Kafka Broker
Broker實際上就是kafka實例,每一個節點都是獨立的Kafka服務器。
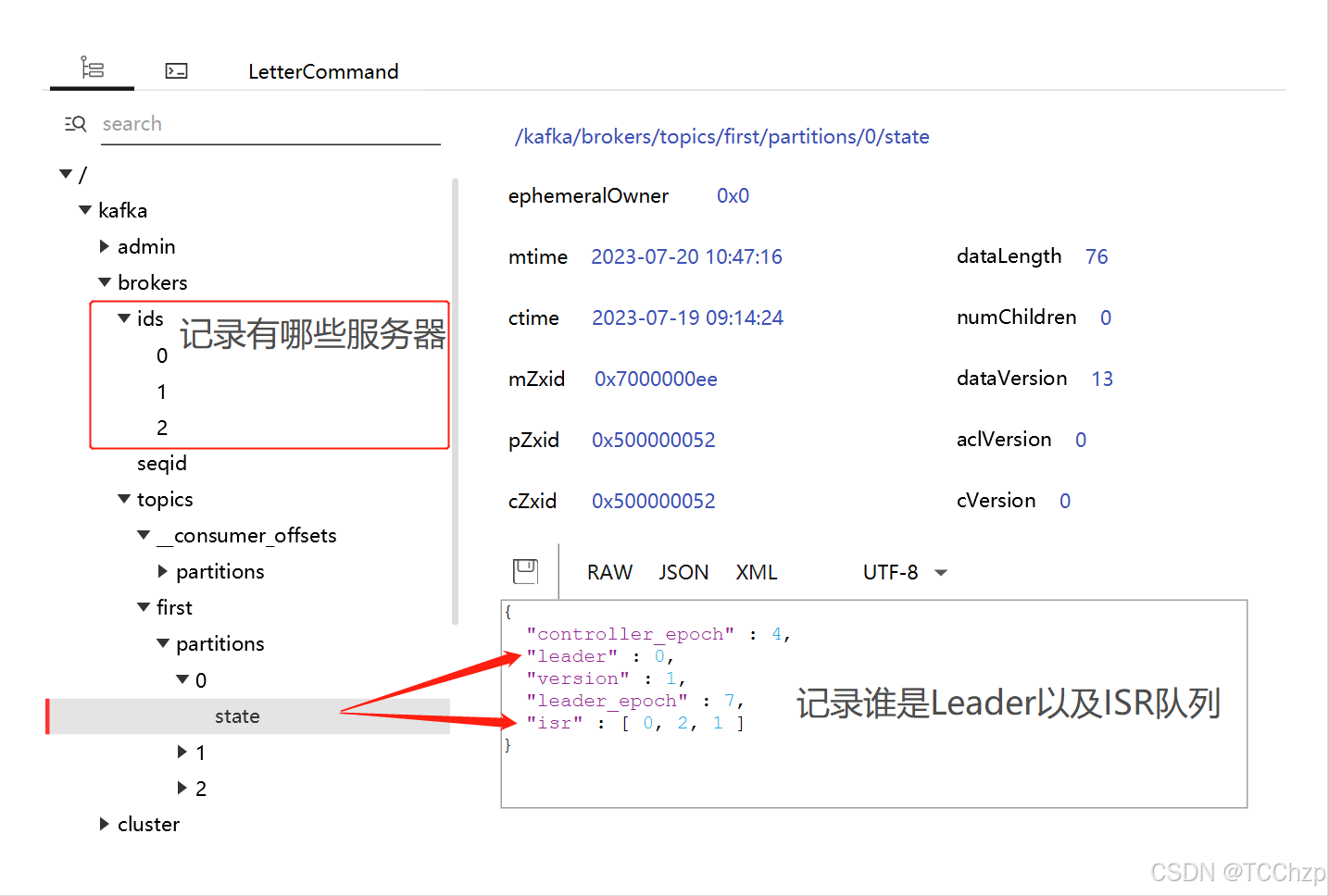
Zookeeper中存儲的Kafka信息
節點的服役以及退役
服役
首先要重新建立一臺全新的服務器105,并且在服務器中安裝JDK、Zookeeper、以及Kafka。配置好基礎的信息之后,再將節點加入到kafka集群之中。如果是直接拷貝配置好的主機一定要先修改主機的ip地址以及主機名,那么一定要移除kafka的broker.id并且要刪除kafka安裝目錄下的datas以及logs下的所有文件,不然復制的主機和被復制的主機會產生沖突。
rm -rf datas/ logs/
將節點加入到kafka集群之中,只需要在105機器中的kafka安裝目錄下執行啟動命令
bin/kafka-server-start.sh -daemon config/server.properties
啟動之后,kafka就會將自己的broker.id注冊到zookeeper中,這樣就加入了kafka集群。此時雖然加入了集群,但是并沒有跟101、102、103之間同步數據,相當于沒有起到作用。此時需要執行負載均衡操作,讓105能夠和其他三臺主機一起共同工作。
首先在安裝目錄下創建一個新文件(直接操作101主機即可)
vim topics-to-move.json
{"topics":[{"topic":"first"}],"version":1
}
執行生成負載均衡計劃命令,為0,1,2,3生成負載均衡計劃,系統會生產一個負載均衡計劃
bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.27.101:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate
查看計劃如果滿足要求,那么復制計劃,并新建一個文件將復制的計劃粘貼到文件中
vim increase-replication-factor.json
執行副本存儲計劃
bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.27.101:9092 --reassignment-json-file increase-replication-factor.json --execute
驗證副本執行計劃
bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.27.101:9092 --reassignment-json-file increase-replication-factor.json --verify
此時105主機就承擔了一部分的副本存儲壓力,此時才正式服役。
退役舊節點
退役一臺節點時,直接再執行一次負載均衡計劃,比如退役105主機,105的broker.id=3
首先創建文件
vim topics-to-move.json
{"topics":[{"topic":"first"}],"version":1
}
執行生成負載均衡計劃命令,只為0,1,2生成負載均衡計劃,系統會生產一個負載均衡計劃
bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.27.101:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate
查看生成的計劃,如果滿足要求,那么復制計劃,并將復制的計劃粘貼到文件increase-replication-factor.json中
vim increase-replication-factor.json
執行副本存儲計劃
bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.27.101:9092 --reassignment-json-file increase-replication-factor.json --execute
驗證副本執行計劃
bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.27.101:9092 --reassignment-json-file increase-replication-factor.json --verify
此時105主機就可以直接停止進行退役。
副本
Kafka使用副本來提高數據可靠性,kafka默認使用一個副本,但是在生產環境中一般配置兩個,保證數據可靠性。副本不是越多越好,會增加磁盤存儲空間,增加網絡中的數據傳輸,降低效率。
Kafka副本中分為Leader和Follower,Kafka生產者只會把數據發往Leader,然后Follower主動找Leader同步數據。
Kafka分區中的所有副本統稱為AR(Assigned Repllicas)
AR=ISR+OSR
