Amazon S3(Amazon Simple Storage Service)即亞馬遜簡單存儲服務,是 AWS(Amazon Web Services)提供的一種對象存儲服務,在大數據領域被廣泛使用。以下是關于它的詳細介紹:
基本概念
Amazon S3 主要用于存儲和檢索任意數量的數據。這里的數據以對象(Object)的形式存在,每個對象由數據本身、鍵(Key,類似于文件名,用于唯一標識對象)和元數據(Metadata,如文件大小、創建時間、自定義標簽等信息)組成。對象被存儲在存儲桶(Bucket)中,存儲桶可以看作是存放對象的容器, 它有一個在全球范圍內唯一的名稱,用戶可以創建多個存儲桶,并對存儲桶和其中的對象進行管理。
主要特點
- 高持久性:Amazon S3 設計目的是為了實現數據的高持久性,承諾提供 99.999999999%(11 個 9)的對象持久性。這意味著數據丟失的可能性極低,它通過在多個設施和多個設備上自動存儲數據的多個副本,來確保即使在出現硬件故障、自然災害等意外情況時,數據也不會丟失。
- 無限可擴展性:S3 能夠存儲幾乎無限量的數據,無論是少量的文件還是 PB 級甚至 EB 級的海量數據,都可以輕松存儲。用戶不需要擔心存儲容量的限制,并且可以根據實際存儲需求自動擴展。
- 高可用性:具有較高的可用性,能夠保證用戶可以隨時訪問存儲的數據。AWS 在全球分布有多個區域(Region)和可用區(Availability Zone),用戶可以選擇將數據存儲在離自己較近或符合業務需求的區域,同時,S3 會在可用區內自動復制數據,以保障數據的高可用性。
- 安全可靠:提供了多種安全功能,包括身份驗證(通過 AWS 訪問密鑰進行用戶身份驗證)、訪問控制(可以使用訪問控制列表 ACL 和桶策略來管理對存儲桶和對象的訪問權限)、數據加密(支持靜態加密,包括 S3 托管密鑰 SSE - S3、AWS Key Management Service 托管密鑰 SSE - KMS 以及客戶管理密鑰 CSE - CKM)等,確保數據的安全性。
- 靈活性:支持各種類型的數據存儲,包括文本文件、圖像、視頻、備份數據、日志文件、數據庫轉儲等。并且提供了豐富的 API(Application Programming Interface),可以通過編程方式與 S3 進行交互,方便集成到各種應用程序和工作流程中 。
應用場景
- 數據湖:作為構建數據湖的基礎存儲,用于集中存儲來自不同數據源(如業務系統數據庫、物聯網設備、移動應用等)的結構化、半結構化和非結構化數據,以便后續進行數據分析、機器學習等操作。例如,電商公司可以將用戶訂單數據、商品信息、用戶行為日志等各種數據都存儲在 S3 中,然后通過大數據分析工具進行深入挖掘,了解用戶購買行為和偏好。
- 數據備份與存檔:適合長期保存不經常訪問但需要保留的數據,如企業的歷史交易記錄、醫療記錄、法律合規文件等。S3 提供了不同的存儲級別(如標準存儲、標準 - infrequent Access(標準 IA)、One Zone - Infrequent Access(單區 IA)、Glacier、Glacier Deep Archive 等),用戶可以根據數據的訪問頻率和保留期限,選擇成本最優的存儲級別。
- 內容分發:可以與 Amazon CloudFront(內容分發網絡 CDN)結合使用,用于快速分發網站內容、軟件安裝包、視頻流等。CloudFront 會在全球的邊緣位置緩存 S3 中的內容,使用戶能夠從離自己最近的位置獲取數據,提高訪問速度和用戶體驗。
- 大數據處理:與 AWS 上的其他大數據服務(如 AWS Glue、Amazon EMR 等)緊密集成。例如,Amazon EMR 集群可以直接讀取和處理存儲在 S3 中的數據,進行大規模的數據處理和分析任務,如日志分析、數據清洗、機器學習模型訓練等。
AWS Glue 是亞馬遜云服務(AWS)提供的一項無服務器(Serverless)數據集成服務,專注于元數據管理和 ETL(Extract,Transform,Load,即提取、轉換、加載)操作。以下為你詳細介紹:
無服務器(Serverless)特性
