目錄
一、RAG技術的定義與作用
二、RAG技術的關鍵組件
三、RAG技術解決的問題
四、RAG技術的核心價值與應用場景
五、如何實現利用RAG技術構建企業私有知識庫
六、Dify知識庫實現詳解
七、創建知識庫
1、創建知識庫
2、上傳文檔
3、文本分段與清洗
4、索引方式
5、Embedding 模型
6、檢索設置
八、構建應用并關聯知識庫
1、創建空白應用
2、關聯知識庫
3、引用和歸屬
4、知識召回
RAG(Retrieval-Augmented Generation,檢索增強生成)技術是一種將檢索模型與生成模型結合的架構,旨在通過引用外部知識庫的信息來生成答案或內容,提升生成答案或內容的準確性和專業性,以下是對RAG技術的詳細解析:
一、RAG技術的定義與作用
RAG技術通過從外部知識庫中實時檢索相關信息,動態補充大模型的輸入數據。這種技術結合了信息檢索(Retrieval)與生成模型(Generation)的優勢,構建了“先檢索、再生成”的閉環邏輯,從而提升了生成內容的準確性和專業性。其核心機制在于利用檢索模塊從海量文檔中精準找到與問題緊密相關的證據性內容,并將這些信息作為生成模型的上下文輸入,進而生成既符合語境又緊扣真實信息的回答。
二、RAG技術的關鍵組件
-
知識庫:存儲結構化或非結構化數據,如企業文檔、法律條文等,作為檢索模塊的信息來源。
-
向量數據庫:將文本轉化為向量表征,實現高效的語義檢索。向量數據庫支持基于語義相似性的快速精準檢索,能夠大幅提升RAG系統的效率。
-
生成器:基于檢索到的上下文信息生成最終回答。生成器通常是一個強大的生成模型,能夠充分利用外部知識庫中的信息,生成連貫、準確且信息詳實的文本內容。
三、RAG技術解決的問題
-
知識局限性:RAG技術能夠彌補大模型訓練數據的滯后性,通過實時檢索外部知識庫,使生成內容能夠反映最新的信息和知識。
-
生成可控性:通過引用可追溯的外部知識源,RAG技術提高了結果的透明度和可信度,使用戶更容易理解生成結果的來源和依據。
-
隱私與安全:RAG技術通過本地知識庫隔離敏感數據,避免敏感信息直接輸入大模型,從而降低了數據泄露的風險。
