對比
對比維度及優缺點分析
| 對比維度 | LangChain(封裝 FAISS) | 直接使用 FAISS |
|---|---|---|
| 易用性 | ? 高,提供高級封裝,簡化開發流程 | ? 中等,需要熟悉 FAISS API |
| 學習成本 | ? 低,適合快速開發 | ? 高,需要掌握 FAISS 的索引類型、添加/查詢流程等 |
| 集成能力 | ? 強,天然支持 LLM、Prompt、Chain 等模塊 | ? 弱,需手動集成 LLM 相關邏輯 |
| 封裝程度 | ? 高,隱藏底層實現細節 | ? 低,需自己管理索引、內存、數據結構等 |
| 靈活性 | ? 有限,依賴 LangChain 提供的封裝接口 | ? 高,可完全控制 FAISS 行為 |
| 性能優化 | ? 一般,封裝可能帶來額外開銷 | ? 高,可針對特定場景進行優化 |
| 持久化支持 | ? 有,LangChain 提供了 save_local / load_local 方法 | ? 有,FAISS 也支持保存和加載索引文件 |
| 索引類型支持 | ? 有限(通常使用 IndexFlatL2) | ? 豐富(支持 IndexFlatL2、IVFPQ、HNSW 等) |
| 擴展性 | ? 高,可輕松對接其他向量數據庫(如 Pinecone、Chroma) | ? 低,需手動切換數據庫 |
| 部署難度 | ? 低,適合本地開發、小項目 | ? 中等,適合中大型項目或生產環境優化 |
| 調試與維護 | ? 簡單,封裝好日志、錯誤提示 | ? 復雜,需自行處理底層錯誤、內存問題等 |
典型使用場景對比
| 使用場景 | 推薦方式 | 說明 |
|---|---|---|
| 快速搭建一個本地向量數據庫 | ? LangChain + FAISS | 適合開發、測試、教學 |
| 需要高性能、大規模向量檢索 | ? 直接使用 FAISS | 可選擇 IVFPQ、HNSW 等高效索引 |
| 與 LLM、Prompt、Chain 結合使用 | ? LangChain | LangChain 提供了統一接口,方便構建完整流程 |
| 需要切換向量數據庫(如從 FAISS 切換到 Pinecone) | ? LangChain | 封裝抽象,只需改配置 |
| 需要深度優化索引性能 | ? 直接使用 FAISS | 可靈活配置索引類型、量化方式等 |
| 生產環境部署 | ? LangChain + FAISS(簡單場景) ? 直接使用 FAISS(復雜場景) | 根據規模和性能需求選擇 |
本地搭建embedding模型(Qwen3-Embedding-0.6B)
本文向量提取均使用本地embedding模型
vllm下載
conda create -n myenv python=3.12 -y
conda activate myenv
pip install --upgrade uv
uv pip install vllm --torch-backend=auto -i https://pypi.tuna.tsinghua.edu.cn/simple
下載模型
pip install modelscope
mkdir models
modelscope download --model Qwen/Qwen3-Embedding-0.6B --local_dir /models/Qwen3-Embedding-8B
modelscope download --model Qwen/Qwen3-Embedding-0.6B --local_dir /models/Qwen3-Reranker-8B
啟動命令
vllm serve Qwen/Qwen3-Embedding-0.6B
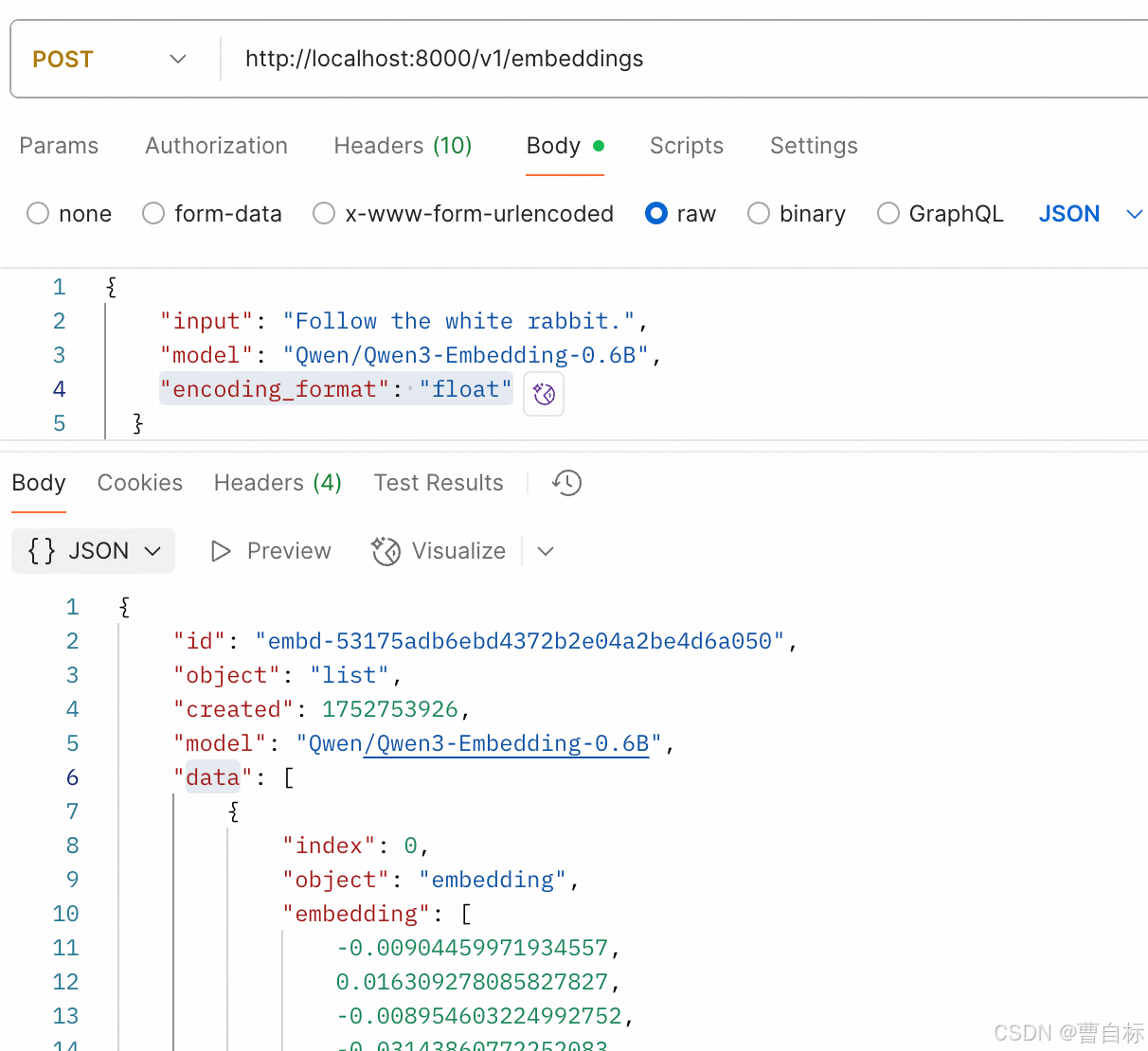
