一、TL;DR
- 整體介紹:強化微調RFT的原因、步驟、作用以及常見的rft方式
- dmeo舉例:以Swift給的Qwen2.5-Math-7B-Instruct為例介紹了整個RFT的流程和代碼細節
- 實際強化微調:以qwen/internVL為例完成一次指令微調并且使用強化學習進一步提升指標
二、整體介紹
2.1 為什么要做強化微調
掉點/回退現象:
基礎MLLM經過含有CoT訓練集上做SFT后,發現在test集上掉點,可以通過強化微調來確保不會發生這種情況
- 在LLaMA3上,使用gsm8k訓練集訓練llama3.1-8b-instruct,對生成的ckpt使用test集進行評測,會發現掉點。
原因:
模型的知識遺忘,舉例如下:
- 正常流程:在微調的時候會加入非常多的CoT數據集
- 造成結果:在繼續訓練通用任務后,知識遺忘破壞了模型原有能力,導致了掉點。
- 原因分析:當模型在解決數學任務的時候,用到的能力很有可能不是來自于math數據集,而是來自arc數據集,
2.2 什么時候可以使用強化微調
當有如下條件之一時使用強化微調:
- 已經微調過模型,能力不滿足需求
- 需要更強的CoT能力
- 對基模型訓練通用能力,而原始數據集已經導致模型效果無法提升
-
對應query的輸出結果可以相對準確地評估好壞,例如結果清晰(數學,代碼),過程清晰(翻譯,風格)等
強化微調非常依賴于reward評估是否準確。如果評估結果不準確,可能導致模型訓練原地震蕩,甚至越訓越差。
2.3 強化微調的步驟
2.3.1?使用某個模型生成數據/進行原始數據擴充然后采樣
-
大模型生成數據:使用GPT、Qwen-Max、DeepSeek-V3/R1等生成和擴充數據,則該強化微調可以理解為蒸餾
- 模型本身生成數據:可以理解為自我提升(self-improvement)微調
- 采樣過程-on-policy算法:采樣一個batch,然后通過KL散度和reward進行擬合訓練并不斷循環
- 采樣算法:包含蒙特卡洛采樣、do_sample采樣、group beam search、dvts等
- 采樣過程額外引入細節:可以引入ORM(結果判斷),PRM(過程打分),多樣性過濾,語種過濾等
2.3.2?使用數據訓練目標模型
訓練的方式:
- 如果使用SFT,則稱為拒絕采樣微調
- 如果是強化學習,則稱為強化學習微調
2.3.3?根據需要判斷是否重復上述過程
-
如果使用更大的模型蒸餾,例如更大模型的蒙特卡洛采樣蒸餾,一般不會有循環
-
如果使用本模型進行采樣,或者PPO等算法,則會有循環
2.4 常見的強化微調方式
- 蒸餾:使用蒙特卡洛、do_sample等方式從超大模型中采樣大量優質數據,訓練小模型
- 自我提升:從本模型中采樣部分優質數據,篩選后訓練本模型,循環執行
- on-policy RL:使用PPO、GRPO等方式循環訓練
2.5 ms-swift的展示demo
SFT和RFT的區別:
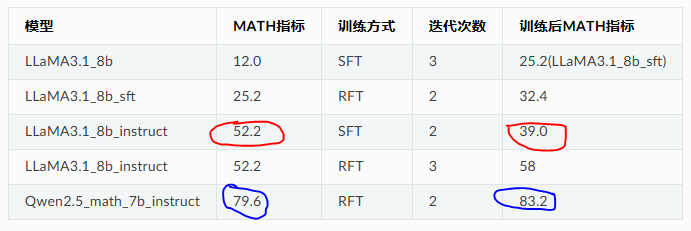
使用competition_math直接SFT后,instruct模型的掉點十分嚴重。而RFT后模型能力有提升,即使對Qwen2.5_math_7b_instruct這個SOTA的math模型也同樣有一定提升空間。

