作者前言
🎂 ??????🍧🍧🍧🍧🍧🍧🍧🎂
?🎂 作者介紹: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你會, 🎂
簡單介紹:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜歡學習C語言、C++和python等編程語言,是一位愛分享的博主,有興趣的小可愛可以來互討 🎂🎂🎂🎂🎂🎂🎂🎂
🎂個人主頁::小小頁面🎂
🎂gitee頁面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一個愛分享的小博主 歡迎小可愛們前來借鑒🎂
C++11
- **作者前言**
- {}初始化
- auto
- decltype
- nullptr
- STL 的一些變換
- 右值引用和移動語義
- 左右值
- 左右值引用的比較
- 左右值引用解決的問題
- 完美轉發
- 新的類功能
- 可變參數模板
- lambda表達式
- 包裝器
- function包裝器
- bing包裝器
{}初始化
C++11擴大了用大括號括起的列表(初始化列表)的使用范圍,使其可用于所有的內置類型和用戶自定義的類型,使用初始化列表時,可添加等號(=),也可不添加。可以理解為一切可以使用{}初始化
#include<iostream>
struct MyStruct
{int _x;int _y;
};
class Date
{
public:Date(int year = 0, int mothon = 0, int day = 0):_year(year),_mothon(mothon),_day(day){}Date(const Date& date){_year = date._year;_mothon = date._mothon;_day = date._day;}
private:int _year;int _mothon;int _day;
};
int main()
{//內置類型初始化int a = 10;int b{ 10 };//數組初始化int arr[] = { 1,2,3,4,7,9 };int arr1[]{ 1,2,3,4,5,8 };//結構體初始化MyStruct pion = { 1,2 };MyStruct pionOne{ 1,2 };//new的初始化int* stataArr = new int[4]();//初始化為0;int* stataArr1 = new int[4]{ 1,2,3,4 };//自定義類型初始化Date date1(10,10,10);//c++98Date date2 = { 10,10,10 };//C++11Date date3{ 10,10,10 };//c++11Date* dates = new Date[3];Date* dates1 = new Date[3]{date1,date2,date3 };Date* dates2 = new Date[3]{{10,10,10},{10,10,10},{10,10,10}};return 0;
}
還有一些特殊情況,SLT容器使用的
std::vector<int> vet = { 1,2,3,4,5,6,8 };
//相當于vet(std::initializer_list<int>{1,2,3,4,5,6,8 })
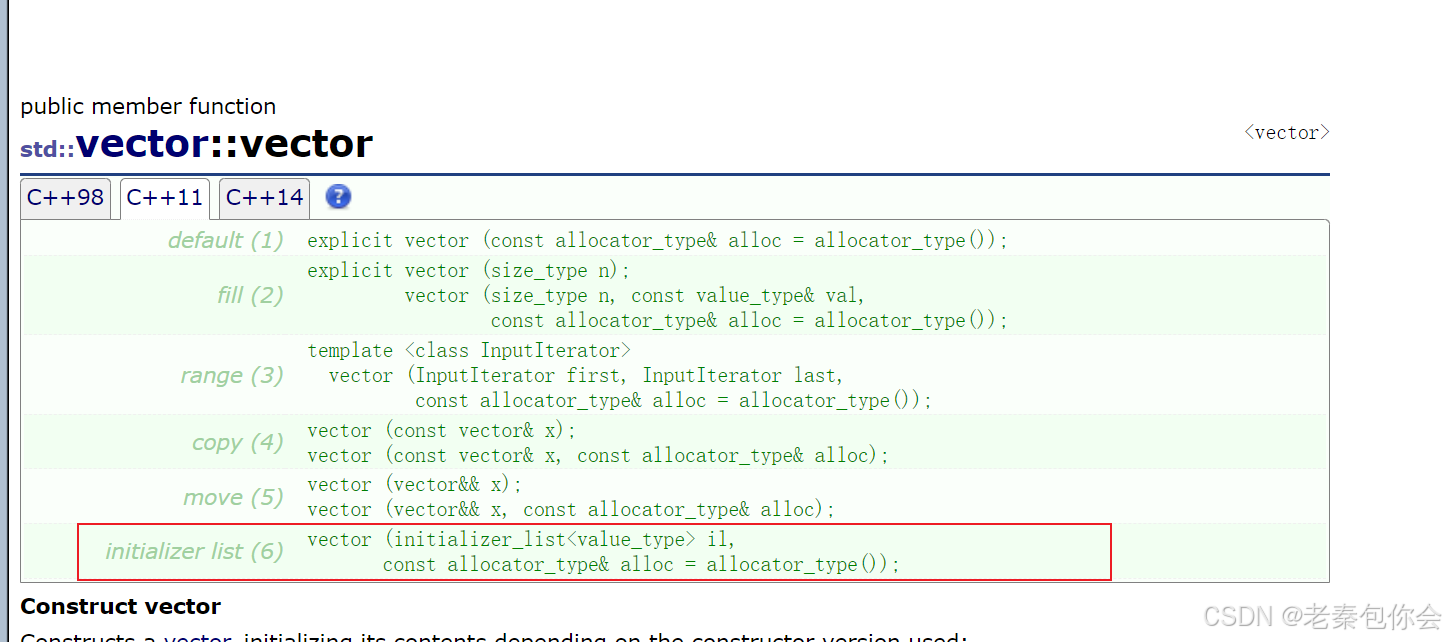
如圖,這是因為在vector的調用了std::initializer_list這個,std::initializer_list一般是作為構造函數的參數,C++11對STL中的不少容器就增加
std::initializer_list作為參數的構造函數,這樣初始化容器對象就更方便了。也可以作為operator=的參數,這樣就可以用大括號賦值。
auto
在C++98中auto是一個存儲類型的說明符,表明變量是局部自動存儲類型,但是局部域中定義局部的變量默認就是自動存儲類型,所以auto就沒什么價值了。C++11中廢棄auto原來的用法,將其用于實現自動類型腿斷。這樣要求必須進行顯示初始化,讓編譯器將定義對象的類型設置為初始化值的類型。
decltype
關鍵字decltype將變量的類型聲明為表達式指定的類型。這個一般用于推導出表達式的類型
int Funtion()
{return 1;
}
int main()
{int x = 0;int y = 10;decltype(x+y) z = 1;vector<decltype(Funtion())> vet;return 0;
}
一般的使用場景是不知道表達式的類型或變量的類型,可以使用這個進行推導出來
nullptr
由于C++中NULL被定義成字面量0,這樣就可能回帶來一些問題,因為0既能指針常量,又能表示整形常量。所以出于清晰和安全的角度考慮,C++11中新增了nullptr,用于表示空指針。
STL 的一些變換
- unordered_map和unordered_set以及array和forward_list的增加(新容器增加)
- 提供了cbegin和cend方法返回const迭代器等等,(增加新接口)
右值引用和移動語義
左右值
前面的學習中,會有一種認識誤區就是可以修改的就是左值, 不能修改的是右值,這個說法不完全正確。
左值和左值引用
左值是一個表示數據的表達式(如變量名或解引用的指針),我們可以獲取它的地址,一般情況下可以對它賦值,左值可以出現賦值符號的左邊,右值不能出現在賦值符號左邊。定義時const修飾符后的左值,不能給他賦值,但是可以取它的地址。
