目錄
一 網絡爬蟲的了解
1 爬蟲庫
urllib庫
requests庫
scrapy庫
selenium庫
2 注意!!!
二 requests庫
1 request庫的安裝
2 認識網頁資源
3 獲取網頁資源
4 小案例
5 代理服務器
三 selenium
1 準備工作
2 應用
3 實例
一 網絡爬蟲的了解
????????網絡爬蟲是一種自動化程序,用于從互聯網上抓取、解析和存儲網頁數據。通常用于搜索引擎、數據分析或信息聚合等場景。
1 爬蟲庫
python給我們提供了多個爬蟲庫,下面我們來先了解四個
urllib庫
????????urllib是Python內置的HTTP請求庫,包含多個模塊用于處理URL操作。主要模塊包括urllib.request(打開和讀取URL)、urllib.error(異常處理)、urllib.parse(解析URL)和urllib.robotparser(解析robots.txt文件)。適用于簡單的HTTP請求,但功能相對基礎,缺乏高級特性如會話保持和連接池。
requests庫
????????requests是一個第三方HTTP庫,基于urllib開發,但提供了更簡潔的API和更強大的功能。支持HTTP連接保持、會話對象、Cookie持久化、文件上傳等。其設計注重易用性,適合大多數HTTP請求場景,如API調用或網頁抓取。
scrapy庫
????????scrapy是一個開源的爬蟲框架,用于大規模數據抓取。提供完整的爬蟲工作流管理,包括請求調度、數據提取、存儲等。支持異步處理、中間件擴展和分布式爬取。適合復雜爬蟲項目,但學習曲線較陡峭,需遵循框架的設計模式。
selenium庫
????????selenium是一個自動化測試工具,主要用于瀏覽器自動化。通過驅動真實瀏覽器(如Chrome、Firefox)模擬用戶操作,支持JavaScript渲染頁面的抓取。適用于動態網頁或需要交互的場景,但性能較低,資源消耗較大。
四者的選擇取決于需求:簡單請求用requests,復雜爬蟲用scrapy,動態頁面用selenium,而urllib適合無需依賴第三方庫的基礎場景。
這篇我們來具體學習requests,selenium庫
2 注意!!!
????????所有學習爬蟲的學者在學習爬蟲之前都要閱讀爬蟲規則,不是所有網站上的資源都允許爬取的,我們在爬取之前要查看該網站的robots.txt規則。下面以CSDN為例查看一下
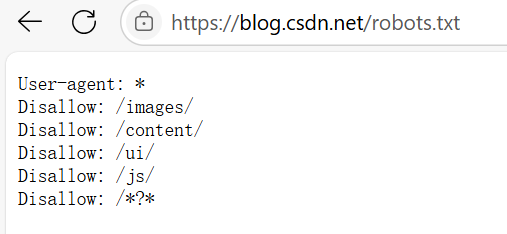
上面列舉了這些不能爬取的。如果硬爬的話小心進局子!
