? ? ? ? ?
づ?ど
?🎉?歡迎點贊支持🎉

個人主頁:勵志不掉頭發的內向程序員;
專欄主頁:python學習專欄;
文章目錄
前言
一、變量作用域
二、函數執行過程
三、鏈式調用
四、嵌套調用
五、函數遞歸
六、參數默認值
七、關鍵字參數
總結
前言
上一章節我們了解到了 Python 中的函數的最基本的定義和調用規則,本章節我們繼續來深入函數學習,來學習函數的不同結構以及不同的調用方法。我們一起來看看吧。

一、變量作用域
來觀察以下代碼。
def getPoint():x = 10y = 20return x, yx, y = getPoint()在這個代碼中,函數內部存在 x,y,函數外部也有 x,y。但其實這兩個 x,y 不是相同的變量,而只是恰好有一樣的名字而已。
我們可能會經常發現有的時候同一個變量名在不同的地方多次出現。但是這個同一個變量名并不意味著是同一個變量。就比如我管我最喜歡的東西叫做 “寶貝兒”,但是大家肯定也有自己的 “寶貝兒”。雖然都是 “寶貝兒”,但是顯而易見不是同一個東西。
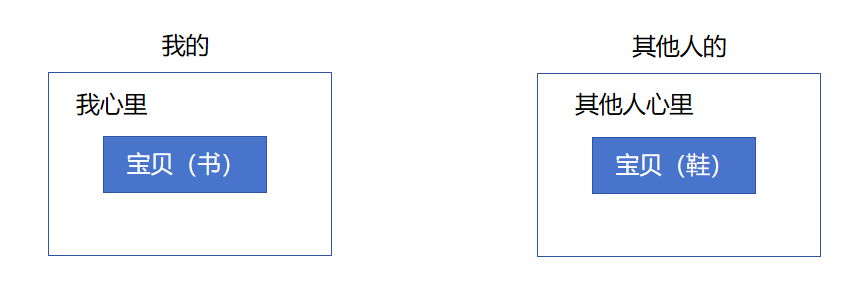
雖然名字一樣,但其實也是不會混淆的。因為它是在各自不同的范圍生效的。我叫我的寶貝是我和我寶貝之間的事情,而其他人叫他的寶貝也只是他和他寶貝之間的事情。它們互不影響。
以上的一個情況就描述了一個概念,那就是變量的作用域。一個變量名的有效范圍是一定的,只在一個固定的區域內生效。
我們剛才的那一串代碼。
def getPoint():x = 10y = 20return x, yx, y = getPoint()getPoint() 中的 x,y 是函數內部的變量名,函數內部的變量名只能在函數內部生效,出了函數就無效了。
def getPoint():x = 10y = 20return x, ygetPoint()
print(x, y)我們來嘗試直接在函數外面打印我們函數內部的變量名。
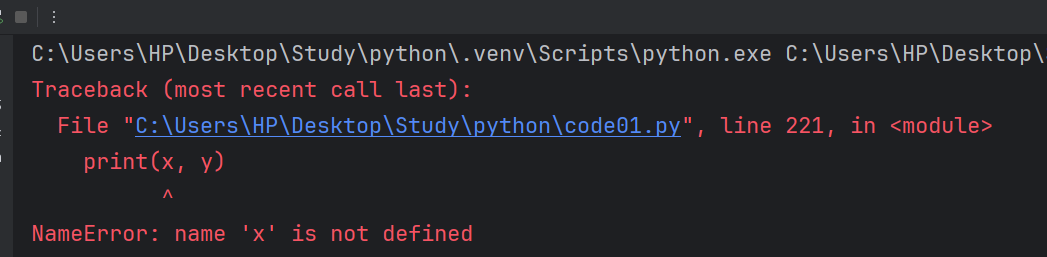
