你是否有過這樣的經歷?
精心配置了 Kubernetes 的 Pod,設置了“剛剛好”的 CPU 和內存(至少你當時是這么想的),結果應用不是資源緊張喘不過氣,就是像“雙十一”搶購一樣瘋狂搶占資源。
過去,唯一的解決辦法就是重啟整個 Pod?——這種破壞性的做法就像用黃油刀做開胸手術,而 SRE 團隊正透過手術室的窗戶盯著看,緊張但無能為力。
不過,近期發布的 Kubernetes 1.33 版本帶來了我們夢寐以求的功能:原地 Pod 垂直伸縮(In-place Pod Vertical Scaling)。
在 Kubernetes 1.33 中該功能已升級為 Beta 版,并且默認啟用。你不再需要手動啟用特性,這使得它在生產環境中更加易用
(可查閱 Kubernetes 官方文檔:https://kubernetes.io/docs/tasks/configure-pod-container/resize-container-resources/)。
這意味著你可以調整正在運行的 Pod 的 CPU 和內存配置,而無需重啟。
如果你一直在琢磨垂直自動伸縮(VPA)的細節,那么這次更新會令人格外興奮——雖然 VPA 的“重新創建”模式在理論上很美好,但實操過程中常常狀況百出。
原地 Pod 垂直伸縮提供了一種更加優雅的資源調整方式,或許能讓 VPA 的體驗更加順滑。
01/為什么這項更新如此重要?
對 Kubernetes 用戶來說,這是一項革新式的重要更新。
假設當應用突然遇到流量激增的高峰期時,過去的做法是要么預留大量資源,但成本很高;要么觸發 VPA 更新,導致 Pod 重啟。而現在,通過這項更新可以直接實時增加 CPU 和內存配置,不會造成應用卡頓,用戶側幾乎無感。
尤其對于那些有狀態應用、數據庫,或要求持續可用性的服務而言,原地擴縮容能大幅降低宕機時間,提供更加無縫的彈性伸縮體驗。
為什么這項特性能實現這一效果?讓我們來簡單分析一下:
- 告別 Pod重啟?: 過去每次調整資源,服務是否宕機全看運氣。VPA 會像一個過于熱情的保安一樣把 Pod 趕下線。現在呢?擴容絲滑得像咖啡師拉花。
- 成本優化魔法?: 不再需要為了“以防萬一”的情況,而過度配置資源。正如 Sysdig 團隊指出的,這實現了真正的按需付費云經濟。
- 拯救有狀態工作負載 :?數據庫不再需要在“性能”與“可用性”之間做選擇了。這就像在行駛的汽車上換輪胎 ——雖然有風險,但現在已經可行!
02/實際應用場景
以下是一些具體的應用場景,從中可以窺見這一功能的實用性:
- 數據庫工作負載?當你的 PostgreSQL 實例突然需要更多 RAM 來處理營銷部門的數據分析的請求時,你可以在不中斷正在進行的交易或清空連接池的情況下擴展資源。用戶再也不會看到“請稍后再試”的消息了!
- Node.js API 服務?Node.js 應用可以在無需重啟的情況下動態使用新增的 CPU 和內存。因此非常適合使用原地擴縮容來應對流量激增。
- 機器學習推理服務?TensorFlow Serving 等服務在處理更大批量或更復雜模型時,可以實時擴容,無需中斷正在進行的推理請求。
- 服務網格 Sidecar?在 Istio 之類的服務網格中, Envoy 代理現在可以根據流量模式動態調整資源,而不會干擾主應用容器的運行。
關于 Java 應用的提醒:
對于基于 JVM 的應用,僅僅調整 Pod 的內存配置并不會自動改變 JVM 的堆(heap)大小,后者通常是在啟動時通過-Xmx等參數設置的。雖然原地 Pod 調整可以優化非堆內存和 CPU 資源的使用,但如果想要充分利用擴容后的內存限制,Java應用通常需要調整配置并重啟。因此,對于不希望重啟的場景來說,Java 應用并不適合進行內存擴容。
03/技術揭秘:Kubernetes 如何靈活調整資源
接下來,讓我們深入探討技術細節,下圖展示了 K8s 資源調整的工作流程:
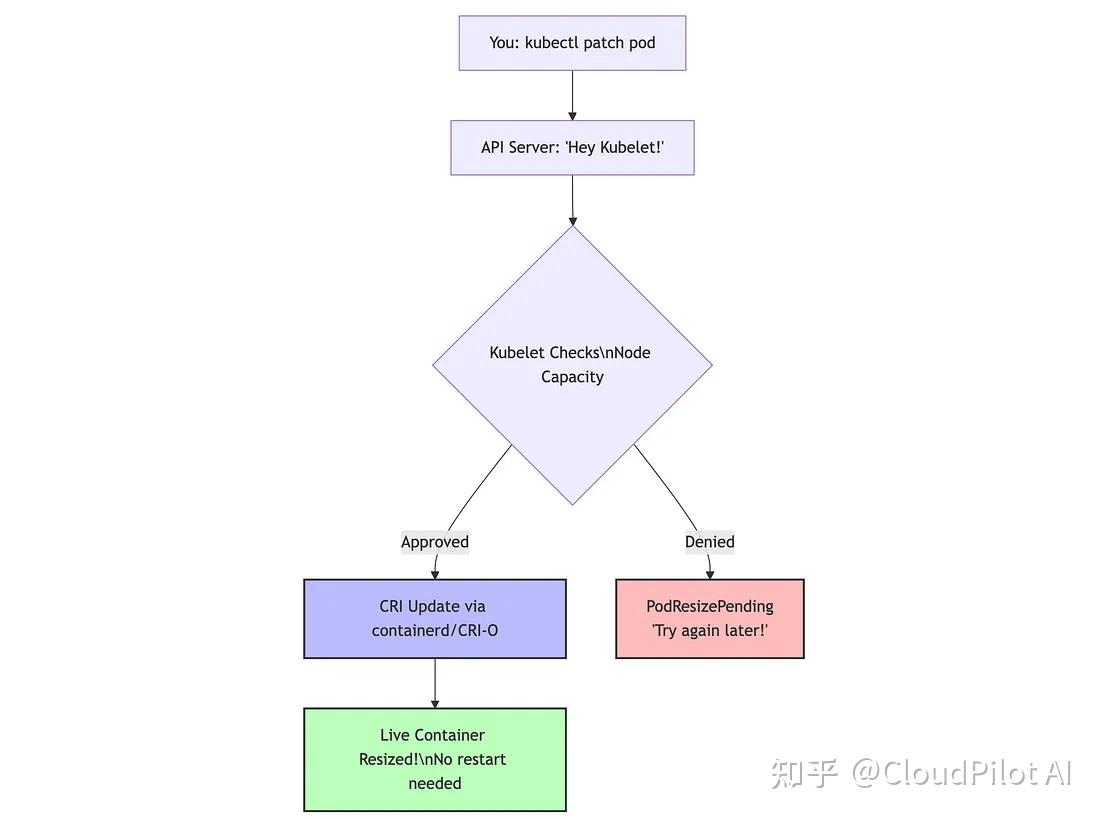
實際發生了什么
- 可變資源字段已支持動態更新?得益于這個 issue (https://github.com/kubernetes/enhancements/issues/1287),Pod 規范中的
