摘要
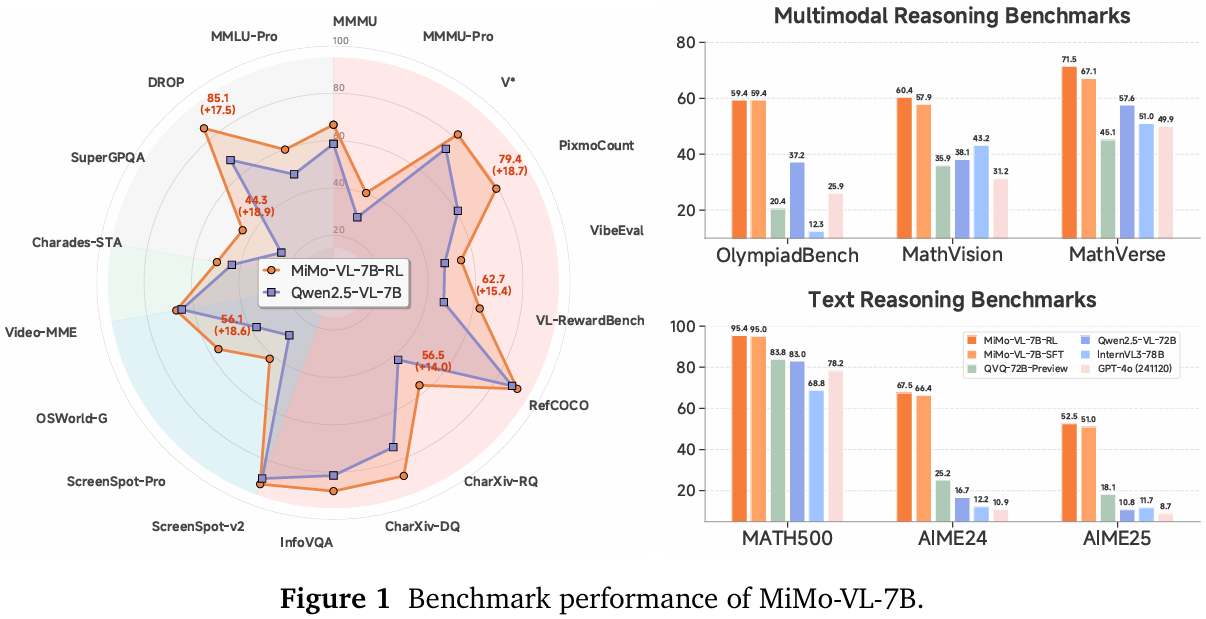
我們開源了 MiMo-VL-7B-SFT 和 MiMo-VL-7B-RL 兩個強大的視覺語言模型,它們在通用視覺理解和多模態推理方面均展現出最先進的性能。MiMo-VL-7B-RL 在 40 項評估任務中的 35 項上優于 Qwen2.5-VL-7B,并在 OlympiadBench 上獲得 59.4 分,超越了參數量高達 780 億的模型。對于 GUI 定位應用,它在 OSWorld-G 上達到了 56.1 分,樹立了新的標準,甚至超越了 Ui-TARS 等專業模型。我們的訓練方法結合了四階段預訓練(2.4 萬億個 token)與混合在線策略強化學習(MORL),后者整合了多種獎勵信號。我們發現,在預訓練階段融入高質量、長思維鏈(Chain-of-Thought)的推理數據至關重要,同時混合強化學習雖能帶來性能提升,但在多領域同步優化方面仍面臨挑戰。我們還貢獻了一個涵蓋 50 多項任務的綜合評估套件,以促進可重復性和推動領域發展。模型檢查點和完整評估套件可在 https://github.com/XiaomiMiMo/MiMo-VL 獲取。
1 引言
視覺語言模型(VLMs)已成為多模態 AI 系統的基礎骨干,使自主智能體能夠感知視覺世界、對多模態內容進行推理(Yue 等,2024b),并與數字(Xie 等,2024;OpenAI,2025)和物理環境(Zitkovich 等,2023;Black 等,2024)進行交互。這些能力的重要性促使研究者在多個維度上進行了廣泛探索,包括新穎的架構設計(Alayrac 等,2022;Team,2024;Ye 等,2025)以及采用優化數據配方的創新訓練方法(Karamcheti 等,2024;Dai 等,2024),從而推動了該領域的快速發展(Liu 等,2023;Tong 等,2024;Bai 等,2025a)。
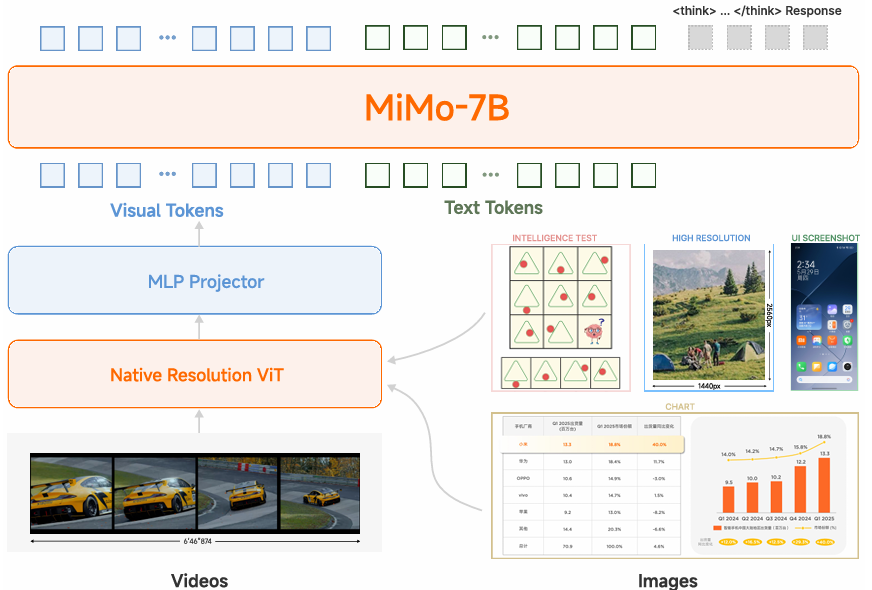
在本報告中,我們分享了構建緊湊而強大的 VLM 模型 MiMo-VL-7B 的經驗。MiMo-VL-7B 包含三個組件:(1) 一個保留精細視覺細節的原生分辨率視覺 Transformer(ViT)編碼器;(2) 一個用于高效跨模態對齊的多層感知機(MLP)投影器;(3) 專為復雜推理任務優化的 MiMo-7B(Xiaomi,2025)語言模型。
MiMo-VL-7B 的開發涉及兩個連續的訓練過程:(1) 四階段預訓練階段,包括投影器預熱、視覺-語言對齊、通用多模態預訓練以及長上下文監督微調(SFT)。在這些階段中,我們通過戰略性地組合開源數據集和合成數據生成技術來策劃高質量數據集,消耗了 2.4 萬億個 token,并在不同階段調整數據分布以促進訓練。該階段生成 MiMo-VL-7B-SFT 模型。(2) 后續的后訓練階段,我們引入了混合在線策略強化學習(MORL),這是一種新型框架,能夠無縫整合涵蓋感知準確性、視覺定位精度、邏輯推理能力和人類偏好的多樣化獎勵信號。我們采用了 GRPO(Shao 等,2024)的理念,并通過在此階段僅執行在線策略梯度更新來增強訓練穩定性。該階段生成 MiMo-VL-7B-RL 模型。