它會報錯,并且說 x 未定義。既然我們函數內部的變量在函數外部無法生效,這也就意味著我們在函數外面同樣可以使用 x,y 的變量名。此時,這兩個 x,y 就是完全不相同的變量。
我們再來看看這個例子。
x = 10def test():x = 20print(f"函數內部:{x}")test()
print(f"函數外部:{x}")此時我們就能更加清楚的看到相同變量名的區別了。
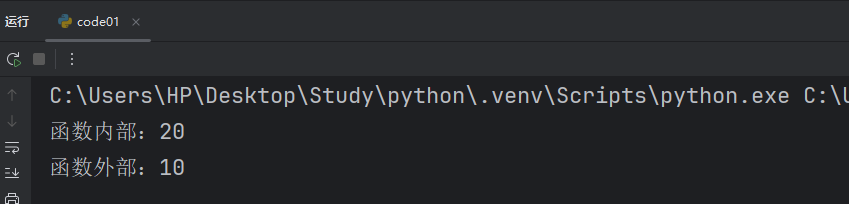
我們把 x = 10 代碼所處的位置叫做全局變量,全局變量是在整個程序中都有效的。而函數內部的 x = 20 叫做局部變量,只在函數內部有效。由于全局變量是在整個程序中都有效的,所以我們函數中也是可以使用我們的全局變量的。
x = 10def test():print(f"函數內部:{x}")test()當函數訪問某個變量的時候,會先嘗試在局部變量中查找,如果找到,就直接訪問,如果沒找到,就會往上一級作用域中進行查找。test 再往上一級作用域,就是全局了。

可以如愿的輸出我們的 10。
我們讀取還是比較簡單的,但是我們修改操作就沒那么容易了。
x = 10
# 使用這個函數,把全局變量 x 改成20
def test():x = 20test()
print(f"x = {x}")我們如果直接修改是不行的。
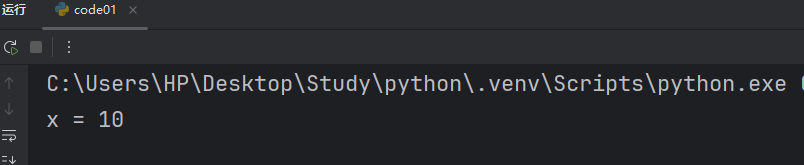
這是因為我們 x = 20 的 x 被當成函數內部創建的一個局部變量。所以沒辦法改,如果想要改成20,我們就得使用 Python 中的一個關鍵字 global 聲明一下我們的 x,我們的就能修改全局變量的 x 了。
x = 10
# 使用這個函數,把全局變量 x 改成20
def test():global xx = 20test()
print(f"x = {x}")此時我們的修改就是針對全局的修改了。

當然,像 if,else,while,for 這些關鍵字也會引入 “代碼塊”,但是這些代碼塊不會對變量的作用域產生影響。在上述語句代碼塊內部定義的變量,可以在外面被訪問。
for i in range(1, 11):print(i)print("--------------------")