resources.requests?和?resources.limits?字段現在支持動態修改,無需再為 Spec 是否不可變而爭論了。 - Kubelet 的評估機制?當你提交 patch 時,kubelet 會評估:(
節點可用資源總量) - (當前所有容器資源分配總和) ≥ (新請求資源)?滿足條件就允許變更,否則就返回?PodResizePending。 - CRI 協議握手?kubelet 會通過容器運行時接口 (CRI) 與 containerd 或 CRI-O 通信:“給這個容器加點資源”。運行時隨后會調整對應的 cgroup,無需重啟,輕松搞定。這是異步、非阻塞的流程,Kubelet 可以在處理資源調整的同時繼續執行其他重要任務。
- 狀態更新提示?在執行
kubectl describe pod時,你會看到兩個新狀態: - PodResizePending —— “節點當前資源不足,稍后再試。”
- PodResizeInProgress —— “正在處理,資源調整中。”
容器運行時兼容性
這一功能在不同的容器運行時中均可使用,但支持程度有差異,情況如下:
- containerd(v1.6+):完全支持,可以平滑調整 CPU 和內存的 cgroup
- CRI-O(v1.24+):完全支持原地擴縮容
- Docker:支持有限,因為它正在逐步退出 Kubernetes
注意:cgroup v2 在內存回收方面比 cgroup v1 更強大,特別是對于內存限制減少的情況下。
04/上手實踐:安全地搞點事情
讓我們通過一個簡單的演示來展示原地 Pod 調整的實際效果,你可以從 Kubernetes API 和 Pod 內部同時查看資源變更。
整個演示運行在 GKE 的 Kubernetes 1.33 上。
- 創建一個資源監控 Pod
首先創建一個持續監控自身資源分配的Pod:
kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:name: resize-demo
spec:containers:- name: resource-watcherimage: ubuntu:22.04command:- "/bin/bash"- "-c"- |apt-get update && apt-get install -y procps bcecho "=== Pod Started: $(date) ==="# Functions to read container resource limitsget_cpu_limit() {if [ -f /sys/fs/cgroup/cpu.max ]; then# cgroup v2local cpu_data=$(cat /sys/fs/cgroup/cpu.max)local quota=$(echo $cpu_data | awk '{print $1}')local period=$(echo $cpu_data | awk '{print $2}')if [ "$quota" = "max" ]; thenecho "unlimited"elseecho "$(echo "scale=3; $quota / $period" | bc) cores"fielse# cgroup v1local quota=$(cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us)local period=$(cat /sys/fs/cgroup/cpu/cpu.cfs_period_us)if [ "$quota" = "-1" ]; thenecho "unlimited"elseecho "$(echo "scale=3; $quota / $period" | bc) cores"fifi}get_memory_limit() {if [ -f /sys/fs/cgroup/memory.max ]; then# cgroup v2local mem=$(cat /sys/fs/cgroup/memory.max)if [ "$mem" = "max" ]; thenecho "unlimited"elseecho "$((mem / 1048576)) MiB"fielse# cgroup v1local mem=$(cat /sys/fs/cgroup/memory/memory.limit_in_bytes)echo "$((mem / 1048576)) MiB"fi}# Print resource info every 5 secondswhile true; doecho "---------- Resource Check: $(date) ----------"echo "CPU limit: $(get_cpu_limit)"echo "Memory limit: $(get_memory_limit)"echo "Available memory: $(free -h | grep Mem | awk '{print $7}')"sleep 5doneresizePolicy:- resourceName: cpurestartPolicy: NotRequired- resourceName: memoryrestartPolicy: NotRequiredresources:requests:memory: "128Mi"cpu: "100m"limits:memory: "128Mi"cpu: "100m"
EOF2. 查看 Pod 的初始狀態
從 Kubernetes API 的角度查看 Pod 的資源:
kubectl describe pod resize-demo | grep -A8 Limits:你會看到類似以下輸出:
Limits:cpu: 100mmemory: 128MiRequests:cpu: 100mmemory: 128Mi現在,看看 Pod 自身如何看待它的資源:
kubectl logs resize-demo --tail=8輸出中會包含容器視角的 CPU 和內存限制。
3. 無縫調整 CPU
讓我們在不重啟的情況下將 CPU 加倍:
kubectl patch pod resize-demo --subresource resize --patch \'{"spec":{"containers":[{"name":"resource-watcher", "resources":{"requests":{"cpu":"200m"}, "limits":{"cpu":"200m"}}}]}}'檢查調整狀態:
kubectl get pod resize-demo -o jsonpath='{.status.conditions[?(@.type=="PodResizeInProgress")]}'注意:在 GKE 的 Kubernetes 1.33 上,你可能看不到PodResizeInProgress狀態,即使調整操作已經成功。如果kubectl get pod resize-demo -o jsonpath='{.status.conditions}'沒有顯示調整信息,請直接檢查實際資源。
調整完成后,從 Kubernetes API 查看更新后的資源:
kubectl describe pod resize-demo | grep -A8 Limits:并驗證 Pod 現在看到的 CPU 限制:
kubectl logs resize-demo --tail=8你會注意到 CPU 限制從100m翻倍到200m,而 Pod 沒有重啟!Pod 的日志會顯示 cgroup 的 CPU 限制從大約10000/100000變為20000/100000(表示從 100m 到 200m 的 CPU)。
4. 無痛調整內存
現在,讓我們將內存分配加倍:
kubectl patch pod resize-demo --subresource resize --patch \'{"spec":{"containers":[{"name":"resource-watcher", "resources":{"requests":{"memory":"256Mi"}, "limits":{"memory":"256Mi"}}}]}}'稍等片刻后,從 API 驗證:
kubectl describe pod resize-demo | grep -A8 Limits:從 Pod 內部查看:
kubectl logs resize-demo --tail=8你會看到內存限制從 128Mi 變為 256Mi,而容器沒有重啟!
