通過網絡初識,我們認識了網絡的協議棧,TCP/IP 分為五層:應用層,傳輸層,網絡層,數據鏈路層,物理層。也介紹了其中的關鍵協議。而這些協議的理解,是我們寫網絡代碼的基礎。
應用層,是程序員打交道最多的層次。
與應用程序直接相關,程序員寫的代碼,只要是涉及到網絡通信的,都可以視為是應用層的一部分~~
應用層這里的東西是和程序員直接相關的,而且應用層中設計到的網絡通信協議,很多也都是程序員自定制的。(也就是你自己寫代碼的時候,發明創造出來的協議。)
那具體如何自定義協議呢?
自定義協議,分為兩個階段:
1.根據需求,明確傳輸哪些信息。
就拿外賣平臺舉例:
首先,會顯示一個商家列表。
客戶端 - 服務器 傳遞的信息(根據需求來的)
請求:
用戶的位置信息(經緯度,用戶的id)
響應:
商家的id,商家的名字,商家的圖片,評分,配送費,種類[…]
2.約定好信息組織的格式
有很多種方式:
1)行文本的方式

上述給出的方案,只是隨便寫的,實際約定的時候,可以有很多變數的。
列和列之間,不一定使用“,”,也可以使用“;”,也可以使用“.”也可以使用 “\t”
多個數據之間,也不一定使用 “\n”,也可以隨心所欲使用任何你喜歡的分隔符。
自定義協議,你就是說了算的那個,只要客戶端和he服務器都按照這同一套規則來進行構造/解析數據就行了。
(如果客戶端和服務器是你一個人搞定,隨便怎么約定都行,如果客戶端和服務器是兩個人搞,需要你兩商量好,達成一致。)
2)通過 xml 格式來約定請求和響應的數據。
說起 xml 可能不太熟悉,但說起 html ,就不那么陌生了,最起碼聽過。
html 和 xml 都是成對的標簽構成的鍵值對結構,而 html 標簽內容都是固定的,大佬們約定好的,你不能亂寫,也不能創建新的標簽。(現在 html5 允許自定義標簽了)但 xml 標簽內容是自定義的。

xml 是用來網絡傳輸的,和瀏覽器怎么顯示無關,html 是約定瀏覽器是怎么顯示的。
xml 可以用于很多場景,組織一段格式化數據用來網絡傳輸,作為配置文件等…
對于 xml 方案,放到十年前,用的還是挺多的,但是現在,已經很少用 xml 進行網絡傳輸了。
xml 的優點:可讀性好。
缺點:冗余信息太多了,網絡傳輸中,消耗更多的帶寬。(對于服務器來說,帶寬是最貴的)
3)使用 json (json 當下最流行的網絡數據格式組織的方案)

json 的優點:可讀性也是很好的,消耗的帶寬,也比剛才談到的 xml 更節省
缺點:還是存在冗余信息。
4)protobuf
基于二進制的格式,對數據進行壓縮,不涉及到 json/xml 冗余信息了。帶寬消耗最少,可讀性就變差了。
對于 protobuf 在性能要求高的場景就需要使用,如果性能要求不高,還是建議使用 json。
它是用開發效率換執行效率(比較少)
總結一下:
數據組織格式:
1.文本行(最原始)
2.xml (比較原始,可讀性好,冗余較多)
3.json(主流的方式,可讀性好,冗余一般)
4.protobuf(高性能場景下使用的方式,可讀性差,冗余最小)
但凡實現一個具體的程序,寫代碼之前,一定是要先約定應用層協議的格式的,應用層這里,除了自定義協議之外,也有一些大佬們現成搞好的協議了。
(FTP 文件傳輸, SSH 遠程操作主機, telnet 網絡調試工具, HTTP 協議[重點]…)。
HTTP 協議是當前 web 開發中最核心的協議,使用網站,都會用到 http,并且 Spring,也是圍繞 http轉。
我們打開一個網站我們會看見 https 。 https = http 基礎上 + 安全層(S 表示安全層 SSL)
HTTP
HTTP是什么
HTTP(全稱為“超文本傳輸協議”)是一種應用非常廣泛的 應用層協議。
“超文本”的含義,就是傳輸的內容不僅僅是文本(比如 html,css這個就是文本),還可以是一些其他的資源,比如圖片,視頻,音頻等二進制的數據。
HTTP誕生于1991年,目前已經發展為最主流使用的一種應用層協議。

