前面有寫過一篇瀑布流的采集方法,今天在添加一個POST方法來采集Ajax刷新頁面的教程。
之前的文章請看:火車頭采集動態加載Ajax數據(無分頁瀑布流網站)
如果遇到POST方法來架子Ajax數據,這和我之前寫的是兩個類型,瀑布流是直接刷新出數據的頁面。
采集網站分析
采集任何一個新站前我們都要對他進行一番分析才好下手。
列表頁分析
這個網站的列表頁,前面并不是通過Ajax加載的。CTRL+U可以直接看到列表內容,通過瀏覽器也看不到相關請求地址。
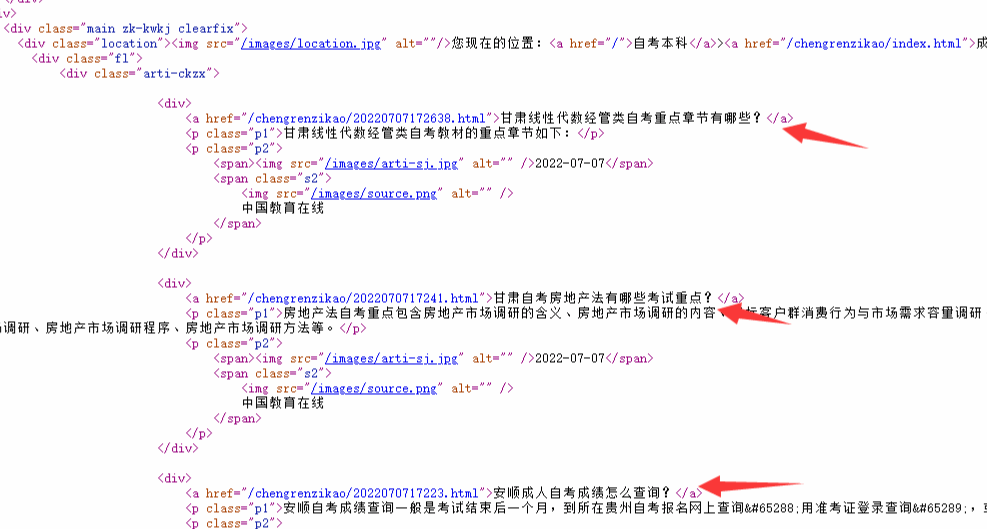
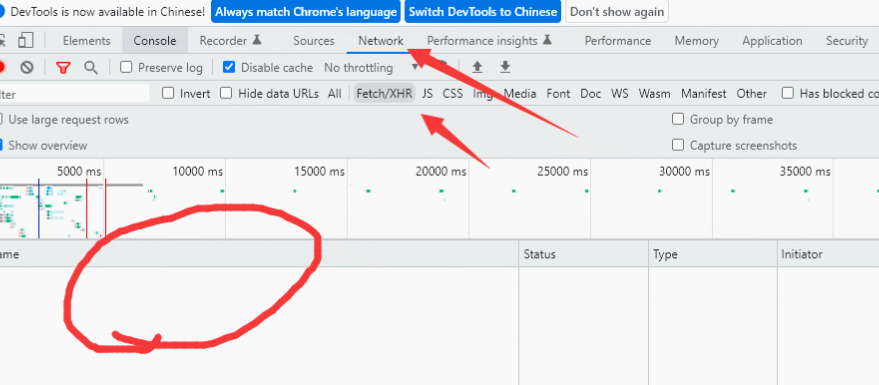