簡單理解左值的特性一般是, 可以被取地址
函數的左值引用返回時左值
左值引用就是給左值的引用,給左值取別名。
int& Funtion()//函數的左值引用返回時左值
{static int x = 0;return x;
}
int main()
{//左值int a = 10;int b = 10;const int c = 10;const int* p = nullptr;//左值引用int& ra = a;int& rb = b;const int& rc = c;const int*& rp = p;return 0;
}
代碼中的a、b、c就是左值,對應的引用就是左值引用 ,funtion()函數的返回值也是左值
?右值和右值引用
右值也是一個表示數據的表達式,如:字面常量、表達式返回值,函數返回值(這個不能是左值引用返回)等等,右值可以出現在賦值符號的右邊,但是不能出現出現在賦值符號的左邊,右值不能取地址。右值引用就是對右值的引用,給右值取別名。
在C++中對右值有進行更具體的區分
- 純右值: 如2
- 將亡值:如匿名對象、傳值返回函數
int main()
{int a = 10;int b = 10;//右值10,下面的也是a + b;Funtion(a , b);//右值引用,這里使用的&&int&& rr = 10;return 0;
}
如果查看反匯編就會知道
00BF18BD mov dword ptr [ebp-30h], 0Ah ; 將 10 (0xA) 存入棧地址 [ebp-30h]
00BF18C4 lea eax, [ebp-30h] ; 將 [ebp-30h] 的地址加載到 eax
00BF18C7 mov dword ptr [rr], eax ; 將 eax 的值(即地址)存入變量 rr
總結:
語法上, 引用就是別名,左值引用就是給左值取別名,右值引用就是給右值取別名,別名不開空間
底層上:引用就是指針的實現,左值引用就是存儲左值的地址,右值引用就是把右值拷貝到棧的空間上,存儲的是這個臨時變量的地址
左右值引用的比較
左值引用總結
- 左值引用只能引用左值,不能引用右值。
- 但是const左值引用既可引用左值,也可引用右值。
右值引入總結:
- 右值引用只能右值,不能引用左值。
- 但是右值引用可以move以后的左值。
總代碼如下:
int main()
{//左值為a ,右值為10int a = 10; //左值引用不能引用右值,但是const可以int& r = 10;//出錯const int& rr = 10;//右值引用不能引用左值, 但是move后的可以int&& ra = a;//報錯int&& rb = move(a);return 0;
}
左右值引用解決的問題
左值引用:
- 解決了傳參拷貝等問題,(傳參為引用)
- 解決部分傳返回值,(靜態變量返回值)
無法解決的問題:
當函數返回對象是一個局部變量,出了函數作用域就不存在了,就不能使用左值引用返回,只能傳值返回。
代碼如下:
#define _CRT_SECURE_NO_WARNINGS
#include<assert.h>
#include<iostream>
#include<string.h>
#include<string>
using namespace std;
namespace bit
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷貝構造string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷貝" << endl;string tmp(s._str);swap(tmp);}//移動拷貝構造string(bit::string&& s):_str(nullptr),_size(0),_capacity(0){cout << "string(const string& s) -- 移動拷貝" << endl;swap(s);//不再進行深拷貝,直接獲取s的所有資源}~string(){delete[] _str;_str = nullptr;}// 賦值重載string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷貝" << endl;string tmp(s);swap(tmp);return *this;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(const char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}//string operator+=(char ch)string& operator+=(char ch){push_back(ch);return *this;}const char* c_str() const{return _str;}void Reversal(bit::string::iterator stat, bit::string::iterator end){bit::string strOne;for (bit::string::iterator stat1 = stat; stat1 != end; stat1++){strOne.push_back(*stat1);}bit::string::iterator ro = strOne.end()-1;for (; stat != end; stat++){*stat = *ro;ro--;}}int size(){return _size;}friend std::ostream& operator<<(std::ostream& os, bit::string& str);private:char* _str;//創建的數組size_t _size;//需要創建的大小size_t _capacity; // 不包含最后做標識的\0 當前的長度};std::ostream& operator<<(std::ostream& os, const bit::string& str) {return os;}template<class T = int>string To_String(T a){bit::string str{""};if (a < 0){a = 0 - a;str.push_back('-');}int num = (str.size() > 0 ? 1 : 0);while (a / 10){str.push_back('0' + (a % 10));a /= 10;}str.push_back('0' + a);str.Reversal(str.begin() + num , str.end());for (bit::string::iterator stat = str.begin(); stat != str.end(); stat++){cout << *stat;}cout << endl;return str;}
}
int main()
{bit::string ret = bit::To_String(-123456);//調用的是深拷貝構造,因為拷貝構造的參數是一個const左值引用,可以引用左值和右值return 0;
}
圖如下:
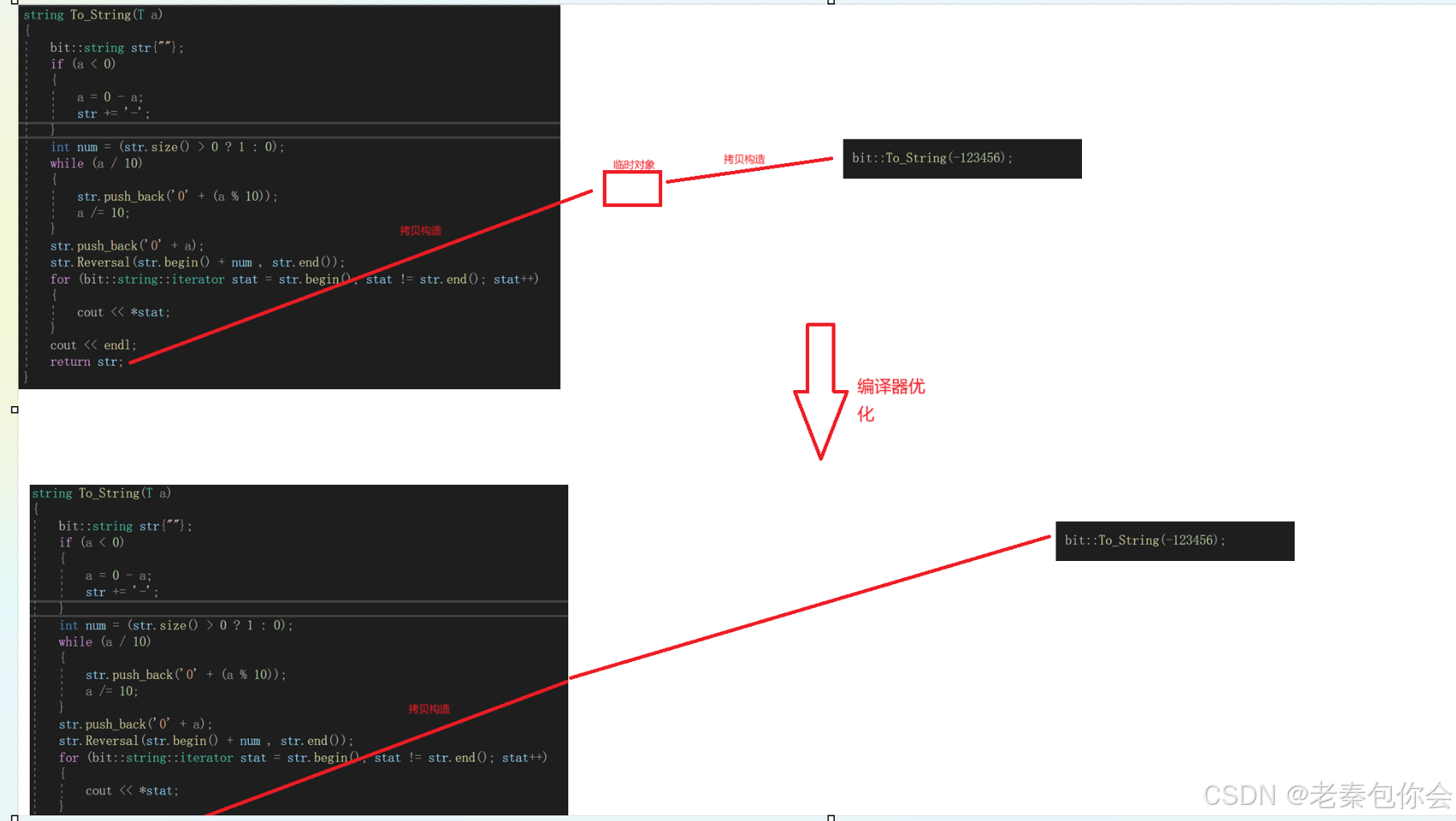
在To_String函數中,返回的是局部對象,出作用域就會銷毀, 進行兩次拷貝構造,在新的編譯器中,會對幾步進行優化,優化為1次拷貝構造,,這就是左值引用的優化過程
右值引用和移動語義
在上面的 代碼中,如果使用 使用To_String函數的返回值,進行如下操作
bit::string ret = bit::To_String(-123456);
會發現調用的仍然是拷貝構造,因為拷貝構造函數的參數是一個const左值引用,可以引用左值,To_String函數的返回值就是一個右值,我們知道,一個右值是一個即將消亡的對象,如果再去進行深拷貝,就會浪費時間和空間,為此,我們可以寫一個移動拷貝函數進行把這個對象對應的資源拿過來使用,
移動拷貝:通常指的是 ??移動語義(Move Semantics)??,它通過 std::move和移動構造函數/移動賦值運算符實現,用于高效轉移資源所有權,避免不必要的深拷貝。
當運行代碼的時候,編譯器會把返回值識別為右值,
在這個過程中,編譯器也經歷了一部分的優化,在C++11把右值引用引入后,編譯器會把局部的返回值調用拷貝構造生成對應的臨時變量, 這個臨時變量就是右值, 然后右值再進行一次移動構造,這是編譯器在引入右值引用的優化之前的過程,在優化之后,就會進行默認的move左值,變成右值,然后調用一次移動構造

移動賦值拷貝
bit::string s;
bit::string r;//假設z是一個將亡值
bit::string&& z = r;//z為右值引用
s = z

z賦值給s,而z為一個右值引用,s可以把z的資源拿過來,s把屬于自己的資源(原本要釋放的)給z,由z進行銷毀。
具體如下:
//移動賦值拷貝string& bit::strig::operator=(string&& s){cout << "string& operator=(string s) -- 移動賦值拷貝" << endl;swap(s);return *this;}int main(){bit::string ret1;ret = bit::To_String(-6);return 0;}
注意: 右值不能被修改,但是右值引用可以被修改,并且右值引用是一個左值屬性,這樣才能被修改,如果是直接傳右值引用為函數參數就會被當成左值。如果要不想為左值,可以把這個右值引用進行move
如圖:
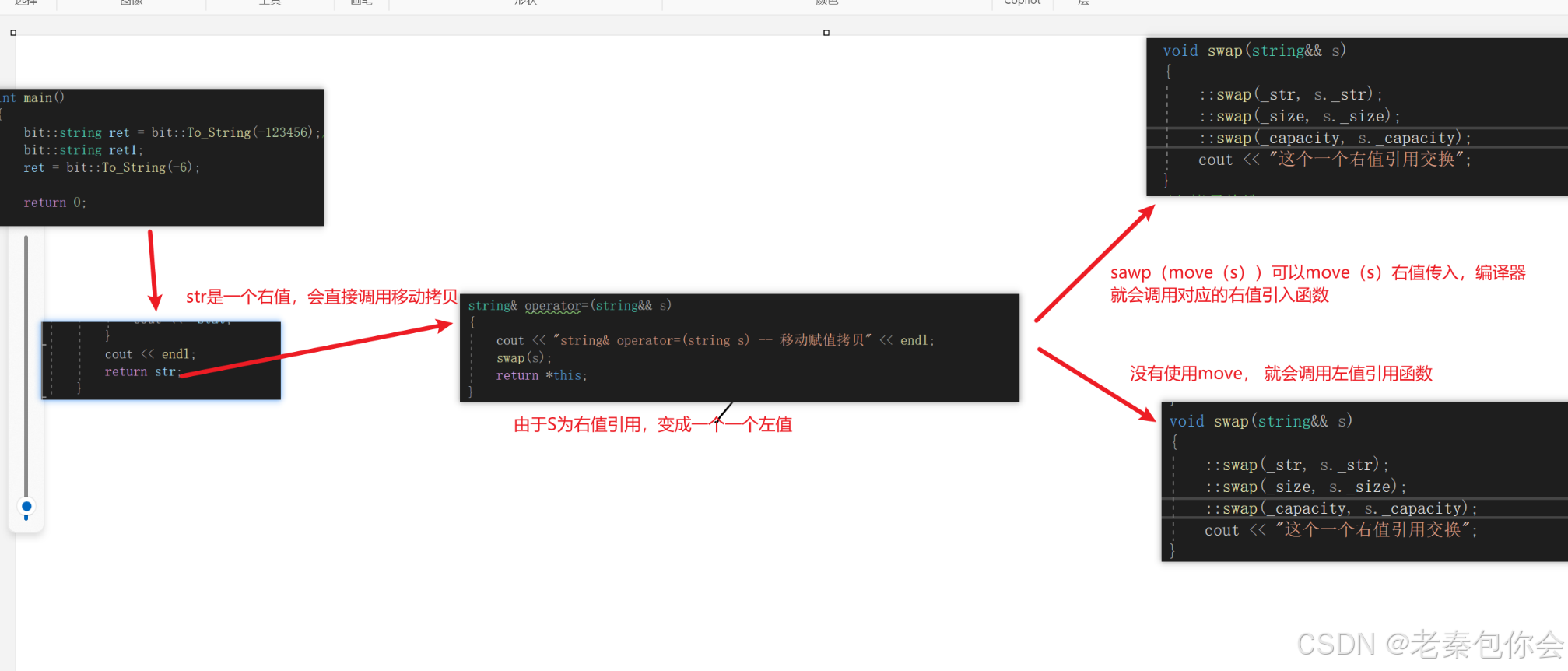
這也就能解釋出來,為啥右值不可以修改,右值引用可以修改,
完美轉發
寫法:搭配函數模板使用
在模板中的 萬能引用
void Fun(int& t)
{cout << "左值引用" << endl;
}
void Fun(const int& t)
{cout << "const 左值引用" << endl;
}
void Fun(int&& t)
{cout << "右值引用" << endl;
}
void Fun(const int&& t)
{cout << "const 右值引用" << endl;
}
template<class T>
void Funtion(T && t)
{Fun(t);
}
int main()
{int a = 10;Funtion(10);//右值Funtion(a);//左值Funtion(move(a));//右值// constconst int b = 20;Funtion(b);//左值Funtion(move(b));//右值return 0;
}
代碼中的Funtion函數的使用了函數模板,參數類型T&&t只是一個參數, 模板中的&&不代表右值引用,而是萬能引用,
萬能引用的定義條件??
