Spatial Transformer Networks
本文了講述STN的基本架構,空間幾何注意力模塊的基本原理,冒煙測試以及STN在MNIST數據集用于模型自動調整圖片視角的實驗,如果大家有不懂或者發現了錯誤的地方,歡迎討論。
- 中文名:空間Transformer網絡
- 論文鏈接:Arxiv
我更傾向于叫它為Spatio Geometry Transformer Network, 因為它的注意力同時包括了是旋轉,平移,仿射等多種幾何變換,而不是單純地裁剪以注意空間里面的重點。
目錄
- Spatial Transformer Networks
- 模型簡介
- 提出背景
- 設計思路
- 達到效果及優勢
- 對后續模型的影響
- 網絡結構
- Pytorch模型實現+MNIST數據集視角調整實驗
- 準備庫、數據集、數據加載器
- 定義網絡結構
- 定義訓練/測試過程
- 可視化效果
模型簡介
- 作者:Ghassen HAMROUNI
- 發布年:2015
- 為什么這么叫:因為它用使用了空間幾何注意力
- 主要成就:第一個使用空間幾何注意力的卷積神經網絡
STN是對任何空間變化的推廣,其允許神經網絡學習如何對輸入圖像進行 空間變換,以增強模型的 幾何不變性。例如,其可以對感興趣的區域進行裁剪,或者縮放和矯正圖像的方向。這個機制對CNN很有用,因為其對旋轉、縮放、甚至更一般的放射變換并非不變。

提出背景
之前有哪些相同目的的模型/方法?
在STN出現之前,主要是用純粹的CNN來對圖像進行特征圖的提取。但是由于CNN對于圖像的幾何變換的魯棒性不強,因此研究人員設計了幾種方法來改良CNN對于幾何變換的魯棒性:
- 數據增強(Data Augmentation):這是最簡單也最常用的方法。通過對訓練集中的圖片進行隨機旋轉、縮放、平移或裁剪等操作,來增加數據的多樣性。這使得模型在訓練時能接觸到更多不同幾何形態的樣本,從而提高其泛化能力
- 多尺度或者多角度訓練:直接在多個尺度或角度下對同一圖像進行訓練,迫使網絡學習對這些變換不變的特征。
- 使用手工設計的特征(如SIFT、ORB等): 在傳統的計算機視覺任務中,人們會使用這些對幾何變換具有一定不變性的特征來處理問題。例如,SIFT特征描述子在一定程度上對尺度和旋轉是不變的。
之前的模型/方法有什么不足?
- 數據增強的局限性: 數據增強雖然有效,但它是一種“靜態”的、預先定義好的方法。它并不能讓網絡自適應地學習應該對哪些變換進行處理。換句話說,模型是在被動地接受經過變換的數據,而不是主動地去“尋找”并“矯正”那些重要的區域。
- 計算效率低下:多尺度或多角度訓練會顯著增加計算量和內存消耗,因為需要為每個變換后的版本都進行一次前向傳播。
- 無法處理復雜的、非預期的變換: 數據增強通常只覆蓋簡單的變換,如旋轉和平移。對于更復雜的、特定于任務的“扭曲”或“不規則”變換,效果不佳。
設計思路
這個模型針對不足提出了什么改進方案?解決了什么問題?有什么人類直覺在里面?
鑒于之前方法的缺陷,作者從人類直覺的角度進行了思考,他認為,人類之所以能夠從一個偏移,旋轉,或者不同視角下的圖片中還原原本的圖片(比如把一不同視角下的5,無論仰視還是俯視都可以看出來),是因為我們腦袋中 “自帶一個用來進行動態幾何變換的機制” (可以理解為自帶一個“自適應”的幾何變換矩陣),我們能根據注意力自動調整這個矩陣的參數,把圖像校正到我們大腦中最容易理解和識別的“理想狀態”。

以下是幾何變換矩陣的原理:

如果對變換矩陣施加如下約束,那么這個矩陣則可以對原圖進行旋轉,平移,以及仿射變換。

但是實際的代碼實現中并不會對其施加以上約束,因為模型可能通過學習學到更加高級的幾何變換,而不僅僅局限于以上三種變換。
達到效果及優勢

- 性能提升: 相比于其他沒有使用STN的模型(如 Cimpoi '15, Simon '15 等),使用了STN的CNN模型在CUB-200-2011鳥類分類數據集上的準確率有了明顯的提升。在高分辨率的圖片上性能提升更加顯著。
- 可解釋的空間變換注意力: 這是STN最直觀也最令人興奮的優勢。圖表右側的圖片展示了2xST-CNN和4xST-CNN模型中STN模塊學習到的空間變換。論文作者在圖中特別指出,對于2xST-CNN模型,一個STN模塊(紅色框)學習定位和放大鳥的頭部,而另一個STN模塊(綠色框)則學習定位和放大鳥的身體。也就是每個STN模塊都注意到了不同的,但是對鳥的分類至關重要東西!
- 即插即用的模塊:STN最大的優勢之一就是他能非常容易地插入任何現有的CNN,并且只需要很小的修改!
對后續模型的影響
-
開創“可學習的變換”思想
STN首次將空間變換的能力作為可學習的模塊集成到神經網絡中。它證明了網絡可以自己決定如何對輸入數據進行幾何變換,而不是依賴于預先設定好的規則(如數據增強)。 這種思想被廣泛應用于各種需要處理非剛性、非線性變換的任務中。例如,在醫學圖像處理中,STN的思想被用來進行圖像配準(Image Registration),自動對齊不同時間或不同設備拍攝的病灶圖像。 -
空間注意力機制的先驅
盡管STN的關注點是“幾何變換”,但它通過定位并變換最關鍵的區域,實際上實現了一種形式的注意力。它讓網絡將“注意力”集中在最關鍵的像素或特征上,并將其“擺正”以方便后續處理。它的成功啟發了后續的注意力機制(Attention Mechanism)研究。雖然STN是“空間注意力”,更嚴謹一定來說叫“空間幾何注意力”,但它證明了讓網絡“有選擇地”關注輸入中最重要的部分是提高性能的有效手段。這為后來更廣泛的通道注意力(Channel Attention)、自注意力(Self-Attention)以及Transformer模型的興起奠定了基礎。 -
“即插即用”模塊化設計的典范
STN模塊可以輕松地插入到任何CNN架構中,這極大地降低了其應用門檻,并展示了模塊化設計在深度學習中的巨大潛力。* 這種設計理念被廣泛采納。如今,許多深度學習模型都由各種可插拔的模塊組成,比如SENet中的“通道注意力”模塊、ECA-Net中的“高效通道注意力”模塊等等。這些模塊都遵循了STN的“即插即用”設計思想,讓研究人員可以更容易地進行模型改進和創新。
總而言之,STN的貢獻遠不止于提高了一點點準確率。它引入的 “可學習變換” 、 “空間注意力” 和 “模塊化設計” 等核心思想,深刻地影響了后續的計算機視覺和深度學習研究,成為連接傳統CNN和現代Transformer模型的一個重要橋梁。
網絡結構
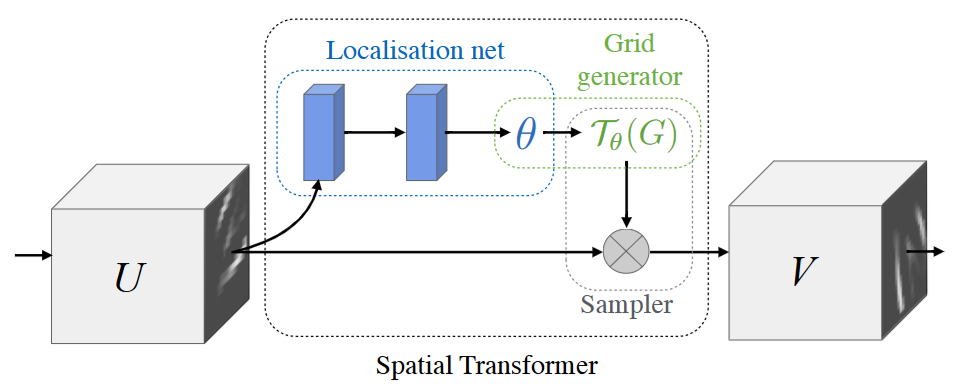
Spatial Transformer 模組可以分解成如下三個關鍵組成部分:
- 定位網絡(localisation net):其中包括兩個全連接層,第一個層負責提取圖片中的基礎幾何信息,第二個層負責根據基礎幾何信息回歸出幾何變換矩陣
- 網格生成器(grid generator): 負責根據生成的變換矩陣生成變換網格,本質上是定義了圖像的變換
- 采樣器(Sampler):利用定義好的grid對原圖片進行變換
Pytorch模型實現+MNIST數據集視角調整實驗
準備庫、數據集、數據加載器
首先我們把庫和數據集,以及數據加載器準備好:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as npplt.ion() # interactive modefrom six.moves import urllib
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
urllib.request.install_opener(opener)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# Training dataset
train_loader = torch.utils.data.DataLoader(datasets.MNIST(root='.', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])), batch_size=64, shuffle=True, num_workers=4)
# Test dataset
test_loader = torch.utils.data.DataLoader(datasets.MNIST(root='.', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])), batch_size=64, shuffle=True, num_workers=4)
定義網絡結構
接下來就是搭建我們帶有一個簡單Spatio Transformer 模塊的網絡了:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5) self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.conv2_drop = nn.Dropout2d()self.fc1 = nn.Linear(320, 50)# 修復:等號'='而不是'-'self.fc2 = nn.Linear(50, 10)self.flatten = nn.Flatten()# STN模塊組成-特征提取localization子網絡, 用來先提取能反應圖像幾何信息的高級特征# 修復:括號'()'而不是')'self.localization = nn.Sequential(nn.Conv2d(1, 8, kernel_size=7),nn.MaxPool2d(2, stride=2),nn.ReLU(True),nn.Conv2d(8, 10, kernel_size=5),nn.MaxPool2d(2, stride=2),nn.ReLU(True))# STN模塊組成-全連接定位網絡-回歸仿射矩陣self.fc_loc = nn.Sequential(nn.Linear(10 * 3 * 3, 32), nn.ReLU(True),# 直接把幾何變換矩陣全連接出來nn.Linear(32, 3 * 2))# 