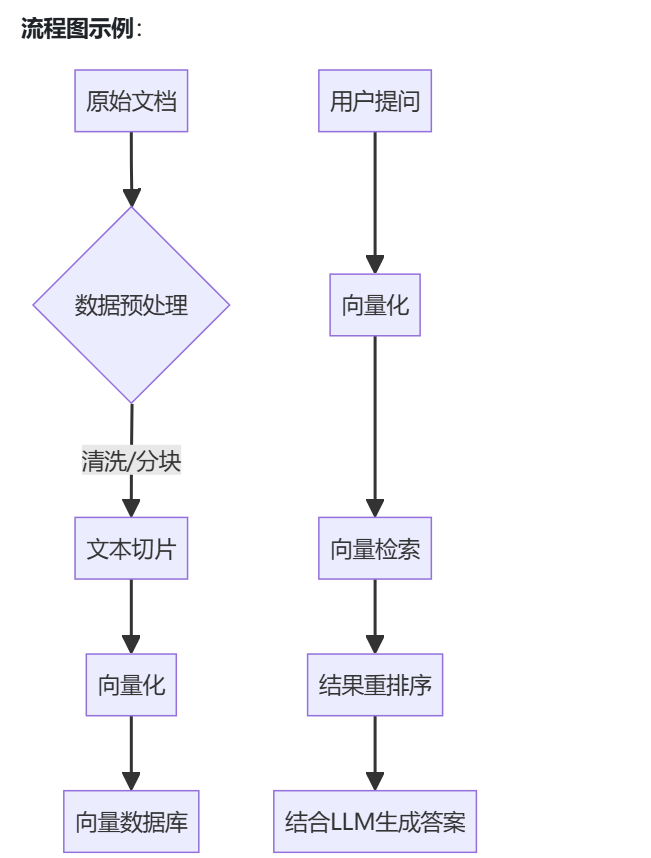
RAG(檢索增強生成)的完整流程可分為5個核心階段:
- 數據準備:清洗文檔、分塊處理(如PDF轉文本切片);
- 向量化:使用嵌入模型(如BERT、BGE)將文本轉為向量;
- 索引存儲:向量存入數據庫(如Milvus、Faiss、Elasticsearch);
- 檢索增強:用戶提問向量化后檢索相關文檔;
- 生成答案:將檢索結果與問題組合輸入大模型生成回答。
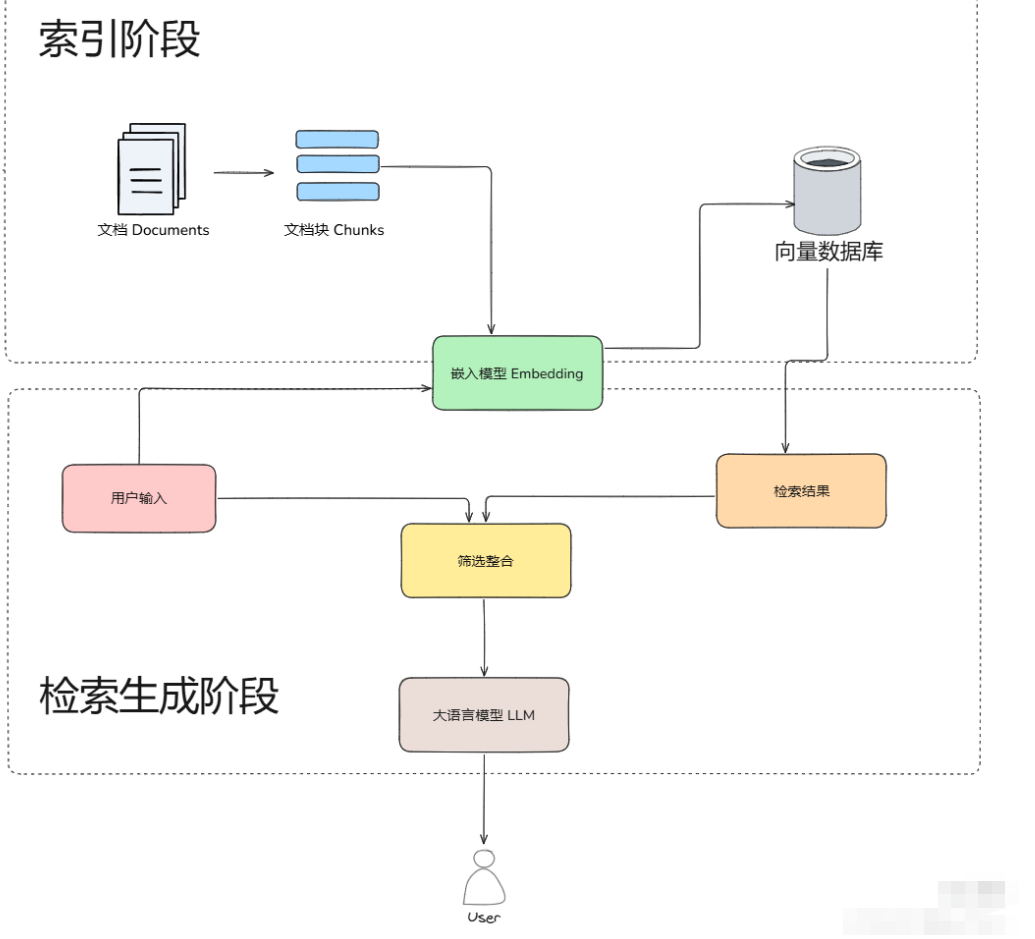
也可以從三個階段來回答:
- 在 RAG 索引階段,首先對原始文檔進行解析,并將其拆分成多個較小的文本塊。隨后,這些文本塊會通過嵌入模型進行向量化處理,生成的向量將被存儲在向量數據庫中,供后續檢索使用。
- 在 RAG 檢索階段,RAG 系統會將用戶的查詢同樣進行向量化,并在向量數據庫中執行語義相似度匹配,篩選出與查詢最相關的一組文本塊。
- 最后在生成階段,系統將用戶查詢與檢索到的相關文本塊進行組合,通過提示工程(Prompt Engineering)設計適當的輸入格式,然后交由大語言模型生成最終的回答,至此完成整個 RAG 的流程。
擴展知識
文檔處理的關鍵細節
文檔分塊策略:
- 按語義切分:用
SemanticSplitter確保每塊語義獨立(如問答對單獨成塊); - 按結構切分:HTML/PDF按標題層級切割(如
HTMLHeaderTextSplitter保留結構); - 遞歸切分:
RecursiveCharacterTextSplitter兼顧文本連貫性和長度限制。
檢索階段的優化策略
多階段檢索:
- 粗篩:用BM25快速匹配關鍵詞(如“iPhone 15”);
- 精排:向量相似度+重排序模型(如Cohere Reranker);
混合檢索:同時使用向量和關鍵詞結果,通過RRF(倒數排名融合)合并。
生成階段的Prompt設計示例
▼
python
復制代碼
# 示例Prompt模板(網頁2) prompt = "用戶問題: {query}\n相關文檔: {doc1}\n{doc2}\n請結合以上信息回答。"
可以進行上下文壓縮:對檢索結果摘要(如RAPTOR樹狀摘要)減少冗余輸入。

















)

