前言
截止到25年6.6日,在沒動我司『七月在線』南京、武漢團隊的機器的前提下,長沙這邊所需的前幾個開發設備都已到齊——機械臂、宇樹g1 edu、VR、吊架
- ?長沙團隊必須盡快追上南京步伐 加速前進
如上篇文章所說的,
為盡快 讓近期新招的新同事們,盡快具備對應的能力,我給新同事們 定了兩個目標,即老同事不做太多輔助的情況下,六月份之內
? 通過協作機械臂,完成疊衣服的任務,對于該任務,會先嘗試π0、dexvla
且我們長沙具身團隊目前還在持續擴人(之后是上海、武漢再分別擴員),目前已有來自華科、中南的,有意來我司全職或實習的,歡迎私我
而對于這兩個任務,我們遠遠不只是為了完成個任務而已,而是在疊衣服的過程中,會對比各種模型、方法、策略,畢竟針對各個場景始終尋找更優的解決方案,是我個人和我司的職責之一 - 因為具身訂單需求源源不斷,所以長遠來看,我們也有源源不斷的經費,支撐我們無止境的科研探索
故,最終凡是值得探索的,我們都會考慮,且我們也不想做誰誰誰,或某某中國版,而是——只做世界唯一
綜上,一方面因為疊衣服這個任務,二方面,因為無止境的科研探索,故關注到了本文所要介紹的DexWild
PS,當然,如果只是單純針對疊衣服這個任務,個人認為還是VLA會表現的更好些,下一篇文章會解讀HybridVLA
第一部分?DexWild:面向真實環境的靈巧人類交互機器人策略
1.1 引言與相關工作
1.1.1 引言
如原論文所說,近年來,收集機器人數據集
- 一種關鍵方法是通過遙操作,這種方式能夠提供高精度、高質量的動作數據,便于策略直接進行訓練
8-?Open X
21-Droid: A large-scale in-the-wild robot manipulation dataset
54-Bridgedata v2: A dataset for robot learning at scale
然而,獲取這些數據需要經過高度訓練的人類操作員,并依賴于專門的機器人設備。在多樣化環境中收集數據還面臨額外挑戰,例如需要將機器人實際轉移到每一個新環境
整個數據收集過程不僅勞動強度大,而且成本高昂,因此難以擴展到支持在未見環境下靈巧泛化所需的數據量 - 另一種擴展機器人數據集的方法是利用來自YouTube等平臺的互聯網級視頻數據,這些視頻為真實世界環境中的視覺基礎提供了豐富且多樣的資源
15-Ego4d: Around the world in 3,000 hours of egocentric video
10-Epic-kitchens: A large-scale dataset for recognizing, anticipating, and retrieving handobject interactions
然而,有效利用這些數據也面臨重大挑戰
首先,公開可用的視頻通常缺乏捕捉手部細節狀態所需的細粒度精度,因為基于視覺的身體檢測模塊往往噪聲大且不可靠
此外,這些視頻本身并沒有以任務為單位進行結構化分類——這進一步增加了其在機器人領域直接應用的復雜性
18-Toward general-purpose robots via foundation models: A survey and meta-analysis
1-Affordances from human videos as a versatile representation for robotics
40-Videodex: Learning dexterity from internet videos
雖然已經有一些數據采集工作能夠獲得更為準確和結構化的數據
60-Freihand: A dataset for markerless capture of hand pose and shape from single rgb images
2-Hot3d: Hand and object tracking in 3d from egocentric multi-view videos
但其環境多樣性仍然不足 - 為克服這些障礙,一些研究嘗試通過為用戶配備可穿戴式夾持器,將用戶的手部動作直接映射為機器人的動作,從而在自然環境中收集準確的人類演示數據 [7-umi]
然而,這種方法繁瑣,不適用于自然、日常的交互,并且數據的收集不得不限定在某個特定的具身形式下
其他研究 [55-dexcap] 提出了使用靈巧手和手套的方法

但這些方法無法擴展到自然環境中
1.1.2 相關工作
第一,對于模仿學習的泛化能力
- 機器人操作通用策略的學習取得了快速進展,這主要得益于視覺表征學習和基于大規模數據集的模仿學習的發展。在視覺領域,具身表征學習受益于如Ego4D [15] 和 EPIC-KITCHENS [10] 等第一人稱數據集,近期的方法
27-?R3M: A universal visual representation for robot manipulation
