摘要
圖像分割模型的性能歷來受到大規模標注數據收集成本高昂的制約。Segment Anything Model(SAM)通過一種可提示、與語義無關的分割范式緩解了這一根本問題,但在處理新圖像時,仍然需要手動提供視覺提示或依賴復雜的領域相關提示生成規則。為減輕這一新負擔,我們的工作研究了一種在僅提供少量參考圖像條件下的物體分割任務。我們的關鍵洞見是:利用基礎模型所學習的強大語義先驗,在參考圖像與目標圖像之間識別對應區域。我們發現,這種對應關系能夠自動生成下游任務所需的實例級分割掩碼,并通過一個多階段、無需訓練的方法來實現,包含以下三個步驟:(1)構建記憶庫;(2)表征聚合;(3)語義感知特征匹配。實驗結果表明,我們的方法在分割指標上實現了顯著提升——在 COCO FSOD 基準上達到 36.8% nAP,在 PASCAL VOC 少樣本分割上達到 71.2% nAP50,并且在跨域少樣本分割基準上以 22.4% nAP 超越了現有所有無需訓練的方法。
網站: https://miquel-espinosa.github.io/no-time-to-train
引言
眾所周知,為分割任務收集大規模標注數據既昂貴又耗時[2, 17, 57]。近年來,以可提示分割框架為代表的研究進展[29, 44, 56, 73, 74, 89]——尤其是 Segment Anything Model(SAM)[33, 61]——通過使用點、框或粗略素描等簡單幾何提示,實現了高質量的掩碼生成,大幅減少了人工工作量。盡管這在降低人工成本方面取得了重要進展,但這些掩碼缺乏語義意識[9, 21, 27, 64],且要實現自動化處理,仍需手動干預或構建復雜的、領域特定的提示生成流程(例如在醫學影像[37, 48, 83, 84]、農業[5, 69]、遙感[49, 55, 70]等場景中)。依賴對每張圖像的手動提示限制了方法的可擴展性(尤其是針對大型數據集或需要自動化處理的場景),而依賴領域受限的自動化流程又限制了跨領域場景的泛化能力。
基于參考圖像的實例分割[15, 19, 53]通過利用少量帶注釋的參考圖像來指導大量目標圖像的分割,為這一難題提供了有前景的解決方案。該思路有望為那些標注成本高、耗時長且需要專業知識的數據集提供廉價、快速且自動化的標注方式[2, 57]。與緩慢的手動提示[24]不同,使用參考圖像可以直接從示例中獲取語義理解,因此非常適合自動化分割任務。盡管已有方法取得了一定進展,我們發現現有的基于參考圖像的分割方法通常需要對新類別進行微調,這會帶來諸多已知問題,包括任務特定的數據需求、過擬合和域偏移。我們推測,一種可行的替代思路是復用視覺基礎模型[4, 33, 54, 60, 61]的通用能力,以指導基于參考的實例分割。
已有若干工作[46, 67, 74]嘗試將預訓練模型用于參考分割,例如 Matcher[46] 將 DINOv2 與 SAM 結合用于語義分割任務。然而,這些方法面臨若干限制:首先,它們依賴計算代價高昂的距離度量(如地球移動距離)和復雜的閾值機制,顯著降低了推理速度;其次,它們并不適合實例級分割任務,在復雜多目標場景中難以實現細粒度區分。實際上,實例分割設置提出了獨特挑戰——如何僅憑少量參考圖像應對遮擋、尺度變化、邊界模糊及圖像質量差異等問題——這些都需要精心設計。如何在不進行大量微調的情況下,有效地結合基礎模型,仍然是一個重大挑戰[9],尤其是在嘗試利用語義 ViT 主干(如 DINOv2)的泛化能力來實現精確定位時[82]。
為此,我們提出了一種無需訓練的三階段方法:(1)構建類別專屬特征記憶庫;(2)通過兩步聚合優化特征表征;(3)基于特征匹配和新穎的語義感知軟合并策略進行推理。該方法形成了一個高性能的、無需訓練的框架,在多個基準數據集上實現了顯著性能提升。此外,我們的方法在跨領域場景下也表現出色,僅需固定的超參數設置,因而易于在各種應用中推廣。
我們的主要貢獻如下:
提出了一種無需訓練的方法,有效地將語義無關的分割掩碼候選與細粒度語義融合,用于基于參考的實例分割。
