目錄
一、前言
二、條形圖
1.?簡單的條形圖
2.堆積、分組和填充條形圖(柱狀圖)?
(1)堆積圖,對Improved進行堆積,注意position=“stack”
(2)分組圖,對Improved進行分組,注意position=“dodge”:
?(3)填充條形圖,對Improved進行填充,注意position=“fill”:
(4)關于position的設置可以分為以下4種:
3.均值條形圖
(2)計算不同地區的平均文盲率:
(3)作圖
(4)帶誤差線的條形圖
?4.條形圖的微調
(1)顏色
(2)條形圖的標簽
1)旋轉
2)修改坐標軸的字體字號和旋轉角度
一、前言
????????ggplot2 是一個基于 R 語言的數據可視化包,提供了一種結構化的方法來描述和構建圖表,因此被廣泛用于制作可視化圖表。其是tidyverse數據科學生態系統的一部分。
????????在 ggplot2 中,每一個圖形都是從數據映射到美學屬性(如顏色、形狀和大小)、加上幾何對象(如點、線和條形圖)、統計變換和坐標系等元素組合而成。這種分層和模塊化的方法使得用戶可以靈活地創建復雜的圖表,同時保持代碼的可讀性和易用性。通過ggplot2,你可以創建各種圖表:包括但不限于散點圖、線圖、直方圖、條形圖和箱線圖。此外,ggplot2 提供了廣泛的自定義選項,允許用戶調整幾乎圖表的每個細節,以適應具體的展示需求。
????????簡而言之,ggplot2 是 R 語言中一個功能強大且靈活的數據可視化工具。因此,本文主要學習如何在R語言中通過ggplot2來繪制條形圖、堆積圖、餅圖、直方圖、核密度圖、箱圖、小提琴圖。
二、條形圖
以 vcd 包中的Arthritis數據框為例:
install.packages("vcd")
library(vcd)
library(grid)
data_frame <- package_name::data_frame_name
Arthritis <- vcd::Arthritis
Arthritis?輸出如下:
ID Treatment Sex Age Improved
1 57 Treated Male 27 Some
2 46 Treated Male 29 None
3 77 Treated Male 30 None
4 17 Treated Male 32 Marked
5 36 Treated Male 46 Marked
6 23 Treated Male 58 Marked
7 75 Treated Male 59 None
8 39 Treated Male 59 Marked
9 33 Treated Male 63 None
10 55 Treated Male 63 None
11 30 Treated Male 64 None
12 5 Treated Male 64 Some
13 63 Treated Male 69 None
14 83 Treated Male 70 Marked