- 無需管理基礎設施:使用 AWS Glue 時,用戶無需操心服務器的配置、搭建、維護等工作,比如硬件選型、軟件安裝與更新、服務器的日常監控等。AWS 會自動處理底層資源的分配、擴展和維護,極大地減少了運維成本和工作量。
- 按需付費:AWS Glue 根據實際使用的資源(如執行 ETL 作業的時長、處理的數據量等)來計費。在沒有作業運行時,用戶無需支付計算資源的費用,相比傳統的自管理服務器方式,成本更加可控,尤其適合數據處理量有較大波動的場景。
元數據管理
- 數據目錄(Data Catalog):這是 AWS Glue 元數據管理的核心組件,它是一個集中式的存儲庫,用于存儲和管理數據資產的元數據信息,包括數據庫、表、分區等。例如,在一個電商數據湖中,Data Catalog 可以記錄用戶訂單表、商品信息表等的表結構(字段名稱、數據類型、長度等)、數據存儲位置(如存儲在 Amazon S3 的具體路徑)、表的分區方式(按日期分區、按地區分區等)。
- 爬蟲(Crawlers):這是 AWS Glue 用于自動發現和提取元數據的工具。用戶可以配置爬蟲,讓它掃描各種數據源,比如 Amazon S3 存儲桶、關系型數據庫(如 Amazon RDS 中的 MySQL、PostgreSQL 等)、NoSQL 數據庫(如 Amazon DynamoDB)等。爬蟲會自動識別數據格式(CSV、JSON、Parquet 等),并將解析出的元數據寫入 Data Catalog 。比如,當新一批用戶行為日志數據被上傳到 S3,配置好的爬蟲就可以快速識別日志文件的結構,將相關元數據添加到 Data Catalog,方便后續分析。
- 統一視圖:Data Catalog 為不同數據源提供了統一的元數據視圖,使得不同的分析工具(如 Amazon EMR 上的 Hive、Spark,Amazon Athena 等)可以共享和訪問這些元數據,避免了重復定義元數據的麻煩,提高了數據發現和使用的效率。
ETL 功能
- 可視化界面與代碼編寫:AWS Glue 提供了可視化的 ETL 作業編輯器,用戶可以通過簡單的拖拽操作來定義數據的提取、轉換和加載流程,無需編寫大量代碼,降低了 ETL 開發的門檻。同時,也支持使用 Python、Scala 等編程語言編寫自定義的轉換邏輯,以滿足復雜的數據處理需求。例如,對于一個包含用戶注冊信息的 CSV 文件,用戶可以在可視化界面中輕松設置提取特定字段(如用戶名、郵箱、注冊時間),對郵箱進行格式校驗和脫敏等轉換操作,然后將處理后的數據加載到目標數據庫中。
- 豐富的內置轉換:AWS Glue 內置了多種常見的數據轉換功能,如數據類型轉換(將字符串類型的日期轉換為日期類型)、數據清洗(去除重復記錄、填充缺失值)、數據聚合(求和、平均值計算等)、數據過濾(篩選出特定地區的用戶數據)等。這些內置轉換可以通過可視化界面快速配置,加快 ETL 作業的開發速度。
- 與其他 AWS 服務集成:AWS Glue 可以與 Amazon S3、Amazon Redshift、Amazon EMR 等眾多 AWS 服務無縫集成。比如,從 S3 中提取原始數據進行處理,將處理后的數據加載到 Redshift 用于數據分析;或者將 ETL 作業提交到 EMR 集群上運行,利用 EMR 的計算資源處理大規模數據。
典型應用場景
- 構建數據湖:在數據湖架構中,使用 AWS Glue 的爬蟲發現和管理存儲在 S3 中的各種數據的元數據,通過 ETL 作業清洗、轉換數據,為后續的數據分析師、數據科學家提供高質量的分析數據。
- 數據倉庫 ETL:將不同數據源(如業務系統數據庫、日志文件)的數據,通過 AWS Glue 進行 ETL 處理后,加載到數據倉庫(如 Amazon Redshift)中,支持業務報表生成、決策支持等場景。
- 數據遷移:當需要將數據從一個數據源遷移到另一個數據源時,AWS Glue 可以幫助進行數據提取、格式轉換和加載,實現數據的平滑遷移,比如從本地數據庫遷移到 AWS 上的數據庫。
