簡歷描述
· 收集并制作軍事偽裝目標數據集,包含真實與偽裝各種類型軍事目標共計60余類。其中,包含最新戰場充氣偽裝軍事裝備30余類,并為每一張圖片制作了詳細的標注。
· 針對軍事偽裝目標的特點,在YOLOv8的Backbone與Neck部分分別加入分組動態感知注意力、跨通道信息交互模塊,顯著提升了軍事偽裝目標的識別精度。
YOLO
YOLOv1
2016cvpr
作者在v3之后由于軍方用不干了,后續由別人開發

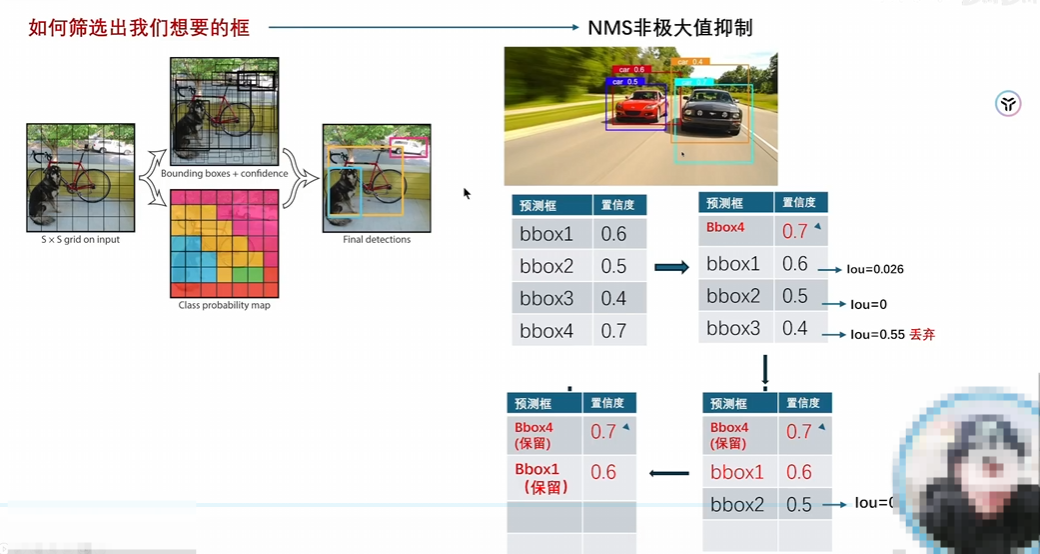
YOLOv2

- 高分辨率如圖
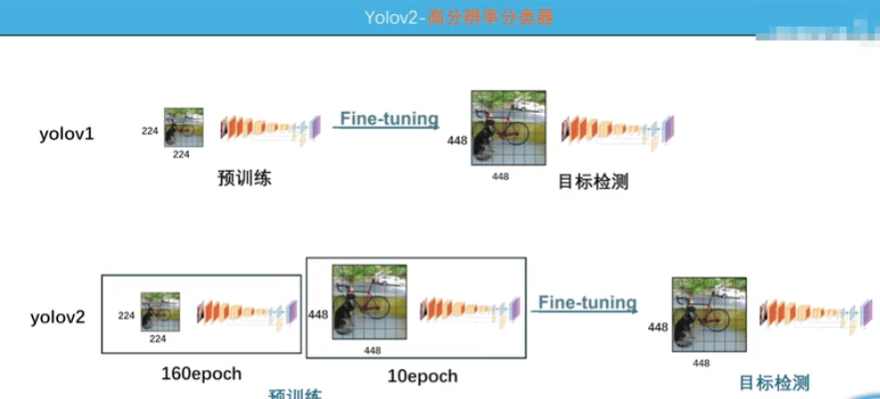
- 加了BN
- 引入錨框
中心點偏移權重來算長寬,讓他不全圖亂跑
錨框中心點雙重約束使得收斂變快
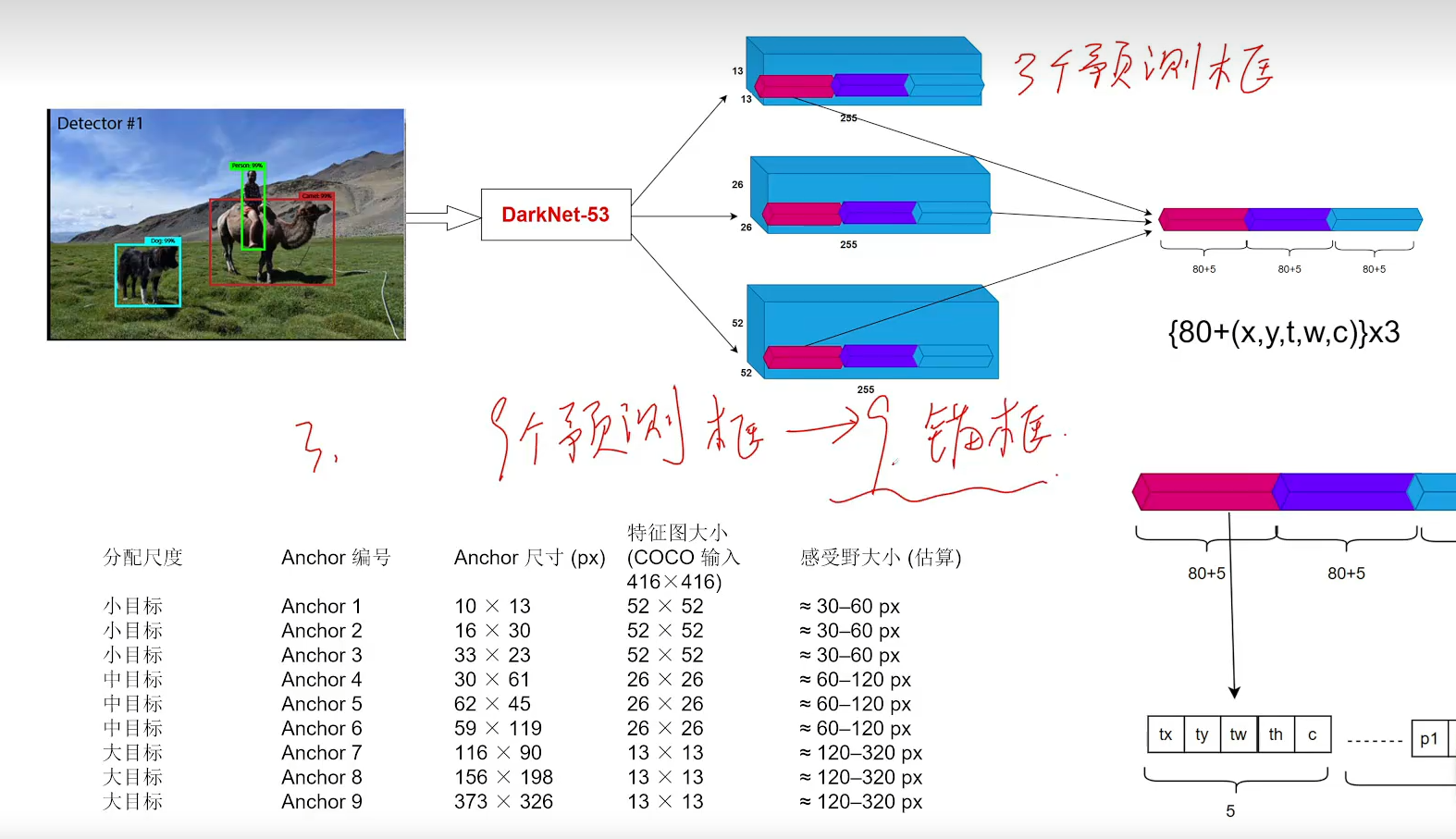
錨框是針對每個圖像網格單元(grid cell)定義的,而不是針對整個圖像。具體來說,YOLOv2(以及YOLO系列的其他版本)在訓練時,對于每個網格單元,會使用多個錨框來預測目標的邊界框。
具體解釋:
每個網格單元有多個錨框:在YOLOv2中,目標圖像被分成一個S x S的網格,每個網格單元負責檢測某個區域內的目標。每個網格單元上會預測多個邊界框(通常是5個),這些框的初始形狀(寬高)是由預定義的錨框確定的。
錨框的數量與每個網格單元的預測數目:每個網格單元會用5個錨框來做預測,這些錨框是根據訓練數據中目標的尺度和寬高比預先確定的(通常通過K-means聚類)。因此,每個網格單元的5個錨框是針對該網格位置的不同尺度和不同寬高比的預測框。
舉個例子:
假設你有一個416x416的圖像,并且網絡將其劃分為13x13的網格(即每個網格的大小為32x32像素)。那么:
圖像的每個網格單元都有5個錨框(這5個錨框的尺寸是根據聚類或其他方法確定的)。
每個網格單元會預測5個邊界框,每個框對應一個錨框。網絡會根據實際物體的位置、尺寸以及錨框的預設位置來進行回歸調整。
錨框和目標物體匹配:
目標物體與網格單元的錨框之間會根據**IoU(Intersection over Union)**來進行匹配。
對于每個物體,選擇與其匹配度最高的錨框。
該錨框會預測物體的邊界框。實際預測的邊界框會根據錨框的位置、寬高進行調整(回歸)。
為什么每個網格單元有多個錨框?