在此過程中,我們發現:
-
(1) 從預訓練階段開始融入高質量、覆蓋廣泛的推理數據對提升模型性能至關重要。在當前"思考型"模型的時代,大量的多模態預訓練數據正經歷顯著的重新評估。傳統的問答(QA)數據因其直接、簡短的答案,往往限制模型僅進行表面的模式匹配,導致過擬合。相比之下,帶有長思維鏈(CoT)的合成推理數據使模型能夠學習復雜的邏輯關系和可泛化的推理模式,提供更豐富的監督信號,顯著提升性能和訓練效率。為了利用這一優勢,我們通過識別多樣化問題、使用大型推理模型重新生成帶有長思維鏈的響應,并應用拒絕采樣來確保質量,從而策劃高質量推理數據。此外,我們不是將其視為補充性的微調數據,而是將大量此類合成推理數據直接融入后期預訓練階段,通過擴展訓練持續提升性能而不出現飽和。
-
(2) 混合在線策略強化學習進一步提升了模型性能,但實現穩定的同步改進仍具挑戰性。我們在包括推理、感知、定位和人類偏好對齊在內的多樣化能力上應用強化學習,涵蓋文本、圖像和視頻等多種模態。雖然這種混合訓練方法進一步釋放了模型潛力,但不同數據域之間的干擾仍然是一個挑戰。響應長度和任務難度水平的增長趨勢差異阻礙了所有能力的穩定同步提升。
MiMo-VL-7B-RL 在全方位多模態能力上表現出色。
- (1) 在基礎視覺感知任務中,它在同等規模的開源 VLM 中實現了最先進的性能,在 MMMU(Yue 等,2024b)上獲得 66.7 分,并在 40 項評估任務中的 35 項上優于 Qwen2.5-VL-7B(Bai 等,2025a)。
- (2) 對于復雜的多模態推理,MiMo-VL-7B-RL 表現出色,在 OlympiadBench(He 等,2024)上獲得 59.4 分,超越了高達 720 億參數的模型。
- (3) 在面向智能體應用的 GUI 定位方面,我們的模型通過在 OSWorld-G(Xie 等,2025)上達到 54.7 分樹立了新標準,甚至超過了 Ui-TARS(Qin 等,2025b)等專業模型。
- (4) 在用戶體驗和偏好方面,MiMo-VL-7B-RL 在我們的內部用戶偏好評估中獲得了所有開源 VLM 中最高的 Elo 評分,與 Claude 3.7 Sonnet 等專有模型相比也具有競爭力。
這些結果驗證了我們的方法:通過我們的 MORL 框架結合強大的感知能力、復雜的推理能力和精確的定位能力,MiMo-VL-7B-SFT 和 MiMo-VL-7B-RL 為開源視覺語言模型樹立了新標準。為了促進透明度和可重復性,我們還貢獻了一個涵蓋 50 多項任務的綜合評估套件,包含完整的提示詞和協議,使社區能夠在此基礎上繼續發展。
