引言
知識圖譜作為一種結構化的知識表示方式,在智能問答、推薦系統、數據分析等領域有著廣泛應用。在信息爆炸的時代,如何從非結構化文本中提取有價值的知識并進行結構化展示,是NLP領域的重要任務。知識三元組(Subject-Relation-Object)是知識圖譜的基本組成單元,通過大模型強大的語義理解能力,我們可以自動化提取這些三元組,并構建可交互的知識圖譜可視化界面。本文將介紹一個基于大模型的知識圖譜構建工具,它能從文本中自動提取知識三元組(主體-關系-客體),并通過可視化工具生成交互式知識圖譜。
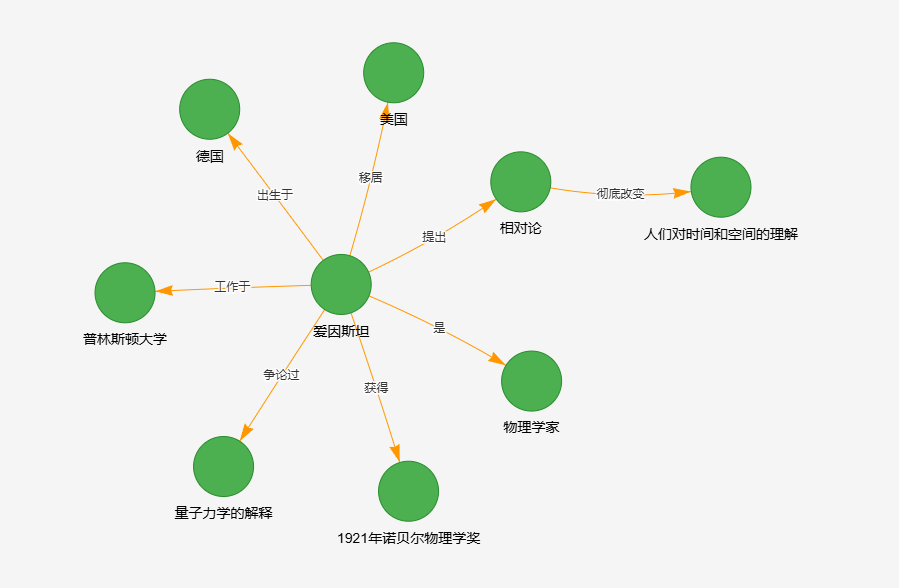
這是運行結果獲得,如下圖示:
一、核心依賴庫
在開始之前,確保已安裝以下依賴庫:
pip install networkx pyvis # 知識圖譜構建與可視化
# 其他基礎庫:json, re, os(通常Python環境自帶)
而至于大模型環境,我們不在給出。
二、代碼整體結構解析
整個項目代碼主要包含四個核心模塊,形成"文本輸入→三元組提取→圖譜構建→可視化輸出"的完整流程:
# 核心模塊關系
文本輸入 → extract_triples() → 知識三元組 → build_knowledge_graph() → 圖譜數據 → visualize_knowledge_graph() → 可視化HTML
下面我們逐個解析關鍵模塊的實現邏輯。
1. 大模型調用與三元組提取(extract_triples函數)
該函數是整個流程的核心,負責調用大模型從文本中提取知識三元組。其關鍵實現思路如下:
大模型提示詞設計
為了讓大模型精準輸出符合要求的三元組,我們設計了嚴格的系統提示詞(System Prompt):
system_prompt = """你是專業知識三元組提取器,嚴格按以下規則輸出:
1. 僅從文本提取(主體, 關系, 客體)三元組,忽略無關信息。
2. 必須用JSON數組格式返回,每個元素含"subject"、"relation"、"object"字段。
3. 輸出僅保留JSON數組,不要任何解釋、說明、代碼塊標記。
4. 確保JSON格式正確:引號用雙引號,逗號分隔,無多余逗號。
"""
提示詞明確了輸出格式要求,這是后續解析三元組的基礎。
流式響應處理
大模型通常采用流式輸出方式返回結果,我們需要持續接收并拼接響應內容:
full_response = ""
for chunk in stream_invoke(ll_model, messages):full_response += str(chunk)print(f"\r已接收 {len(full_response)} 字符...", end="")
這種處理方式能實時反饋進度,提升用戶體驗。
格式修復機制
大模型輸出可能存在格式問題(如引號不規范、多余逗號等),因此需要異常處理和格式修復:
try:return json.loads(full_response)
except json.JSONDecodeError:# 嘗試提取JSON結構并修復json_match = re.search(r'\[.*\]', full_response, re.DOTALL)if json_match:cleaned_response = json_match.group()cleaned_response = cleaned_response.replace("'", '"') # 單引號轉雙引號cleaned_response = re.sub(r',\s*]', ']', cleaned_response) # 移除末尾多余逗號try:return json.loads(cleaned_response)except json.JSONDecodeError as e:print(f"修復后仍解析失敗:{e}")return []