因為習慣原因,我直接看了下尾頁列表頁。然后順手CTRL+U看看網站代碼結構有沒有大的變化。防止后期采集出錯。結果就發現無法看到列表內容。瀏覽器可以看到一個通過post請求的地址。
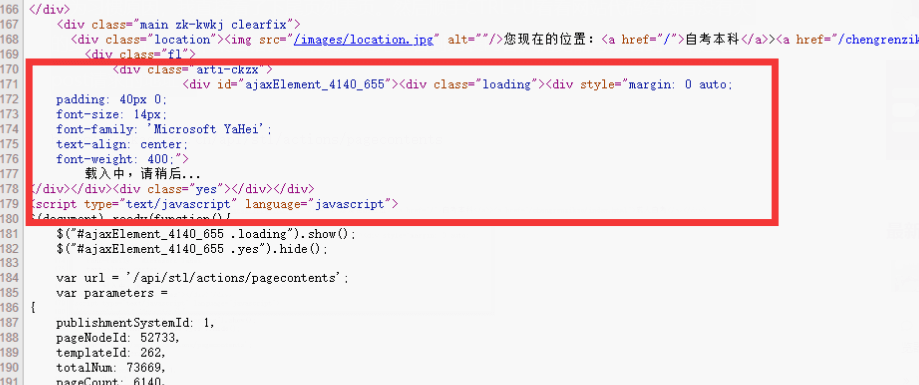
這時候就意識到這網站列表頁可能后面的應該全是通過Ajax加載的。
通過笨方法,手動訪問頁面看看Ajax加載大概是哪些。最后找到大概從2200頁左右開始Ajax加載。
那我們采集的時候,前面的列表頁就可以使用普通方式去采集(速度更快)。
2200頁開始到尾頁就通過post請求Ajax頁面數據。
抓包獲取Post數據
這個Ajax地址我在瀏覽器看不到任何跟頁碼有關的數據。最后只能使用抓包工具看一下詳細的請求內容了。
使用抓包工具Fiddler
