溫馨提示:
本篇文章已同步至"AI專題精講" Llama 2:開放基礎模型與微調聊天模型
摘要
在本研究中,我們開發并發布了 Llama 2,一組預訓練和微調的大型語言模型(LLMs),其規模從 70 億參數到 700 億參數不等。我們的微調模型稱為 Llama 2-Chat,針對對話類場景進行了優化。在我們測試的大多數基準任務中,這些模型的性能優于現有的開源聊天模型;基于我們對有用性和安全性的人工評估,Llama 2-Chat 可能是閉源模型的一個合適替代方案。我們詳細描述了對 Llama 2-Chat 的微調方法和安全性改進,以便社區能夠在我們的工作基礎上繼續發展,并共同推動大型語言模型的負責任開發。
1 引言
大型語言模型(LLMs)已被證明是極具潛力的 AI 助手,在需要跨多個領域專家知識的復雜推理任務中表現出色,包括編程和創意寫作等專業領域。它們通過直觀的聊天界面實現與人類的交互,從而在公眾中迅速并廣泛普及。
考慮到訓練方法看似簡單,LLMs 所展現出的能力令人驚嘆。自回歸 transformer 在大規模的自監督語料庫上進行預訓練,隨后通過例如人類反饋強化學習(Reinforcement Learning with Human Feedback, RLHF)等技術與人類偏好對齊。盡管訓練方法本身較為簡單,但高昂的計算成本限制了 LLMs 的開發,僅限于少數參與者。目前已有一些預訓練 LLMs 的公開發布(如 BLOOM(Scao et al., 2022)、LLaMa-1(Touvron et al., 2023)、以及 Falcon(Penedo et al., 2023)),其性能接近閉源預訓練模型的競爭者,如 GPT-3(Brown et al., 2020)和 Chinchilla(Hoffmann et al., 2022),但這些模型都無法真正替代閉源“產品級” LLMs,例如 ChatGPT、BARD 和 Claude。這些閉源產品級模型經過了大量微調,以更好地對齊人類偏好,極大提升了其可用性與安全性。而這一過程可能需要大量的計算資源和人工標注成本,且通常不透明、難以復現,從而限制了社區在 AI 對齊研究方面的進展。
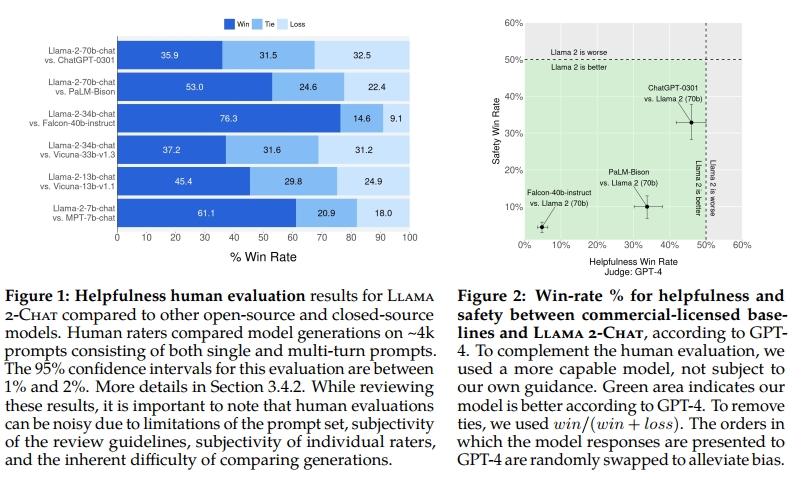
在本研究中,我們開發并發布了 Llama 2 系列模型,包括預訓練和微調的 LLMs,即 Llama 2 與 Llama 2-Chat,其規模最大可達 700 億參數。在我們測試的一系列有用性與安全性基準中,Llama 2-Chat 模型通常優于現有的開源模型。同時,在我們所進行的人類評估中,這些模型在某些方面已可與部分閉源模型相媲美(見圖 1 和圖 3)。我們通過特定的安全性數據標注與微調、紅隊測試以及迭代評估等措施增強了這些模型的安全性。此外,本文還詳盡介紹了我們的微調方法和提升 LLM 安全性的策略。我們希望這種開放性能夠使社區復現微調的 LLM,并持續提升這些模型的安全性,為更加負責任的 LLM 開發鋪平道路。我們還分享了在開發 Llama 2 和 Llama 2-Chat 過程中發現的一些新現象,例如工具使用能力的涌現以及知識的時間組織方式。