2 預訓練
本節將介紹 MiMo-VL-7B 的架構設計,隨后闡述預訓練階段的數據構建流程與訓練策略。
2.1 架構設計
MiMo-VL-7B 由三部分組成:(1) 用于編碼圖像和視頻等視覺輸入的視覺 Transformer(ViT);(2) 將視覺編碼映射至與大語言模型(LLM)對齊的潛在空間的投影器;(3) 執行文本理解與推理的 LLM 本體。為支持原生分辨率輸入,我們采用 Qwen2.5-ViT(Bai 等,2025a)作為視覺編碼器。LLM 骨干網絡以 MiMo-7B-Base(Xiaomi,2025)初始化以繼承其強大推理能力,投影器則使用隨機初始化的多層感知機(MLP)。整體架構如圖 2 所示,模型配置詳見附錄 B。
2.2 預訓練數據
MiMo-VL-7B 預訓練數據集包含 2.4 萬億 token 的高質量、多樣化多模態數據,涵蓋圖像、視頻及文本。該綜合數據集包括通用圖像描述、交錯數據、光學字符識別(OCR)數據、定位數據、視頻內容、GUI 交互、推理示例及純文本序列。
為確保各模態數據質量,我們針對不同數據類型特性設計了專用數據構建流程。訓練過程中,我們系統性地調整各階段不同模態數據的比例,以優化訓練效率與模型穩定性。此外,采用基于感知哈希(phash)的圖像去重技術,消除訓練數據與評估基準間的潛在重疊,最大限度避免數據污染。
以下詳述各類型數據的具體處理流程:
2.2.1 圖像描述數據
圖像描述數據集構建采用多階段流程以確保高質量與分布均衡:
- 數據聚合:從網絡來源收集大量公開描述數據
- 嚴格去重:結合圖像感知哈希(phash)與文本過濾,生成精簡版原始描述集
- 重描述生成:以圖像及原始文本為先驗,調用專用描述模型對原始數據集重新生成描述
- 質量過濾:基于語言一致性與重復模式對生成描述進行過濾
- 分布優化:采用 MetaCLIP(Xu 等,2023)方法構建中英雙語元數據,修正描述分布,緩解高頻條目過表達問題并降低數據噪聲
此流程最終生成均衡、高質量且多樣化的描述數據集。實證表明,此類豐富數據顯著提升模型泛化能力與定性表現,其價值在現有專項基準測試中未必完全體現。
2.2.2 交錯數據
我們從網頁、書籍及學術論文等多源渠道構建大規模圖像-文本交錯數據集:
- 內容提取:對書籍/論文內容采用高級 PDF 解析工具進行提取與清洗
- 數據篩選:優先保留蘊含世界知識的數據類型(教材、百科、手冊、指南、專利、傳記)
- 文本評估:基于知識密度與可讀性指標篩選文本片段
- 圖像過濾:剔除尺寸過小、比例異常、含不安全內容或視覺信息稀疏的圖像(如裝飾性章節標題)
- 配對評分:從相關性、互補性及信息密度平衡性三維度對圖文對評分,確保保留高質量數據
此數據集顯著擴充模型知識庫,為后續推理能力奠定堅實基礎。
2.2.3 OCR 與定位數據