本地接口測試
curl --location 'http://localhost:8000/v1/embeddings' \
--header 'Content-Type: application/json' \
--data '{"input": "Follow the white rabbit.","model": "Qwen/Qwen3-Embedding-0.6B","encoding_format": "float"}'
自封裝本地embedding模型
class LocalEmbeddings(Embeddings):def __init__(self, api_url: str = "http://localhost:8000/v1/embeddings"):self.api_url = api_urldef embed_documents(self, texts: List[str]) -> List[List[float]]:payload = {"input": texts,"model": "Qwen/Qwen3-Embedding-0.6B", # 替換為你實際使用的模型名"encoding_format": "float"}response = requests.post(self.api_url, json=payload)if response.status_code != 200:raise Exception(f"API request failed with status code {response.status_code}: {response.text}")result = [item["embedding"] for item in response.json()["data"]]return resultdef embed_query(self, text: str) -> List[float]:return self.embed_documents([text])[0]
Langchain實現
安裝faiss(https://github.com/facebookresearch/faiss/blob/main/INSTALL.md)
conda install -c pytorch faiss-cpu=1.11.0
進行向量存儲和檢索
from langchain.embeddings.base import Embeddings
import requests
from typing import List
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter# 初始化本地 embeddings
embeddings = LocalEmbeddings()# 示例文本
# texts = ["這是一個測試句子", "這是另一個測試句子"]
#
# # 使用 embeddings 構建向量數據庫
# vectorstore = FAISS.from_texts(texts=texts, embedding=embeddings)# 加載本地文檔,并進行切分
raw_documents = TextLoader('xxx.txt').load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
print(len(documents))# 對切分后的文檔進行提取特征和入庫向量庫
db = FAISS.from_documents(documents, embedding=embeddings)# 查詢相似文本
query = "測試句子"
docs = db.similarity_search(query, 4)
print(docs)