萬能引用(Universal Reference)必須滿足以下兩個條件:
??模板類型推導上下文??:T&&必須直接參與模板參數推導。
??精確的 T&&形式??:不能有 const修飾或其他變化。
模板的萬能引用只是提供了能夠接收同時接收左值引用和右值引用的能力,當傳入的是左值,這個參數就是左值引用,如果是右值就是右值引用。
寫法如下:
void Funtion(T && t)
{Fun(std::forward<T>(t));
}
forward是一個函數模板 傳入類型和參數就行
新的類功能
前面我們在學習類的默認成員函數知道,有六大成員函數:
- 構造函數
- 析構函數
- 拷貝構造函數
- 拷貝賦值重載
- 取地址重載
- const 取地址重載
現在C++11引入了兩個:移動構造函數和移動賦值運算符重載。
針對移動構造函數和移動賦值運算符重載有一些需要注意的點如下:
- 如果你沒有自己實現移動構造函數,且沒有實現析構函數 、拷貝構造、拷貝賦值重載中的任意一個。那么編譯器會自動生成一個默認移動構造。默認生成的移動構造函數,對于內置類型成員會執行逐成員按字節拷貝,自定義類型成員,則需要看這個成員是否實現移動構造,如果實現了就調用移動構造,沒有實現就調用拷貝構造。
- 如果你沒有自己實現移動賦值重載函數,且沒有實現析構函數 、拷貝構造、拷貝賦值重載中的任意一個,那么編譯器會自動生成一個默認移動賦值。默認生成的移動構造函數,對于內置類型成員會執行逐成員按字節拷貝,自定義類型成員,則需要看這個成員是否實現移動賦值,如果實現了就調用移動賦值,沒有實現就調用拷貝賦值。(默認移動賦值跟上面移動構造完全類似)
- 如果你提供了移動構造或者移動賦值,編譯器不會自動提供拷貝構造和拷貝賦值。
類成員變量初始化
C++11允許在類定義時給成員變量初始缺省值,默認生成構造函數會使用這些缺省值初始化。
強制生成默認函數的關鍵字default
C++11可以讓你更好的控制要使用的默認函數。假設你要使用某個默認的函數,但是因為一些原因這個函數沒有默認生成。比如:我們提供了拷貝構造,就不會生成移動構造了,那么我們可以使用default關鍵字顯示指定移動構造生成。
class Person
{
public:Person(const char* name = "", int age = 0):_name(name), _age(age){}Person(const Person& p):_name(p._name), _age(p._age){}Person(Person&& p) = default;//強制生成移動構造
private:bit::string _name;int _age;
};
如果 強制生成移動構造,如果沒有寫拷貝構造,編譯器是不會去生成拷貝構造,這樣可以約束一下寫法,避免在生成移動構造,就忽略不寫拷貝構造。
