教程/講解視頻點擊文末名片
1、什么是語義分割,什么是FCN
我們提出了一種新穎且實用的深度全卷積神經網絡架構,用于語義像素級分割,命名為SegNet。
語義分割是指為圖像中的每個像素分配一個類別標簽(如道路、天空、汽車),以實現對場景的細粒度理解。
全卷積神經網絡(Fully Convolutional Network,簡稱 FCN)于2015提出。是深度學習用于語義分割領域的開山之作,在傳統卷積神經網絡(CNN)的基礎上進行了改進,傳統 CNN 主要用于圖像分類任務。它的結構通常包括卷積層、池化層和全連接層。在圖像分類中,CNN 的輸出是一個固定大小的向量(例如,1000 類分類任務的輸出向量長度為 1000),表示輸入圖像屬于各個類別的概率分布。
全連接層的輸入大小是固定的,這意味著輸入圖像的大小也必須固定。此外,全連接層的參數量巨大,導致模型復雜度高且難以擴展到像素級任務。
全卷積神經網絡的核心思想是將傳統 CNN 中的全連接層替換為卷積層,實現對任意大小輸入圖像的像素級處理。
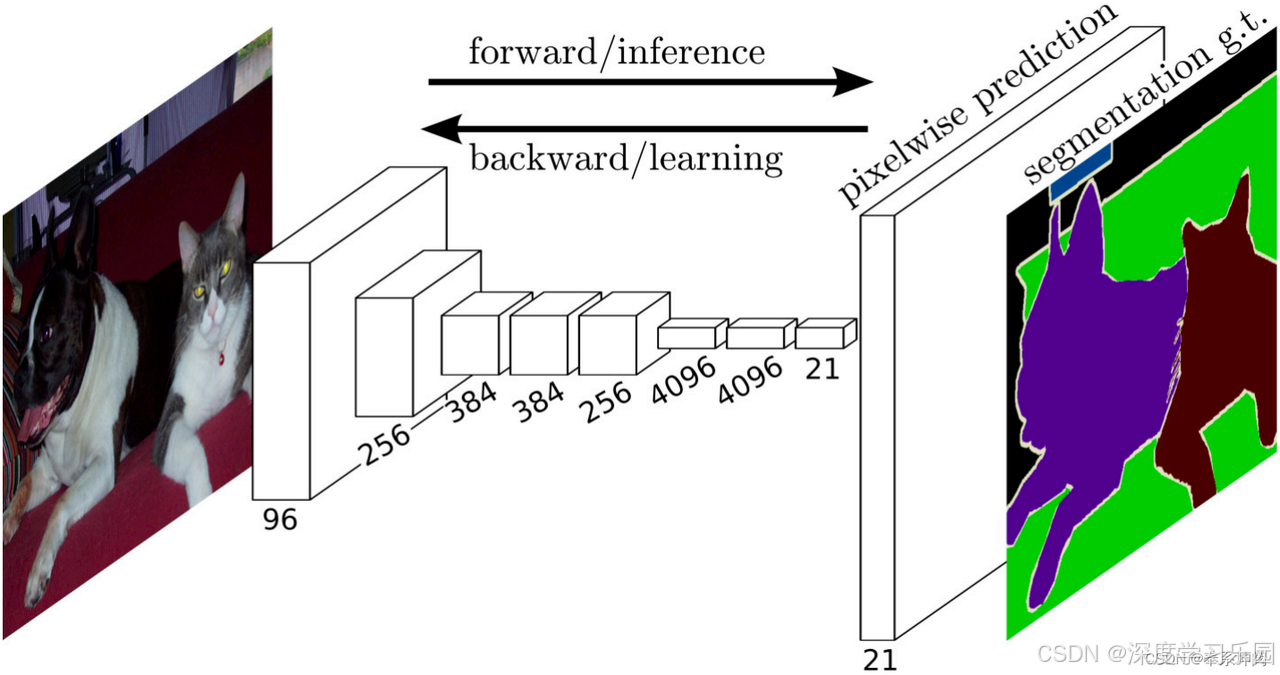
如fig1所示,全卷積網絡先使用卷積神經網絡抽取圖像特征,然后通過卷積層將通道數變換為類別個數,最后再通過轉置卷積層將特征圖的高和寬變換為輸入圖像的尺寸。因此,模型輸出與輸入圖像的高和寬相同,且最終輸出通道包含了該空間位置像素的類別預測。
2、SegNet架構簡介
該核心可訓練分割引擎由編 碼器網絡、對應的解碼器網絡以及像素級分類層組成。編碼器網絡的拓撲結構與VGG16網絡[1]中的13個卷積層完全一致。解碼器網絡 的作用是將低分辨率編碼器特征圖映射為全輸入分辨率特征圖,以便進行像素級分類
SegNet 的核心就是一個“分割引擎”,它由三部分組成:
- 編碼器網絡(Encoder):負責提取圖像的特征。
- 解碼器網絡(Decoder):負責把提取到的特征恢復成和輸入圖像一樣大的特征圖。
- 像素級分類層(Pixel-wise Classification Layer):負責給每個像素分配一個類別(比如“這是道路”“這是車輛”“這是行人”)。
編碼器網絡(Encoder)
編碼器網絡的結構和 VGG16 網絡中的前 13 個卷積層一模一樣。你可以把 VGG16 想象成一個“特征提取器”,它通過一層一層的卷積操作,把輸入的圖像變成一個低分辨率的特征圖。這個特征圖雖然小,但包含了圖像的關鍵信息。