Amazon EMR on EC2(Elastic MapReduce on Amazon Elastic Compute Cloud )是 AWS(Amazon Web Services)提供的一項托管式大數據分布式計算服務,主要用于運行 Apache Hadoop、Apache Spark、Apache Flink 等開源分布式計算框架集群,幫助用戶輕松處理和分析大規模數據。以下是詳細介紹:
服務概述
- 托管服務:AWS 負責處理集群的搭建、配置、監控和維護等繁瑣工作,比如安裝和配置 Hadoop、Spark、Flink 等軟件,管理集群節點的硬件資源(CPU、內存、存儲等)。用戶無需關心底層基礎設施的運維細節,專注于數據分析和應用開發。
- 基于 EC2:利用 Amazon EC2(彈性計算云)的資源來創建集群節點。EC2 提供了多種類型的實例(如計算優化型、內存優化型、存儲優化型等),用戶可以根據具體的計算任務需求,靈活選擇合適的實例類型構建集群,并且可以根據數據處理量的大小動態地增加或減少集群節點數量,實現資源的彈性伸縮。
支持的計算框架
- Apache Hadoop:
- 批處理:作為 Hadoop 生態系統的核心,MapReduce 是 Hadoop 的經典計算模型,適用于大規模數據集的離線批處理作業。例如,對電商平臺海量的歷史訂單數據進行統計分析(如計算各地區的銷售額、各類商品的銷售數量等),可以將數據存儲在 Hadoop 分布式文件系統(HDFS)中,通過 EMR 上的 Hadoop 集群運行 MapReduce 作業來完成計算任務。
- 數據存儲:HDFS 提供了高吞吐量的數據訪問,能夠存儲 PB 級的大規模數據,并且通過數據副本機制保證數據的可靠性和可用性。
- Apache Spark:
- 通用計算引擎:Spark 比 MapReduce 具有更高的執行效率,支持多種編程模型,如批處理、流處理、機器學習和圖計算等。在 EMR 上,用戶可以使用 Spark 進行復雜的數據處理任務,例如在實時推薦系統中,利用 Spark Streaming 處理用戶實時行為數據,結合機器學習算法(MLlib)為用戶實時推薦感興趣的商品。
- 內存計算:Spark 能夠將數據緩存到內存中進行計算,減少對磁盤 I/O 的依賴,大大加快了數據處理速度,尤其適合迭代式計算(如機器學習中的梯度下降算法)和交互式數據分析。
- Apache Flink:
- 實時流處理:Flink 是一個強大的流處理框架,具有低延遲、高吞吐和準確的語義保證。在 EMR 上運行 Flink,可以用于處理實時數據,如實時監控網絡流量、金融交易實時風控等場景。例如,對股票交易的實時數據流進行處理,及時發現異常交易行為并觸發警報。
- 批處理能力:除了流處理,Flink 也支持批處理,并且在批處理性能上表現出色,能夠高效處理大規模的靜態數據集。
優勢
- 彈性伸縮:用戶可以根據業務需求和數據量的變化,通過簡單的操作(如 API 調用、控制臺操作)動態地增加或減少集群節點數量。比如在業務高峰期,增加節點以提高數據處理速度;在業務低谷期,減少節點以降低成本。
- 高可用性:通過多可用區部署、數據備份與恢復等機制,保證集群的高可用性。即使某個節點或可用區出現故障,集群也能繼續運行,并且數據不會丟失。
- 豐富的生態集成:無縫集成 AWS 其他服務,如 Amazon S3(作為數據存儲)、AWS Glue(用于數據集成和元數據管理)、Amazon Redshift(數據倉庫)等。方便用戶構建端到端的大數據處理和分析解決方案,例如從 S3 中讀取原始數據,利用 EMR 上的 Spark 進行處理,然后將結果寫入 Redshift 供業務人員進行數據分析。
- 成本控制:按使用付費模式,用戶只需為實際使用的計算資源(EC2 實例運行時間、存儲等)付費,避免了資源閑置造成的浪費。同時,通過合理配置集群規模和實例類型,可以進一步優化成本。
應用場景
- 日志分析:收集和處理來自網站、應用程序、服務器等的海量日志數據,通過 EMR 上的 Hadoop 或 Spark 進行清洗、解析和分析,挖掘有價值的信息,如用戶行為模式、系統性能瓶頸等。
- 基因數據分析:在生物信息領域,處理大規模的基因測序數據。利用 EMR 上的計算框架,進行序列比對、變異檢測等復雜計算任務。
