目錄
一、前言
二、工作流程總覽
三、最常用內置變量
四、命令格式
五、20 個高頻實戰案例
5.1 基礎打印
awk '{print "hello"}' < /etc/passwd 所有行打印成hello
awk '{print}' test6.txt? 打印test6.txt文件
awk '{print $1}' test6.txt 默認以空格為分割,取第一列
awk -F:? 按照冒號分隔,取第五列
?awk -F: '{print $1 $2}' test6.txt 按照冒號分隔,取第一和第二列
awk -F[:/] '{print $9}' test6.txt? ? ? 以 : 或者 / 作為分隔符,取第九列
5.2 內置變量速用
awk -F: '/root/{print $0}' test6.txt 取含有root的每一行
?awk -F: '/root/{print $1}' test6.txt 取含有root字段行的第一列
awk -F: '/root/{print $1,$4}' test6.txt 取第一列和第四行
awk -F[:/] '{print NF}' test6.txt? 當前行的列數
awk -F[:/] '{print NR}' test6.txt? 當前行號
awk -F: '{print NR,$0}' test6.txt 輸出行號和內容
awk 'NR==2{print}' /etc/passwd 打印第二行
awk -F: 'NR==2{print $1}' +文件名? 打印第二行第一列
?awk -F: '{print $NF}' +文件名 打印最后一列
awk -F: '{print "第"NR"行有"NF"列"}' 打印有多少行和多少列
5.3 BEGIN & END 經典場景
awk 'BEGIN' 在文件開始時運用
?awk 'END +命令' +文件路徑? 文件結束后打印
5.4 條件與邏輯
awk -F: '$1~/root/'? 某一列中含有root的
awk -F: '$1~/ro/' 模糊匹配,只要第一列中含有ro就可以了
awk -F: '$7!~/nologin$/{print $1,$7}' /etc/passwd 打印第七列不以/nologin結尾的行的第一列和第七列
awk 'NR==5{print}' +文件名? 打印第五行
awk 'NR<5' /etc/passwd? 打印前四行
awk 'NR>=45' /etc/passwd? 打印45行以后
awk -F: '$1=="root"' /etc/passwd? 打印第一列是root的
awk -F: '$3<30 || $3>1000' test8.txt? ?第三列小于30或者第三列大于1000
awk -F: '$3>30 && $3<1000' test8.txt? 第3列大于30小于1000
awk -F: 'NR>4 && NR<10' /etc/passwd 第4-10行
5.5 輸出格式控制
awk 'BEGIN{FS=":"}{print $1}' test8.txt? 打印之前定義字段,分隔符為冒號
awk 'BEGIN{FS=":";OFS="---"}{print $1,$2}' test8.txt 以冒號為分隔符,中間用---連接5.5 輸出格式控制
5.6 生產常用
5.7 調用 Shell 命令
六、數組 + 循環:日志分析利器
6.1 基本數組
6.2 統計 SSH 爆破 IP
七、面試題加餐
八、三劍客對比
九、總結
一、前言
awk 是 Linux 文本三劍客中的“列處理專家”,貝爾實驗室三巨頭發明,現以 gawk 形式隨系統自帶。它按行讀取、以列運算,用 pattern{action} 一句話就能完成取字段、過濾、統計、格式化輸出。BEGIN 初始化,END 匯總,內置變量 1NF NR FS 等讓日常 90% 的日志分析、系統巡檢、數據報表需求一行搞定;支持正則、邏輯運算、數組循環,更可管道調用 shell 命令,堪稱運維與開發的萬能文本瑞士軍刀。
二、工作流程總覽
BEGIN{ … } # 初始化,只執行一次
/pattern/{ … } # 對每一行匹配 pattern 后執行動作(默認無 pattern 則全部執行)
END{ … } # 收尾匯總,只執行一次核心循環:讀(Read) → 執行(Execute) → 重復(Repeat),直到文件結束。
三、最常用內置變量
| 變量 | 含義 | 示例 |
|---|---|---|
$0 | 整行內容 | |
$n | 第 n 列 | $1?第 1 列 |
NF | 當前行的列數 | print NF |
NR | 當前行號(所有文件累計) | print NR |
FNR | 當前行號(每個文件單獨計數) | |
FS | 輸入字段分隔符(默認空格/Tab) | FS=":" |
OFS | 輸出字段分隔符(默認空格) | OFS="," |
RS | 輸入記錄分隔符(默認?\n) | |
ORS | 輸出記錄分隔符(默認?\n) |
四、命令格式
# 單行直寫
awk [選項] '模式{動作}' file# 腳本文件
awk -f script.awk file五、20 個高頻實戰案例
5.1 基礎打印
# 1. 每行打印 hello
awk '{print "hello"}' /etc/passwd# 2. 輸出整行
awk '{print}' zz# 3. 以冒號為分隔符,打印第 5 列
