本文目錄:
- 一、案例概述
- 二、數據集
- 三、案例步驟
- (一)導入工具包和工具函數
- (二)數據預處理
- (三)構建數據源對象
- (四)構建數據迭代器
- (五)構建基于GRU的編碼器和解碼器
- 1.構建基于GRU的編碼器
- 2. 構建基于GRU的解碼器
- 3 .構建基于GRU和Attention的解碼器
- 4.構建模型訓練函數, 并進行訓練
- 5.構建模型評估函數并測試
前言:前文分享了注意力機制,今天開始分享案例:seqtoseq英譯法。
一、案例概述
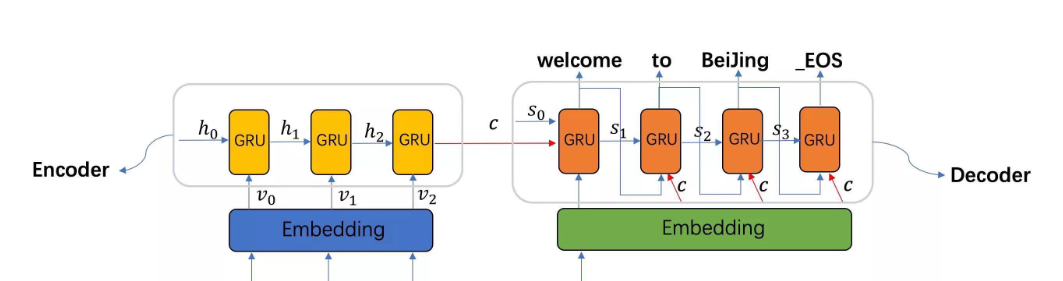
任務:將英文短句翻譯成法文(例如:“I am happy.” → “Je suis heureux.”)
模型架構:Seq2Seq 帶注意力機制(Attention)
二、數據集
i am from brazil . je viens du bresil .
i am from france . je viens de france .
i am from russia . je viens de russie .
i am frying fish . je fais frire du poisson .
i am not kidding . je ne blague pas .
i am on duty now . maintenant je suis en service .
i am on duty now . je suis actuellement en service .
i am only joking . je ne fais que blaguer .
i am out of time . je suis a court de temps .
i am out of work . je suis au chomage .
i am out of work . je suis sans travail .
i am paid weekly . je suis payee a la semaine .
i am pretty sure . je suis relativement sur .
i am truly sorry . je suis vraiment desole .
i am truly sorry . je suis vraiment desolee .三、案例步驟
基于GRU的seq2seq模型架構實現翻譯的過程:
第一步: 導入工具包和工具函數;
第二步: 對持久化文件中數據進行處理, 以滿足模型訓練要求;
第三步: 構建基于GRU的編碼器和解碼器;
第四步: 構建模型訓練函數, 并進行訓練;
第五步: 構建模型評估函數, 并進行測試以及Attention效果分析。
(一)導入工具包和工具函數
# 用于正則表達式
import re
# 用于構建網絡結構和函數的torch工具包
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
# torch中預定義的優化方法工具包
import torch.optim as optim
import time
# 用于隨機生成數據
import random
import matplotlib.pyplot as plt# 設備選擇, 我們可以選擇在cuda或者cpu上運行你的代碼
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 起始標志
SOS_token = 0
# 結束標志
EOS_token = 1
# 最大句子長度不能超過10個 (包含標點)
MAX_LENGTH = 10
# 數據文件路徑
data_path = './data/eng-fra-v2.txt'# 文本清洗工具函數
def normalizeString(s):"""字符串規范化函數, 參數s代表傳入的字符串"""s = s.lower().strip()# 在.!?前加一個空格 這里的\1表示第一個分組 正則中的\nums = re.sub(r"([.!?])", r" \1", s)# s = re.sub(r"([.!?])", r" ", s)# 使用正則表達式將字符串中 不是 大小寫字母和正常標點的都替換成空格s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)return s(二)數據預處理
def my_getdata():# 1 按行讀文件 open().read().strip().split(\n)my_lines = open(data_path, encoding='utf-8').read().strip().split('\n')print('my_lines--->', len(my_lines))# 2 按行清洗文本 構建語言對 my_pairs# 格式 [['英文句子', '法文句子'], ['英文句子', '法文句子'], ['英文句子', '法文句子'], ... ]# tmp_pair, my_pairs = [], []# for l in my_lines:# for s in l.split('\t'):# tmp_pair.append(normalizeString(s))# my_pairs.append(tmp_pair)# tmp_pair = []my_pairs = [[normalizeString(s) for s in l.split('\t')] for l in my_lines]print('len(pairs)--->', len(my_pairs))# 打印前4條數據print(my_pairs[:4])# 打印第8000條的英文 法文數據print('my_pairs[8000][0]--->', my_pairs[8000][0])print('my_pairs[8000][1]--->', my_pairs[8000][1])# 3 遍歷語言對 構建英語單詞字典 法語單詞字典# 3-1 english_word2index english_word_n french_word2index french_word_nenglish_word2index = {"SOS": 0, "EOS": 1}english_word_n = 2french_word2index = {"SOS": 0, "EOS": 1}french_word_n = 2# 遍歷語言對 獲取英語單詞字典 法語單詞字典for pair in my_pairs:for word in pair[0].split(' '):if word not in english_word2index:english_word2index[word] = english_word_nenglish_word_n += 1for word in pair[1].split(' '):if word not in french_word2index:french_word2index[word] = french_word_nfrench_word_n += 1# 3-2 english_index2word french_index2wordenglish_index2word = {v:k for k, v in english_word2index.items()}french_index2word = {v:k for k, v in french_word2index.items()}print('len(english_word2index)-->', len(english_word2index))print('len(french_word2index)-->', len(french_word2index))print('english_word_n--->', english_word_n, 'french_word_n-->', french_word_n)return english_word2index, english_index2word, english_word_n, french_word2index, french_index2word, french_word_n, my_pairs運行結果:
my_lines---> 10599
len(pairs)---> 10599
[['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .'], ['i m ok .', 'ca va .'], ['i m fat .', 'je suis gras .']]
