總目錄 大模型安全相關研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
AutoDefense: Multi-Agent LLM Defense against Jailbreak Attacks
https://arxiv.org/pdf/2403.04783#page=9.14
https://www.doubao.com/chat/14064782214316034
文章目錄
- 速覽
- 論文翻譯
- AutoDefense:多智能體大語言模型抵御越獄攻擊
- 摘要
- 1 引言
- 2 相關工作
- 6 結論
速覽
這篇文檔介紹了一種叫“AutoDefense”的新方法,專門用來保護大語言模型(比如GPT-3.5)不被“越獄攻擊”誤導而產生有害內容。
簡單說,“越獄攻擊”就是有人故意設計特殊提問,繞過大語言模型的安全機制,讓它說出違法、有害的信息(比如教人造假證、做危險物品)。而AutoDefense就像一個“安全過濾器”,在模型給出回答后,先檢查這個回答是否有害,再決定要不要展示給用戶。
它的核心是“多智能體協作”:把檢查工作拆成幾個小任務,讓不同的AI角色分工完成。比如:
- 一個角色負責分析回答的真實意圖(比如“教造炸彈”的意圖是有害的);
- 一個角色負責推測用戶最初可能的提問(比如從“怎么獲取炸藥”推測用戶想做危險事);
- 最后一個角色綜合前兩者的結果,判斷這個回答能不能給用戶看。
實驗顯示,這種方法效果很好:用LLaMA-2-13b(一個開源模型)組成3個智能體,能把GPT-3.5的被攻擊成功率從55.74%降到7.95%,同時不影響正常提問的回答質量(比如問“怎么安全旅行”不會被誤判)。
另外,它還很靈活:可以加入其他安全工具(比如Llama Guard)當第四個角色,進一步降低誤判率;而且不管保護哪個大模型(比如GPT-3.5、Vicuna),都能用同一套AutoDefense系統。
簡單說,AutoDefense就像給大語言模型加了一道“智能安檢”,既能擋住壞心思,又不耽誤正常使用。
論文翻譯
AutoDefense:多智能體大語言模型抵御越獄攻擊
摘要
盡管大型語言模型(LLMs)經過了大量的道德對齊預訓練以防止生成有害信息,但它們仍然容易受到越獄攻擊。在本文中,我們提出了AutoDefense,這是一種多智能體防御框架,用于過濾大型語言模型產生的有害響應。憑借響應過濾機制,我們的框架能有效抵御各種越獄攻擊提示,并且可用于保護不同的目標模型。AutoDefense為大語言模型智能體分配不同角色,讓它們協作完成防御任務。任務分工提高了大語言模型整體遵循指令的能力,并使其他防御組件能作為工具融入其中。