HTTP 往往是基于傳輸層的 TCP 協議實現的。(HTTP1.0 , HTTP 1.1 , HTTP 2.0 均為 TCP,HTTP 3基于 UDP 實現)目前我們主要使用的還是 HTTP 1.1 和 HTTP 2.0。這里以 HTTP 1.1 版本為主。
HTTP 是一問一答 模式的協議。客戶端發一個請求,服務器就返回一個響應,請求和響應一一對應。
(網絡通信中也有其他的模型:多問一答(上傳大文件),一問多答(下載大文件),多問多答(遠程控制(todesk)),由于瀏覽器打開網頁的場景/手機app加載數據的場景,就是典型的一問一答場景,所以使用 HTTP 就非常合適。)
抓包工具的使用
理解 HTTP 報文格式時,需要搭配一個重要的工具,進行學習,抓包工具。
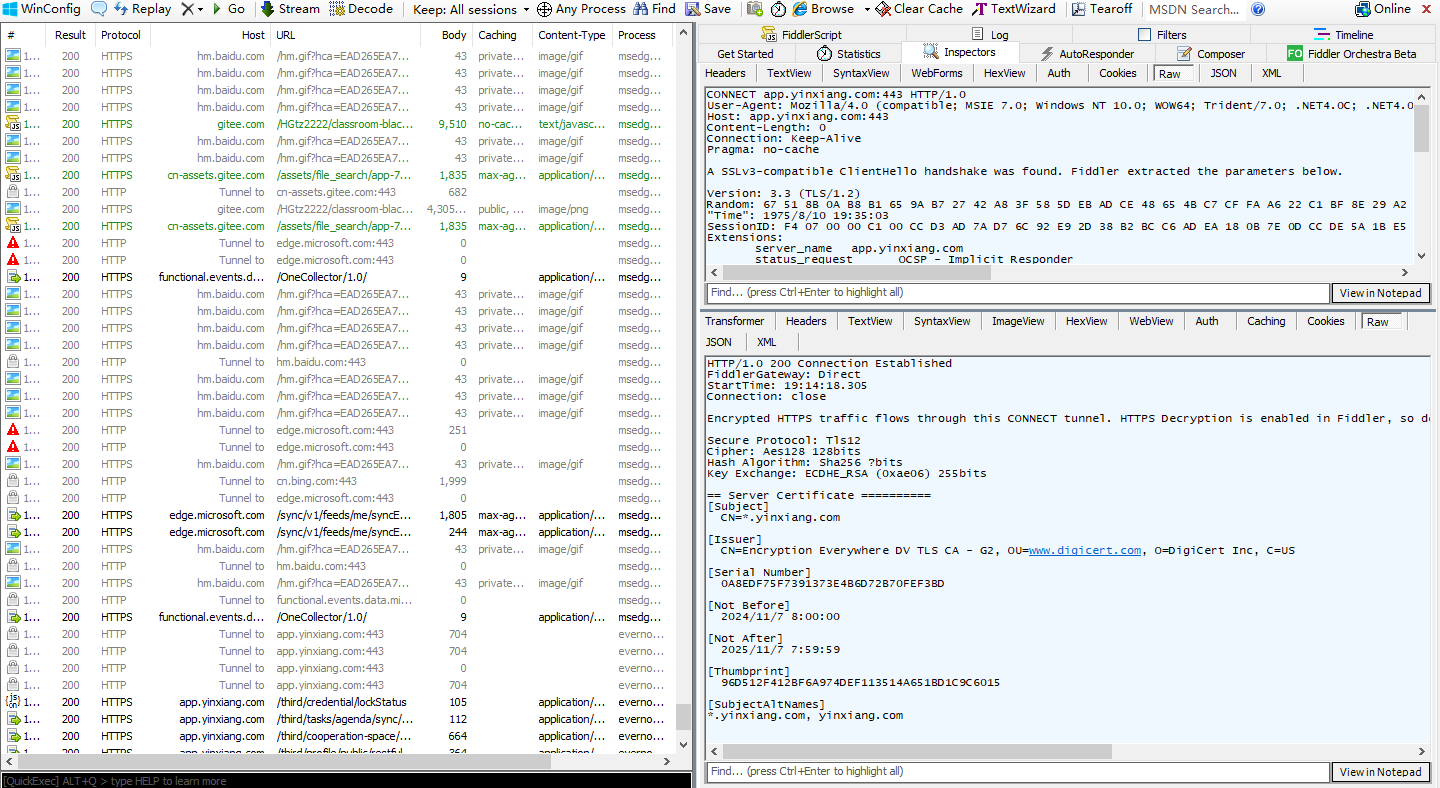
抓包工具就相當一個”代理“,它能夠獲取到網絡的數據包,詳細的格式都解析出來了。
代理就可以簡單理解為一個跑腿小弟,你想買瓶可樂,但是又不想自己買,所以你就把錢給你的跑腿小弟,跑腿小弟來到超市把錢給老板,老板再把可樂拿過來交到你的手上,在這個過程中,這個跑腿小弟對"你"和"老板"之間的交易細節,是非常清楚的。這個跑腿小弟就被稱為正向代理(代表客戶端干活),當然也有反向代理(代表服務器干活)
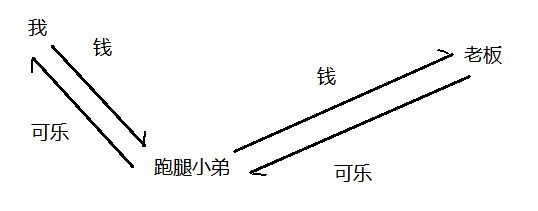
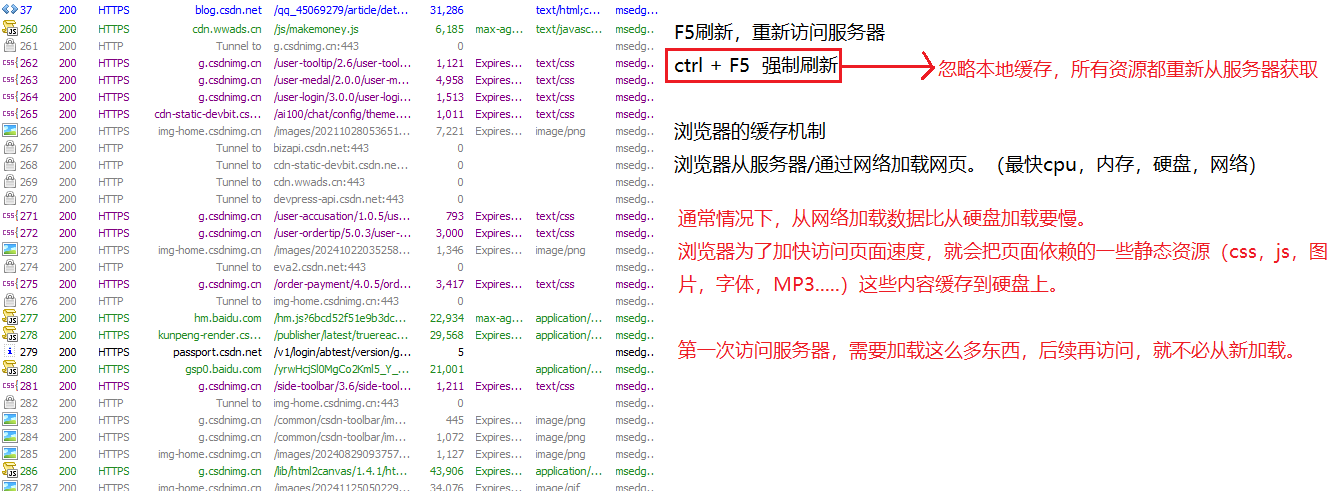
電腦上所有的網絡通信,都會先發給這個抓包程序,抓包程序再把數據轉發給服務器。
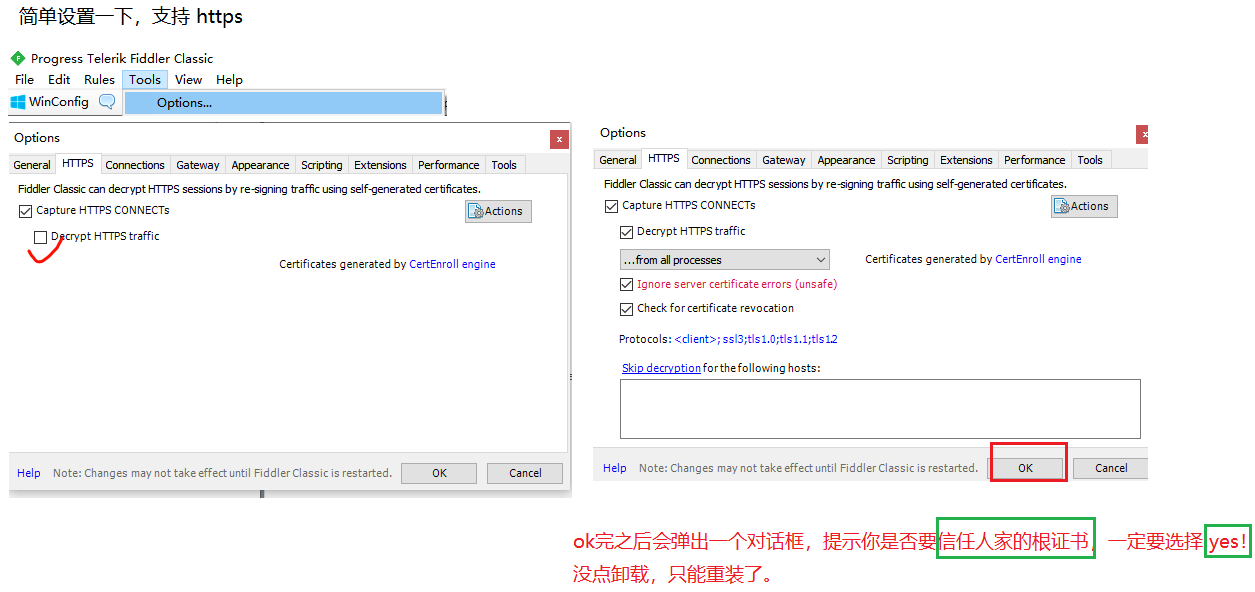
還有,在我們使用抓包的時候,一定要關閉梯子/梯子類的瀏覽器插件,可能會和抓包工具沖突。
抓包工具就以 fiddler 為例(fiddler 是專門抓 http 的,功能更簡單也夠用,使用更簡單)。