awk -F: '{print $5}' zz# 4. 多分隔符(冒號或斜杠)
awk -F '[:/]' '{print $9}' zzawk '{print "hello"}' < /etc/passwd 所有行打印成hello
[root@zard3 shelldemo]# awk '{print "hello"}' < /etc/passwd
hello
hello
hello
hello
hello
hello
hello
hello
hello
hello
hello
hello
hello
hello
hello
...... 一共52行,因為cat /etc/passwd里面一共是52行awk '{print}' test6.txt? 打印test6.txt文件
[root@zard3 shelldemo]# cat /etc/passwd | head -10 > test6.txt
[root@zard3 shelldemo]# awk '{print}' test6.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
awk '{print $1}' test6.txt 默認以空格為分割,取第一列
[root@zard3 shelldemo]# awk '{print $1}' test6.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
awk -F:? 按照冒號分隔,取第五列
[root@zard3 shelldemo]# awk -F: '{print $5}' test6.txt
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
?awk -F: '{print $1 $2}' test6.txt 按照冒號分隔,取第一和第二列
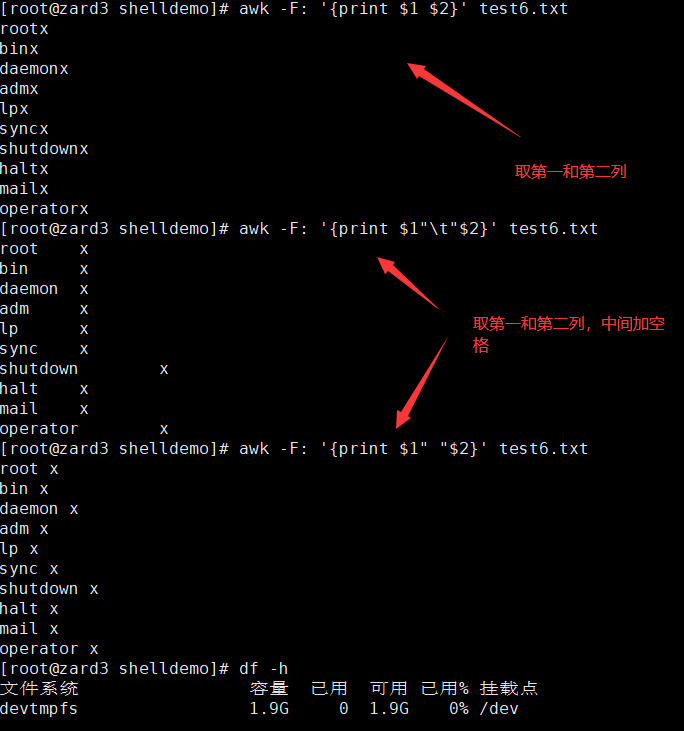
awk -F[:/] '{print $9}' test6.txt? ? ? 以 : 或者 / 作為分隔符,取第九列
[root@zard3 shelldemo]# awk -F[:/] '{print $9}' test6.txt
bin
sbin
sbinlpd
bin
sbin
sbin
mail
sbin
注意:在每一行中:/在一起是算作是一個空字符的
以第一行為例,證明以上觀點

5.2 內置變量速用
# 5. 行號 + 整行
awk '{print NR,$0}' /etc/passwd# 6. 只看第 2 行
awk 'NR==2' /etc/passwd# 7. 最后一列
awk -F: '{print $NF}' /etc/passwd# 8. 文件總行數
awk 'END{print NR}' /etc/passwdawk -F: '/root/{print $0}' test6.txt 取含有root的每一行
[root@zard3 shelldemo]# awk -F: '/root/{print $0}' test6.txt
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin?awk -F: '/root/{print $1}' test6.txt 取含有root字段行的第一列
[root@zard3 shelldemo]# awk -F: '/root/{print $1}' test6.txt
root
operatorawk -F: '/root/{print $1,$4}' test6.txt 取第一列和第四行
[root@zard3 shelldemo]# awk -F: '/root/{print $1,$4}' test6.txt
root 0
operator 0
awk -F[:/] '{print NF}' test6.txt? 當前行的列數
[root@zard3 shelldemo]# awk -F[:/] '{print NF}' test6.txt
10
10
10
11
12
10
10
10
12
10
awk -F[:/] '{print NR}' test6.txt? 當前行號
[root@zard3 shelldemo]# awk -F[:/] '{print NR}' test6.txt
1
2
3
4
5
6
7
8
9
10awk -F: '{print NR,$0}' test6.txt 輸出行號和內容
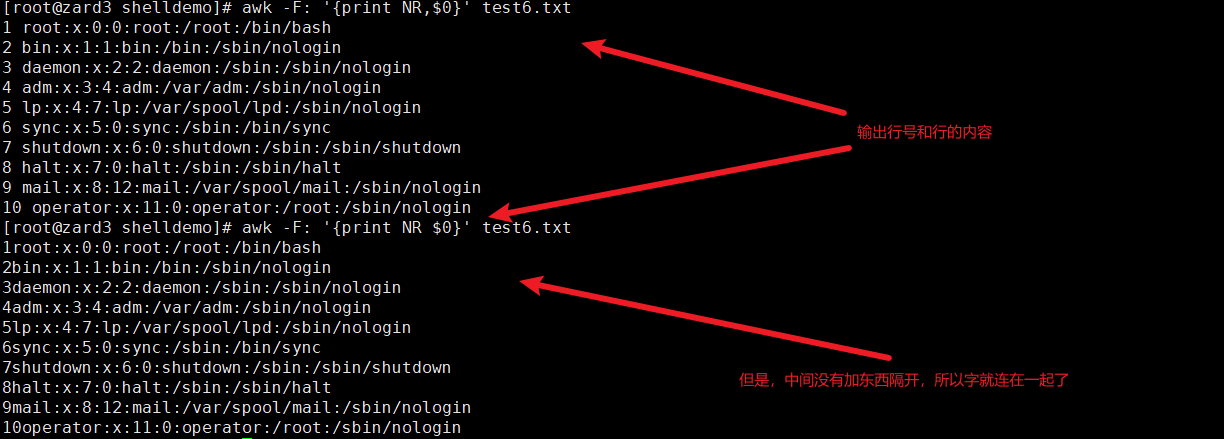
awk 'NR==2{print}' /etc/passwd 打印第二行

awk -F: 'NR==2{print $1}' +文件名? 打印第二行第一列
[root@zard3 shelldemo]# awk -F: 'NR==2{print $1}' /etc/passwd
bin?awk -F: '{print $NF}' +文件名 打印最后一列
[root@zard3 shelldemo]# awk -F: '{print $NF}' /etc/passwd
/bin/bash
/sbin/nologin
/sbin/nologin
/sbin/nologin
/sbin/nologin
/bin/sync
/sbin/shutdown