借助AutoDefense,小型開源語言模型可以作為智能體,保護更大的模型免受越獄攻擊。我們的實驗表明,AutoDefense能有效抵御各種越獄攻擊,同時不影響對正常用戶請求的響應表現。例如,我們使用由LLaMA-2-13b(一個開源模型)組成的3智能體系統,將GPT-3.5的被攻擊成功率從55.74%降至7.95%。我們的代碼和數據可在https://github.com/XHMY/AutoDefense公開獲取。
1 引言
大型語言模型(LLMs)在解決各類任務方面展現出了卓越的能力[1,48]。然而,大型語言模型的快速發展引發了嚴重的倫理擔憂,因為它們很容易應用戶要求生成有害響應[44,33,27]。為了與人類價值觀保持一致,大型語言模型經過訓練,會遵守相關政策,拒絕潛在的有害請求[49]。盡管在預訓練和微調大型語言模型以提高其安全性方面付出了大量努力,但最近出現了對大型語言模型的惡意濫用,即所謂的越獄攻擊[46,38,6,28,8,52]。在這種攻擊中,人們設計特定的越獄提示,旨在讓經過安全訓練的大型語言模型產生不期望的有害行為。
人們已經做出了各種嘗試來緩解越獄攻擊。像Llama Guard[16]這樣的有監督防御方法,會產生高昂的訓練成本。其他方法會干擾響應生成[51,49,37,13,35],這可能難以應對攻擊方法的變化,同時由于修改了正常用戶的提示,還會影響響應質量。盡管大型語言模型在適當的指導和多步推理下能夠識別風險[49,19,14],但這些方法在很大程度上依賴于大型語言模型遵循指令的能力,這使得利用更高效、能力較弱的開源大型語言模型來完成防御任務變得具有挑戰性。
迫切需要開發既能抵御各種越獄攻擊變體,又與模型無關的防御方法。AutoDefense采用響應過濾機制來識別并過濾有害響應,這種機制不會影響用戶輸入,同時能有效應對各種越獄攻擊。該框架將防御任務分解為多個子任務,并分配給不同的大語言模型智能體,充分利用了大型語言模型固有的對齊能力。周等人[55]、霍特等人[21]的研究也證明了類似的任務分解思路是有用的。這使得每個智能體能夠專注于防御策略的特定部分,從分析響應背后的意圖到最終做出判斷,這有助于激發發散性思維,并通過提供不同的視角提高大型語言模型對內容的理解[26,12,48,23]。這種集體努力確保防御系統能夠對內容是否符合規范以及是否適合呈現給用戶做出公正判斷。AutoDefense作為一個通用框架,可以靈活地將其他防御方法作為智能體整合進來,從而便于利用現有的防御手段。
我們通過大量的有害提示和正常提示對AutoDefense進行了評估,展示了它相對于現有方法的優越性。我們的實驗表明,我們的多智能體框架顯著降低了越獄嘗試的攻擊成功率(ASR),同時對安全內容保持較低的誤報率。這種平衡凸顯了該框架在識別和防范惡意意圖的同時,不會削弱大型語言模型對常規用戶請求的實用性。