15 66 Treated Female 23 None
16 40 Treated Female 32 None
17 6 Treated Female 37 Some
18 7 Treated Female 41 None
19 72 Treated Female 41 Marked
20 37 Treated Female 48 None
21 82 Treated Female 48 Marked
22 53 Treated Female 55 Marked
23 79 Treated Female 55 Marked
24 26 Treated Female 56 Marked
25 28 Treated Female 57 Marked
26 60 Treated Female 57 Marked
27 22 Treated Female 57 Marked
28 27 Treated Female 58 None
29 2 Treated Female 59 Marked
30 59 Treated Female 59 Marked
31 62 Treated Female 60 Marked
32 84 Treated Female 61 Marked
33 64 Treated Female 62 Some
34 34 Treated Female 62 Marked
35 58 Treated Female 66 Marked
36 13 Treated Female 67 Marked
37 61 Treated Female 68 Some
38 65 Treated Female 68 Marked
39 11 Treated Female 69 None
40 56 Treated Female 69 Some
41 43 Treated Female 70 Some
42 9 Placebo Male 37 None
43 14 Placebo Male 44 None
44 73 Placebo Male 50 None
45 74 Placebo Male 51 None
46 25 Placebo Male 52 None
47 18 Placebo Male 53 None
48 21 Placebo Male 59 None
49 52 Placebo Male 59 None
50 45 Placebo Male 62 None
51 41 Placebo Male 62 None
52 8 Placebo Male 63 Marked
53 80 Placebo Female 23 None
54 12 Placebo Female 30 None
55 29 Placebo Female 30 None
56 50 Placebo Female 31 Some
57 38 Placebo Female 32 None
58 35 Placebo Female 33 Marked