- 金融風險評估:對金融機構的大量交易數據進行實時和離線分析,使用 Flink 進行實時流處理監測異常交易,使用 Spark 進行歷史數據挖掘和風險評估模型訓練。
Amazon Redshift 是 AWS 推出的一款云端數據倉庫服務,專為高效處理大規模數據的分析工作負載而設計,能夠支持 PB 級別的數據存儲與分析,在企業級數據分析領域應用廣泛,以下是對它的詳細介紹:
關鍵特性
- 大規模并行處理(MPP)架構:
- 原理:Redshift 采用 MPP 架構,將數據分布存儲在多個節點上,每個節點都有獨立的計算和存儲資源。在執行查詢時,這些節點可以并行處理數據,極大地提高了查詢性能。例如,當企業需要分析數百萬行的銷售記錄,查找不同地區、不同時間段的銷售趨勢時,Redshift 可以將數據分割,讓多個節點同時進行計算,快速得出結果。
- 優勢:這種架構使 Redshift 能夠輕松應對復雜的分析查詢,即使處理 PB 級別的海量數據,也能保持高效,滿足企業對大數據快速分析的需求。
- 列式存儲:
- 原理:與傳統的行式存儲不同,Redshift 將數據按列存儲。在數據倉庫場景中,分析查詢通常只涉及部分列,列式存儲可以避免讀取不必要的列數據,減少 I/O 操作。比如在分析客戶數據時,若只需要查詢客戶的購買金額和購買時間,列式存儲只需讀取這兩列的數據,而無需讀取整行數據。
- 優勢:列式存儲還能對數據進行高效壓縮,進一步減少存儲空間,提高數據讀取和處理效率。
- 與 AWS 生態深度集成:
- 數據存儲集成:可以直接從 Amazon S3 快速加載數據,S3 作為數據湖,能夠存儲各種原始數據,Redshift 利用自身的 COPY 命令,能高效地將 S3 中的數據導入到數倉中,為數據分析提供豐富的數據源。
- 分析工具集成:無縫對接 Amazon QuickSight、Tableau 等商業智能(BI)工具,用戶可以方便地連接到 Redshift,進行數據可視化和交互式分析,快速生成報表和洞察。此外,還支持與 AWS Glue 集成,借助 Glue 的 ETL 能力,對數據進行清洗、轉換后再加載到 Redshift 中。
- 自動擴展:
- 原理:用戶可以根據業務需求和數據增長情況,通過簡單的操作增加或減少 Redshift 集群中的節點數量。AWS 會自動管理數據在節點之間的重新分布,確保查詢性能不受影響。
- 優勢:這種自動擴展功能使得企業無需擔心數據倉庫的容量限制,在數據量不斷增長時,能夠靈活調整資源,同時也避免了過度預配置資源帶來的成本浪費。
數據加載方式
- COPY 命令:這是最常用的數據加載方式,支持從 Amazon S3、Amazon DynamoDB 等數據源快速加載數據。COPY 命令具有高度的可配置性,可以指定數據格式(如 CSV、JSON、Parquet 等)、壓縮方式等參數。例如,將存儲在 S3 中的每日銷售數據加載到 Redshift 中,只需簡單配置 COPY 命令,就能高效完成數據導入,且支持并行加載,加快數據加載速度。
- SQL 接口:通過標準的 SQL 語句,如 INSERT INTO 等,也可以將數據插入到 Redshift 表中。不過,這種方式更適合少量數據的插入,對于大規模數據加載,COPY 命令通常效率更高。
應用場景
- 企業報表與商業智能:企業可以將來自多個業務系統的數據(如銷售系統、庫存系統、客戶關系管理系統等)匯總到 Redshift 中,利用 BI 工具進行可視化分析,生成各種報表,幫助管理層進行決策。例如,零售企業通過分析 Redshift 中的銷售數據、庫存數據,了解商品的銷售情況,優化庫存管理和商品采購策略。
- 數據分析與數據挖掘:數據科學家和分析師可以在 Redshift 上進行復雜的數據分析和數據挖掘工作。比如,電信企業利用 Redshift 分析用戶的通話記錄、上網行為數據,挖掘用戶的消費習慣和潛在需求,制定精準的營銷策略。
- 廣告與營銷分析:廣告平臺可以將廣告投放數據、用戶點擊數據等存儲在 Redshift 中,分析廣告效果,優化廣告投放策略。例如,通過分析不同廣告渠道的轉化率、用戶留存率等指標,確定最有效的廣告投放渠道,提高廣告投資回報率。
?
