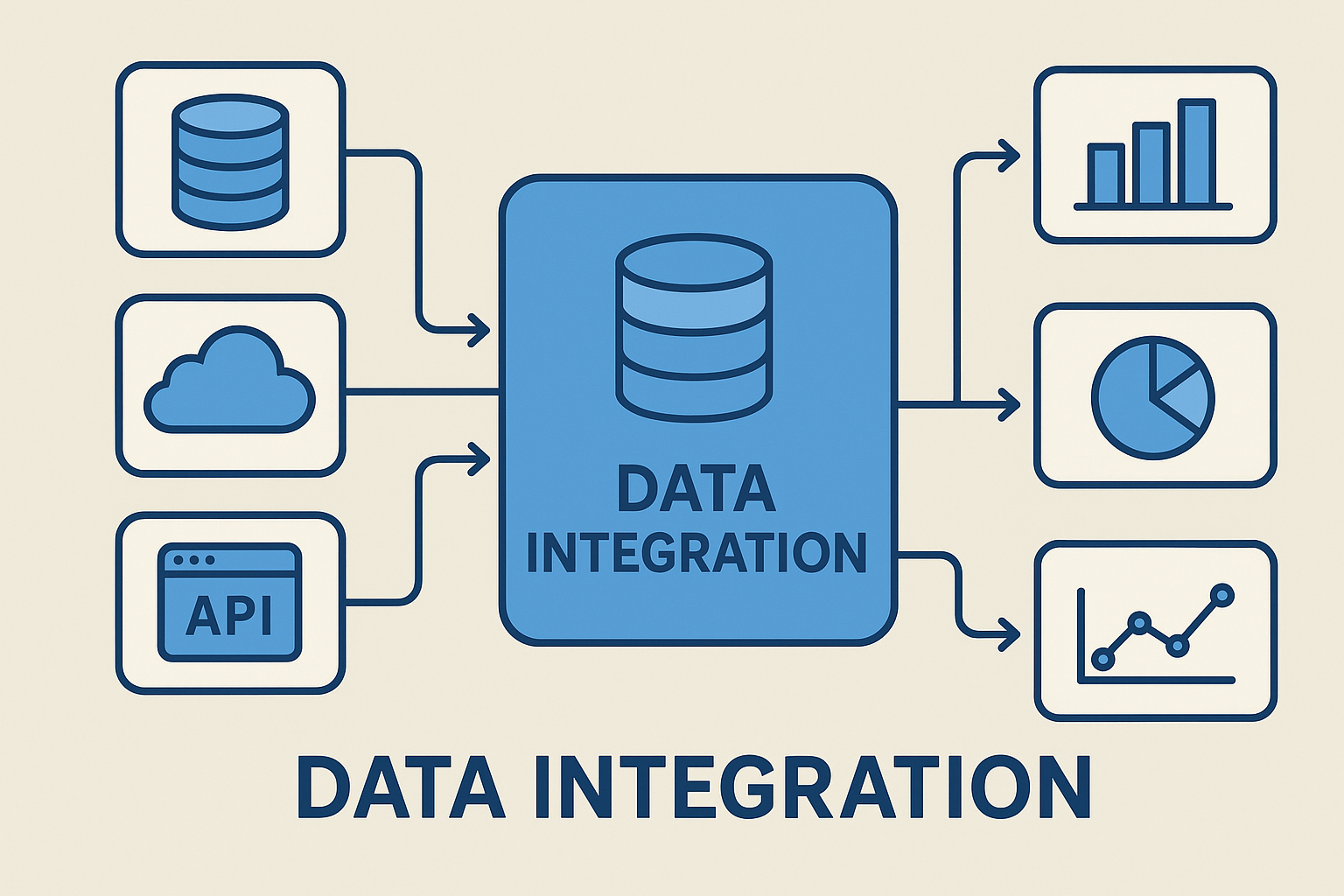
一、什么是數據集成?
數據集成的定義:
數據集成(Data Integration)是指將分布在不同來源、不同格式、不同結構的數據進行清洗、轉換、統一和匯聚的過程。數據集成的目的是提供一個一致性高、可訪問性強、質量可靠的數據視圖,供企業進行決策分析和業務創新。
數據集成關鍵特征:
多源性:來自數據庫、API、日志文件、IoT設備等多種渠道。
實時性:支持批處理(Batch)與流處理(Streaming)兩類型數據傳輸的整合。
一致性:確保不同來源數據在口徑與標準上保持統一。
可擴展性:能適應企業數據規模快速增長需求。
常見的數據集成方式:
ETL(抽取-轉換-加載):傳統的數據倉庫方法, 相對要求有強大的數據轉換能力。
ELT(抽取-加載-轉換):通常見于云計算與大數據環境, 對于數據轉換有高性能要求。
實時數據流集成:Kafka、Flink 等技術應用, 有流式數據分析需求,需要抽取流式數據。
簡而言之,數據集成就是打通數據通道,讓數據產出使用同一種語言。
二、數據集成對數據治理的影響?