二 requests庫
1 request庫的安裝
在命令提示符窗口或pycharm終端進行安裝。(如果比較慢,我們可以用清華源安裝)
pip install requests -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple2 認識網頁資源
我們可以通過在網頁空白處,點擊左鍵,會出現
網頁源代碼
????????我們先點擊一下查看頁面源代碼,我們查找一下.jpg發現沒有一張圖片但網頁中卻存在許多雜照片,這是是因為.jpg是經過瀏覽器渲染之后才會出現的,在源代碼中不存在.jpg格式的數據
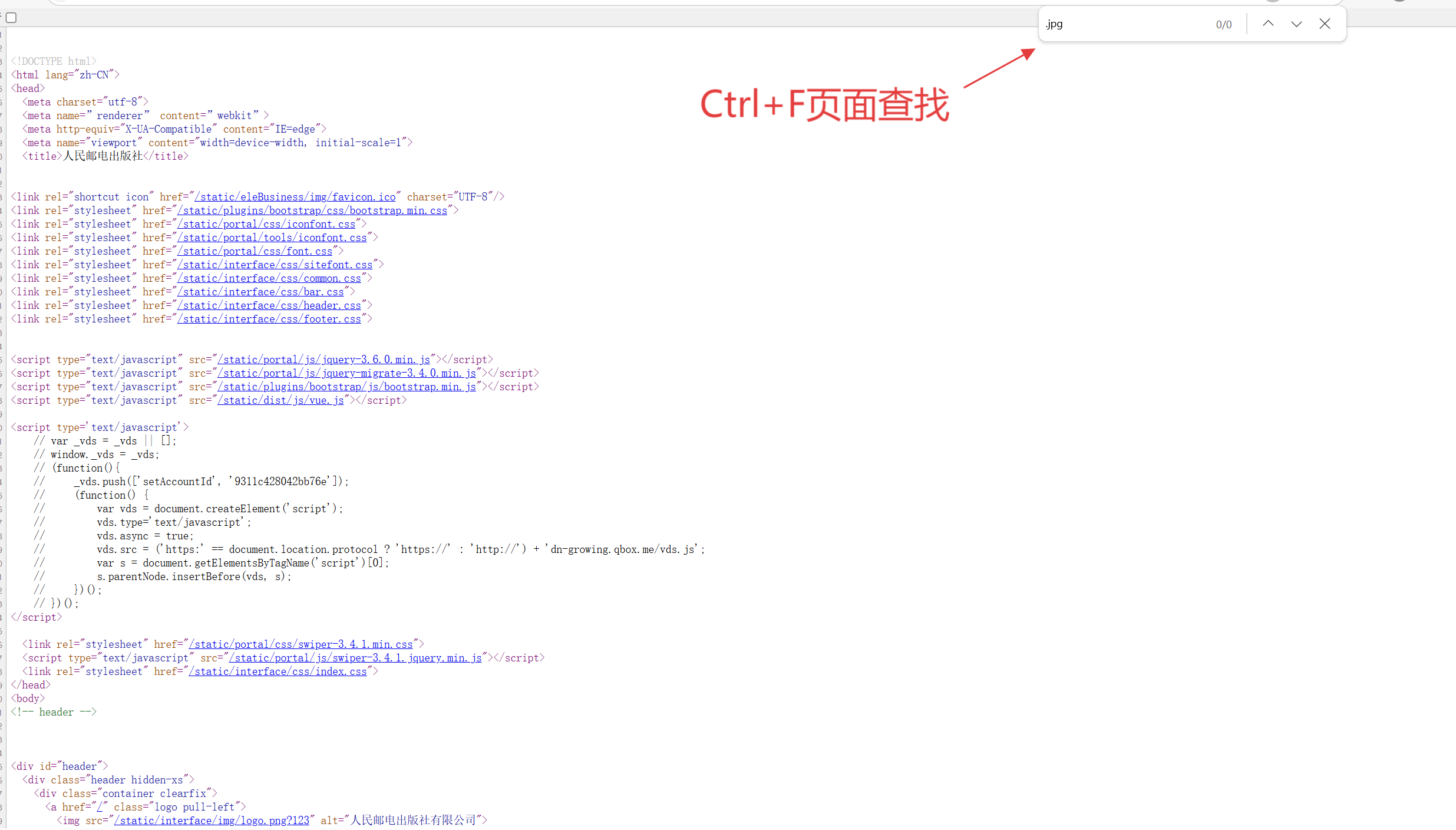
檢查
我們點擊完檢查,然后再點擊中間那個按鈕,然后就可以自動定位到這個圖片的url了,我們也就可以使用了,所有這個是渲染之后的?