-
成本效率:相比全量微調模型,RAG技術顯著降低了領域知識適配的成本,使模型能夠更快速地適應新的知識和場景。
四、RAG技術的核心價值與應用場景
-
企業知識管理:RAG技術可用于構建私有化知識庫,如法律咨詢中即時檢索最新法規輔助生成法律意見,提高知識管理的效率和準確性。
-
實時信息整合:通過聯網檢索,RAG技術能夠補充最新數據,如市場動態、新聞資訊等,使生成內容更加時效和有價值。
-
專業領域增強:在醫療、金融等需要高準確性的領域,RAG技術能夠確保生成內容符合專業規范,提高決策的準確性和可靠性。
-
高并發優化:通過向量數據庫的水平擴展,RAG技術能夠支持大規模并發檢索,滿足高并發場景下的需求。
五、如何實現利用RAG技術構建企業私有知識庫
要實現利用RAG技術構建企業私有知識庫,可以按照以下步驟進行:
-
準備知識庫:收集并整理企業內部的文檔、數據等信息,構建結構化或非結構化的知識庫。
-
構建向量數據庫:將知識庫中的文本轉化為向量表征,并存儲在向量數據庫中,以便進行高效的語義檢索。
-
集成檢索與生成模塊:將檢索模塊和生成模塊集成到企業知識管理系統中,實現“先檢索、再生成”的功能。
-
優化與調整:根據實際需求對RAG系統進行優化和調整,如改進分塊策略、向量匹配算法等,以提高系統的性能和準確性。
綜上所述,RAG技術通過結合檢索和生成技術的優勢,實現了對外部知識庫信息的有效利用,為企業知識管理、實時信息整合、專業領域增強等場景提供了有力的支持。
六、Dify知識庫實現詳解
Dify知識庫作為文檔集合的核心功能,通過整合多種文檔類型和自動化處理流程,實現了高效的檢索增強生成(RAG)流水線。
-
?知識庫基礎概念?: Dify知識庫由數據集構成,每個數據集包含多個文檔(如文本、表格等),可直接集成到AI應用中作為檢索上下文使用。知識庫通過RAG技術讓大語言模型在生成回答前,先從可控的知識源中檢索相關信息,提升準確性和實用性。
-
?RAG流水線可視化?: Dify提供用戶友好的界面,支持RAG流水線各環節的可視化管理,包括文檔上傳、分段清洗、嵌入向量存儲和元數據設置。整個流程可簡化到幾分鐘內完成,開發者無需代碼即可構建應用。例如:
-
上傳文檔后,系統自動分段并清洗內容。
-
提交至LLM供應商嵌入為向量數據存儲。
-
為文檔設置元數據便于后續檢索。
-
-
?支持的數據格式?: Dify兼容多種源數據格式,確保靈活適配各類業務需求。具體包括:
-
?長文本內容?:TXT、Markdown、DOCX、HTML、JSON、PDF(單文件上限通常為15MB)。
-
?結構化數據?:CSV、Excel,支持表格數據的導入與轉換。
此外,Dify支持從外部數據源(如Notion)導入文檔,并實現自動同步更新
-
-
模型集成關鍵要求?: 為保障私有知識庫效果,必須結合embedding模型和reranker模型優化檢索精度。在Dify中,需通過以下步驟啟用:
-
在設置中選擇模型供應商(如OpenAI或本地模型)。
-
配置embedding模型處理向量轉換,并引入reranker模型優化相關度排序。
-
將模型API密鑰集成至工作流,確保RAG管道高效運行。
-
注:私有知識庫要達到良好的效果,必須與embedding模型和reranker模型相結合,請在xinterface中啟?相關模型并引?Dify
七、創建知識庫
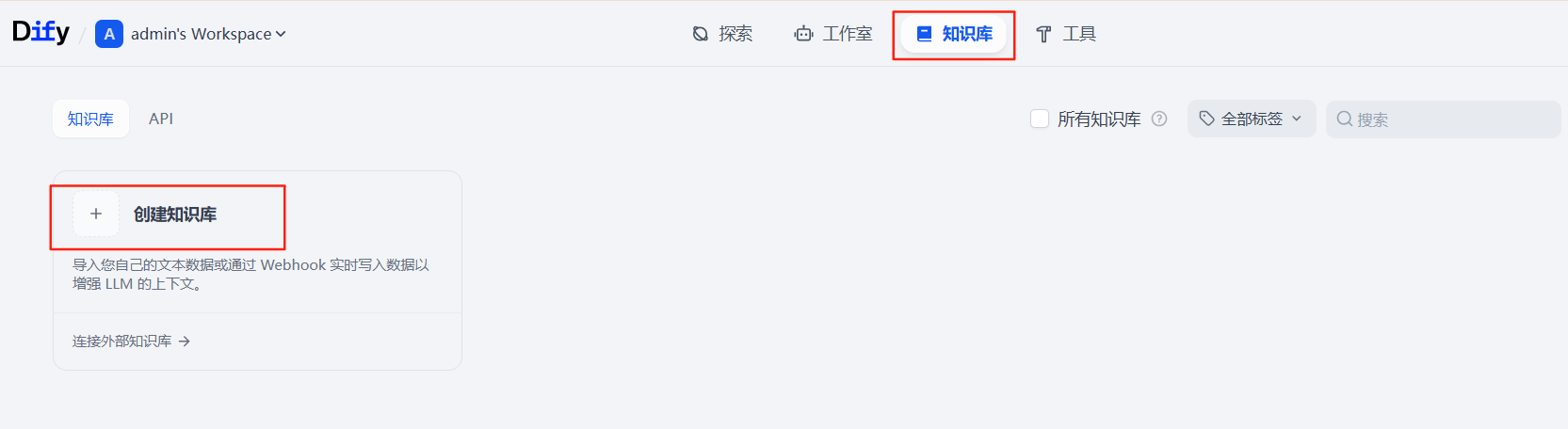
1、創建知識庫
點擊「知識庫」→「新建知識庫」
2、上傳文檔
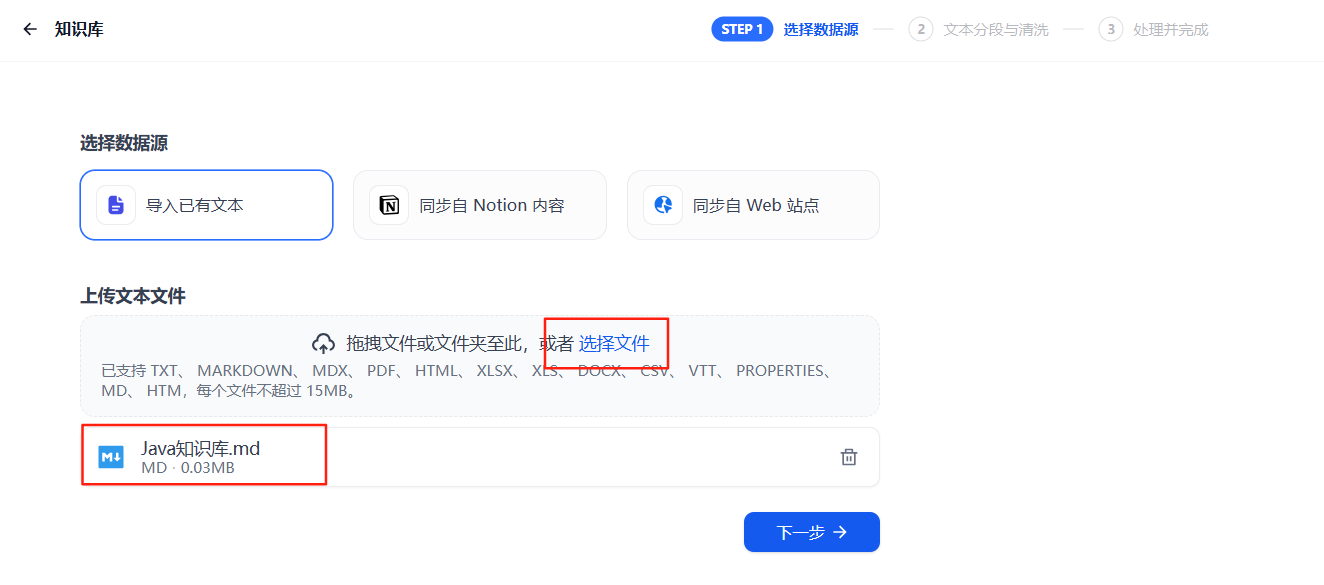
選擇本地文件(如《Java知識庫.md》)導入,點擊“下一步”。支持HTML、文本、PDF等格式,文件上傳后進入分段處理環節。
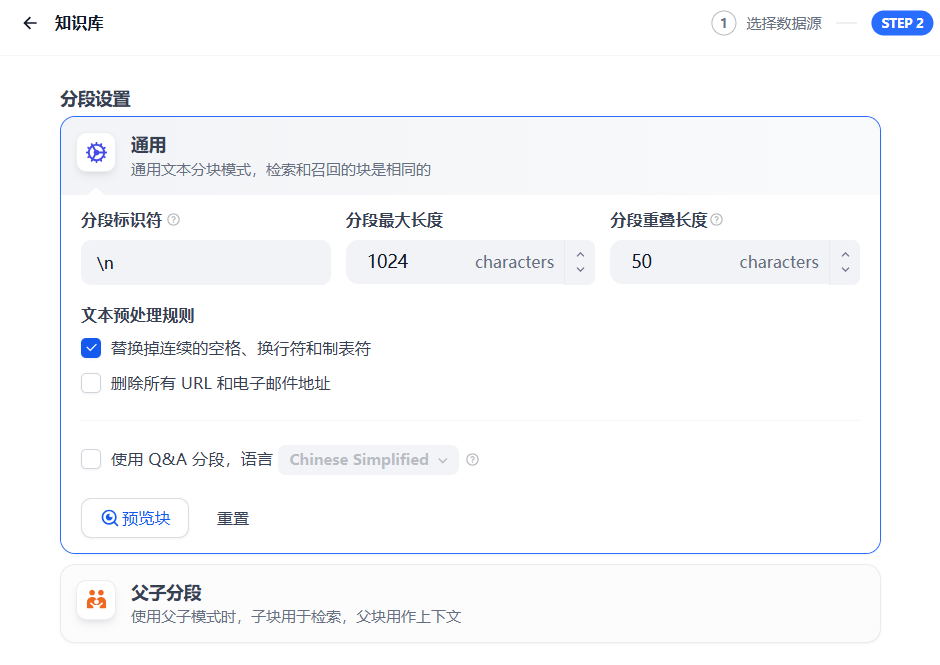
3、文本分段與清洗
-
?分段?:大語言模型受上下文窗口限制,需將文本切分為合適段落(建議256–512 tokens),通過分段Top-K召回提升語義匹配精度。
-
?清洗?:去除冗余字符或空行以減少噪聲,Dify內置多類清洗方法優化輸出質量。