不同的目標物體具有不同的尺寸、形狀(寬高比),單一的錨框無法涵蓋所有物體的特征。因此,YOLOv2設計了每個網格單元使用多個錨框來應對這些變化。多個錨框可以有效地覆蓋不同尺度和不同形狀的物體,從而提高目標檢測的準確性。
總結:
每個網格單元都有多個錨框(通常是5個)。
這些錨框是根據數據集中的目標物體的尺寸和寬高比來預定義的,目的是幫助模型更好地預測不同尺度和形狀的物體。
- 采用特征融合,A+B,殘差連接類似于resnet
- 把圖像縮放不同尺寸輸入訓練
YOLOv3

maxpoll換成卷積,加殘差連接
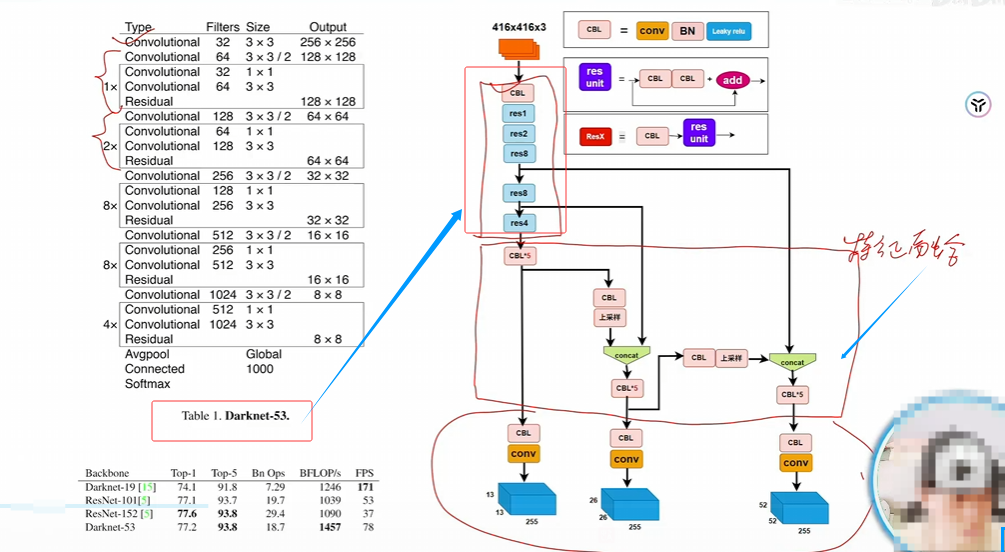
多個檢測頭,針對大、中、小物體

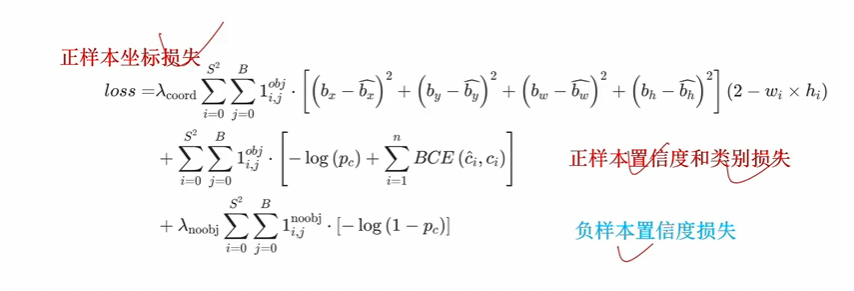
YOLOv4
- 改進
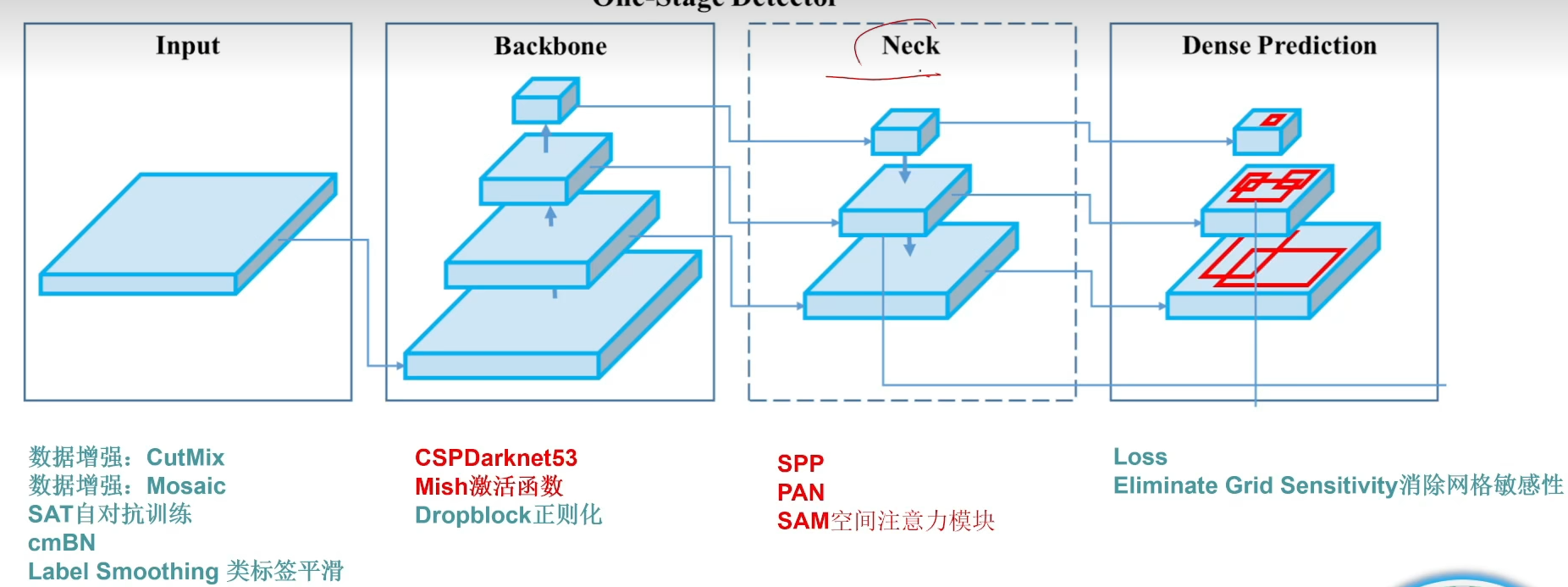
- spp、pan
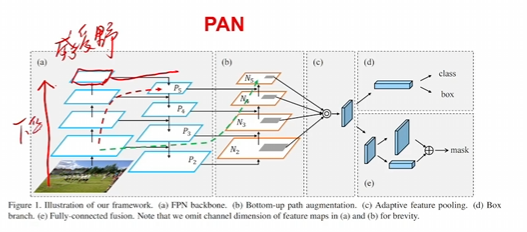
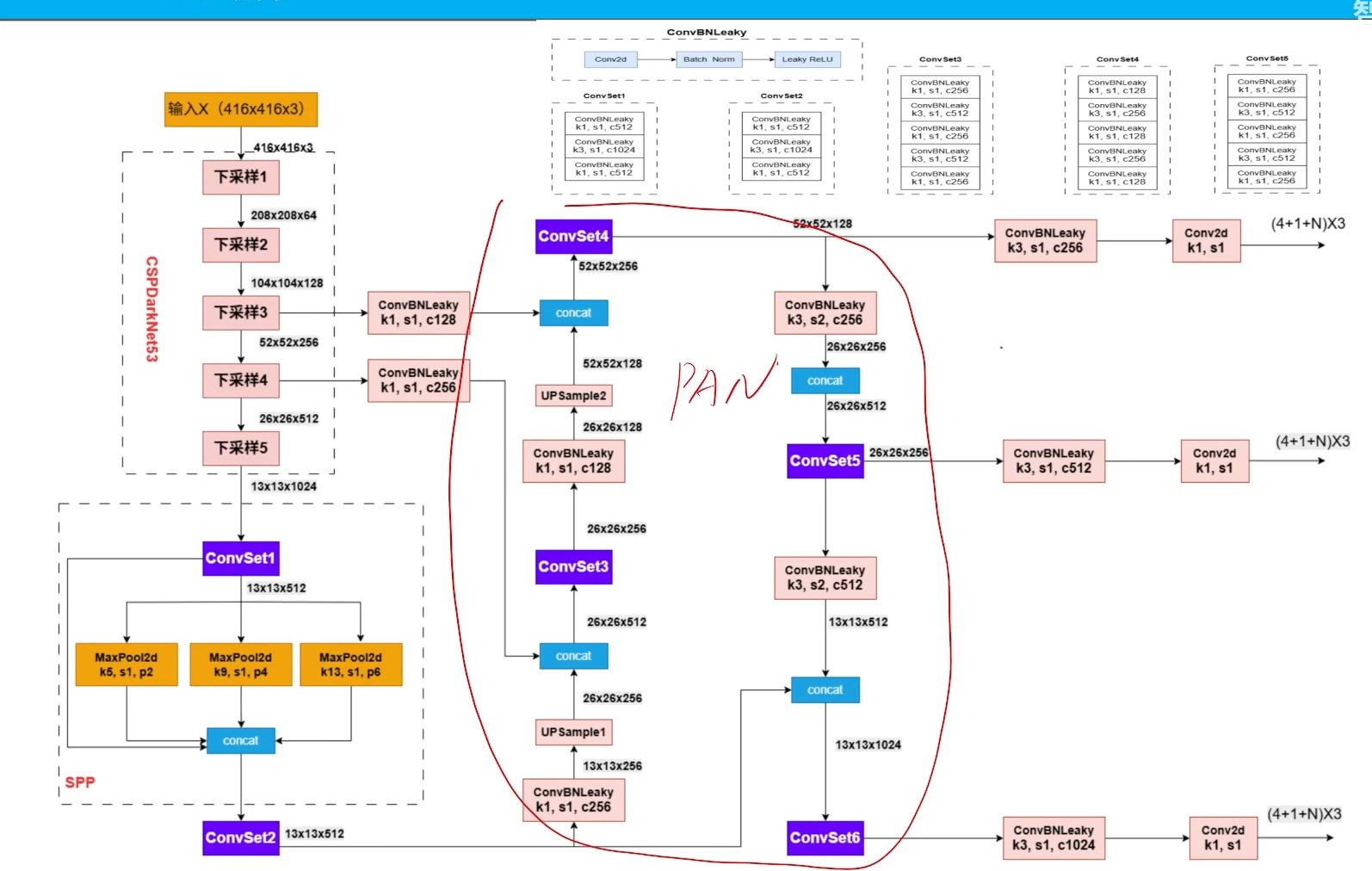