11-An unbiased look at datasets for visuomotor pre-training
47-?HRP: Human affordances for robotic pre-training
39-?Videodex: Learning dexterity from internet videos
利用這些數據集訓練可擴展的視覺編碼器 - 然而,這些方法在訓練控制策略時,仍然需要大量的下游機器人示范數據。與此同時,僅由機器人演示的數據集在規模和多樣性方面顯著增長
21-Droid: A large-scale in-the-wild robot manipulation dataset
8- Open X
54-?Bridgedata v2: A dataset for robot learning at scale
推動了行為克隆的研究,并促進了通用策略架構的發展
49-?Octo
8-?Open X
22-?Openvla
盡管這些策略在許多任務中展現出令人印象深刻的性能,但它們往往難以泛化到未見過的物體類別、場景布局或環境條件 [25- What matters in learning from offline human demonstrations for robot manipulation]
總之,這種魯棒性的不足仍然是當前系統的一個關鍵限制
第二,對于機器人操作的數據生成
克服機器人數據瓶頸已成為機器人學習領域的核心挑戰
- 一種方法利用互聯網視頻來提取動作信息。已有多項研究,如 VideoDex [40] 和 HOP [42],通過重定向大規模人體視頻來學習動作先驗,并以此推動策略訓練
- 另一些方法,如 LAPA [57],則利用無標簽視頻生成可用于下游任務的潛在動作表征。盡管這些基于視頻的方法具有豐富的視覺多樣性,但通常難以捕捉到實際操作所需的精確、低層次運動指令
- 仿真能夠快速大規模生成動作數據,然而,為眾多任務創建多樣且逼真的環境,并解決仿真到現實的差距,仍然充滿挑戰
近年來,將操作策略從仿真遷移到現實的研究已取得一定成功 [43-Dextrah-rgb: Visuomotor
policies to grasp anything with dexterous hands],但主要局限于桌面場景,缺乏在多樣環境中部署所需的泛化能力。直接在實體機器人上進行遠程操作雖然能獲得最高的保真度,但難以擴展 - 近期的研究在固定場景下展現了令人印象深刻的靈巧性和高效學習能力
59-ALOHA
56-Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators
41-??Bimanual dexterity for complex tasks
19-?OPEN TEACH: A versatile teleoperation system for robotic manipulation
OPEN TEACH基于Meta Quest 3,用戶能夠實時控制各種機器人,包括多指手和雙手手臂。用戶可以通過自然的手勢和動作以高達 90Hz 的頻率操控機器人,并獲得流暢的視覺反饋和提供近距離環境視圖的界面小部件
與 AnyTeleop 框架相比,其遠程操作能力顯著提升。進一步的實驗表明,所收集的數據與 10 個靈巧且接觸豐富的操作任務的策略學習兼容。OPEN TEACH 目前支持 Franka、xArm、Jaco 和 Allegro 平臺
然而,要收集足夠多的演示以實現對多樣場景的泛化,成本很快就會變得極其高昂
近年來,越來越多的研究利用專門采集的高質量人體具身數據,而無需繁瑣的遠程操作
第三,對于人體動作追蹤系統
- 為了獲取高質量的人體動作數據,手部和手腕的精確追蹤至關重要。為避免手部姿態估計的復雜性,一些研究讓用戶手持機器人夾持器
7-UMI
12-Robot utility models: General policies for zero-shot deployment in new environments
46-?Grasping in the wild: Learning 6dof closedloop grasping from low-cost demonstrations
這種方法雖然簡化了動作重定向,但也限制了用戶只能適應機器人夾持器的特定結構,從而減少了所能捕捉行為的多樣性 - 此外,許多此類系統依賴于基于SLAM的手腕追蹤,但在特征稀疏的環境或出現遮擋時(如打開抽屜或使用工具時)
7-UMI
23-?Data scaling laws in imitation learning for robotic manipulation
這種方法可能會失效 - 其他方法旨在直接從視覺輸入中估算手部和手腕的姿態
29-Reconstructing hands in 3d with transformers.
