概述
????????縮略詞指的是一個詞或者短語的縮略形式,其通常由原詞中的一些組成部分構成,同時保持原詞的含義。縮略詞的檢測與抽取在方法上與同義詞的檢測與抽取類似,但是相比同義詞,縮略詞在文本中出現的規則往往更簡單。
? ? ? ? 不同語言縮略詞的形式不同。以表音文字(如拉丁語系)和表意文字(如中文)為例。拉丁語系的縮略詞形式包括contractions(簡稱)、crasis(元音融合)、acronyms(首字母縮寫)和initialisms(首字母縮寫)。而表意文字的縮略形式相對復雜,并且在自然語言處理中依賴分詞算法來對其詞邊界進行劃分,其縮略形式往往是從每個詞中選取一個或者多個字組成,剩下的那些字則直接省略。
例:
Doctor,I am --> Dr,I'm(英語)
De le,de les --> Du,des(法語)
中國中央電視臺-->央視
縮略詞的檢測與抽取
????????縮略詞的檢測及抽取方法以模式匹配為主,但是自動抽取出的結果常常包含大量噪聲,為此需要利用統計信息結合各類機器學習方法來對抽取結果進行清洗。
基于文本模式的抽取
????????最常用的方法,以同義詞抽取中的規則很相似。X表示原詞,Y表示縮略詞,例:
X(Y)? ? ? ? Support vector machine(SVM)