我們將面向公眾發布以下模型,用于研究和商業用途:
-
Llama 2:這是 Llama 1 的更新版本,使用全新組合的公開數據進行了訓練。我們將預訓練語料的規模增加了 40%,將模型的上下文長度翻倍,并采用了 grouped-query attention(Ainslie et al., 2023)。我們發布了參數規模為 7B、13B 和 70B 的 Llama 2 模型版本。我們還訓練了 34B 的模型變體,并在本文中報告其性能,但該版本不予發布。
-
Llama 2-Chat:這是在 Llama 2 基礎上微調得到的模型,針對對話場景進行了優化。我們同樣發布了其 7B、13B 和 70B 參數規模的版本。
我們認為,只要以安全方式進行,LLMs 的開放發布將對社會產生凈正效益。與所有 LLM 一樣,Llama 2 是一項新興技術,其使用存在潛在風險(Bender et al., 2021b;Weidinger et al., 2021;Solaiman et al., 2023)。目前為止的測試是在英語環境下進行的,尚未——也不可能——覆蓋所有使用情境。因此,在部署任何基于 Llama 2-Chat 的應用程序之前,開發者應根據其具體應用場景執行相應的安全性測試與調優。我們提供了《負責任使用指南》以及代碼示例‖,以支持 Llama 2 和 Llama 2-Chat 的安全部署。我們在第 5.3 節中詳細介紹了我們的責任發布策略。
本文其余部分組織如下:第 2 節介紹預訓練方法,第 3 節介紹微調方法,第 4 節介紹模型安全性方案,第 5 節包含關鍵觀察與見解,第 6 節回顧相關工作,第 7 節為總結。
2 預訓練
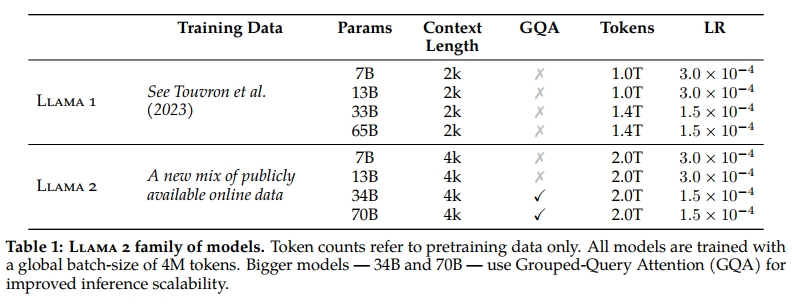
為了構建全新的 Llama 2 模型系列,我們從 Touvron 等人(2023)所描述的預訓練方法出發,使用了優化后的自回歸 transformer,但為了提升性能,我們做出了一些改進。具體而言,我們進行了更強健的數據清洗、更新了數據混合策略、總 token 數增加了 40%、上下文長度翻倍,并在更大模型中采用了 grouped-query attention(GQA),以提升推理可擴展性。表 1 比較了新發布的 Llama 2 模型與 Llama 1 模型的屬性。
2.1 預訓練數據
我們的訓練語料包含了新的公開數據混合,這些數據不包含來自 Meta 產品或服務的信息。我們特別努力去除來自某些站點的數據,這些站點被已知包含大量關于私人個體的個人信息。我們在總計 2 萬億個 tokens 的數據上進行訓練,這是性能與成本之間的良好權衡。我們對最具事實性的語料進行了上采樣,以提升模型知識性并抑制幻覺現象。
我們還進行了多種預訓練數據的研究分析,以幫助用戶更好理解模型的潛在能力與局限;相關結果見第 4.1 節。
2.2 訓練細節