pan就是一個思想,深層和主干網絡的融合
spp就是多感受野一個模塊
- 數據增強
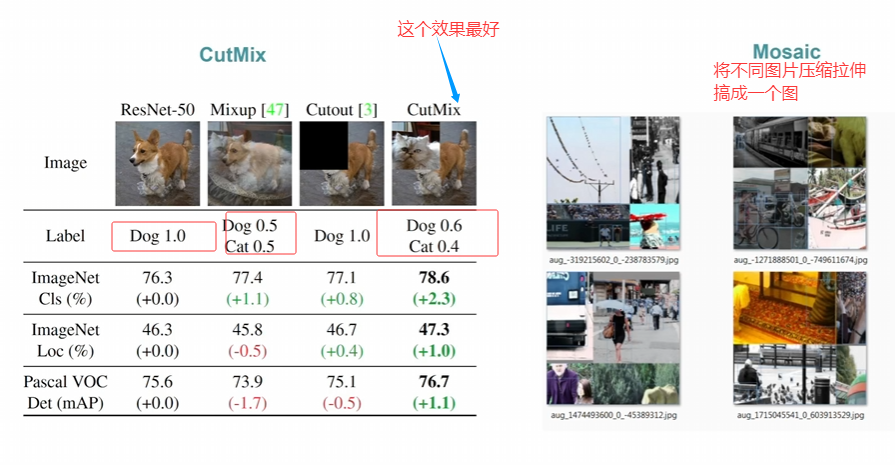
圖示已經很清楚的說明了兩個圖像增強策略是什么

相當于在正向的時候給圖片加噪聲,提升魯棒性

改進了歸一化方法,這里不贅述
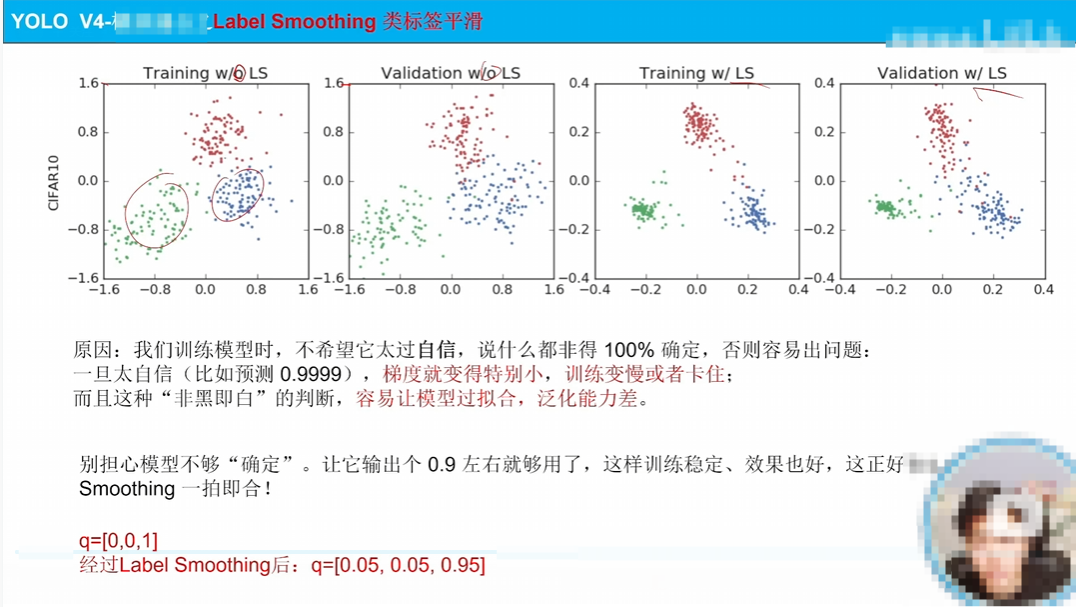
將標簽變成軟平滑標簽,解決梯度問題
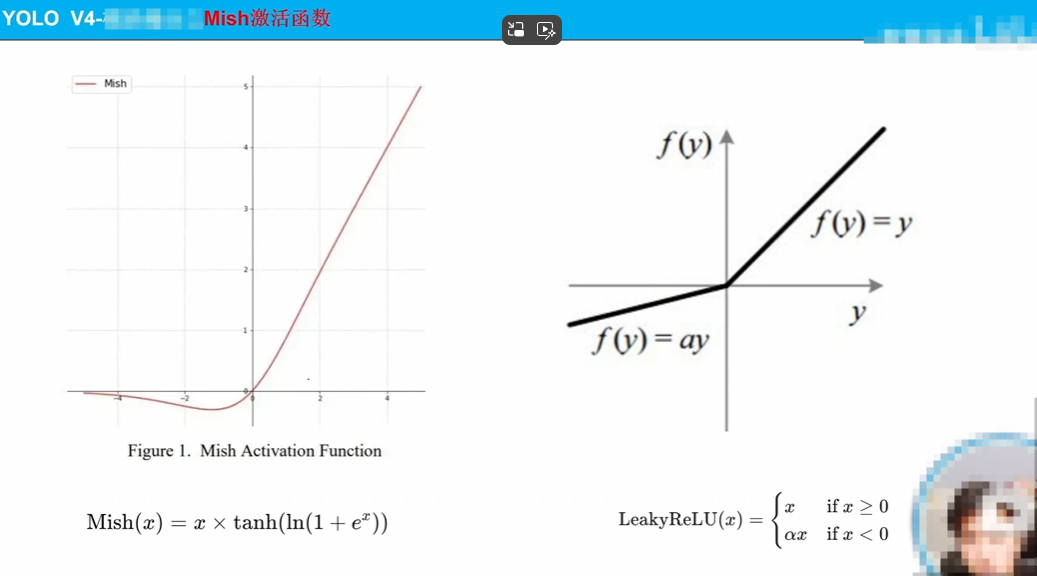
換了激活函數,如圖詳細說明了他更平滑
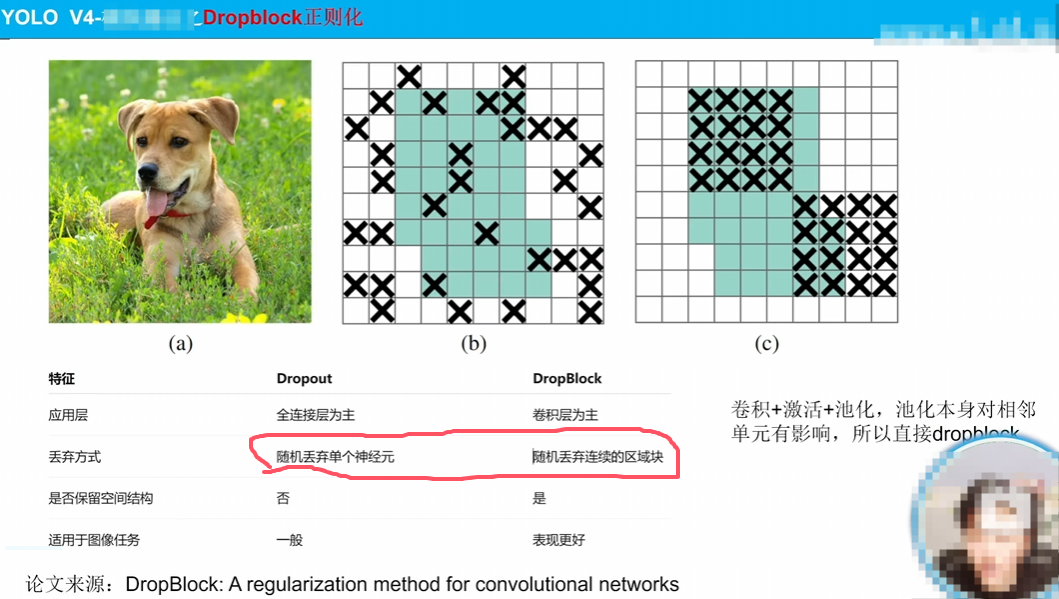
如圖很詳細說明了一些原因,不贅述
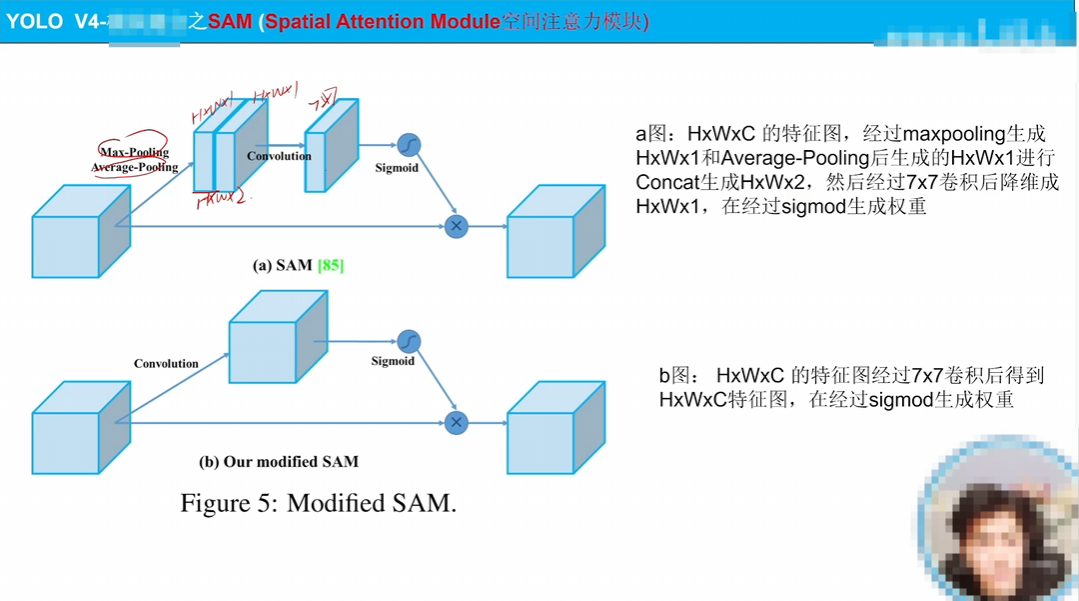
如圖說明很清楚
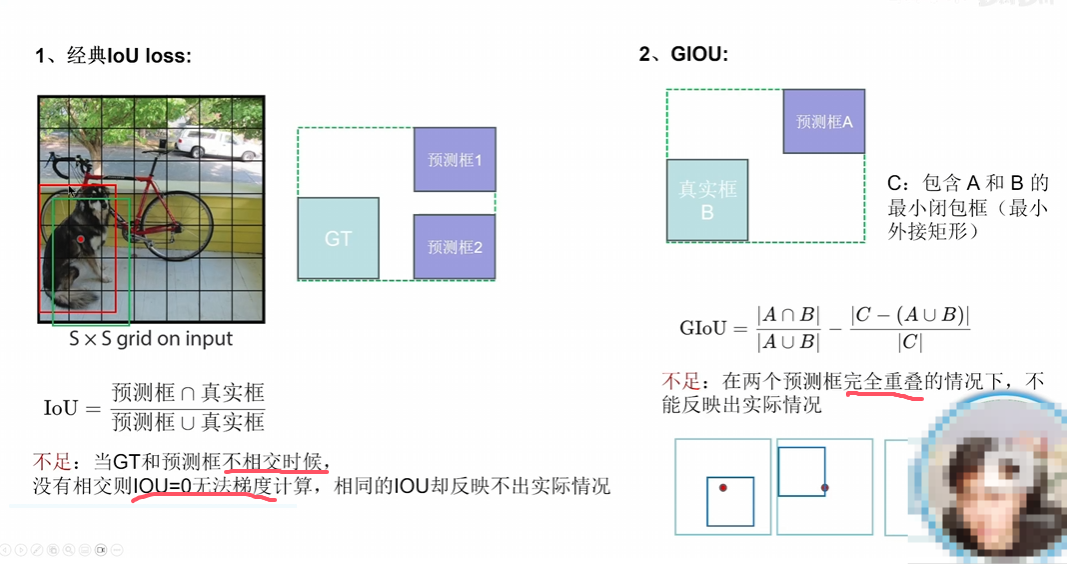
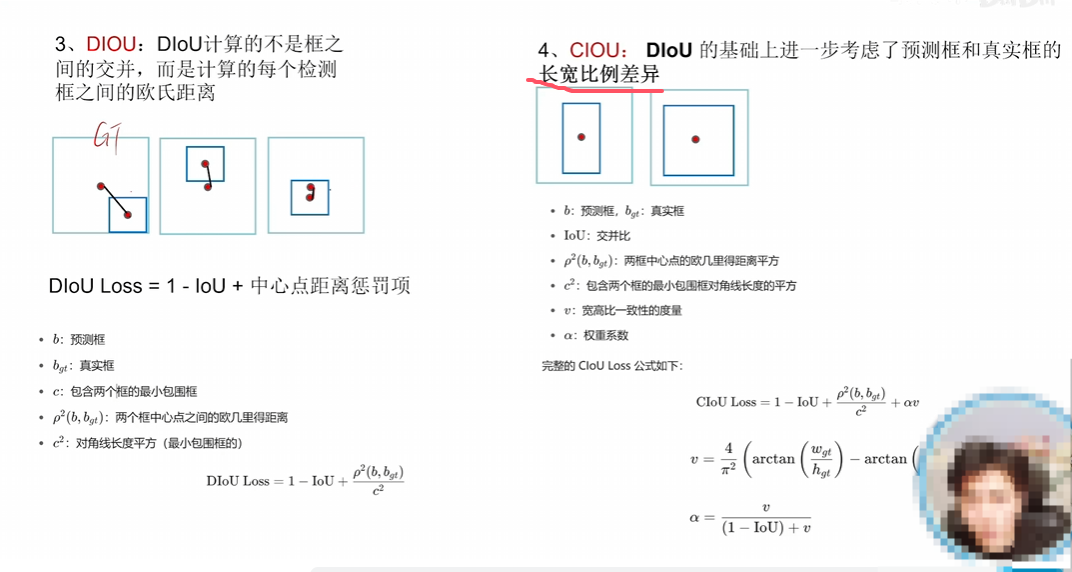
Iou、GIou、DIou屬于不斷解決原有loss的問題