引入了一個針對視覺基礎模型的實例分割新穎三階段框架,通過(1)記憶庫構建、(2)兩步特征聚合和(3)帶語義感知的軟合并特征匹配,解決了關鍵的集成難題。
我們的方法在 COCO-FSOD、PASCAL-FSOD 和 CD-FSOD 基準上實現了最先進的性能,證明了其在多樣化數據集和固定超參數設置下的強大泛化能力,無需中間微調。
相關工作
基于參考的實例分割 旨在對圖像中的單個物體進行分割,區分同一類別的不同實例[6, 39]。傳統方法如 Mask R-CNN[22],使用卷積網絡對候選區域進行掩碼預測;而基于 Transformer 的模型如 DETR[3] 和 Mask2Former[7] 則通過自注意力機制整合全局上下文。這些方法通過利用大規模標注數據集在標準實例分割任務上取得了成功[17, 42]。基于參考的實例分割將此任務擴展到有限標注樣本的新類別上。早期工作[15, 53]通過引入實例級判別特征[15]或不確定性引導的邊界框預測[53]對 Mask R-CNN 進行改造。近期研究將分割任務統一到 in-context 學習框架下[29, 73, 74],需要在廣泛的分割任務(包括實例分割[73, 74])上進行昂貴的預訓練,并使用對比學習預訓練來整合視覺與文本提示[29]。盡管取得了進展,基于參考的實例分割仍面臨諸多挑戰:標注數據匱乏、多實例場景復雜、專門模型跨域泛化能力有限、參考圖像歧義以及對預定義類別標簽的依賴[79]。此外,如何重用預訓練時并非針對實例分割設計的凍結主干網絡,仍然是一個難題[9, 82]。我們的方法有效地復用了兩個現有的凍結視覺基礎模型——它們均未在參考實例分割任務上進行額外訓練——以無需額外訓練的方式解決基于參考的實例分割,同時在非典型領域也表現出良好泛化。
視覺基礎模型 通過學習可遷移到多種任務的強大預訓練表征,已經革新了計算機視覺領域。CLIP[60] 與 DINO 系列模型[4, 54]就是這一趨勢的典型代表,前者通過對比學習對齊視覺與文本表示,后者則從無標簽數據中學習魯棒圖像嵌入。這些模型廣泛應用于下游任務,包括開放詞匯檢測[21, 64]和語義分割[62, 88]。然而,CLIP 在細粒度空間推理方面表現有限,而 DINOv2 雖能捕捉豐富語義,卻產生低分辨率特征圖。Segment Anything Model(SAM、SAM2)[33, 61] 是該類別的另一個重要補充,基于大規模類別無關數據集(SA-1B)進行訓練[33]。SAM 在使用最少輸入(如點、邊框)生成分割掩碼方面表現出色,但缺乏固有的語義理解[9, 21, 27, 64]。已有嘗試將 SAM 與語言模型[34]、擴散模型[87] 配對,或在 COCO[42]、ADE20K[38] 等帶標簽數據集上進行微調,但這些方案往往導致流程復雜或可擴展性受限。此外,SAM 的語義無關特性在需要實例級類別區分的場景下存在局限。我們的工作在不進行微調的前提下,結合了 DINOv2 與 SAM 的互補優勢,通過多參考圖片的特征聚合與匹配,實現了高精度的無需訓練實例分割,并在多種少樣本基準上取得了最先進的結果。
SAM 的自動視覺提示 研究旨在構建自動化提示流水線,提升 SAM 在復雜視覺任務中的通用性,減少對人工輸入的依賴。無需訓練的方法[46, 81]利用特征匹配技術,但常依賴人工調優的閾值、距離度量和復雜流程;其他方法則聚焦于直接學習提示,如空間或語義優化[26, 28, 67],但在多實例或語義密集場景中仍面臨挑戰。零樣本方法[65, 78]通過引入視覺標記來引導分割注意力,卻缺乏細粒度精度。最新工作如 SEEM[89] 通過共享解碼器統一分割與識別任務,SINE[45] 則通過任務解耦來應對分割歧義;也有人將 SAM 與 Stable Diffusion 配合,用于開放詞匯分割[87],或利用語言指令驅動的 LISA[34] 來適配文本引導任務。但在無需訓練的前提下處理多實例場景與語義歧義依然困難。我們的方法區別于現有工作,不進行任何微調或提示優化,將 SAM 與 DINOv2 直接集成,通過記憶庫構建、表征聚合與語義感知軟合并三階段流程,以固定超參數設置在各實驗場景中保持一致,可廣泛應用于各類下游任務,并對從業者友好可用。