ISR:能夠和Leader保持同步的Follower集合,ISR包含Leader本身,如果Follower長時間未向Leader發送通信請求或者同步數據,那么該Follower就會被踢出ISR。該時間閾值由replica.lag.time.max.ms參數設定,默認30s,Leader發生故障之后就會從ISR中選舉新的Leader。
OSR:表示在Follower與Leader同步時,延遲過多的副本。
Leader的選舉流程

如圖所示,Leader的選舉由AR中的順序以及是否在ISR存活決定。
Follower故障處理
LEO:每個副本的最后一個offset,LEO其實就是最新的offset + 1。
HW:所有副本中最小的LEO
實際上HW就是記錄一個消息的偏移量,在這個消息之前的所有消息是Leader以及所有正常的Follower都有的消息。
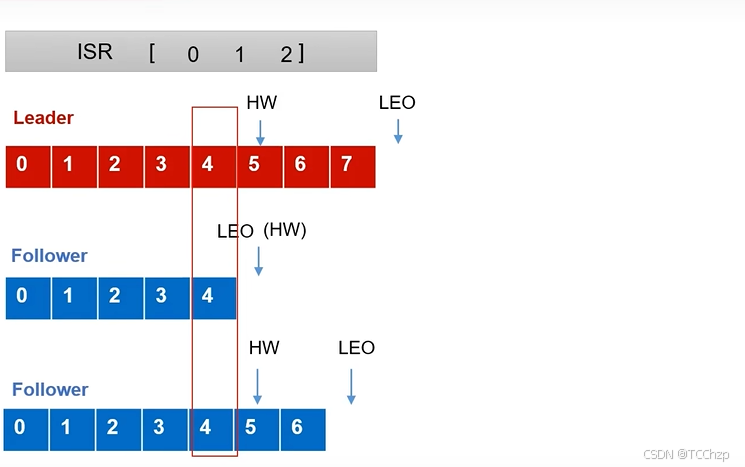
當Followers故障時:
- Followers會被臨時踢出ISR
- 這個期間Leeder和Follower會繼續接收數據
- 當Follower恢復之后,Follower會讀取本地磁盤記錄的上次HW,并且將文件高于HW的部分截取掉,然后從HW開始向Leader進行同步
- 當重新恢復的Follower的LEO大于等于該Partiton的HW時,就代表Follower已經基本同步了Leader的數據,可以重新加入ISR
Leader故障處理
故障處理也跟LEO、HW相關
當Leader故障時:
- 首先將Leader踢出ISR隊列,并從ISR隊列選出一個新的Leader
- 為了保證數據在各個副本中一致(數據可能會丟失或者重復),其余的Follower各自將高于HW的部分截掉,然后從新的Leader處同步數據。
分區副本分配
Kafka會為盡量均勻的分配副本在節點上,增強數據的安全性、可靠性。但是我們可以跟之前服役和退役一樣,來手動設置分區副本的分配。
正常情況下,Kafka會自動把LeaderPartition均勻分散在各個機器上,來保證每臺機器的讀寫吞吐量都是均勻的,但是如果因為某些Broker宕機,會導致Leader Partition過于集中在其他少部分幾臺的Brokers上。導致其他機器請求讀寫壓力過高。而宕機的Leader重啟之后就成了Follower Partition,讀寫請求很低,造成集群負載不均衡
文件存儲機制