Fiddler下載地址:OneDrive-Fiddler-Setup_v5.0.20204.45441.zip
安裝設置完成后我們打開瀏覽器。重新訪問一下采集頁面,Fiddler會抓到很多請求地址。
查看分析Post數據
Ctrl+F 我們搜索那個Ajax地址
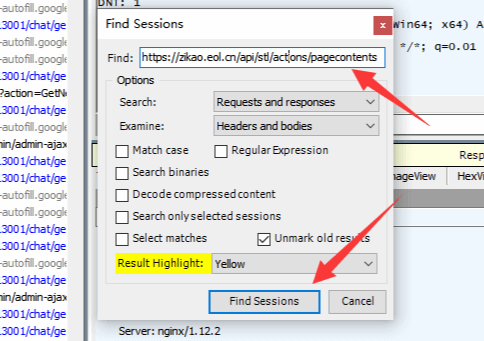
Fiddler會以黃色將搜索到的結果顯示出來,我們點擊一下他。
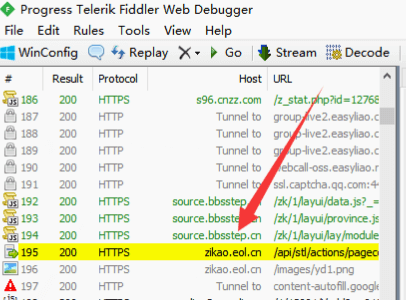
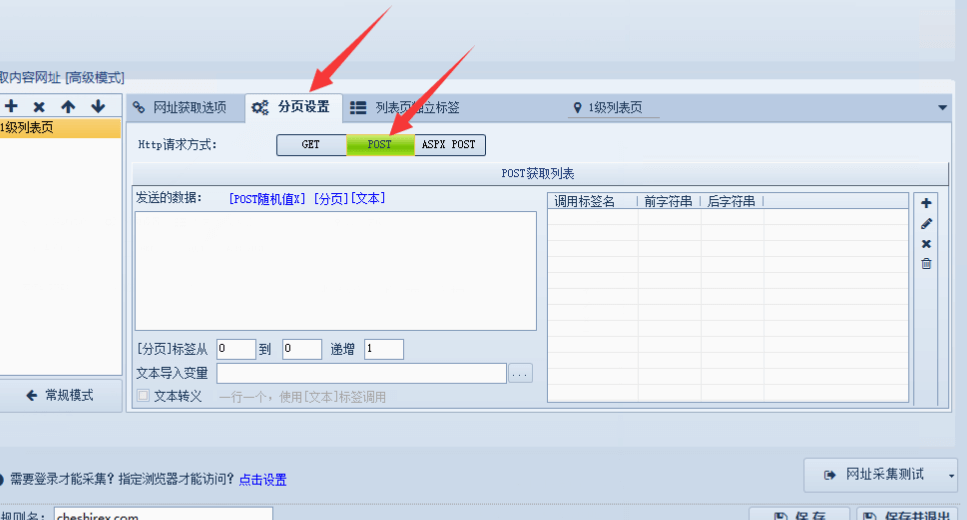
在Fiddler右側會顯示這個請求地址的相關詳細信息。
