一.BEVFusion
1.簡要介紹
BEV是一個俯視空間,Fusion做的就是融合,這里指的就是圖像和點云的融合。那如何把圖像和點云融合在一起?認為融合方法有三種:
- a.point level fusion:點集的融合,從點云中采樣一些點,再根據相機的內外參講這些點投影到圖像上,采樣出圖像特征,然后再拼接到點位上,利用這個融合后的特征去做3D目標檢測
- b.feature?level:將兩種模態的中間特征通過內外參矩陣拼接投影,融合出完整特征去做的。具體啦說就是,對于輸入點云,通過點云網絡得到初始位置,初始位置去圖像上采樣特征,這是一個從點云到圖像的過程,采樣玩特征之后,再拿回到原始的點云空間中,拼接到原始的特征之上(藍色部分是從圖像上采樣過來的特征,橙色部分是原始的初始點云特征),兩種類型特征拼接到一起,去做3D檢測任務
從流程上來看,a和b的方式都離不開一個映射的過程,也就是利用相機內外參,將3D點換算到2D圖像上。但是如果外參計算不好,這也許會導致最終出現問題,同時,如何采樣出來的點對應到圖像上的特定像素,這個像素是模糊的,這都會導致最終效果不好。
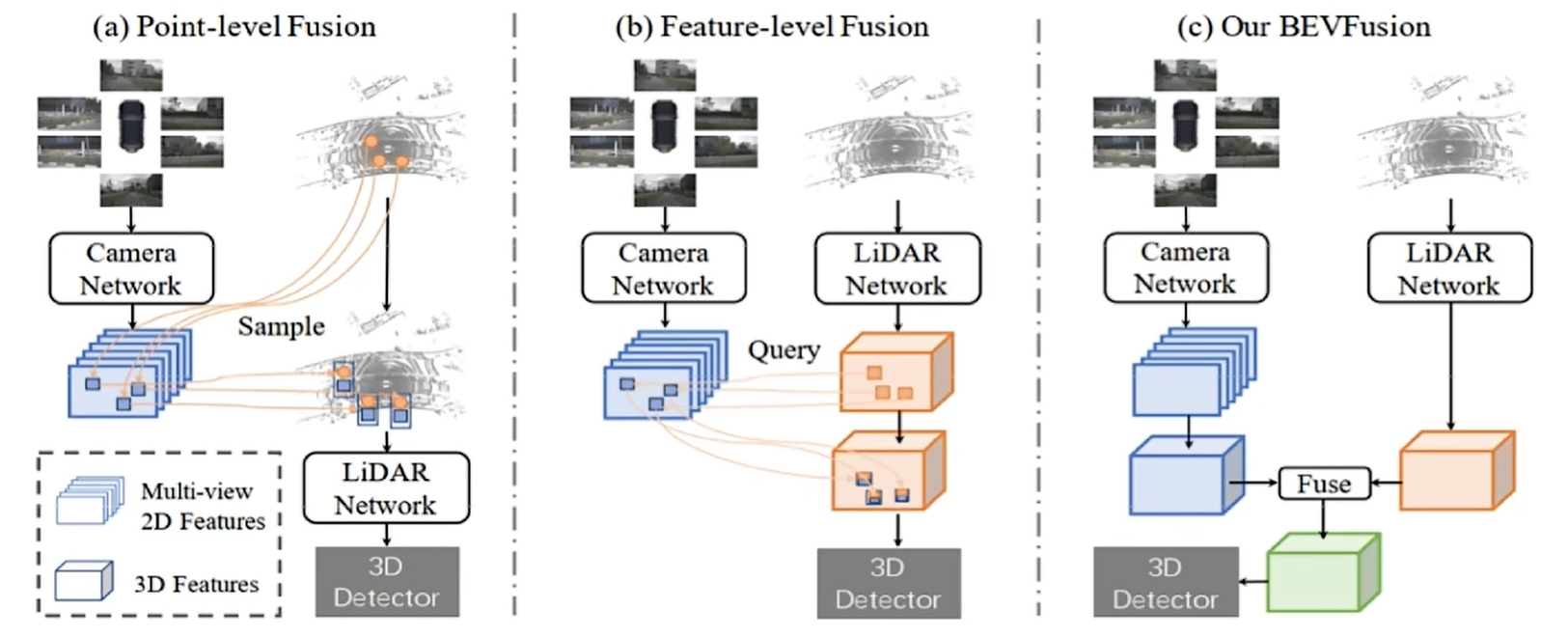
因此,以前的方式,無論是a還是b,都存在一個主次依賴的關系,都從點云出發,但如果點云不準、外參不準,那么后續的檢測也就不會準。因此BEVFusion就希望盡可能降低這個主次依賴關系,對點云和圖像做一個分別處理,然后再在BEV空間去做融合,
2.主體結構
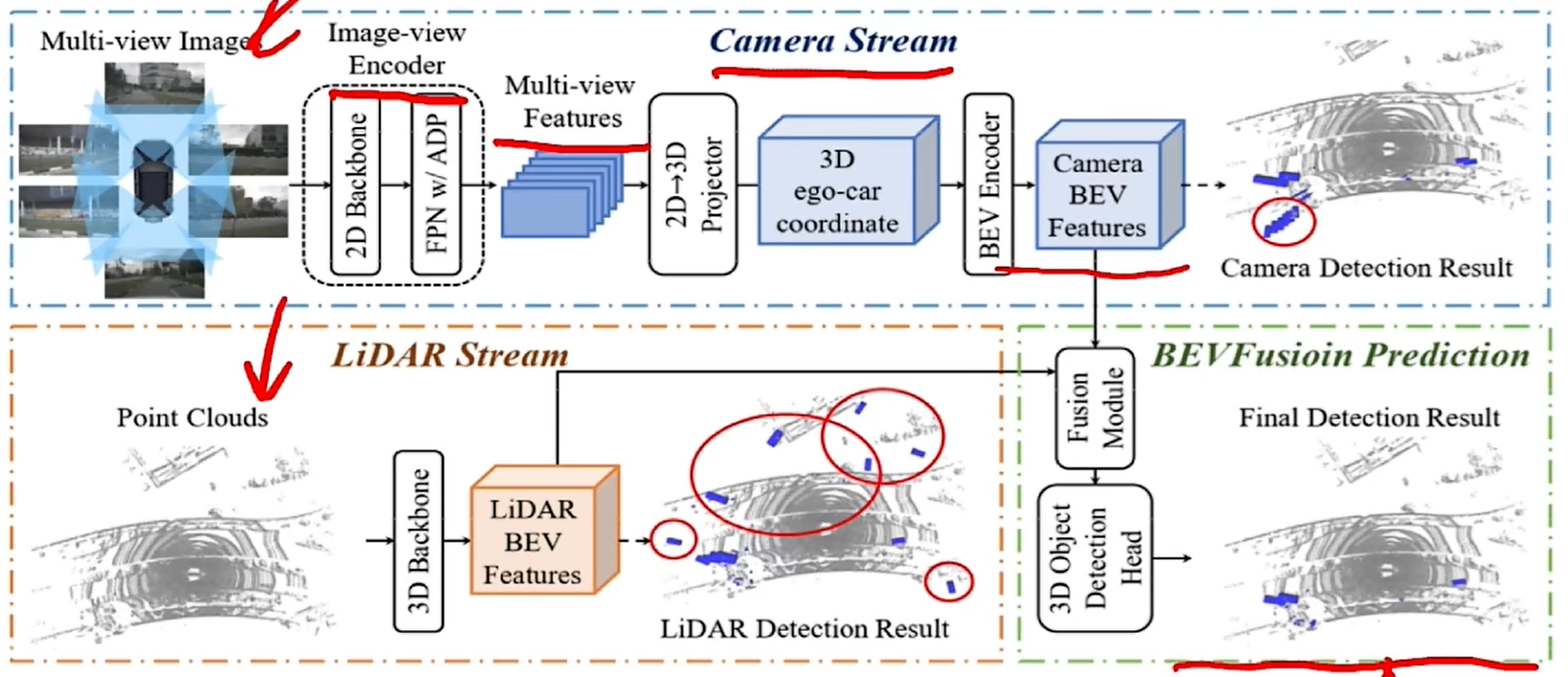
圖像經過編碼器得到圖像特征,再通過一個轉換器將2D變換到3D,再投影到BEV空間上,就得到了圖像特征在BEV空間上的表征(Camera BEV Features)。而雷達點云通過一個3D Backbone 得到點云的BEV特征。接下來就需要去做融合了(Fusion Model),利用得到的混合特征去做預測。
Camera Stream