print(i)我們可以看到,我們在 for 循環里面創建的變量 i,在外面也能打印出來。
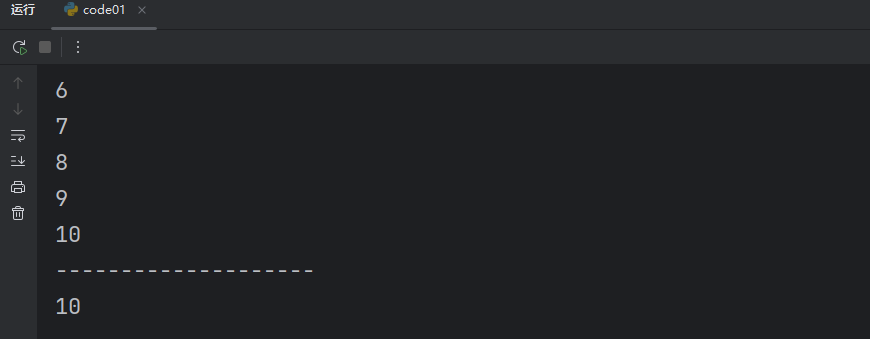
其他的也是同理。所以說不是遇到代碼塊就一定會影響作用域,在 Python 中只要函數和類里面的代碼塊才會涉及到作用域。
二、函數執行過程
- 調用函數才會執行函數體代碼,不調用則不會執行。
- 函數體執行結束(或者遇到 return 語句),則回到函數調用位置,繼續往下執行。
def test():print("執行函數體代碼")print("執行函數體代碼")print("執行函數體代碼")print("111111")
test()
print("222222")
test()
print("333333")
test()
print("444444")我們通過這個代碼來嘗試看看我們函數的執行過程。
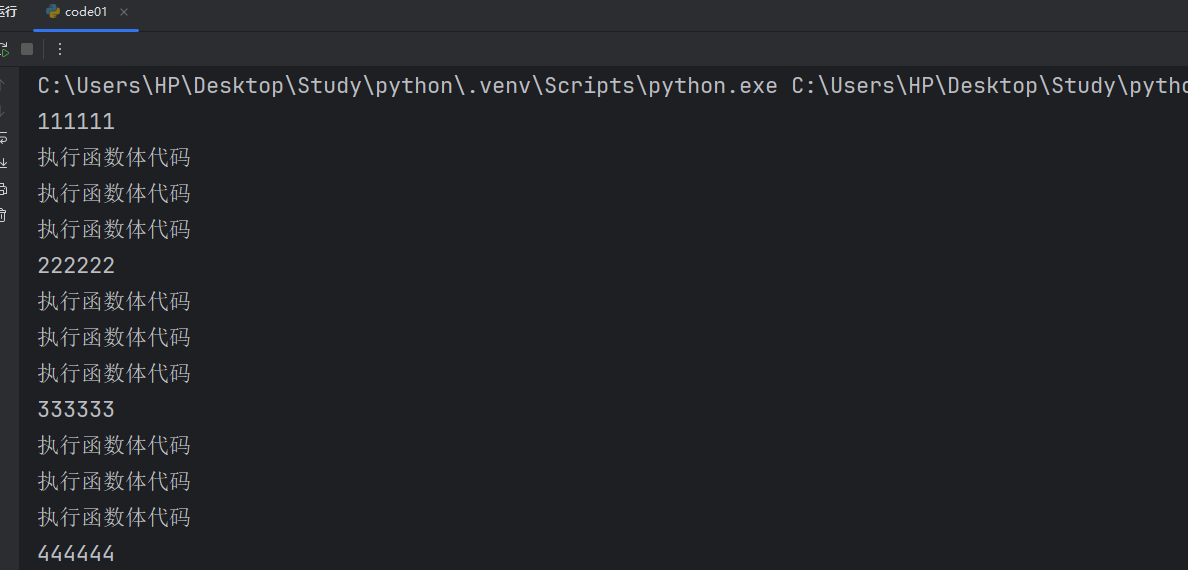
我們可以通過執行結果來簡單分析一下。
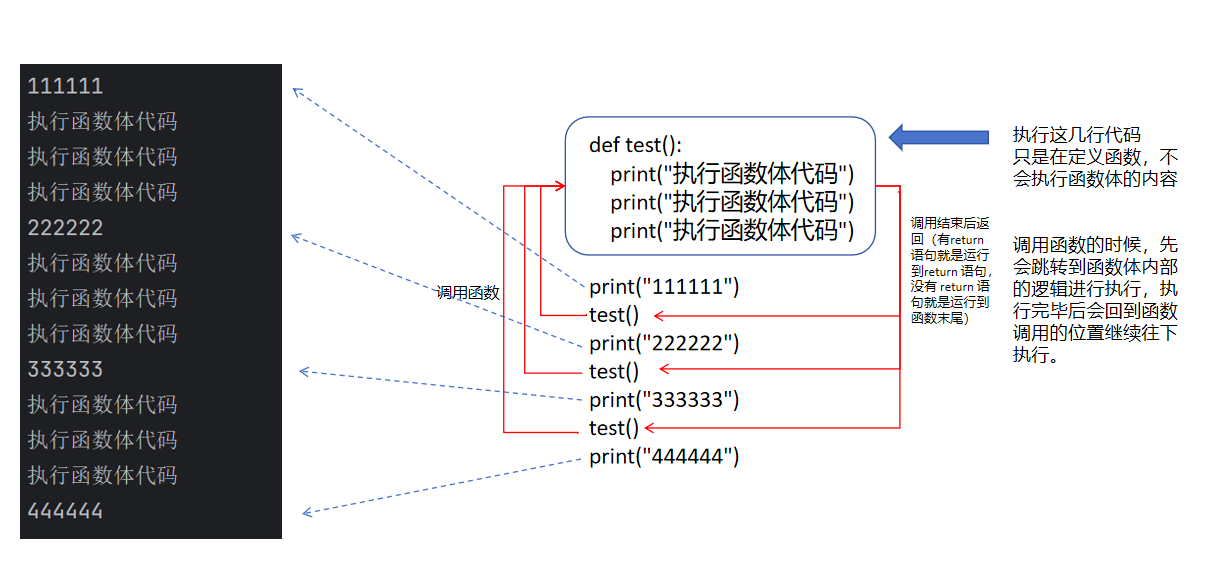
我們程序的運行就是在這些各種函數之間不斷的跳轉,就像盜夢空間一樣,可以在夢里做夢,當夢醒了就又跳轉回原來的夢中,就在這些夢中不斷的跳轉。
我們剛才是通過函數結果來一一分析的,其實我們還可以調用 PyCharm?中的調試器,也能看到一樣的效果。我們可以在行首部分點擊一下就可以打一個斷點,再點一下就會取消。

當我們右鍵時不要選擇運行,而是選擇下面的調試。
我們的程序就會執行到調試執行的模式。我們調試執行和運行的區別就在于我們調試執行遇到斷點就會停下來,也可以隨時停下來,方便我們程序猿去觀察程序的中間過程。
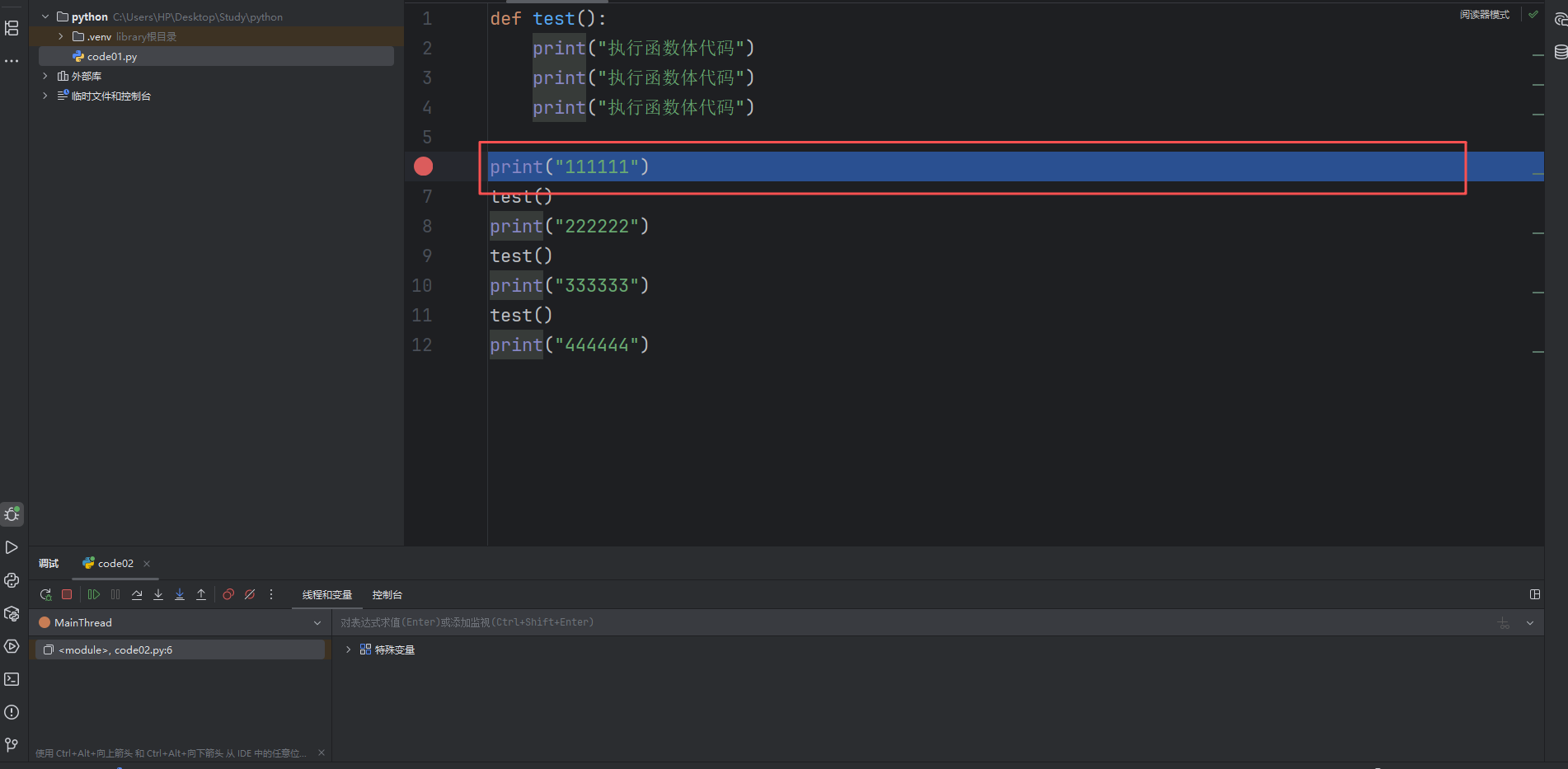
此時我們的程序運行到我們斷點處就停下來了。此時我們就可以讓我們程序一步一步的走。

我們可以在這個地方看到好幾個按鈕。
我們選擇這個按鈕,它就是單步執行我們的代碼,并且遇到自己的函數,能夠進入到函數里面。當然只有調試才可以,運行不行。大家可以自己去嘗試一下,可以看到我們程序的執行過程就和剛才推測的一樣。