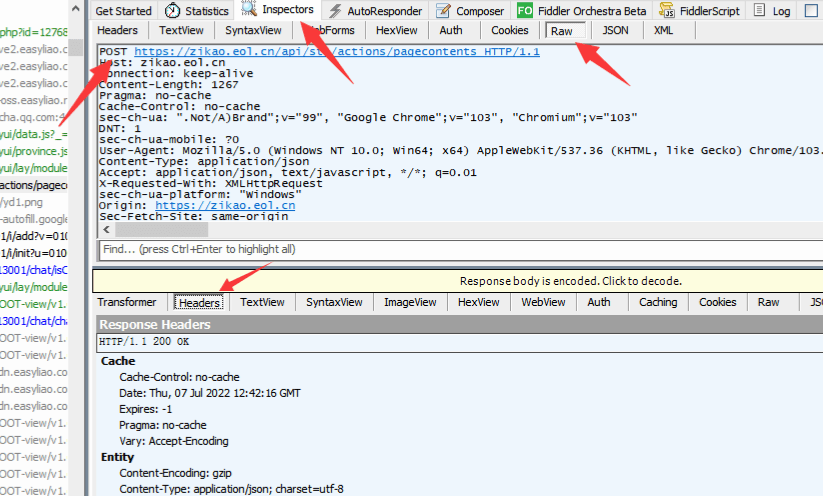
信息頂部可以看到是post請求方法。往下拉。
可以看到有我們請求的頁碼相關內容。
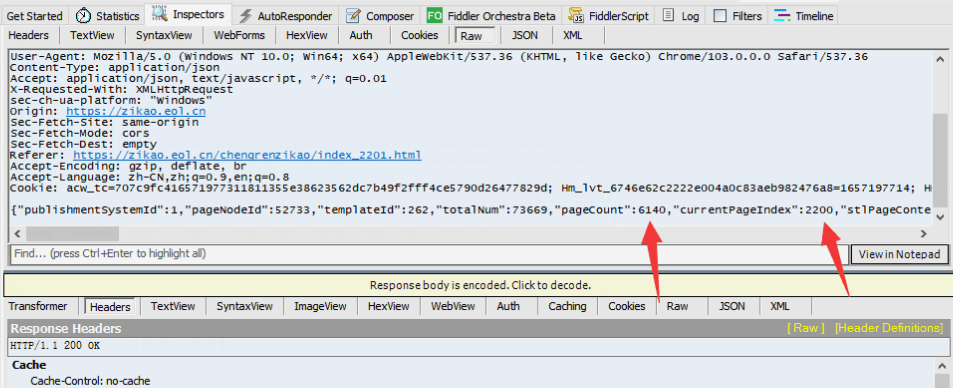
訪問不同頁碼的頁面,經過研究發現規律。
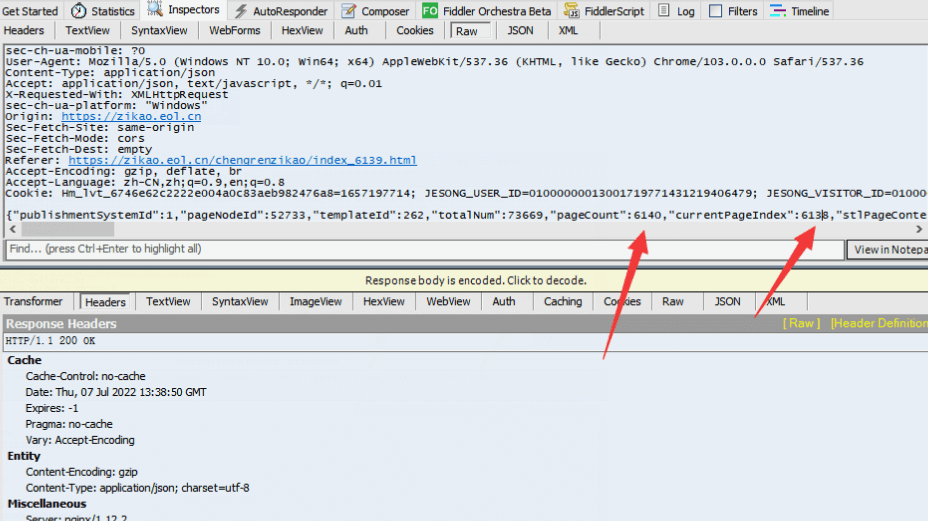
currentPageIndex的值和頁碼相關,值等于頁碼減一。我們訪問6139頁時,currentPageIndex值是6138。
這就找到了規律,我們打開火車頭采集器。
火車頭采集器配置
分頁設置
起始網址填入Ajax請求地址
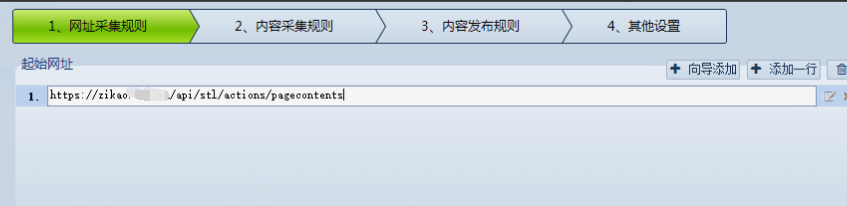
點“高級模式”。