59 51 Placebo Female 37 None
60 54 Placebo Female 44 None
61 76 Placebo Female 45 None
62 16 Placebo Female 46 None
63 69 Placebo Female 48 None
64 31 Placebo Female 49 None
65 20 Placebo Female 51 None
66 68 Placebo Female 53 None
67 81 Placebo Female 54 None
68 4 Placebo Female 54 None
69 78 Placebo Female 54 Marked
70 70 Placebo Female 55 Marked
71 49 Placebo Female 57 None
72 10 Placebo Female 57 Some
73 47 Placebo Female 58 Some
74 44 Placebo Female 59 Some
75 24 Placebo Female 59 Marked
76 48 Placebo Female 61 None
77 19 Placebo Female 63 Some
78 3 Placebo Female 64 None
79 67 Placebo Female 65 Marked
80 32 Placebo Female 66 None
81 42 Placebo Female 66 None
82 15 Placebo Female 66 Some
83 71 Placebo Female 68 Some
84 1 Placebo Female 74 Marked1.?簡單的條形圖
在該數據框中,變量improved記錄了對每位接受了安慰劑或藥物的病人的治療效果:
table(Arthritis$Improved)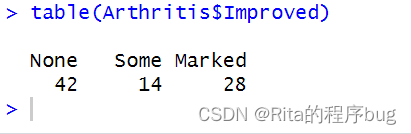
table()函數用于創建頻數表(頻率表)或列聯表,它可以統計向量中每個元素的出現次數。
對Improved變量作簡單的條形圖:
library(ggplot2)
ggplot(Arthritis,aes(x=Improved))+geom_bar()+labs(title = "Simple Bar chart",x="Improved",y="Frequency")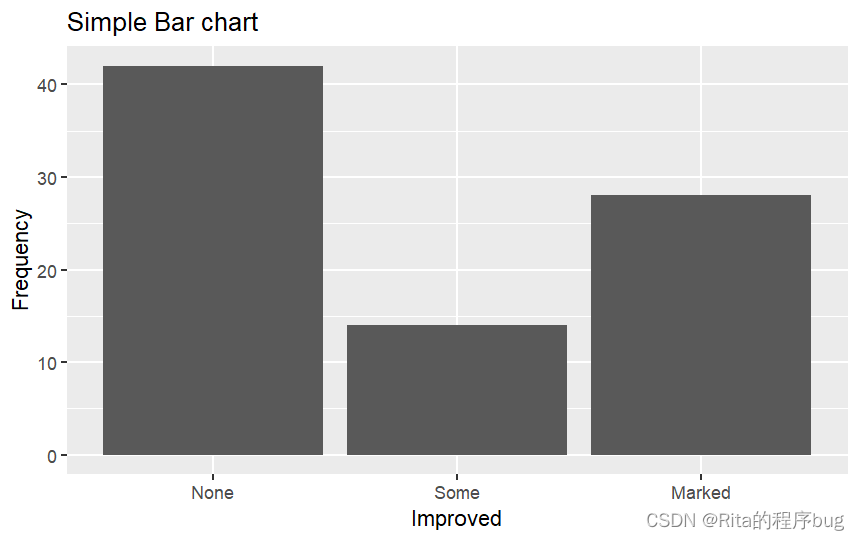
將上面的變量圖修改為橫著的,利用函數coord_flip()可以在繪制圖形時交換x軸和y軸的方向,從而實現圖形的翻轉(全稱coordinate Flip就是坐標翻轉的意思):
library(ggplot2)
ggplot(Arthritis,aes(x=Improved))+geom_bar()+labs(title = "Horizontal Bar chart",x="Improved",y="Frequency")+coord_flip()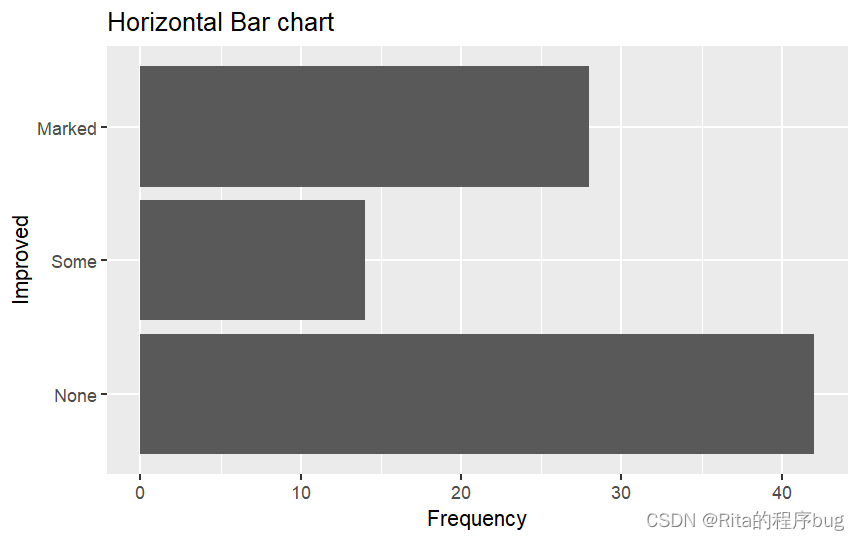