禁止生成默認函數的關鍵字delete:
在C++98之前,如果不想讓類對象被拷貝往往就會把拷貝構造函數私有化+聲明
class A
{
public:A():_s(){}
private:A(const A& de);//防止被好心辦壞事Person _s;
};
int main()
{A s;A ss(s);//報錯return 0;
}
但是在C++11之后,就進行引入關鍵字delete,如下:
class A
{
public:A():_s(){}A(const A& de) = delete;
private://防止被好心辦壞事Person _s;
};
int main()
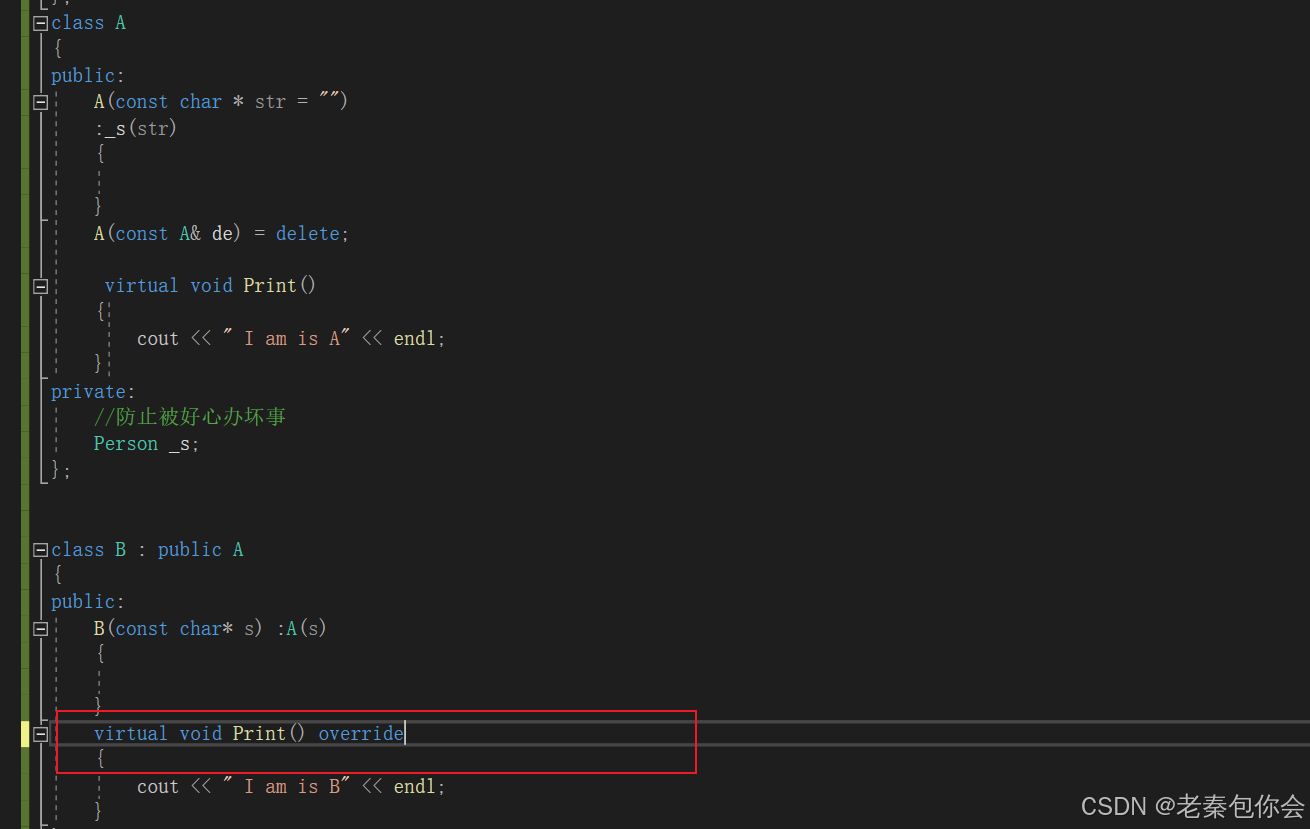
{A s;A ss(s);//報錯}繼承和多態中的?nal與override關鍵字
final關鍵字,作用于虛函數和類。作用于虛函數的時候,讓虛函數不能重寫,如圖:
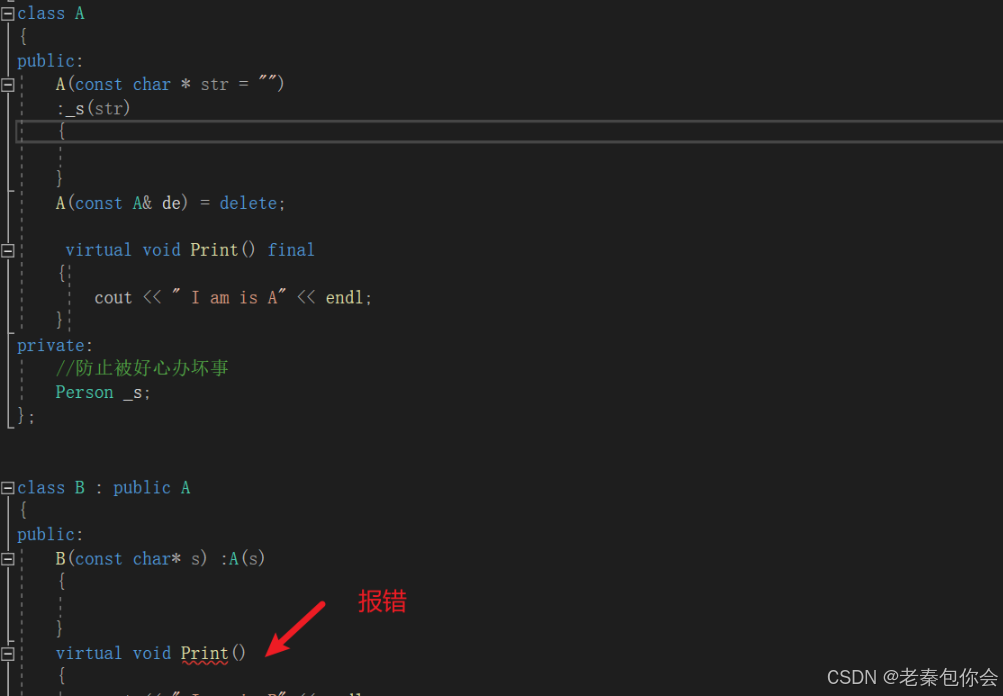
作用于類的時候,讓類不能被繼承。如圖
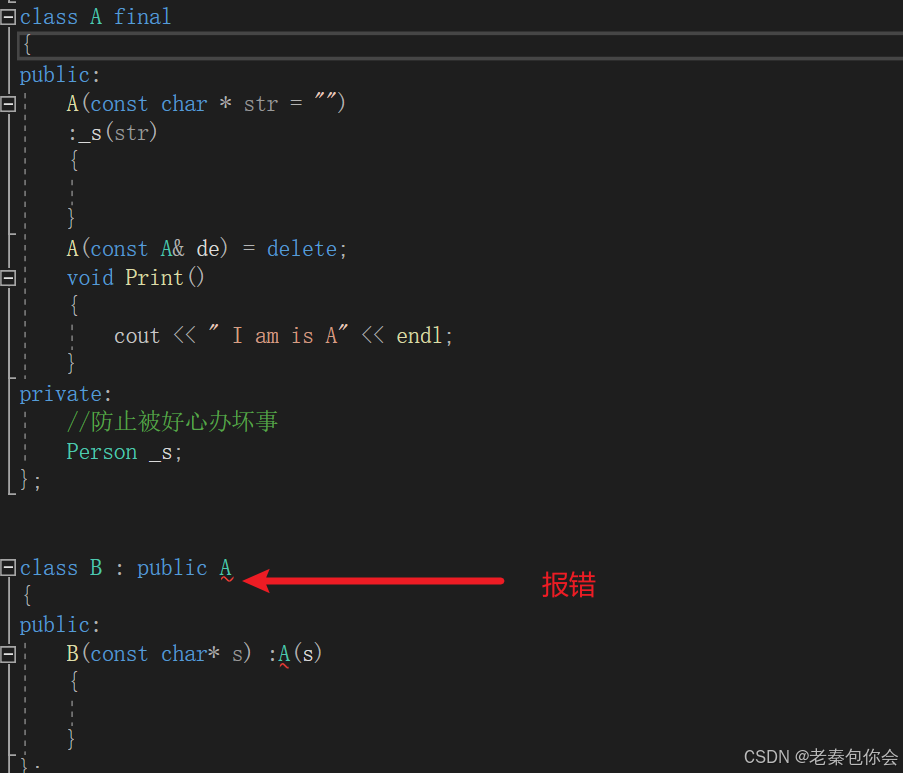
override關鍵字作于于虛函數,主要作用于子類的虛函數重寫,如果沒有重寫父類的虛函數就會報錯
可變參數模板
C++11的新特性可變參數模板能夠讓您創建可以接受可變參數的函數模板和類模板
比如printf函數的形參就是可變參數
一個基本可變參數的函數模板如下:
// Args是一個模板參數包,args是一個函數形參參數包
// 聲明一個參數包Args...args,這個參數包中可以包含0到任意個模板參數。
template <class ...Args>
void ShowList(Args... args)
{}
上面的參數args前面有省略號,所以它就是一個可變模版參數,我們把帶省略號的參數稱為“參數包”,它里面包含了0到N(N>=0)個模版參數。
如果我們想要知道我們往這個函數傳入的參數有多少個,可以使用sizeof…
template<class ...x>//表示有多個類型
void FunOne(x... a)//表示可以傳入多個x類型的參數
{cout << sizeof...(a) << endl;
}
int main()
{FunOne<int>(10);FunOne(10,20);FunOne(10,30,40,50);return 0;
}
如圖:

如果使用可變參數類型模板,我們往往需要知道怎么獲取到參數及其類型
在C語言中的可變參數中,進行參數的解析是在運行時解析的,但是我們這里時模板,模板需要在編譯時解析,在編譯時解析的時候,編譯器會寫一個遞歸解析。長啥樣?