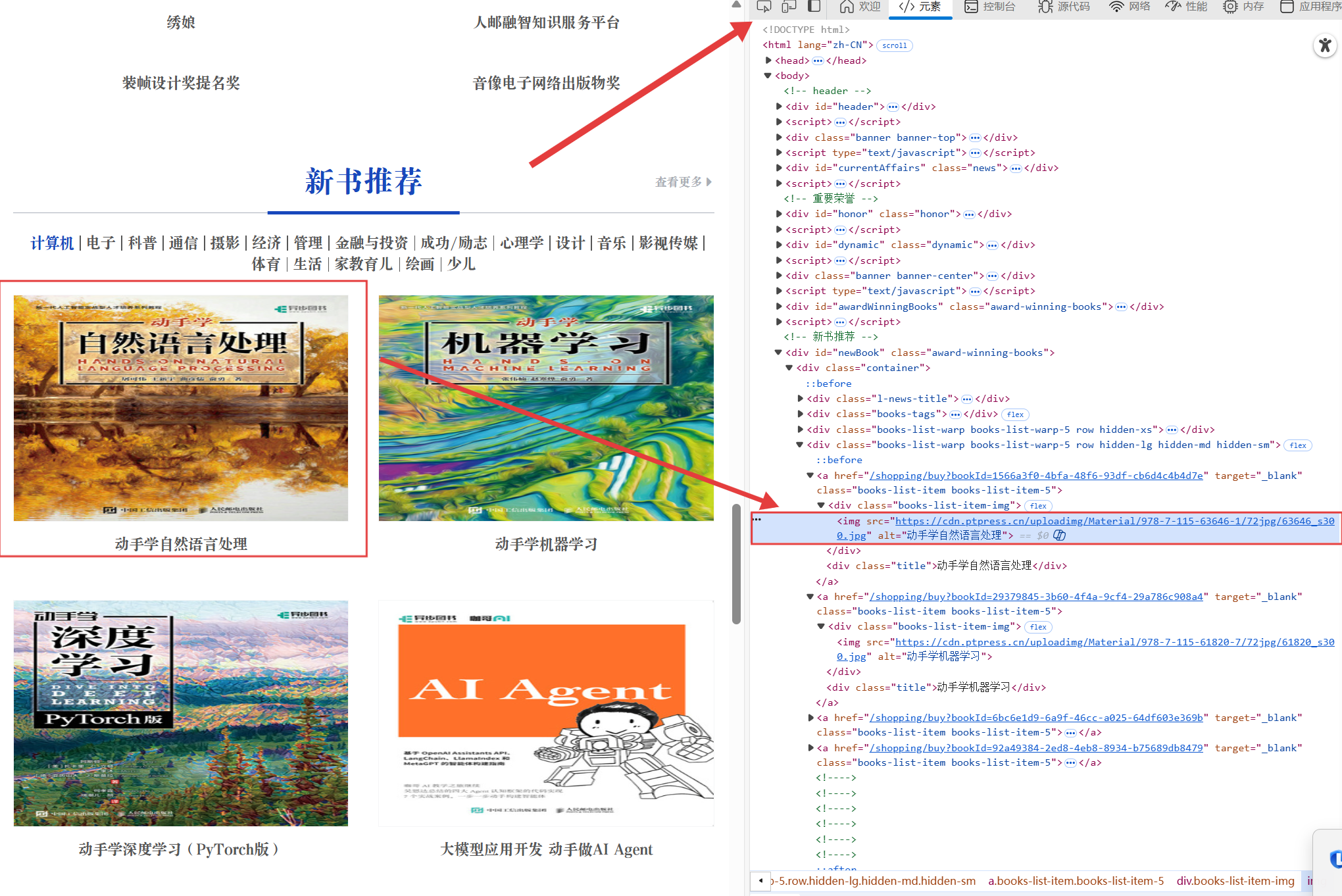
我們先點擊中間那個按鈕,然后就可以自動定位到這個圖片的url了,我們也就可以使用了,所有這個是渲染之后的?