圖像流的輸入是多視角圖像,相同一個2D Backbone提取基礎的圖像特征,再經過FPN+ADP模塊(ADP模塊包括上采樣、池化、卷積)對多尺度特征做一個融合,得到多尺度圖像特征;再通過一個2D->3D轉換模塊做一個轉換,這個轉換的過程其實就是對每一個像素位置做一個 深度分布的預測,會預測一系列的離散的深度概率,這個概率會作為一個權重去乘上像素的圖像特征,然后每個像素點按照射線去進行特征投影,組成了所謂的3D空間;然后再投影,就可以得到Camera BEV Features了。
Lidar Stream
雷達流的輸入是3D雷達點云,經過一個3D Backobone提取點云特征,這里主要使用Point pillar進行點云特征提取,由于點云本身就是3D的,所以只需要做投影或者直接拍扁,就可以將其轉換到BEV空間了。
Fusion Model
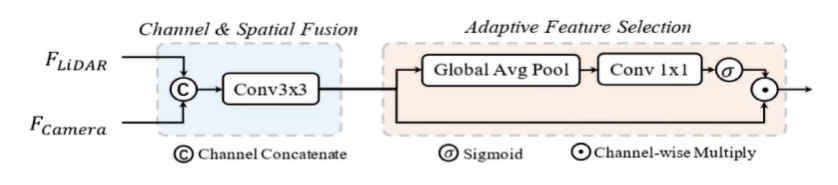