這一機制大幅提升了代碼的健壯性,即使大模型輸出格式略有瑕疵也能嘗試修復。
2. 知識圖譜構建(build_knowledge_graph函數)
提取三元組后,需要將其轉換為結構化的知識圖譜數據結構:
def build_knowledge_graph(triples):if not triples:return None # 處理空三元組情況entities = set()# 收集所有實體(主體和客體都是實體)for triple in triples:entities.add(triple["subject"])entities.add(triple["object"])# 構建實體屬性字典entity_attributes = {entity: {"name": entity} for entity in entities}# 構建關系列表relations = [{"source": triple["subject"],"target": triple["object"],"type": triple["relation"]} for triple in triples]return {"entities": [{"id": entity, **attrs} for entity, attrs in entity_attributes.items()],"relations": relations}
這個函數的核心邏輯是:
- 從三元組中提取所有唯一實體(去重)
- 為每個實體創建基礎屬性(目前包含名稱)
- 將三元組轉換為"源節點-目標節點-關系類型"的邊結構
- 最終返回包含實體和關系的圖譜字典
3. 知識圖譜可視化(visualize_knowledge_graph函數)
可視化是知識圖譜的重要展示方式,本項目使用pyvis庫生成交互式HTML圖譜:
可視化配置與節點邊添加
# 初始化有向圖
net = Network(directed=True, height="700px", width="100%", bgcolor="#f5f5f5", font_color="black",notebook=False # 關鍵配置:非Notebook環境
)# 添加節點
for entity in graph["entities"]:net.add_node(entity["id"],label=entity["name"],title=f"實體: {entity['name']}",color="#4CAF50" # 綠色節點)# 添加邊(關系)
for relation in graph["relations"]:net.add_edge(relation["source"],relation["target"],label=relation["type"],title=relation["type"],color="#FF9800" # 橙色邊)
這里的關鍵配置是notebook=False,解決了非Jupyter環境下的模板渲染錯誤問題。
布局與交互配置
通過JSON配置定義圖譜的視覺樣式和交互行為:
net.set_options("""
{"nodes": {"size": 30,"font": {"size": 14}},"edges": {"font": {"size": 12},"length": 200},"interaction": {"dragNodes": true, # 允許拖拽節點"zoomView": true, # 允許縮放"dragView": true # 允許拖拽視圖}
}
""")
這些配置確保生成的圖譜具有良好的可讀性和交互性。
容錯機制與備選方案