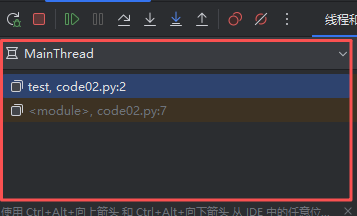
按鈕下面是函數調用棧,描述了當時的代碼是怎么跳轉過去的(進一步的也就是函數之間的調用關系)。
三、鏈式調用
所謂的鏈式調用,就是用一個函數的返回值作為另一個函數的參數。
我們之前寫過一個代碼。
def isOdd(num):if num % 2 == 0:return Falsereturn Trueresult = isOdd(10)
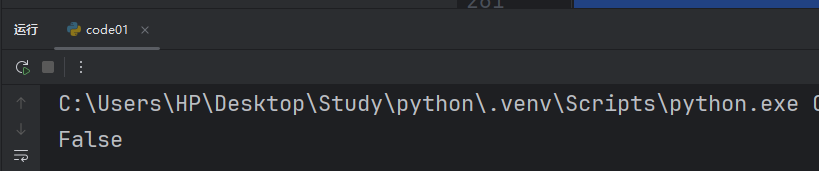
print(result)直接運行就能打印出我們正確的值。
當然,這個代碼我們可以直接簡化成這個樣子。
def isOdd(num):if num % 2 == 0:return Falsereturn Trueprint(isOdd(10))形如這樣的代碼,就叫做函數的鏈式調用。當然,我們的鏈式調用還可以有多層。
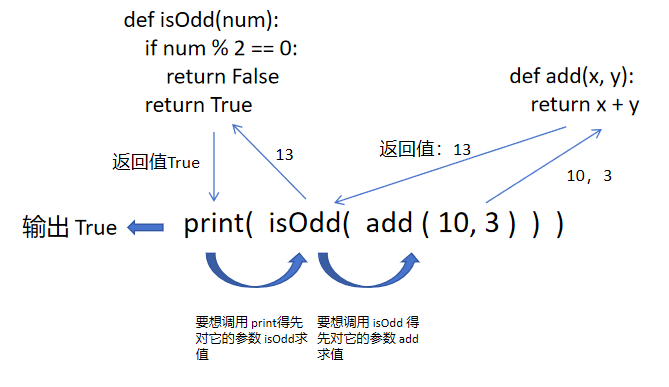
def isOdd(num):if num % 2 == 0:return Falsereturn Truedef add(x, y):return x + yprint(isOdd(add(10, 3)))此時就相當于又來了一層鏈式調用,此時我們add算出來返回值為 13,我們返回值13就變成了isOdd 的參數了,然后 isOdd 判斷出來是奇數,返回值 True 又變成了 print 后輸出。
在鏈式調用中,先執行 ( ) 里面的函數,后執行外面的函數。換句話說,調用一個函數,就需要先對他的參數求值。
雖然我們鏈式嵌套是很常見的,但是我們也不用嵌套層次太深,因為這樣會影響我們的可讀性。
四、嵌套調用
一個函數的函數體內部,還可以調用其他函數。
舉一個簡單的例子。
def test():print("hello")test()這就屬于一個嵌套調用,我們的 test 中嵌套了一個 print,雖然不是我們自己寫的,但它也是一個函數。
同時,我們嵌套調用的層次可以有很多層