2.堆積、分組和填充條形圖(柱狀圖)?
例子:比較分別接受了安慰劑(Placebo)或藥物(Treated)的病人的治療效果

(1)堆積圖,對Improved進行堆積,注意position=“stack”
library(ggplot2)
ggplot(Arthritis,aes(x=Treatment,fill=Improved))+geom_bar(position = "stack")+labs(title="Stacked Bar chart",x="Treament",y="Frequency")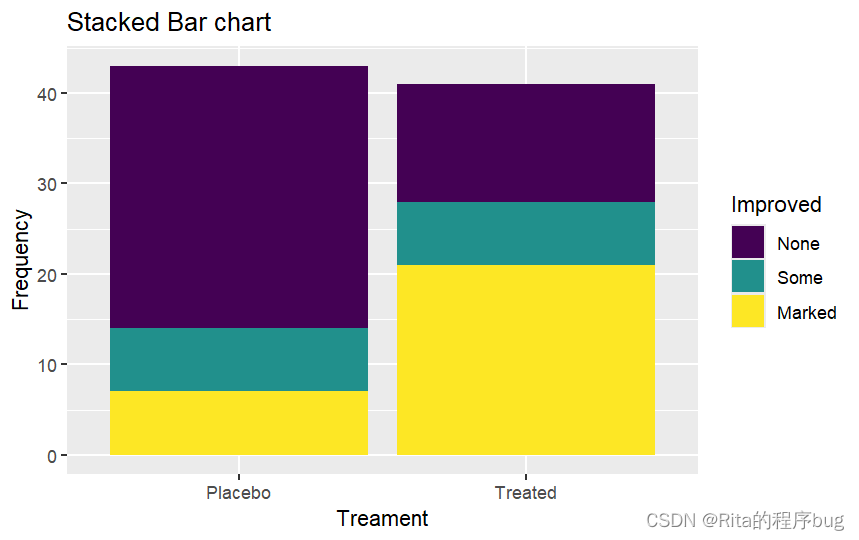
(2)分組圖,對Improved進行分組,注意position=“dodge”:
library(ggplot2)
ggplot(Arthritis,aes(x=Treatment,fill=Improved))+geom_bar(position = "dodge")+labs(title="Grouped Bar chart",x="Treament",y="Frequency")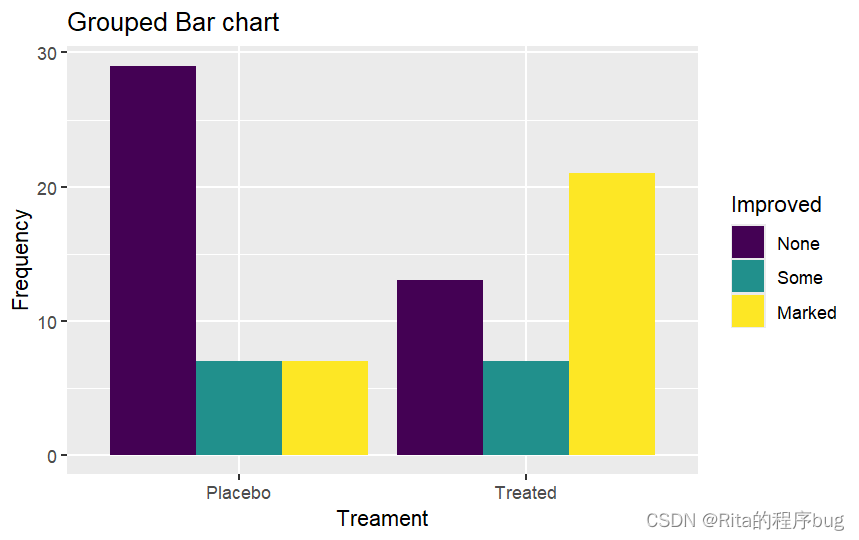
?(3)填充條形圖,對Improved進行填充,注意position=“fill”:
library(ggplot2)
ggplot(Arthritis,aes(x=Treatment,fill=Improved))+geom_bar(position = "fill")+labs(title="Filled Bar chart",x="Treament",y="Frequency")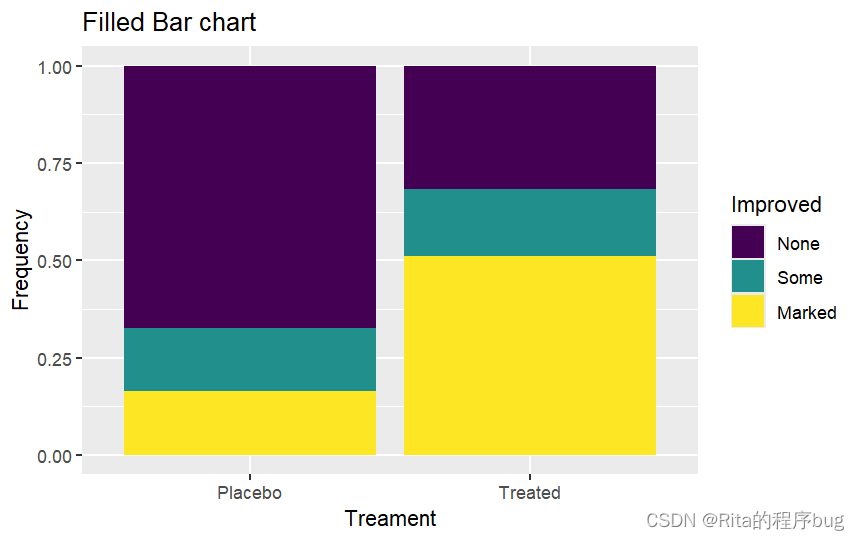
(4)關于position的設置可以分為以下4種:
1)position=“stack”(默認值):將柱子堆疊在一起,形成堆疊柱狀圖。
2)position=“fill”:將每個柱子的高度歸一化為1,使得每個柱子的面積代表相對比例。這樣可以更好地比較不同類別之間的相對頻率或比例。
3)position=“dodge”:將柱子并排顯示,以顯示不同類別之間的直接比較。每個類別的柱子寬度保持不變。
4)position=“identity”(用的少):不對柱子進行任何位置調整,直接使用數據中的數值作為柱子的位置。這通常用于自定義柱狀圖的位置布局。
3.均值條形圖
(1)舉例
用R自帶數據集state.x77來繪制1970年美國各地區的平均文盲率,數據集state.region具有每個州所屬的地區名,看一下state.x77和state.region數據集:
head(state.x77)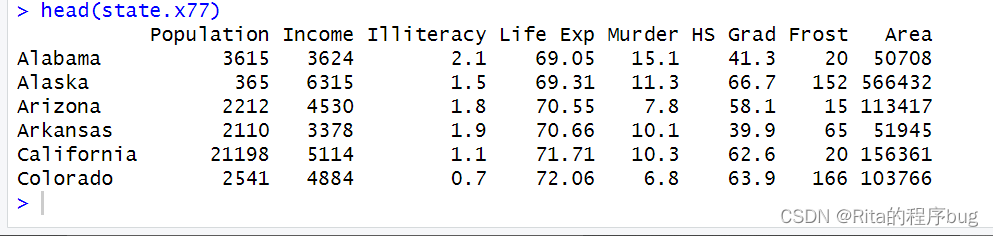
state.region?