/sbin/halt
/sbin/nologin
/sbin/nologin
/sbin/nologin
/sbin/nologin
/sbin/nologin
...此處省略awk -F: '{print "第"NR"行有"NF"列"}' 打印有多少行和多少列
[root@zard3 shelldemo]# awk -F: '{print "第"NR"行有"NF"列"}' /etc/passwd
第1行有7列
第2行有7列
第3行有7列
第4行有7列
第5行有7列
第6行有7列
第7行有7列
第8行有7列
第9行有7列
第10行有7列
第11行有7列
第12行有7列
第13行有7列
第14行有7列
第15行有7列
第16行有7列
第17行有7列
第18行有7列
第19行有7列
第20行有7列
... 此處省略5.3 BEGIN & END 經典場景
# 9. 計算 1~100 的和
seq 100 | awk '{sum+=$1} END{print sum}'# 10. 統計 /bin/bash 結尾的行數
awk 'BEGIN{n=0} /\/bin/bash$/{n++} END{print n}' /etc/passwdawk 'BEGIN' 在文件開始時運用
[root@zard3 shelldemo]# awk 'BEGIN{x=12;print x}'
12
[root@zard3 shelldemo]# awk 'BEGIN{x=12;print x}' test6.txt
12
[root@zard3 shelldemo]# awk 'BEGIN{x=12;print x+1}'
13
[root@zard3 shelldemo]# awk 'BEGIN{x=12;print 4.5+4.5}'
9
[root@zard3 shelldemo]# awk 'BEGIN{x=12;print 3*3}'
9
[root@zard3 shelldemo]# awk 'BEGIN{x=12;print 3**3}'
27
[root@zard3 shelldemo]# awk 'BEGIN{x=12;print 3/4}'
0.75
[root@zard3 shelldemo]# awk 'BEGIN{x=12;print 3/4}' >test7.txt
[root@zard3 shelldemo]# cat test7.txt
0.75?awk 'END +命令' +文件路徑? 文件結束后打印

5.4 條件與邏輯
# 11. 模糊匹配:第 1 列包含 root
awk -F: '$1 ~ /root/' /etc/passwd# 12. 數值比較:UID ≥ 1000
awk -F: '$3>=1000' /etc/passwd# 13. 區間行:第 5~10 行
awk 'NR>=5 && NR<=10' /etc/passwdawk -F: '$1~/root/'? 某一列中含有root的

awk -F: '$1~/ro/' 模糊匹配,只要第一列中含有ro就可以了
[root@zard3 shelldemo]# awk -F: '$1~/ro/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
setroubleshoot:x:993:990::/var/lib/setroubleshoot:/sbin/nologin
chrony:x:992:987::/var/lib/chrony:/sbin/nologinawk -F: '$7!~/nologin$/{print $1,$7}' /etc/passwd 打印第七列不以/nologin結尾的行的第一列和第七列

awk 'NR==5{print}' +文件名? 打印第五行
[root@zard3 shelldemo]# awk 'NR==5{print}' /etc/passwd
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@zard3 shelldemo]# awk 'NR==5' /etc/passwd
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologinawk 'NR<5' /etc/passwd? 打印前四行
[root@zard3 shelldemo]# awk 'NR<5' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologinawk 'NR>=45' /etc/passwd? 打印45行以后
[root@zard3 shelldemo]# awk 'NR>=45' /etc/passwd
test1:x:1001:1001::/home/test1:/bin/bash
tom:x:1002:1002::/home/tom:/bin/bash
mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false
named:x:25:25:Named:/var/named:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
zard111:x:1003:1003::/home/zard111:/bin/bash
test3:x:1004:1004::/home/test3:/bin/bash