35-Frankmocap: A monocular 3d whole-body pose estimation system via regression and integration
5-?Open-television
45-Robotic telekinesis: Learning a robotic hand imitator by watching humans on youtube
28 -?Hamer: Hand mesh recovery for the egoexo4d hand pose challenge
20 -?Egomimic: Scaling imitation learning via egocentric video
32 -?Humanoid policy ? human policy
這些方法易于部署且無需額外設備,但在遮擋——操控過程中不可避免的情況——下,其性能會顯著下降 - 針對手腕追蹤的替代策略,如
基于IMU的方法
9-Hybrid tracking of human operators using imu/uwb data fusion by a kalman filter
50-Upper limb motion tracking with the integration of imu and kinect
和
外部光學系統
30-?Comparative abilities of microsoft kinect and vicon 3d motion capture for gait analysis
但也各有局限
IMU輕便便攜,但易產生漂移;而光學系統精度高,卻需要繁瑣的校準和受控環境
DexWild利用無需校準的Aruco追蹤,大幅提升了可靠性并最小化了設置時間,僅需單目相機即可實現。雖然基于視覺的方法通常嘗試同時追蹤手腕和手指,許多最新系統則將兩者解耦以提升精度 - 運動學外骨骼手套能夠提供高保真度的關節測量,甚至實現觸覺反饋[58-Doglove: Dexterous manipulation with a low-cost open-source haptic force feedback glove],但體積龐大,長期佩戴不舒適
DexWild 與先前的工作 [41-Bimanual dexterity for complex tasks,55-Dexcap] 一樣,采用了一種輕量級的基于手套的解決方案,利用電磁場(EMF)傳感來估算指尖位置

這種方法能夠實現對遮擋具有魯棒性的高精度、實時手部追蹤,并且可以方便地適配到各種類型的機器人手上
1.2?DexWild的完整方法論
1.2.1?數據采集系統:可移植、高保真
一個可擴展的數據采集系統,用于靈巧機器人學習,必須能夠在多樣化環境中實現自然、高效且高保真的數據采集
為此,作者設計了DexWild-System:這是一個便攜且用戶友好的系統,能夠以最少的設置和培訓,捕捉人類的靈巧操作行為