下面寫一個相似的:
void FunTwo()//編譯解析的結束條件
{cout << "運行結束" << endl;
}
template<typename T,class ...X>
void FunTwo(T&& t, X&&... arg)
{cout << typeid(t).name() << t << endl;//if (sizeof...(arg) == 0)//這樣寫是在運行時起效果,但是可變參數類型模板是在編譯時解析的// return;FunTwo(arg...);//當參數為0個,就會調用FunTwo()函數
}template<class ...x>//表示有多個類型
void FunOne(x&&... a)//表示可以傳入多個x類型的參數
{cout << sizeof...(a) << endl;FunTwo(forward<x>(a)...);
}
這個遞歸寫法,主要是為例解析參數有多少個和獲取到對應參數的寫法,采用萬能引用和完美轉發進行寫的遞歸解析,這個遞歸解析的結束條件不能像普通遞歸函數的結束條件一樣,需要寫一個無參數的FunTwo函數重載,因為到最后遞歸到一定是
編譯器在編譯會對模板對進行推演,例如FunOne(10,20);在編譯期間的推演就是如下:
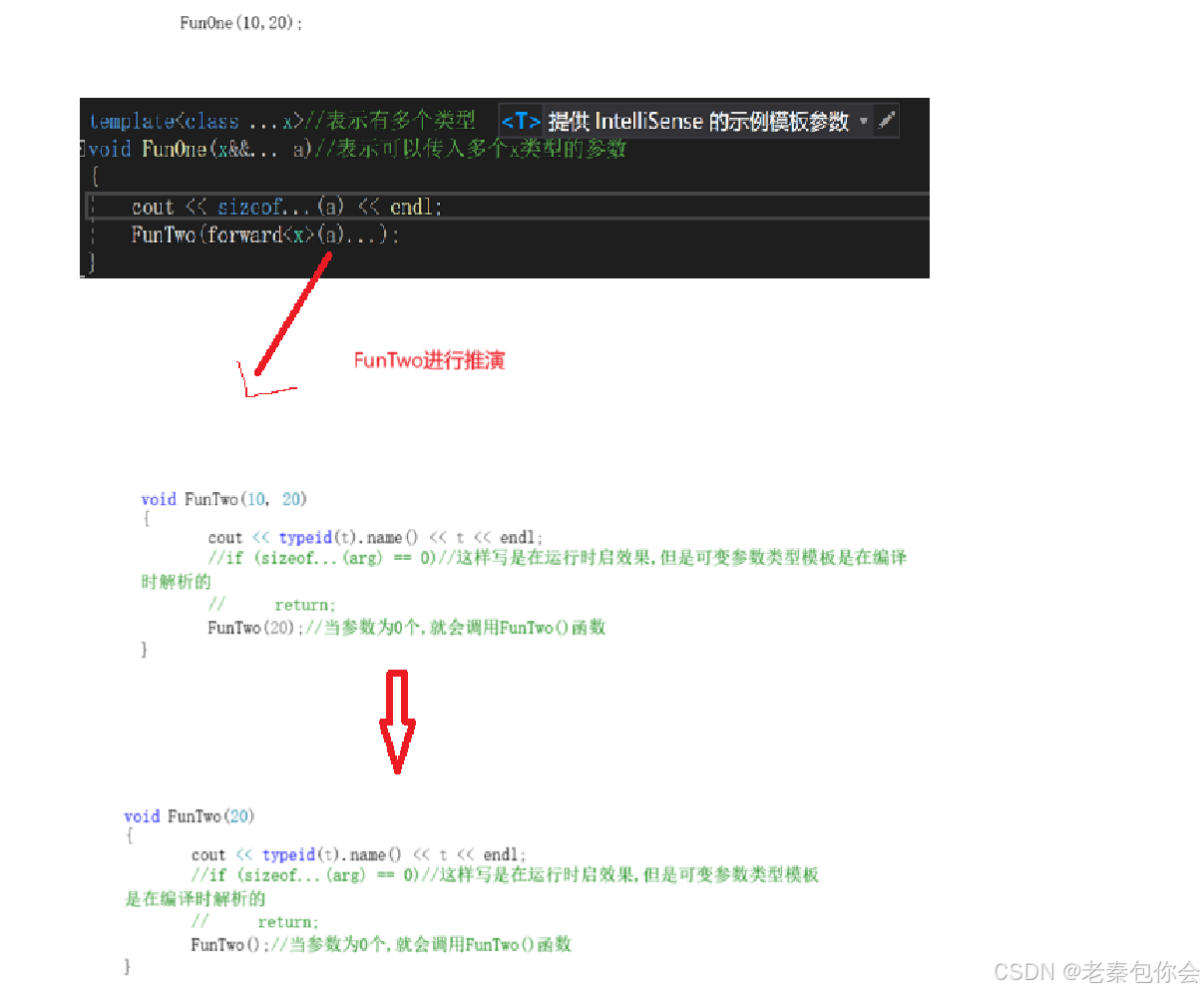
會把多個參數的第一個傳給t形參,剩下的參數傳入到arg中,不斷循環,直到參數為0個
lambda表達式
在一些場合中,會因為要傳入一些對應的的仿函數或者函數指針而去重新寫一個出來,這個過程可能會因為某些命名規則很不方便,例如:
class Goods
{
public:Goods(const char* name, double price, int evaluate):_name(name),_price(price),_evaluate(evaluate){}std::string _name;double _price;int _evaluate;
};
struct ComparePriceLess//仿函數
{bool operator()(const Goods& g1, const Goods& g2){return g1._price < g2._price;}
};
struct ComparePriceRigth//仿函數
{bool operator()(const Goods& g1, const Goods& g2){return g1._price > g2._price;}
};
int main()
{std::vector<Goods> v = { { "蘋果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠蘿", 1.5, 4 } };std::sort(v.begin(), v.end(), ComparePriceLess());//傳入仿函數對象return 0;
}
這個例子就是寫一個一個類和對應的類的某些成員進行比較的仿函數,使用std::sort函數進行對應的排序,可以看出每次為了實現一個algorithm算法,都要重新去寫一個類,如果每次比較的邏輯不一樣,還要去實現多個類,特別是相同類的命名,這些都給編程者帶來了極大的不便。為此引入lambda表達式。
lambda表達式的書寫格式:
[capture-list] (parameters) mutable -> return-type
{statement
}
lambda表達式各部分說明
- [capture-list] : 捕捉列表,該列表總是出現在lambda函數的開始位置,編譯器根據[]來判斷接下來的代碼是否為lambda函數,捕捉列表能夠捕捉上下文中的變量供lambda函數使用。簡單的理解就是你需要這個函數使用啥變量或者對象,只需在【】中寫入就行,在這里一般有幾種捕獲方式:
(1) 傳值捕捉
只是這個捕獲的值是一個拷貝過來的值,是一個const修飾的值,無法被改變,如果想要改變可以添加mutable
int main()
{int a = 10;int b = 30;int c = 40;auto Add = [a,b,c] (const int& ar1, const int& ar2)mutable -> int{a = 1000;return a + b;};cout << Add(20, 30) << endl;cout << "a = " << a;return 0;