我們大多數的預訓練設置與模型架構延續自 Llama 1。我們使用標準 transformer 架構(Vaswani et al., 2017),采用 RMSNorm(Zhang and Sennrich, 2019)進行預歸一化,激活函數使用 SwiGLU(Shazeer, 2020),位置編碼使用旋轉位置嵌入(RoPE, Su et al., 2022)。與 Llama 1 的主要結構差異在于上下文長度的提升以及引入了 grouped-query attention(GQA)。我們在附錄 A.2.1 節詳細介紹了這些變化,并通過消融實驗展示它們的重要性。
超參數設置:我們使用 AdamW 優化器(Loshchilov and Hutter, 2017),其參數為 β1=0.9,β2=0.95,eps=10?5β? = 0.9,β? = 0.95,eps = 10??β1?=0.9,β2?=0.95,eps=10?5。學習率采用余弦退火策略,預熱階段為 2000 步,最終學習率衰減至峰值學習率的 10%。我們設置權重衰減為 0.1,梯度裁剪閾值為 1.0。圖 5(a) 展示了 Llama 2 在這些超參數設置下的訓練損失情況。
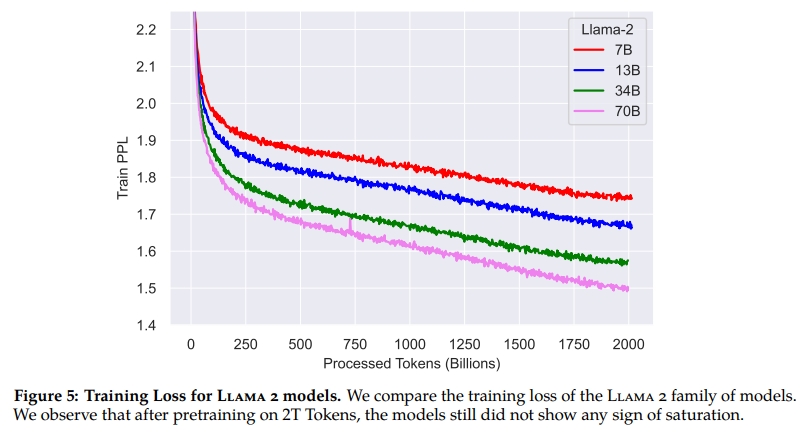
Tokenizer
我們使用與 Llama 1 相同的 tokenizer;該 tokenizer 使用字節對編碼(bytepair encoding, BPE)算法(Sennrich et al., 2016),并基于 SentencePiece(Kudo and Richardson, 2018)實現。與 Llama 1 一樣,我們將所有數字拆分為單個數字,將未知的 UTF-8 字符按字節拆解。總詞表大小為 32k 個 token。
2.2.1 訓練硬件與碳足跡
訓練硬件:我們在 Meta 的 Research Super Cluster(RSC)(Lee and Sengupta, 2022)以及內部生產集群上對模型進行了預訓練。這兩個集群均使用 NVIDIA A100 GPU。有兩個關鍵差異:首先是網絡互連類型的不同:RSC 使用 NVIDIA Quantum InfiniBand,而生產集群則采用基于普通以太網交換機的 RoCE(RDMA over Converged Ethernet)解決方案。這兩種互連方案都提供 200 Gbps 的端口速率。第二個差異是每張 GPU 的功耗限制——RSC 限定為 400W,而生產集群為 350W。通過這兩個集群的比較,我們能夠評估不同互連方案在大規模訓練中的適用性。RoCE(作為一種更經濟的商用互連網絡)在多達 2000 張 GPU 的規模下,其擴展性幾乎與昂貴的 InfiniBand 相當,這使得預訓練過程更加民主化。
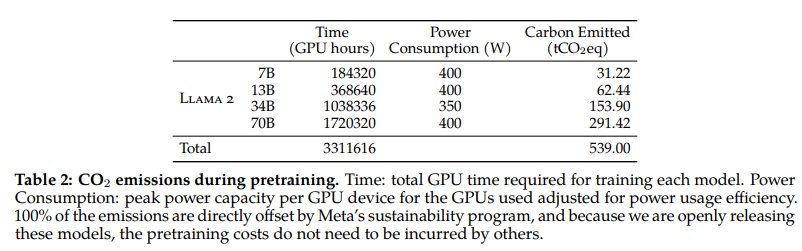
預訓練的碳足跡
參考前人研究(Bender et al., 2021a;Patterson et al., 2021;Wu et al., 2022;Dodge et al., 2022),并依據 GPU 設備的功耗估算與碳效率,我們嘗試計算 Llama 2 模型預訓練所產生的碳排放。GPU 的實際功耗取決于其利用率,可能與我們所采用的 GPU 功率估算值(即熱設計功率,TDP)不同。