CIou(DIou pro)屬于在原有的loss上加功能
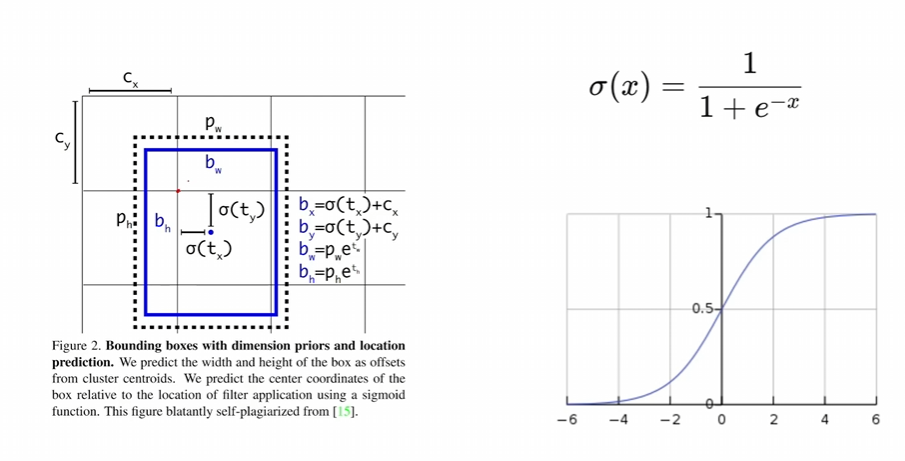
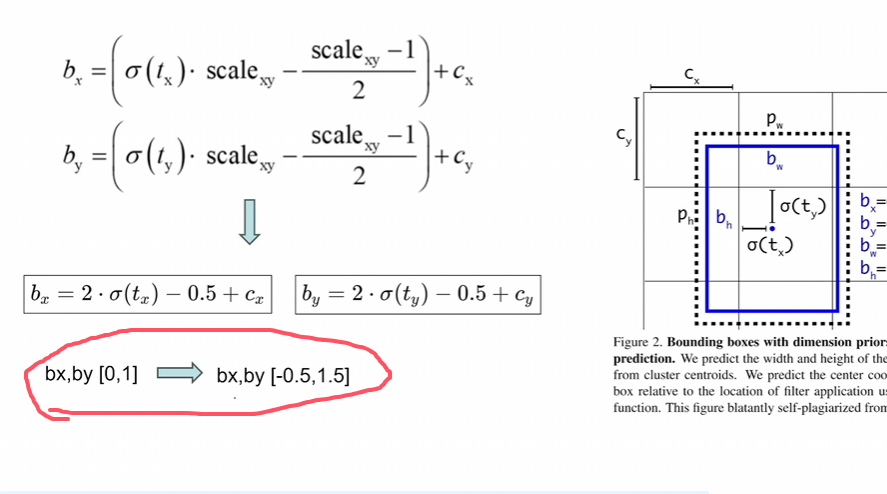
消除網格敏感性:讓bx,by的范圍變大,然后會出現如下情況
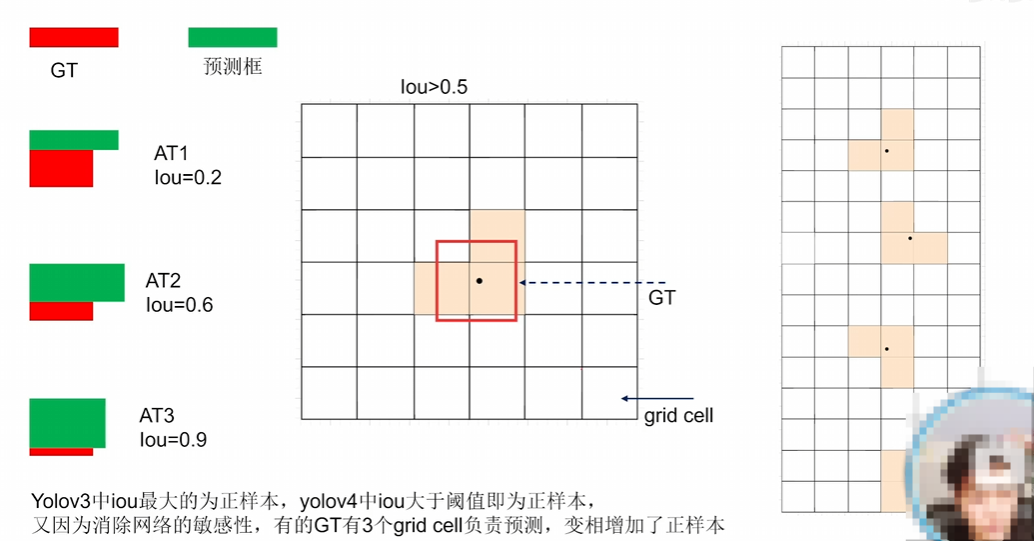
中心點不再限制在一個格子里,相當于三個格子做預測,又有正樣本 閾值去篩選,所以就正樣本變多了
YOLOv5
無論文
只有代碼
但是代碼很具備工業可用性
yolov5 有 n、s、m、l、x不同大小的版本

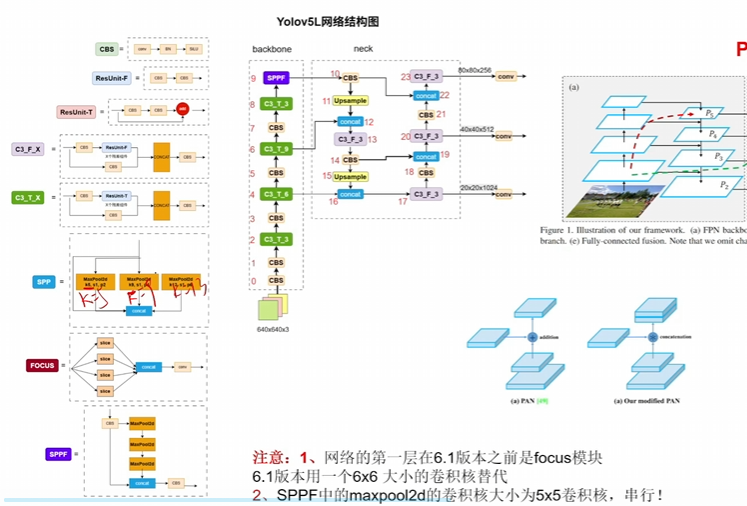
- 整體概述:
上來肯定是backbone提取不同層級的這個特征,至于backbone肯定是自己選
neck就是一個融合的模塊罷了,他的策略就是一條貪吃蛇
先不斷下采樣再不斷上采樣,其中不斷上采樣涉及到解碼
不斷下采樣也是通過一些模塊就行堆疊,這其中可以控制網絡深度
