數據集分析
ORL數據集, 總共40個人,每個人拍攝10張人臉照片
照片格式為灰度圖像,尺寸112 * 92
特點:
-
圖像質量高,無需灰度運算、去噪等預處理
-
人臉已經位于圖像正中央,但部分圖像角度傾斜(可以嘗試五點定位進行透射變換統一視角)

任務介紹
人臉識別:將每個人10張圖片中的6張用來構建訓練集訓練模型,10張中的2張作為驗證集調參,剩余兩張用于測試集驗證效果。
分類任務:給出測試集的圖片,需要準確判斷出是誰的人臉(40類)
總流程介紹
訓練過程
-
數據集劃分
-
訓練集上找PCA正交基,取前k個主要基
-
將訓練集圖片在這k個基上進行投影,特征向量,并且構建庫
測試過程
-
新圖片輸入
-
根據訓練集得到的正交基,在k個基上進行投影,得到特征向量
-
從庫中進行匹配,找出最相似的k個,投票得出分類結果(knn)
方法介紹
K-L變換
不嚴謹的定義:從數據中找到k個正交基,使得以這k個基來表示圖像的時候,最容易把圖像之間彼此區分開。
推一下學長博客,解析的非常到位:
主成分分析法(離散K-L變換) - RyanXing - 博客園主成分分析法(離散K L變換) '主成分分析法(離散K L變換)' '1. 概述' '2. K L變換方法和原理推導' '2.1 向量分解' '2.2 向量估計及其誤差' '2.3 尋找最小誤差對應的正交向量系' '3. K L變換高效率的本質' '4. PCA在編、解碼應用上的進一步推導' '4.![]() https://www.cnblogs.com/RyanXing/p/PCA.html
https://www.cnblogs.com/RyanXing/p/PCA.html
假設有一張100 * 100的圖像,將圖像拉平成一維,共有10000個自由的特征, 最原始的方法是對圖像逐像素計算相似度。但是這樣的相似度計算并不合理。因為在這1w維的向量里邊有很多并不起作用(比如背景像素),也即有很多維度是冗余的。如果能夠找到更精煉的匹配方法,分類的效果會更好
什么是數據的主要特征?
使用一組標準正交基表示n維空間里邊的向量,大家習以為常:
對列向量x ,使用標準正交基{u} 去描述它,每一個維度的系數就是y
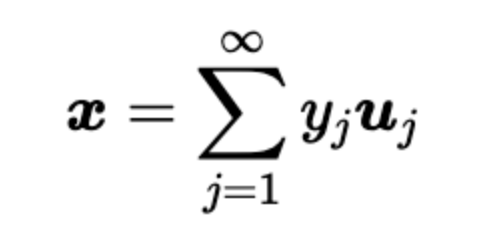
出于特征提取或者數據壓縮等目的,常常采用 n維空間里邊的一部分項去表示向量,比去取前d項
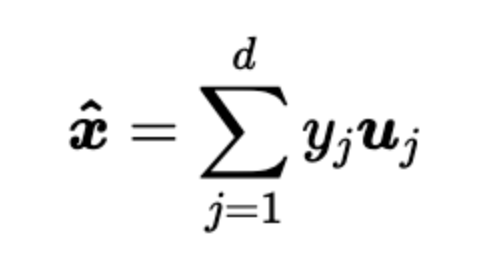
這樣的截取雖然方便了我們去找主要影響因素,但是也損失了一些信息,我們希望損失的信息最少。
在均方損失意義下,損失公式如下(也就是向量每一個維度的估計值減去實際值的平方 最后加和),直觀一點就是被舍棄的那些基分量的平方求和
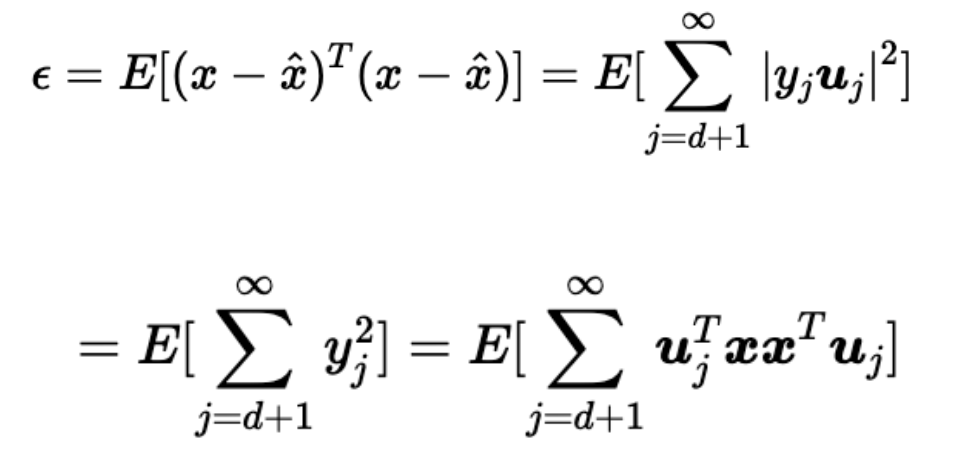
造成損失的最終化簡形式如下,中間的R矩陣是 向量 x 的自相關矩陣
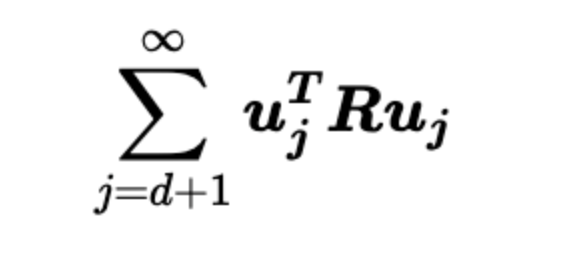
數學推導可以證明,這樣的損失和選取的正交基有關,當選取R的特征向量構成的正交基的時候,這個誤差就最小。
這就是K-L變換,最小均方誤差意義下的最優正交變換。
K-L變換的運算方式
可以對上面的R矩陣硬進行分解,但是運算量非常大。
實際使用的時候大多中心化之后利用SVD加速,因為左奇異矩陣和右奇異矩陣的前若干個奇異值是相等的。
特征臉分析
使用PCA找到了前k個正交基,將這些向量還原回矩陣形式,可以觀察到圖片:這就被稱為特征臉

結果展示
數據集劃分:train:valid:test = 6:2:2
訓練集共240個樣本,經過SVD加速后只能取前240個特征向量,使用0.2的pca基保留率,最終剩下48個特征基
112 * 92 個值 壓縮為 48 個值
驗證集效果:正確率94.9986%
測試集效果:正確率93.7499%
完整代碼鏈接(含數據)
完整代碼鏈接,供交流學習使用,如有不足歡迎批評指正
GitHub - Keith1276/python_DIP_codeContribute to Keith1276/python_DIP_code development by creating an account on GitHub.![]() https://github.com/Keith1276/python_DIP_code/tree/main
https://github.com/Keith1276/python_DIP_code/tree/main


)
的方法)


)

----關于IS-IS的基礎概念)

修復漏洞)


)


)