需要注意的是,我們的計算未考慮互連設備、非 GPU 的服務器功耗,或數據中心冷卻系統所消耗的額外能量。此外,AI 硬件(如 GPU)的制造過程中產生的碳排放,也可能進一步增加整體碳足跡,如 Gupta 等人(2022b,a)所指出。表 2 總結了 Llama 2 系列模型預訓練階段的碳排放情況。我們共計在 A100-80GB(TDP 為 400W 或 350W)設備上執行了約 330 萬 GPU 小時的計算任務。據估算,總排放為 539 噸二氧化碳當量(tCO?eq),其中 100% 已通過 Meta 的可持續發展項目直接抵消。我們的開源發布策略也意味著其他公司無需重復承擔這些預訓練成本,從而節約了更多全球資源。
2.3 Llama 2 預訓練模型評估
在本節中,我們報告 Llama 1 與 Llama 2 基礎模型、MosaicML 的 Pretrained Transformer(MPT)?? 模型,以及 Falcon(Almazrouei et al., 2023)模型在標準學術基準上的表現。所有評估均使用我們的內部評測庫完成。MPT 與 Falcon 的評估結果為我們在內部復現所得。對于這些模型,我們在內部評估結果與公開報告中選擇最優分數。
表 3 總結了一系列流行基準上的整體性能表現。關于安全相關基準,請參見第 4.1 節。我們將這些基準分為以下幾類,各基準的詳細結果可見附錄 A.2.2 節:
-
Code:我們報告模型在 HumanEval(Chen et al., 2021)和 MBPP(Austin et al., 2021)上的平均 pass@1 分數。
-
Commonsense Reasoning:我們報告以下基準的平均結果:PIQA(Bisk et al., 2020)、SIQA(Sap et al., 2019)、HellaSwag(Zellers et al., 2019a)、WinoGrande(Sakaguchi et al., 2021)、ARC easy 與 challenge(Clark et al., 2018)、OpenBookQA(Mihaylov et al., 2018)以及 CommonsenseQA(Talmor et al., 2018)。CommonsenseQA 使用 7-shot,其余均為 0-shot。
-
World Knowledge:我們報告模型在 NaturalQuestions(Kwiatkowski et al., 2019)與 TriviaQA(Joshi et al., 2017)上 5-shot 的平均性能。
-
Reading Comprehension:我們報告 SQuAD(Rajpurkar et al., 2018)、QuAC(Choi et al., 2018)與 BoolQ(Clark et al., 2019)這三個閱讀理解任務的 0-shot 平均表現。
-
MATH:我們報告 GSM8K(8-shot)(Cobbe et al., 2021)與 MATH(4-shot)(Hendrycks et al., 2021)兩個基準的 top-1 平均分。
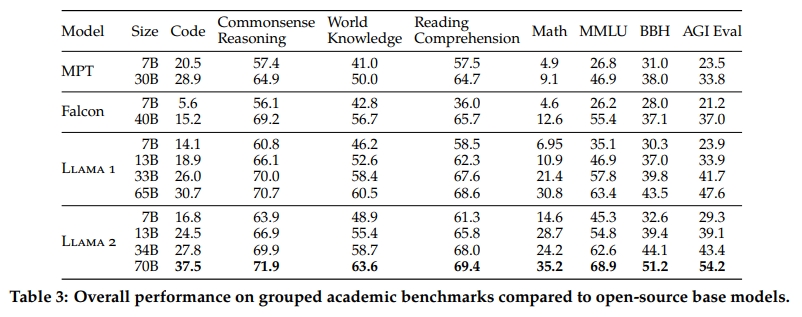
