path='./test.txt',transform=data_transforms['valid'])4.數據打包
由于圖片大小比較大我們就將一個圖片數據打包成一個批次
train_loader=DataLoader(train_data,batch_size=1,shuffle=True)
test_loader=DataLoader(test_data,batch_size=1,shuffle=True)device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')5.定義卷積神經網絡
只需注意必須繼承nn.Module類,和我們此次訓練的是彩色圖片,所以第一個in_channel輸入通道數是3而不是之前手寫數字灰度圖的1,最后全連接層的輸出通道是20因為我們有20種食物
from torch import nn
class CNN(nn.Module):def __init__(self):super().__init__()#nn.Sequential()是將網絡層組合在一起,內部不能寫函數self.conv1=nn.Sequential(#1*3*256*256nn.Conv2d(in_channels=3,#輸入通道數out_channels=8,kernel_size=5,stride=1,padding=2),#1*8*256*256nn.ReLU(),nn.MaxPool2d(kernel_size=2)#1*8*128*128)self.conv2 = nn.Sequential(nn.Conv2d(8,16,5,1,2),#1*16*128*128nn.ReLU(),nn.Conv2d(16,32,5,1,2),#1*32*128*128nn.ReLU(),nn.MaxPool2d(kernel_size=2)##1*32*64*64)self.conv3 = nn.Sequential(nn.Conv2d(32,64,5,1,2),#1*64*64*64nn.ReLU(),nn.Conv2d(64, 64, 5, 1, 2),#1*64*64*64nn.ReLU())self.flatten=nn.Flatten()self.out=nn.Linear(64*64*64,20)def forward(self,x):x=self.conv1(x)x=self.conv2(x)x=self.conv3(x)# x=x.view(x.size(0),-1)x=self.flatten(x)output=self.out(x)return output
6.創建模型
model=CNN().to(device)7.訓練和測試方法定義
與之前手寫數字的方法并無任何不同
def train(dataloader,model,loss_fn,optimizer):model.train()batch_size_num=1for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model(X)loss=loss_fn(pred,y)optimizer.zero_grad()loss.backward()optimizer.step()loss_value=loss.item()if batch_size_num % 100 == 0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num += 1
def test(dataloader,model,loss_fn):model.eval()len_data=len(dataloader.dataset)correct,loss_sum=0,0num_batch=0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss_sum += loss_fn(pred, y).item()correct+=(pred.argmax(1)==y).type(torch.float).sum().item()num_batch+=1loss_avg=loss_sum/num_batchaccuracy=correct/len_dataprint(f'Accuracy:{100 * accuracy}%\nLoss Avg:{loss_avg}')return pred.argmax(1)8.損失函數和優化器
多分類問題選擇交叉熵損失函數
loss_fn=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.0001)9.訓練模型,測試準確率
設置20輪訓練
epochs=20
for i in range(epochs):print(f'==========第{i + 1}輪訓練==============')train(train_loader, model, loss_fn, optimizer)print(f'第{i + 1}輪訓練結束')test(test_loader,model,loss_fn)
準確率很低,后續會改進
10.測試模型
自己輸入一個照片的路徑通過模型來判斷類別,我們需要將照片數據用上面的格式轉化處理,需要注意的是我們必須手動為其添加batch維度,因為這里沒用Dataloader加載數據不會自動添加batch維度
pred.argmax(1).item()是獲取前向傳播之后輸出的最大概率的標簽,.item()是將其轉化為可讀的形式
path=input('請輸入一個圖片地址: ')
image=Image.open(path)
image=data_transforms['valid'](image)
image=image.unsqueeze(0).to(device)#添加batch維度
# 注意使用DataLoader加載數據時,它會自動為批量數據添加 batch 維度
model.eval()
with torch.no_grad():pred=model.forward(image)label=pred.argmax(1).item()print('該圖片是: '+dire[label])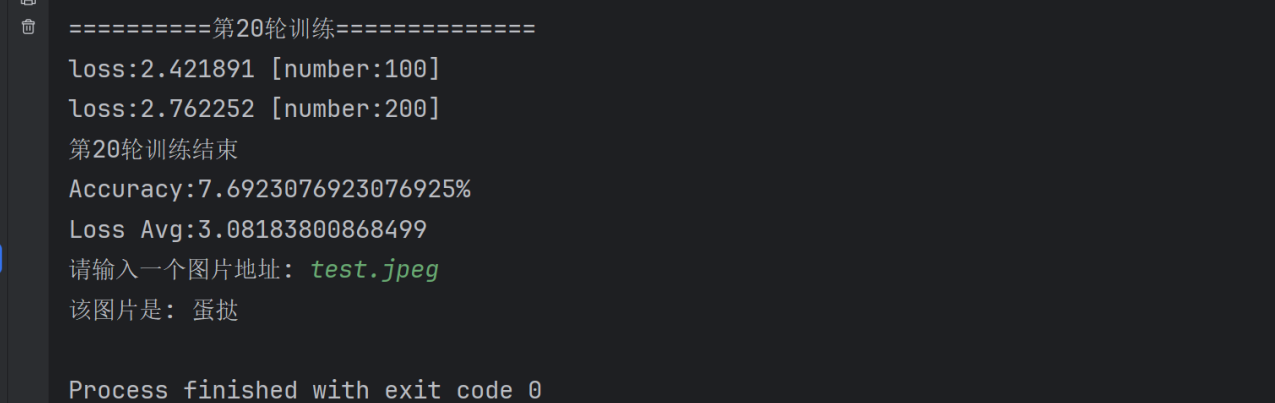
)


















)