MelGAN
論文MelGAN針對的是從mel譜生成語音,里面說當條件很強的時候,隨機噪聲就沒啥用了,因此沒將noise注入到生成器中;

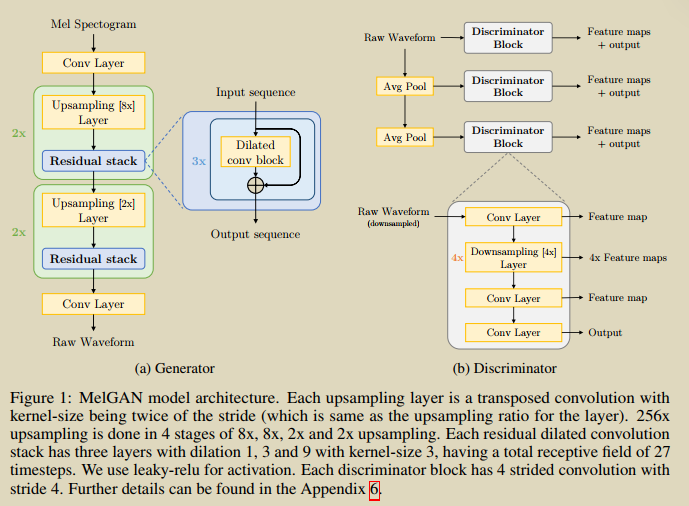
運用的判別器也僅有1個輸入,不是cGAN的形式
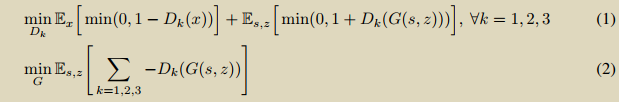
image-to-image translation with conditional adversarial networks
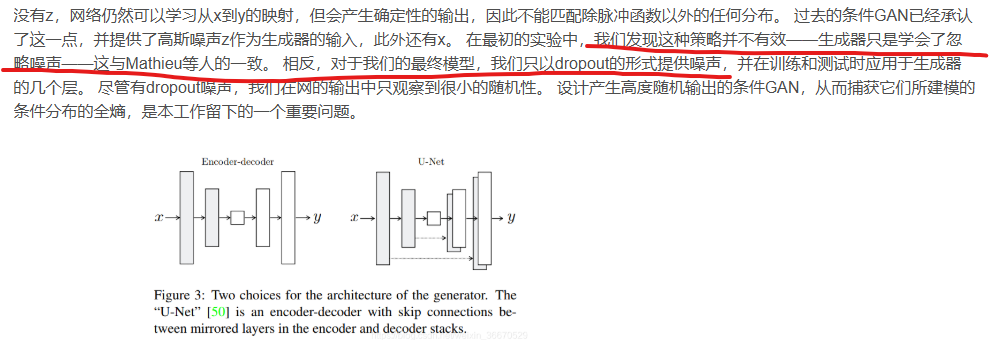
主要針對圖片到圖片的轉換任務,例如:給定輪廓,利用NN補充細節。也說隨機噪聲作用不大。文中僅以dropout的形式實現隨機噪聲,但本文也稱自己為GAN。

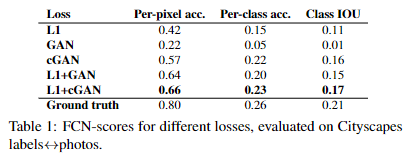
僅使用L1會得到模糊結果(文中其他地方說用L2會更模糊),僅使用GAN會得到清晰但是有artifact的結果,聯合使用L1+GAN效果最好;


L1loss和L2loss在圖像問題上會導致模糊現象,但是這兩個loss都捕捉到了低頻信息。


采用GAN的目的是僅對高頻進行建模,L1用來最低頻做建模

如下結果表明:相較于GAN,cgan還是有優勢的。cgan和gan的區別就是是否將原始特征輸入x中;

Day10)


——聯合體)
![[python][flask]Flask-Login 使用詳解](http://pic.xiahunao.cn/[python][flask]Flask-Login 使用詳解)


)

)




)