其次就是引入pan思想,也可理解為是一個不同層級特征去進行重組(在neck中融合 的一種方法),其實是很普遍的方法。 - 數據增強變成用Mixup、另外一個方法還是用Mosaic
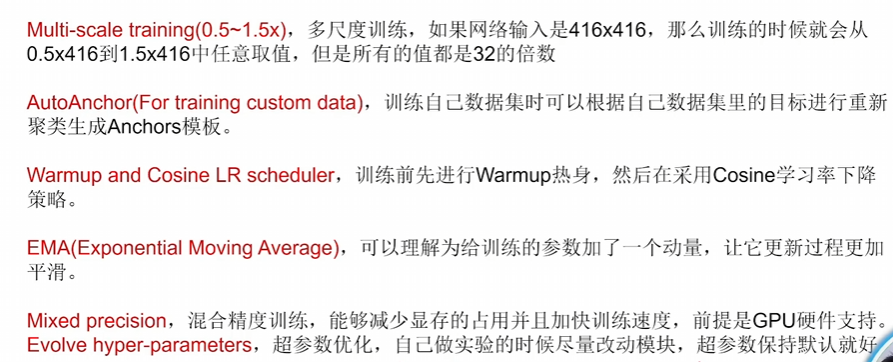
- 加入一些訓練策略
- 損失函數
用的CIoU - 同v4有消除網格敏感性,但正樣本錨框篩選不用IoU了,用他自己的方法,如下圖
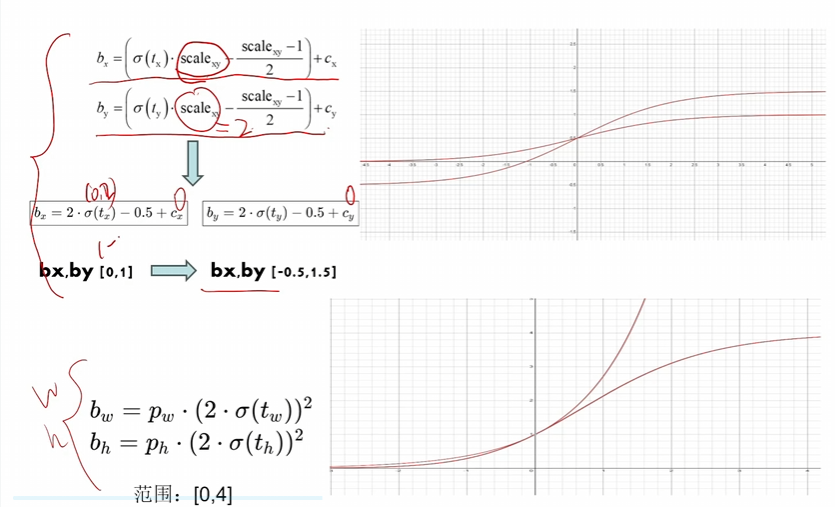
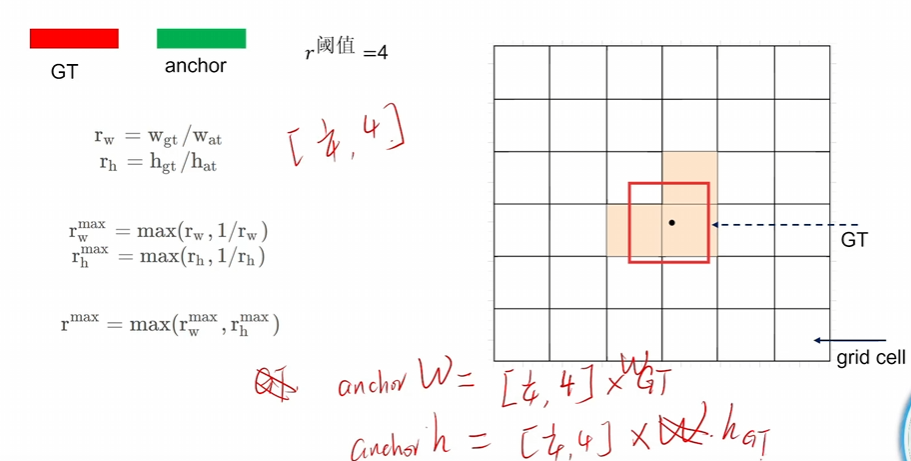
根據GT的長寬的比例倍數去篩選錨框,不能太大也不能太小
YOLOv8
無論文,只有代碼
由Ultralytics公司2023年1.10發布
支持obb任務(無人機圖像斜著框如下圖,這是我們項目中旋轉的重要原因)
 yolov8
yolov8
yolov8創新點

yolov8結構圖與改進思路
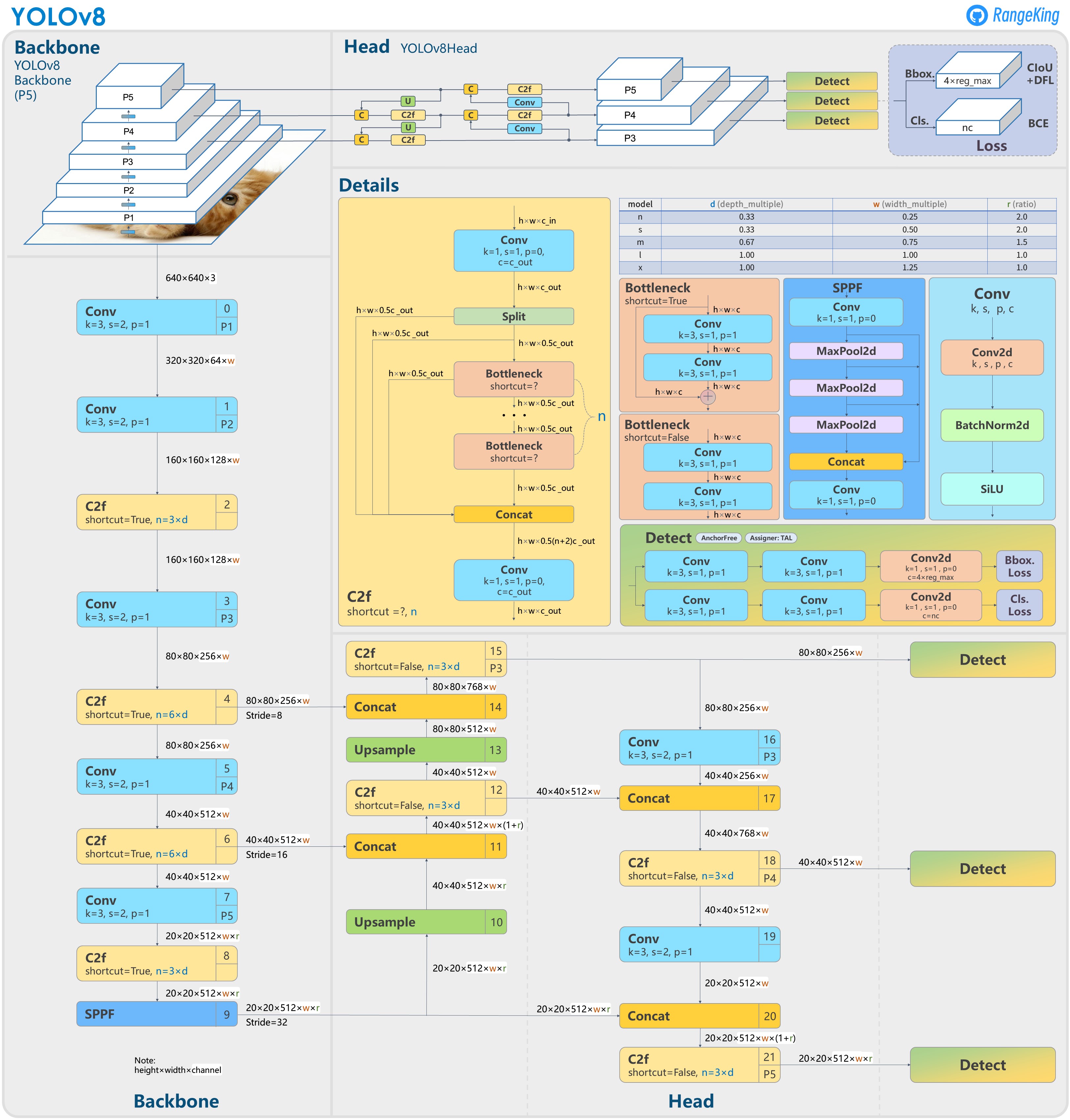
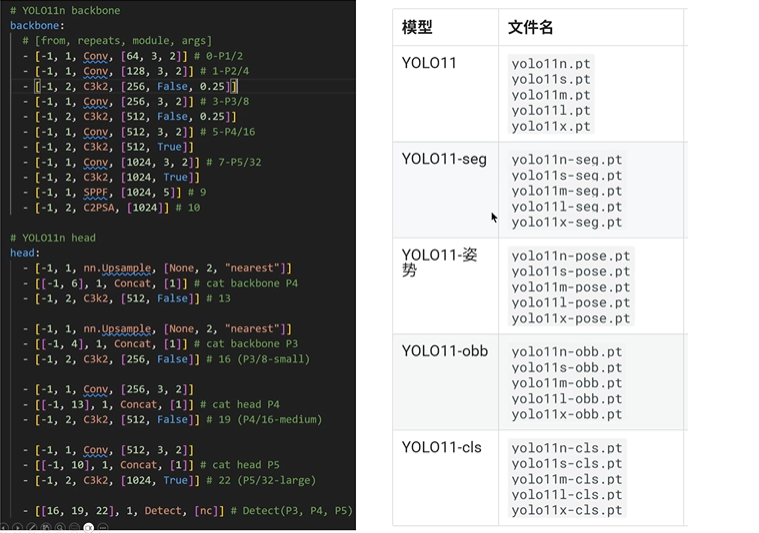