關鍵操作?:勾選“問答分段”可啟用Q2Q(問題匹配問題)模式,直接關聯用戶提問與預定義問題,顯著提升答案相關性
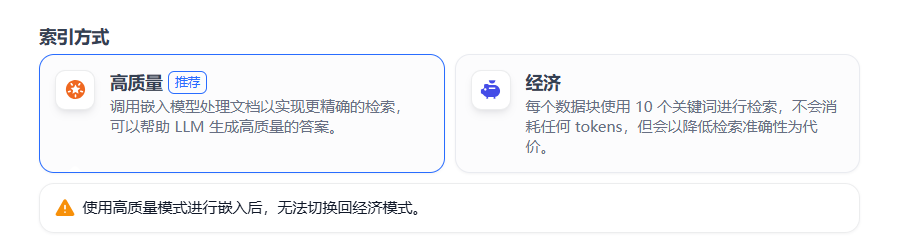
4、索引方式
選擇文本索引策略以適配檢索需求,例如:
-
?關鍵詞索引?:適用于精確術語匹配。
-
?向量索引?:支持語義相似度搜索。 索引策略需與實際場景結合設計
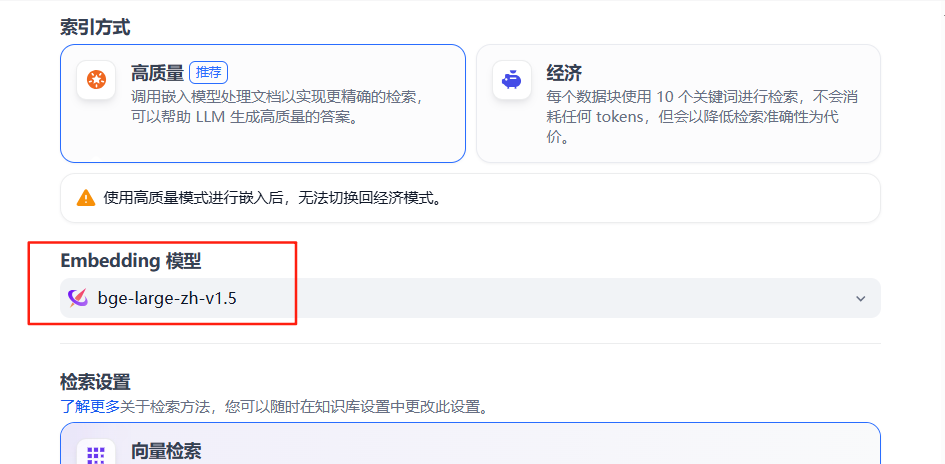
5、Embedding 模型
配置Embedding模型(如bge-large-zh-v1.5),將文本轉換為向量表示,直接影響語義召回效果。需根據模型默認Token上限(如500 tokens)調整分段大小。
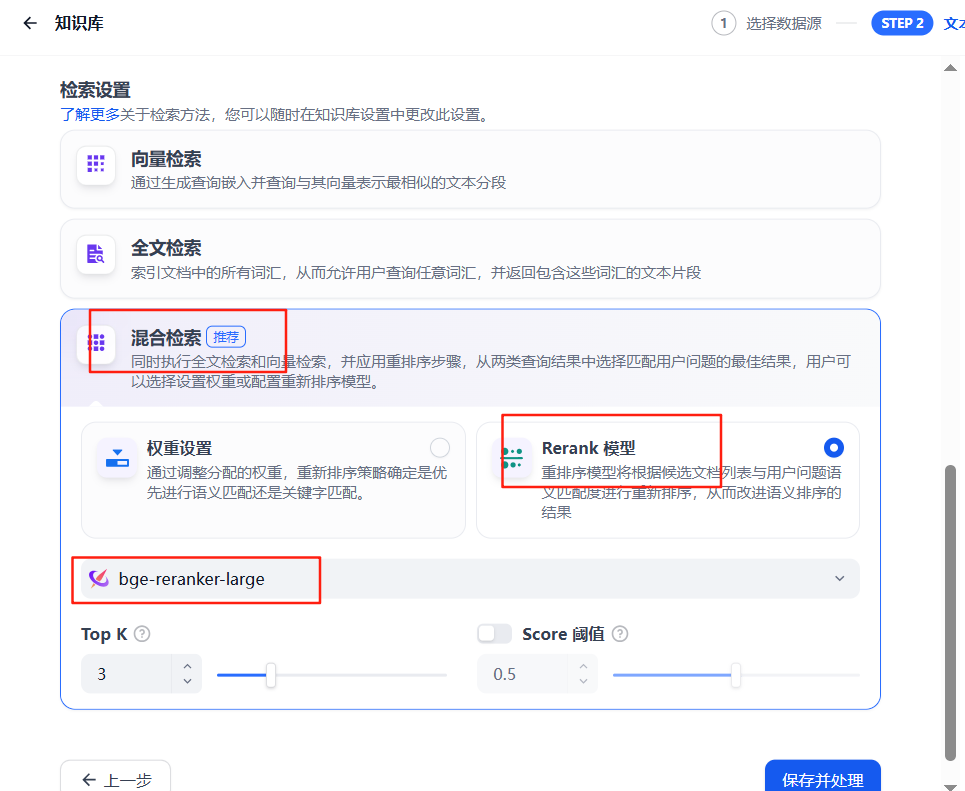
6、檢索設置
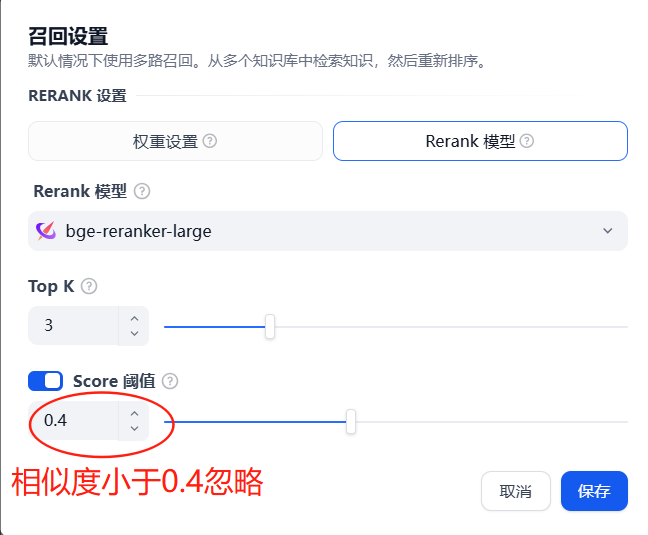
啟用“混合檢索”結合關鍵詞與語義匹配,設置參數(如TOP-K值、分數閾值)后點擊“保存并處理”。