Amazon S3 — 數據湖統一存儲層
作用:作為整個架構的 “數據湖”,存儲所有原始數據(結構化、半結構化、非結構化),如日志文件、CSV/JSON、圖片、視頻等。
場景:接收來自各類數據源的數據(如 IoT 設備、應用日志、數據庫備份等),作為所有后續處理的 “數據源” 和 “結果存儲地”。
AWS Glue — Serverless 元數據 & ETL
數據目錄(Data Catalog):集中管理全量數據的元數據(表結構、分區、數據位置等),相當于 “數據湖的目錄服務”,讓 Hive/Spark 等工具能快速識別數據結構。
Amazon EMR on EC2[分布式計算引擎]?—— 托管 Hadoop/Spark/Flink 集群
作用:基于 EC2 實例創建的分布式計算集群,提供 Hadoop 生態系統的核心工具,支持大規模數據處理。
核心框架(運行在 EMR 上):
Hive:基于 Hadoop 的 “數據倉庫工具”,通過類 SQL(HQL)語法查詢 S3 中的數據,適合離線批處理分析(如統計報表)。
Spark:快速通用的計算引擎,支持批處理、流處理、機器學習(MLlib),比 MapReduce 性能更高,適合復雜數據處理(如用戶行為分析、特征工程)。