def a():print("函數 a")def b():print("函數 b")a()def c():print("函數 c")b()def d():print("函數 d")c()d()這就是我們比較復雜一點的函數嵌套。
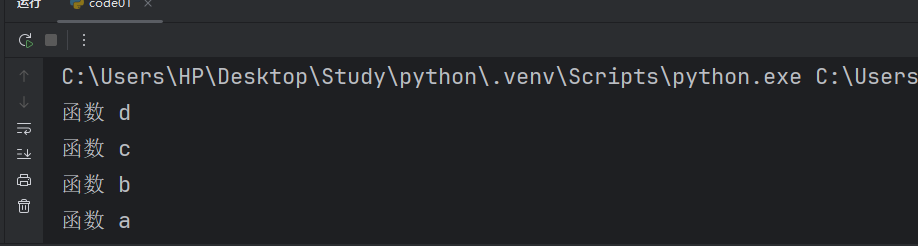
我們來看看這個代碼的執行過程。
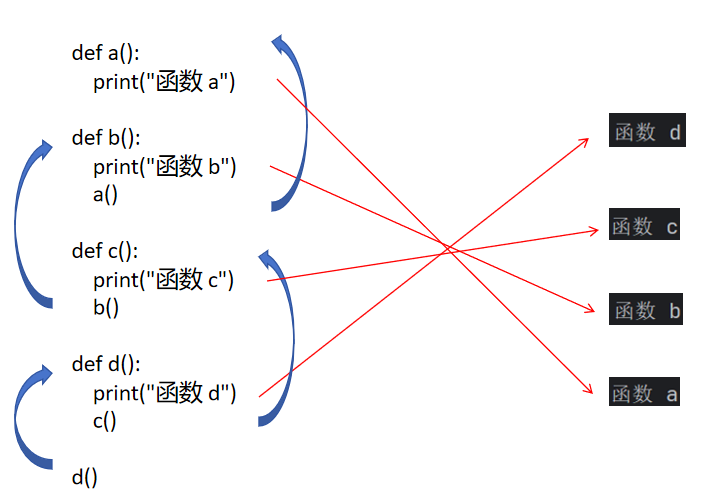
雖然我們函數嵌套了多層,但是函數的執行邏輯是沒有什么變化的。
如果我們把代碼的位置稍微修改一下,我們的執行結果就會天差地別。
def a():print("函數 a")def b():a()print("函數 b")def c():b()print("函數 c")def d():c()print("函數 d")d()我們這里先調用在打印,結果完全相反。
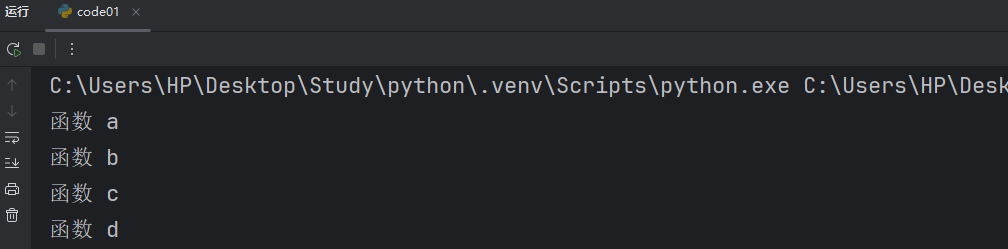
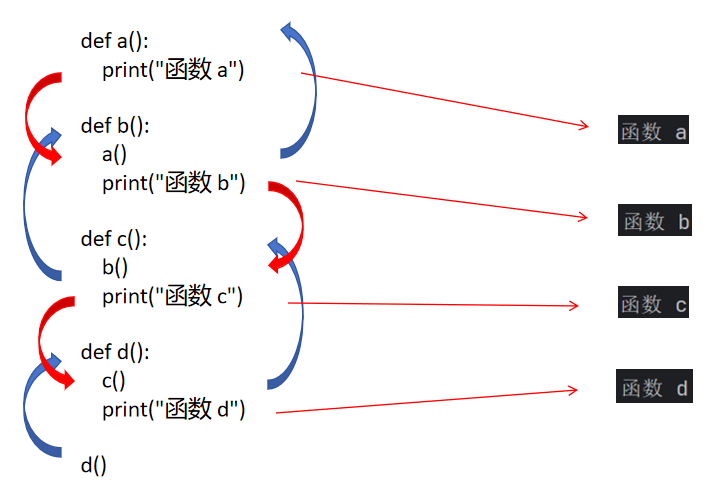
我們代碼稍微微調了一下后就出現了截然相反的結果,所以我們一定要搞明白函數調用的基本過程。當然我們上述過程依然可以用調試器分析。
五、函數遞歸
遞歸時嵌套調用中的一種特殊情況,即一個函數嵌套調用自己。
我們大部分人可能小時候就聽過一個故事:從前有座山,山里有座廟,廟里有個老和尚再給小和尚講故事,故事的內容是:從前做山........

這個故事永遠沒有盡頭。
我們可以來試著用上面的邏輯來生成一個代碼。
# 寫一個函數,來求 n 的階乘(n 是正整數)
def factor(n):result = 1for i in range(1, n + 1):result *= ireturn resultprint(factor(5))這是我們通過循環的方式來寫的求階乘的方法。

我們覺得沒啥意思,于是決定換一種方式,通過遞歸的方式來寫。
我們可以發現:
n! => n * ( n?- 1 )!? ? ? ? // 遞推公式
1! == 1? ? ? ? ? ? ? ? ? ? ? ? // 初始條件
我們知道了遞推公式和初始條件,我們就能來寫遞歸函數了。