安裝完后一路next就好了。
電腦上很多程序,不安分,都在后臺偷偷的做一些事情。
左側窗口為當前的請求/響應的列表(fiddler 只抓 http)
字體的顏色:
紅色表示報錯 藍色表示這個請求得到了這個網頁 綠色的表示得到了一個 js 灰色的表示這個響應的數據已經被緩存了
隨便雙擊一個 http ,隨后點擊右邊窗口
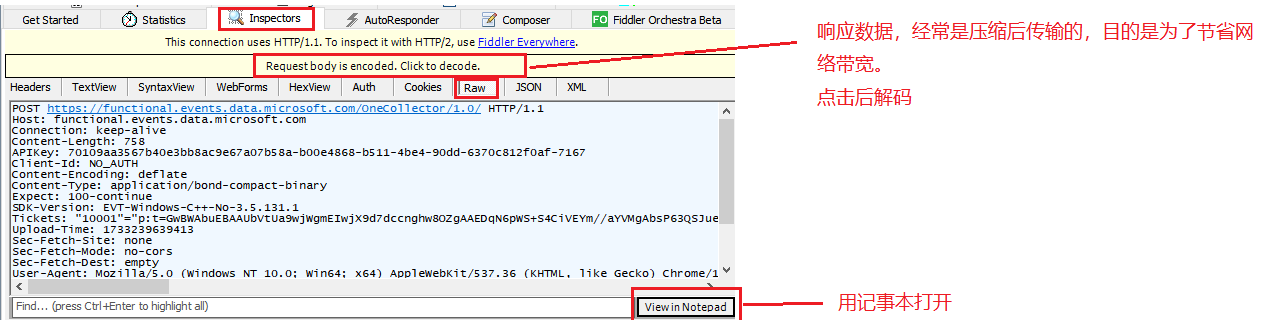
- 左側窗?顯?了所有的 HTTP請求/響應, 可以選中某個請求查看詳情。
- 右側上?顯?了 HTTP 請求的報?內容. (切換到 Raw 標簽?可以看到詳細的數據格式)。
- 右側下?顯?了 HTTP 響應的報?內容. (切換到 Raw 標簽?可以看到詳細的數據格式)。
- 請求和響應的詳細數據, 可以通過右下?的 View in Notepad 通過記事本打開。
- 可以使? ctrl + a 全選左側的抓包結果, delete 鍵清除所有被選中的結果.
抓包結果
HTTP請求的結果:

HTTP響應的結果:

協議格式總結:

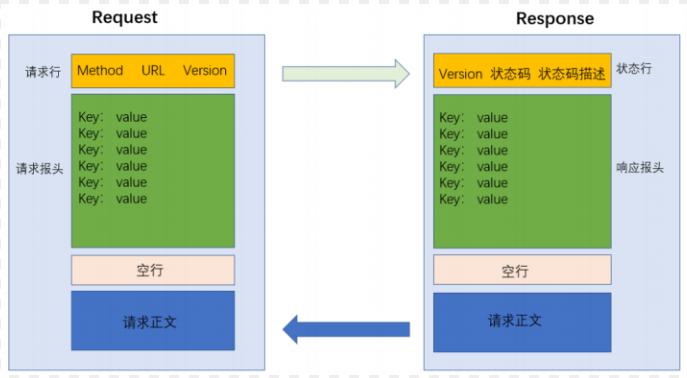
HTTP請求
URL
平時我們俗稱的 “?址” 其實就是說的 URL (Uniform Resource Locator 統?資源定位符)。互聯?上的每個?件都有?個唯?的URL,它包含的信息指出?件的位置以及瀏覽器應該怎么處理它。(描述網絡上的唯一資源的位置)
url的格式:

具體的url:

URL 中的可省略部分
- 協議名: 可以省略, 省略后默認為 http://
- ip 地址 / 域名: 在 HTML 中可以省略(?如 img, link, script, a 標簽的 src 或者 href 屬性). 省略后表?服務器的 ip / 域名與當前 HTML 所屬的 ip / 域名?致.
- 端?號: 可以省略. 省略后如果是 http 協議, 端?號?動設為 80; 如果是 https 協議, 端?號?動設為443.
- 帶層次的?件路徑: 可以省略. 省略后相當于 / . 有些服務器會在發現 / 路徑的時候?動訪問/index.html
- 查詢字符串: 可以省略
- ?段標識: 可以省略
關于URL的encode
URL 中本身就有一些特殊符號,代表不同的特殊含義 “: / ? # & = …”。
由于query string的內容,是程序員自定義的,萬一 query string 里也包含了特殊含義的符號咋辦??
因此,某個參數中需要帶有這些特殊的字符,就必須先對這些特殊字符進行轉義。
一個中文字符由UTF-8或者GBK這樣的編碼方式構成,雖然在URL 中沒有特殊的含義,但是任然需要進行轉義,否則瀏覽器可能把UTF-8/GBK編碼中的某個字節當作URL中的特殊符號。只不過很多瀏覽器為了用戶看起來方便,顯示的時候顯示轉義之前的,實際上,抓包中就能看到,是已經轉義的數據。
轉義的規則如下:將需要轉碼的字符轉為16進制,然后從右到左,取四位(不足四位直接處理),每兩位做一位,前面加上%,編碼成%XY格式。
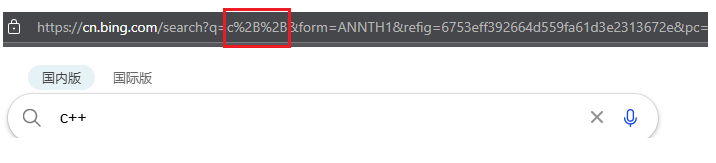
這里面“+”被轉義成“%2B”。
urldecode就是urlencode的逆過程。
認識“方法”
這里面最重要的就是 GET 和 POST方法,其次就是PUT和DELETE 方法。其他了解就行。
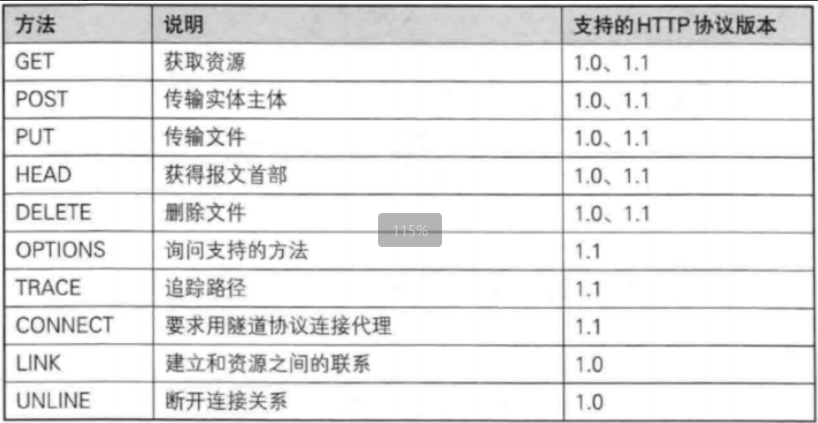
- GET方法
GET 是最常?的 HTTP ?法. 常?于獲取服務器上的某個資源。
在瀏覽器中直接輸? URL, 此時瀏覽器就會發送出?個 GET 請求。
另外, HTML 中的 link, img, script 等標簽,獲取CSS,獲取JS等操作也會觸發 GET 請求。
在上面的結果中可以看到:
最上面的