5. 驗證是否重啟
確認在調整過程中容器從未重啟:
kubectl get pod resize-demo -o jsonpath='{.status.containerStatuses[0].restartCount}'輸出應該是0——證明我們實現了無需服務中斷就能調整資源需求。
6. 清理資源
檢驗完成后:
kubectl delete pod resize-demo搞定!你已經成功地在不重啟?Pod 的情況下原地調整了 CPU 和內存資源。
這種模式適用于任何容器化應用,除了設置適當的resizePolicy外,不需要任何特殊配置。
05/云廠商支持情況
在進行生產環境的嘗試之前,先看看各大 Kubernetes 服務商的支持情況:
- Google Kubernetes Engine (GKE):在 GKE 的 Rapid 渠道中提供支持
- Amazon EKS:Kubernetes 1.33 版本預計將于 2025 年 5 月發布。
- Azure AKS:Kubernetes 1.33 版本現已提供預覽
- 自建集群:只要運行 Kubernetes 1.33+ 并使用 containerd 或 CRI-O 運行時,完全支持
06/局限性:功能雖然強大,但也有邊界
盡管這個功能很酷,但請記住以下幾點:
平臺和運行時限制
- Windows用戶暫不支持:目前僅限Linux
- 某些節點級 Pod 不支持:如果節點啟用了靜態 CPU 或內存管理器(如 CPU 靜態管理器策略),則該節點上的 Pod 將不支持原地擴縮容
- 容器運行時要求:需要 containerd v1.6+ 或 CRI-O v1.24+ 才能提供完整支持
資源管理限制
1.?QoS 類別不可更改:
Pod的原始服務質量等級(Guaranteed/Burstable/BestEffort)保持不變。無法通過調整將BestEffort升級為Guaranteed。
2. 目前只支持 CPU 和內存:
想動態調整 GPU 或臨時存儲?暫時還做不到。目前僅支持 CPU 和內存的原地調整。
3. 內存縮容需謹慎:
- 在不重啟容器的情況下降低內存限制,就像炸彈——理論上可行,實際上極危險。
- 建議你設置?
restartPolicy: RestartContainer以免場面失控。這在使用 cgroup v1 的系統中尤其關鍵。
4. Swap 使用限制:
如果 Pod 開啟了 Swap 功能,那你就無法動態調整內存,除非將內存的?resizePolicy?設置為?RestartContainer。
5. 資源無法移除:
一旦設置了資源 request 或 limit,就不能通過原地調整將其刪除,只能修改數值。
配置和集成限制
1. 并非所有容器都適用
-
- ?初始化容器和臨時容器不支持,這些一次性啟動的容器無法使用此功能,因為他們本身就無法重啟。