3 獲取網頁資源
我們用get()函數來獲取,這個函數有三個形參,分別是
url? ? ? ? 圖片的HTML網址
params? ? ? ? 可選參數,構造url字符串的
返回值是一個由類Response創建的對象
下面舉例
import requests
r=requests.get("https://www.ptpress.com.cn/search",params={'keyword': 'Python教程'})
r.encoding=r.apparent_encoding
n=r.status_code
print(r.text)
print(n)這段代碼,在get中,我們有兩個參數,一個url為中國郵電出版社的網址,一個params為一個字典{'keyword': 'Python教程'},這行代碼也相當于
https://www.ptpress.com.cn/?keyword=python只查找一個python可能會有點麻煩,但如果要查找許多個這樣寫就會便捷許多
如果不對編碼進行調整,返回的text就會有亂碼的部分,這里將檢測到的編碼賦值給了我們設定對象類的編碼。
這里我們還對狀態碼進行了檢查,如果狀態碼為404,那么這個網頁不存在、如果是200則請求成功,如果500則是內部服務器錯誤。
4 返回頁面內容
有個問題,我們這里返回的是網頁源代碼還是檢查得到的內容呢,
我們在返回值中查詢,結果得到的.jpg的數量還是0,說明這個是返回的源代碼的內容
import requests
r=requests.get(r"https://cdn.ptpress.cn/uploadimg/Material/978-7-115-66932-2/72jpg/66932_s300.jpg")
f=open("test.jpg","wb")
f.write(r.content)