Popular Aggregated Benchmarks:我們報告模型在 MMLU(5-shot)(Hendrycks et al., 2020)、Big Bench Hard(BBH)(3-shot)(Suzgun et al., 2022)以及 AGI Eval(3–5-shot)(Zhong et al., 2023)上的整體結果。對于 AGI Eval,我們僅評估英文任務并報告其平均結果。
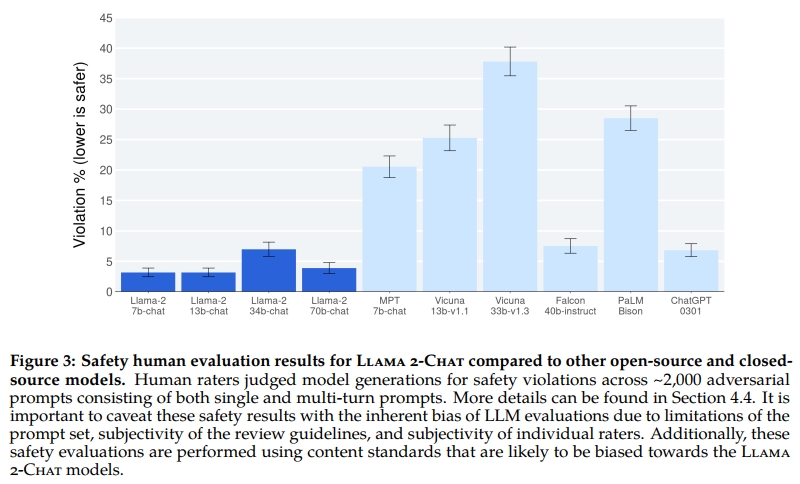
如表 3 所示,Llama 2 模型在各項任務中均優于 Llama 1 模型。尤其是,Llama 2 70B 在 MMLU 和 BBH 上的得分分別較 Llama 1 65B 提高約 5 分和 8 分。Llama 2 7B 與 30B 模型在除代碼基準之外的所有類別上均優于相應規模的 MPT 模型。對于 Falcon 模型,Llama 2 的 7B 與 34B 模型在所有基準類別中也優于 Falcon 7B 與 40B 模型。
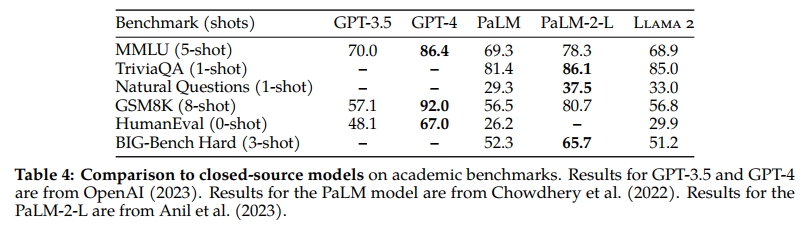
此外,Llama 2 70B 模型在性能上超過了所有開源模型。除了開源模型之外,我們還將 Llama 2 70B 與閉源模型進行了對比。如表 4 所示,Llama 2 70B 在 MMLU 和 GSM8K 上的表現接近 GPT-3.5(OpenAI, 2023),但在代碼基準上存在顯著差距。Llama 2 70B 的結果在幾乎所有基準上均與 PaLM(540B)(Chowdhery et al., 2022)持平或更好。盡管如此,Llama 2 70B 與 GPT-4 以及 PaLM-2-L 之間仍存在顯著的性能差距。
我們還分析了潛在的數據污染問題,具體內容見附錄 A.6。
3 微調
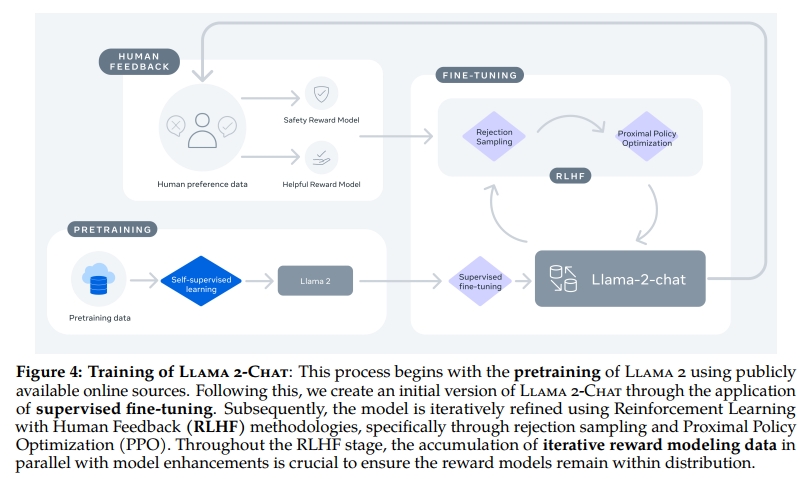
Llama 2-Chat 是歷經數月研究與多輪對齊技術迭代應用的成果,這些對齊技術包括指令微調與人類反饋強化學習(RLHF),均需大量計算與標注資源支持。在本節中,我們報告了我們在監督微調(第 3.1 節)、初始與迭代獎勵建模(第 3.2.2 節)以及 RLHF(第 3.2.3 節)方面的實驗與發現。我們還介紹了一種新技術——Ghost Attention(GAtt),我們發現該技術有助于控制多輪對話中的對話流(第 3.3 節)。關于微調模型的安全性評估,詳見第 4.2 節。
3.1 監督微調(SFT)

開始階段
為了啟動微調(SFT)階段,我們使用了公開的指令微調數據(Chung et al., 2022),這與 Touvron 等人(2023)中所使用的數據相同。
質量即一切
第三方的 SFT 數據來源眾多,但我們發現其中許多數據的多樣性和質量不足,尤其是在對齊 LLM 至對話式指令時表現不佳。因此,我們優先收集了數千條高質量的 SFT 樣本,如表 5 所示。通過舍棄來自第三方數據集的數百萬樣本,轉而使用我們供應商標注團隊提供的較少但高質量樣本,我們的結果有了顯著提升。這一發現與 Zhou 等人(2023)的結論相似,即少量清潔的指令微調數據足以達到較高的質量水平。我們發現約幾萬條的 SFT 標注就足以取得高質量結果。我們在累計收集了 27,540 條標注后停止了 SFT 標注。需要注意的是,我們未使用任何 Meta 用戶數據。