融合模塊輸入前面兩個得到的BEV空間的圖像特征和點云特征,接著按通道級聯點云和圖像BEV特征,再通過卷積網絡提取級聯后的特征,之后引入一個Adaptive Feature Selection模塊,這其實一種通道注意力,去對通道維度進行了加權,考慮的是哪個通道更重要,是點云上的通道呢還是圖象上的通道呢,通過這樣一個權重的預測,對通道維度進行一個重新的加權;之后就得到了一個融合后的特征,自然也就可以用來做預測。
二.BEVFusio4D
三.BEVFormer
1.簡要介紹
BEV是一個俯視空間,Former做的就是Transformer,這里指的就是使用transformer去做BEV的圖像處理,完成后續檢測目標。
2.主體結構
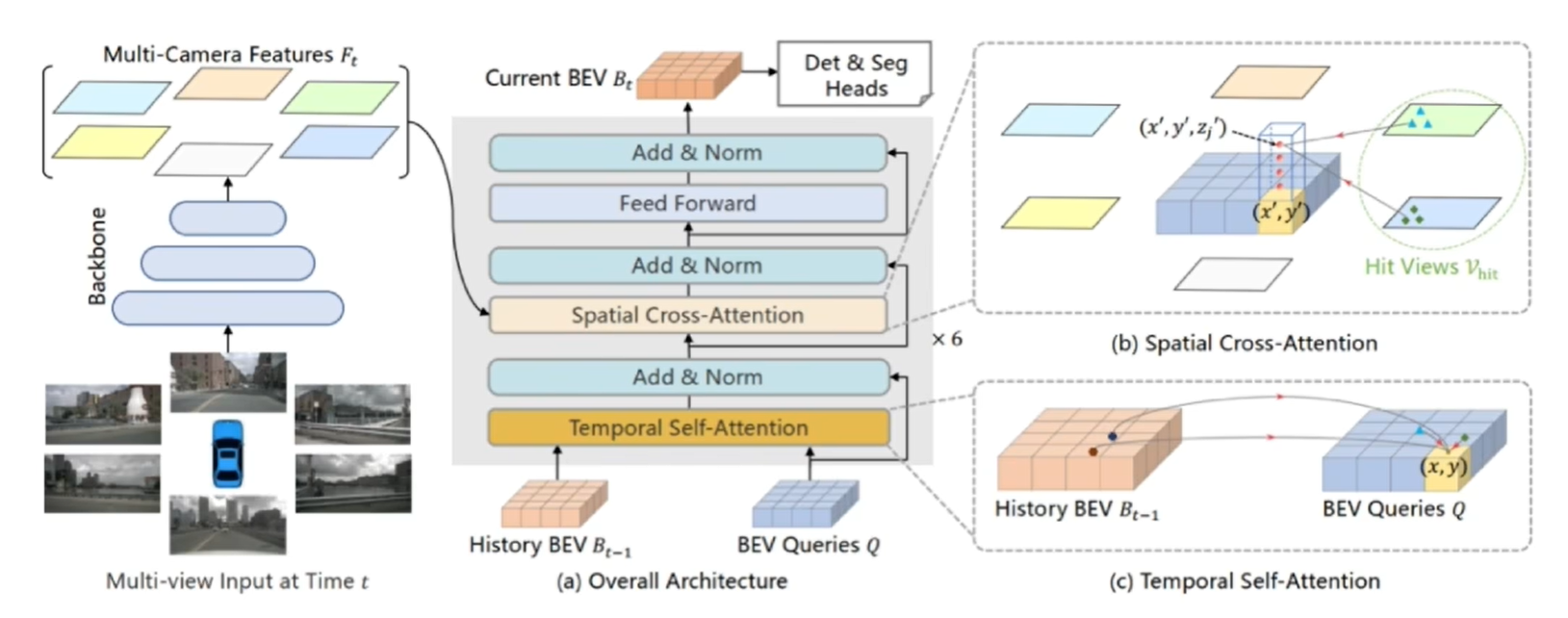
首先,輸入的圖像經過Backbone得到圖像特征,將圖像特征、History BEV、BEV Queries一起輸入到一個結構當中,會得到Current BEV,就可以作為檢測頭的輸入完成后續的檢測分割任務。
Temporal Self-attention