為提升模型在 OCR 與對象定位方面的能力,我們整合開源數據集構建大規模預訓練語料:
- OCR 數據:
- 圖像來源:文檔、表格、通用場景、產品包裝及數學公式
- 增強難度:除標準印刷文本外,特別納入手寫體、變形字體及模糊/遮擋文本圖像
- 定位標注:部分數據標注文本區域邊界框,使模型能同步預測位置
- 定位數據:
- 場景覆蓋:包含單/多對象場景
- 復雜表達:在定位提示中使用復雜對象表述,提升模型理解復雜指代表達的能力
- 坐標表示:所有定位場景均采用絕對坐標表示
2.2.4 視頻數據
視頻數據集主要源自公開網絡視頻,覆蓋廣泛領域、類型及時長:
- 細粒度重描述:設計視頻重描述流程,生成帶精確起止時間戳的事件級描述,培養模型時序感知能力
- 時序定位:從描述數據集中篩選事件時長分布均衡的子集用于時序定位預訓練
- 深度分析:構建視頻分析數據,提煉全局語義(敘事結構、風格要素、隱含意圖),提升模型深度理解能力
- 對話增強:收集多樣化視頻挑戰性問題并合成響應,結合開源視頻描述與對話數據集,強化模型對話連貫性
2.2.5 圖形用戶界面數據
為增強模型在圖形用戶界面(GUI)導航能力:
- 數據來源:整合開源移動端/網頁端/桌面端跨平臺數據,輔以合成數據引擎彌補開源數據局限
- 中文優化:構建海量中文 GUI 數據以提升中文場景處理能力
- 定位訓練:
- 元素定位:基于文本描述精確定位界面元素,強化靜態界面感知
- 指令定位:根據用戶指令識別截圖中的目標對象,提升 GUI 交互邏輯理解
- 動作預測:新增基于前后截圖預測中間動作的預訓練任務,顯著增強動態界面感知能力
- 動作標準化:將跨平臺操作統一至標準化動作空間(詳見附錄 D),既避免動作沖突又保留平臺特性
2.2.6 合成推理數據
合成推理數據生成流程:
- 問題收集:整合開源問題庫,覆蓋感知問答、文檔問答、視頻問答及視覺推理任務,補充網絡與文學作品中的問答對
- 初篩過濾:對原始問題進行基礎質量篩選
- 推理生成:調用大型推理模型生成含顯式推理鏈的答案
- 多級質控:
- 驗證答案事實正確性
- 嚴格評估推理過程(邏輯清晰度、冗余消除、格式一致性)
此高保真數據集使模型有效繼承 MiMo-7B-Base(Xiaomi,2025)的強推理能力,并無縫遷移適配多模態場景,最終在廣泛領域展現強大且通用的多模態推理能力。
2.3 預訓練階段
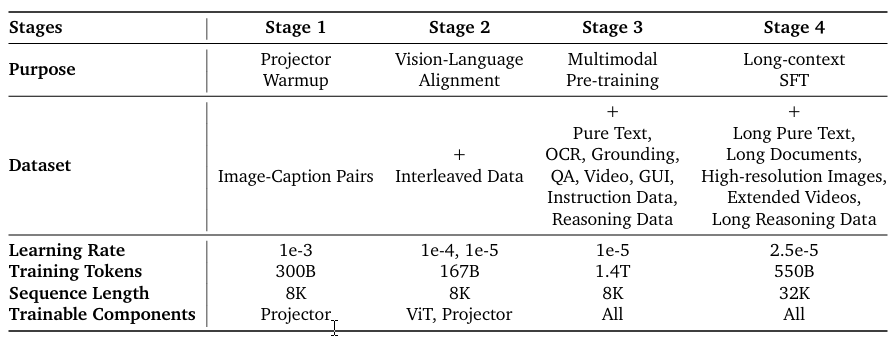
如表 1 所示,模型經歷四階段預訓練:
第一階段:投影器預熱
凍結 ViT 與 LLM 組件,僅用圖像-描述對預熱隨機初始化的投影器。確保投影器有效學習視覺概念到語言模型表征空間的映射,為后續階段提供有效梯度信號而非不良投影器導致的噪聲更新。
第二階段:視覺-語言對齊
解凍 ViT 并引入交錯數據,強化視覺-語言對齊。交錯數據中復雜多樣的圖像提升 ViT 性能與魯棒性。
第三階段:多模態預訓練