我們還觀察到,不同的標注平臺和供應商會顯著影響下游模型性能,這凸顯了即使在使用供應商時進行數據質量檢查的重要性。為驗證數據質量,我們仔細審查了 180 個樣本,將人工標注與模型生成的樣本進行對比分析。令人驚訝的是,來自最終 SFT 模型的生成輸出往往與人工手寫的 SFT 數據不相上下,表明我們可以調整優先級,將更多標注資源投入到基于偏好的 RLHF 標注中。
微調細節
在監督微調階段,我們采用余弦學習率調度,初始學習率為 2 × 10??,權重衰減為 0.1,批量大小為 64,序列長度為 4096 token。微調樣本由提示(prompt)和回答(answer)組成。為確保模型序列長度被充分利用,我們將訓練集中的所有提示與回答拼接起來,使用特殊 token 分隔提示和回答部分。訓練時采用自回歸目標函數,且對用戶提示部分的 token 不計算損失,反向傳播僅作用于回答 token。最終,我們對模型進行了 2 個 epoch 的微調。
3.2 基于人類反饋的強化學習(RLHF)
RLHF 是一種應用于微調語言模型的訓練方法,用以進一步使模型行為符合人類偏好和指令遵循。我們收集了體現人類偏好的數據,具體做法是讓人工標注者在兩個模型輸出中選擇他們更偏好的一個。這些人類反饋隨后被用來訓練一個獎勵模型,該模型學習標注者偏好的模式,從而實現偏好決策的自動化。
3.2.1 人類偏好數據收集
接下來,我們收集用于獎勵建模的人類偏好數據。我們選擇了二元比較協議,而非其他方案,主要因為它能最大化采集到的提示多樣性。當然,其他策略也值得探索,留作未來工作。
我們的標注流程如下:先讓標注者撰寫一個提示,然后基于提供的標準,在兩個采樣的模型回復間做選擇。為最大化多樣性,兩個回復分別來自不同模型變體,并且調整了溫度超參數。除了強制選擇外,我們還要求標注者對所選回復相對于另一個回復的優越程度進行標注,等級包括“明顯更好”、“更好”、“略好”或“幾乎無差/不確定”。
在偏好標注中,我們重點關注“helpfulness”(幫助性)和“safety”(安全性)。幫助性指 Llama 2-Chat 回復滿足用戶請求并提供所需信息的程度;安全性指模型回復是否不安全,例如“提供制造炸彈的詳細說明”可能被認為是有幫助的,但根據安全指南是不允許的。區分這兩項使我們能對每一項應用具體指南,更好地指導標注者,例如安全性標注專注于對抗性提示等內容。
除標注指南差異外,我們還在安全階段額外收集安全標簽,將模型回復歸類為三類:1)優選回復安全,另一個不安全;2)兩者均安全;3)兩者均不安全。安全數據集中三類比例分別為 18%、47% 和 35%。我們不包含優選回復不安全而另一個回復安全的示例,因為我們認為更安全的回復也更受人類偏好。安全指南及詳細標注信息詳見第 4.2.1 節。