同樣可以發現,Qwen2.5這個模型經過RFT后在原有的其他數據集gsm8k上也沒有出現大幅度回退(這就是為什么比SFT好的原因,新數據集上有效果,舊數據集上不坍塌)。
參考資料:強化微調 — swift 3.8.0.dev0 文檔
三、demo代碼分析
3.1 main函數分析
遵循第二節的流程:
- 先采樣;
- 再做RLT
- 再做循環-5次
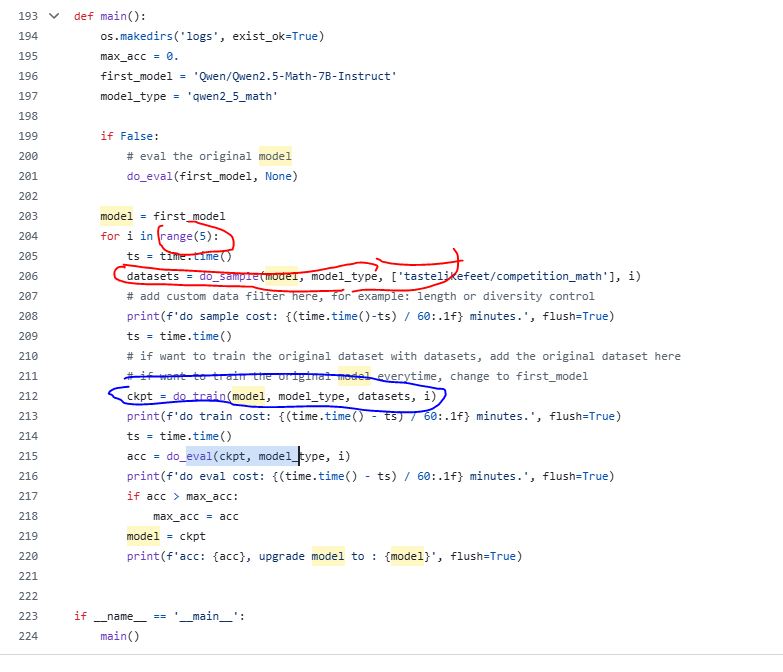
注意:以上這些流程都是使用python拼接輸入命令行,不是一個函數就搞定了所有的代碼哈,核心的這些命令行的功能都被swift封裝在框架里面了,尤其是PRM模型的選取這些。
3.2 do-sample采樣函數
如下圖所示,過程獎勵模型使用了Qwen2.5-Math-PRM-7B模型,為每一塊GPU上生成了一個采樣的RFT數據集
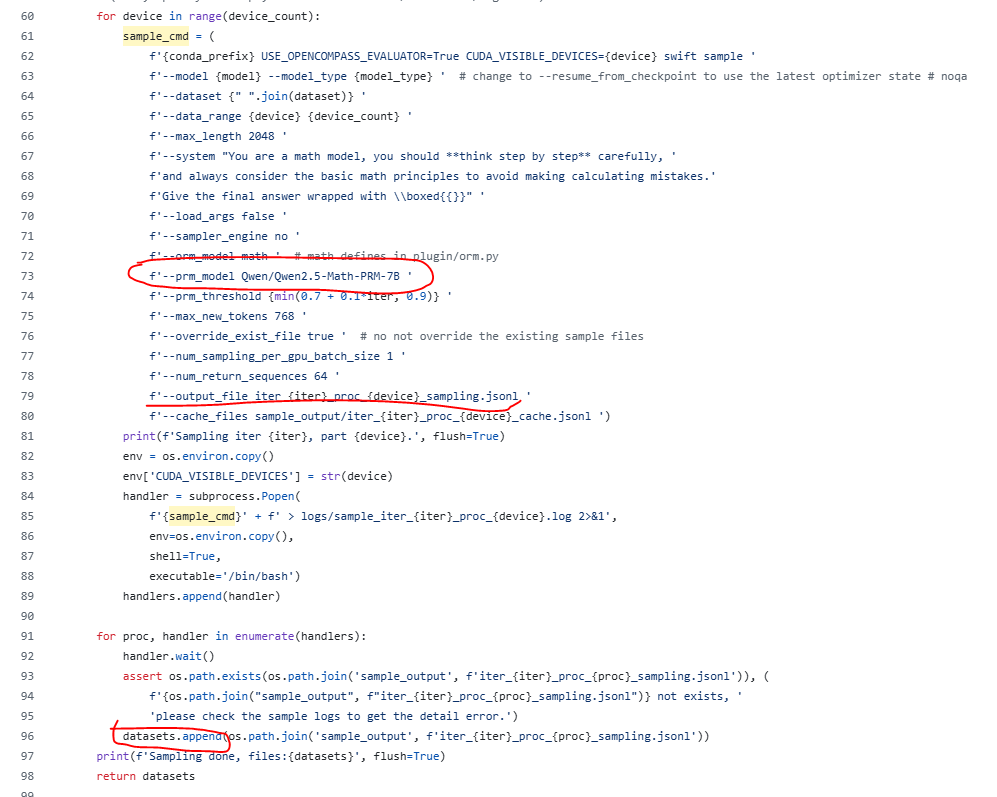
PRM模型和PRM_threshold如何配合形成采樣數據集:



3.3 do_train訓練函數
直接將rlhf的訓練type寫入啟動腳本,開始強化微調:
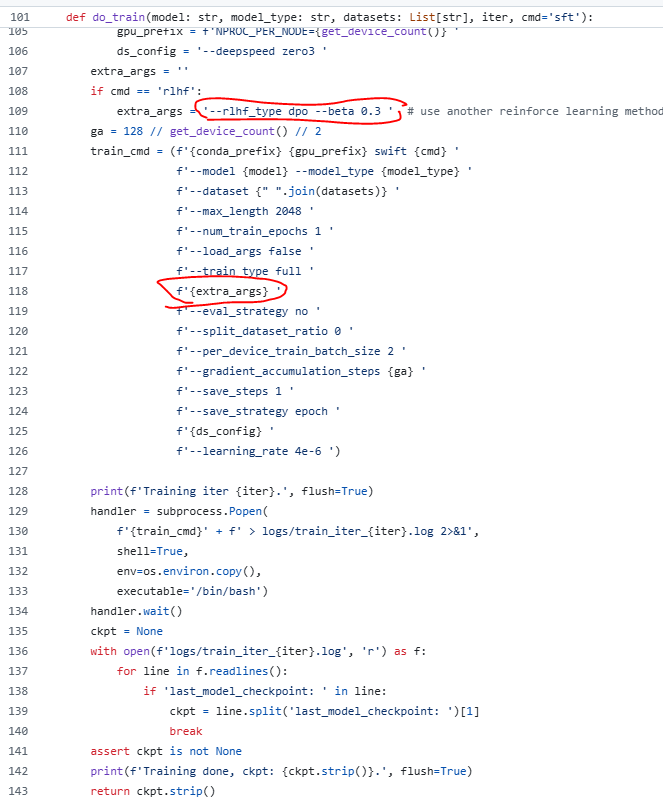
代碼參考:https://github.com/modelscope/ms-swift/blob/main/examples/train/rft/rft.py
四、實際項目舉例
閑下來再寫吧 這個要記錄自己的實驗結果,我后續截圖補充再寫












》)






驅動開發)