test4:x:1005:1005::/home/test4:/bin/bashawk -F: '$1=="root"' /etc/passwd? 打印第一列是root的
[root@zard3 shelldemo]# awk -F: '$1==root' /etc/passwd
[root@zard3 shelldemo]# awk -F: '$1=="root"' /etc/passwd
root:x:0:0:root:/root:/bin/bashawk -F: '$3<30 || $3>1000' test8.txt? ?第三列小于30或者第三列大于1000
[root@zard3 shelldemo]# awk -F: '$3<30 || $3>1000' test8.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
named:x:25:25:Named:/var/named:/sbin/nologin
mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/false
rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin
test1:x:1001:1001::/home/test1:/bin/bash
tom:x:1002:1002::/home/tom:/bin/bash
zard111:x:1003:1003::/home/zard111:/bin/bash
test3:x:1004:1004::/home/test3:/bin/bash
test4:x:1005:1005::/home/test4:/bin/bash
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
awk -F: '$3>30 && $3<1000' test8.txt? 第3列大于30小于1000
[root@zard3 shelldemo]# awk -F: '$3>30 && $3<1000' test8.txt
rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
gdm:x:42:42::/var/lib/gdm:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
avahi:x:70:70:Avahi mDNS/DNS-SD Stack:/var/run/avahi-daemon:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
radvd:x:75:75:radvd user:/:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
qemu:x:107:107:qemu user:/:/sbin/nologin
usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin
pulse:x:171:171:PulseAudio System Daemon:/var/run/pulse:/sbin/nologin
rtkit:x:172:172:RealtimeKit:/proc:/sbin/nologin
abrt:x:173:173::/etc/abrt:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
gnome-initial-setup:x:988:982::/run/gnome-initial-setup/:/sbin/nologin
geoclue:x:989:983:User for geoclue:/var/lib/geoclue:/sbin/nologin
sssd:x:990:984:User for sssd:/:/sbin/nologin
unbound:x:991:986:Unbound DNS resolver:/etc/unbound:/sbin/nologin
chrony:x:992:987::/var/lib/chrony:/sbin/nologin
setroubleshoot:x:993:990::/var/lib/setroubleshoot:/sbin/nologin
saslauth:x:994:76:Saslauthd user:/run/saslauthd:/sbin/nologin
gluster:x:995:992:GlusterFS daemons:/run/gluster:/sbin/nologin
saned:x:996:993:SANE scanner daemon user:/usr/share/sane:/sbin/nologin
colord:x:997:994:User for colord:/var/lib/colord:/sbin/nologin
libstoragemgmt:x:998:995:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
awk -F: 'NR>4 && NR<10' /etc/passwd 第4-10行