方法
3.1 預備知識
Segment Anything Model (SAM) [33] 是一種可提示分割模型,可響應不同類型的幾何提示來生成圖像分割掩碼。它由三部分組成:圖像編碼器、提示編碼器和掩碼解碼器。圖像編碼器是一種預訓練的 Vision Transformer(ViT)[8],針對高分辨率輸入進行了適配[40];提示編碼器則處理稀疏提示(點、框、文字)和稠密提示(粗略掩碼),通過位置注意力和對提示的交叉注意力進行編碼;掩碼解碼器使用修改后的 Transformer 解碼器塊,通過自注意力和對提示的交叉注意力來高效生成掩碼。在訓練階段,SAM 同時采用 focal loss[43] 和 dice loss[50] 作為優化目標。
DINOv2 自監督預訓練視覺編碼器[54],旨在生成通用視覺特征。它基于 ViT 架構[8],采用判別式自監督學習方法,使用師生網絡、Sinkhorn–Knopp 歸一化、多裁剪策略,以及分別用于圖像級和Patch級目標的不同投影頭,并引入多種正則化技術以穩定和擴展訓練過程[4, 85]。DINOv2 在 LVD142M 數據集(1.42 億張圖像)上訓練,使用快速節省內存的注意力機制和隨機深度等高效訓練技術。其特征在多種任務和領域間具有良好可遷移性,是全局與局部視覺理解任務的穩健主干網絡。

3.2 無需訓練的方法
我們的無需訓練方法旨在從一組帶標注的參考樣本中提取類別特征,并利用這些特征對目標圖像中的實例進行分割和分類。與需要重新訓練模型的方法不同,我們采用基于記憶庫的思路來存儲各類別的判別性表征。該方法包含三大步驟:(1)記憶庫構建;(2)兩階段特征聚合;(3)基于特征匹配與語義感知軟合并的推理。圖 2 展示了整體流程。
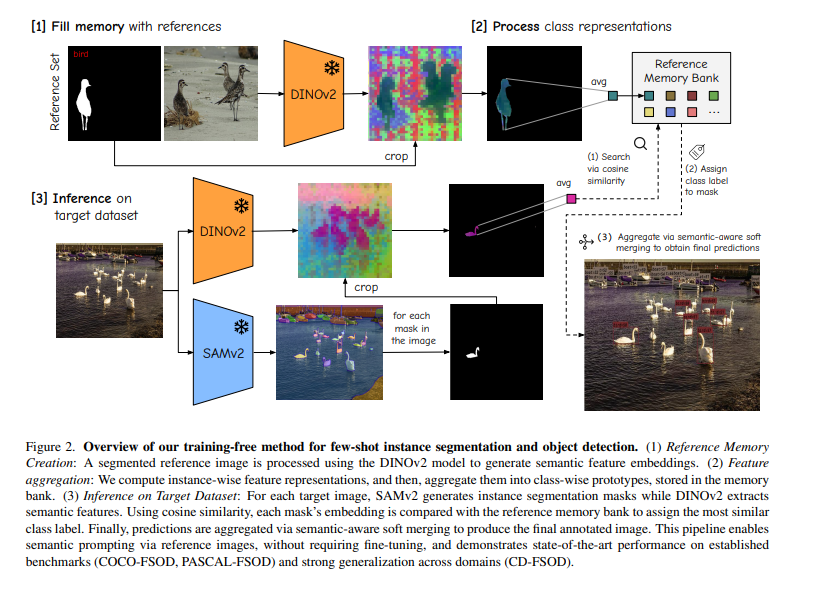
圖 2. 我們的無需訓練的少樣本實例分割與目標檢測方法概覽。
(1) 參考記憶構建:對已分割的參考圖像使用 DINOv2 模型提取語義特征嵌入。
(2) 特征聚合:首先計算每個實例的特征表征,然后將它們聚合成類別級原型并存入記憶庫。
(1)通過余弦相似度進行搜索
(2)為掩碼分配類別標簽
(3)通過具有語義感知能力的軟合并方式將各項結果匯總,從而得出最終的預測結果。
(3) 目標數據集推理:對于每張目標圖像,SAMv2 生成實例分割掩碼,DINOv2 提取語義特征。通過余弦相似度,將每個掩碼的特征與參考記憶庫中的原型進行比較,以分配最相似的類別標簽。最后,采用語義感知軟合并策略對預測結果進行聚合,生成最終標注圖像。
該流程通過參考圖像實現語義提示,無需微調,在多個基準(COCO-FSOD、PASCAL-FSOD)上達到了最先進的性能,并在跨域場景(CD-FSOD)中展現了強大的泛化能力。
1、記憶庫構建

r代表參考圖像
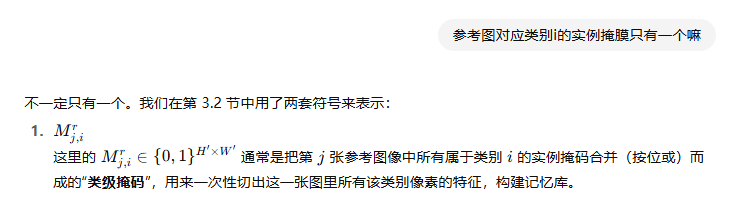


2、兩階段特征聚合

3、目標圖像推理


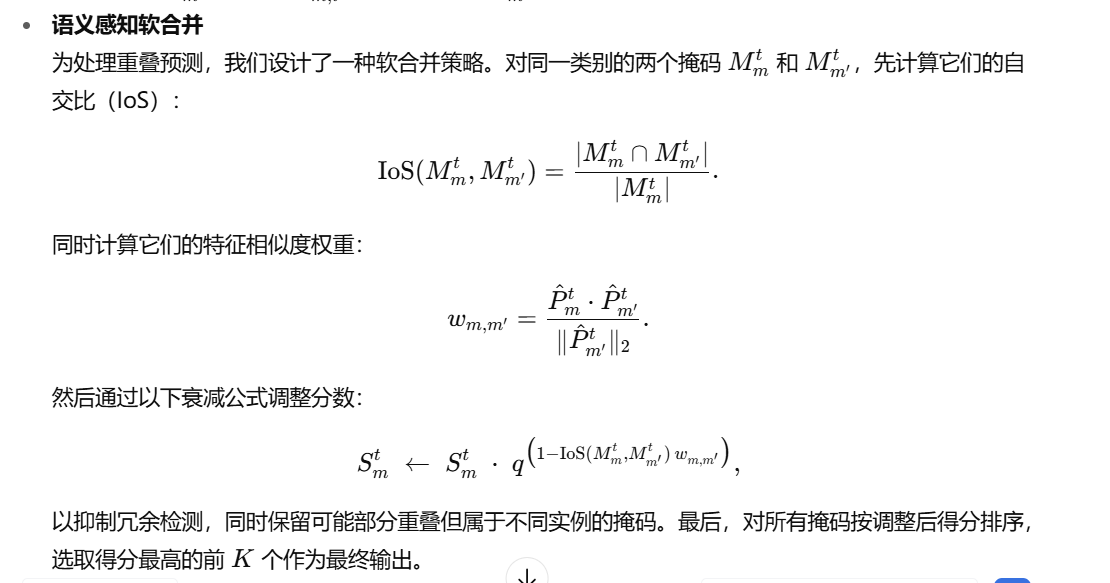
3.3 技術實現細節
我們的代碼庫基于 SAM2-L(分層 ViT)用于掩碼生成,使用 DINOv2-L 作為特征編碼器。編碼器以 518×518 分辨率、14×14 的 patch 大小處理圖像,而 SAM2 以 1024×1024 分辨率運行。推理階段,SAM2 首先通過 32×32 網格的查詢點生成候選掩碼。對于每個掩碼,我們在掩蓋區域內對編碼器特征進行平均池化,并做 L2 歸一化,得到掩碼特征。然后將這些特征與記憶庫中每個類別的 n 張參考圖像特征進行對比。我們采用 IoU 閾值為 0.5 的非極大值抑制(NMS),并結合語義感知軟合并策略來處理重疊預測。每張圖像最多輸出 100 個實例。實現方面,使用 PyTorch[1] 及 PyTorch Lightning[11] 在多 GPU 上進行分布式計算。