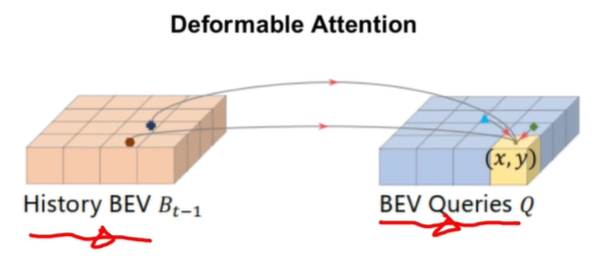
時序注意力是考慮到前一幀和當前幀的一個關聯,那如何將前一幀的特征引入到當前幀的EBV空間中呢。這里使用的就是一個Deformable Attention,History BEV可以自適應選擇哪一個BEV Queries對當前點是有增益的。有了History BEV的引導之后,BEV Queries查詢的先驗也就會更好。后續,再結合當前提取到的空間特征和已經有很強的BEV先驗的Queries,就可以生成更好的BEV Feature。
Spatial Attention
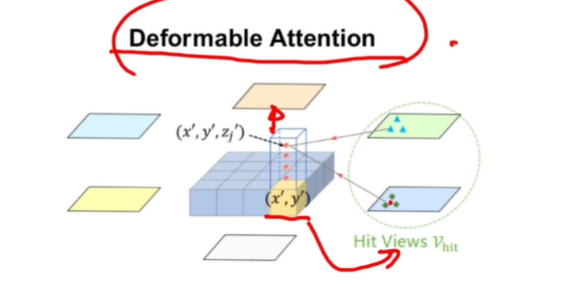
那已經有了提取好的multi-camera feature之后,怎么樣生成想要的當前的BEV feature呢。使用空間注意力,利用BEV Queries對multi-camera feature做一個查詢,去問一問“你有我這個位置的特征嗎”;具體就是將XY先映射到他這個視角下所對應的位置上,通過去找這個位置臨近的相鄰點的一個特征,去進行一個融合,然后生成他當前視角下需要被融合的特征。