[root@zard3 shelldemo]# awk -F: 'NR>4 && NR<10' /etc/passwd
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin5.5 輸出格式控制
# 14. 指定輸出分隔符 OFS
awk -F: 'BEGIN{OFS="---"} {print $1,$2}' /etc/passwd# 15. 把多行合并成一行
awk 'BEGIN{ORS=" "} {print}' /etc/passwdawk 'BEGIN{FS=":"}{print $1}' test8.txt? 打印之前定義字段,分隔符為冒號
[root@zard3 shelldemo]# awk 'BEGIN{FS=":"}{print $1}' test8.txt
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
games
ftp
named
mysql
rpcuser
rpc
ntp
gdm
apache
tss
avahi
tcpdump
sshd
radvd
dbus
postfix
nobody
qemu
usbmuxd
pulse
rtkit
abrt
systemd-network
gnome-initial-setup
geoclue
sssd
unbound
chrony
setroubleshoot
saslauth
gluster
saned
colord
libstoragemgmt
polkitd
zard3
test1
tom
zard111
test3
test4
nfsnobody
awk 'BEGIN{FS=":";OFS="---"}{print $1,$2}' test8.txt 以冒號為分隔符,中間用---連接5.5 輸出格式控制
# 14. 指定輸出分隔符 OFS
awk -F: 'BEGIN{OFS="---"} {print $1,$2}' /etc/passwd# 15. 把多行合并成一行
awk 'BEGIN{ORS=" "} {print}' /etc/passwd5.6 生產常用
# 16. 取本機 ens33 網卡 IP
ifconfig ens33 | awk '/netmask/{print "IP="$2}'# 17. 取根分區可用空間
df -h | awk 'NR==2{print "Avail="$4}'# 18. 統計 Apache 訪問日志中每個 IP 出現次數
awk '{ip[$1]++} END{for(i in ip) print ip[i],i}' /var/log/httpd/access_log | sort -nr | head5.7 調用 Shell 命令
# 19. 統計當前在線用戶
awk 'BEGIN{while ("w"|getline) n++; print n-2}'# 20. 動態獲取主機名
awk 'BEGIN{"hostname"|getline; print $0}'六、數組 + 循環:日志分析利器
6.1 基本數組
# 字符串下標
awk 'BEGIN{a["ip"]=192.168.1.1; print a["ip"]}'6.2 統計 SSH 爆破 IP
awk '/Failed password/{ip[$11]++}END{for(i in ip) print i","ip[i]}' /var/log/secure配合腳本實時告警:
#!/bin/bash
awk '/Failed password/{ip[$11]++}END{for(i in ip){if(ip[i]>=3) print "警告!",i,"失敗次數",ip[i]}}' /var/log/secure七、面試題加餐
-
提取版本號
文本:1.9.7
命令:echo "1.9.7" | awk -F. '{print $1,$2,$3}' -
兩列合并,中間留 2 空格
文件內容:zhangsan 20 江蘇南京 漢族命令
awk '{printf "%s %s\n",$1,$3}' file
八、三劍客對比
| 工具 | 定位 | 擅長場景 |
|---|---|---|
| grep | 純文本過濾 | 快速查找、正則匹配 |
| sed | 流編輯器 | 整行替換/刪除/插入 |
| awk | 報告生成器 | 按列處理、統計、格式化輸出 |
九、總結
awk 是 Linux 下最鋒利的「列級」文本處理刀:按行讀、按列切、按條件算、按格式吐,一行搞定過濾、統計、報表三大需求。
速記
-
結構:
BEGIN{一次} pattern{每行} END{匯總} -
必背 4 變量:
$0整行、$n第 n 列、NF列數、NR行號 -
必背 2 符號:
~包含、!~不包含;-F指定分隔符 -
三板斧:
? 取列:awk -F: '{print $1,$7}' /etc/passwd
? 統計:awk '{ip[$1]++} END{for(i in ip) print ip[i],i}' access.log
? 過濾:awk -F: '$3>=1000 && $7!~/nologin$/{print $1}' /etc/passwd -
場景:日志 IP 排名、系統指標監控、配置文件批量修改、實時告警腳本。
掌握 awk,告別手搓 sed/grep 組合,讓文本處理從 10 行變 1 行。














》)