是通過瀏覽器地址欄發送的GET請求。
也可以觀察請求的詳細結果。

GET請求一般都是沒有 body 的,如果需要通過 GET 給服務器發送一些數據,通過 query string 傳遞過去的。
- POST方法
兩個典型的場景:
1、登錄
2、上傳 => 請求帶有正文的。正文就是保存了當前上傳的數據的內容。
上述請求中,圖片本身是二進制的,通過特殊方式進行轉碼(base64編碼,把二進制轉成文本),其實body 也是可以直接填二進制數據。
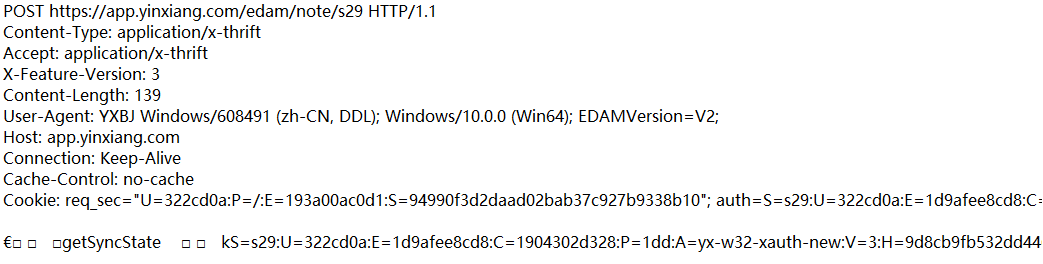
POST 請求的特點:
- ??的第?部分為 POST。
- URL 的 query string ?般為空 (也可以不為空)。
- header 部分有若?個鍵值對結構。
- body 部分?般不為空。 body 內的數據格式通過 header 中的 Content-Type 指定.。body 的?度,由 header 中的 Content-Length 指定。
談談GET和POST區別:
- 1、語義不同:GET一般用于獲取數據,POST一般用于提交數據。(語義上可以混著用)
- 2、攜帶數據的方式:GET的body一般為空,需要傳遞的數據通過 query string傳遞,POST的 query string 一般為空,需要傳遞的數據通過 body 傳遞。(POST也是可以帶有query string(還是有一些的),GET理論上也是可以帶 body(更少見))
- 3、GET 請求一般是冪等的(HTTP標準文檔給的建議,但只是建議,不是強制要求),POST請求一般是不冪等的。(如果多次請求得到的結果一樣,就視為請求是冪等的)
- 4、GET設計成冪等了,就可以允許 GET 請求的結果被緩存,POST 由于不要求冪等,經常是不冪等的,就認為不能被緩存。
對于PUT和DELETE,實現restful風格的 api 的時候,會用到。
設計服務器接口的一種”習慣“
新增:POST
刪除:DELETE
修改:PUT
查詢:GET
這四個操作的任何一個,都可以進行增刪查改,完全取決于你代碼咋寫。
認識請求報頭(header)
header 的整體的格式也是“鍵值對”結構,每個鍵值對占一行。鍵和值之間使用“: 空格”分割。
報頭的種類有很多, 此處僅介紹?個常?的
- Host:表示服務器主機的地址和端口

有的人可能會想到在 url 里面不是就有 IP地址(域名):端口號嗎?為什么還要用Host再記錄一下?
由于在絕大部分情況下,這兩屬性也是一致的,但是也是有一些特殊場景下是不一致的。那就是使用了 代理 ,使用代理之后,url 里的IP:端口號會改變,因此,即使使用了代理,也是可以通過 Host 來獲取到最原始的目標是什么。
- Content—Length:表示 body 中的數據長度,單位是字節
HTTP 協議,傳輸層這里基于 TCP 實現的(版本號 <= 2.0),所謂的HTTP協議,就是把字符串構造成HTTP約定的格式。

把這一串字符串,寫入到 tcp socket中,對于TCP 來說,一個連接上可以發多個請求,那服務器這邊收到數據的時候就得區分一下,從哪里到哪里是一個完整的http請求數據。
沒有body的 http 請求,讀到空行,就可以認為是結束了。
有body 的 http 請求呢?先讀取首行和 header ,讀到空行,解析 header中的 Content—Length 根據這里的值,接下來再讀取固定字節的長度。
- Content—Type:表示請求的 body 中的數據格式
提示了接收方如何解析 body 中的數據。

再 fiddler里我們可以直接看出 Content—Type
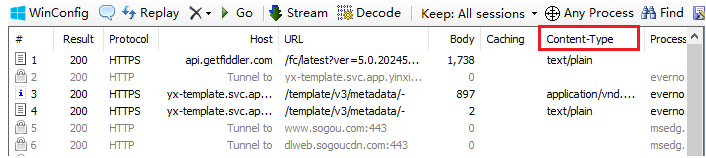
小知識:
我們來看一個Content-Type為js的body
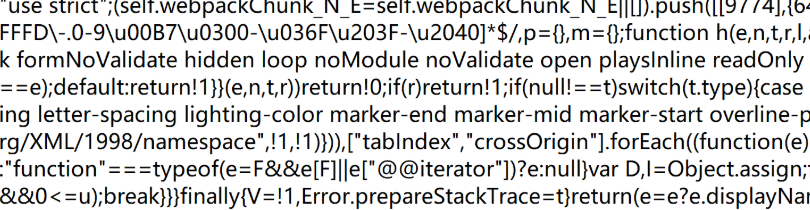
這些東西都是合法的 js 的語句,只是看起來和咱們學的 js 是不一樣的,本質語法都是同一套。像C++/Java這樣的代碼,會編譯成二進制,發布給用戶,用戶拿到的是二進制代碼,用戶想根據二進制還原出源代碼是什么樣子的,是非常麻煩的。
由于 js 這樣的代碼則是把原始代碼直接由用戶瀏覽器下載到,用戶就能看到 js 的原始的樣子,因此,為了防止別人基于你的代碼,搭建出一樣的網頁,我們會用專門的工具,把 js 做出變換,使得代碼混淆(也就是在代碼邏輯不變的情況下,把js 代碼給改亂,讓別人讀起來的成本更高)。
對于 Content-Length 和 Content-Type ,如果請求有 body,并且沒有這兩個屬性(哪怕只有一個)都認為是非法的/錯誤的http報文。
- User-Agent(簡稱UA):表示用戶使用的設備的瀏覽器/操作系統的屬性情況。