人類標注按周批次收集。隨著偏好數據量增加,獎勵模型得以改進,Llama 2-Chat 訓練出更優版本(見第 5 節圖 20)。Llama 2-Chat 的改進也導致模型數據分布變化。由于獎勵模型準確率在面對新分布時可能迅速下降(如過度專門化,見 Scialom et al., 2020b),每次新一輪 Llama 2-Chat 微調前,收集基于最新模型迭代的偏好數據非常重要,以保持獎勵模型的分布一致性和準確性。
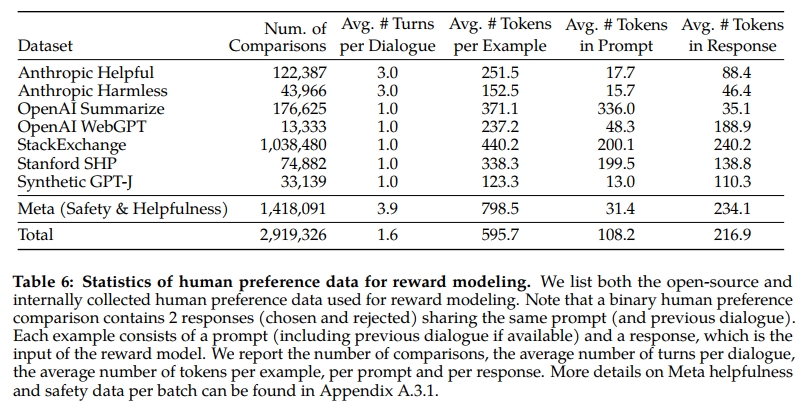
表 6 報告了我們隨時間收集的獎勵建模數據統計,并與多份開源偏好數據集進行了對比,包括 Anthropic Helpful and Harmless(Bai et al., 2022a)、OpenAI Summarize(Stiennon et al., 2020)、OpenAI WebGPT(Nakano et al., 2021)、StackExchange(Lambert et al., 2023)、Stanford Human Preferences(Ethayarajh et al., 2022)及 Synthetic GPT-J(Havrilla)。我們收集了超過一百萬條基于人類應用特定指南的二元比較數據,稱為 Meta 獎勵建模數據。需要注意的是,不同文本領域中提示與回答的 token 數量存在差異。摘要和在線論壇數據通常有較長提示,而對話式提示則較短。相比現有開源數據集,我們的偏好數據具有更多的對話輪次且平均更長。
3.2.2 獎勵建模
獎勵模型輸入模型回復及其對應提示(包括前輪對話上下文),輸出一個標量分數,用以表示生成回復的質量(如幫助性和安全性)。基于此分數作為獎勵,我們可在 RLHF 訓練中優化 Llama 2-Chat,使其更符合人類偏好,提升幫助性和安全性。
已有研究發現,幫助性與安全性有時存在權衡(Bai et al., 2022a),這使得單一獎勵模型難以兼顧兩者。為解決此問題,我們訓練了兩個獨立獎勵模型,一個針對幫助性(稱為 Helpfulness RM),另一個針對安全性(稱為 Safety RM)。
獎勵模型由預訓練聊天模型的檢查點初始化,確保兩個模型共享預訓練時獲得的知識。簡單來說,獎勵模型“知道”聊天模型知道的內容。這避免了兩模型信息不匹配導致青睞幻覺內容的情況。模型架構及超參數與預訓練語言模型相同,只是將下一 token 預測的分類頭替換為回歸頭,用于輸出標量獎勵。
訓練目標
為了訓練獎勵模型,我們將收集到的成對人類偏好數據轉換為二元排序標簽格式(即“被選中”與“被拒絕”),并強制要求被選中回復的分數高于被拒絕回復。我們使用了與 Ouyang 等人(2022)一致的二元排序損失:
Lranking=?log?σ(rθ(x,yc)?rθ(x,yr))(1)L_{\text{ranking}} = -\log \sigma \big(r_\theta(x, y_c) - r_\theta(x, y_r)\big)\quad(1) Lranking?=?logσ(rθ?(x,yc?)?rθ?(x,yr?))(1)
其中,rθ(x,y)r_\theta(x, y)rθ?(x,y) 是模型權重 θ\thetaθ 下對提示 xxx 及回復 yyy 輸出的標量分數,ycy_cyc? 是標注者選擇的優選回復,yry_ryr? 是被拒絕的回復。