開放全部參數訓練,引入 OCR、定位、視頻、GUI 等 1.4 萬億 token 多樣化數據,增強模型通用多模態能力。為確保中期評估穩定性,少量納入 QA、指令遵循及推理數據;同時保留少量純文本數據以維持 MiMo-7B-Base 文本能力。
第四階段:長上下文 SFT
- 將訓練序列長度從 8K 擴展至 32K token
- 引入長純文本、高分辨率圖像、長文檔、擴展視頻及長推理數據
- 因長上下文打包顯著增加有效批量,學習率從 1e-5 調整至 2.5e-5
- 相比第三階段大幅提高推理數據比例,并引入長形式推理模式
通過四階段訓練,最終生成強大模型 MiMo-VL-7B-SFT。尤其在第四階段,模型推理能力得到充分釋放,可解決高度復雜的 STEM 問題,且該能力有效泛化至通用感知任務,使模型在各類下游基準測試中均表現卓越。
3 后訓練
在預訓練建立的視覺感知能力和多模態推理基礎上,我們進行后訓練以進一步提升 MiMo-VL-7B。我們的方法采用了一種新型混合在線策略強化學習(MORL)框架,無縫整合了基于可驗證獎勵的強化學習(RLVR)(邵等人,2024;Lambert 等人,2025)與基于人類反饋的強化學習(RLHF)(歐陽等人,2022),以提升 MiMo-VL-7B 在挑戰性推理任務上的表現并使其與人類偏好保持一致。
3.1 基于可驗證獎勵的強化學習
RLVR 完全依賴于基于規則的獎勵函數,使模型能夠持續自我改進。在 MiMo-VL-7B 的后訓練中,我們設計了多種可驗證的推理和感知任務,其中最終解決方案可以使用預定義規則進行精確驗證。
視覺推理 視覺推理能力對于多模態模型理解并解決需要視覺感知和邏輯思維的復雜問題至關重要。為促進這一能力,我們從開源社區和專有 K-12 題庫中收集多樣化的可驗證 STEM 問題。通過提示大型語言模型篩選基于證明的問題,并將選擇題重寫為自由回答格式(包含數值或符號答案),從而緩解潛在的獎勵作弊問題。我們進一步通過全面的基于模型的難度評估來優化問題質量,排除那些高級 VLM 無法解決或過于簡單的問題(MiMo-VL-7B rollout 通過率超過 90%)。此外,我們還移除了即使沒有圖像輸入也能解決的問題。經過數據清洗和類別平衡后,我們整理出包含 8 萬個問題的視覺推理數據集。在評估時,我們使用基于規則的 Math-Verify 庫來確定響應的正確性。
文本推理 由于大多數視覺推理數據僅限于 K-12 級別問題,經 RL 訓練的模型在推理性能上可能受到限制。相比之下,純文本推理數據集包含更多需要大學或競賽級別智力的挑戰性問題。為充分釋放模型的推理潛力,我們整合了來自小米(2025)的數學推理數據。獎勵使用相同的基于規則的 Math-Verify 庫計算,確保視覺和文本推理任務評估的一致性。