網絡權重初始化,保證一開始的變換矩陣從什么都不做的單位幀self.fc_loc[2].weight.data.zero_() # 定位網絡直接用0初始化權重self.fc_loc[2].bias.data.copy_(torch.tensor([1, 0, 0, 0, 1, 0], dtype=torch.float)) """[1, 0, 0][0, 1, 0]"""def stn(self, x):xs = self.localization(x)xs = self.flatten(xs)# 修復:xs_theta = self.fc_loc(xs)# 重塑成矩陣形狀theta = theta.view(-1, 2, 3)# 網格生成部分,對圖像引用幾何變換矩陣產生新圖像grid = F.affine_grid(theta, x.size(), align_corners=True)x = F.grid_sample(x, grid, align_corners=True)return xdef forward(self, x):x = self.stn(x)# 傳給分類層# Perform the usual forward passx = F.relu(F.max_pool2d(self.conv1(x), 2))x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))x = self.flatten(x)x = F.relu(self.fc1(x))x = F.dropout(x, training=self.training)x = self.fc2(x)return F.log_softmax(x, dim=1)# 冒煙測試
# 修復:缺失 device 的定義
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Net().to(device)
# 修復:缺失 .to(device)
input = torch.randn(1, 1, 28, 28).to(device)
output = model(input)
# 修復:輸出的維度是 [1, 10],所以應該使用 output.shape
print(output.shape) # 輸出torch.Size([1, 10])
定義訓練/測試過程
optimizer = optim.SGD(model.parameters(), lr=0.01)def train(epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % 500 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))
#
# A simple test procedure to measure the STN performances on MNIST.
#def test():with torch.no_grad():model.eval()test_loss = 0correct = 0for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)# sum up batch losstest_loss += F.nll_loss(output, target, size_average=False).item()# get the index of the max log-probabilitypred = output.max(1, keepdim=True)[1]correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))
可視化效果
我們這里直接可視化原圖像在經過空間注意力模塊調整之后會變成啥樣:
def convert_image_np(inp):"""Convert a Tensor to numpy image."""inp = inp.numpy().transpose((1, 2, 0))mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])inp = std * inp + meaninp = np.clip(inp, 0, 1)return inp# We want to visualize the output of the spatial transformers layer
# after the training, we visualize a batch of input images and
# the corresponding transformed batch using STN.def visualize_stn():with torch.no_grad():# Get a batch of training datadata = next(iter(test_loader))[0].to(device)input_tensor = data.cpu()transformed_input_tensor = model.stn(data).cpu()in_grid = convert_image_np(torchvision.utils.make_grid(input_tensor))out_grid = convert_image_np(torchvision.utils.make_grid(transformed_input_tensor))# Plot the results side-by-sidef, axarr = plt.subplots(1, 2)axarr[0].imshow(in_grid)axarr[0].set_title('Dataset Images')axarr[1].imshow(out_grid)axarr[1].set_title('Transformed Images')for epoch in range(1, 20 + 1):train(epoch)test()# Visualize the STN transformation on some input batch
visualize_stn()plt.ioff()
plt.show()

最終的準確率在epoch20之后達到了99%,并且可以看到STN模塊確實對原圖進行了幾何變換,把圖像校正到了對模型,甚至對人類都更容易理解和識別的“理想狀態”。




)


 緩存增強生成(CAG) 生成中檢索(RICHES) 知識庫增強語言模型(KBLAM))
的工作原理 圖文講解)





)


的討論)