為應對HTML生成失敗的情況,代碼設計了備選可視化方案:
try:net.write_html(output_file, open_browser=False)
except Exception as e:# 備選方案:使用matplotlib生成靜態PNGimport matplotlib.pyplot as pltplt.figure(figsize=(12, 8))pos = nx.spring_layout(nx.DiGraph([(r["source"], r["target"]) for r in graph["relations"]]))nx.draw_networkx_nodes(pos, node_size=3000, node_color="#4CAF50")nx.draw_networkx_labels(pos, labels={e["id"]: e["name"] for e in graph["entities"]})nx.draw_networkx_edges(pos, edgelist=[(r["source"], r["target"]) for r in graph["relations"]], arrowstyle="->")nx.draw_networkx_edge_labels(pos, edge_labels={(r["source"], r["target"]): r["type"] for r in graph["relations"]})plt.savefig(output_file.replace(".html", ".png"))
這種雙重保障機制確保即使pyvis出現問題,也能獲得基礎的可視化結果。
4. 主流程控制(process_text_to_graph函數)
該函數整合了前面的所有模塊,形成完整的"文本→三元組→圖譜→可視化"流程:
def process_text_to_graph(text):print("正在從文本中提取知識三元組...")triples = extract_triples(text)if not triples:print("未能提取到任何知識三元組")return Noneprint(f"成功提取 {len(triples)} 個知識三元組:")for i, triple in enumerate(triples, 1):print(f"{i}. ({triple['subject']}, {triple['relation']}, {triple['object']})")print("\n正在構建知識圖譜...")graph = build_knowledge_graph(triples)if not graph:print("構建知識圖譜失敗")return Noneprint("\n正在生成知識圖譜可視化...")output_file = visualize_knowledge_graph(graph)return output_file
流程清晰,包含了必要的日志輸出和異常判斷,方便用戶跟蹤進度和排查問題。
三、使用方法與示例
運行示例
if __name__ == "__main__":sample_text = """愛因斯坦是一位著名的物理學家,他出生于德國。1905年,愛因斯坦提出了相對論。相對論徹底改變了人們對時間和空間的理解。愛因斯坦因光電效應獲得了1921年諾貝爾物理學獎。他后來移居美國,并在普林斯頓大學工作。愛因斯坦與玻爾就量子力學的解釋有過著名的爭論。"""process_text_to_graph(sample_text)
輸出結果
運行后會得到以下輸出:
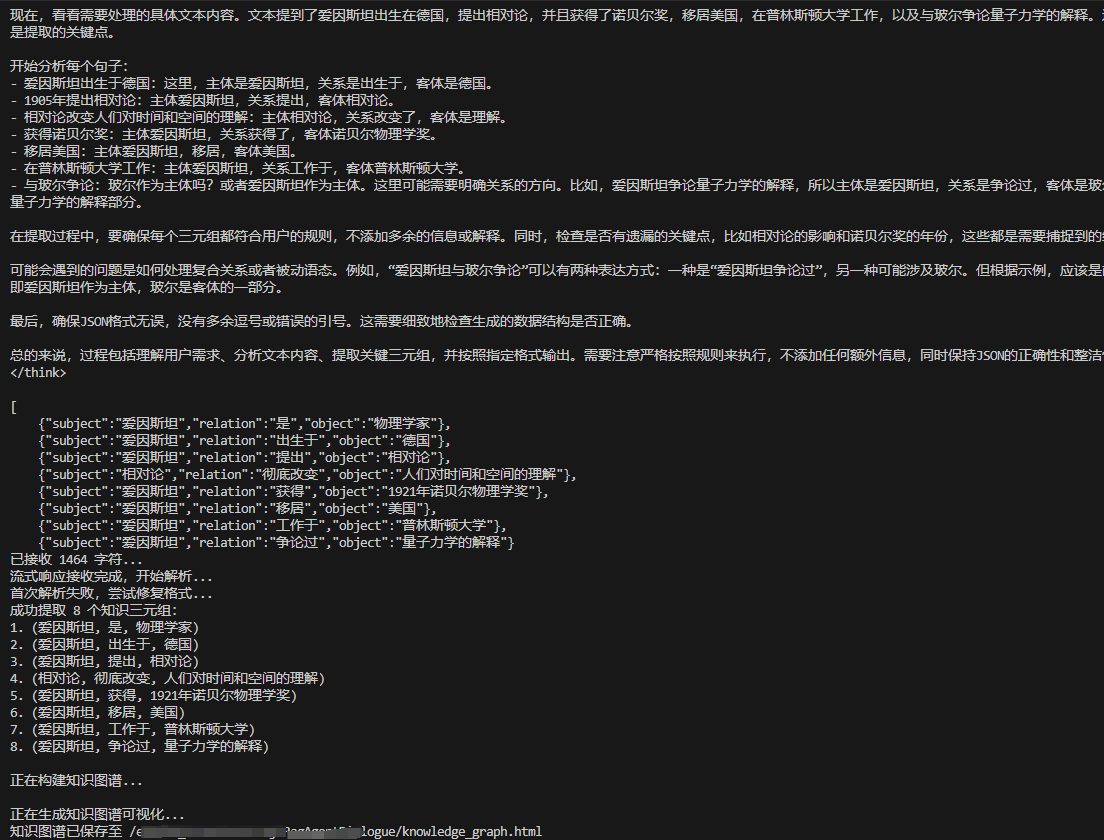
正在從文本中提取知識三元組...