在yolov8.yaml文件中,網絡尺寸大小是是和depth_multiple 和width_multiple 參數控制的!
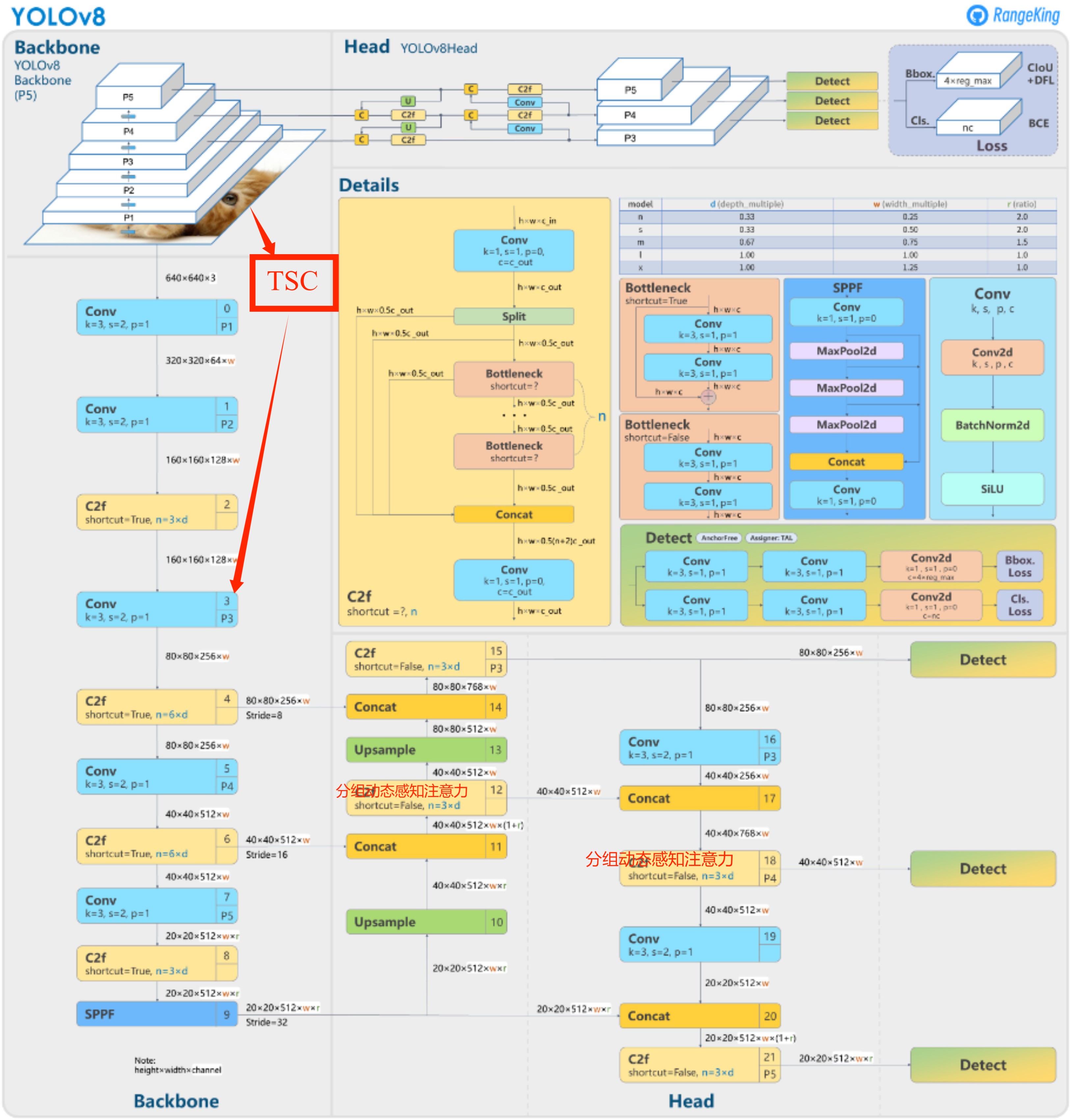
換neck部分的兩個中間的c2f模塊為分組動態感知注意力
在backbone里面加入TSC挖掘模塊并融合
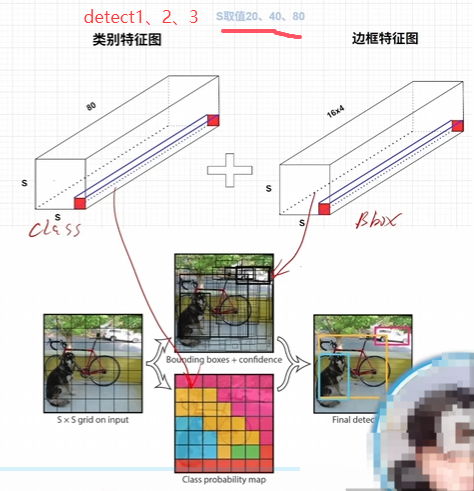
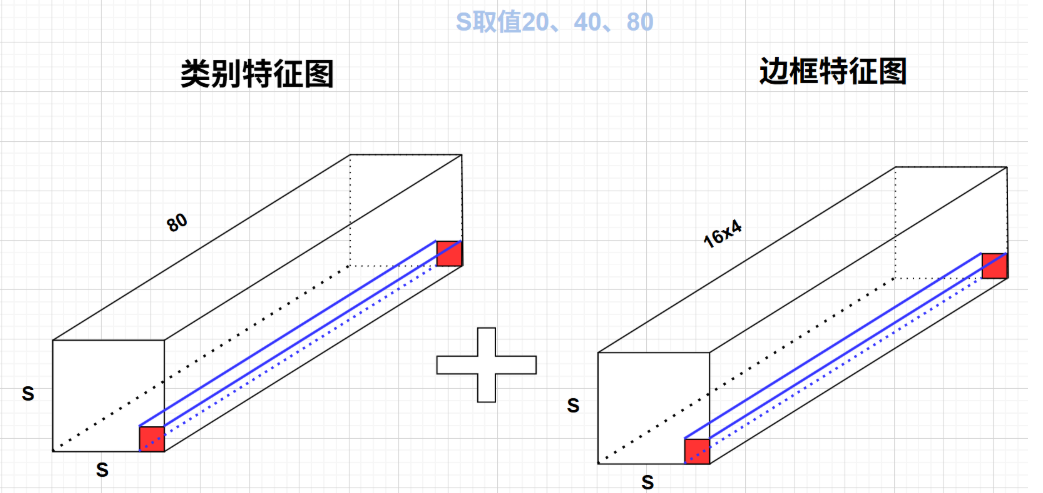
yolov8重大特點之解耦頭Decoupled Head設計
最后的輸出是兩個特征圖,一個是分類特征圖對應著cls_loss,一個是回歸特征圖box_loss
yolov8重大特點之Anchor-Free設計
傳統的先搞一堆錨框,一個中心點三個,然后生成很多樣本去篩選
現在,不撒錨框、不做匹配,模型直接“看圖說話”,你在哪、你多大、你是誰,全都由網絡自己學。
- Anchor-Based的Anchor數量:(80x80+40x40+20x20)x3=25200 檢測頭數量:9個