(2)計算不同地區的平均文盲率:
states <- data.frame(state.region,state.x77)
library(dplyr)
plotdata <- states %>%group_by(state.region)%>%summarize(mean=mean(Illiteracy))
plotdata?
(3)作圖
library(ggplot2)
ggplot(plotdata,aes(x=reorder(state.region,mean),y=mean))+geom_bar(stat = "identity")+labs(x="region",y="mean",title = "Mean Illiteracy Rate")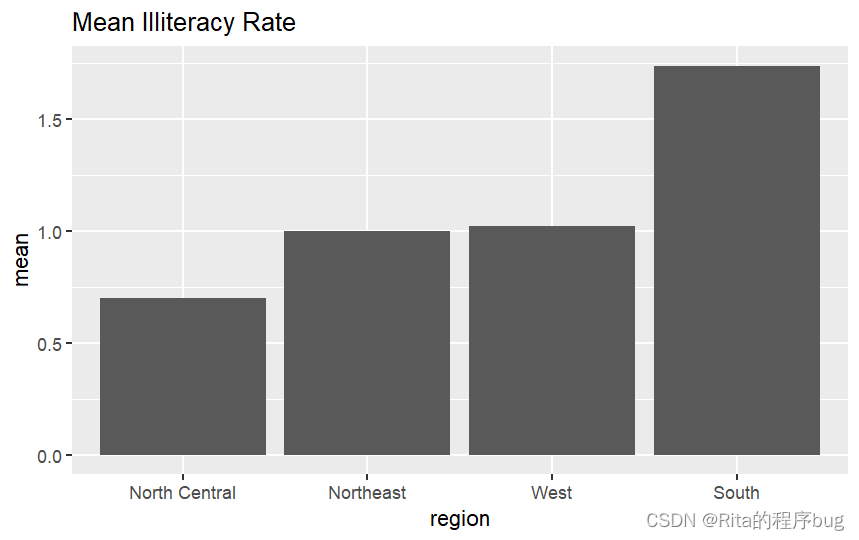
注意:
1)reorder()函數用于對因子(factor)變量進行重新排序,以便根據另一個變量的值對其進行排序。它通常與aes()函數結合使用,用于設置繪圖的變量映射:
reorder(variable, by_variable, FUN = NULL)variable:是要重新排序的因子變量。被排序者
by_variable是用于排序的參考變量,可以是任何數值型變量或表達式。按什么排序
FUN是一個可選的函數,用于對by_variable進行聚合。默認情況下,它不進行聚合,而是直接使用by_variable的值進行排序。
2)stat = “identity”表示不進行任何統計變換,直接使用原始數據進行繪圖。stat還可以設置為:
stat=“count”:默認選項,根據每個類別的頻數(計數)創建柱狀圖。這是geom_bar的默認統計變換,它會自動對數據進行計數,并使用計數值作為柱子的高度。
stat=“bin”:將連續變量進行離散化分組,并顯示每個分組的頻數。這通常用于創建直方圖,將連續變量分成多個離散的區間,并顯示每個區間中觀測值的頻數。
stat=“density”:根據密度估計函數,計算每個類別的密度曲線。這適用于連續變量的柱狀圖,其中柱子的高度表示密度而不是頻數。
stat=“summary”:根據指定的摘要函數,計算每個類別的摘要統計量,例如均值、中位數等。這對于創建帶有摘要統計信息的柱狀圖很有用。
stat=“bin2d”:用于創建二維直方圖,將兩個連續變量分成多個二維的離散區間,并顯示每個區間中觀測值的頻數。
(4)帶誤差線的條形圖
求SEM=SD/sqrt(n),這里用n=n()來計算每組組內觀測值的數量:
states <- data.frame(state.region,state.x77)
library(dplyr)
plotdata1<- states %>%group_by(state.region)%>%summarize(n=n(),mean=mean(Illiteracy),SEM=sd(Illiteracy)/sqrt(n))
plotdata1?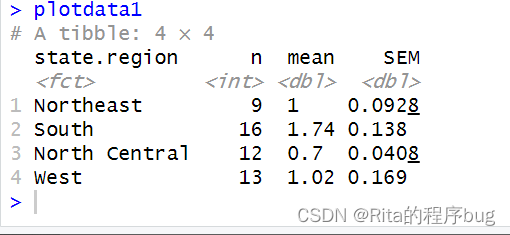
作圖(帶誤差線)用函數geom_errorbar(),并用ymin和ymax設置誤差線的上下限:
library(ggplot2)
