一、常用的Action算子
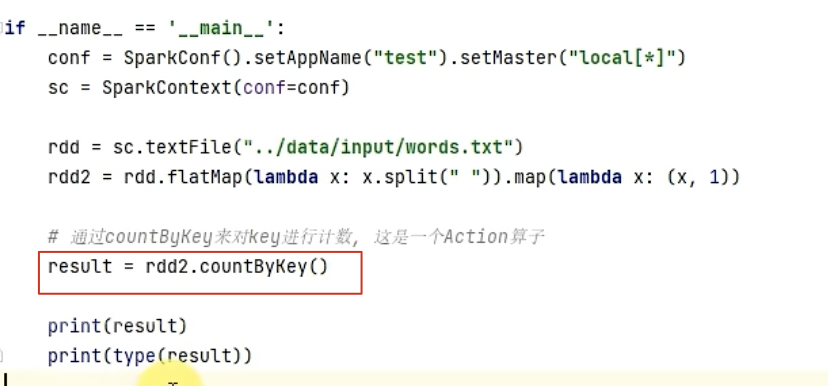
1-1、countByKey算子
作用:統計key出現的次數,一般適用于K-V型的RDD。
【注意】:
1、collect()是RDD的算子,此時的Action算子,沒有生成新的RDD,所以,沒有collect()!!!
2、Action算子,返回值不再是RDD,而是字典!
示例:

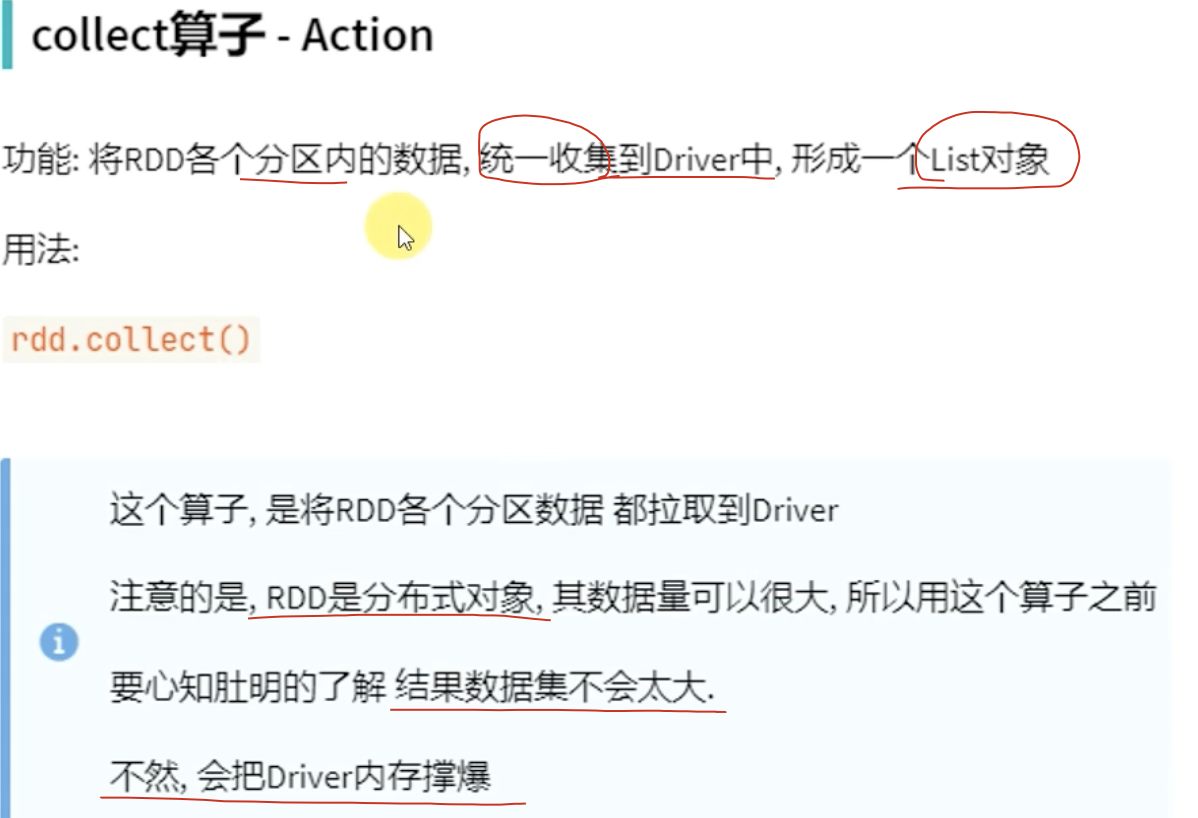