后續他把這個多視角全都查詢完之后,會生成X'Y'位置上通過multi-camera feature融合好的特征
四.PETR
從名字可以知道,主要就是Position Emebedding Transformer。那么核心設計思路就是位置編碼(position emebedding)的設計上。
DETR3D
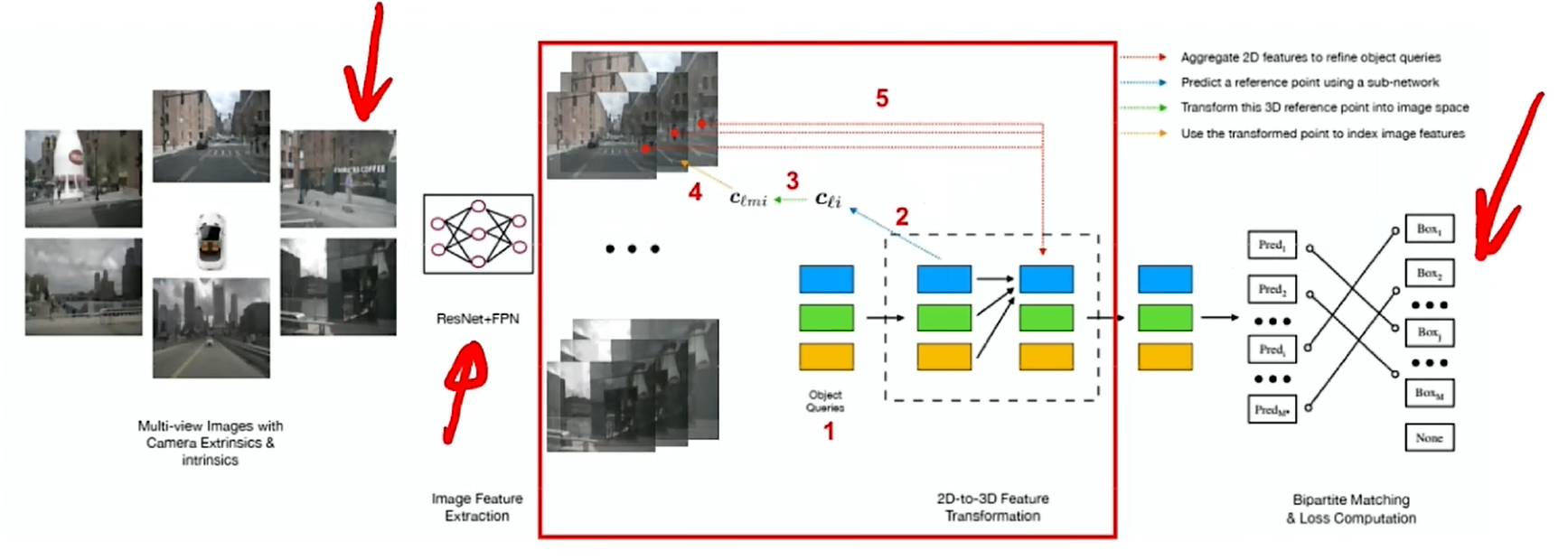
PETR是一個根據DETR3D改進的一個工作,因此先回顧一下DETR3D。對于輸入的多視角圖像,采用ResNet+FPN來提取圖像特征,得到多尺度圖像融合特征;再初始化一系列的Object query,query的主要作用就是隨機初始化一些查詢向量,用于查詢空間中哪里有物體,query通過transformer結構來預測生成3D reference point,有了參考點之后就可以根據相機內外參,將參考點逆投影回圖像空間,找到參考點在圖象上的位置,進而找到該像素位置對應的特征。