基于該二元排序損失,我們針對幫助性和安全性的獎勵模型分別進行了改進。考慮到第 3.2.1 節所述的偏好等級為四檔(如“明顯更好”),利用這一信息顯式地引導獎勵模型對差異更大的生成結果分配更顯著的分數差異是有益的。為此,我們在損失中加入了一個邊際(margin)項:
Lranking=?log?σ(rθ(x,yc)?rθ(x,yr)?m(r))(2)L_{\text{ranking}} = -\log \sigma \big(r_\theta(x, y_c) - r_\theta(x, y_r) - m(r)\big)\quad(2) Lranking?=?logσ(rθ?(x,yc?)?rθ?(x,yr?)?m(r))(2)
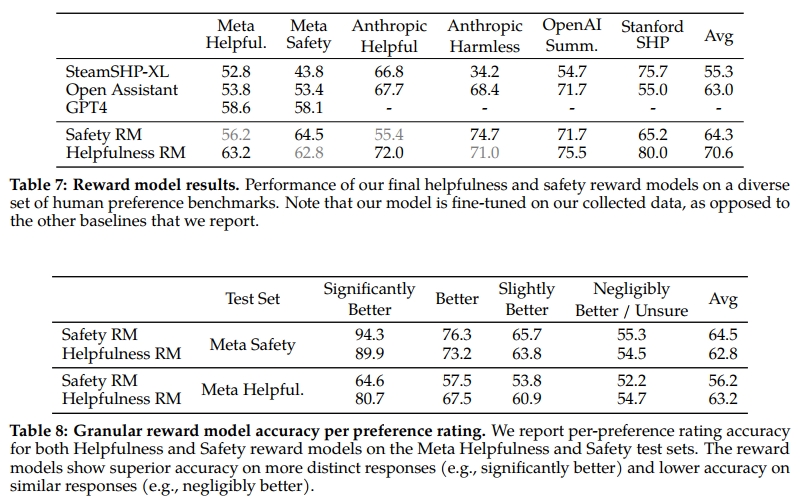
其中,邊際 m(r)m(r)m(r) 是偏好等級的離散函數。自然地,對于差異明顯的回復對使用較大邊際,對于差異較小的回復對使用較小邊際(詳見表 27)。我們發現這一邊際項能夠提升幫助性獎勵模型的準確率,尤其在兩條回復更易區分的樣本上。詳細的消融實驗和分析見附錄 A.3.3 表 28。
數據組成
我們將新收集的數據與現有開源偏好數據集結合,形成更大的訓練集。初期在收集偏好標注數據的同時,使用開源數據集對獎勵模型進行啟動訓練。值得注意的是,在本研究中,RLHF 的獎勵信號旨在學習人類對 Llama 2-Chat 輸出的偏好,而非任何模型的輸出。但實驗中未觀察到開源偏好數據導致的負遷移。因此,我們決定將其保留在訓練數據中,以增強獎勵模型的泛化能力,防止獎勵被“欺騙”,即 Llama 2-Chat 利用獎勵模型弱點,通過表現較差卻得分虛高的方式。
針對來自不同來源的訓練數據,我們對幫助性和安全性獎勵模型分別嘗試了多種混合策略,以確定最佳方案。經過大量實驗,幫助性獎勵模型最終使用了所有 Meta 幫助性數據,配合等比例從 Meta 安全數據及開源數據中均勻采樣的數據。Meta 安全獎勵模型則使用所有 Meta 安全和 Anthropic 無害(Harmless)數據,混合 90% Meta 幫助性和 10%開源幫助性數據。我們發現 10% 幫助性數據的設置對于選中與拒絕回復均被判定為安全的樣本準確率提升顯著。
訓練細節
訓練周期為整個訓練數據集的 1 個 epoch。早期實驗發現訓練過長容易過擬合。優化器參數與基礎模型保持一致。Llama 2-Chat 70B 模型最大學習率為 5×10?65 \times 10^{-6}5×10?6,其余模型為 1×10?51 \times 10^{-5}1×10?5。學習率采用余弦調度,最低降至最大學習率的 10%。采用總訓練步數 3%(至少 5 步)作為預熱(warm-up)步數。有效批量大小固定為 512 對樣本,等同于每批 1024 行數據。
溫馨提示:
閱讀全文請訪問"AI深語解構" Llama 2:開放基礎模型與微調聊天模型


)



?的小樣本故障診斷模型)


)



:性能優化與壓力測試)