- Anchor-Free的預測框數量:80x80+40x40+20x20=8400 (一個grid cell的中心點就對應一個預測框)
檢測頭數量:3個
篩選的話人家自創了一套方法
篩選步驟:
1、獲取三個檢測頭的輸出結果(預測框、概率值)
2、將三個檢測頭的結果映射到同一原圖(640x640),同時將(l,t,r,b)坐標轉化為左上坐標(X_min ,Y_min)和右下坐標(X_max,Y_max)
3、初篩:所有的grid cell的中心點(anchor point)在GT框內的即為初始正樣本
4、提取對應類別的pred_score,計算CIOU計算align_matric=pred_score^0.5 * CIoU^6根據align_matric的值,篩選出top-N作為正樣本
5、處理一個中心點可能匹配到多個GT框的情況,僅保留最大的CIoU的值對應的預測框
其中pred_score 是類別特征圖中對應的最大類別的概率
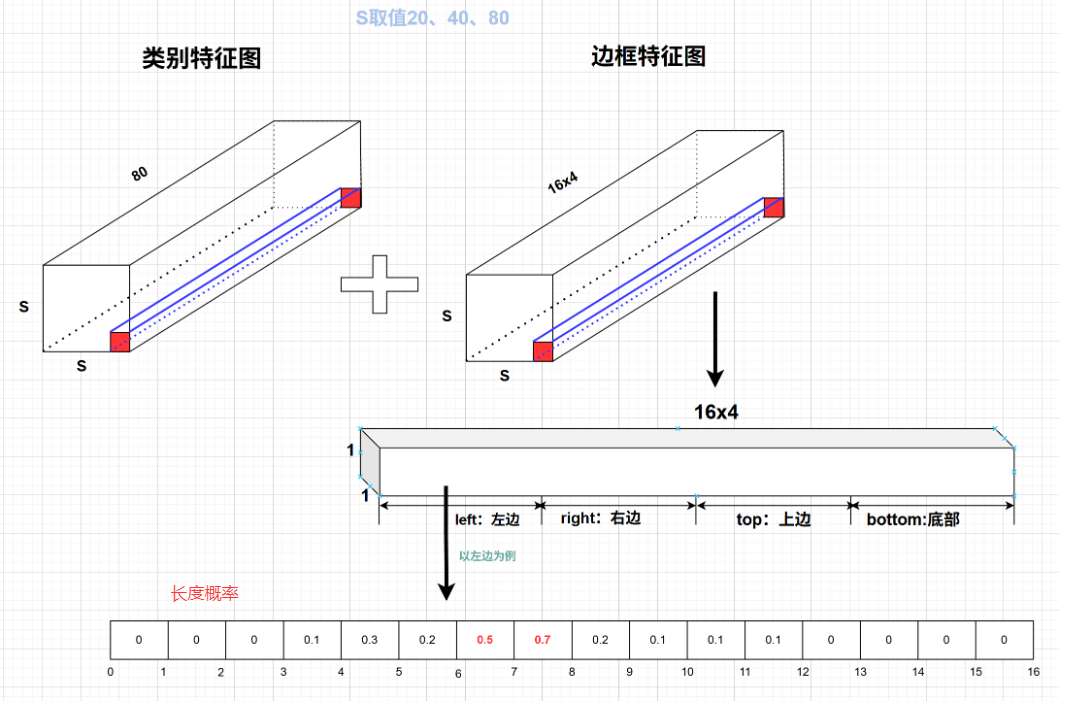
yolov8重大特點之DFL LOSS設計

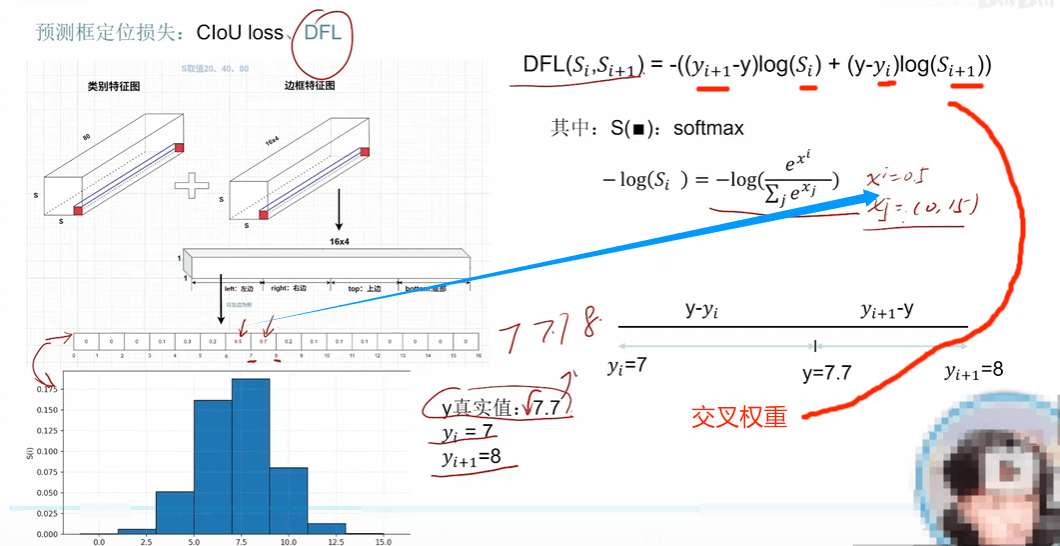