Topic是邏輯上的概念,而Partiton是物理上的概念,每個Partition對應一個log文件,該log文件中存儲的是Producer生產的數據。Producer生產的數據會不斷的追加到log文件末端,為防止log文件過大導致數據定位效率低下,因此Kafka采取了分片和索引機制,將每個Partition分為多個Segment。每個Segment包括,“.index"偏移量索引文件、”.log"日志文件和".timeindex"時間戳索引文件等文件,這些文件位于一個以topic名稱+分區序號為命名規則的文件夾下。


如果需要查看文件內容,那么可以通過kafka的命令進行查看。
[root@centos101 first-0]# kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index
Dumping ./00000000000000000000.index
offset: 0 position: 0
index為稀疏索引,大約每往log文件寫入4kb數據,會往index文件寫入一條索引。參數log.index.interval.bytes默認為4kb
index文件中保存的offset為相對offset,這樣能確保offset的值所占空間不會過大,因此能將offset的值控制在固定大小
Kafka文件清除策略
Kafka默認的日志保存時間為7天,可以調整以下參數修改保存時間
- log.retention.hour (最低優先級)小時,默認七天
- log.retention.minutes 分鐘
- log.retention.ms (最高優先級)毫秒
- log.retention.check.interval.ms 負責設置檢查周期,隔一段時間檢測是否過期,默認5分鐘
日志保存時間和檢查周期要進行搭配配置,不然檢查周期過長就起不到效果。
Kafka提供的日志清理策略log.cleanup.policy有兩種:delete以及compact兩種
Delete
- 基于時間:默認開啟,以segment中所有記錄的最大時間戳作為該文件的過期時間戳,也就是segment中最晚過期的記錄過期,才會清除這個segment
- 基于大小:默認關閉,超過設置的所有日志總大小,刪除最早的segment。log.retention.bytes,默認為-1,表示無窮大
Compact
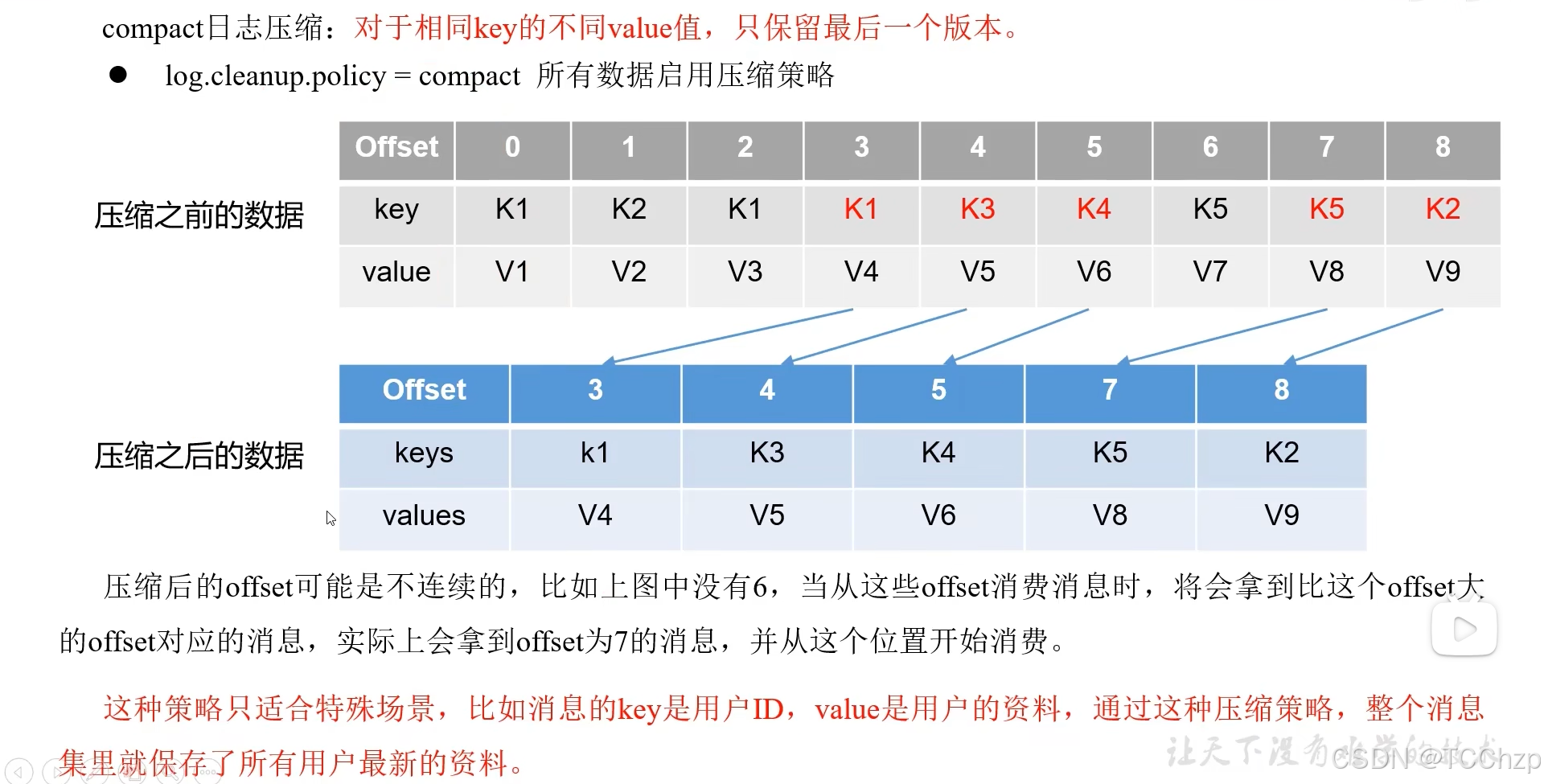
compact日志壓縮:對于相同的key的不同value值,只保留最后一個版本。開啟該策略只需修改log.cleanup.policy = compact.