為什么要有UA?
隨著互聯網的快速發展,瀏覽器的版本也在不斷更新,同一個時間段內,有些用戶的瀏覽器,版本是比較舊的,支持的功能少,有些用戶瀏覽器版本更新,支持的功能多,如果要是支持的功能少,可能就打不過競爭對手,要是支持的功能多,舊版本瀏覽器設備的用戶,可能就展示不了。所以,要根據用戶使用的設備進行區分,通過 UA 中的瀏覽器版本/操作系統版本,區分出當前用戶的設備,最多支持哪些特性~因此程序員就需要維護多套代碼,對于老的瀏覽器,返回功能少的網頁,正確顯示,對于新的瀏覽器,返回功能多的網頁,體驗豐富。此外 UA 還有另外一個用途:可以用來區分用戶的設備。
windows/mac => PC 根據用戶的設備,返回不同版本的頁面
ios/android => 手機
User-Agent 之所以是這個樣?是因為歷史遺留問題.感興趣的可以去搜一搜UA的故事。
- Referer:描述了當前頁面的來源(這個頁面是從哪個頁面跳轉過來的)
如果直接在瀏覽器中輸?URL, 或者直接通過收藏夾訪問??時是沒有 Referer 的.
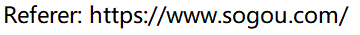
意思是這個頁面是從www.sougou.com 跳轉過來的。
- Cookie
瀏覽器展示頁面的過程中,頁面里雖然可以通過 js 來實現一些邏輯,但是 js 代碼無法訪問你的硬盤(文件系統),瀏覽器給 js 帶上的緊箍咒。但是在實際開發中,有的時候還是希望把某些數據能夠保存到本地硬盤的。因此,瀏覽器引入了 cookie 機制。
cookie 就是瀏覽器允許網頁在本地硬盤存儲數據的一種機制,不是讓網頁代碼直接訪問文件系統,而是做了一層抽象,而是瀏覽器的 cookie 提供了鍵值對存儲機制。
Cookie 這里是按照鍵值對的方式來存儲數據的~
講到現在,細心的小伙伴會發現我們已經提了很多遍 “鍵值對”了。