- ?支持 Sidecar 容器:如果你喜歡用 Sidecar 模式,Sidecar 容器和主容器一樣,支持原地進行資源調整,互不打擾。
2.?resizePolicy不可更改:
一旦 Pod 創建,就無法更改其resizePolicy。所以請慎重選擇,這是資源配置關系里的“從一而終”。
3. 特定應用限制:
如前所述,基于 JVM 的應用在不進行配置修改的情況下,無法自動使用擴容后的內存,通常還需要重啟。這類限制適用于所有自行管理內存池的應用。
4. 縮容的風險:
如果你嘗試把內存限制調低到低于當前使用量(即使設置了restartPolicy)也可能導致內存溢出(OOM)。
性能注意事項
1. 節點預留資源很關鍵:
節點需要有足夠的可用容量才能成功調度資源。在資源緊張的集群中,Pod 可能會長時間處于?PodResizePending?狀態,遲遲不能完成調整。
2.資源調整并非實時完成:
kubelet 是異步處理調整請求的。復雜的 cgroup 更新可能需要幾秒鐘才能完全生效。
3.調度器不感知擴縮容狀態:
Kubernetes 調度器在進行 Pod 調度時不會感知有 Pod 正在調整資源,這可能導致資源壓力誤判,甚至調度沖突。
記住這些注意事項,你就能避免最糟糕的情況。
07/VPA:很努力但還差點意思
正如我最近在 LinkedIn 上感嘆的,垂直 Pod 自動擴縮容(VPA)就像彈性伸縮家族聚會里那個總被忽視的尷尬親戚。
但好消息是,它的“逆襲”正在進行中。
當前狀態(截至 Kubernetes 1.33):
- VPA 尚不支持原地調整——它在調整資源時仍然會直接刪除然后再重建 Pod,這在很多場景下顯得非常粗暴。
- Kubernetes文檔明確指出這一限制:“截至Kubernetes 1.33,VPA 不支持原地調整 Pod,但相關集成正在開發中。”
在?kubernetes/autoscaler PR #7673?中(https://github.com/kubernetes/autoscaler/pull/7673),社區已著手將 VPA 與原地擴縮容機制集成。這意味著未來我們有望看到?VPA 真正實現資源動態調整,而無需重啟應用。
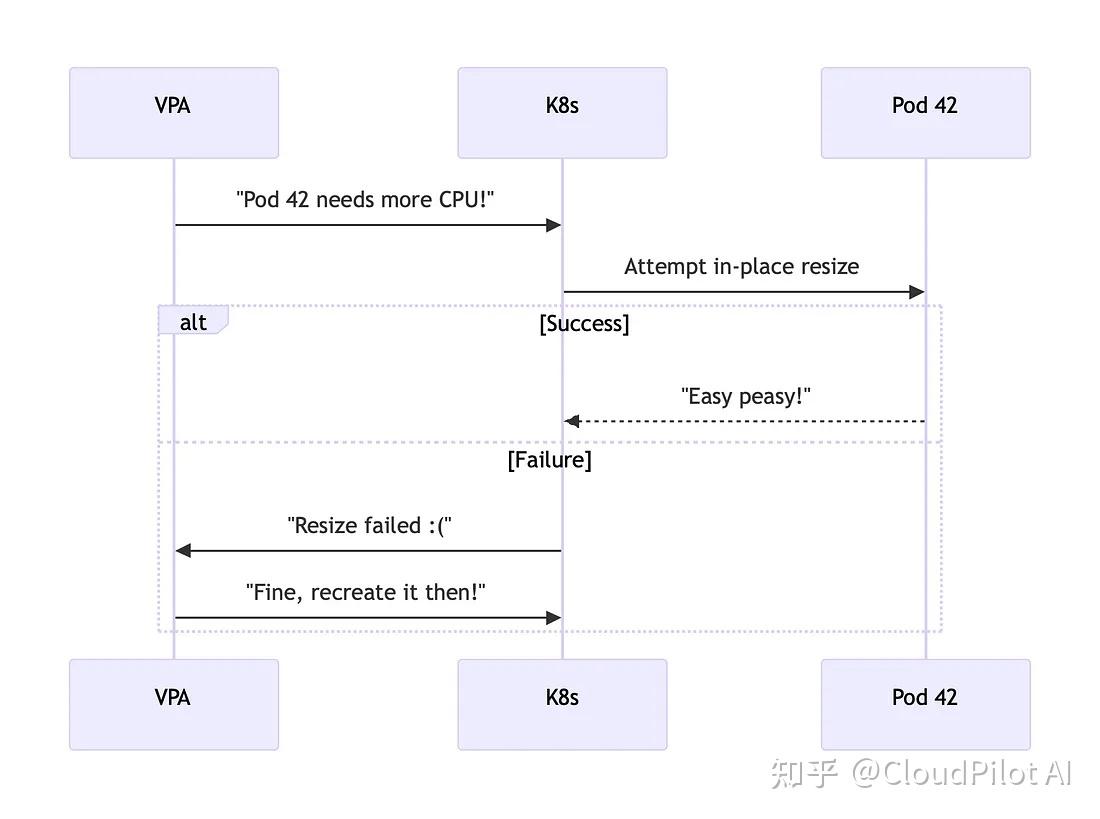
這種混合方案有望讓 VPA 真正能具備在生產環境中支持有狀態工作負載的能力。在此之前,我們只能繼續手動和 Pod 玩資源疊疊樂,謹慎地調整資源。
當前結合 VPA 和手動調整的方法
雖然 VPA 尚未原生支持原地擴縮容,但你仍然可以同時受益于兩者:
- 使用 VPA 的“Off”模式:只生成資源推薦,不自動調整
- 基于推薦手動執行擴縮容:根據 VPA 的建議手動進行原地調整
- 編寫腳本自動化操作流程:通過腳本自動化手動步驟,避免 Pod 重建