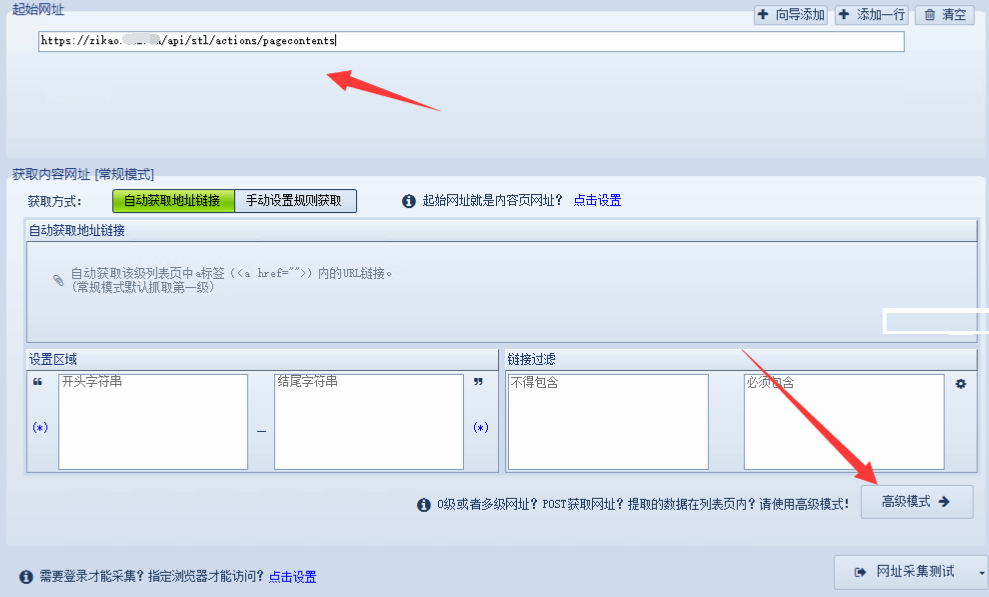
點“分頁設置”,http請求方式“post”。
把我們Fiddler抓包獲取的內容填進去。
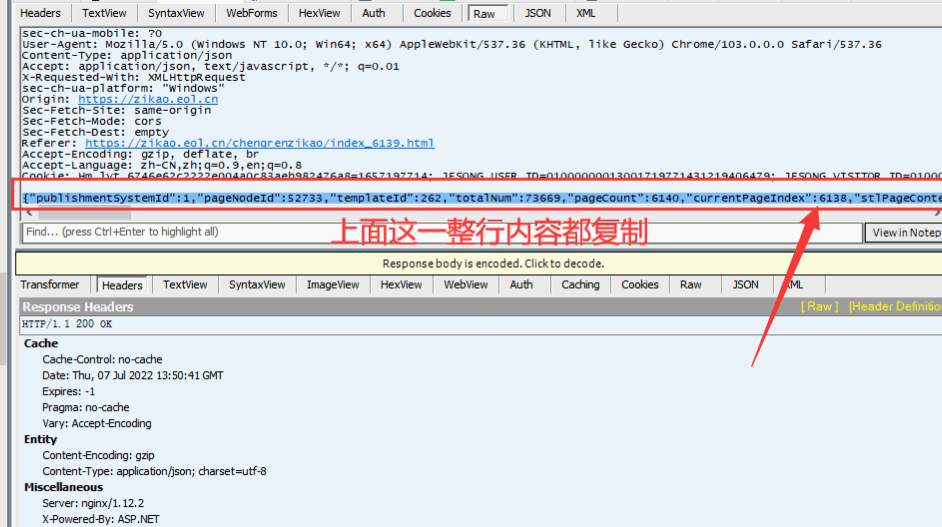
將currentPageIndex值的內容替換成火車頭采集器的“分頁”標簽。
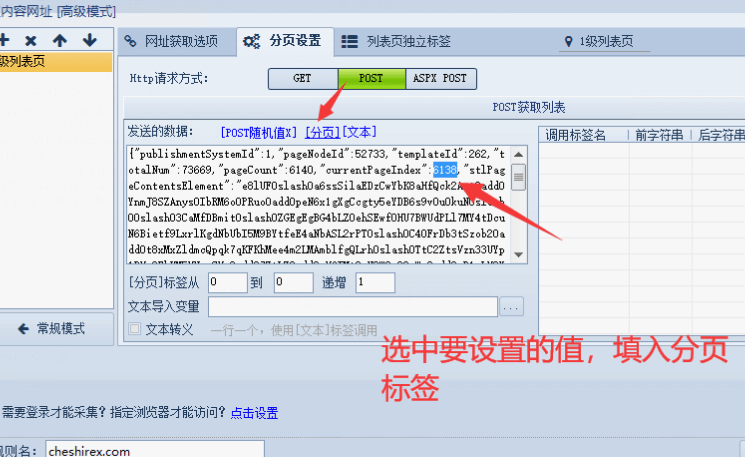
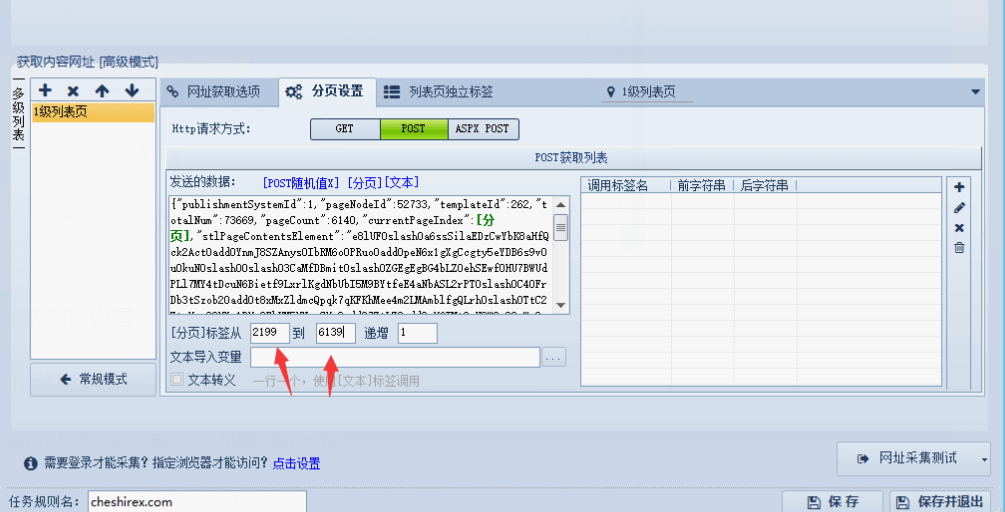
下面填入頁碼。
頁面地址是從2200到6140,上面我們分析得出post請求內容的currentPageIndex值是實際頁碼減一。所以這里面我們填2199到6139.