my_pairs[8000][0]---> they re in the science lab .
my_pairs[8000][1]---> elles sont dans le laboratoire de sciences .
len(english_word2index)--> 2803
len(french_word2index)--> 4345
english_word_n---> 2803 french_word_n--> 4345
x.shape torch.Size([1, 9]) tensor([[ 75, 40, 102, 103, 677, 42, 21, 4, 1]])
y.shape torch.Size([1, 7]) tensor([[ 119, 25, 164, 165, 3222, 5, 1]])
x.shape torch.Size([1, 5]) tensor([[14, 15, 44, 4, 1]])
y.shape torch.Size([1, 5]) tensor([[24, 25, 62, 5, 1]])
x.shape torch.Size([1, 8]) tensor([[ 2, 3, 147, 61, 532, 1143, 4, 1]])
y.shape torch.Size([1, 7]) tensor([[ 6, 297, 7, 246, 102, 5, 1]])(三)構建數據源對象
# 原始數據 -> 數據源MyPairsDataset --> 數據迭代器DataLoader
# 構造數據源 MyPairsDataset,把語料xy 文本數值化 再轉成tensor_x tensor_y
# 1 __init__(self, my_pairs)函數 設置self.my_pairs 條目數self.sample_len
# 2 __len__(self)函數 獲取樣本條數
# 3 __getitem__(self, index)函數 獲取第幾條樣本數據
# 按索引 獲取數據樣本 x y
# 樣本x 文本數值化 word2id x.append(EOS_token)
# 樣本y 文本數值化 word2id y.append(EOS_token)
# 返回tensor_x, tensor_yclass MyPairsDataset(Dataset):def __init__(self, my_pairs):# 樣本xself.my_pairs = my_pairs# 樣本條目數self.sample_len = len(my_pairs)# 獲取樣本條數def __len__(self):return self.sample_len# 獲取第幾條 樣本數據def __getitem__(self, index):# 對index異常值進行修正 [0, self.sample_len-1]index = min(max(index, 0), self.sample_len-1)# 按索引獲取 數據樣本 x yx = self.my_pairs[index][0]y = self.my_pairs[index][1]# 樣本x 文本數值化x = [english_word2index[word] for word in x.split(' ')]x.append(EOS_token)tensor_x = torch.tensor(x, dtype=torch.long, device=device)# 樣本y 文本數值化y = [french_word2index[word] for word in y.split(' ')]y.append(EOS_token)tensor_y = torch.tensor(y, dtype=torch.long, device=device)# 注意 tensor_x tensor_y都是一維數組,通過DataLoader拿出數據是二維數據# print('tensor_y.shape===>', tensor_y.shape, tensor_y)# 返回結果return tensor_x, tensor_y(四)構建數據迭代器
def dm_test_MyPairsDataset():# 1 實例化dataset對象mypairsdataset = MyPairsDataset(my_pairs)# 2 實例化dataloadermydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)for i, (x, y) in enumerate (mydataloader):print('x.shape', x.shape, x)print('y.shape', y.shape, y)if i == 1:break運行結果:
x.shape torch.Size([1, 8]) tensor([[ 2, 16, 33, 518, 589, 1460, 4, 1]])
y.shape torch.Size([1, 8]) tensor([[ 6, 11, 52, 101, 1358, 964, 5, 1]])
x.shape torch.Size([1, 6]) tensor([[129, 78, 677, 429, 4, 1]])
y.shape torch.Size([1, 7]) tensor([[ 118, 214, 1073, 194, 778, 5, 1]])(五)構建基于GRU的編碼器和解碼器
1.構建基于GRU的編碼器
編碼器結構圖:
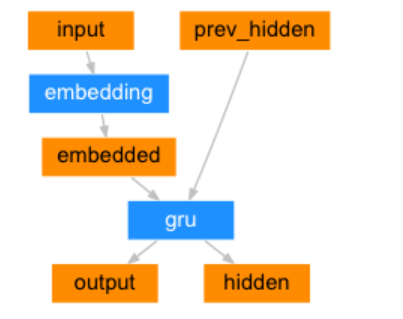
class EncoderRNN(nn.Module):def __init__(self, input_size, hidden_size):# input_size 編碼器 詞嵌入層單詞數 eg:2803# hidden_size 編碼器 詞嵌入層每個單詞的特征數 eg 256super(EncoderRNN, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_size# 實例化nn.Embedding層self.embedding = nn.Embedding(input_size, hidden_size)# 實例化nn.GRU層 注意參數batch_first=Trueself.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)def forward(self, input, hidden):# 數據經過詞嵌入層 數據形狀 [1,6] --> [1,6,256]output = self.embedding(input)# 數據經過gru層 數據形狀 gru([1,6,256],[1,1,256]) --> [1,6,256] [1,1,256]output, hidden = self.gru(output, hidden)return output, hiddendef inithidden(self):# 將隱層張量初始化成為1x1xself.hidden_size大小的張量return torch.zeros(1, 1, self.hidden_size, device=device)
調用:
def dm_test_EncoderRNN():# 實例化dataset對象mypairsdataset = MyPairsDataset(my_pairs)# 實例化dataloadermydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)# 實例化模型input_size = english_word_nhidden_size = 256 #my_encoderrnn = EncoderRNN(input_size, hidden_size)print('my_encoderrnn模型結構--->', my_encoderrnn)# 給encode模型喂數據for i, (x, y) in enumerate (mydataloader):print('x.shape', x.shape, x)print('y.shape', y.shape, y)# 一次性的送數據hidden = my_encoderrnn.inithidden()encode_output_c, hidden = my_encoderrnn(x, hidden)print('encode_output_c.shape--->', encode_output_c.shape, encode_output_c)# 一個字符一個字符給為模型喂數據hidden = my_encoderrnn.inithidden()for i in range(x.shape[1]):tmp = x[0][i].view(1,-1)output, hidden = my_encoderrnn(tmp, hidden)print('觀察:最后一個時間步output輸出是否相等') # hidden_size = 8 效果比較好print('encode_output_c[0][-1]===>', encode_output_c[0][-1])print('output===>', output)break
輸出效果:
# 本輸出效果為hidden_size = 8
x.shape torch.Size([1, 6]) tensor([[129, 124, 270, 558, 4, 1]])
y.shape torch.Size([1, 7]) tensor([[ 118, 214, 101, 1253, 1028, 5, 1]])
encode_output_c.shape---> torch.Size([1, 6, 8])
tensor([[[-0.0984, 0.4267, -0.2120, 0.0923, 0.1525, -0.0378, 0.2493,-0.2665],[-0.1388, 0.5363, -0.4522, -0.2819, -0.2070, 0.0795, 0.6262, -0.2359],[-0.4593, 0.2499, 0.1159, 0.3519, -0.0852, -0.3621, 0.1980, -0.1853],[-0.4407, 0.1974, 0.6873, -0.0483, -0.2730, -0.2190, 0.0587, 0.2320],[-0.6544, 0.1990, 0.7534, -0.2347, -0.0686, -0.5532, 0.0624, 0.4083],[-0.2941, -0.0427, 0.1017, -0.1057, 0.1983, -0.1066, 0.0881, -0.3936]]], grad_fn=<TransposeBackward1>)
觀察:最后一個時間步output輸出是否相等
encode_output_c[0][-1]===> tensor([-0.2941, -0.0427, 0.1017, -0.1057, 0.1983, -0.1066, 0.0881, -0.3936],grad_fn=<SelectBackward0>)
output===> tensor([[[-0.2941, -0.0427, 0.1017, -0.1057, 0.1983, -0.1066, 0.0881,-0.3936]]], grad_fn=<TransposeBackward1>)2. 構建基于GRU的解碼器
解碼器結構圖:
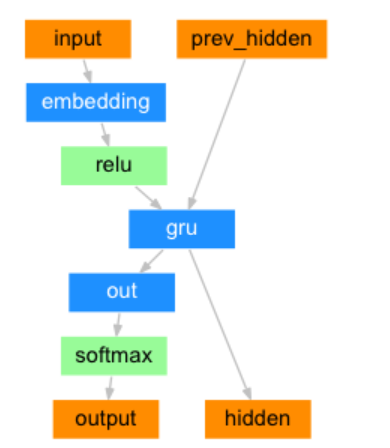
class DecoderRNN(nn.Module):def __init__(self, output_size, hidden_size):# output_size 編碼器 詞嵌入層單詞數 eg:4345# hidden_size 編碼器 詞嵌入層每個單詞的特征數 eg 256super(DecoderRNN, self).__init__()self.output_size = output_sizeself.hidden_size = hidden_size# 實例化詞嵌入層self.embedding = nn.Embedding(output_size, hidden_size)# 實例化gru層,輸入尺寸256 輸出尺寸256# 因解碼器一個字符一個字符的解碼 batch_first=True 意義不大self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)# 實例化線性輸出層out 輸入尺寸256 輸出尺寸4345self.out = nn.Linear(hidden_size, output_size)# 實例化softomax層 數值歸一化 以便分類self.softmax = nn.LogSoftmax(dim=-1)def forward(self, input, hidden):# 數據經過詞嵌入層# 數據形狀 [1,1] --> [1,1,256] or [1,6]--->[1,6,256]output = self.embedding(input)# 數據結果relu層使Embedding矩陣更稀疏,以防止過擬合output = F.relu(output)# 數據經過gru層# 數據形狀 gru([1,1,256],[1,1,256]) --> [1,1,256] [1,1,256]output, hidden = self.gru(output, hidden)# 數據經過softmax層 歸一化# 數據形狀變化 [1,1,256]->[1,256] ---> [1,4345]output = self.softmax(self.out(output[0]))return output, hiddendef inithidden(self):# 將隱層張量初始化成為1x1xself.hidden_size大小的張量return torch.zeros(1, 1, self.hidden_size, device=device)
調用:
def dm03_test_DecoderRNN():# 實例化dataset對象mypairsdataset = MyPairsDataset(my_pairs)# 實例化dataloadermydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)# 實例化模型input_size = english_word_nhidden_size = 256 # 觀察結果數據 可使用8my_encoderrnn = EncoderRNN(input_size, hidden_size)print('my_encoderrnn模型結構--->', my_encoderrnn)# 實例化模型input_size = french_word_nhidden_size = 256 # 觀察結果數據 可使用8my_decoderrnn = DecoderRNN(input_size, hidden_size)print('my_decoderrnn模型結構--->', my_decoderrnn)# 給模型喂數據 完整演示編碼 解碼流程for i, (x, y) in enumerate (mydataloader):print('x.shape', x.shape, x)print('y.shape', y.shape, y)# 1 編碼:一次性的送數據hidden = my_encoderrnn.inithidden()encode_output_c, hidden = my_encoderrnn(x, hidden)print('encode_output_c.shape--->', encode_output_c.shape, encode_output_c)print('觀察:最后一個時間步output輸出') # hidden_size = 8 效果比較好print('encode_output_c[0][-1]===>', encode_output_c[0][-1])# 2 解碼: 一個字符一個字符的解碼# 最后1個隱藏層的輸出 作為 解碼器的第1個時間步隱藏層輸入for i in range(y.shape[1]):tmp = y[0][i].view(1, -1)output, hidden = my_decoderrnn(tmp, hidden)print('每個時間步解碼出來4345種可能 output===>', output.shape)break
輸出效果:
my_encoderrnn模型結構---> EncoderRNN((embedding): Embedding(2803, 256)(gru): GRU(256, 256, batch_first=True)
)
my_decoderrnn模型結構---> DecoderRNN((embedding): Embedding(4345, 256)(gru): GRU(256, 256, batch_first=True)(out): Linear(in_features=256, out_features=4345, bias=True)(softmax): LogSoftmax(dim=-1)
)
x.shape torch.Size([1, 8]) tensor([[ 14, 40, 883, 677, 589, 609, 4, 1]])
y.shape torch.Size([1, 6]) tensor([[1358, 1125, 247, 2863, 5, 1]])
每個時間步解碼出來4345種可能 output===> torch.Size([1, 4345])
每個時間步解碼出來4345種可能 output===> torch.Size([1, 4345])
每個時間步解碼出來4345種可能 output===> torch.Size([1, 4345])
每個時間步解碼出來4345種可能 output===> torch.Size([1, 4345])
每個時間步解碼出來4345種可能 output===> torch.Size([1, 4345])
每個時間步解碼出來4345種可能 output===> torch.Size([1, 4345])
3 .構建基于GRU和Attention的解碼器
解碼器結構圖:
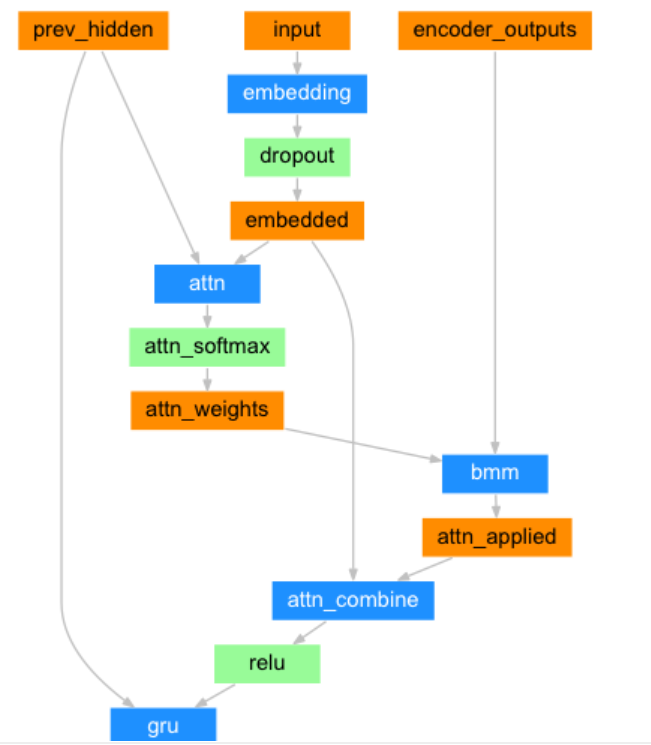
class AttnDecoderRNN(nn.Module):def __init__(self, output_size, hidden_size, dropout_p=0.1, max_length=MAX_LENGTH):# output_size 編碼器 詞嵌入層單詞數 eg:4345# hidden_size 編碼器 詞嵌入層每個單詞的特征數 eg 256# dropout_p 置零比率,默認0.1,# max_length 最大長度10super(AttnDecoderRNN, self).__init__()self.output_size = output_sizeself.hidden_size = hidden_sizeself.dropout_p = dropout_pself.max_length = max_length# 定義nn.Embedding層 nn.Embedding(4345,256)self.embedding = nn.Embedding(self.output_size, self.hidden_size)# 定義線性層1:求q的注意力權重分布self.attn = nn.Linear(self.hidden_size * 2, self.max_length)# 定義線性層2:q+注意力結果表示融合后,在按照指定維度輸出self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)# 定義dropout層self.dropout = nn.Dropout(self.dropout_p)# 定義gru層self.gru = nn.GRU(self.hidden_size, self.hidden_size, batch_first=True)# 定義out層 解碼器按照類別進行輸出(256,4345)self.out = nn.Linear(self.hidden_size, self.output_size)# 實例化softomax層 數值歸一化 以便分類self.softmax = nn.LogSoftmax(dim=-1)def forward(self, input, hidden, encoder_outputs):# input代表q [1,1] 二維數據 hidden代表k [1,1,256] encoder_outputs代表v [10,256]# 數據經過詞嵌入層# 數據形狀 [1,1] --> [1,1,256]embedded = self.embedding(input)# 使用dropout進行隨機丟棄,防止過擬合embedded = self.dropout(embedded)# 1 求查詢張量q的注意力權重分布, attn_weights[1,10]attn_weights = F.softmax(self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)# 2 求查詢張量q的注意力結果表示 bmm運算, attn_applied[1,1,256]# [1,1,10],[1,10,256] ---> [1,1,256]attn_applied = torch.bmm(attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))# 3 q 與 attn_applied 融合,再按照指定維度輸出 output[1,1,256]output = torch.cat((embedded[0], attn_applied[0]), 1)output = self.attn_combine(output).unsqueeze(0)# 查詢張量q的注意力結果表示 使用relu激活output = F.relu(output)# 查詢張量經過gru、softmax進行分類結果輸出# 數據形狀[1,1,256],[1,1,256] --> [1,1,256], [1,1,256]output, hidden = self.gru(output, hidden)# 數據形狀[1,1,256]->[1,256]->[1,4345]output = self.softmax(self.out(output[0]))# 返回解碼器分類output[1,4345],最后隱層張量hidden[1,1,256] 注意力權重張量attn_weights[1,10]return output, hidden, attn_weightsdef inithidden(self):# 將隱層張量初始化成為1x1xself.hidden_size大小的張量return torch.zeros(1, 1, self.hidden_size, device=device)調用:
def dm_test_AttnDecoderRNN():# 1 實例化 數據集對象mypairsdataset = MyPairsDataset(my_pairs)# 2 實例化 數據加載器對象mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)# 實例化 編碼器my_encoderrnnmy_encoderrnn = EncoderRNN(english_word_n, 256)# 實例化 解碼器DecoderRNNmy_attndecoderrnn = AttnDecoderRNN(french_word_n, 256)# 3 遍歷數據迭代器for i, (x, y) in enumerate(mydataloader):# 編碼-方法1 一次性給模型送數據hidden = my_encoderrnn.inithidden()print('x--->', x.shape, x)print('y--->', y.shape, y)# [1, 6, 256], [1, 1, 256]) --> [1, 6, 256][1, 1, 256]output, hidden = my_encoderrnn(x, hidden)# print('output-->', output.shape, output)# print('最后一個時間步取出output[0,-1]-->', output[0, -1].shape, output[0, -1])# 中間語義張量Cencode_output_c = torch.zeros(MAX_LENGTH, my_encoderrnn.hidden_size,device=device)for idx in range(output.shape[1]):encode_output_c[idx] = output[0, idx]# # 編碼-方法2 一個字符一個字符給模型送數據# hidden = my_encoderrnn.inithidden()# for i in range(x.shape[1]):# tmp = x[0][i].view(1, -1)# # [1, 1, 256], [1, 1, 256]) --> [1, 1, 256][1, 1, 256]# output, hidden = my_encoderrnn(tmp, hidden)# print('一個字符一個字符output', output.shape, output)# 解碼-必須一個字符一個字符的解碼 for i in range(y.shape[1]):tmp = y[0][i].view(1, -1)output, hidden, attn_weights = my_attndecoderrnn(tmp, hidden, encode_output_c)print('解碼output.shape', output.shape )print('解碼hidden.shape', hidden.shape)print('解碼attn_weights.shape', attn_weights.shape)break
輸出效果:
x---> torch.Size([1, 7]) tensor([[ 129, 78, 1873, 294, 1215, 4, 1]])
y---> torch.Size([1, 6]) tensor([[ 210, 3097, 248, 3095, 5, 1]])
解碼output.shape torch.Size([1, 4345])
解碼hidden.shape torch.Size([1, 1, 256])
解碼attn_weights.shape torch.Size([1, 10])
解碼output.shape torch.Size([1, 4345])
解碼hidden.shape torch.Size([1, 1, 256])
解碼attn_weights.shape torch.Size([1, 10])
解碼output.shape torch.Size([1, 4345])
解碼hidden.shape torch.Size([1, 1, 256])
解碼attn_weights.shape torch.Size([1, 10])
解碼output.shape torch.Size([1, 4345])
解碼hidden.shape torch.Size([1, 1, 256])
解碼attn_weights.shape torch.Size([1, 10])
解碼output.shape torch.Size([1, 4345])
解碼hidden.shape torch.Size([1, 1, 256])
解碼attn_weights.shape torch.Size([1, 10])
解碼output.shape torch.Size([1, 4345])
解碼hidden.shape torch.Size([1, 1, 256])
解碼attn_weights.shape torch.Size([1, 10])4.構建模型訓練函數, 并進行訓練
(1) teacher_forcing的作用
- 能夠在訓練的時候矯正模型的預測,避免在序列生成的過程中誤差進一步放大;
- teacher_forcing能夠極大的加快模型的收斂速度,令模型訓練過程更快更平穩。
(2) 構建內部迭代訓練函數
模型訓練參數
# 模型訓練參數
mylr = 1e-4
epochs = 2
# 設置teacher_forcing比率為0.5
teacher_forcing_ratio = 0.5
print_interval_num = 1000
plot_interval_num = 100
代碼實現:
def Train_Iters(x, y, my_encoderrnn, my_attndecoderrnn, myadam_encode, myadam_decode, mycrossentropyloss):# 1 編碼 encode_output, encode_hidden = my_encoderrnn(x, encode_hidden)encode_hidden = my_encoderrnn.inithidden()encode_output, encode_hidden = my_encoderrnn(x, encode_hidden) # 一次性送數據# [1,6],[1,1,256] --> [1,6,256],[1,1,256]# 2 解碼參數準備和解碼# 解碼參數1 encode_output_c [10,256]encode_output_c = torch.zeros(MAX_LENGTH, my_encoderrnn.hidden_size, device=device)for idx in range(x.shape[1]):encode_output_c[idx] = encode_output[0, idx]# 解碼參數2decode_hidden = encode_hidden# 解碼參數3input_y = torch.tensor([[SOS_token]], device=device)myloss = 0.0y_len = y.shape[1]use_teacher_forcing = True if random.random() < teacher_forcing_ratio else Falseif use_teacher_forcing:for idx in range(y_len):# 數據形狀數據形狀 [1,1],[1,1,256],[10,256] ---> [1,4345],[1,1,256],[1,10]output_y, decode_hidden, attn_weight = my_attndecoderrnn(input_y, decode_hidden, encode_output_c)target_y = y[0][idx].view(1)myloss = myloss + mycrossentropyloss(output_y, target_y)input_y = y[0][idx].view(1, -1)else:for idx in range(y_len):# 數據形狀數據形狀 [1,1],[1,1,256],[10,256] ---> [1,4345],[1,1,256],[1,10]output_y, decode_hidden, attn_weight = my_attndecoderrnn(input_y, decode_hidden, encode_output_c)target_y = y[0][idx].view(1)myloss = myloss + mycrossentropyloss(output_y, target_y)topv, topi = output_y.topk(1)if topi.squeeze().item() == EOS_token:breakinput_y = topi.detach()# 梯度清零myadam_encode.zero_grad()myadam_decode.zero_grad()# 反向傳播myloss.backward()# 梯度更新myadam_encode.step()myadam_decode.step()# 返回 損失列表myloss.item()/y_lenreturn myloss.item() / y_len(3)構建模型訓練函數
def Train_seq2seq():# 實例化 mypairsdataset對象 實例化 mydataloadermypairsdataset = MyPairsDataset(my_pairs)mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)# 實例化編碼器 my_encoderrnn 實例化解碼器 my_attndecoderrnnmy_encoderrnn = EncoderRNN(2803, 256)my_attndecoderrnn = AttnDecoderRNN(output_size=4345, hidden_size=256, dropout_p=0.1, max_length=10)# 實例化編碼器優化器 myadam_encode 實例化解碼器優化器 myadam_decodemyadam_encode = optim.Adam(my_encoderrnn.parameters(), lr=mylr)myadam_decode = optim.Adam(my_attndecoderrnn.parameters(), lr=mylr)# 實例化損失函數 mycrossentropyloss = nn.NLLLoss()mycrossentropyloss = nn.NLLLoss()# 定義模型訓練的參數plot_loss_list = []# 外層for循環 控制輪數 for epoch_idx in range(1, 1+epochs):for epoch_idx in range(1, 1+epochs):print_loss_total, plot_loss_total = 0.0, 0.0starttime = time.time()# 內層for循環 控制迭代次數for item, (x, y) in enumerate(mydataloader, start=1):# 調用內部訓練函數myloss = Train_Iters(x, y, my_encoderrnn, my_attndecoderrnn, myadam_encode, myadam_decode, mycrossentropyloss)print_loss_total += mylossplot_loss_total += myloss# 計算打印屏幕間隔損失-每隔1000次if item % print_interval_num ==0 :print_loss_avg = print_loss_total / print_interval_num# 將總損失歸0print_loss_total = 0# 打印日志,日志內容分別是:訓練耗時,當前迭代步,當前進度百分比,當前平均損失print('輪次%d 損失%.6f 時間:%d' % (epoch_idx, print_loss_avg, time.time() - starttime))# 計算畫圖間隔損失-每隔100次if item % plot_interval_num == 0:# 通過總損失除以間隔得到平均損失plot_loss_avg = plot_loss_total / plot_interval_num# 將平均損失添加plot_loss_list列表中plot_loss_list.append(plot_loss_avg)# 總損失歸0plot_loss_total = 0# 每個輪次保存模型torch.save(my_encoderrnn.state_dict(), './my_encoderrnn_%d.pth' % epoch_idx)torch.save(my_attndecoderrnn.state_dict(), './my_attndecoderrnn_%d.pth' % epoch_idx)# 所有輪次訓練完畢 畫損失圖plt.figure()plt.plot(plot_loss_list)plt.savefig('./s2sq_loss.png')plt.show()return plot_loss_list運行結果:
輪次1 損失8.123402 時間:4
輪次1 損失6.658305 時間:8
輪次1 損失5.252497 時間:12
輪次1 損失4.906939 時間:16
輪次1 損失4.813769 時間:19
輪次1 損失4.780460 時間:23
輪次1 損失4.621599 時間:27
輪次1 損失4.487508 時間:31
輪次1 損失4.478538 時間:35