結果
4.1 目標檢測與實例分割
雖然我們的無需訓練方法直接輸出分割掩碼,但為了與現有工作進行公平比較,我們將實例掩碼轉換為邊界框。
COCO-FSOD 基準
我們在 COCO-20i 數據集 [30, 42] 的嚴格少樣本設置下評估所提方法,采用標準的 10-shot 和 30-shot 設置。COCO-FSOD 基準的結果如表 1 所示。所有結果均針對 COCO 新類別(即與 PASCAL VOC 類別 [10] 重疊的那些類別)進行匯報。我們的方法在完全無需訓練的前提下便取得了最先進的效果,優于所有對新類別進行微調的方法。
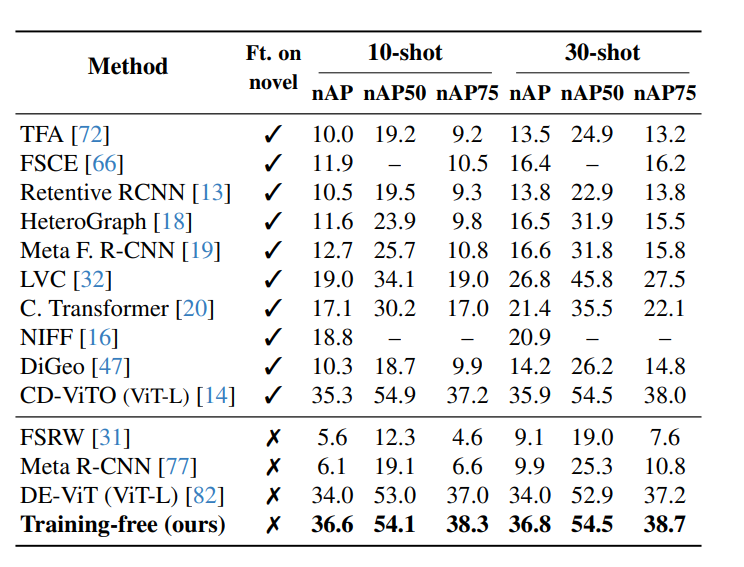
表 1. 在 COCO-FSOD 基準的 10-shot 和 30-shot 設置下,我們的無需訓練方法與最先進方法的對比。我們的方法在不對新類別進行微調的情況下(“Ft. on novel”)依然取得了最先進的性能。結果以 nAP、nAP50 和 nAP75 報告,其中 nAP 表示僅針對新類別的 mAP。其他方法的結果來源于文獻 [14]。由于我們是唯一同時提供邊界框和分割結果的方法,為簡潔起見,本表中省略了分割 AP
圖 3 給出了定性結果,展示了本方法在擁擠場景中處理多重重疊實例的能力,兼具細粒度語義理解與精確定位。借助語義感知軟合并策略,我們有效緩解了重復檢測和誤報問題。失敗案例詳見附錄材料。

圖 3. 在 COCO val2017 測試集上的定性結果,10-shot 設置(每個類別使用 10 張參考圖像)。
邊界框可視化閾值為 0.5。我們的方法能夠在擁擠場景中有效處理多重重疊實例,展現細粒度的語義理解與精確的定位。通過語義感知軟合并策略,我們能夠避免重復檢測和誤報。建議放大后查看以獲得最佳效果。
PASCAL-VOC 少樣本評估
PASCAL-VOC 數據集 [10] 包含 20 個類別。對于少樣本評估,我們沿用了標準做法 [16],將 20 個類別分成 3 個拆分,每組包含 15 個基礎類別和 5 個新類別。如先前工作 [82],我們在各拆分的新類別上報告 AP50 結果。表 2 顯示,本方法在所有拆分上均超越了之前的所有方法,無論是那些對新類別進行微調的方法,還是無需微調的方法,均實現了最先進的性能。
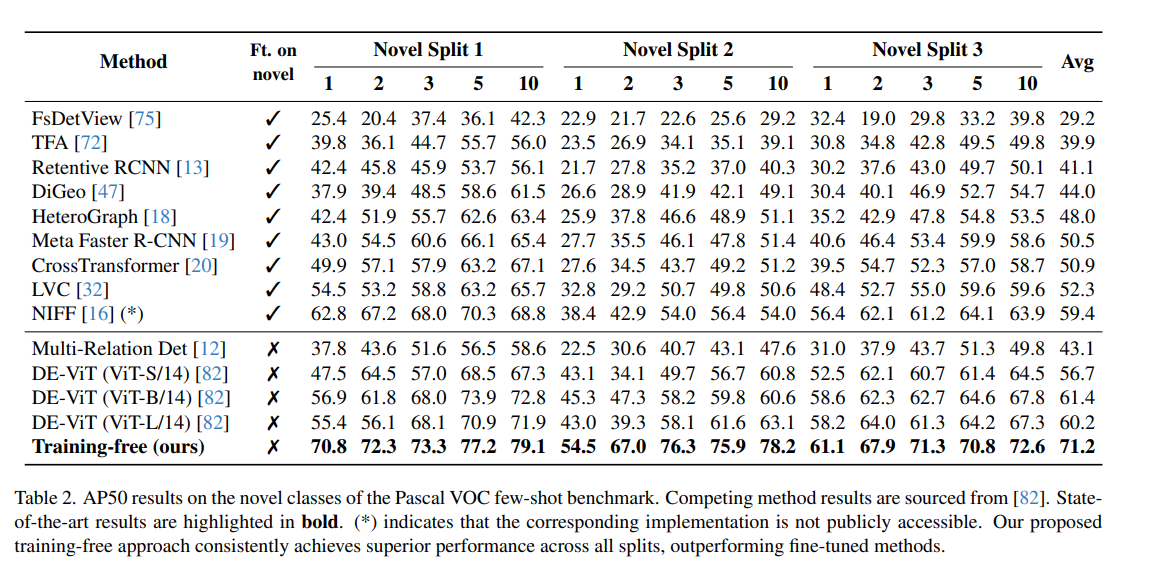
表 2. 在 Pascal VOC 少樣本基準的新類別上,AP50 結果對比。其他方法的結果來源于文獻 [82]。最先進的結果以 加粗 標示。(*) 表示對應實現未公開可獲取。我們的無訓練方法在所有拆分上持續取得優越性能,超越了所有微調方法。
4.2 跨域少樣本目標檢測
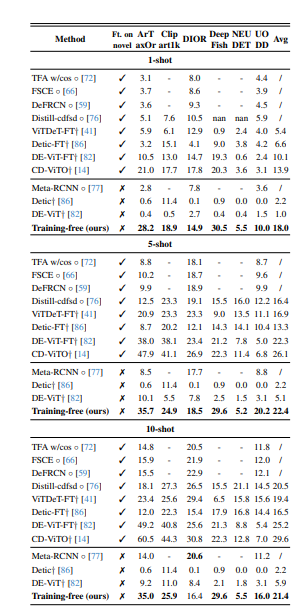
CD-FSOD 基準 [14] 專為評估跨域少樣本目標檢測(CD-FSOD)模型而設計,通過在域偏移和數據匱乏場景下考驗模型性能。該基準使用 COCO [42] 作為源訓練集(SD),并包含六個目標數據集(TD):ArTaxOr、Clipart1k、DIOR、DeepFish、NEUDET 和 UODD,覆蓋了真實照片、卡通、航空遙感、水下和工業領域,且類別間差異較大。盡管許多方法會在測試前對目標數據集的少量帶標簽樣本(支持集 S)進行微調,我們的模型則完全無需訓練,直接在六個目標數據集上進行評估,無任何微調。
表 3 給出了 CD-FSOD 基準下 1-shot、5-shot 和 10-shot 設置中各 FSOD 方法的比較。我們的無訓練方法在所有無訓練方法中創下新紀錄,并且與那些經過微調的模型相比,依然保持了極具競爭力的性能。這些結果證明了本方法在跨域場景下的強大泛化能力和魯棒性,無需重新訓練即可直接部署。