1-2、collect算子
1-3、reduce算子

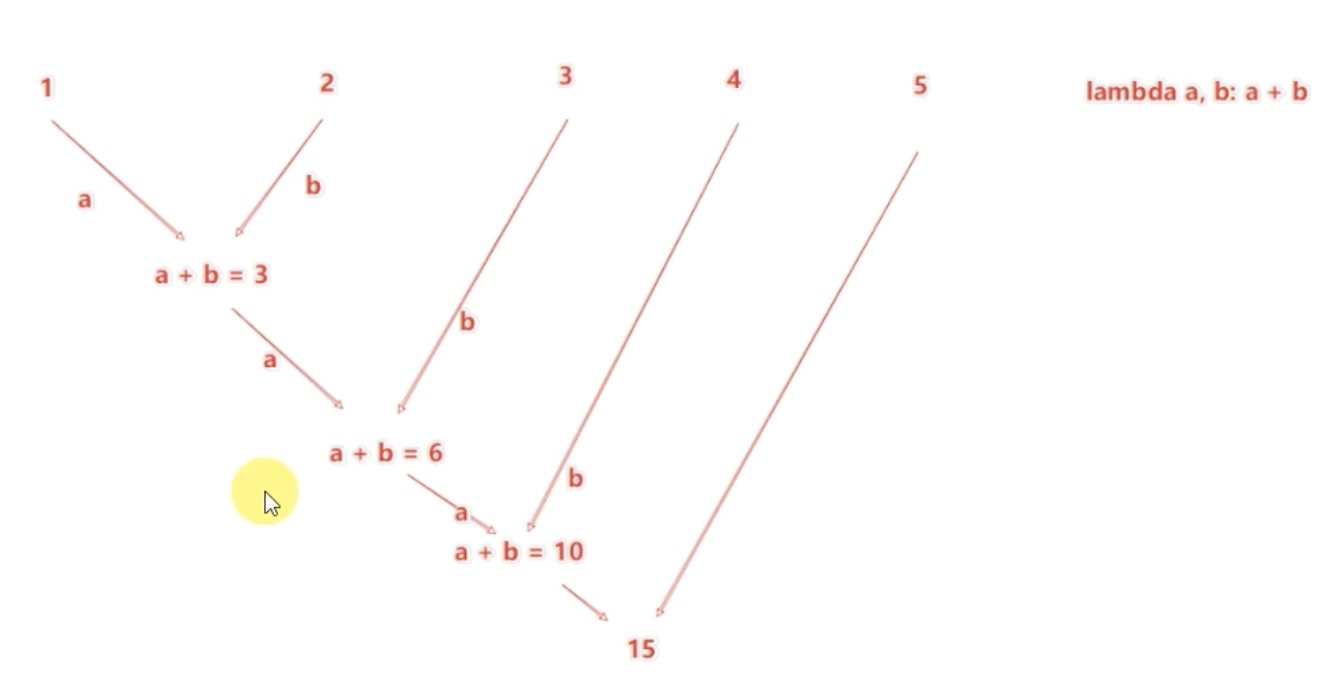
示例:
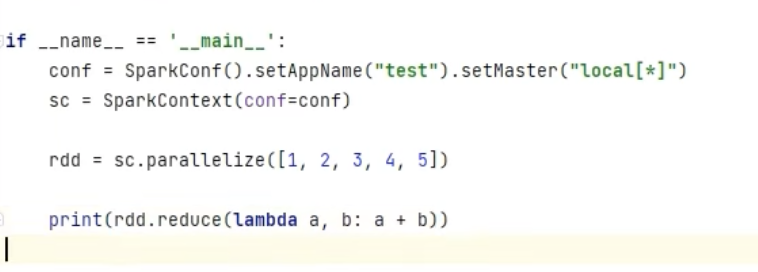
返回結果:15
回顧:reduceByKey的邏輯:Spark03-RDD01-簡介+常用的Transformation算子-CSDN博客
1-4、fold算子

1-5、first算子

示例:
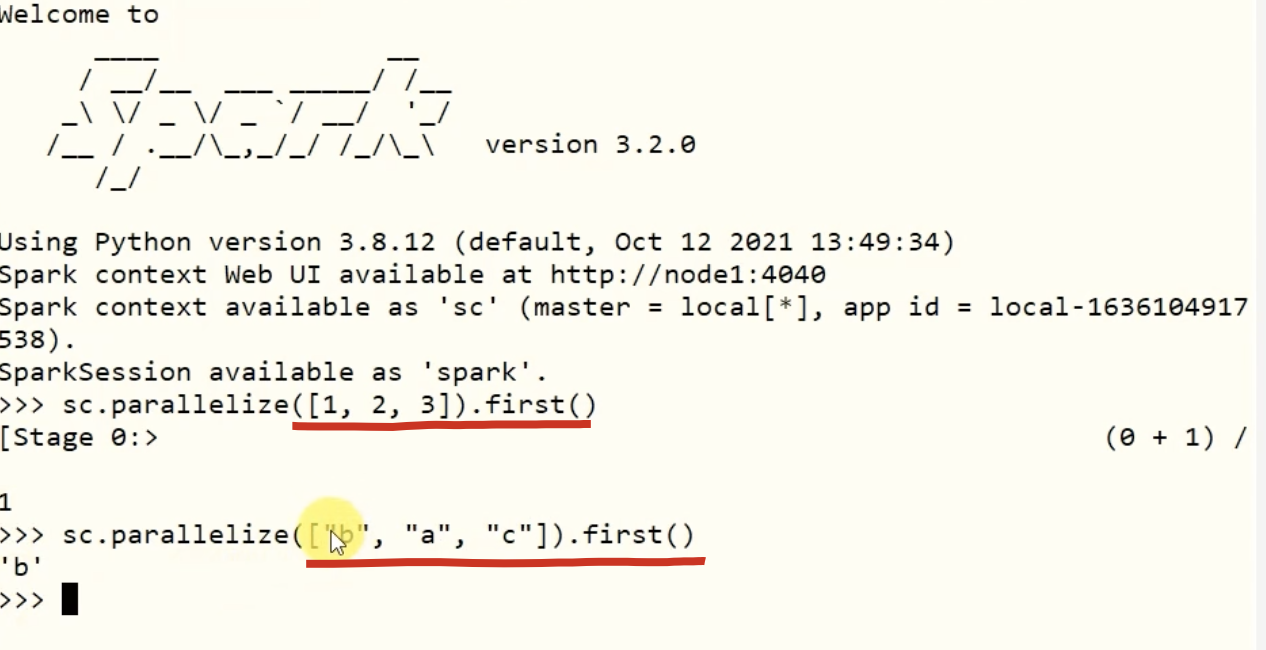
1-6、take算子
功能:獲取RDD的前N個元素,組合成list返回給你。
示例:

1-7、top算子
功能:對RDD數據集,先降序,再取前N個。相當于:取最大的前N個數字,返回類型:list。
【注意】:item之間的比較,可以自定義比較函數。
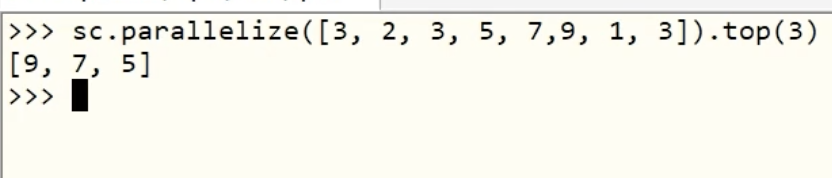
1-8、count算子
計算RDD有多少條數據,返回的是一個數字!