輪次1 損失4.245148 時間:39
輪次1 損失4.602579 時間:44
輪次1 損失4.256789 時間:48
輪次1 損失4.218111 時間:52
輪次1 損失4.393134 時間:56
輪次1 損失4.134959 時間:60
輪次1 損失4.164878 時間:63
(4)損失曲線分析
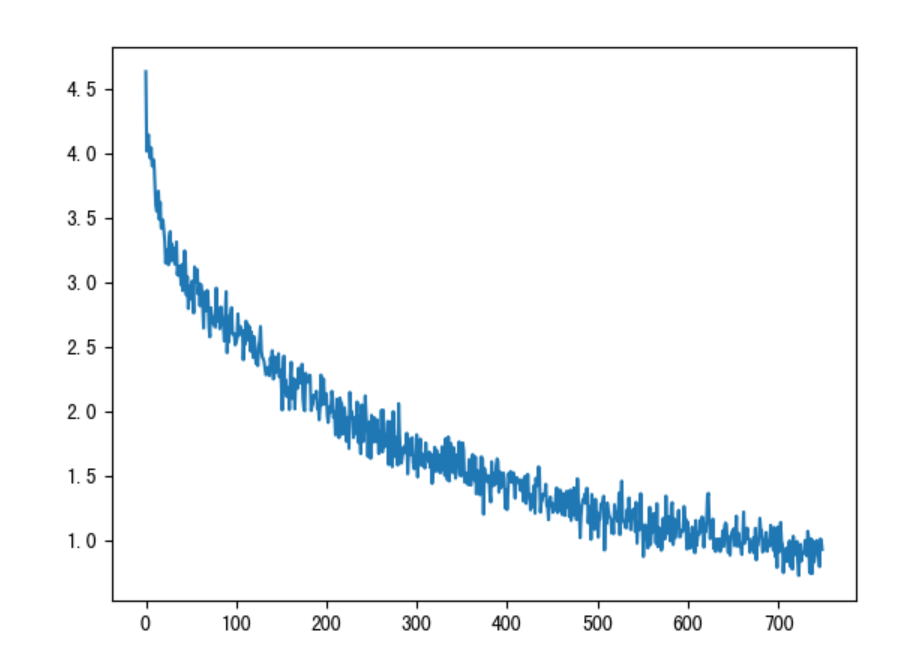
一直下降的損失曲線, 說明模型正在收斂, 能夠從數據中找到一些規律應用于數據。
5.構建模型評估函數并測試
(1)構建模型評估函數
# 模型評估代碼與模型預測代碼類似,需要注意使用with torch.no_grad()
# 模型預測時,第一個時間步使用SOS_token作為輸入 后續時間步采用預測值作為輸入,也就是自回歸機制
def Seq2Seq_Evaluate(x, my_encoderrnn, my_attndecoderrnn):with torch.no_grad():# 1 編碼:一次性的送數據encode_hidden = my_encoderrnn.inithidden()encode_output, encode_hidden = my_encoderrnn(x, encode_hidden)# 2 解碼參數準備# 解碼參數1 固定長度中間語義張量cencoder_outputs_c = torch.zeros(MAX_LENGTH, my_encoderrnn.hidden_size, device=device)x_len = x.shape[1]for idx in range(x_len):encoder_outputs_c[idx] = encode_output[0, idx]# 解碼參數2 最后1個隱藏層的輸出 作為 解碼器的第1個時間步隱藏層輸入decode_hidden = encode_hidden# 解碼參數3 解碼器第一個時間步起始符input_y = torch.tensor([[SOS_token]], device=device)# 3 自回歸方式解碼# 初始化預測的詞匯列表decoded_words = []# 初始化attention張量decoder_attentions = torch.zeros(MAX_LENGTH, MAX_LENGTH)for idx in range(MAX_LENGTH): # note:MAX_LENGTH=10output_y, decode_hidden, attn_weights = my_attndecoderrnn(input_y, decode_hidden, encoder_outputs_c)# 預測值作為為下一次時間步的輸入值topv, topi = output_y.topk(1)decoder_attentions[idx] = attn_weights# 如果輸出值是終止符,則循環停止if topi.squeeze().item() == EOS_token:decoded_words.append('<EOS>')breakelse:decoded_words.append(french_index2word[topi.item()])# 將本次預測的索引賦值給 input_y,進行下一個時間步預測input_y = topi.detach()# 返回結果decoded_words, 注意力張量權重分布表(把沒有用到的部分切掉)return decoded_words, decoder_attentions[:idx + 1]
(2)模型評估函數調用
# 加載模型
PATH1 = './gpumodel/my_encoderrnn.pth'
PATH2 = './gpumodel/my_attndecoderrnn.pth'
def dm_test_Seq2Seq_Evaluate():# 實例化dataset對象mypairsdataset = MyPairsDataset(my_pairs)# 實例化dataloadermydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)# 實例化模型input_size = english_word_nhidden_size = 256 # 觀察結果數據 可使用8my_encoderrnn = EncoderRNN(input_size, hidden_size)# my_encoderrnn.load_state_dict(torch.load(PATH1))my_encoderrnn.load_state_dict(torch.load(PATH1, map_location=lambda storage, loc: storage), False)print('my_encoderrnn模型結構--->', my_encoderrnn)# 實例化模型input_size = french_word_nhidden_size = 256 # 觀察結果數據 可使用8my_attndecoderrnn = AttnDecoderRNN(input_size, hidden_size)# my_attndecoderrnn.load_state_dict(torch.load(PATH2))my_attndecoderrnn.load_state_dict(torch.load(PATH2, map_location=lambda storage, loc: storage), False)print('my_decoderrnn模型結構--->', my_attndecoderrnn)my_samplepairs = [['i m impressed with your french .', 'je suis impressionne par votre francais .'],['i m more than a friend .', 'je suis plus qu une amie .'],['she is beautiful like her mother .', 'elle est belle comme sa mere .']]print('my_samplepairs--->', len(my_samplepairs))for index, pair in enumerate(my_samplepairs):x = pair[0]y = pair[1]# 樣本x 文本數值化tmpx = [english_word2index[word] for word in x.split(' ')]tmpx.append(EOS_token)tensor_x = torch.tensor(tmpx, dtype=torch.long, device=device).view(1, -1)# 模型預測decoded_words, attentions = Seq2Seq_Evaluate(tensor_x, my_encoderrnn, my_attndecoderrnn)# print('decoded_words->', decoded_words)output_sentence = ' '.join(decoded_words)print('\n')print('>', x)print('=', y)print('<', output_sentence)運行結果:
> i m impressed with your french .