4.3 COCO 少樣本語義分割
盡管我們的方法是為實例分割設計的,但我們也在 COCO-20i 少樣本語義分割基準[52]上進行了評估。將 COCO 的 80 個類別劃分為四個拆分[25, 52, 71],每個拆分包含 60 個基礎類別和 20 個新類別。我們在嚴格的 1-shot 和 5-shot 設置[87]下,對 20 個新類別的性能進行評估,結果如表 4 所示。
為了將我們的實例分割預測適配到語義分割任務,我們將同一類別的所有實例合并為語義圖,以便與之前的方法直接比較。盡管完全無需訓練,我們的方法在與微調方法的對比中也取得了具有競爭力的表現。
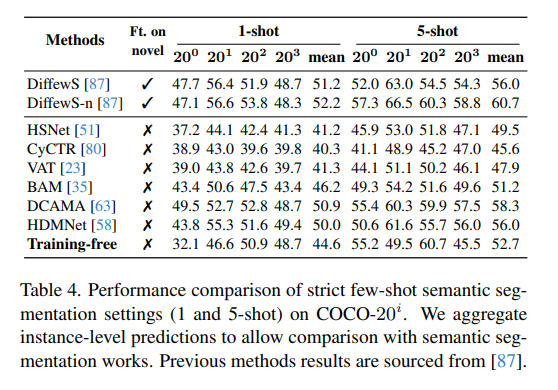
表 4. 在 COCO-20i 上嚴格少樣本語義分割設置(1-shot 和 5-shot)的性能對比。我們將實例級預測聚合為語義圖,以便與語義分割方法進行比較。先前方法的結果來源于文獻 [87]。
4.4 參考集的差異性
使用不同的參考圖像會導致結果的波動,因為性能依賴于每個類別所選參考圖像的質量。
為了量化這種差異,我們在 COCO-20i 少樣本目標檢測基準上,采用不同的隨機種子來選擇參考圖像,進行了多次評估。圖 4 顯示了 10 次運行的標準差(std)。我們觀察到,隨著參考圖像數量的增加(shot 數增大),結果的方差逐漸減小,標準差也更低。在 1-shot、2-shot 和 3-shot 設置中,參考圖像的選擇對性能影響更為顯著;而在 5-shot 及以上時,較低的標準差表明方法對參考集的變化具有較強的魯棒性。這些結果表明,在特定的 shot 設置下,有些參考圖像本質上更具代表性。如何找到“最優”參考集的特征仍是未來值得深入探索的方向。
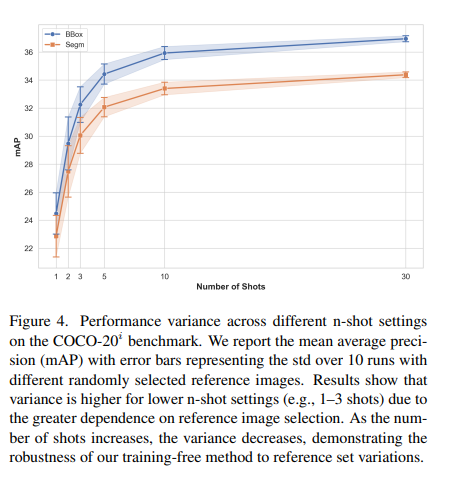
圖 4. 在 COCO-20i 基準上不同 n-shot 設置下的性能方差。我們報告了平均精度(mAP)及其誤差線,誤差線表示在使用不同隨機選擇的參考圖像進行 10 次運行時的標準差。結果表明,由于對參考圖像選擇的依賴性更強,低 n-shot 設置(如 1–3 shot)時方差更大;隨著 shot 數增加,方差減小,展示了我們無需訓練方法對參考集變化的魯棒性。
結論
在本工作中,我們提出了一種新穎的無需訓練的少樣本實例分割在這里插入代碼片方法,將 SAM 的掩碼生成能力與 DINOv2 的細粒度語義理解相結合。我們的方法通過參考圖像構建記憶庫,采用特征聚合精煉內部表征,并利用余弦相似度與語義感知軟合并對新實例進行特征匹配。實驗表明,精心工程化已有的凍結基礎模型即可在無需額外訓練的情況下實現最先進的性能:我們在 COCO-FSOD 上取得了 36.8% nAP(超越了微調方法)、在 PASCAL VOC 少樣本分割上取得了 71.2% nAP50,并在跨域場景(如 CD-FSOD 基準)中展現了強大的泛化能力。此外,我們的語義分割結果也證明了該方法可通過將實例預測聚合為語義圖進行擴展。
未來工作中,我們識別出若干有前景的研究方向:(1)探索基于學習的策略,以在 1–5 shot 場景中自動選擇最具信息量的參考圖像;(2)通過改進特征定位能力來克服 DINOv2 的全局語義偏差,尤其針對細粒度任務;(3)研究輕量級微調方法,以提升 1–5 shot 場景下記憶庫表征的質量。
Inference code
在 Few-shot COCO 上復現 30-shot SOTA 結果
首先定義必要變量并創建保存結果的文件夾:
CONFIG=./no_time_to_train/new_exps/coco_fewshot_10shot_Sam2L.yaml
CLASS_SPLIT="few_shot_classes"
RESULTS_DIR=work_dirs/few_shot_results
SHOTS=30
SEED=33
GPUS=4mkdir -p $RESULTS_DIR