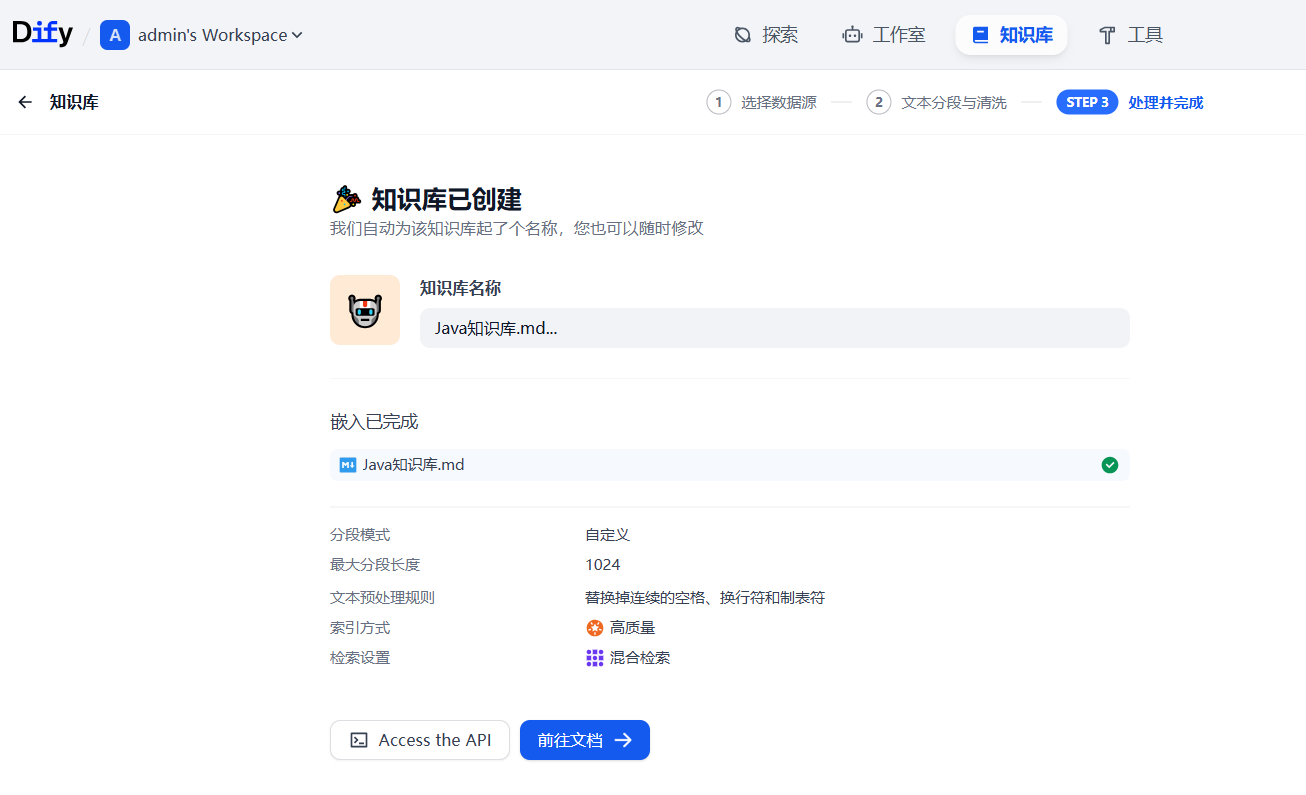
至此,知識庫創建已完成,接下來構建應用并關聯知識庫。
八、構建應用并關聯知識庫
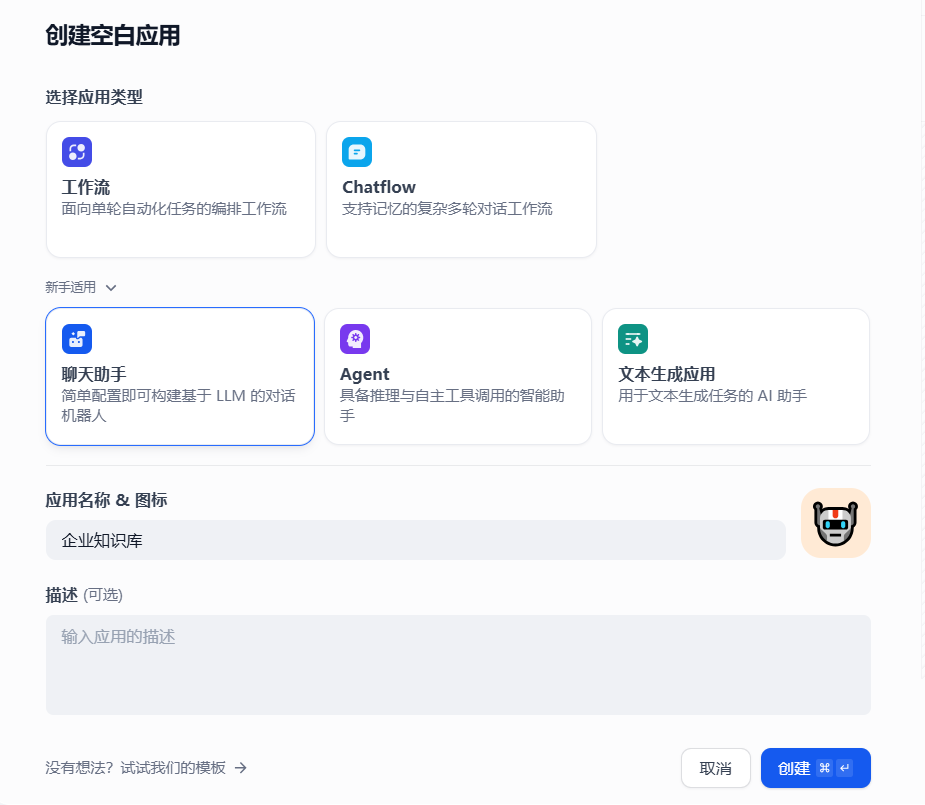
1、創建空白應用
2、關聯知識庫
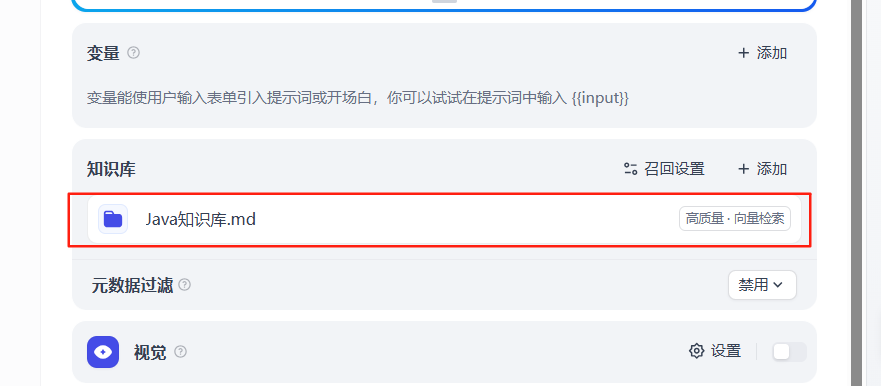
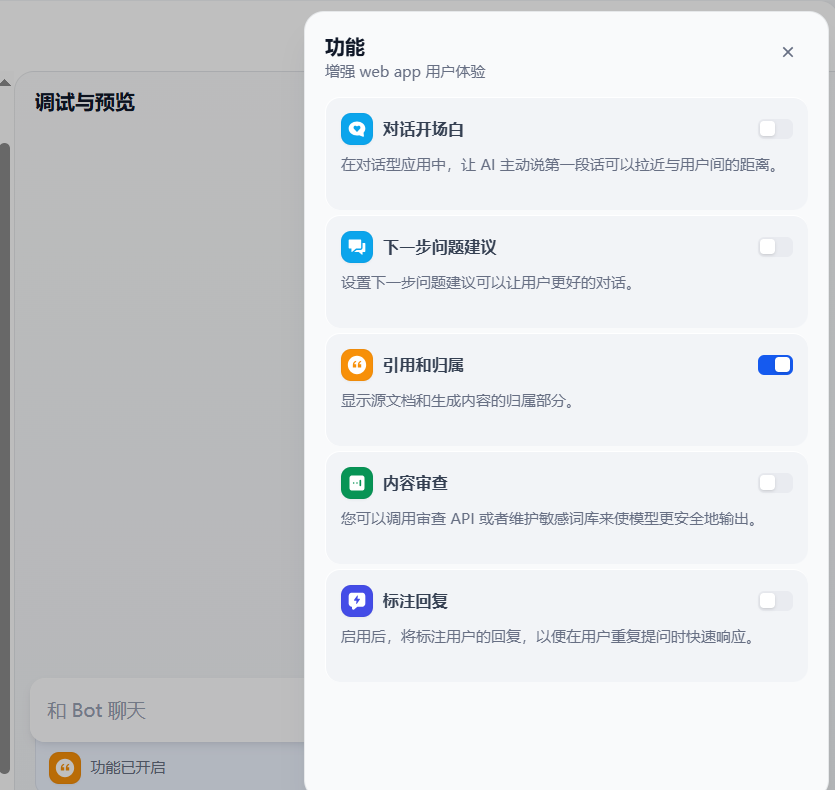
3、引用和歸屬
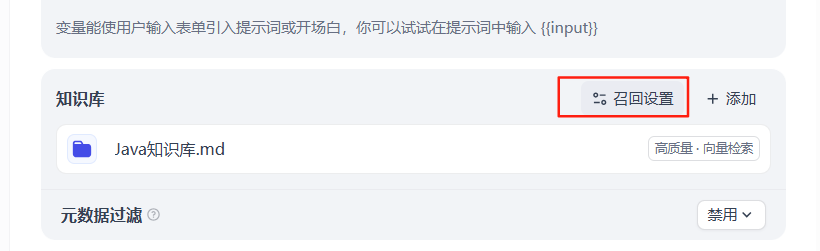
4、知識召回
效果演示:
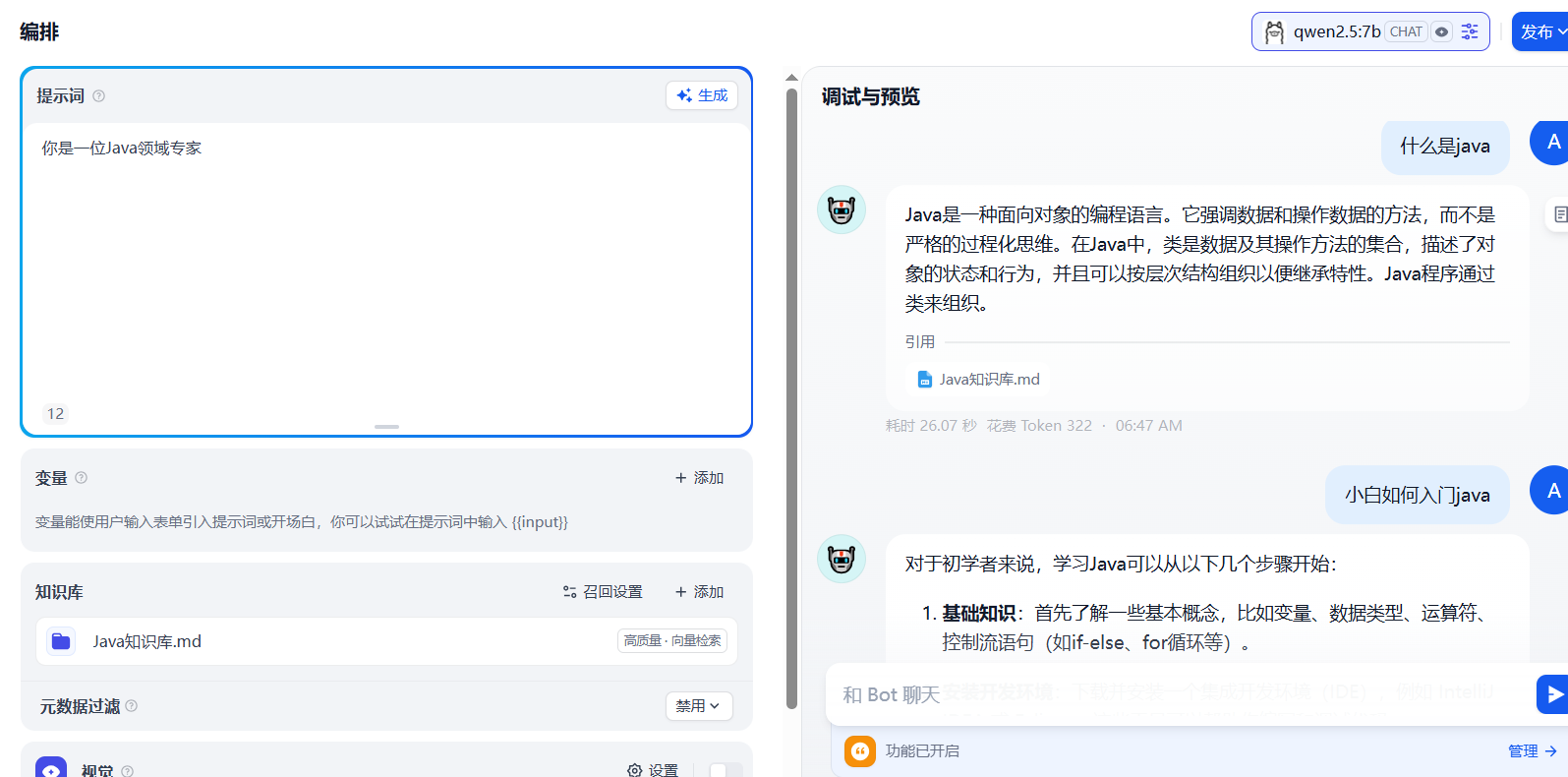
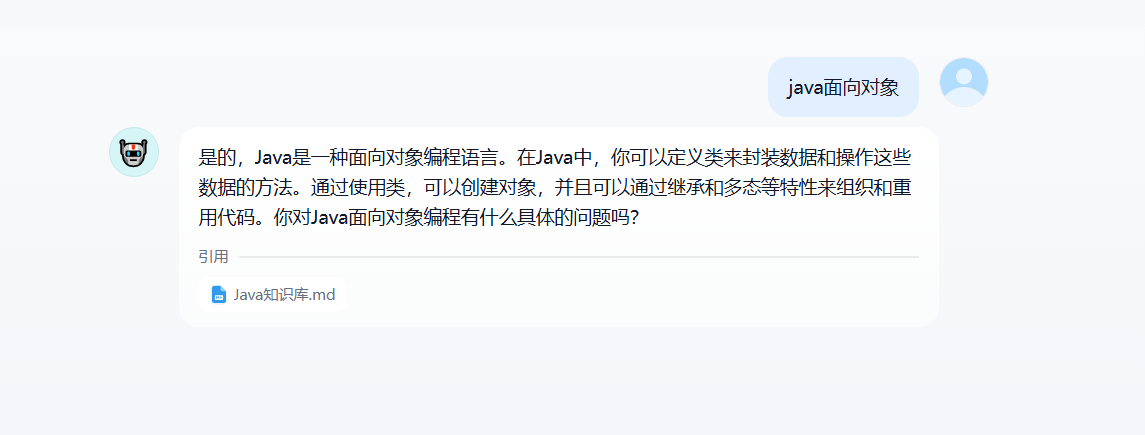
👉 Docker部署Dify詳細教程
👉 Docker部署Xinference詳細教程
👉 Ollama安裝詳細教程



新特性)



:GMP 模型深度解析)

一種高性能的物理引擎)
)





)