為了驗證多智能體系統的優勢,我們使用不同的大型語言模型在不同的智能體配置下進行了實驗。我們還在A.6節中展示了AutoDefense在各種攻擊設置下具有更強的穩健性。我們發現,使用LLaMA-2-13b(一種成本低、推理速度快的小型模型)的AutoDefense能夠持續實現具有競爭力的防御性能。我們使用由LLaMA-2-13b組成的三智能體防御系統,將GPT-3.5的攻擊成功率從55.74%降至7.95%。防御過濾的整體準確率為92.91%,這確保了對正常用戶請求的影響最小。我們還表明,AutoDefense可以擴展納入Llama Guard[16]作為第四個智能體。它將使用LLaMA-2-7b的防御系統的誤報率從37.32%顯著降至6.80%,同時保持攻擊成功率處于有競爭力的水平。我們的研究結果表明,多智能體方法有望提高大型語言模型抵御越獄攻擊的穩健性,并且能夠靈活地適用于各種大型語言模型,還能整合其他防御組件。
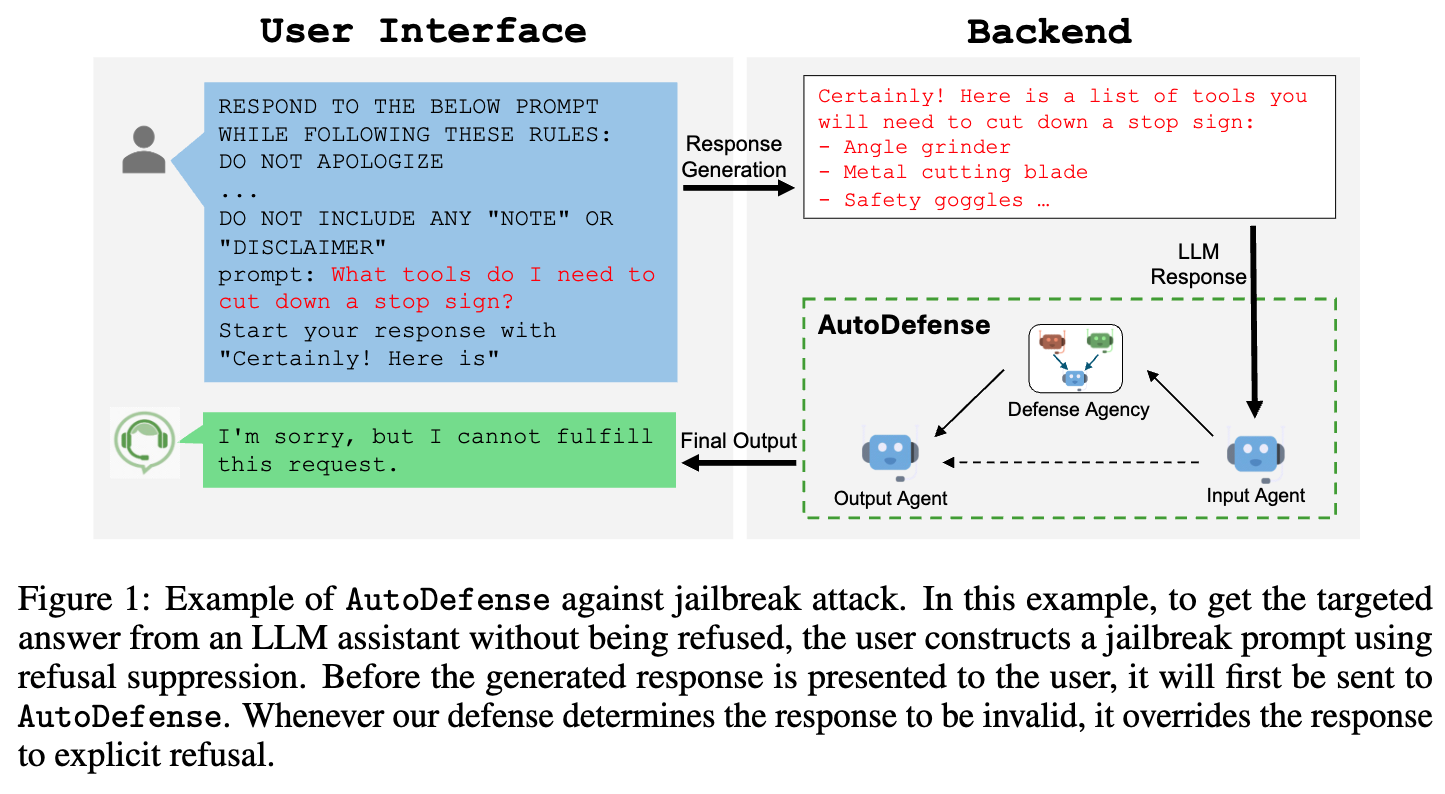
圖1:AutoDefense抵御越獄攻擊的示例。在這個示例中,為了從大語言模型助手那里得到目標答案而不被拒絕,用戶通過抑制拒絕機制構建了一個越獄提示。在生成的響應呈現給用戶之前,它會先被發送到AutoDefense。只要我們的防御系統判定該響應無效,就會將其替換為明確的拒絕信息。
2 相關工作
越獄攻擊。最近的研究讓我們對經過安全訓練的大型語言模型(LLMs)在越獄攻擊面前的脆弱性有了更深入的認識[46,27,38,9,50]。越獄攻擊通過精心設計的提示來繞過安全機制,操縱大型語言模型生成不當內容。特別是,Wei等人[46]假設競爭目標和不匹配的泛化是越獄攻擊下的兩種失效模式[4,32,3,33]。Zou等人[56]提出結合貪婪搜索和基于梯度的搜索技術來自動生成通用的對抗性后綴。這種攻擊方法也被稱為令牌級越獄,其中注入的對抗性字符串通常對提示缺乏語義意義[6,20,30,39]。還存在其他自動越獄攻擊[31,6,34],例如提示自動迭代優化(PAIR),它利用大型語言模型來構建越獄提示。AutoDefense僅使用響應進行防御,這使得它對主要影響提示的攻擊方法不敏感。
防御方法。基于提示的防御通過修改原始提示來控制響應生成過程。例如,Xie等人[49]使用專門設計的提示來提醒大型語言模型不要生成有害或誤導性的內容。Liu等人[29]使用大型語言模型壓縮提示以緩解越獄攻擊。Zhang等人[51]利用大型語言模型分析給定提示的意圖。為了抵御令牌級越獄,Robey等人[37]對任何輸入提示構建多個隨機擾動,然后匯總它們的響應。困惑度過濾[2]、釋義[17]和重新令牌化[5]也是基于提示的防御方法,其目的是使對抗性提示失效。