FILENAME=few_shot_${SHOTS}shot_seed${SEED}.pkl- 創建參考集(reference set)
python no_time_to_train/dataset/few_shot_sampling.py \--n-shot $SHOTS \--out-path ${RESULTS_DIR}/${FILENAME} \--seed $SEED \--dataset $CLASS_SPLIT- 用參考集填充 Memory Bank
python run_lightening.py test --config $CONFIG \--model.test_mode fill_memory \--out_path ${RESULTS_DIR}/memory.ckpt \--model.init_args.model_cfg.memory_bank_cfg.length $SHOTS \--model.init_args.dataset_cfgs.fill_memory.memory_pkl ${RESULTS_DIR}/${FILENAME} \--model.init_args.dataset_cfgs.fill_memory.memory_length $SHOTS \--model.init_args.dataset_cfgs.fill_memory.class_split $CLASS_SPLIT \--trainer.logger.save_dir ${RESULTS_DIR}/ \--trainer.devices $GPUS- 后處理 Memory Bank
python run_lightening.py test --config $CONFIG \--model.test_mode postprocess_memory \--model.init_args.model_cfg.memory_bank_cfg.length $SHOTS \--ckpt_path ${RESULTS_DIR}/memory.ckpt \--out_path ${RESULTS_DIR}/memory_postprocessed.ckpt \--trainer.devices 1- 在目標圖像上推理
python run_lightening.py test --config $CONFIG \--ckpt_path ${RESULTS_DIR}/memory_postprocessed.ckpt \--model.init_args.test_mode test \--model.init_args.model_cfg.memory_bank_cfg.length $SHOTS \--model.init_args.model_cfg.dataset_name $CLASS_SPLIT \--model.init_args.dataset_cfgs.test.class_split $CLASS_SPLIT \--trainer.logger.save_dir ${RESULTS_DIR}/ \--trainer.devices $GPUS

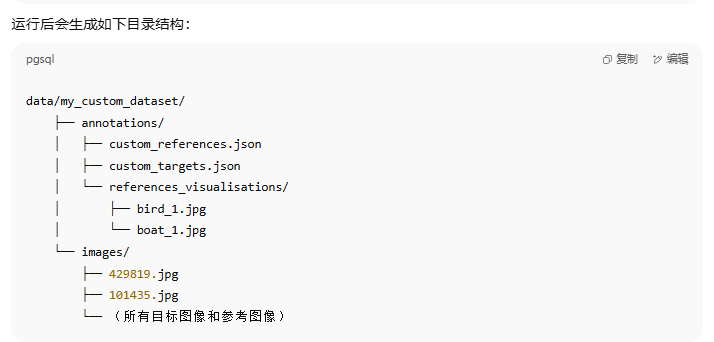
Custom dataset 自定義數據集
我們提供了在自定義數據集上運行整個流程的使用說明。標注格式必須是 COCO 格式。
簡要說明(TLDR)
如果想直接查看如何在自定義數據集上運行完整流程,請參考 scripts/matching_cdfsod_pipeline.sh,以及 CD-FSOD 數據集的示例腳本(例如 scripts/dior_fish.sh)。


0.1 如果只有邊界框標注
我們還提供了一個腳本,可以使用 SAM2 從參考圖像的邊界框標注生成實例級別的分割掩碼。
這在你只有參考圖像的 bounding box 標注時非常有用。