f.close()這個代碼中我們輸入的一個.jpg格式的網站,然后我們把這個內容保存到了一個二進制文件中,然后就變成了一個圖片了,這個說明了r.content返回的內容和上面.txt返回的內容不一樣,這個返回的是一個保存著這個圖片的二進制的文件。
圖片、音頻、視頻、壓縮包可以用.content保存,HTML、JSON等可以用.txt保存
4 小案例
我們把一個網站中所有的書名打印下來
import re
import requests
r=requests.get(r"https://www.ryjiaoyu.com/book")
# title="計算機應用基礎習題與實驗教程(Windows 10+Office 2016)(第3版)">計算機應用基礎習題與實驗教程(Windows 10+Office 2016)(第3版)</a></h4>
result=re.findall(r'title=(.+?)">(.+?)</a></h4>',r.text)
print(result)
for i in range(len(result)) :print('第'+str(i+1)+'本書:'+result[i][1])輸出結果:
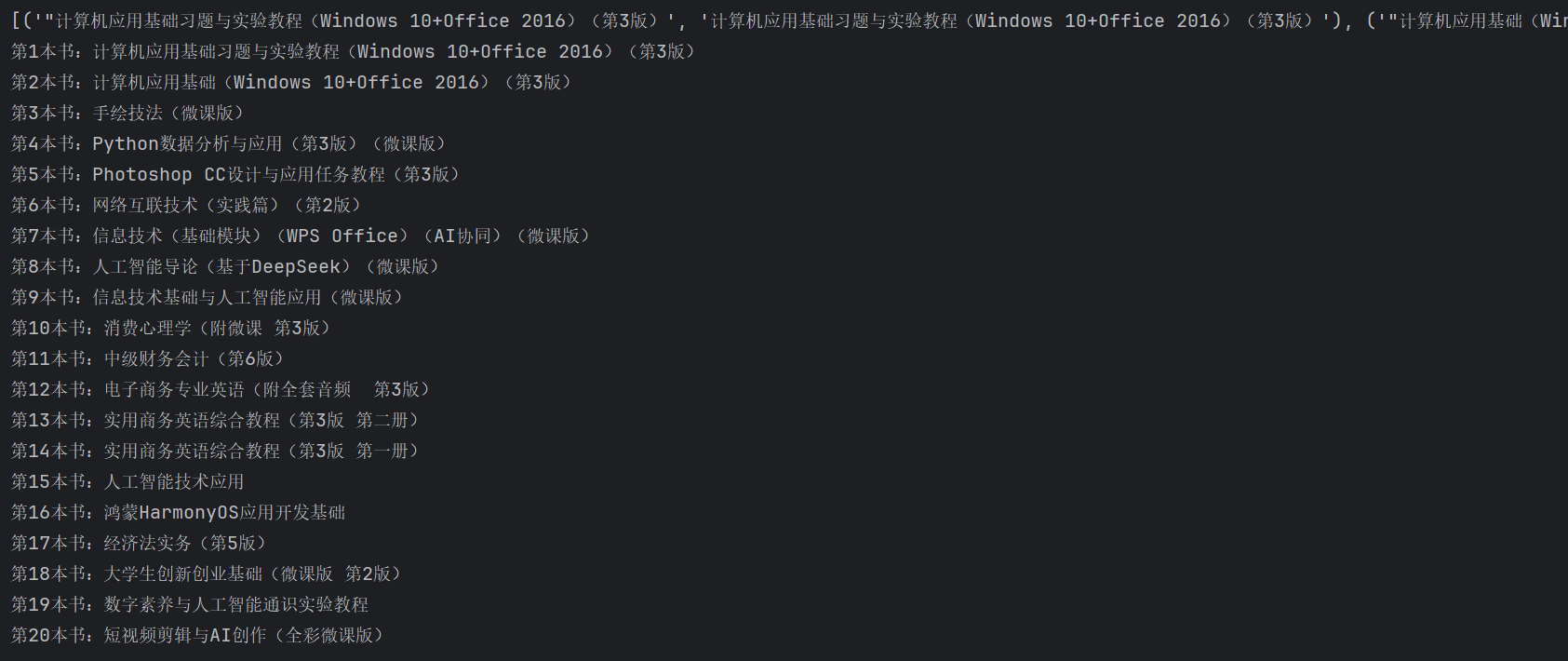
代碼解讀:
?首先導入庫,然后用requests.get()函數讀取網址內容,然后觀察網址中我們要找書名存在位置行的特征,寫出正則表達式,我們這里保存下來的結果是一個列表,列表中包含若干個元組,然后我們循環打印出索引為1的值就出結果了
5 代理服務器
代理服務器就是當我們請求過多被加入黑名單之后,然后可以通過買代理服務器來繼續請求,這個服務器可以理解成另一個電腦,建立鏈接,我們向代理服務器發送請求,然后代理服務器把請求發送給目標網站,然后目標網站返回信息,代理服務器在返回給我們。
使用方法
import requestsproxie={'http':'代理服務器ip'}