通過3種尺度的融合,得到最終的圖像特征,進而可以進行預測;而這個過程其實是一個迭代預測的過程,是多次refine的過程,可以不斷地得到新的object query,不斷地更新預測。DETR3D通過這樣一個過程去做3D目標檢測任務。
PETR
動機
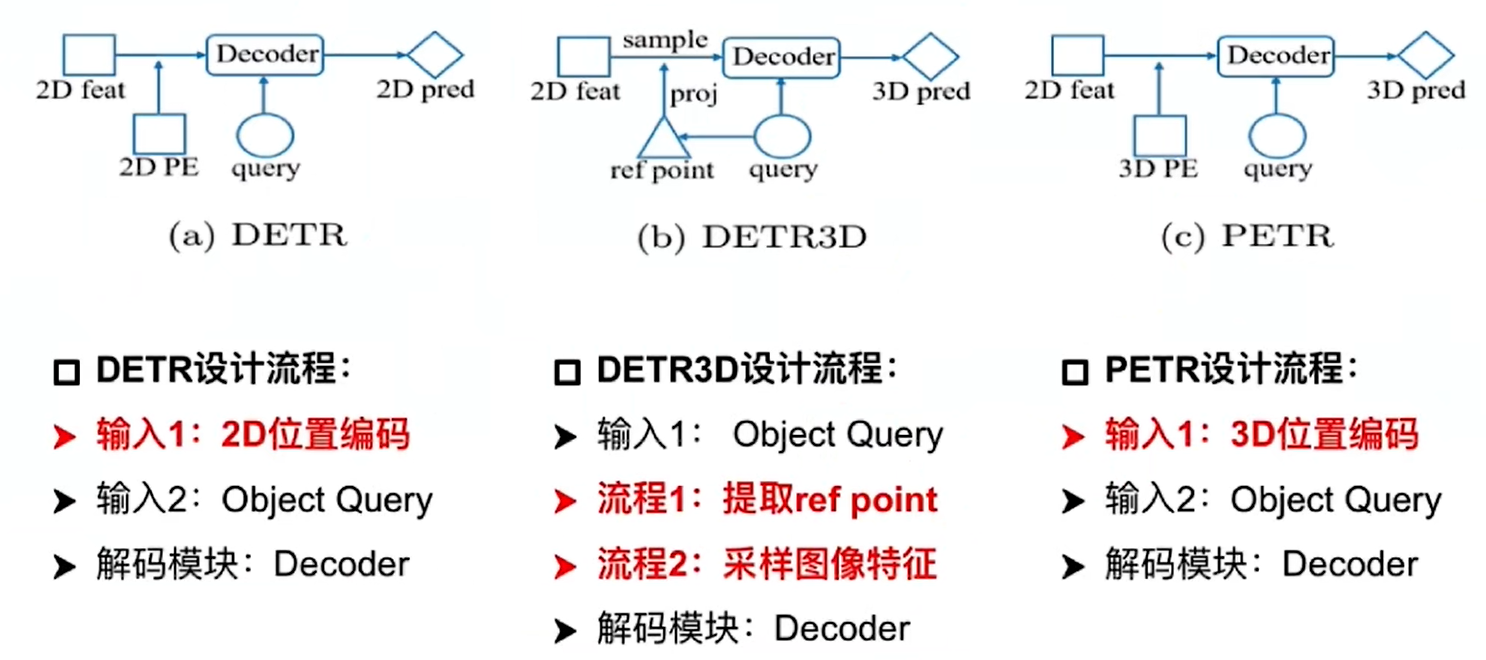
PETR認為DETR3D中的利用3D參考點來索引圖像特征是不合理的,因為如果參考點位置出錯了,那么圖像特征也就錯了,從而導致采樣到的圖像特征是無效的,同時認為,如果只采用參考點的投影位置得到圖像特征來更新query是不夠充分的,可能導致模型對于全局特征學習的不夠充分。
因此PETR使用3D PE(position emebedding)將多視角的2D圖像特征轉化為3D感知特征,也就是將2D feature和3D PE結合得到3D感知特征,這也使得query可以在3D語義環境下進行更新,從而省略了來回投影的過程,簡化了DETR3D的流程。