Kafka高效讀寫數據
-
Kafka本身是分布式集群,采用分區技術,并行度高
-
讀數據采用稀疏索引,可以快速定位要消費的數據
-
順序寫磁盤,寫入log文件時是一直追加到文件的末端,使用順序寫,減少了大量磁頭尋址的時間
-
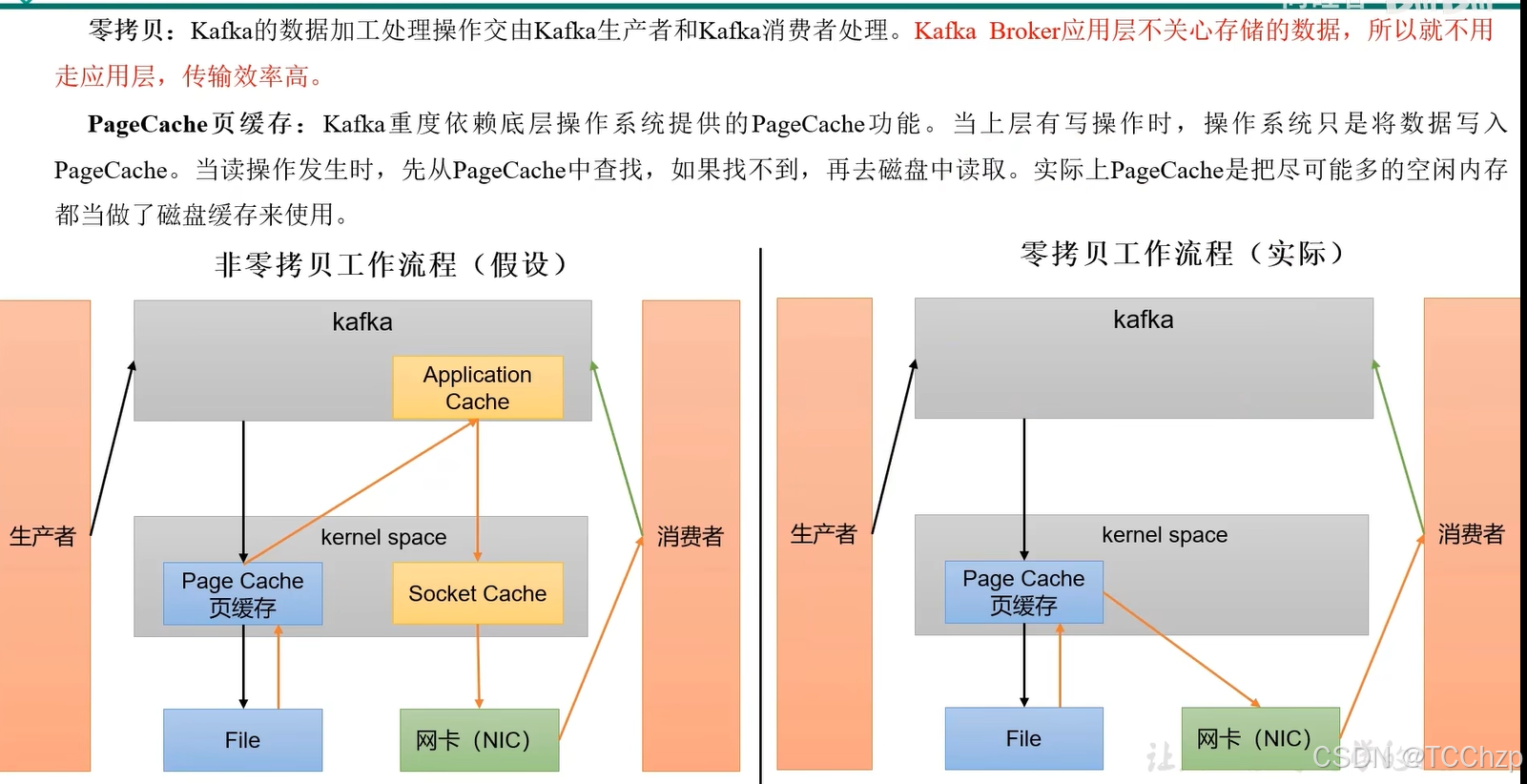
頁緩存+零拷貝技術
)
】使用UDTF時出現報錯“FlatEventUDTF cannot be resolved”)





原理與實踐)
)





)



)
