“團隊要上線一個智能客服系統,預算有限,中文場景為主,偶爾需要讀圖——該選豆包1.5還是GPT-5-min?”
“個人開發者想接大模型API做寫作助手,要求響應快、成本低,Claude Haiku、Moonshot、GPT-5-min 哪個更劃算?”
這些具體到價格、語言、場景的選型問題,靠廠商宣傳稿或碎片化評測根本無法回答。當技術決策者面對數十個參數各異的大模型時,真正的痛點不是“不知道”,而是“如何快速找到符合業務需求且成本可控的那一個”。
AIBase 模型對比平臺(國內外AI大模型價格對比評測平臺_國內外LLM API成本排行榜_AIbase)?正是為此而生——不做學術參數堆砌,只做真實場景下的決策羅盤。
一、為什么你需要“真實場景對比”而非參數表?
大模型選型絕非“跑分高=好用”。忽略以下因素,輕則預算超支,重則項目受阻:
中文理解深度:英文模型在中文場景可能水土不服
長文本溢價規則:某些模型低量便宜,長文本卻價格飆升
圖像推理成本:按Token計費還是按張計費?差別巨大
響應速度:實時交互場景,延遲直接影響體驗
生態適配:是否需要額外部署?是否支持API流式輸出?
而AIBase模型對比平臺的核心價值,是把抽象參數轉化為可行動的決策依據。
二、真實案例
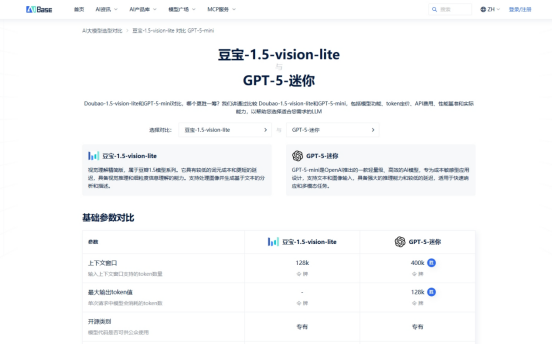
豆包1.5 Vision Lite vs GPT-5-min,誰更勝一籌?
假設你正在為一個電商客服中臺選型,需求明確:
? 強中文支持 ? 多模態(能讀商品圖) ? 高性價比 ? 穩定API接入
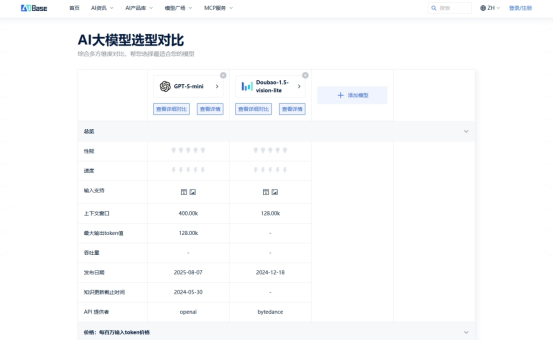
在AIBase平臺只需三步:
篩選條件:勾選“中文”、“多模態”、“支持API”
加入對比:選擇「豆包1.5 Vision Lite」和「GPT-5-min」
關鍵維度:聚焦下表紅框指標

結論清晰浮現:
若業務以中文圖文交互為核心,豆包1.5在成本、語言適配、長文本處理上優勢顯著;
若需求是輕量英文文本生成,GPT-5-min的全球化部署更具普適性。
三、這才是AIBase對比平臺的正確打開方式
1.?拒絕參數轟炸,只比關鍵指標
隱藏晦澀的學術指標(如MMLU分數),突出價格、語言支持、上下文長度、API速率、多模態成本等業務級參數
支持按場景篩選:勾選“中文優化”、“開源可商用”、“低延遲”、“圖像/音頻支持”等標簽,瞬間過濾噪音
2.?成本算得清,拒絕隱藏坑
直接標注每百萬Token輸入/輸出價格(如:Moonshot輸入¥0.5/百萬Token)
揭露長文本溢價規則(如:GPT-5-min超過5000字符單價上升30%)
明示多模態附加費(如:Gemini Vision圖文混合請求按總Token計費)
3.?一鍵導出對比表,團隊決策有依據
選擇3-5個候選模型,生成PDF對比報告,含官網鏈接與測試時間戳
分享鏈接給技術伙伴,同步查看實時數據(例:豆包1.5 vs GPT-5-min vs Claude 3 Haiku對比頁)
四、誰正在用這個工具省下數百小時?
技術總監:快速篩選符合預算的API方案,輸出對比報告說服管理層
產品經理:根據“對話式AI”場景過濾模型,找到支持長上下文且低延遲的選項
個人開發者:按“免費額度”排序,發現新上線的Llama 3 400B API仍提供500萬Token試用
企業采購:驗證廠商報價是否合理,避免為品牌溢價買單
五、讓模型選型回歸業務本質
在AIBase模型對比平臺,沒有“最好”的模型,只有“最適合你當前需求”?的選項。
要低成本處理中文長文檔?看豆包、Kimi、DeepSeek的“上下文性價比”排序
需高精度圖像分析?對比GPT-4V、Gemini 1.5 Pro、Claude 3 Opus的多模態細項
求極速響應?按“API延遲”篩選,發現Moonshot、Claude Haiku等黑馬
告別在廠商文檔中反復切換,告別為隱藏成本交學費。
訪問 →?AIBase 模型對比平臺AIbase基地 - 讓更多人看到未來 通往AGI之路
用10分鐘對比,省下100小時試錯——讓每一分算力預算都花在刀刃上。

![[Oracle數據庫] Oracle 常用函數](http://pic.xiahunao.cn/[Oracle數據庫] Oracle 常用函數)
講解+架構搭建(可直接copy運行)+ MNIST數據集視角調整實驗)




)


 緩存增強生成(CAG) 生成中檢索(RICHES) 知識庫增強語言模型(KBLAM))
的工作原理 圖文講解)





)