主體結構
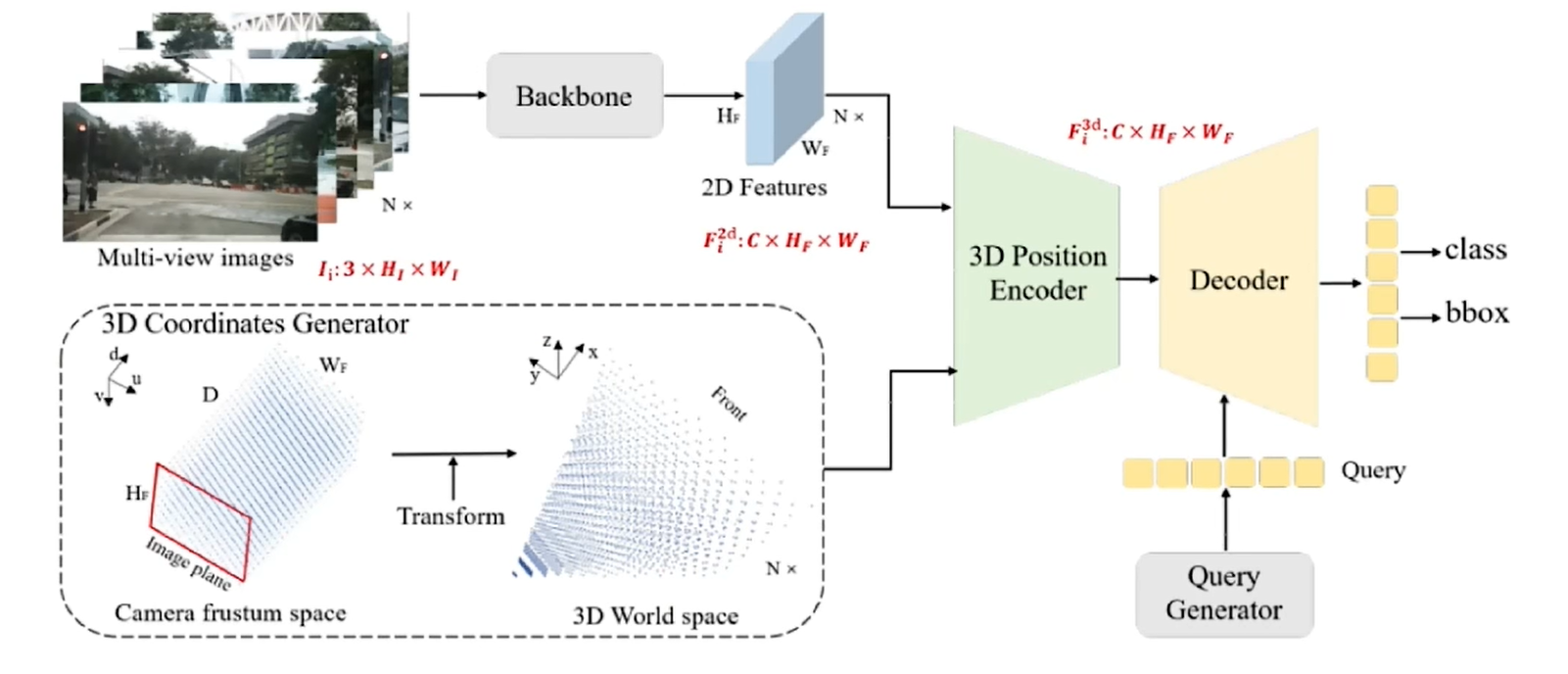
對于輸入的多視角圖像,經過Backbone可以得到圖像特征,同時3D坐標生成器(3D Coordinates Generator)經過一系列的坐標變換將圖像坐標轉化為3D空間中的坐標,然后2D圖像特征和3D位置坐標同時送到3D位置編碼(3D Position Encoder),將3D位置信息融入到2D特征里面,生成一系列的object query,與得到的特征一起去得到預測結果。
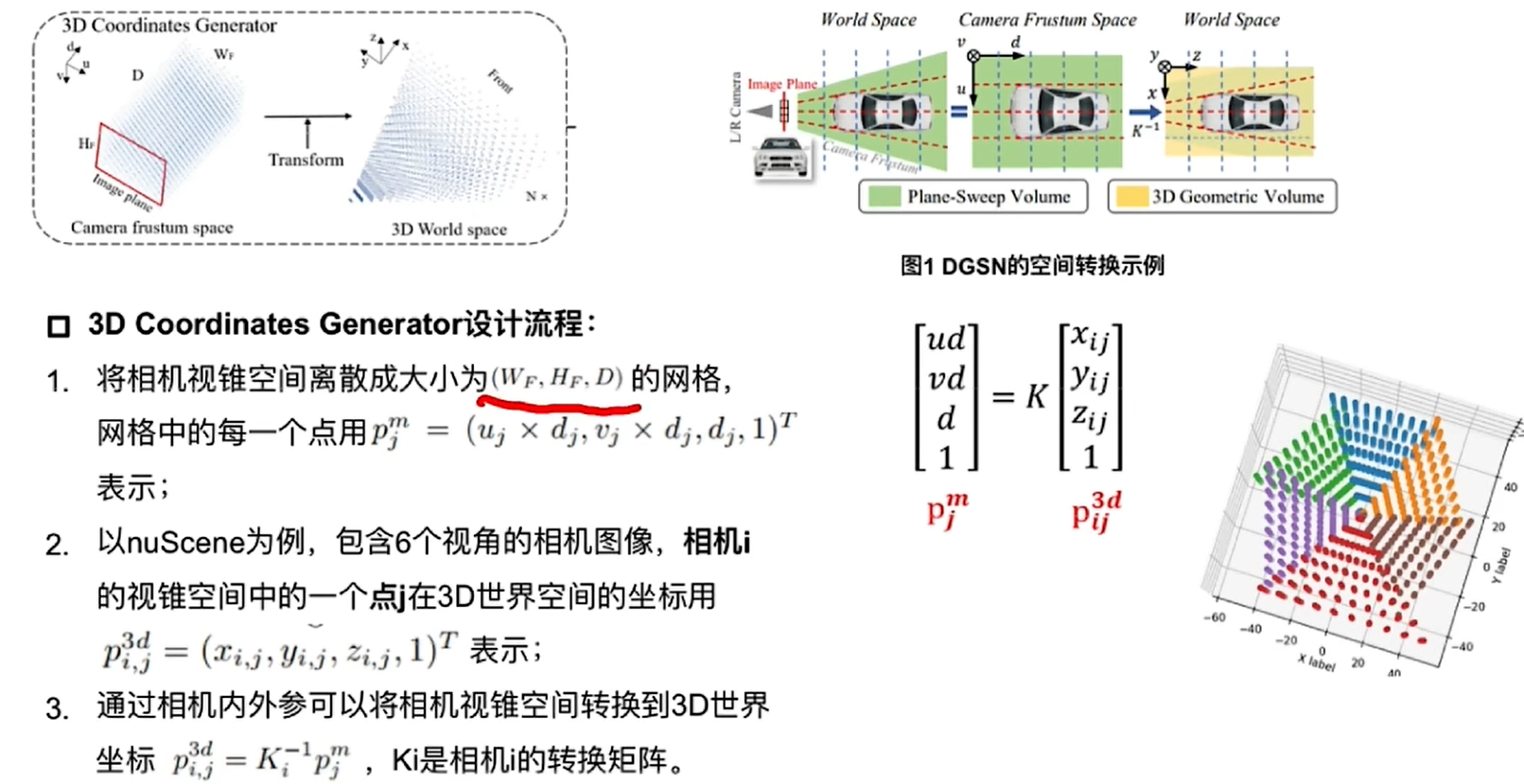
3D Coordinates Generator:
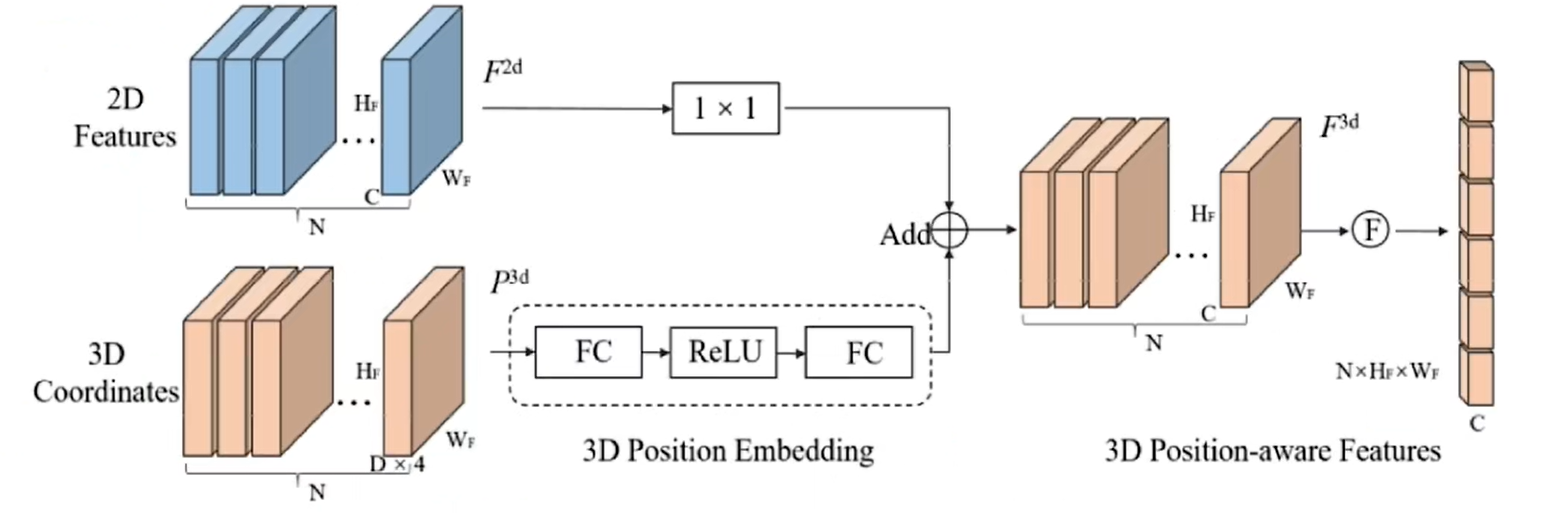
3D Position Encoder:






)


)


——右值引用和移動語義)