正在接收大模型流式響應...
已接收 236 字符...
流式響應接收完成,開始解析...
成功提取 6 個知識三元組:
1. (愛因斯坦, 是, 物理學家)
2. (愛因斯坦, 出生于, 德國)
3. (愛因斯坦, 提出, 相對論)
4. (相對論, 改變, 人們對時間和空間的理解)
5. (愛因斯坦, 獲得, 1921年諾貝爾物理學獎)
6. (愛因斯坦, 工作于, 普林斯頓大學)正在構建知識圖譜...
正在生成知識圖譜可視化...
知識圖譜已保存至 /path/to/knowledge_graph.html
打開生成的knowledge_graph.html文件,可看到交互式知識圖譜,支持節點拖拽、縮放和平移操作。
代碼運行圖示:
四、完整代碼
運行知識圖譜完整代碼,該代碼需要調用大模型構建的代碼。我只是作為列子給出知識圖譜的prompt方法。你可以根據graphrag等方式來提取知識圖譜或更專業的方式來提取。
大模型調用完整代碼
from langchain_openai import ChatOpenAI
import sys
import os
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))# 給出大語言模型默認參數字典的導入內容
llm_config = {"deepseek_1.5b": {"model_name": "deepseek-r1:1.5b","api_url": "http://162.130.245.26:9542/v1","api_key": "sk-RJaJE4fXaktHAI2MB295F6Ad58004feBcE25B83CdD6F0","embedding_ctx_length": 8191,"chunk_size": 1000,"max_retries": 2,"timeout": None, # 請求超時時間,默認為 None"default_headers": None, # 默認請求頭"default_query": None, # 默認查詢參數"retry_min_seconds": 4,"retry_max_seconds": 20,},"deepseek_14b": {"model_name": "deepseek-r1:14b","api_url": "http://162.130.245.26:9542/v1","api_key": "sk-RJaJE4fXaktHAI2MB295F6Ad58004feBcE25B83CdD6F0","embedding_ctx_length": 8191,"chunk_size": 1000,"max_retries": 2,"timeout": None, # 請求超時時間,默認為 None"default_headers": None, # 默認請求頭"default_query": None, # 默認查詢參數"retry_min_seconds": 4,"retry_max_seconds": 20,},"deepseek_32b": {"model_name": "deepseek-r1:32b","api_url": "http://162.130.245.26:9542/v1","api_key": "sk-RJaJE4fXaktHAI2MB295F6Ad58004feBcE25B83CdD6F0","embedding_ctx_length": 8191,"chunk_size": 1000,"max_retries": 2,"timeout": None, # 請求超時時間,默認為 None"default_headers": None, # 默認請求頭"default_query": None, # 默認查詢參數"retry_min_seconds": 4,"retry_max_seconds": 20,},"qwen3_14b": {"model_name": "qwen3:14b","api_url": "http://192.145.216.20:7542/v1","api_key": "sk-RJaJE4fXaktHAI2M295F6Ad58004f7eBcE25B863CdD6F0","embedding_ctx_length": 8191,"chunk_size": 1000,"max_retries": 2,"timeout": None, # 請求超時時間,默認為 None"default_headers": None, # 默認請求頭"default_query": None, # 默認查詢參數"retry_min_seconds": 4,"retry_max_seconds": 20,},"qwen3_32b": {"model_name": "qwen3:32b","api_url": "http://192.145.216.20:7542/v1","api_key": "sk-RJaJE4fXaktHAI2MB295F6d58004f7eBcE255B863CdD6F0","embedding_ctx_length": 8191,"chunk_size": 1000,"max_retries": 2,"timeout": 60, # 請求超時時間,默認為 None"default_headers": None, # 默認請求頭"default_query": None, # 默認查詢參數"retry_min_seconds": 4,"retry_max_seconds": 20,},}def stream_invoke(llm_model,prompt):"""prompt可以做成2種方式,方式一:from langchain.schema import HumanMessagemessages = [HumanMessage(content=prompt)]方式二:{"role": "user", "content": question}"""full_response = ""results = llm_model.stream(prompt)for chunk in results:print(chunk.content, end="", flush=True) # 逐塊輸出full_response += chunk.contentreturn full_responsedef invoke( llm_model,prompt):"""調用模型生成響應。:param prompt: 輸入的提示文本:return: 模型生成的響應內容"""response = llm_model.invoke(prompt)print(response)return response.content