Flink:實時流處理引擎,擅長低延遲、高吞吐的實時數據處理(如實時監控、實時推薦),也支持批處理。
Amazon Redshift — PB 級云數倉
作用:基于列式存儲的企業級數據倉庫,專為高性能分析和復雜查詢設計,支持 PB 級數據的快速查詢。
場景:接收經 Glue/EMR 處理后的 “干凈數據”,供業務人員通過 BI 工具(如 Amazon QuickSight、Tableau)進行交互式分析、生成報表。
與其他組件集成:
可直接從 S3 加載數據(通過 COPY 命令),或接收 Glue ETL 的輸出結果。
支持與 Spark 集成,將分析結果寫回 Redshift 供進一步查詢。
AWS數據處理全流程
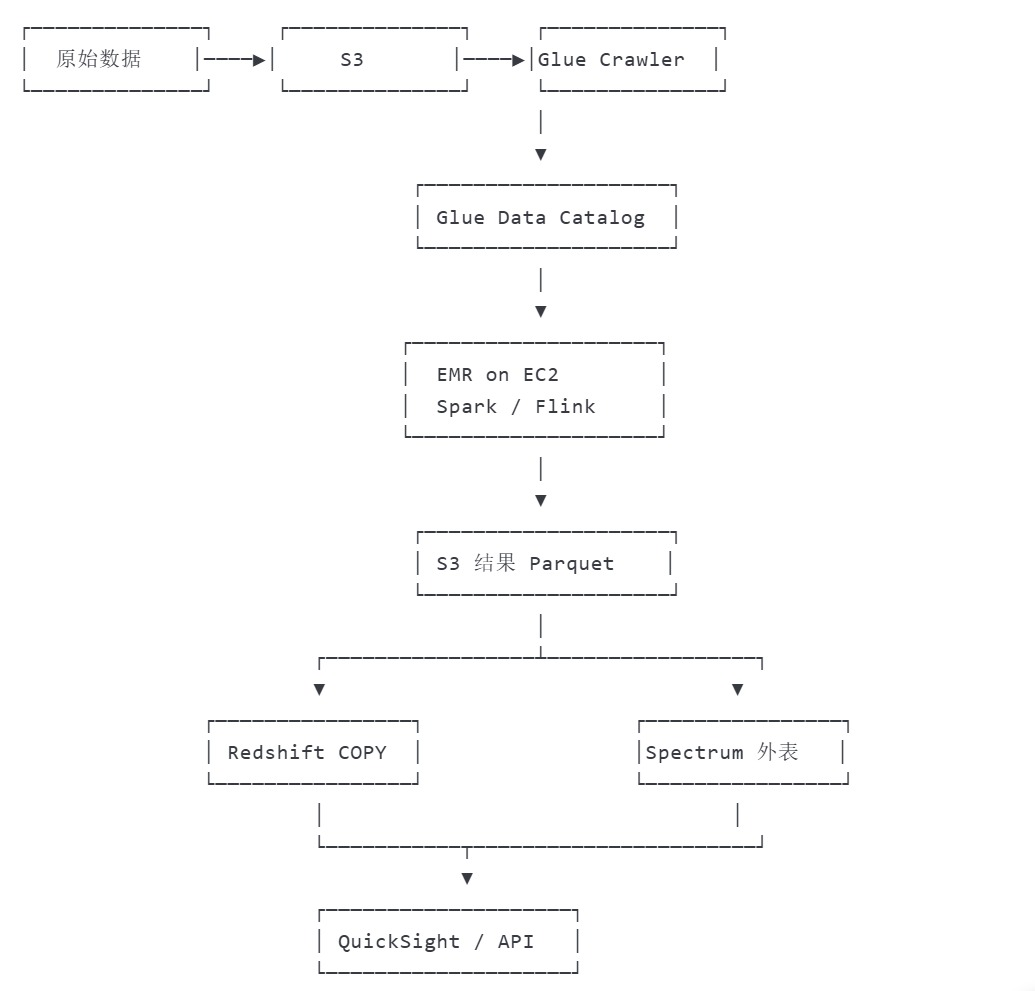
用戶行為數據分析流程?
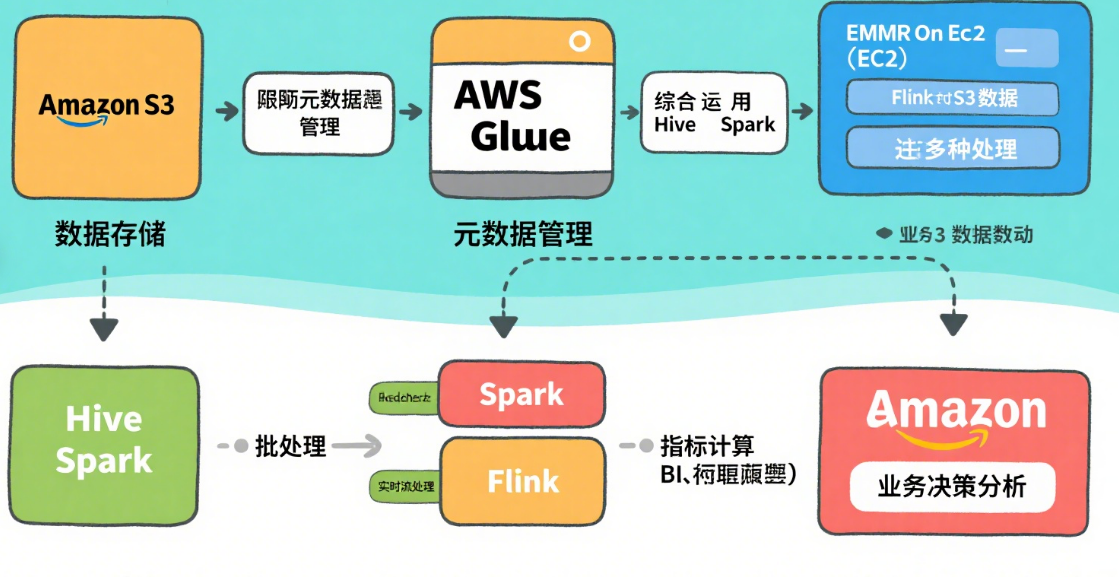
總結:
S3 存一切,
Glue 管元數據 + 輕量 ETL,
EMR on EC2 跑大規模 Spark/Flink/Hive,
Redshift 做高性能數倉 & 直接“湖上查詢”。







:使用云平臺最小外部依賴方案)







服務器/多客戶端模型)


——設備樹(上))
)