}
如圖:
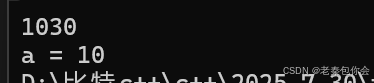
如果沒有添加mutable是不能修改的
(2) 傳引用捕捉
int main()
{int a = 10;int b = 30;int c = 40;auto Add = [&a,&b,&c] (const int& ar1, const int& ar2) -> int{a = 1000;return a + b;};cout << Add(20, 30) << endl;cout << "a = " << a;return 0;
}
效果:

可以看出,沒有添加mutable也可以直接修改。
(3)捕捉當前作用域的全部變量
int main()
{int a = 10;int b = 30;int c = 40;auto Add = [=] (const int& ar1, const int& ar2)mutable -> int{a = 1000;return a + b;};cout << Add(20, 30) << endl;cout << "a = " << a;return 0;
}
寫法是 [=]
(4)捕獲當前作用域的所有對象引用
int main()
{int a = 10;int b = 30;int c = 40;auto Add = [&] (const int& ar1, const int& ar2)-> int{a = 1000;return a + b;};cout << Add(20, 30) << endl;cout << "a = " << a;return 0;
}
剩下的就是混合捕捉,比較好理解剩下就不寫;
3. (parameters):參數列表。與普通函數的參數列表一致,如果不需要參數傳遞,則可以連同()一起省略,簡單的理解就是,這個就是函數的形參
-
mutable:默認情況下,lambda函數總是一個const函數,mutable可以取消其常量性。使用該修飾符時,參數列表不可省略(即使參數為空)。
-
->returntype:返回值類型。用追蹤返回類型形式聲明函數的返回值類型,沒有返回值時此部分可省略。返回值類型明確情況下,也可省略,由編譯器對返回類型進行推導。
-
{statement}:函數體。在該函數體內,除了可以使用其參數外,還可以使用所有捕獲到的變量。
lambda表達式我們可以理解為一個匿名函數對象,就像是匿名對象一個樣子,我們可以看看lambda在編譯器中是怎么樣的,下面寫一個代碼進行驗證:
template<typename T>
struct AddClass//仿函數
{
public:AddClass(const T& na):_a(na){}T operator()(const T& g1 , const T& g2){return g1 + g2;}
private:T _a;
};
int main()
{int a = 10;int b = 30;int c = 40;//lambda表達式auto Add = [=] (const int& ar1, const int& ar2) mutable-> int{a = 1000;return a + b;};Add(20, 30);//仿函數AddClass<int> r1(1);r1(20, 30);cout << "a = " << a;return 0;
}
效果如下:
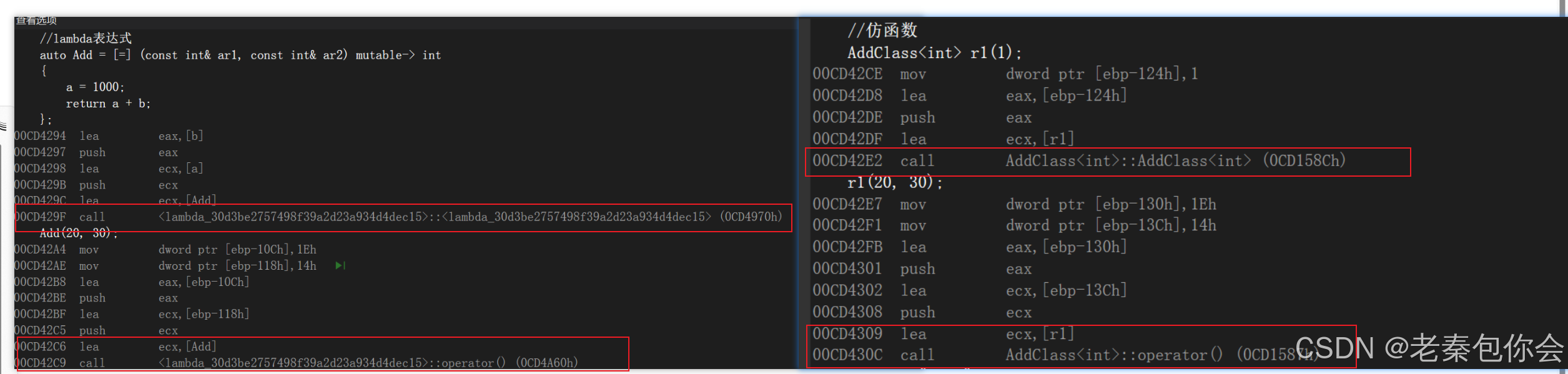
可以看出,在反匯編中,lambda表達式和仿函數是完全一樣的,實際在底層編譯器對于lambda表達式的處理方式,完全就是按照函數對象的方式處理的,即:如果定義了一個lambda表達式,編譯器會自動生成一個類,在該類中重載了operator()。lambda捕獲的變量或者對象,變成這個類的成員變量,捕捉相當于就是拷貝了一份const成員變量。
包裝器
function包裝器
function包裝器 也叫作適配器。C++中的function本質是一個類模板,也是一個包裝器。
前面我們總共學習三種可調用對象,函數指針、仿函數、lambda表達式
例如:
ret = func(x);
// 上面func可能是什么呢?那么func可能是函數名?函數指針?函數對象(仿函數對象)?也有可能
是lamber表達式對象?所以這些都是可調用的類型!