# Example of a simple script to apply VPA recommendations via in-place resize
#!/bin/bash
POD_NAME="my-important-db"
CPU_REC=$(kubectl get vpa db-vpa -o jsonpath='{.status.recommendation.containerRecommendations[0].target.cpu}')
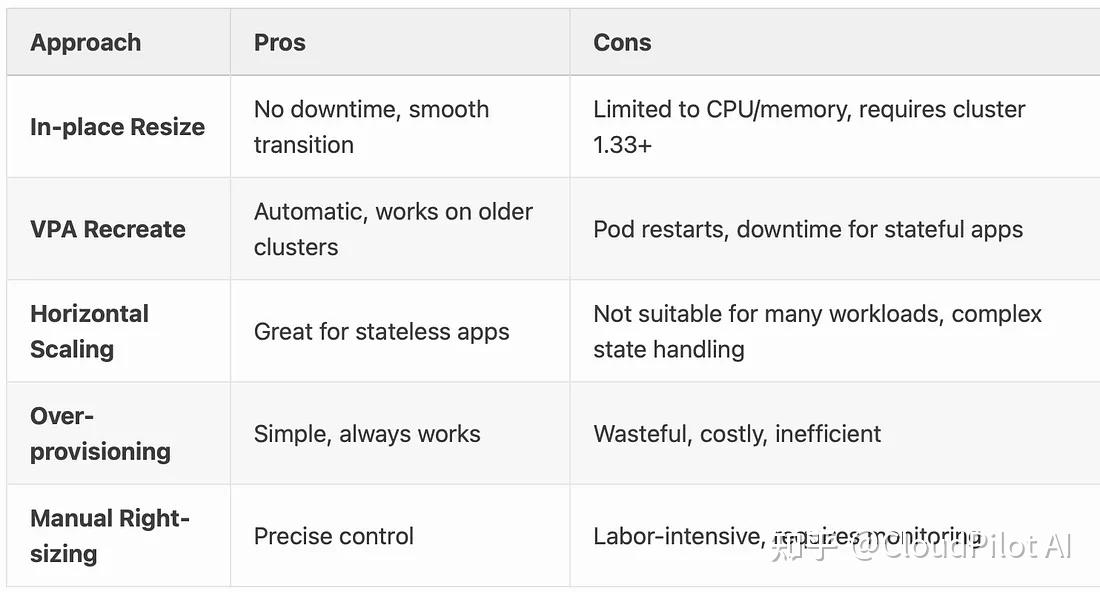
MEM_REC=$(kubectl get vpa db-vpa -o jsonpath='{.status.recommendation.containerRecommendations[0].target.memory}')kubectl patch pod $POD_NAME --subresource resize --patch \"{\"spec\":{\"containers\":[{\"name\":\"database\",\"resources\":{\"requests\":{\"cpu\":\"$CPU_REC\",\"memory\":\"$MEM_REC\"}}}]}}"08/與其他解決方案的對比
09/展望未來
Kubernetes 1.33 引入的原地 Pod 調整是讓垂直擴縮容走向“無感知”的重要一步,但這只是開始。接下來還有更多令人期待的進展:
- VPA 深度集成(開發中)?首先嘗試原地調整,僅在絕對必要時才重建 Pod,不再有突發的 Pod 驅逐。
- 支持更多資源類型?不止 CPU 和內存,未來可能連 GPU、臨時存儲都能動態調整。
- 調度器智能感知?目前調整操作不會通知調度器,Pod 仍可能因節點資源不足被驅逐。后續可能讓其具備感知能力,優先保障資源,避免被意外重新調度。
- 和 Cluster Autoscaler / Karpenter 的聯動?實現更智能的資源決策,僅在無法原地調整時擴展節點。
- 基于應用指標的自動調整資源?不再只盯著 CPU 和內存,未來可能支持基于“請求延遲”、“隊列深度”等應用級指標進行資源動態調整。
這些逐步完善的功能功能共同描繪出一個未來愿景:Kubernetes 正在邁向一個真正智能、高效、不中斷的垂直擴縮容時代。
對于開發者和平臺團隊而言,原地擴縮容(in-place pod resize)功能已經具備實驗性使用的條件,非常適合在非生產環境中進行測試和評估。
需要注意的是,盡管該特性功能強大,在引入生產環境前仍需充分驗證與測試,以規避潛在的不確定性和兼容性風險。期待這個功能可以幫助你持續提升集群資源管理效率。

)



)






)
)


)