langchain調用qwen文章參考:https://qwen.readthedocs.io/zh-cn/latest/framework/Langchain.html
Faiss實現
直接上代碼
import faiss
from langchain.embeddings.base import Embeddings
import requests
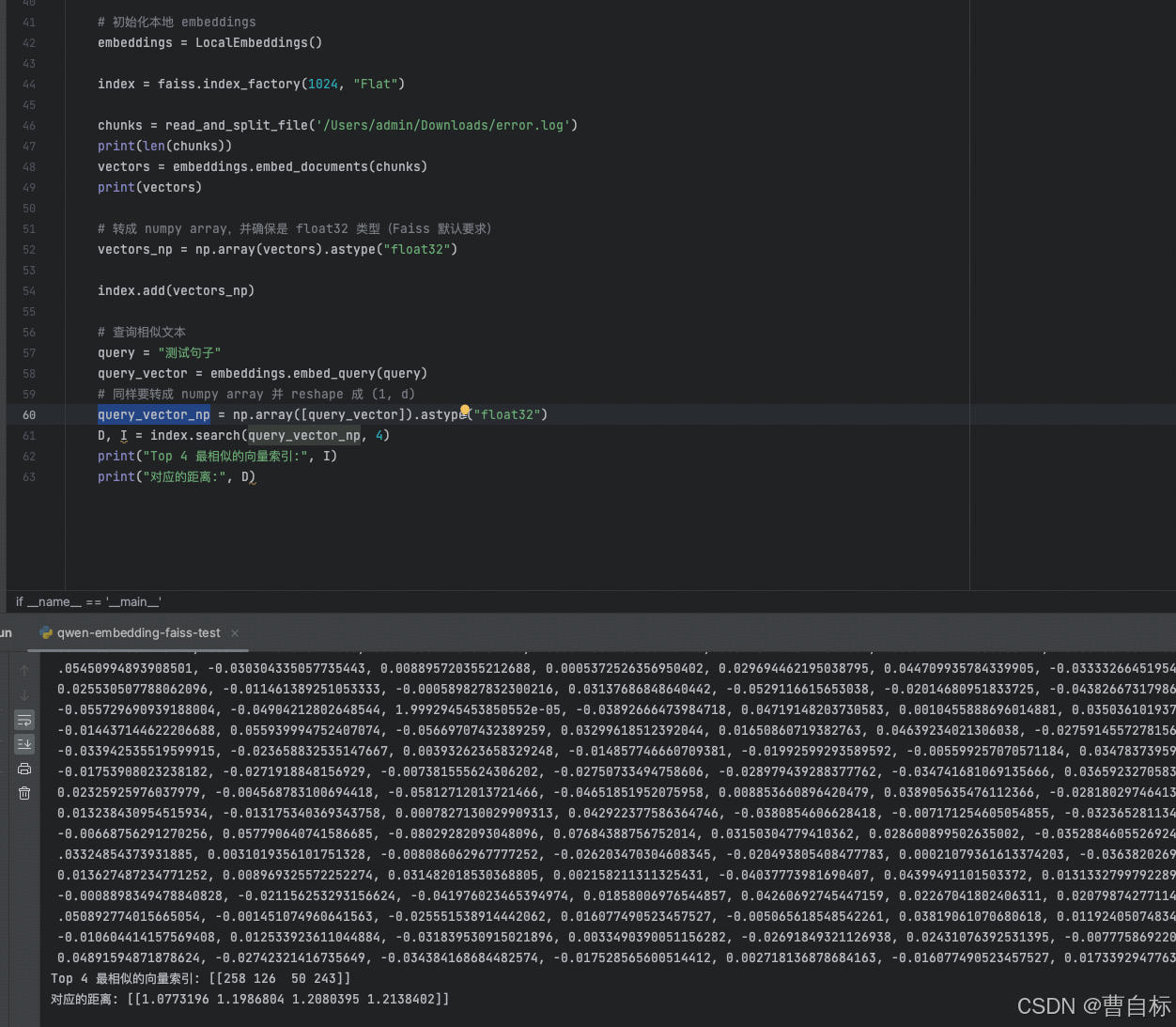
from typing import Listdef read_and_split_file(filepath, chunk_size=500):with open(filepath, 'r', encoding='utf-8') as file:data = file.read()# Split the text into chunks of 500 characters.chunks = [data[i:i + chunk_size] for i in range(0, len(data), chunk_size)]return chunks# 初始化本地 embeddings
embeddings = LocalEmbeddings()index = faiss.index_factory(1024, "Flat")chunks = read_and_split_file('/Users/admin/Downloads/error.log')
print(len(chunks))
vectors = embeddings.embed_documents(chunks)
print(vectors)# 轉成 numpy array,并確保是 float32 類型(Faiss 默認要求)
vectors_np = np.array(vectors).astype("float32")index.add(vectors_np)# 查詢相似文本
query = "測試句子"
query_vector = embeddings.embed_query(query)
# 同樣要轉成 numpy array 并 reshape 成 (1, d)
query_vector_np = np.array([query_vector]).astype("float32")
D, I = index.search(query_vector_np, 4)
print("Top 4 最相似的向量索引:", I)
print("對應的距離:", D)




)



?的小樣本故障診斷模型)


)



:性能優化與壓力測試)