下載 sam_h 模型權重
可以使用更近期的檢查點(注意:可能需要適配代碼):
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth -O checkpoints/sam_vit_h_4b8939.pth從真實標注的 bounding box 自動生成實例分割:
python no_time_to_train/dataset/sam_bbox_to_segm_batch.py \--input_json data/my_custom_dataset/annotations/custom_references.json \--image_dir data/my_custom_dataset/images \--sam_checkpoint checkpoints/sam_vit_h_4b8939.pth \--model_type vit_h \--device cuda \--batch_size 8 \--visualize由 SAM2 根據真實邊界框生成的參考圖像實例分割掩碼(1-shot 示例):
生成的分割掩碼可視化結果保存在:
data/my_custom_dataset/annotations/custom_references_with_SAM_segm/references_visualisations/
將 COCO 標注文件轉換為 pickle 文件
python no_time_to_train/dataset/coco_to_pkl.py \data/my_custom_dataset/annotations/custom_references_with_segm.json \data/my_custom_dataset/annotations/custom_references_with_segm.pkl \11. 用參考圖像填充 Memory Bank

DATASET_NAME=my_custom_dataset
DATASET_PATH=data/my_custom_dataset
CAT_NAMES=boat,bird
CATEGORY_NUM=2
SHOT=1
YAML_PATH=no_time_to_train/pl_configs/matching_cdfsod_template.yaml
PATH_TO_SAVE_CKPTS=./tmp_ckpts/my_custom_dataset
mkdir -p $PATH_TO_SAVE_CKPTS運行 Step 1:
python run_lightening.py test --config $YAML_PATH \--model.test_mode fill_memory \--out_path $PATH_TO_SAVE_CKPTS/$DATASET_NAME\_$SHOT\_refs_memory.pth \--model.init_args.dataset_cfgs.fill_memory.root $DATASET_PATH/images \--model.init_args.dataset_cfgs.fill_memory.json_file $DATASET_PATH/annotations/custom_references_with_segm.json \--model.init_args.dataset_cfgs.fill_memory.memory_pkl $DATASET_PATH/annotations/custom_references_with_segm.pkl \--model.init_args.dataset_cfgs.fill_memory.memory_length $SHOT \--model.init_args.dataset_cfgs.fill_memory.cat_names $CAT_NAMES \--model.init_args.model_cfg.dataset_name $DATASET_NAME \--model.init_args.model_cfg.memory_bank_cfg.length $SHOT \--model.init_args.model_cfg.memory_bank_cfg.category_num $CATEGORY_NUM \--trainer.devices 12. 后處理 Memory Bank