瀏覽器中可以直接看到當前頁面保存的cookie有哪些。
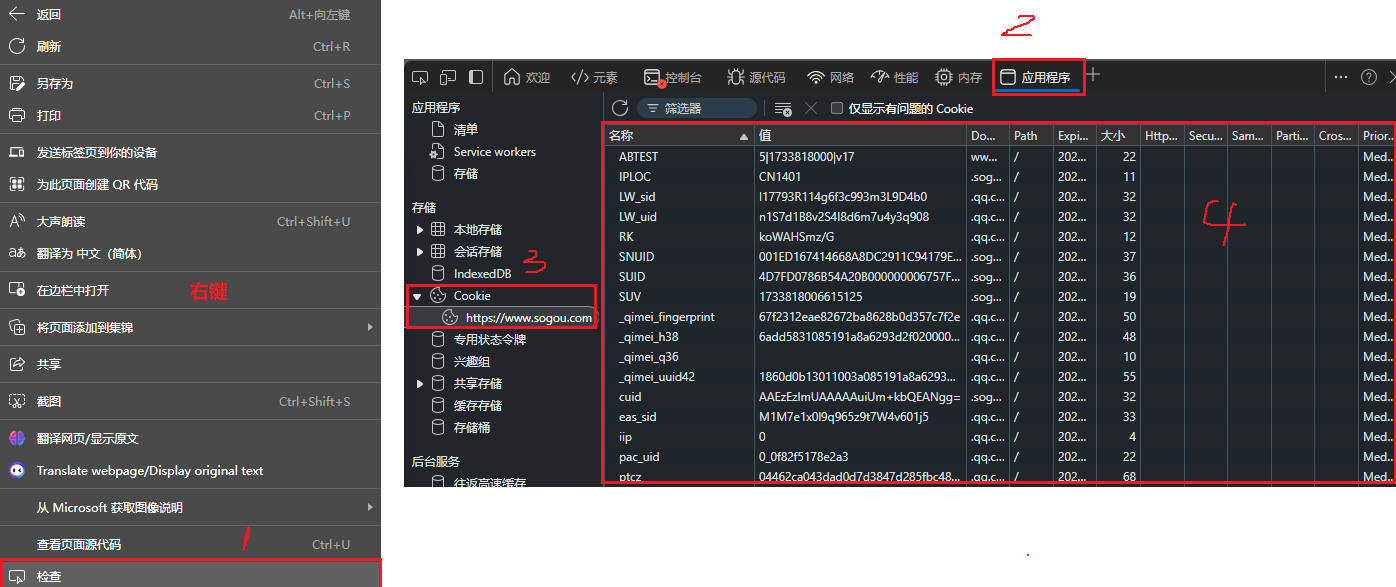
cookie 按照域名維度來組織的,每個不同的域名下都可以有不同的 Cookie, 不同?站之間的 Cookie 并不沖突
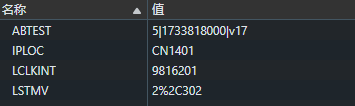
這些都是程序員自定的。
瀏覽器保存了這些 cookie 之后,就會在后續給服務器發送請求的時候,把這些 cookie 鍵值對放到請求 cookie header 中傳輸給服務器。
cookie 到哪里去:最終發回給服務器。
cookie 從哪里來:也是從服務器這邊來的.(后端開發程序員決定的)
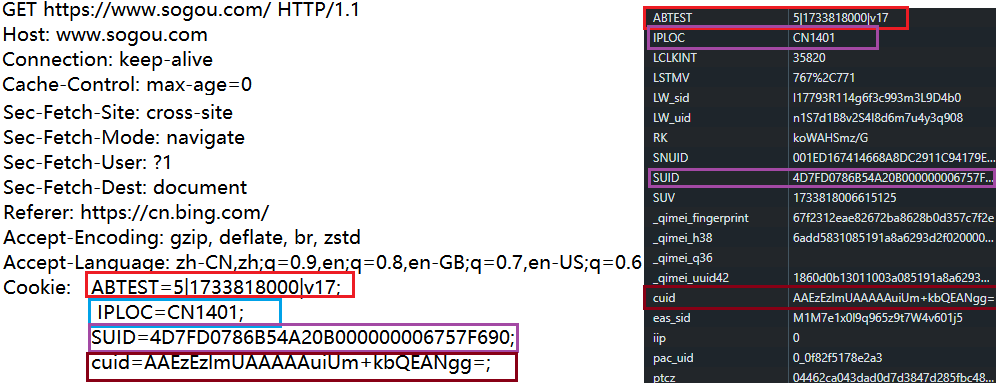
Cookie 里的數據都是程序員自定義內容,業務相關的,但是有一個典型的場景,屬于“通用業務”,登陸和用戶認證。
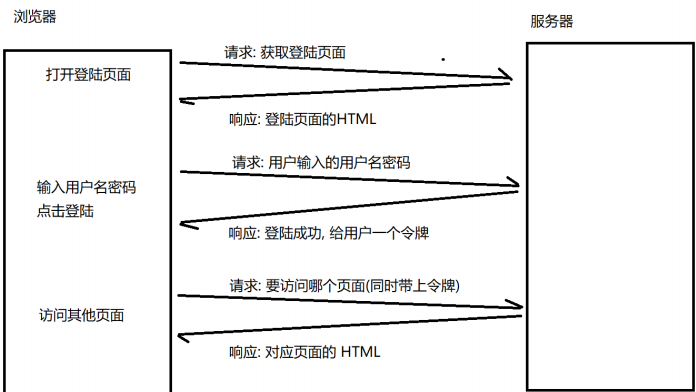
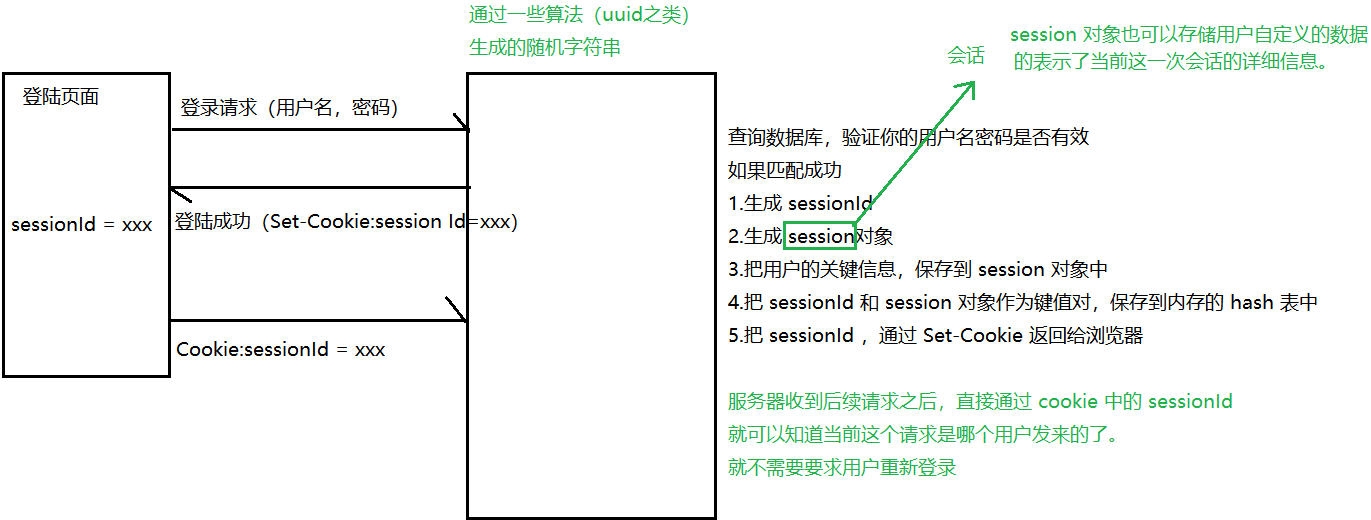
會話:描述了客戶端和服務器之間的一種交互關系
數據庫,也是服務器。對應的客戶端,就是你的應用程序 /Workbench…
你的這個客戶端訪問一次數據庫服務器,這個中間的過程也可以稱為是一次會話。
Cookie是可能會過期的(有的網站,對于安全性要求不高,過期時間就長,有的網站,對于安全性要求很高,過期時間就短),服務器返回 Cookie 的時候,是可以設置有效時間。有的 Cookie 中的 sessionId 過期了,此時就需要用戶重新登錄了。但用戶重新登錄的時候,是否需要重新手動輸入一遍密碼,就是瀏覽器的記住密碼功能解決的問題了。
這個過程和去醫院看病很相似.
- 到了醫院先掛號. 掛號時候需要提供?份證, 同時得到了?張 “就診卡”, 這個就診卡就相當于患者的"令牌(token)".
- 后續去各個科室進?檢查, 診斷, 開藥等操作, 都不必再出??份證了, 只要憑就診卡即可識別出當前患者的?份.
- 看完病了之后, 不想要就診卡了, 就可以注銷這個卡. 此時患者的?份和就診卡的關聯就銷毀了. (類似于?站的注銷操作)
- ?來看病, 可以辦?張新的就診卡, 此時就得到了?個新的 ”令牌“
請求”正文“(body)
正文中的內容格式和 header 中的 Content-Type 密切相關。
我們都是可以通過 fiddler 觀察的。這里就不多于講了。就展開比較常見的json。
application/json