簡單來說,編碼器的工作就是:
- 輸入一張大圖像(比如 224×224)。
- 經過 13 層卷積操作,輸出一個很小的特征圖(比如 7×7)。
- 這個特征圖雖然小,但包含了圖像的“精華”信息。
解碼器網絡(Decoder)
解碼器的作用是把編碼器輸出的低分辨率特征圖恢復成和輸入圖像一樣大的特征圖。這個過程有點像“放大鏡”,把小圖變成大圖。
解碼器的工作流程是: - 上采樣(Upsampling):解碼器利用編碼器階段保存的最大池化索引,把小特征圖“放大”成大特征圖。這個過程是非線性的,不需要學習額外的參數。
- 稀疏特征圖(Sparse Feature Map):上采樣后的特征圖是稀疏的,只有部分位置有值,其他位置是零。
- 卷積操作(Convolution):通過卷積操作,把稀疏特征圖變成密集特征圖。這個過程會讓特征圖更加“完整”,為后續的分類做好準備。
像素級分類層(Pixel-wise Classification Layer)
最后一步是像素級分類。解碼器輸出的高分辨率特征圖包含了每個像素的特征信息。像素級分類層的任務是: - 對每個像素的特征進行分類,判斷它屬于哪個類別(比如“道路”“車輛”“行人”)。
- 輸出一個和輸入圖像一樣大的分割圖,每個像素都有一個類別標簽。
3、SegNet創新點
SegNet的創新點在于解碼器對低分辨率輸入特征圖進行上采樣的方式。具體而言,解碼器利用編碼器對應步驟中計算的最大池化索引進行非線性上采樣,從而無需學習上采樣過程。 上采樣后的特征圖具有稀疏性,隨后通過與可訓練濾波器卷積生成密集特征圖。
優勢總結
- 無需學習上采樣參數:
- 傳統方法需要學習額外的參數來進行上采樣,而 SegNet 直接利用編碼器階段保存的索引信息進行上采樣,避免了學習上采樣參數的復雜性和計算開銷。
- 保留更多細節信息:
- 通過最大池化索引進行上采樣,能夠更準確地恢復特征圖的細節信息,因為它是基于原始特征圖中的最大值位置進行恢復的,而不是通過插值或其他近似方法。
- 稀疏特征圖的高效性:
- 稀疏特征圖在存儲和計算上更加高效,因為只有部分位置有非零值。通過卷積操作生成密集特征圖后,這些稀疏特征圖可以被有效地轉換為適合分類的密集特征圖。
- 背景:為什么需要上采樣?