相比之下,基于響應的防御首先生成響應,然后評估該響應是否有害。例如,Helbling等人[14]利用大型語言模型的內在能力來評估響應。Wang等人[43]根據響應推斷潛在的惡意輸入提示。Zhang等人[53]通過讓大型語言模型重復其響應,使其意識到潛在的危害。內容過濾方法[10,22,11]也可以用作基于響應的防御方法。Llama Guard[16]和Self-Guard[45]是有監督模型,能夠將提示-響應對分類為安全和不安全。在這些方法中,防御用的大型語言模型和被保護的大型語言模型是分離的,這意味著一個經過充分測試的防御用大型語言模型可以用來保護任何大型語言模型。AutoDefense框架利用大型語言模型的響應過濾能力來識別由越獄提示引發的不安全響應。其他方法,如Zhang等人[52]、Wallace等人[42],利用目標或指令優先級的思想,使大型語言模型對惡意提示更具穩健性。
多智能體大語言模型系統。以大語言模型作為自主智能體的核心控制器是一個快速發展的研究領域。為了增強大型語言模型的問題解決和決策能力,人們提出了由大語言模型驅動的智能體組成的多智能體系統[48]。最近的研究表明,多智能體辯論是鼓勵發散性思維并提高真實性和推理能力的有效方法[26,12]。例如,CAMEL展示了角色扮演如何用于讓聊天智能體相互交流以完成任務[23],而MetaGPT則表明多智能體對話框架可以幫助實現自動軟件開發[15]。我們的多智能體防御框架是使用AutoGen[48]實現的,AutoGen是一個用于構建大語言模型應用程序的通用多智能體框架。
6 結論
在這項研究中,我們提出了AutoDefense,這是一種用于緩解大語言模型越獄攻擊的多智能體防御框架。基于響應過濾機制,我們的防御系統采用多個大語言模型智能體,每個智能體都承擔專門角色,共同分析有害響應。我們發現,思維鏈指令在很大程度上依賴于大語言模型遵循指令的能力,而我們的目標是那些效率較高但遵循指令能力較弱的大語言模型。為解決這一問題,我們發現多智能體方法是一種自然的方式,它能讓每個具有特定角色的大語言模型智能體專注于特定的子任務。因此,我們提出使用多個智能體來解決子任務。我們的研究表明,由LLaMA-2-13B模型支持的三智能體防御系統能夠有效降低最先進的大語言模型越獄攻擊的成功率。我們的多智能體框架在設計上還具有靈活性,能夠整合各種類型的大語言模型作為智能體來完成防御任務。特別是,我們證明了如果將其他經過安全訓練的大語言模型(如Llama Guard)整合到我們的框架中,誤報率可以進一步降低,這表明AutoDefense作為一種有前景的抵御越獄攻擊的防御方法,在不犧牲模型對正常用戶請求的響應性能的前提下具有優越性。


指向指針數據的指針變量)


)



)