這里都是自定義的。
HTTP響應
狀態碼(status code)
狀態碼表示訪問頁面的結果,是訪問成功,還是出錯,出錯是什么原因。
以下是常見的狀態碼。
- 200 OK : 這是一個最常見的狀態碼,表示訪問成功。
- 404 Not Found : 訪問的資源沒找到。(瀏覽器輸入一個URL,目的就是為了訪問對方服務器的一個資源,而URL中,ip定位到主機,port定位到程序,path定位到程序管理的資源,如果 path 訪問的資源,在服務器上沒有,就會 404)
- 403 Forbidden : 表示訪問被拒絕(沒有權限),有的頁面通常需要用戶具有一定的權限才能訪問,如果用戶沒有登錄直接訪問,就容易見到403。
- 405 Method Not Allowed : 方法不被允許,請求的方法和服務器這邊聲明的注解不匹配,就會出現405。(網上找別人的網站出現 405,比較難找的,但自己開發過程中,很容易出現405 )
- 500 Internal Server Error : 服務器出現錯誤,一般是服務器的代碼執行過程中遇到了一些特殊情況(服務器異常崩潰)會產生這個狀態碼。也就是服務器處理邏輯的代碼中拋出異常,但是你沒有catch到。
- 504 Gateway Timeout : 當服務器負載比較大的時候,服務器處理單條請求的時候消耗的時間就會很長,就可能會導致出現超時的情況。(Gateway:網關,也就是網絡的入口,一般來說,入口服務器就認為是網關,可能是一個軟件,也可能是一個專門的機器)
- 302 Move temporarily : 臨時重定向。
- 301 Moved Permanently :永久重定向,當瀏覽器收到這種響應時,后續的請求都會被自動改成新的地址。
理解”重定向“
相當于訪問A服務器,服務器A告訴你去找 B。例如遷移域名。如果直接遷移了l,就會使所有保存舊域名的人無法訪問了,于是就把服務器架設在新域名上,給舊域名設置重定向,可以重定向到新域名,因此如果訪問新域名就能直接進,訪問舊域名就會自動跳轉到新域名上。
在登錄頁面中經常會見到302,用于實現登錄成功后自動跳轉到主頁,響應報文的header部分會包含一個location字段,表示要跳轉到哪個頁面。
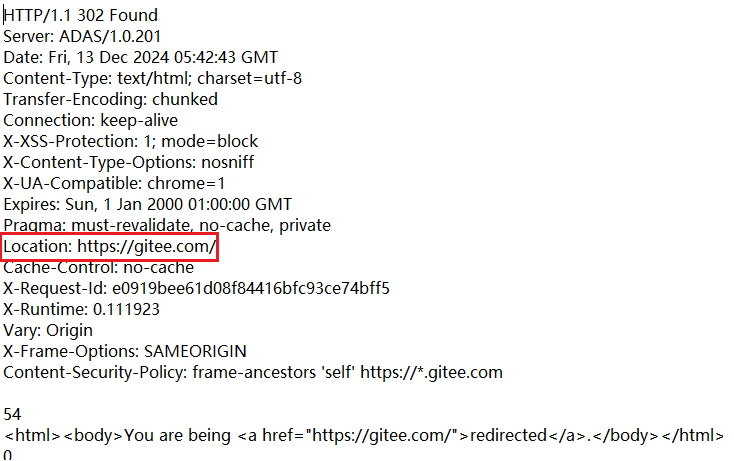
可以看到header中的 Location:http://gitee.com/ ,接下來瀏覽器就會自動發送GET請求,獲取Location:http://gitee.com/。
狀態碼整體有很多:
2XX 都可以視為是成功,3XX 都是重定向, 4XX 客戶端出錯,用戶構造的請求有問題, 5XX 服務器出錯(Java程序員主要關注這個,一定是服務器出問題了大概率就是你的代碼有bug)

認識響應“報頭”(header)
響應報頭的基本格式和請求報頭的格式基本一致,類似于 Content -Type,Content-Length等屬性的含義也和請求中的含義一致。
Content-Type
響應中的 Content-Type 常見取值有以下幾種:
- text/html:body數據格式是 HTML
- text/css:body數據格式是CSS
- application/javascript:body數據格式是 JavaScript。
- application/json:body數據格式是JSON。
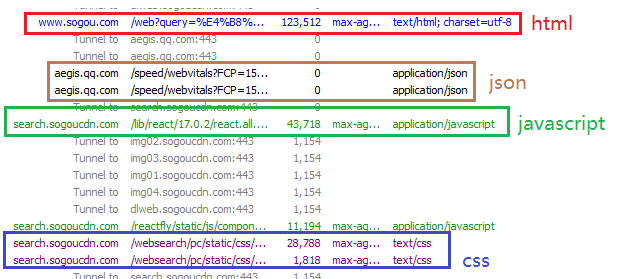
響應“正文”(body)
正文的具體格式取決于 Content-Type。可以觀察上面幾個抓包結果中的響應部分。
1、text/html

2、text/css

3、application/javascript

4.application/json

通過 Java socket 構造 HTTP 請求
所謂的“發送 HTTP 請求”,本質上就是按照 HTTP 的格式往 TCP Socket 中寫入一個字符串。
所謂的“接受 HTTP 響應”,本質上就是從 TCP Socket 中讀取一個字符串,再按照 HTTP 的格式來解析。
此外呢,我們還可以使用 Postman,apifox 這樣的工具來構造 HTTP 請求。

)



:性能優化與壓力測試)













)