response = requests.get("https://www.ptpress.com.cn/",proxies=proxie)
print(response.text) # 獲取網頁內容
這里http應為代理服務器網址,可以買,免費的很少且不穩定。
三 selenium
????????驅動真實瀏覽器(如Chrome、Firefox)模擬用戶操作,且瀏覽器可以實現頁面的渲染,因此我們很容易獲得選然后的數據信息。(說明這里我們得到的是’檢查‘得到的內容)
1 準備工作
? ? ? ? selenium可以驅動內核,但我們還是要安裝對應版本的瀏覽器的內核驅動程序以便于更好的驅動瀏覽器。下面我們來安裝下WebDriver
第一步 先查看我們電腦的瀏覽器版本號(不同瀏覽器的驅動也不一樣,我這里是edge)
? ? ? ?在右上角有三個點,下面可以看到關于Microsoft Edfe

然后可以查看到,我的瀏覽器內核版本為138.0.3351.95
第二步 去官網下載
Microsoft Edge WebDriver | Microsoft Edge Developer上面可以找到對應版本。一般我們電腦下載x64位就好了
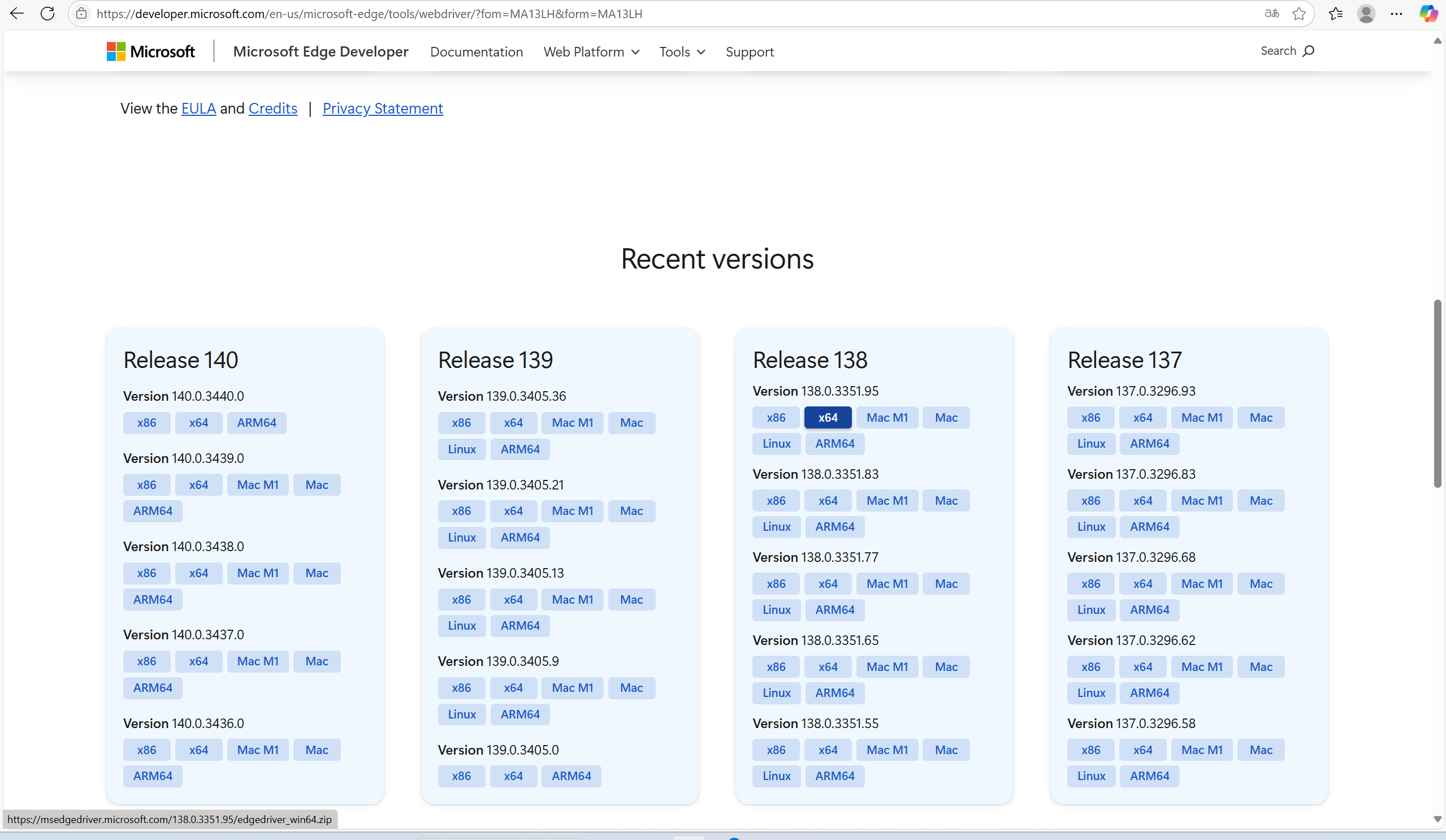
?第三步 把msedgedriver放到我們python的Scripts中

?(最好scripts中和python所在文件夾中分別放一個)
第四步 下載selenium庫
直接在終端pip安裝就好
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple了解selenium操作原理
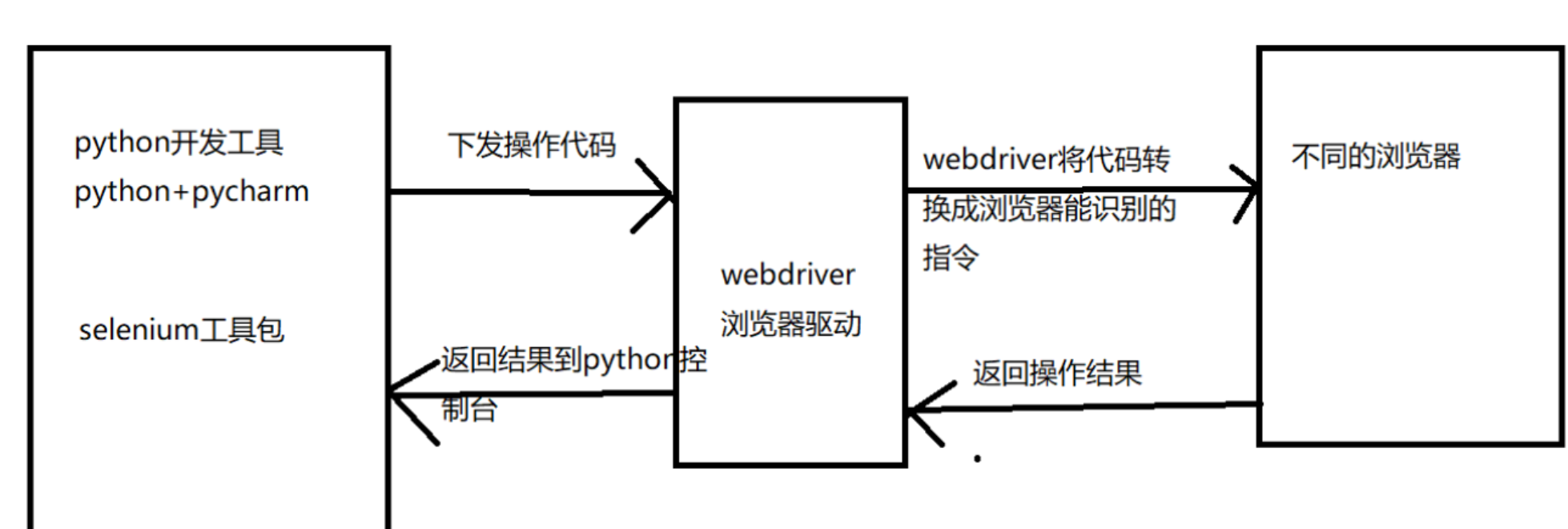
2 應用
import time
import requests
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/search?keyword=c++&jc=")
print(driver.page_source)
sleep(100)不同人的edge的位置可能不用,要修改下edge_options.binary_locatio
不同瀏覽器的這個也不同,例如我的edge是這樣webdriver.Edge(options=edge_options)驅動的
如果是谷歌就是driver = webdriver.Edge(options=chrome_options)
然后就可以驅動起來了,但是驅動完又會直接退出,這里可以sleep一下
加載網頁用driver.get()來加載,填入url就可以加載頁面了
可以通過driver.page_source來獲取渲染后的網頁代碼,下面是部分

3 實例
使用selenium把中國郵電出版社的c++板塊的幾本書圖片給爬下來。
import re
import timeimport requests
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/search?keyword=c++&jc=")
print(driver.page_source)
result=re.findall('<img src="(.+?jpg)">',driver.page_source)suresult=re.findall('</div><p>(.+?)</p></a>',driver.page_source)for i in range(len(result)):r = requests.get(result[i])name=r'c++圖書/'+suresult[i].replace(" ", "")+'.jpg'f = open(name, "wb")f.write(r.content)f.close()
輸出結果

??











)




)
)