def build_model(mode="deepseek_32b"):config = llm_config[mode]model_name = config["model_name"]api_key = config["api_key"] api_url = config["api_url"]LLM = ChatOpenAI(model=model_name,openai_api_key=api_key,openai_api_base=api_url)return LLMdef remove_think(answer, split_token='</think>'):"""處理模型響應,分離 think 內容和實際回答。:param answer: 模型的完整響應:param split_token: 分隔符,默認為 </think>:return: 實際回答和 think 內容"""parts = answer.split(split_token)content = parts[-1].lstrip("\n")think_content = None if len(parts) <= 1 else parts[0]return contentif __name__ == "__main__":llm_model = build_model(mode="qwen3_14b")# print(llm_model)stream_invoke(llm_model,"解釋大語言模型LLM")知識圖譜提取完整代碼
from Models.LLM_Models import build_model, stream_invoke
import networkx as nx
from pyvis.network import Network
import json
import re
import os # 新增:用于處理文件路徑# 初始化大模型
ll_model = build_model()def extract_triples(text):"""使用stream_invoke從文本中提取知識三元組"""system_prompt = """你是專業知識三元組提取器,嚴格按以下規則輸出:1. 僅從文本提取(主體, 關系, 客體)三元組,忽略無關信息。2. 必須用JSON數組格式返回,每個元素含"subject"、"relation"、"object"字段。3. 輸出僅保留JSON數組,** 不要任何解釋、說明、代碼塊標記(如```json)**。4. 確保JSON格式正確:引號用雙引號,逗號分隔,無多余逗號。示例輸出:[{"subject":"愛因斯坦","relation":"是","object":"物理學家"},{"subject":"愛因斯坦","relation":"提出","object":"相對論"}]"""user_input = f"從以下文本提取三元組,嚴格按示例格式輸出:\n{text}"messages = [{"role": "system", "content": system_prompt},{"role": "user", "content": user_input}]# 接收流式響應print("正在接收大模型流式響應...")full_response = ""for chunk in stream_invoke(ll_model, messages):# 根據實際返回格式調整,有些stream_invoke可能需要chunk["content"]full_response += str(chunk)print(f"\r已接收 {len(full_response)} 字符...", end="")print("\n流式響應接收完成,開始解析...")full_response = full_response.strip()# 格式修復try:return json.loads(full_response)except json.JSONDecodeError:print("首次解析失敗,嘗試修復格式...")json_match = re.search(r'\[.*\]', full_response, re.DOTALL)if json_match:cleaned_response = json_match.group()cleaned_response = cleaned_response.replace("'", '"')cleaned_response = re.sub(r',\s*]', ']', cleaned_response)try:return json.loads(cleaned_response)except json.JSONDecodeError as e:print(f"修復后仍解析失敗:{e}")return []else:print("未找到有效JSON結構")return []def build_knowledge_graph(triples):"""構建知識圖譜數據結構"""if not triples:return None # 新增:處理空三元組情況entities = set()for triple in triples:entities.add(triple["subject"])entities.add(triple["object"])entity_attributes = {entity: {"name": entity} for entity in entities}relations = [{"source": triple["subject"],"target": triple["object"],"type": triple["relation"]} for triple in triples]return {"entities": [{"id": entity, **attrs} for entity, attrs in entity_attributes.items()],"relations": relations}def visualize_knowledge_graph(graph, output_file="knowledge_graph.html"):"""修復可視化函數,解決模板渲染錯誤"""if not graph:print("無法可視化空圖譜")return None# 確保輸出目錄存在output_dir = os.path.dirname(output_file)if output_dir and not os.path.exists(output_dir):os.makedirs(output_dir, exist_ok=True)# 初始化圖時指定notebook=False(關鍵修復)net = Network(directed=True, height="700px", width="100%", bgcolor="#f5f5f5", font_color="black",notebook=False # 新增:明確指定非 notebook 環境)# 添加節點和邊for entity in graph["entities"]:net.add_node(entity["id"],label=entity["name"],title=f"實體: {entity['name']}",color="#4CAF50")for relation in graph["relations"]:net.add_edge(relation["source"],relation["target"],label=relation["type"],title=relation["type"],color="#FF9800")# 簡化配置選項,避免復雜JSON解析問題net.set_options("""{"nodes": {"size": 30,"font": {"size": 14}},"edges": {"font": {"size": 12},"length": 200},"interaction": {"dragNodes": true,"zoomView": true,"dragView": true}}""")# 直接使用write_html方法,避免show()的復雜邏輯try:net.write_html(output_file, open_browser=False)print(f"知識圖譜已保存至 {os.path.abspath(output_file)}")return output_fileexcept Exception as e:print(f"生成HTML時出錯: {e}")# 嘗試備選方案:使用networkx的基本可視化import matplotlib.pyplot as pltplt.figure(figsize=(12, 8))pos = nx.spring_layout(nx.DiGraph([(r["source"], r["target"]) for r in graph["relations"]]))nx.draw_networkx_nodes(pos, node_size=3000, node_color="#4CAF50")nx.draw_networkx_labels(pos, labels={e["id"]: e["name"] for e in graph["entities"]})nx.draw_networkx_edges(pos, edgelist=[(r["source"], r["target"]) for r in graph["relations"]], arrowstyle="->")nx.draw_networkx_edge_labels(pos, edge_labels={(r["source"], r["target"]): r["type"] for r in graph["relations"]})plt.savefig(output_file.replace(".html", ".png"))print(f"已生成PNG備選可視化: {output_file.replace('.html', '.png')}")return output_file.replace(".html", ".png")def process_text_to_graph(text):"""端到端處理流程"""print("正在從文本中提取知識三元組...")triples = extract_triples(text)if not triples:print("未能提取到任何知識三元組")return Noneprint(f"成功提取 {len(triples)} 個知識三元組:")for i, triple in enumerate(triples, 1):print(f"{i}. ({triple['subject']}, {triple['relation']}, {triple['object']})")print("\n正在構建知識圖譜...")graph = build_knowledge_graph(triples)if not graph:print("構建知識圖譜失敗")return Noneprint("\n正在生成知識圖譜可視化...")output_file = visualize_knowledge_graph(graph)return output_file# 示例用法
if __name__ == "__main__":sample_text = """愛因斯坦是一位著名的物理學家,他出生于德國。1905年,愛因斯坦提出了相對論。相對論徹底改變了人們對時間和空間的理解。愛因斯坦因光電效應獲得了1921年諾貝爾物理學獎。他后來移居美國,并在普林斯頓大學工作。愛因斯坦與玻爾就量子力學的解釋有過著名的爭論。"""process_text_to_graph(sample_text)基于 Go 和 gopacket+Fyne 的跨平臺網絡抓包工具開發實錄)





)



?的小樣本故障診斷模型)


)



:性能優化與壓力測試)