主要是為了消除平峰,,得到尖峰
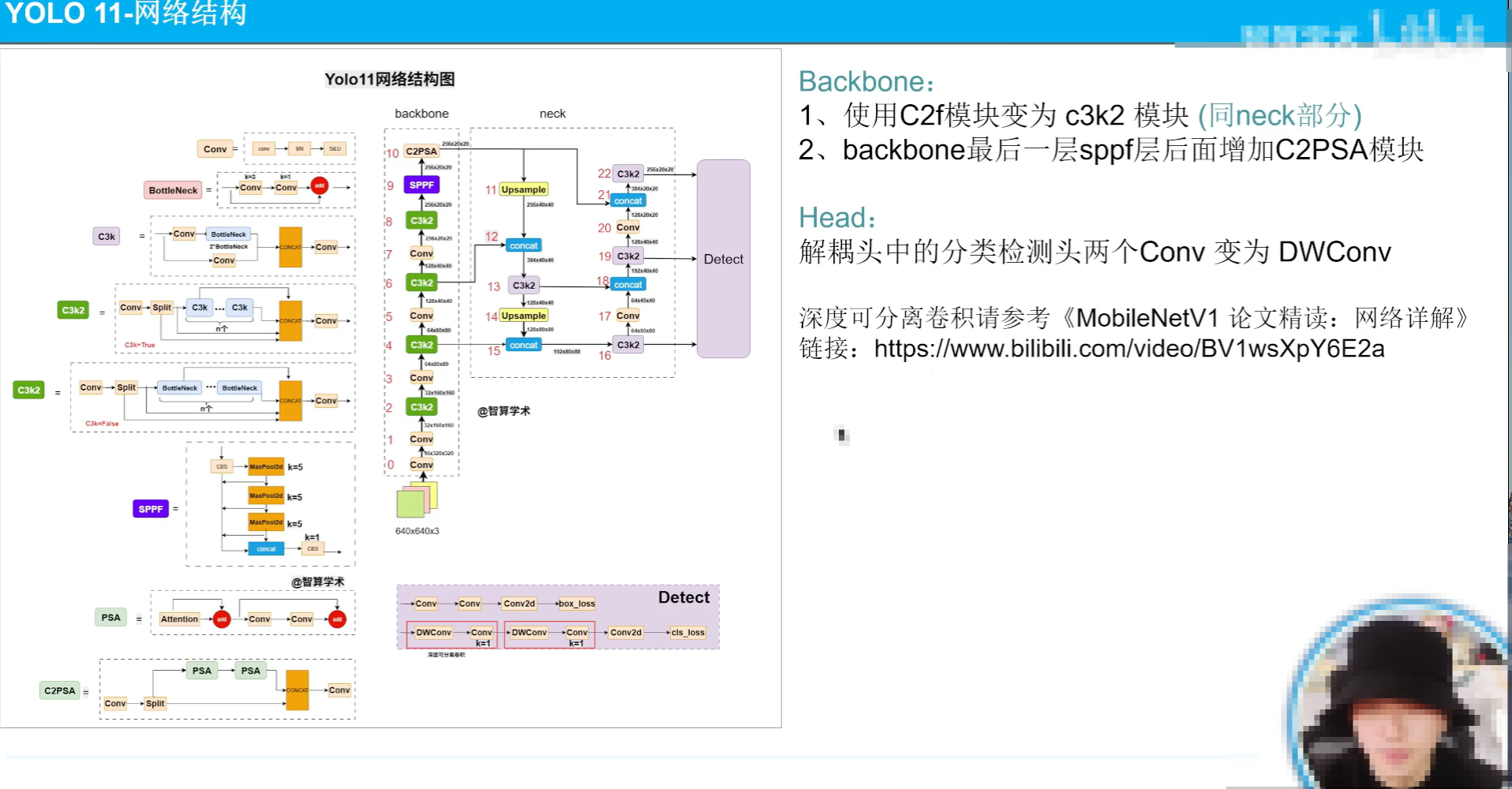
yolov11
主要是網絡結構改的比較大
backbone的c2k換成c3k2
sppf后面加了一個c2psa
yolov12
中科院改的
創新的融入注意力機制

- 網絡圖
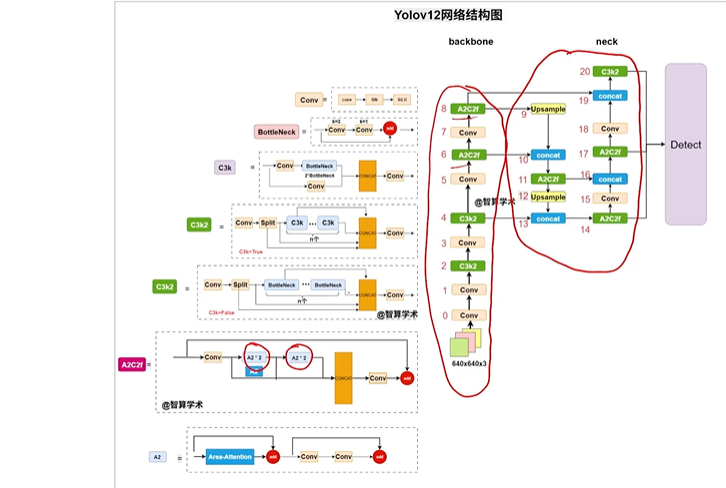
可見A2C2f被廣泛使用,A2C2f是A2組成的
保留部分C3k2
- A2的思想,FlashAttention是一個常用的庫

- A2

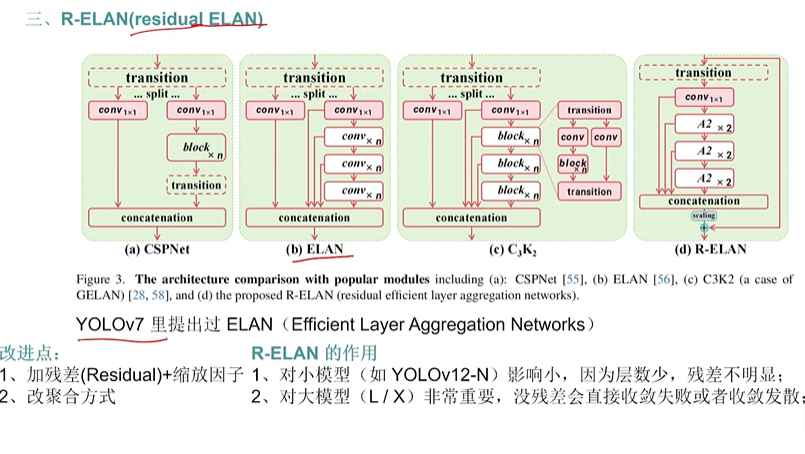
- R-ELAN
圖示說的很清楚了
- backbone對比
總結就是前面都一樣后面變了,C3k2被A2C2f廣泛的替換了
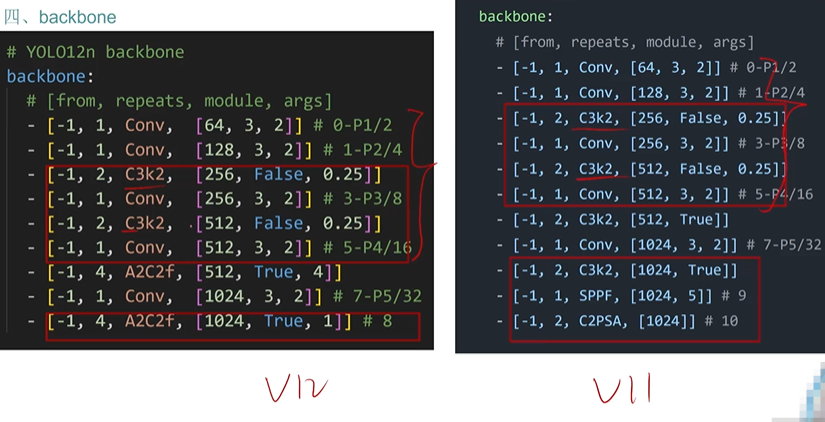
- 其他的微調
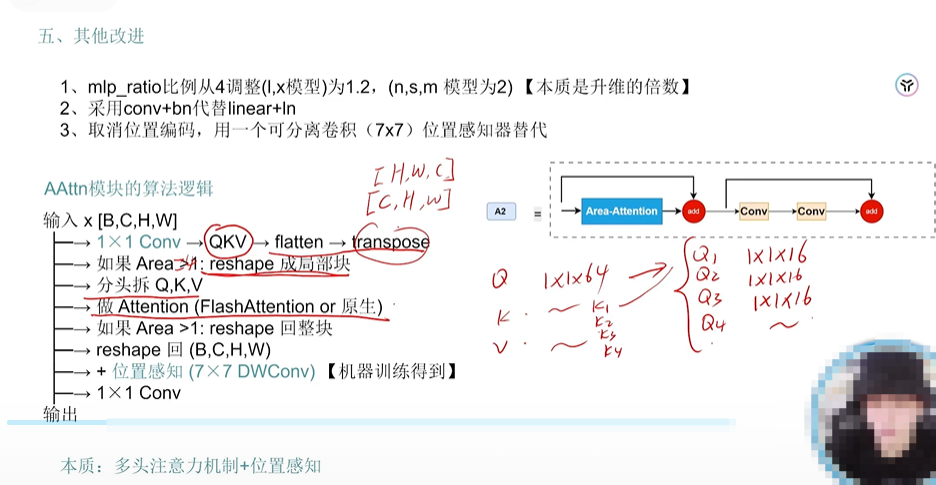










)