X.*(Y)? ? ? ? Support vector machine for gression(SVM)
Y is the abbreviation of X? ? ? ? SVM is the abbreviation of Support vector machine
? ? ? ? 通過編制復雜且精細的模式能保證基于模式匹配的縮略詞抽取方法的準確率,但是召回率往往較低,并且枚舉長尾模式也十分困難。此外,抽取仍然可能錯誤,需要對抽取結果進行清洗和篩選。
抽取結果的清洗和篩選
????????主要分兩種:利用數據集有關縮寫的統計指標進行識別;使用機器學習模型構建二元分類模型來判斷。前者使用的統計指標一般包含頻率、卡方檢驗、互信息以及最大熵等,后者需要依賴認為設計的特征,特征除了包含前面的統計指標外,也包括文本特征。縮略詞判定的文本特征主要包括字符匹配程度(縮略詞中是否包含全稱以外的詞,縮略詞與全稱的編輯距離,縮略詞與全稱的長度差異,縮略詞中的字在全稱中的位置等)、詞性特征兩類。
枚舉并剪枝
? ? ? ? 針對中文縮略詞提出的一種有效辦法。首先窮舉目標實體名稱所有的子序列,即所有可能的縮略形式,進一步排除沒有在文本中出現過的或者出現次數太少的候選縮略詞。書上的一個例子:
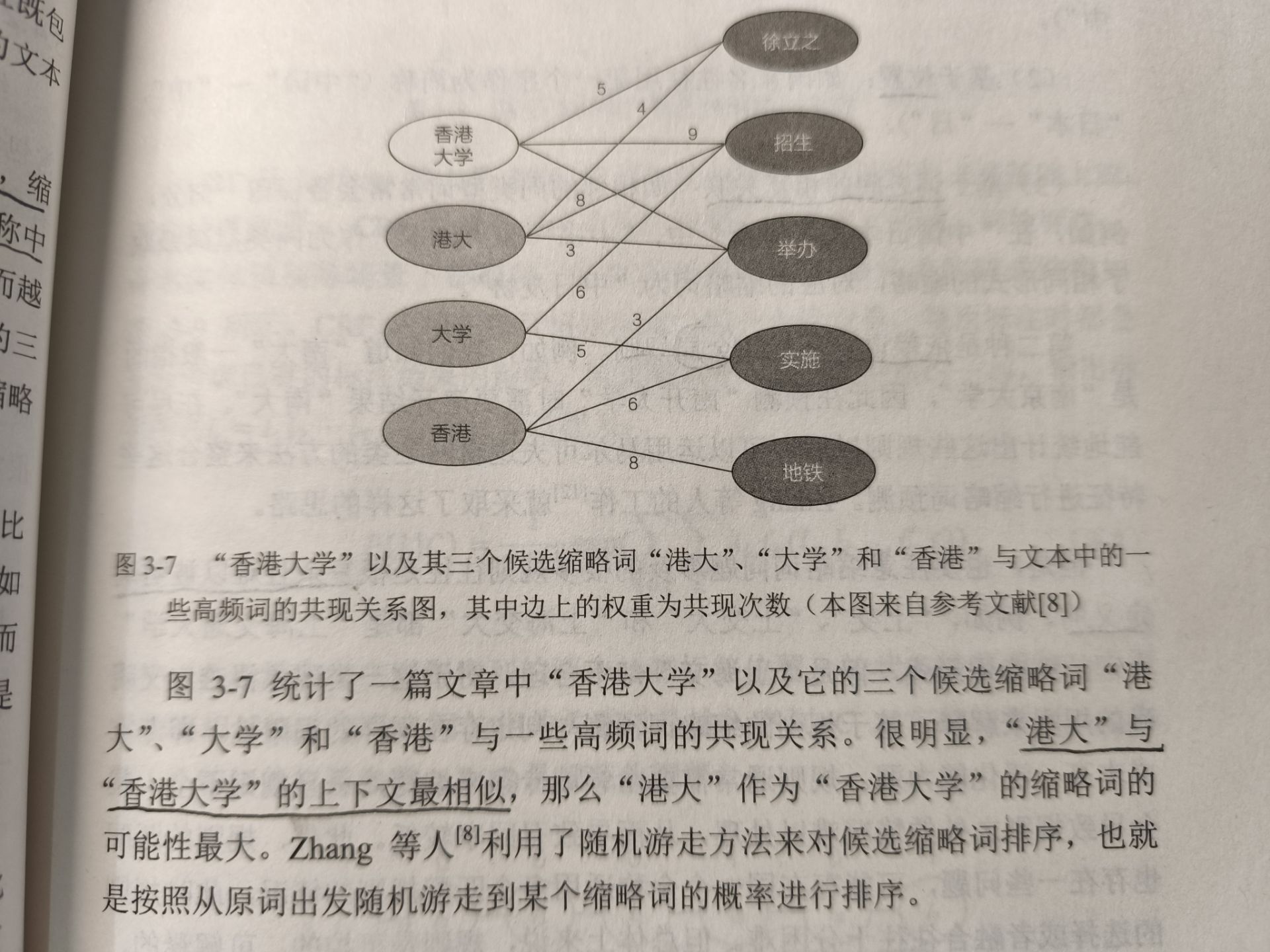
縮略詞的預測