以往的野外數據采集方法通常依賴于帶有傳感器的機械手,但作者的目標是創造一種更為直觀的硬件接口,以更貼近人類自然與世界交互的方式。從精細的微操作到有力的抓握,人類在廣泛的操作任務中展現出靈巧性
DexWild-System 的設計圍繞三個核心目標展開:
- 便攜性:能夠在不同環境中快速、大規模地采集數據,無需復雜的校準流程
- 高保真度:精確捕捉手部與環境之間的細粒度交互,這對于訓練高精度的靈巧操作策略至關重要
- 與具體實現無關:實現從人類演示到各種機器人手的無縫重定向
對于可移植性:為了在多樣化的真實環境中采集數據,系統必須具備可移植性、魯棒性,并且任何人都能使用。作者以這些目標為導向設計了DexWild-System:該系統重量輕,便于攜帶,幾分鐘內即可完成搭建,從而支持在多個地點進行大規模數據采集
如下圖圖2所示,DexWild-System僅由三個組件組成:
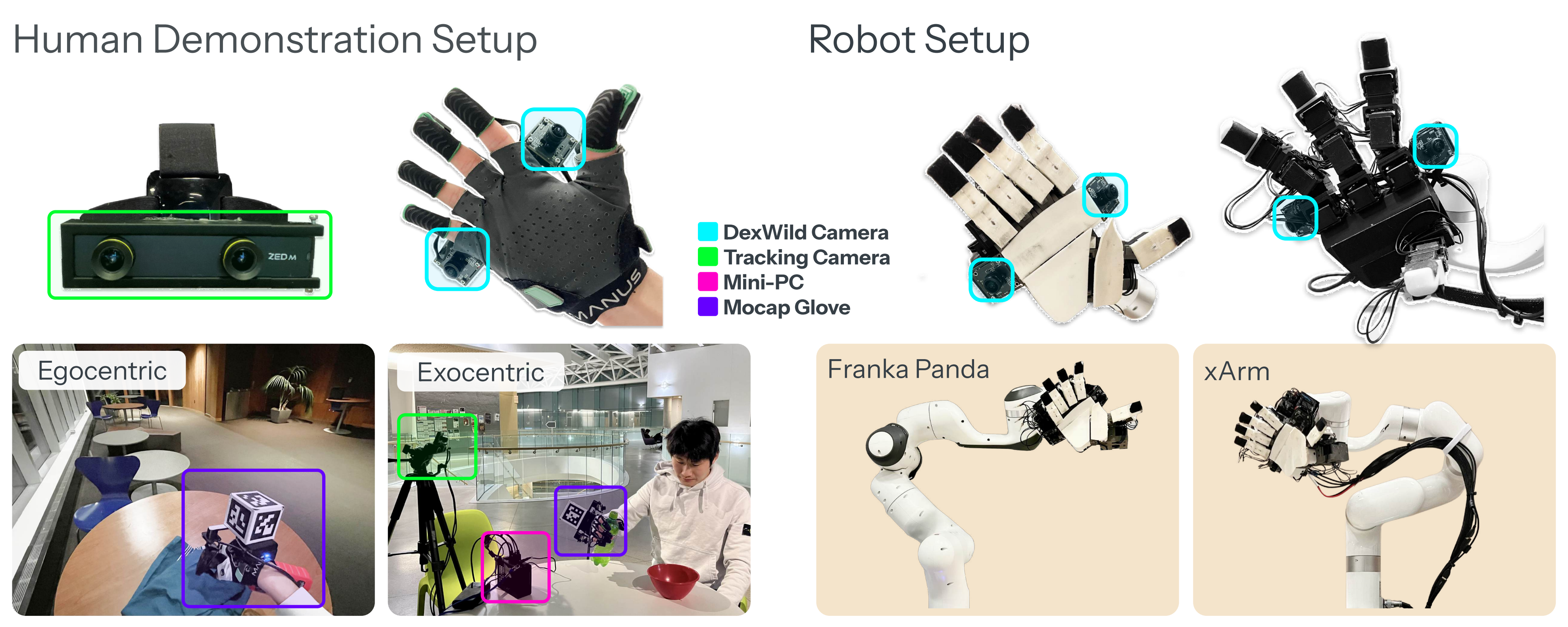
- 用于手腕姿態估計的單一跟蹤攝像頭
- 用于機載數據采集的電池供電迷你電腦
- 以及由動作捕捉手套和同步掌面攝像頭組成的定制傳感器模塊
與傳統的動作捕捉系統
- 60-Freihand: A dataset for markerless capture of hand pose and shape from single rgb images
- 13-?Arctic: A dataset for dexterous bimanual handobject manipulation
- 4-Dexycb:A benchmark for capturing hand grasping of objects
- 52-Valve Corporation. https://store.steampowered.com/steamvr
通常依賴于復雜的外部跟蹤設備并需要校準不同,DexWild-System 真正實現了免校準,因此在任何場景下都具有高度適應性,并且對未經訓練的操作者也非常友好
- 這一優勢通過采用相對狀態-動作表示來實現,其中每個狀態和動作都表示為相對于前一時刻姿態的變化
這種方式消除了對全局坐標系的需求,使得跟蹤攝像頭可以自由放置——無論是以自我為中心還是以外部為中心 - 此外,手掌攝像頭被剛性地固定安裝在人體和機器人兩種形態上。這保證了視覺觀測在不同領域間的對齊,從而在部署時無需進一步校準
外部跟蹤攝像頭在精心布置后,還能捕捉有助于學習魯棒策略的補充環境信息
對于高保真,為了學習靈巧的行為,訓練數據集中必須捕捉到細致入微、精細化的動作。盡管 DexWild-System僅由少量便攜組件組成,作者在數據保真度上絕不妥協
他們宣稱,他們的系統專為精確捕捉手部與腕部動作而設計,并配合高質量的視覺觀測數據
- 對于手腕和手部跟蹤,純視覺方法易于部署
然而,這些方法在便攜性上有所提升的同時,往往犧牲了精度和魯棒性,導致姿態估計結果較為噪聲,從而影響策略學習的效果
41-Bimanual dexterity for complex tasks
14-?Open-television