圖像定位 精確的空間定位對于模型理解圖像中對象關系和空間推理至關重要。我們在 RLVR 框架中包含一般和 GUI 定位任務,以增強 MiMo-VL-7B 的定位能力。對于邊界框預測,獎勵通過預測框與真實框之間的廣義交并比(GIoU)(Rezatofighi 等人,2019)計算。對于點式輸出,獎勵取決于預測點是否落在真實邊界框內。
視覺計數 精確的計數能力對于視覺環境中的定量視覺理解和數學推理至關重要(Chen 等人,2025a)。我們通過 RL 訓練增強視覺計數能力,其中獎勵定義為模型計數預測與真實計數的準確性。
時序視頻定位 除了靜態圖像理解和推理外,我們將 RLVR 框架擴展到動態視頻內容,以捕捉時間依賴性。我們整合了時序視頻定位任務,要求模型定位與自然語言查詢相對應的視頻片段(Wang 等人,2025)。模型以 [mm:ss, mm:ss] 格式輸出時間戳,指示目標視頻片段的開始和結束時間。獎勵通過預測和真實時間片段之間的交并比(IoU)計算。
3.2 基于人類反饋的強化學習
為使模型輸出與人類偏好保持一致并減少不良行為,我們將基于人類反饋的強化學習(RLHF)作為可驗證獎勵框架的補充方法。
查詢收集 查詢多樣性對 RLHF 的成功至關重要。我們的方法首先從開源指令微調數據集和內部人工編寫來源收集多模態和純文本查詢。所有收集到的查詢(包括文本和多模態)隨后經過專門的篩選過程。為進一步增強多樣性,我們采用基于嵌入的查詢聚類技術并分析結果模式。關鍵的是,我們在策劃最終查詢集之前平衡了中文和英文查詢的比例,以及針對有用性和無害性的查詢比例。對于每個選定的查詢,MiMo-VL-7B 和多個其他頂級 VLM 生成響應。這些響應隨后由高級 VLM 進行成對排序,以構建獎勵模型訓練的最終數據集。值得注意的是,為減輕潛在的獎勵作弊問題,同一查詢集同時用于獎勵模型訓練和 RLHF 過程。
獎勵模型 我們開發了兩個專門針對不同輸入模態的獎勵模型,使用 Bradley-Terry 獎勵建模目標(歐陽等人,2022)進行訓練。純文本獎勵模型從 MiMo-7B(小米,2025)初始化,以利用其強大的語言理解能力,而多模態獎勵模型則基于 MiMo-VL-7B 構建,以有效處理包含視覺輸入的查詢。這種雙模型方法確保在文本和多模態評估場景中均能實現最佳性能。
3.3 混合在線策略強化學習
在 MiMo-VL-7B 的后訓練階段,我們實施混合在線策略強化學習(MORL),以同時優化 RLVR 和 RLHF 目標。如圖 3 所示,我們在 verl 框架(Sheng 等人,2024)中將基于規則和基于模型的獎勵集成到統一服務中,并通過無縫 Rollout 引擎(小米,2025)進行增強。
在線策略 RL 方案 我們采用 GRPO(邵等人,2024)的完全在線策略變體作為 RL 算法,該算法展現出穩健的訓練穩定性和有效的探索能力(Chen 等人,2025b)。對于每個問題 q,該算法從策略 πθ\pi_{\theta}π

)









)





)
之進銷存庫存管理—仙盟創夢IDE)