在 SegNet 中,編碼器部分會把輸入圖像逐步壓縮成低分辨率的特征圖,這樣可以提取圖像的核心特征。但是,為了進行像素級分割,我們需要把這些低分辨率的特征圖恢復到和輸入圖像一樣的分辨率,這樣才能對每個像素進行分類。這個過程就叫“上采樣”。 - 傳統方法的局限性
在傳統的上采樣方法中,比如反卷積(Deconvolution)或插值(Interpolation),通常需要學習額外的參數來完成上采樣。這些方法的問題是:
- 需要額外的參數:這些參數需要通過訓練來學習,增加了模型的復雜性和訓練時間。
- 可能丟失細節:這些方法在恢復圖像細節方面可能不夠精確,導致分割結果不夠準確。
4、對比
Deconvolutional Network
DeepLab-LargeFOV
DeepLab-LargeFOV 是一種用于語義分割的深度學習模型,屬于 DeepLab 系列的早期版本。它的核心思想是通過使用空洞卷積(Atrous Convolution)來擴大感受野(Field of View)
- 普通卷積(Normal Convolution)
先來說說普通的卷積。想象一下,你有一張照片,你想用一個小窗口(卷積核)在照片上滑動,每次滑動都計算一下窗口內的像素值,然后生成一個新的像素值。這個過程就像是用一個小刷子在照片上涂抹,每次涂抹只覆蓋一小塊區域。
舉個例子:
- 假設你有一個 3×3 的卷積核,它會在輸入圖像上滑動,每次計算一個 3×3 區域內的像素值,生成一個新的像素值。
- 如果輸入圖像的分辨率是 224×224,經過普通卷積后,輸出圖像的分辨率會變小(比如 222×222),因為卷積核滑動時會丟失邊緣信息。
- 空洞卷積(Atrous Convolution)
空洞卷積和普通卷積有點像,但它有一個特別的地方:它會在卷積核中“跳過”一些像素。這就像是你在用一個小刷子涂抹時,故意跳過一些點,而不是連續地涂抹。
具體來說:
- 膨脹系數(Dilation Rate):空洞卷積有一個參數叫膨脹系數(dilation rate)。膨脹系數決定了卷積核中像素之間的間隔。
- 膨脹卷積核:如果膨脹系數是 1,空洞卷積就和普通卷積一樣。但如果膨脹系數大于 1,卷積核就會“膨脹”,跳過一些像素。
舉個例子: - 假設你有一個 3×3 的卷積核,膨脹系數是 2。那么,這個卷積核實際上會覆蓋一個 5×5 的區域,但中間的像素是跳過的。
- 具體來說,普通卷積的 3×3 卷積核是這樣的:
- 復制
1 2 3
4 5 6
7 8 9 - 但膨脹系數為 2 的空洞卷積核覆蓋的區域是這樣的:
- 復制
1 0 2 0 3
0 0 0 0 0
4 0 5 0 6
0 0 0 0 0
7 0 8 0 9 - 其中,0 表示跳過的像素。
- 空洞卷積的優勢
- 擴大感受野:普通卷積的感受野比較小,每次只能看到一個小區域。空洞卷積通過跳過像素,可以覆蓋更大的區域,從而擴大感受野。這就好像是你用一個小刷子,但每次涂抹時可以跳過一些點,覆蓋更大的范圍。
- 不丟失分辨率:普通卷積會導致輸出圖像的分辨率變小,但空洞卷積可以在不丟失分辨率的情況下擴大感受野。這就好像是你在用一個小刷子涂抹時,雖然跳過了一些點,但整體覆蓋的范圍更大了,而且不會丟失細節。
- 計算效率高:空洞卷積通過跳過像素,減少了計算量,同時保持了輸出圖像的分辨率。
5、SegNet的背景和設計動機
- 語義分割的應用和背景
語義分割是一種技術,它的任務是把圖像里的每個像素都標注出它屬于什么類別(比如道路、建筑物、汽車、行人等)。這種技術用途很廣,比如:
- 場景理解:讓計算機明白圖像里都有哪些東西,它們之間的關系是什么。
- 自動駕駛:幫助自動駕駛系統識別道路、行人、交通標志等。
- 早期方法和深度學習的突破
以前,人們主要用一些簡單的視覺線索(比如顏色、紋理)來做語義分割,但這種方法效果不太好。后來,深度學習出現了,它在很多領域都取得了重大突破,比如:
- 手寫數字識別:識別手寫的數字。
- 語音處理:把語音轉換成文字。
- 圖像分類:判斷圖像里是什么東西。
- 物體檢測:在圖像里找到物體的位置。
深度學習的出現讓語義分割的效果也有了很大的提升。
- 像素級標注的挑戰
雖然深度學習在語義分割上取得了進步,但直接用傳統的深度學習架構(比如VGG16)來做像素級標注還是有問題的。主要問題是:
- 最大池化和下采樣:這些操作會讓特征圖的分辨率變低,導致邊界信息丟失。這在需要精確邊界的地方(比如道路和人行道的分界線)就不太好了。