1-9、takeSample算子
1. 作用
takeSample 用于從 RDD 中隨機抽取一定數量的元素,返回的是一個 Python list(而不是 RDD)。
它常用于數據探索,比如從一個很大的分布式數據集中 隨機取樣 看看大概長什么樣。
2. 函數簽名
RDD.takeSample(withReplacement, num, seed=None)
-
withReplacement:
True/False-
True:有放回抽樣(同一個元素可能被多次抽到) -
False:無放回抽樣(每個元素最多出現一次)
-
-
num:
int-
需要抽取的樣本數量
-
-
seed:
int(可選)-
隨機數種子。指定后每次結果一致;不指定時每次運行結果可能不同
-
3. 返回值
返回的是一個 list,包含抽到的樣本。
?? 注意:不會返回一個 RDD,而是直接把樣本收集到 driver 程序。
????????
在 PySpark 的
takeSample里,如果是無放回抽樣 (withReplacement=False),且你請求的樣本數量 大于 RDD 總數,即:?num > RDD.count(),結果會直接返回 整個 RDD,不會報錯。
4. 示例代碼
from pyspark import SparkContextsc = SparkContext("local", "TakeSampleExample")data = sc.parallelize(range(1, 101)) # RDD: 1 ~ 100# 無放回抽樣,取 10 個
sample1 = data.takeSample(False, 10)
print("無放回抽樣:", sample1)# 有放回抽樣,取 10 個
sample2 = data.takeSample(True, 10)
print("有放回抽樣:", sample2)# 固定隨機種子
sample3 = data.takeSample(False, 10, seed=42)
print("固定種子:", sample3)
運行可能結果:
無放回抽樣: [57, 3, 85, 21, 92, 38, 44, 71, 5, 66]
有放回抽樣: [21, 21, 45, 72, 3, 98, 45, 12, 7, 7]
固定種子: [63, 2, 73, 82, 23, 18, 47, 74, 96, 94]
5. 特點 & 注意點
-
返回 Python list,所以抽樣結果會被拉回 driver 內存。
-
不適合
num特別大(比如幾百萬),會導致 driver 內存爆炸。
-
-
比
sample不同-
sample(withReplacement, fraction, seed)→ 返回 RDD(按比例抽樣) -
takeSample(withReplacement, num, seed)→ 返回 list(按數量抽樣)
總結:
-
想要 指定比例抽樣 → 用
sample -
想要 指定數量抽樣 → 用
takeSample
-
6. 使用場景
-
調試 / 探索:比如 RDD 太大,不可能直接
collect(),就可以takeSample(False, 20)隨機取 20 個元素看一眼。 -
機器學習抽樣:從數據集中隨機取一部分作為訓練集 / 測試集。
-
模擬實驗:需要隨機數據時快速取一批樣本。
1-10、takeOrder算子
1. 作用
takeOrdered 用于 從 RDD 中取出前 n 個元素,返回的是一個 Python list。
-
默認情況下,按 升序 排序后取前 n 個;(最小的前n個)
-
也可以通過
key參數指定排序規則。
2. 函數簽名
RDD.takeOrdered(num, key=None)
-
num:
int
要取的元素個數。 -
key:
function(可選)
用來指定排序方式。-
不指定 → 默認升序
-
指定
lambda x: -x→ 可以變成降序
-
3. 返回值
返回一個 list,長度最多是 num,包含排序后的前 n 個元素。
(?? 和 takeSample 一樣,也會把結果拉回到 driver)
4. 示例代碼
from pyspark import SparkContext