數據治理強調對數據的標準化、合規性和價值實現,而數據集成正是其基礎設施。
保障數據質量:數據集成在采集與處理過程中,會進行去重、清洗與標準化,從源頭提升數據質量。
提升數據可用性:通過集成,不同系統的數據會集中到統一平臺中,消除數據孤島,讓治理工作更順暢。
增強數據合規與安全:數據治理需符合GDPR、數據安全法等規范。集成過程中內置審計與權限管理,確保數據流動合法合規。
支撐智能化決策:集成后的數據會提高質量,才能進一步用于BI分析、機器學習和AI預測,從而增強治理成效。
簡言之,沒有數據集成,就沒有真正意義上的數據治理。
三、數據集成要做哪些事幫助數據治理?
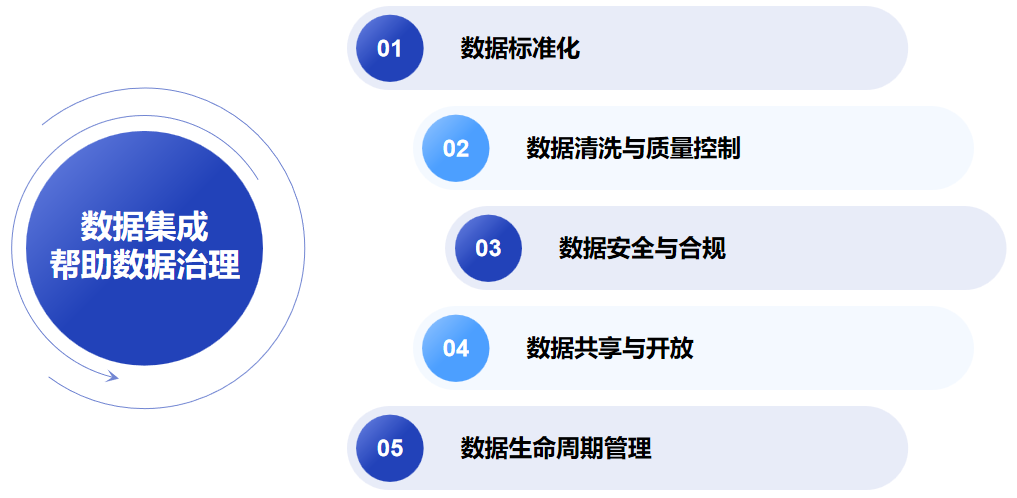
統一數據命名規范, 如產品料號名稱要叫 Item?還是 Part?
建立主數據管理, Master Data Management(MDM)
制定元數據 (Meta Data) 管理規則
數據清洗與質量控制:
去重、糾錯、補全缺失值
數據一致性校驗
自動化質量監控
數據安全與合規:
權限分級管理
數據加密與脫敏
數據使用日志審計
數據共享與開放:
建立統一的數據交換平臺
提供API接口實現跨系統調用
構建數據服務化 DaaS(Data as a Service)模式
數據生命周期管理:
從采集、存儲到銷毀全流程可控
支持版本管理與歷史追溯
數據集成不僅僅是“匯總數據”,更是“賦能數據治理”的重要引擎。
四、數據集成在數據治理會有哪些挑戰?
數據來源復雜性:不同系統間存在格式差異、語義沖突,導致集成難度大。
數據質量難以保證:即使有自動清洗,仍可能出現臟數據、重復數據、缺失值。
實時與批處理的性能與需求平衡:企業需要既支持實時監控,又支持歷史數據分析,這對架構設計提出挑戰。
安全與隱私保護:跨系統數據共享增加了泄露風險,需要更嚴格的安全機制。
成本與技術門檻:高質量的數據集成平臺需要投入大量人力、技術與資金。
因此,數據集成在支持推動治理同時,也需要企業不斷迭代優化策略。
五、數據集成歸納總結
數據集成不僅是技術問題,更是企業戰略的一部分。
數據治理的基石:沒有集成,治理無法落地。
數據價值的放大器:讓數據真正產生業務洞察與創新。
如何面臨挑戰:通過合適的工具與策略,可以有效解決。
未來,隨著AI、云計算和大數據平臺的不斷發展,數據集成將更智能化、自動化,進一步助推數據治理的深化與升級。
六、常見問題解答(FAQs)
Q1: 數據集成與數據治理的關系是什么?
A1: 數據集成是數據治理的前提,治理依賴于完整、一致和可信的數據,這些都必須通過集成實現。
Q2: 企業為什么必須重視數據集成?
A2: 因為只有打通數據孤島,企業才能實現跨部門協作、合規監管和智能決策。
Q3: 數據集成和ETL有什么區別?
A3: ETL是一種實現集成的方法,而數據集成是更大的概念,包含ETL、ELT、虛擬化和實時流處理等多種方法。
Q4: 數據集成如何保證數據安全?
A4: 通過加密、脫敏、權限管理與審計機制,確保數據在傳輸和存儲過程中的安全合規。
Q5: 數據集成最大的挑戰是什么?
A5: 數據源復雜性和數據質量問題最為突出,同時還需要平衡實時性與成本。
Q6: 未來數據集成的發展趨勢是什么?
A6: 向智能化、自動化和云原生方向發展,更多依賴AI算法和大數據平臺。



