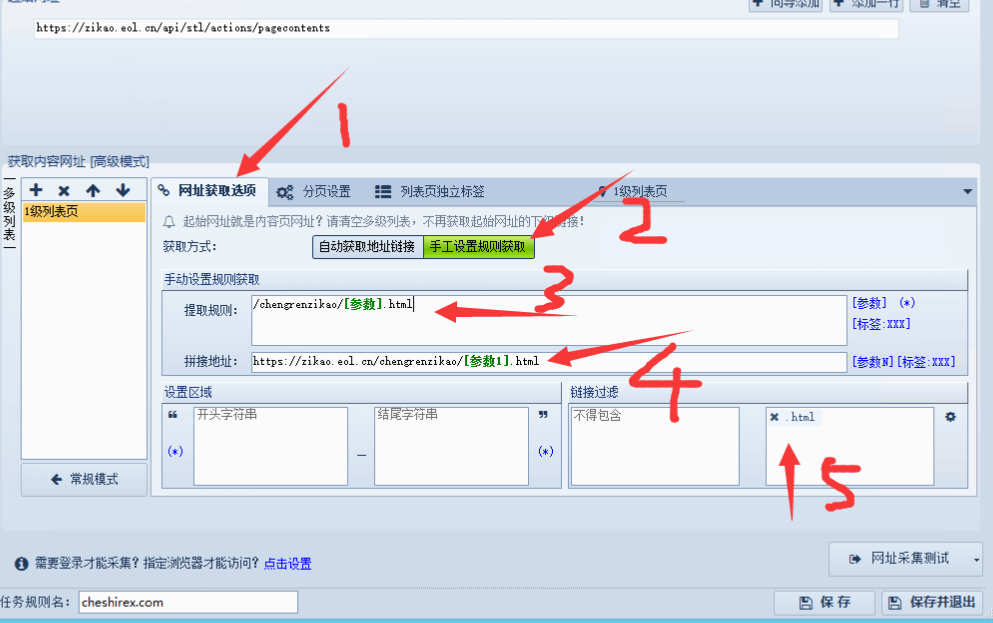
網址獲取選項設置
為了篩選出我們需要的內容,我們設置一下網址獲取選項。
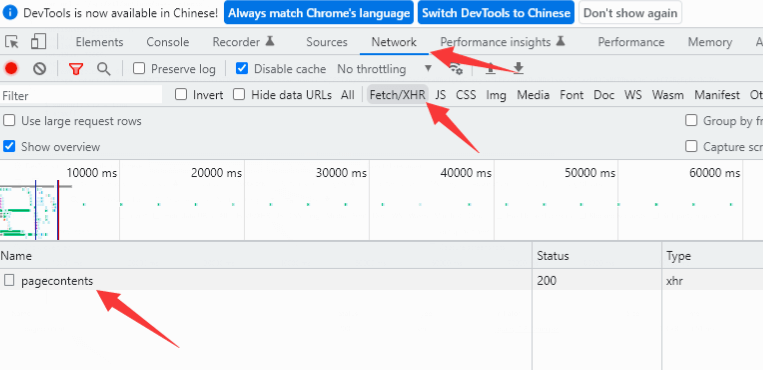
打開瀏覽器F12開發工具,預覽一下Ajax獲取的內容。
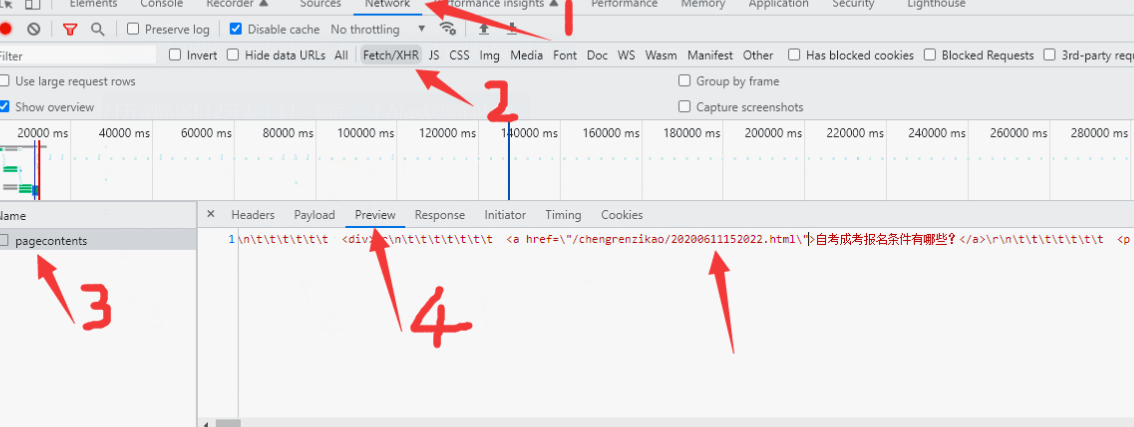
可以看到鏈接的形式是
<a href=\"/chengrenzikao/20200611152022.html\">自考成考報名條件有哪些?</a>
完整的鏈接地址是
https://域名/chengrenzikao/20200611152022.html
那我們就可以使用下面的規則提取地址。
我們測試一下網址采集。
測試網址采集