32-Humanoid policy ?human policy
7-UMI - 故在手部姿態估計方面,作者采用動作捕捉手套,其具有高精度、低延遲以及對遮擋的強魯棒性 [41-Bimanual dexterity for complex tasks]
對于手腕跟蹤,作者在手套上安裝了 ArUco 標記,并通過外部攝像頭進行跟蹤
該方法避免了基于 SLAM 的手腕跟蹤易受損壞的問題,因為 SLAM 在特征稀疏的環境或遮擋嚴重的任務(如抽屜開啟)中常常失效
且與許多依賴于第一人稱或遠距離外部攝像頭的數據集不同,作者將兩臺全局快門攝像頭直接安裝在手掌上
如圖2所示
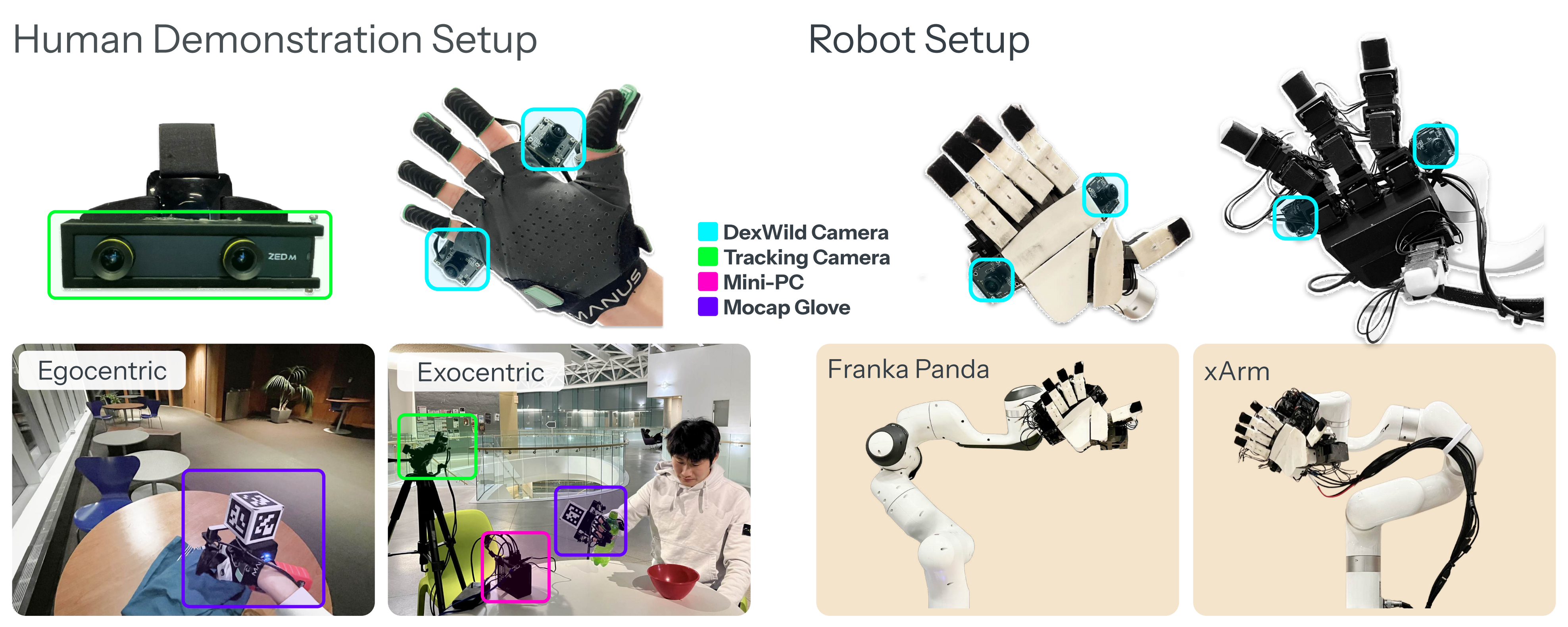
這組立體攝像頭能夠以極小的運動模糊和寬廣的視野,捕捉到細致且局部化的交互畫面。如此寬廣的視野使得策略僅需依賴手掌上的攝像頭即可運行,無需依賴任何靜態視角
對于與具體體態無關的特點,具體而言,為了確保DexWild數據的持久性和多樣性,作者的目標是使其在不同機器人實體中依然具有實用價值——即便硬件平臺不斷演進
要實現這一目標,必須對人類與機器人之間的觀測空間和動作空間進行精確對齊
- 作者首先對觀測空間進行標準化。盡管系統掌上攝像頭使得具有廣闊的視野,但作者有意將其定位為主要聚焦于環境,從而最大程度地減少手部本身的可見性
重要的是,相機在人體手和機器人手之間的位置是對稱設置的。如圖3所示
這一設計在不同實體之間產生了視覺上一致的觀測結果,使策略能夠學習可在人體和機器人領域泛化的共享視覺表征
且為了實現動作空間對齊,作者借鑒了先前工作的見解
17-Dexpilot: Vision-based teleoperation of dexterous robotic hand-arm system
44-Robotic telekinesis: Learning a robotic hand imitator by watching humans on youtube
通過優化機器人手部運動學,使其指尖位置與人類演示中觀察到的位置相匹配
他們指出,這種方法具有通用性,適用于任何機器人手的實現形式。該方法對所有用戶采用固定的超參數,并且對手部尺寸的變化具有較強的魯棒性,無需針對特定用戶進行調整。使用自然人手進行數據采集不僅僅具有易用性的優勢
由于不同人類演示者的手部形態各異,這種多樣性帶來了有益的變化,作者推測這有助于策略學習到更具泛化能力的抓取方法——這一點尤為重要,因為人類與機器人手部運動學之間本質上存在差異 - 總之,DexWild 是一款便攜式、高質量、以人為中心的系統,任何操作員都可以佩戴它,在真實環境中收集人體數據
1.2.2?訓練數據模態與預處理
靈巧操作中的泛化既需要規模,也需要具身基礎。為此,DexWild 收集了兩類互補的數據集:
- 一個大規模的人類示范數據集
,通過DexWild-System 采集
- 以及一個較小的遙操作機器人數據集
人類數據在現實環境中易于采集且任務多樣性廣,但缺乏具身對齊。機器人數據雖然規模有限,卻為機器人的動作和觀測空間提供了關鍵的具身基礎