ggplot(plotdata1,aes(x=reorder(state.region,mean),y=mean))+geom_bar(stat = "identity",fill="skyblue")+geom_errorbar(aes(ymin=mean-SEM,ymax=mean+SEM),width=0.2)+labs(x="region",y="mean",title = "Mean Illiteracy Rate",subtitle = "with standard error bars")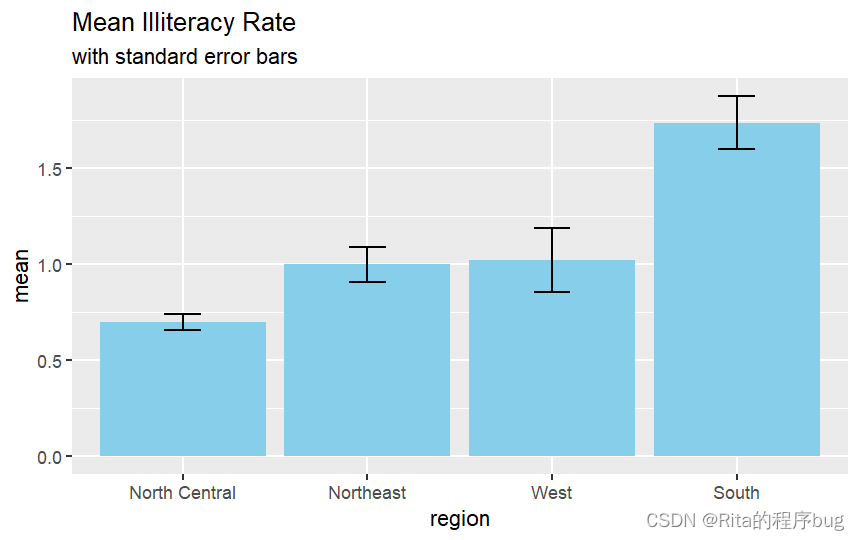
?4.條形圖的微調
(1)顏色
在geom_bar中,fill=“color“指定區域顏色,color=”color”指定邊框顏色。
前面對所有組添加的是同樣的顏色,也可以利用scale_fill_manual(values=c(“color1”,“color2”,“color3”,…))來手動設定不同組為不同的顏色,例如:
library(ggplot2)
ggplot(Arthritis,aes(x=Treatment,fill=Improved))+geom_bar(position = "stack",color="black")+scale_fill_manual(values = c("blue","red","skyblue"))?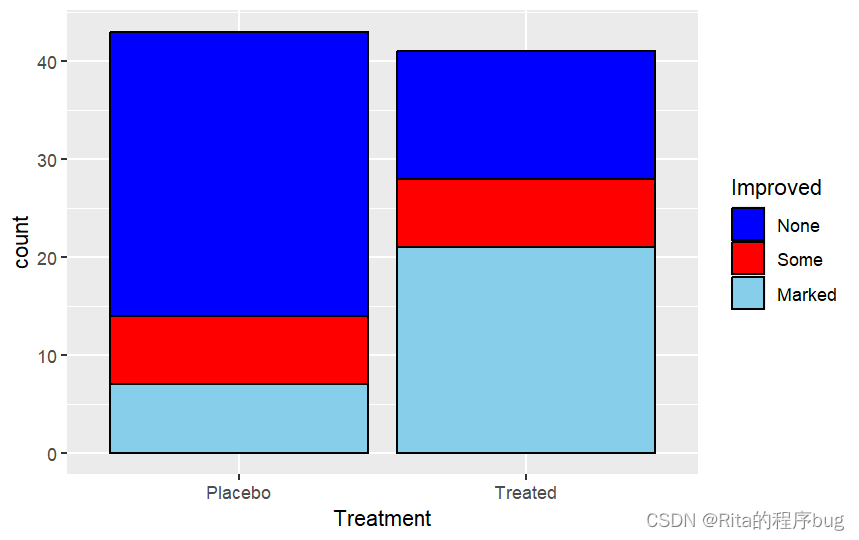
labs(title="Stacked Bar chart",x="Treament",y="Frequency")?
(2)條形圖的標簽
直接來看例子:
ggplot(mpg,aes(x=model))+geom_bar()+labs(title = "Car",y="Frequency",x="")?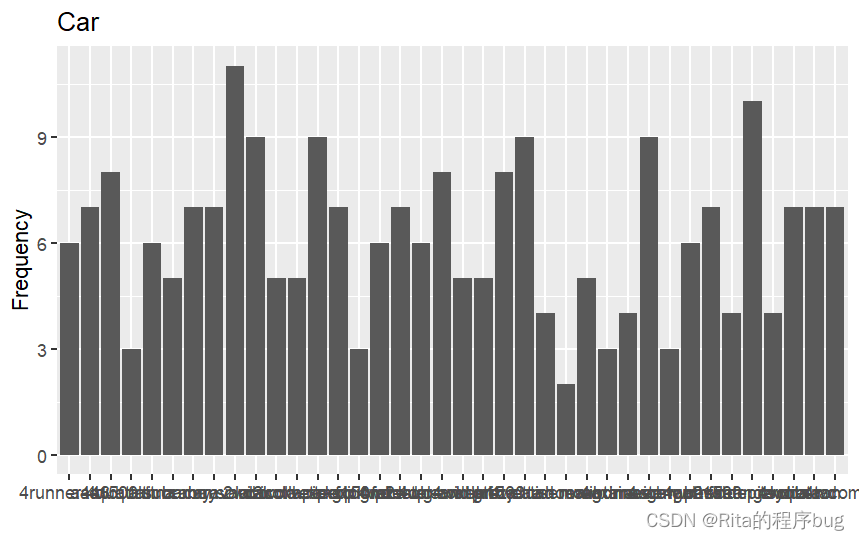
