混合專家(MoE)
??混合專家(Mixture of Experts, MoE)?? 是一種機器學習模型架構,其核心思想是通過組合多個“專家”子模型(通常為小型神經網絡)來處理不同輸入,從而提高模型的容量和效率。MoE的關鍵特點是??動態激活??:對于每個輸入,僅調用部分相關的專家進行計算,而非全部,從而在保持模型規模的同時降低計算成本。
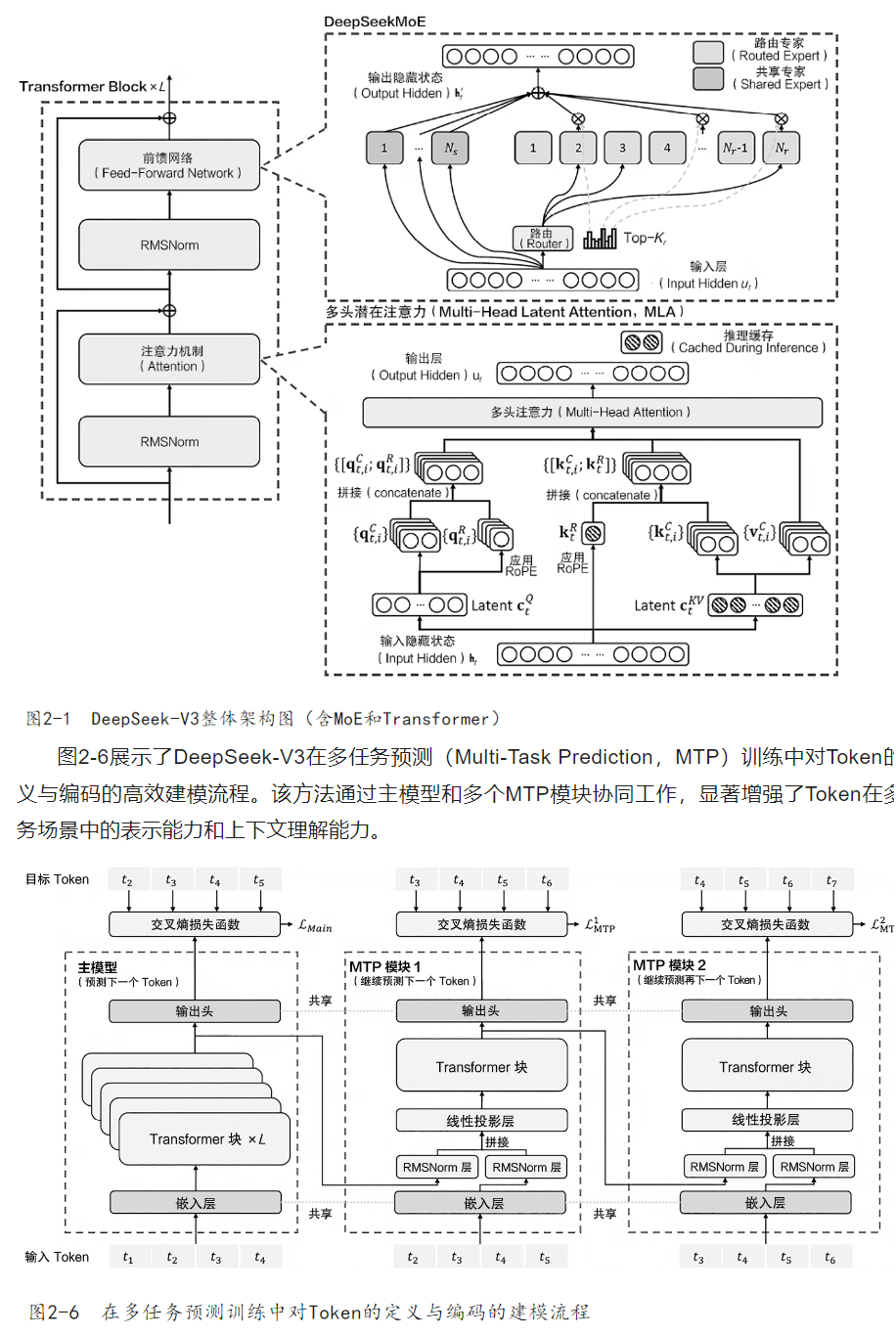
MoE架構是一種創新的模型架構,通過引入多個“專家網絡”來提升模型的表達能力和計算效率。在MoE架構中,多個專家網絡被獨立設計為處理不同的特定任務或特定特征,模型根據輸入數據的特點動態選擇部分專家{L-End}參與計算,而不是同時激活所有專家網絡。這種“按需計算”的方式顯著減少了資源消耗,同時提升了模型的靈活性和任務適配能力。MoE的核心思想是通過動態路由機制,在每次推理或訓練中只激活一部分專家,從而在大規模模型中實現參數規模的擴展,而不會顯著增加計算開銷。
MoE的優勢與意義
MoE架構的引入為大規模模型解決了參數擴展與計算效率之間的矛盾,在以下幾個方面形成了優勢。
(1)參數規模的擴展:MoE架構允許模型擁有超大規模的參數量,但每次計算中只需要激活一小部分參數,從而大幅提升模型的表達能力。
(2)高效資源利用:通過動態選擇專家,MoE架構避免了計算資源的浪費,同時節省了顯存和計算成本。
(3)任務適配能力增強:不同的專家網絡可以針對不同任務進行優化,使模型在多任務環境中具備更強的適應性。
(4)分布式訓練的友好性:MoE架構天然適配分布式計算環境,通過將不同的專家網絡分布到多個計算節點,顯著提升了并行計算效率。
)
的方法)


)

----關于IS-IS的基礎概念)

修復漏洞)


)


)




)