- SegNet的設計動機
SegNet就是為了解決這些問題而設計的。它的目標是:
- 高效:既要節省內存,又要運行速度快。
- 精確:能夠精確地標注每個像素的類別,尤其是邊界部分。
- 端到端訓練:通過隨機梯度下降(SGD)等技術,一次性訓練整個網絡,這樣更容易重復和優化。
- SegNet的設計細節
編碼器(Encoder)
- 結構:SegNet的編碼器和VGG16的卷積層一模一樣,但移除了VGG16的全連接層。這樣參數量大大減少,訓練起來也更容易。
- 功能:提取圖像的特征,但不會丟失太多細節。
解碼器(Decoder) - 核心組件:解碼器是SegNet的關鍵,它由多個解碼器層組成,每個解碼器層都對應一個編碼器層。
- 最大池化索引:解碼器利用編碼器記錄的最大池化索引,對特征圖進行上采樣。這樣可以恢復邊界信息,讓分割結果更精確。
- 非線性上采樣:通過這種方式,解碼器可以把低分辨率的特征圖還原成高分辨率的圖像。
- SegNet的優勢
- 高效:參數量少,運行速度快,內存占用低。
- 精確:通過記錄最大池化索引,能夠恢復邊界信息,適合需要精確分割的任務。
- 端到端訓練:整個網絡可以一次性訓練,優化起來更方便。
- 應用場景
SegNet特別適合道路場景理解,比如:
- 道路和建筑物:這些大類別的像素占大部分,需要生成平滑的分割結果。
- 行人和小目標:即使目標很小,也能通過保留邊界信息來精確分割。
6、模型解剖
編碼器網絡中的每個編碼器通過濾波器組進行卷積運算, 生成一組特征圖 - 操作:編碼器通過一組濾波器(也可以叫卷積核)在圖像上滑動,每個濾波器會提取圖像的某種特征(比如邊緣、紋理等),最后生成一組特征圖。
- 舉例:就像用不同的放大鏡去看一幅畫,每個放大鏡(濾波器)會幫你看到畫里不同的細節(特征)。
隨后對這些特征圖進行批量歸一化處理 - 操作:對生成的特征圖進行批量歸一化處理。
- 目的:讓特征圖的數據分布更加“規整”,避免在訓練過程中出現數值不穩定的情況,這樣可以讓訓練過程更加順利。
- 舉例:就像在比賽前把所有選手的起跑線都調整到同一個位置,這樣比賽才會更公平。
然后應用元素級修正線性非線性函數 - 操作:對特征圖的每個元素應用ReLU函數,即如果元素的值大于0就保持不變,小于0就變成0。
- 目的:給模型引入非線性,讓模型能夠學習更復雜的特征和模式。
隨后執行最大池化操作,采用2×2窗口和步 長為2(非重疊窗口),并將輸出結果進行2倍下采樣。最大 池化用于實現對輸入圖像小范圍空間位移的平移不變性。下 采樣使得特征圖中每個像素對應一個較大的輸入圖像上下文 (空間窗口) - 操作:用一個2×2的窗口在特征圖上滑動,每次取窗口里最大的值,然后把特征圖縮小2倍(步長為2)。
- 目的:
- 平移不變性:讓模型對圖像的小范圍移動不那么敏感。比如,一個物體在圖像里稍微移動了一下位置,模型仍然能認出來。
- 提取上下文信息:下采樣后,特征圖中的每個像素對應了輸入圖像中一個更大的區域(空間窗口),這樣可以讓模型更好地理解圖像的整體結構。
- 舉例:就像從遠處看一幅畫,你只能看到大致的輪廓,但看不到細節。不過這樣也有好處,比如你可以更容易地看出畫的整體布局。
因此我們提出了一種更高效的存儲方案:僅需存儲最大池化索引i。e、每個池化窗口中最 大特征值的位置信息會被存儲在對應的編碼器特征圖中。從 原理上說,這種方法可以為每個2×2的池化窗口分配2位數 據,因此相比以浮點精度存儲特征圖
雖然最大池化和下采樣有很多好處,但它們也會導致一個問題:特征圖的空間分辨率降低,邊界細節丟失。這在需要精確分割的任務(比如語義分割)中是不利的,因為我們需要明確的邊界劃分。
(1)存儲所有特征圖的方案 - 方案:如果內存足夠,可以存儲所有經過下采樣的特征圖。
- 問題:在實際應用中,內存通常是有限的,所以這個方案不太可行。
(2)存儲最大池化索引的方案 - 方案:只存儲每個池化窗口中最大特征值的位置信息(索引),而不是存儲整個特征圖。
- 優點:
- 高效:每個2×2的池化窗口只需要2位數據來存儲索引,相比存儲浮點特征圖,這種方式節省了很多內存。
- 舉例:假設一個2×2的窗口里有4個值,最大值的位置可以用2位二進制數來表示(00、01、10、11),這樣存儲起來非常節省空間。
- 缺點:雖然這種方法節省了內存,但會導致精度略有損失。不過,后續的研究表明,這種損失在實際應用中是可以接受的。






)
--分組密碼)









 的弊端及修復方式)

)