下面寫一個代碼進行感受一下:
template<typename T>
struct AddClass//仿函數
{
public:AddClass(const T& na):_a(na){}T operator()(const T& g1 , const T& g2){return g1 + g2;}
private:T _a;
};template<typename T, class F>
F User(T t, F f)
{static int count = 0;cout << "count:" << ++count << endl;cout << "count:" << &count << endl;return t(std::forward<F>(f));
}template<class T>
T Funtion(T a)
{cout << "Funtion" << endl;return a;
}template<class T>
class FuntionClass
{
public:T operator()(T a){cout << " FuntionClass" << endl;return a;}
};
int main()
{int elemest = 2;//使用User函數進行三種調用User(Funtion<decltype(elemest)>, elemest);//傳入函數指針User(FuntionClass<decltype(elemest)>(), elemest);//傳入仿函數User([](decltype(elemest) a) {cout << "lambda" << endl;return a;}, elemest);//lambda表達式return 0;
}如圖:
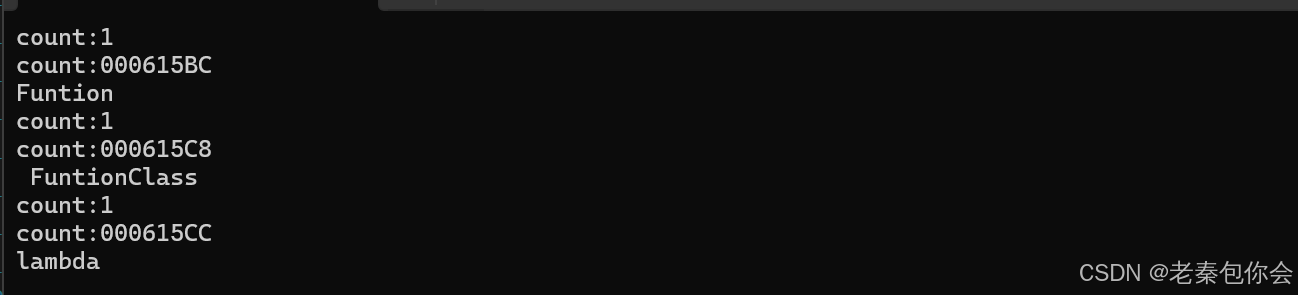
代碼中,User函數模板實例化三份`,每次調用 User時,由于傳入的參數類型不同,編譯器會生成 ??三個獨立的模板實例??,每個實例都有自己的靜態變量 count:為了解決這個問題
在C++11引入了包裝器,以function為例,這個一個類模板
std::function在頭文件<functional>
// 類模板原型如下
template <class T> function; // undefinedtemplate <class Ret, class... Args>
class function<Ret(Args...)>;
模板參數說明:
Ret: 被調用函數的返回類型
Args…:被調用函數的形參
這個不僅僅可以把函數進行包裝,還可以把仿函數和lambda表達式進行包裝,進行優化后,代碼如下:
int main()
{int elemest = 2;//使用User函數進行三種調用function<decltype(elemest)(decltype(elemest))> df = Funtion<decltype(elemest)>;User(df, elemest);//傳入函數指針function<decltype(elemest)(decltype(elemest))> df1 = FuntionClass<decltype(elemest)>();User(df1, elemest);//傳入仿函數function<decltype(elemest)(decltype(elemest))> df2 = [](decltype(elemest) a) {cout << "lambda" << endl;return a;};User(df, elemest);//lambda表達式return 0;
}
如圖:
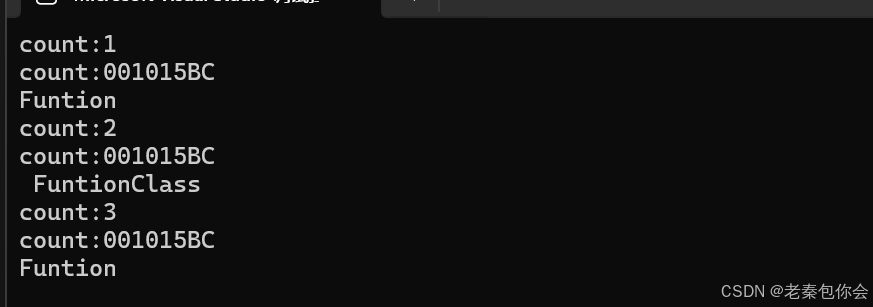
可以看到User調用的都是都是一個樣子的模板。所以就會模板實例一次,所以說function就是封裝并統一類型(意義),為啥這樣說?因為函數指針寫起來不方便,而仿函數的類型有不同的類型,lambda表達式在語法層是沒有類型的,
除此之外,function還可以進行包裝對應的類成員函數,
class Plus
{
public:static int FunctionOne(int a, int b){cout << a + b << endl;return a + b;}int FunctionTwo(int a, int b){return _parper;}private:int _parper = 20;};
int main()
{function<int(int, int)> f = &Plus::FunctionOne;//靜態成員函數//非靜態成員函數function<int(Plus, int, int)> ff = &Plus::FunctionTwo;//第一種方法cout << ff(Plus(), 20, 30) << endl;//傳入對象function<int(Plus*, int, int)> ff1 = &Plus::FunctionTwo;//第二種方式Plus ss;ff1(&ss, 30,20);//傳入對象的指針return 0;
}
上述代碼就是包裝類的成員函數的例子。可以大致猜到function是一個類似仿函數的類。
bing包裝器
除了上面的function模板類,還有一個bind函數。
std::bind函數定義在頭文件中,是一個函數模板,它就像一個函數包裝器(適配器),接受一個可調用對象(callable object),生成一個新的可調用對象來“適應”原對象的參數列表。一般而言,我們用它可以把一個原本接收N個參數的函數fn,通過綁定一些參數,返回一個接收M個(M可以大于N,但這么做沒什么意義)參數的新函數。同時,使用std::bind函數還可以實現參數順序調整等操作。
/ 原型如下:
template <class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
// with return type (2)
template <class Ret, class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
bing主要針對可調用對象進行參數的調整:
- 調整參數順序
- 調整參數的個數
我們可以將bind函數看作是一個通用的函數適配器,它接受一個可調用對象,生成一個新的可調用對象來“適應”原對象的參數列表。
調用bind的一般形式:auto newCallable = bind(callable,arg_list);
int Sub(int x, int y)
{return x - y;
}int main()
{int a = 10; int b = 20;cout << Sub(a, b) << endl;auto fun = bind(Sub, std::placeholders::_2, std::placeholders::_1);//std::placeholders::_1表示Sub函數的第一個參數, std::placeholders::_2并表示Sub函數的第二個參數.cout << fun(a, b) << endl;//a傳給std::placeholders::_1, b傳給std::placeholders::_2,return 0;
}
效果如下:

調用fun給我們的表象就是fun(10,20),實際上就是Sub(20,10)
這里引入placeholders的命名空間,
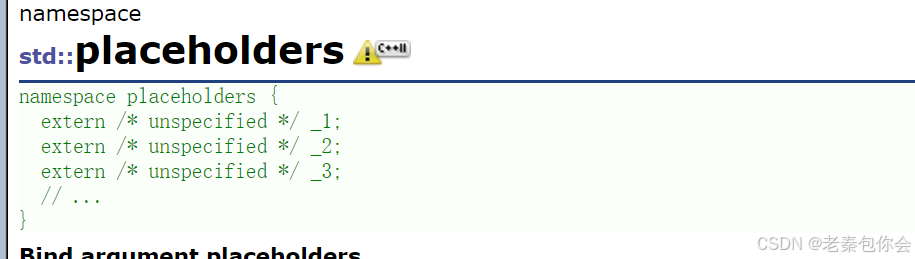
使用bind的使用,涉及到參數一定要從std::placeholders::_1(始終表示第一個參數)開始寫入,否則會報錯。下面我們把function包裝的類的成員函數進行改良一下,類的靜態成員函數和類的成員函數,最大的區別就是靜態成員函數沒有this指針,所以使用function進行模板實例的時候,多寫一個類型,
如下:
Plus ss;function<int(int, int)> ff1 = bind(&Plus::FunctionTwo, ss, 200,std::placeholders::_1);ff1(30,20);//30傳給placeholders::_1
航空軸承剩余壽命預測:多生成器GAN與CBAM融合的創新方法)







)



)

)


![[Oracle數據庫] Oracle 常用函數](http://pic.xiahunao.cn/[Oracle數據庫] Oracle 常用函數)
講解+架構搭建(可直接copy運行)+ MNIST數據集視角調整實驗)