sc = SparkContext("local", "TakeOrderedExample")data = sc.parallelize([5, 1, 8, 3, 2, 10, 6])# 取前 3 個最小的元素(默認升序)
result1 = data.takeOrdered(3)
print("最小的3個:", result1)# 取前 3 個最大的元素(用 key 參數)
result2 = data.takeOrdered(3, key=lambda x: -x)
print("最大的3個:", result2)# 按元素的平方排序,取前 3 個
result3 = data.takeOrdered(3, key=lambda x: x*x)
print("平方最小的3個:", result3)
可能輸出:
最小的3個: [1, 2, 3]
最大的3個: [10, 8, 6]
平方最小的3個: [1, 2, 3]
5. 特點 & 注意點
-
返回 Python list,結果會直接拉到 driver。
-
如果
num很大,可能導致內存壓力。
-
-
和其他算子的區別
-
top(n):返回最大的 n 個元素,默認降序。(只能是降序) -
takeOrdered(n):返回最小的 n 個元素,默認升序。 -
sortBy(key, ascending, numPartitions):返回排序后的 RDD,比takeOrdered重得多,因為它要分布式全排序。
總結:
-
只想取 前 n 個 → 用
takeOrdered或top(高效) -
想要 全局排序 → 用
sortBy(代價更大)
-
6. 使用場景
-
取 Top-N 或 Bottom-N 樣本,比如成績前 10 名、銷售額最高的 5 個商品。
-
數據探索時快速查看極值(最小/最大值)。
-
機器學習前的數據預處理,比如截取一部分樣本。
1-11、foreach算子
1. 作用
foreach 用于對 RDD 的每個元素執行一個指定的函數(function),但 不會返回任何結果。
它的典型用途是:
-
在每個分區的 worker 節點上,對數據做副作用操作,比如寫數據庫、寫文件、更新計數器。
2. 函數簽名
RDD.foreach(f)
-
f: 一個函數,接收 RDD 的元素作為輸入,對它進行處理。
3. 特點
-
沒有返回值
-
foreach的返回值是None,所以你不能像map那樣拿到新 RDD。 -
它是一個 Action 算子,會觸發真正的執行。
-
-
副作用在 Executor 端發生
-
函數
f會在集群各個節點(Executor)上執行,而不是在 driver 上。 -
所以你在
f里print,日志會打印到 Executor 的日志里,而不是 driver 的控制臺。 -
如果你要在 driver 上調試看數據,可以用
collect()。
-
-
常用場景
-
寫數據庫:
foreach(lambda x: save_to_mysql(x)) -
寫文件系統:
foreach(lambda x: write_to_hdfs(x)) -
更新外部存儲:
foreach(lambda x: redis_client.set(x[0], x[1]))
-
4. 示例
from pyspark import SparkContextsc = SparkContext("local", "ForeachExample")data = sc.parallelize([1, 2, 3, 4, 5])def process(x):print(f"處理元素: {x}")# foreach 對每個元素執行 process
data.foreach(process)
?? 注意:
-
在本地模式(local)下,你可能能在控制臺看到輸出。
-
在集群模式(YARN、Standalone、Mesos),打印信息會在 Executor 日志,driver 控制臺一般看不到。
5. foreach 和 foreachPartition 的區別
-
foreach(f)
→ 每個元素都執行一次f。 -
foreachPartition(f)
→ 每個 分區 執行一次f,f的輸入是該分區的迭代器。
一般寫數據庫、寫外部存儲時推薦 foreachPartition,這樣可以:
-
避免頻繁建立連接(每個分區建立一次連接,而不是每條記錄都建立)。
-
提高性能。
6. 對比 map
| 算子 | 是否返回新 RDD | 是否觸發 Action | 典型用途 |
|---|---|---|---|
map | ? 是 | ? 否 | 數據轉換 |
foreach | ? 否 | ? 是 | 副作用操作(寫庫/打印/發送消息) |
1-12、saveAsTextFile算子
1. 基本功能
saveAsTextFile(path) 是 Action算子(觸發計算的算子),用于將 RDD 的內容 保存到 HDFS、本地文件系統或其他兼容 Hadoop 的文件系統中,存儲格式是 文本文件。
-
每個元素會被轉換為一行字符串(調用
str()方法) -
最終生成的結果是 一個目錄,而不是單個文件
-
目錄中包含多個分區文件(如
part-00000、part-00001…),每個文件對應 RDD 的一個分區
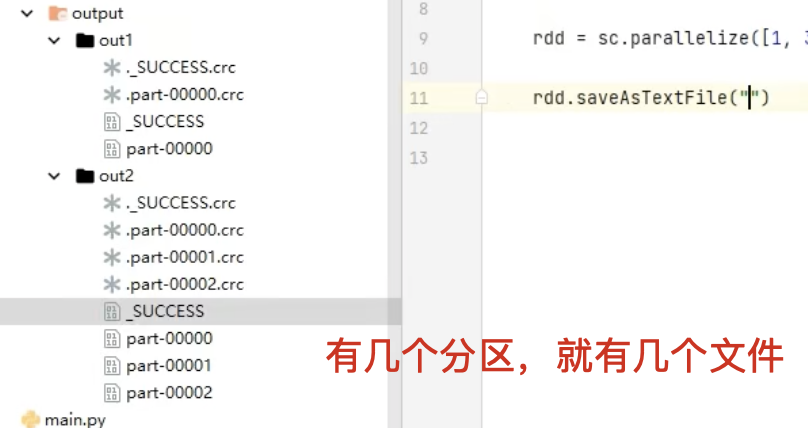
2. 使用方法
# 假設已有一個RDD
rdd = sc.parallelize([1, 2, 3, 4, 5], numSlices=2)# 保存為文本文件
rdd.saveAsTextFile("output_rdd")
結果目錄結構
output_rdd/├── part-00000├── part-00001└── _SUCCESS
-
part-00000、part-00001:存儲 RDD 每個分區的數據 -
_SUCCESS:一個空文件,表示任務成功結束
3. 關鍵注意事項
-
路徑必須不存在
Spark 默認不允許寫入已存在的目錄,否則會報錯:org.apache.hadoop.mapred.FileAlreadyExistsException解決辦法:先刪除舊目錄,再保存。
import shutil shutil.rmtree("output_rdd", ignore_errors=True) rdd.saveAsTextFile("output_rdd") -
輸出是多個文件
如果需要單個文件,可以在保存前 合并分區:rdd.coalesce(1).saveAsTextFile("output_single_file")輸出目錄下只會有一個
part-00000。
coalesce(1)會把 RDD 的所有數據壓縮到 一個分區。“創建一個新的目標分區,然后把數據往里壓”。- 保存時 Spark 會根據分區數寫出文件,因此只會生成 一個
part-00000文件。
如果是要交付給外部系統(比如 CSV 文件要交給別人用),那通常會
coalesce(1)
? ? ? ? 3. 數據類型要求
????????示例:
kv_rdd = sc.parallelize([("a", 1), ("b", 2)], 2)
kv_rdd.saveAsTextFile("output_kv")
# 文件內容大概是:
# ('a', 1) part-00000
# ('b', 2) part-00001
-
saveAsTextFile默認調用str()轉換元素 -
如果是
(key, value)形式的 RDD,輸出會是(key, value)的字符串
4. 典型應用場景
-
保存日志處理結果到 HDFS
-
將 RDD 轉換為文本存儲,供下游任務(Hive、Spark SQL)使用
-
與
saveAsSequenceFile、saveAsObjectFile對比,用于不同場景的持久化存儲
【小結】:
- foreach
- saveAsTestFile
這兩個算子是分區(Excutor)直接執行的,跳過Driver,由所在的分區(Excutor)直接執行,性能比較好!
其余的Action算子都會將結果發送至Driver
![[Android] 顯示的內容被導航欄這擋住](http://pic.xiahunao.cn/[Android] 顯示的內容被導航欄這擋住)


軟件包管理器 yum | Vim 編輯器 | Vim 文本批量化操作 | 配置 Vim)
:基于Cross Attention的VGG16增強方案)


)
)



航空軸承剩余壽命預測:多生成器GAN與CBAM融合的創新方法)