def factor(n):if n == 1:return 1return n * factor(n - 1)print(factor(5))我們 return n * factor(n - 1) 其實就是我們的遞推公式,而 return 1 就是我們的初始條件。

這一串代碼雖然寫起來沒幾行,但是其實理解起來還挺困難的,我們來看看它的執行過程。
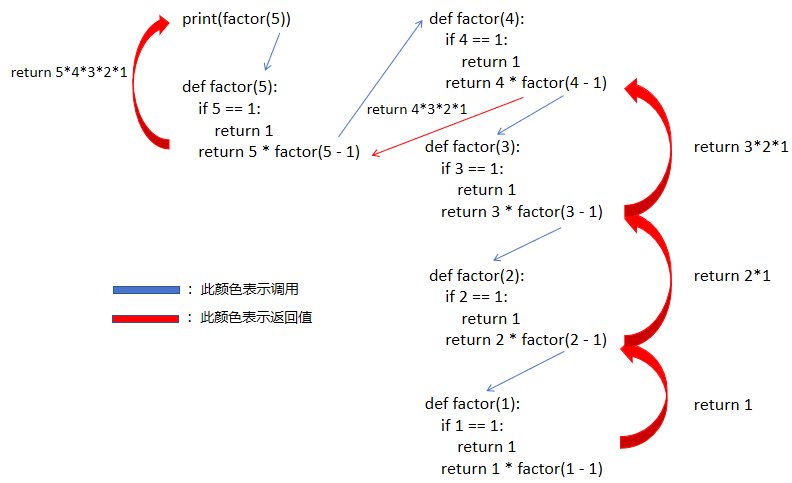
我們可以看到,雖然都是 n,但是 n是函數形參,形參相當于函數的局部變量。我們的遞歸代碼,不會無限的往下執行,會在每一次遞歸的時候,都會無限逼近遞歸的結束條件。
我們遞歸的代碼,雖然很多時候看起來寫法很簡單,但是執行過程可能會非常復雜,在分析遞歸代碼的時候,光靠腦子想,是很困難的。所以在分析遞歸過程時,最好就是畫圖,或者借助調試器去進一步了解遞歸的過程。
我們遞歸代碼必須有兩個要素,第一就是遞歸結束條件,第二就是遞歸的遞推公式。這和數學歸納法很相像(也是兩個條件:初始條件和遞推公式)。
我們遞歸的缺點在于:
1、執行過程非常復雜,難以理解。
2、遞歸代碼容易出現棧溢出的情況。
3、遞歸代碼一般都是可以轉換成等價的循環代碼的,并且循環的版本通常運行速度比遞歸版本有優勢。
我們的遞歸代碼,不會無限的往下執行,會在每一次遞歸的時候,都會無限逼近遞歸的結束條件,但是如果我們的代碼寫錯了,就會導致我們每次遞歸參數不能正確的接近遞歸結束條件,就會出現無限遞歸的情況。
def factor(n):if n == 1:return 1return n * factor(n)print(factor(5))假如是這樣就會報錯。
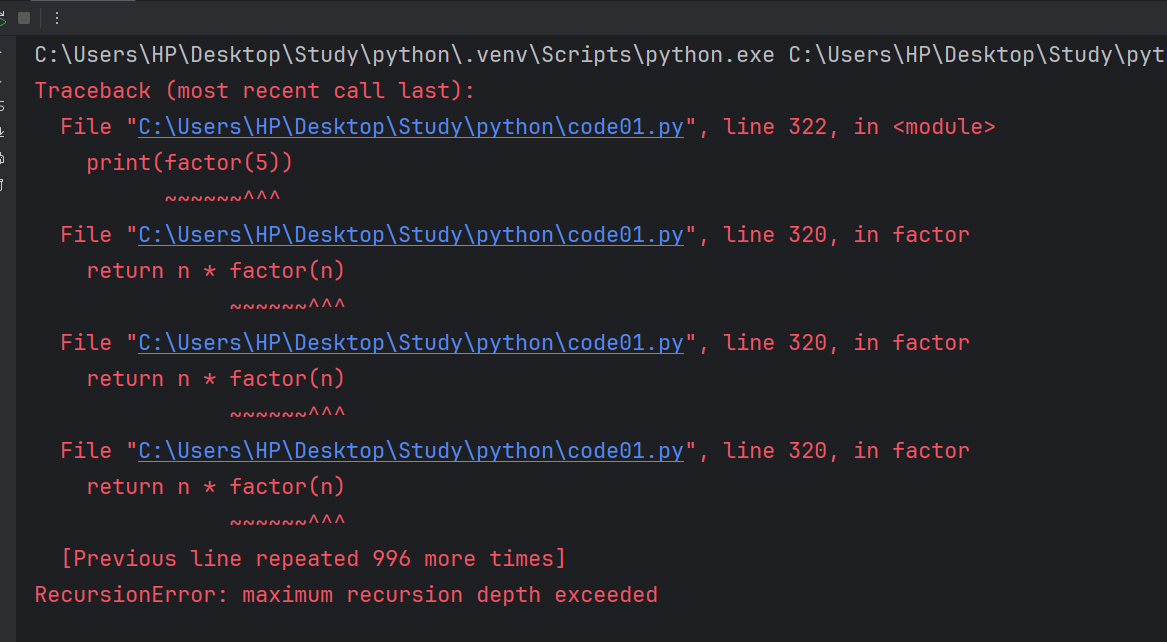
遞歸的優點就在于代碼非常簡潔,尤其是處理一些 “問題本身就是通過遞歸的方式定義的”。
六、參數默認值
Python 中的函數,可以給形參指定默認值。
帶有默認值的參數,可以在調用的時候不傳參
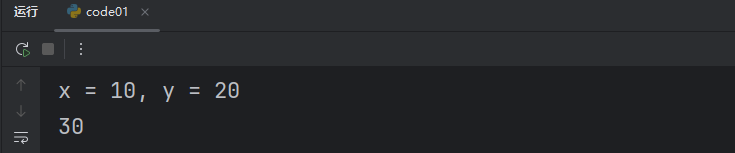
def add(x, y):print(f"x = {x}, y = {y}")return x + yresult = add(10, 20)