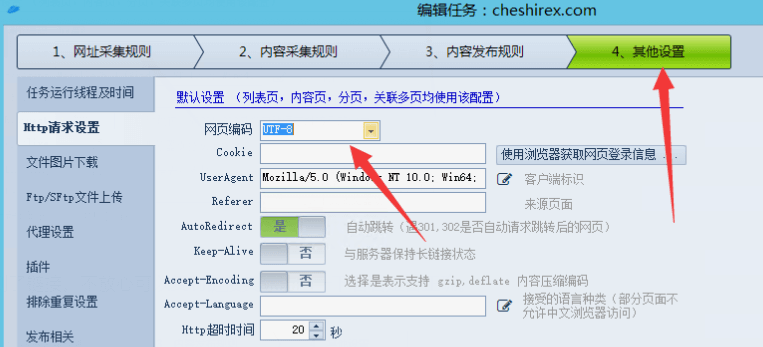
點擊測試可能提示“post請求必須選擇網頁編碼”我們在火車頭其他設置中將編碼選為“UTF8”即可。
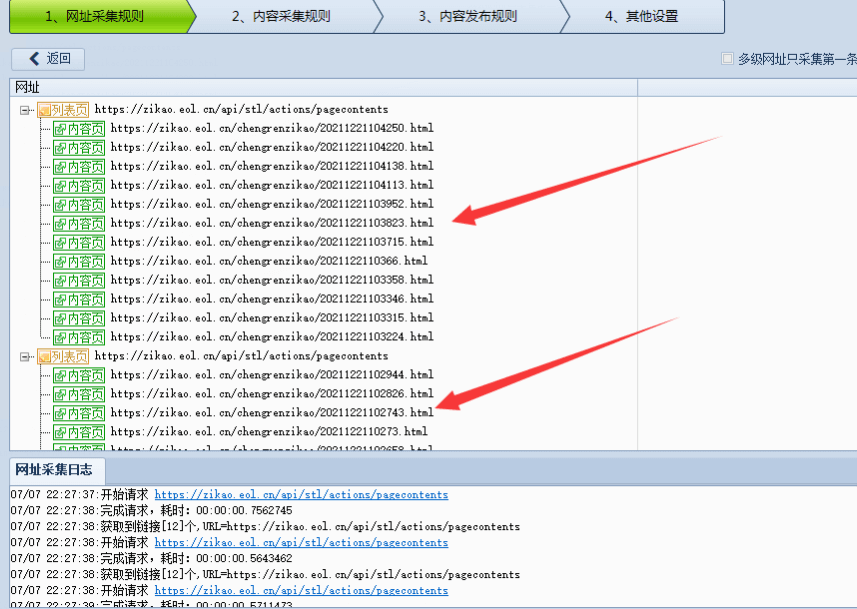
可以看到已經正確獲取到了鏈接。不放心可以復制鏈接實際訪問一下看看是否正確。
注意事項
采集過程注意運行線程和請求間隔時間。教程在測試時因為開的線程較多,頻率過高導致對方網站開啟了防CC設置。拉黑了我一個服務器IP,此教程寫完用了兩臺服務器。
我們實際采集可以只開1個線程,并設置合適的間隔時間,比如1000ms到1500ms左右。
本文由來自2號站長網,轉載請注明出處:https://www.zz2zz.com/331414.html



