為了結合兩者的優勢,作者在一個批次內以固定比例聯合訓練策略,在多樣性與具身基礎之間取得平衡,從而在部署時實現穩健的泛化能力
在每次訓練迭代中,作者根據協同訓練權重分別從 和
中采樣一批包含轉移
和
的數據。每個在時間步
?的轉移
包含
- 觀測
:在給定時間步的觀測由兩張同步的手掌相機圖像
和
組成,這兩張圖像在當前時間步采集
并且還包括一個歷史狀態序列,該序列以給定步長在時間范圍內采樣,由
組成,每個
?包含相對的歷史末端執行器位置
- 動作
:大小為
的動作片段,包括動作
,其中
是當前時間步的動作
具體來說,
:一個9 維向量,描述相對末端執行器的位置(3D)和姿態(6D)
:一個17 維向量,描述機器人手指關節的位置目標
對于雙手任務,觀測空間和動作空間均被復制,并且在觀測中附加了雙手之間的姿態信息,以促進協作
雖然他們的重定向過程將人類和機器人軌跡映射到統一的動作空間,但為了使人類和機器人數據集能夠共同訓練,還需要進行以下幾個額外步驟:
- 動作歸一化:針對人類和機器人數據的動作分別進行歸一化處理,以彌補其固有的分布不匹配問題
- 演示過濾:由于人類演示數據由未經訓練的操作者在非受控環境中采集,作者采用基于啟發式的過濾流程,自動檢測并移除低質量或無效的軌跡。該過濾步驟在無需人工標注的情況下,顯著提升了數據集的質量
1.2.3?策略訓練:ViT +?擴散U-Net模型
通過對硬件、觀測和動作接口的精心設計,能夠利用簡單的行為克隆(BC)目標 [31,37,36] 來訓練靈巧機器人的策略
為了有效地從多模態、多樣化數據中學習,他們的訓練流程利用了大規模預訓練的視覺編碼器,并在不同的策略架構下展現出強大的性能
- 視覺編碼器:在 DexWild 數據上的訓練使得對應的策略面臨場景、物體和光照等方面的顯著視覺多樣性,因此需要一個能夠很好泛化到這種多變性的編碼器
為此,作者采用了預訓練的 VisionTransformer(ViT)主干網絡,該網絡在野外操作任務中相較于基于 ResNet 的編碼器表現出更優異的性能[16,23]
總之,預訓練的 ViT,尤其是在大規模互聯網數據集上訓練的模型,在提取豐富且可遷移的特征方面尤為有效 [27,33,47,11],因此非常適合本文的應用場景 - 策略類別:盡管近期已經提出了多種模仿學習架構[59,6],作者采用了一種基于擴散模型的策略。擴散模型特別適用于靈巧操作任務,因為它們能夠捕捉多模態動作分布,相較于高斯混合模型(GMMs)或transformer等替代方法,其表現更為出色
這一能力在DexWild中變得尤為重要,因為演示數據來自多位人類,策略多樣,導致行為本質上呈現多模態。隨著數據集規模的擴大,建模這種變異性對于實現魯棒的策略學習至關重要
DexWild采用擴散U-Net模型[6]來生成動作片段
具體而言,訓練過程如算法1所示

// 待更
1.3 實驗
// 待更
】使用UDTF時出現報錯“FlatEventUDTF cannot be resolved”)





原理與實踐)
)





)



)