????????受限于語料大小,縮略詞抽取的方法能獲得大量縮略詞對,但是對于新登錄詞往往效果較差。目前的一些相關研究著眼于分析縮略詞的規則,自動習得縮略詞形式并進行預測。
基于規則的方法
????????大致分為兩種:針對特性字符和詞語形式的局部規則(基于詞性、位置、詞之間的相互關聯);依賴語言環境的全局規則。
? ? ? ? 縮略詞問題涉及的很多規則往往是很復雜且難以被明確定義的,并且相關規則需要領域專家進行編寫,成本高且泛化性差,一旦遇到規則之外的情況就難以處理,導致召回率很低。此外,可能出現在同一個全稱適用多個匹配規則的情況,此時規則的選擇或者融合往往十分困難。但總體上說,規則是可控、可解釋的。
條件隨機場
????????絕大部分縮略詞都由全稱中包含的字符組成,并且字符間的順序往往會保留。借助這一特性,可以將其轉化為序列標注問題。條件隨機場(CRF)是較早運用于進行縮略詞生成的序列標注模型。
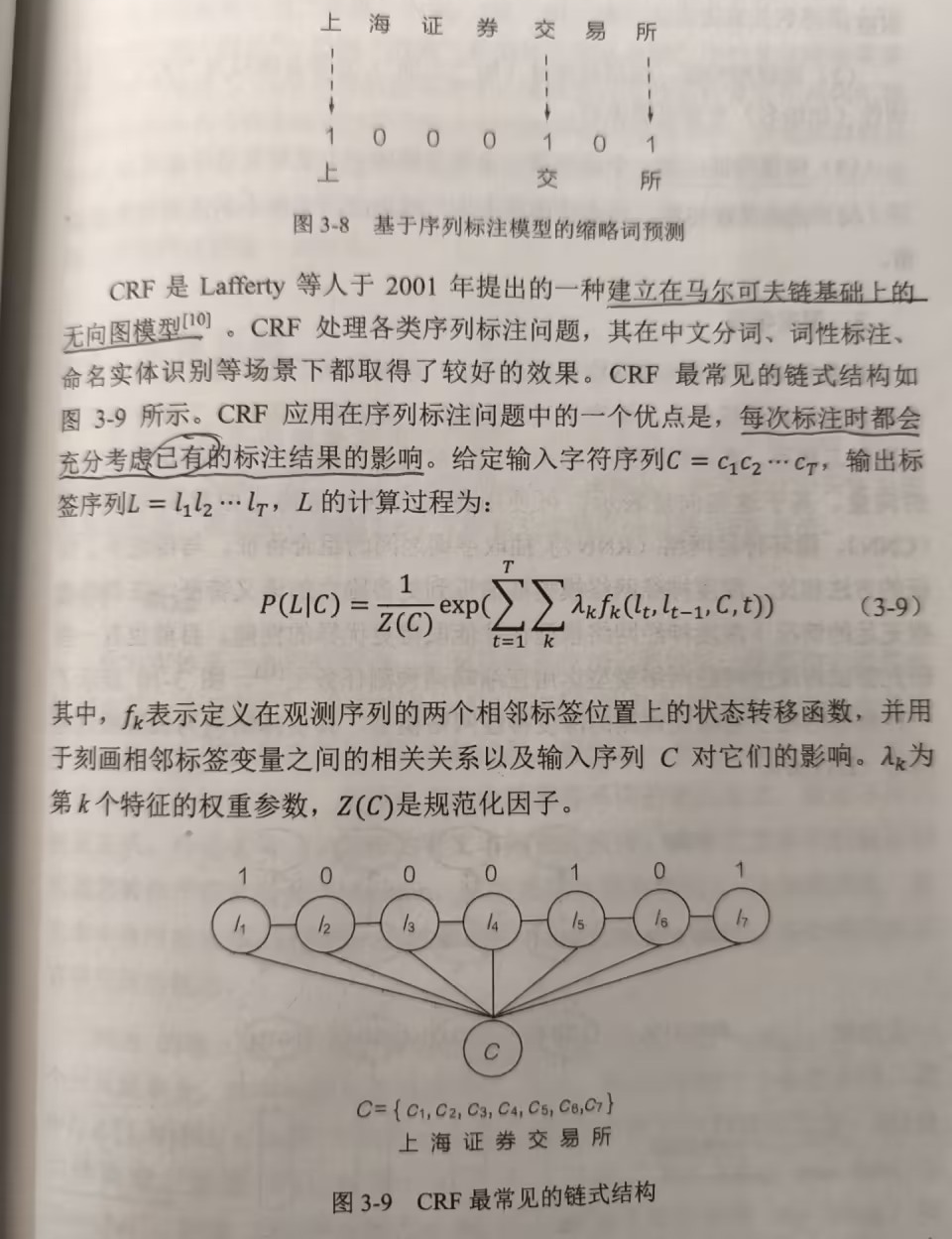
CRF極簡引用
深度學習
????????在神經網絡方法中,詞或字符被表示為一個低維稠密空間中的向量,借助于典型網絡結構(CNN、RNN等)抽取字詞之間的組合特征。深度神經網絡往往能夠取得更優異的性能,但是與神經網絡的通病一樣,可解釋性差。



