python run_lightening.py test --config $YAML_PATH \--model.test_mode postprocess_memory \--ckpt_path $PATH_TO_SAVE_CKPTS/$DATASET_NAME\_$SHOT\_refs_memory.pth \--out_path $PATH_TO_SAVE_CKPTS/$DATASET_NAME\_$SHOT\_refs_memory_postprocessed.pth \--model.init_args.model_cfg.dataset_name $DATASET_NAME \--model.init_args.model_cfg.memory_bank_cfg.length $SHOT \--model.init_args.model_cfg.memory_bank_cfg.category_num $CATEGORY_NUM \--trainer.devices 13. 在目標圖像上進行推理
如果將 ONLINE_VIS=True,預測結果會保存到
results_analysis/my_custom_dataset/ 并在計算時顯示出來。
?? 注意:開啟在線可視化會顯著降低推理速度。
可以調整 分數閾值 VIS_THR 來控制輸出更多或更少的實例分割結果。
ONLINE_VIS=True
VIS_THR=0.4
python run_lightening.py test --config $YAML_PATH \--model.test_mode test \--ckpt_path $PATH_TO_SAVE_CKPTS/$DATASET_NAME\_$SHOT\_refs_memory_postprocessed.pth \--model.init_args.model_cfg.dataset_name $DATASET_NAME \--model.init_args.model_cfg.memory_bank_cfg.length $SHOT \--model.init_args.model_cfg.memory_bank_cfg.category_num $CATEGORY_NUM \--model.init_args.model_cfg.test.imgs_path $DATASET_PATH/images \--model.init_args.model_cfg.test.online_vis $ONLINE_VIS \--model.init_args.model_cfg.test.vis_thr $VIS_THR \--model.init_args.dataset_cfgs.test.root $DATASET_PATH/images \--model.init_args.dataset_cfgs.test.json_file $DATASET_PATH/annotations/custom_targets.json \--model.init_args.dataset_cfgs.test.cat_names $CAT_NAMES \--trainer.devices 1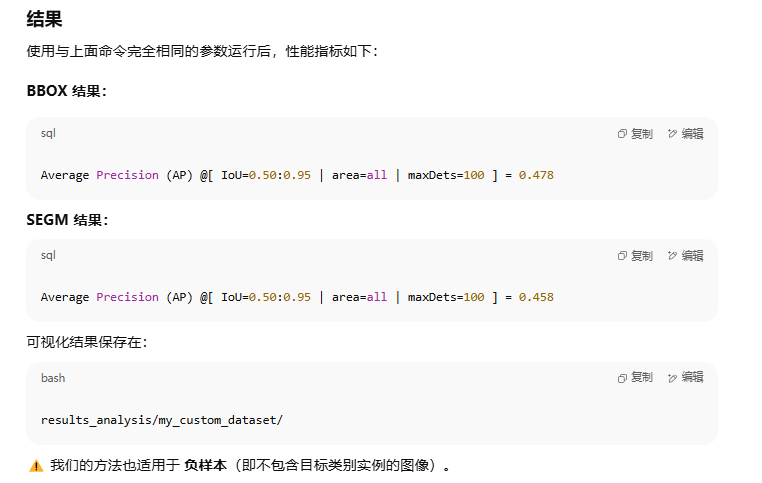









)


、resource() 和 prompt() 裝飾器)





:基于獎勵修正的強化學習視角)
Mac 終端上配置代理)