= je suis impressionne par votre francais .
< je suis impressionnee par votre francais . <EOS>> i m more than a friend .
= je suis plus qu une amie .
< je suis plus qu une amie . <EOS>> she is beautiful like her mother .
= elle est belle comme sa mere .
< elle est sa sa mere . <EOS>> you re winning aren t you ?
= vous gagnez n est ce pas ?
< tu restez n est ce pas ? <EOS>> he is angry with you .
= il est en colere apres toi .
< il est en colere apres toi . <EOS>> you re very timid .
= vous etes tres craintifs .
< tu es tres craintive . <EOS>(3) Attention張量制圖
def dm_test_Attention():# 實例化dataset對象mypairsdataset = MyPairsDataset(my_pairs)# 實例化dataloadermydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)# 實例化模型input_size = english_word_nhidden_size = 256 # 觀察結果數據 可使用8my_encoderrnn = EncoderRNN(input_size, hidden_size)# my_encoderrnn.load_state_dict(torch.load(PATH1))my_encoderrnn.load_state_dict(torch.load(PATH1, map_location=lambda storage, loc: storage), False)# 實例化模型input_size = french_word_nhidden_size = 256 # 觀察結果數據 可使用8my_attndecoderrnn = AttnDecoderRNN(input_size, hidden_size)# my_attndecoderrnn.load_state_dict(torch.load(PATH2))my_attndecoderrnn.load_state_dict(torch.load(PATH2, map_location=lambda storage, loc: storage), False)sentence = "we re both teachers ."# 樣本x 文本數值化tmpx = [english_word2index[word] for word in sentence.split(' ')]tmpx.append(EOS_token)tensor_x = torch.tensor(tmpx, dtype=torch.long, device=device).view(1, -1)# 模型預測decoded_words, attentions = Seq2Seq_Evaluate(tensor_x, my_encoderrnn, my_attndecoderrnn)print('decoded_words->', decoded_words)# print('\n')# print('英文', sentence)# print('法文', output_sentence)plt.matshow(attentions.numpy()) # 以矩陣列表的形式 顯示# 保存圖像plt.savefig("./s2s_attn.png")plt.show()print('attentions.numpy()--->\n', attentions.numpy())print('attentions.size--->', attentions.size())運行結果:
decoded_words-> ['nous', 'sommes', 'toutes', 'deux', 'enseignantes', '.', '<EOS>']Attention可視化:
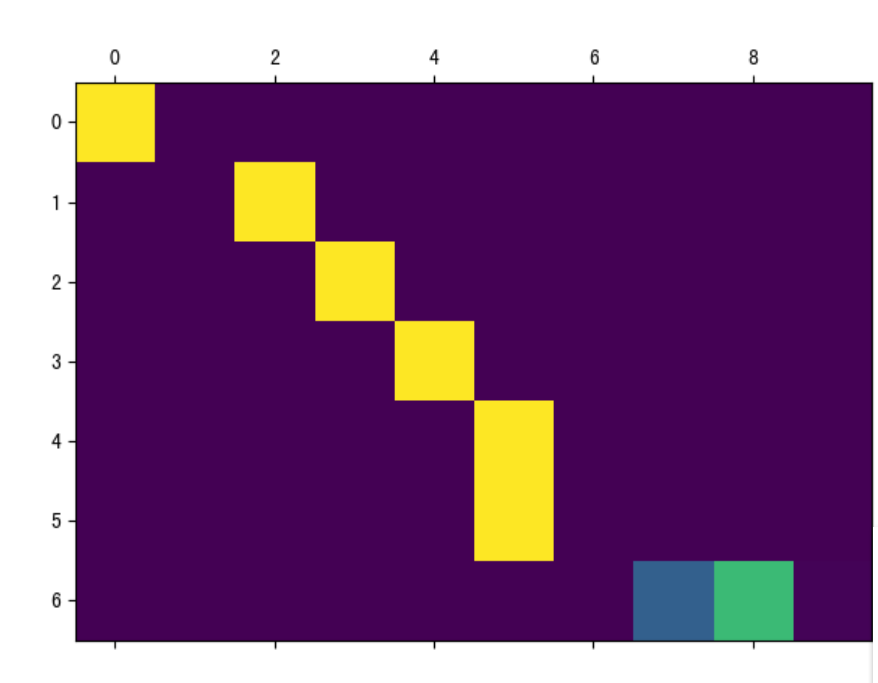
Attention圖像的縱坐標代表輸入的源語言各個詞匯對應的索引:
0-6分別對應[“we”, “re”, “both”, “teachers”, “.”, “”], 縱坐標代表生成的目標語言各個詞匯對應的索引, 0-7代表[‘nous’, ‘sommes’, ‘toutes’, ‘deux’, ‘enseignantes’, ‘.’, ‘’], 圖中淺色小方塊(顏色越淺說明影響越大)代表詞匯之間的影響關系, 比如源語言的第1個詞匯對生成目標語言的第1個詞匯影響最大, 源語言的第4,5個詞對生成目標語言的第5個詞會影響最大。
通過這樣的可視化圖像, 我們可以知道Attention的效果好壞, 進而衡量我們訓練模型的可用性。
今日分享到此結束。

)








![[hot 100 ]最長連續序列-Python3](http://pic.xiahunao.cn/[hot 100 ]最長連續序列-Python3)
![[element-plus] el-table show-overflow-tooltip 沒有顯示省略號](http://pic.xiahunao.cn/[element-plus] el-table show-overflow-tooltip 沒有顯示省略號)