print(result)我們完成了一個基本的函數調用。
在函數內部加上打印信息,可以方便我們進行調試。但是像這種調試信息,我們希望在正式發布的時候不要有,只是在調試階段才有,此時我們可以給我們代碼增加一個條件語句。
def add(x, y, debug):if debug:print(f"x = {x}, y = {y}")return x + yresult = add(10, 20, True)
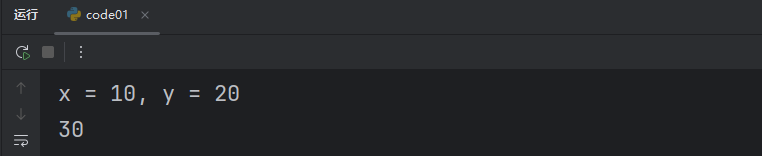
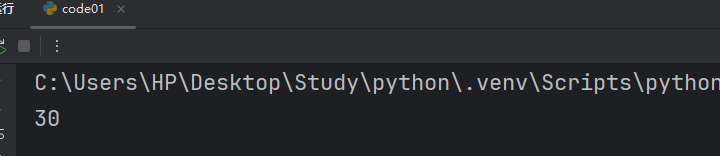
print(result)此時我們可以在調用函數時傳遞 True/False,當傳遞 True 時就有調試信息,傳遞 False 時就沒有。
True:
False:
但是這樣每次傳遞函數都得傳一個 True/False,看上去比較丑,所以我們可以在 debug 上指定一個默認參數。
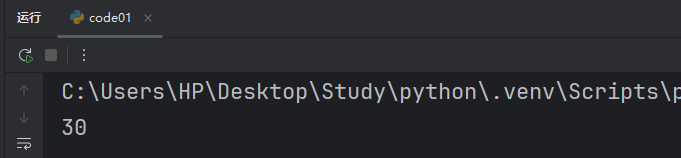
def add(x, y, debug = False):if debug:print(f"x = {x}, y = {y}")return x + yresult = add(10, 20)
print(result)此時如果我們不傳 debug 的參數,就默認是 False。
如果我們想要調試,只需要手動加上我們的 True即可。
result = add(10, 20, True)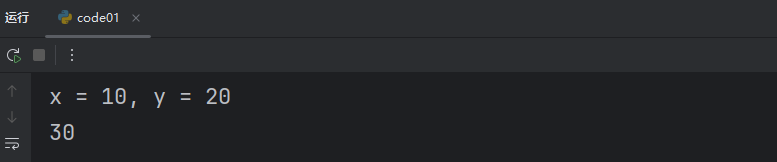
我們此處的 debug = False 就是我們形參的默認值,帶有默認值的形參就可以在調用函數時不必傳參,不傳參就是使用我們的默認值。通過這樣的默認值,就可以讓我們函數設計的更加靈活。
我們默認值也有一些要求,它要求帶有默認值的形參,得在形參列表后面,而不能在中間。
def add(x, debug = False, y):if debug:print(f"x = {x}, y = {y}")return x + y這樣是不允許的,這樣我們傳遞第二個參數時不知道是給 debug 還是給 y 的。