很顯然,x軸的標簽全部擠在一起,根本沒法看,可以選擇轉換橫縱坐標或者縮小x軸標簽的字號并對其旋轉一定角度。
1)旋轉
ggplot(mpg,aes(x=model))+geom_bar()+labs(title = "Car",y="Frequency",x="")+coord_flip()?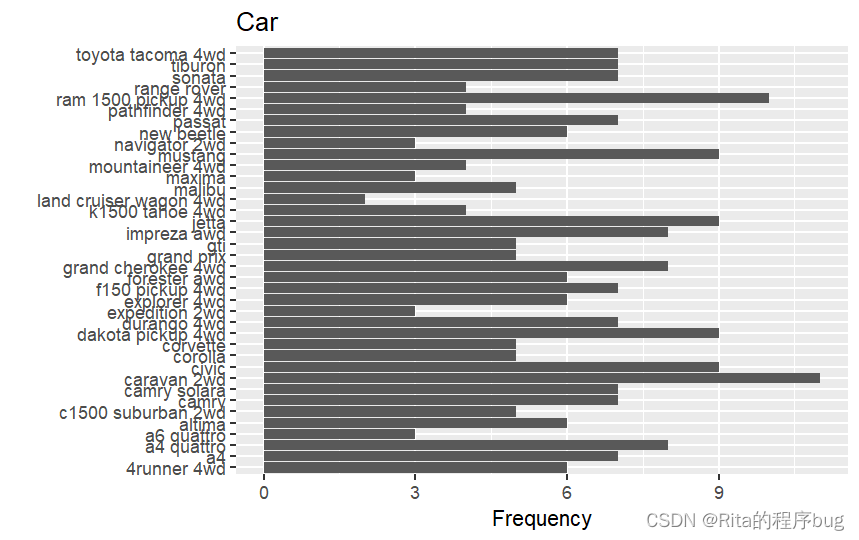
2)修改坐標軸的字體字號和旋轉角度
ggplot(mpg,aes(x=model))+geom_bar()+labs(title = "Car",y="Frequency",x="")+theme(axis.text.x = element_text(angle = 45,hjust = 1,size = 8))
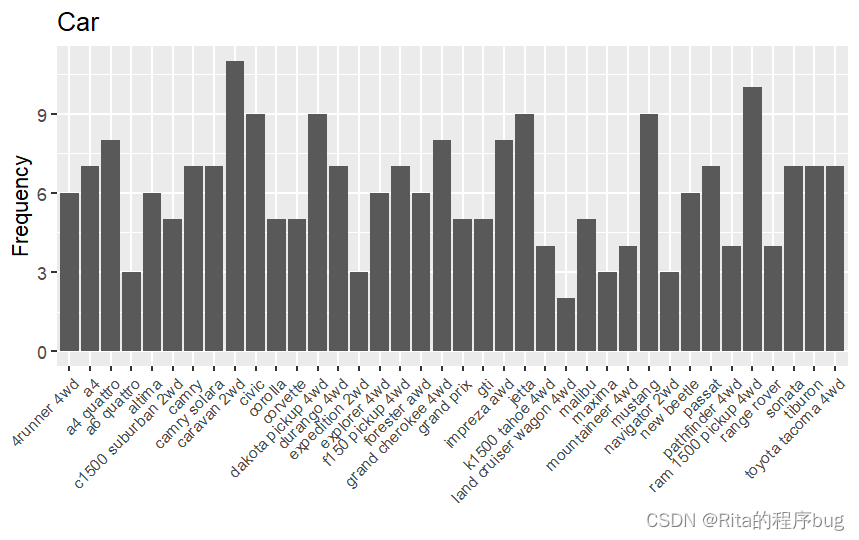
這里的theme()函數:
axis.text.x: 這指定我們正在自定義繪圖中的x軸文本。
element_text(): 這是用于自定義繪圖中文本元素(如軸標簽、標題和圖例)的函數。
angle = 45: 這個參數將x軸文本標簽的角度設定為45度。這意味著標簽將以順時針45度的角度旋轉。
hjust = 1: horizontal justification的縮寫,意為水平對齊方式。0:左對齊;0.5:居中對齊;1:右對齊。
size = 8: 這個參數將x軸文本標簽的大小設定為8點。它決定了標簽的字體大小。







)
--分組密碼)









 的弊端及修復方式)