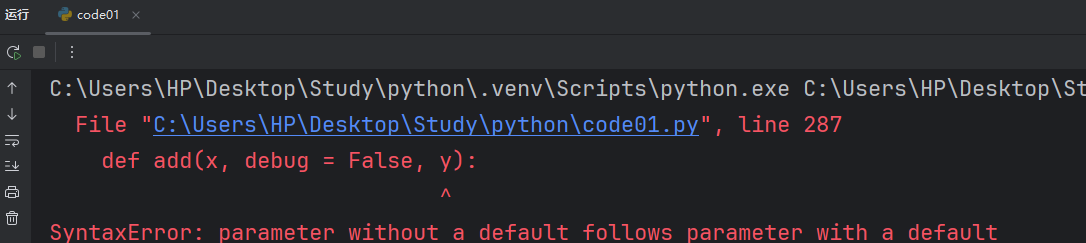
錯誤提示是不能把非默認參數放到默認參數前。所以如果多個帶有默認參數的形參,這些都得放到后面。
七、關鍵字參數
在調用函數的時候,需要給函數指定的實參,一般默認情況下是按照形參順序,來依次傳遞實參的。但是我們也可以通過關鍵字參數來調整這里的傳參順序,顯式指定當前實參傳遞給哪個形參。
def add(x, y):return x + yadd(10, 20)我們的第一個實參 10 就是傳遞給我們第一個形參?x 的,而第二個實參 20 就是傳遞給我們第二個形參?y 的。這種按照先后順序來傳參的這種傳參風格稱為 “位置參數”。這是各個編程語言中最普遍的方式。
除了上種方式外,Python 還有一中非常有特色的傳參方式,那就是關鍵字傳參,也就是按照形參的名字來進行傳參。
def test(x, y):print(f'x = {x}')print(f'y = {y}')test(x = 10, y = 20)我們調用的參數中的 x、y 就是從形參而來。此時我們運行程序。

使用這種關鍵字參數的最大意義就是能夠非常明顯的告訴我們程序猿說我們的這些參數是要傳給誰。另外可以無視形參和實參的順序。
test(y = 100, x = 200)倒過來寫也是完全可以的。

我們位置參數和關鍵字參數還可以混合使用,只不過混合使用時我們要求位置參數在前,關鍵字參數在后。
而我們關鍵字參數一般都是搭配默認參數來使用的。一個函數,可以提供很多參數來實現對這個函數內部功能做出一些調整設定,但是為了降低調用者的使用成本,就可以把大部分參數設定出默認值。當調用者需要調整其中的一部分參數時,就可以搭配關鍵字參數來進行操作。
總結
以上便是我們函數主要的內容,比起其他的語言,多了不少新的特性,我們可以多加感悟它的新特性,但是想要熟練掌握還是得多多刷題,多多敲代碼,練習也是學習的一部分。
🎇堅持到這里已經很厲害啦,辛苦啦🎇
? ? ? ? ?
づ?ど



















)
