協議
在網絡通信中,協議是非常重要的概念。協議是在網絡通信過程中的約定。發送方和接收方需要提前商量好數據的格式,才能確保正確進行溝通。
應用層協議
應用層,對應著應用程序,是跟我們程序員打交道最多的一層。調用操作系統提供的網絡API寫出的代碼,都是在應用層上的。
應用層這里有很多現成的協議,但更多的,還是需要我們程序員根據實際的業務場景自定義協議(網絡傳輸的數據要怎么使用,也要考慮數據是什么樣的格式,包含哪些內容)。
應用層的協議在開發時一般是客戶端和服務器共同約定的。
自定義協議,一般要約定好兩方面內容:
1、客戶端和服務器要交互哪些信息
2、數據的具體格式
客戶端按照上述約定發送請求,服務器按照上述約定解析請求,服務器按照上述約定構造響應,客戶端按照上述約定解析響應。
舉個例子:
點個外賣~
打開外賣相關的APP,顯示出主頁,主頁里面就會顯示出一些快餐店、飯店的列表。
而這些飯店都是在我們附近的(打開軟件時,客戶端和服務器交互了位置信息),顯示的飯店列表中,也會包含一些信息——飯店的名稱、圖片、評分、簡介……上述的這些信息,需要通過一定的格式來組織的,往往是設計客戶端和設計服務器這兩伙程序員坐在一起,一起把這個事情敲定下來的~~~
一個簡單粗暴但五臟俱全的例子:
1、請求,約定使用行文本的格式來進行表示:
userId,postion\n(請求以\n結尾,使用,對信息進行分割)
例如:(1001,[經緯度]\n)?
2、 響應,也是使用行文本來表示,一個響應中可能會包含多個飯店,每個飯店占一行,每個飯店都要返回 id,名稱,圖片,評分,簡介
例如:( 2001,A 飯店,[logo圖片地址],4.9,高端飯店\n
? ? ? ? ? ? ???2002,B飯店,[logo圖片地址],4.5,干凈衛生的飯店\n
? ? ? ? ? ? ? ? \n)
若干行的最后,使用空行來作為所有數據的結束標志,上面這一系列內容就是同一個響應中的數據了。
補充:
客戶端和服務器之間往往交互的是“結構化數據”(結構化數據:一個結構體/類,其中包含了很多個屬性),而網絡傳輸的數據其實是“字符串”、“二進制比特流”。
約定協議的過程,其實就是把結構化數據轉成字符串/二進制比特流的過程。
把結構化數據轉成字符串/二進制bit流的操作,稱為“序列化”。
把字符串/二進制比特流還原成結構化數據的操作,稱為“反序列化”。
序列化/反序列化具體要組織成什么樣的格式,要包含哪些信息,約定這兩件事情的過程,就是自定義協議的過程。
為了讓程序員更方便地去約定這里的協議格式,業界給出了幾個比較好用地方案:
xml協議
大致模型如下:
<屬性名>稱為標簽(tag),一般是成對出現的,分別為開始標簽和結束標簽。開始標簽和結束標簽中間夾著的是標簽的值,標簽是可以嵌套的。(標簽名/標簽值/標簽的嵌套關系,這些都是程序員自定義的)
優點 :使得數據內容的可讀性和拓展性都提升了很多,標簽的名字能夠對數據起到說明作用,后續再增加一個屬性,新添加一個標簽即可,對已有代碼影響不大
缺點:冗余信息比較多,標簽的描述性信息,占據的空間反而比數據本身還要多了。
json協議
大致模型如下:
采用的是鍵值對結構:
鍵與值之間用:進行分割,鍵與鍵之間用,進行分割,若干個鍵值對之間使用{? }分隔開,一個{? }就形成了一個json對象,還可以把多個json對象放到一起,使用,分隔開,將整體使用[? ]括起來,此時就形成了一個json數組。
優點:可讀性、擴展性都更好,而且對比xml來說,占用的空間更少了。
缺點:雖然json的確比xml占用的空間更少了,節省了寬帶,但很明顯,這里的寬帶仍然還是有浪費的部分,尤其是這種數組格式的json,這種情況下往往會傳輸很多相同的數據字段,很多key關鍵字都是重復傳輸的(id、name……)。
protobuffer
這種約定是更加節省寬帶的方式,也是效率最高的方式。
protobuffer只是在發階段(寫代碼階段)定義出這里有的哪些資源,描述每個字段的定義。程序真正運行時,實際傳輸的數據是不包含這些信息的。這樣的數據都是按照二進制的方式來進行組織的。
這種方式雖然程序運行的效率會很高,但不利于程序員進行閱讀。
所以雖然protobuffer運行效率更高,但是使用并沒有比json廣泛,只有一些對于性能要求非常高的場景protobuffer。
傳輸層協議
傳輸層的協議,雖然是系統內核已經實現好的,但我們仍需要重點進行關注,我們在之前的網絡編程中使用的socket? API? 就是傳輸層提供的。
端口號
端口號,是一個兩個字節的整數。標識了一個主機上的正在進行網絡通信應用程序。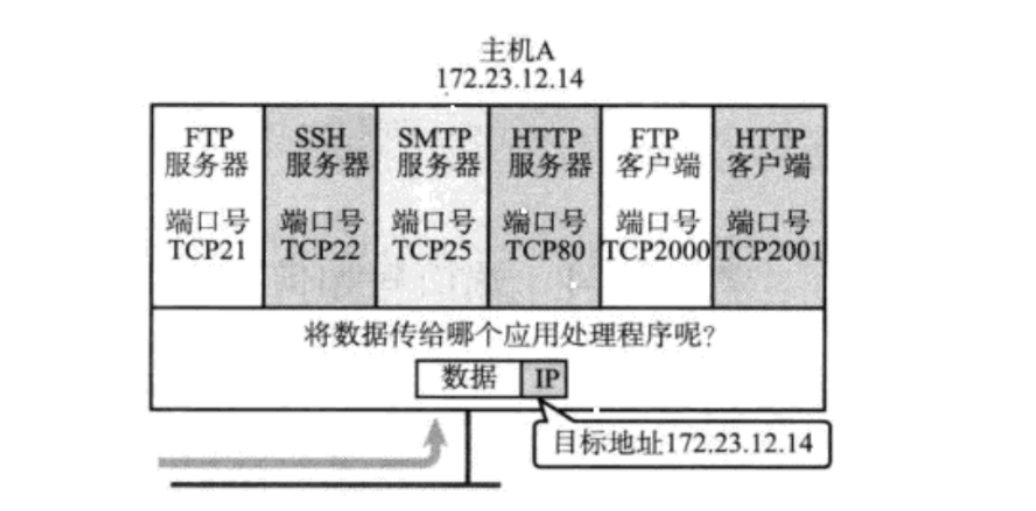
在TCP/IP協議中,用源IP、源端口號、目的IP、目的端口號、協議號,這樣一個五元組來標識一個通信。?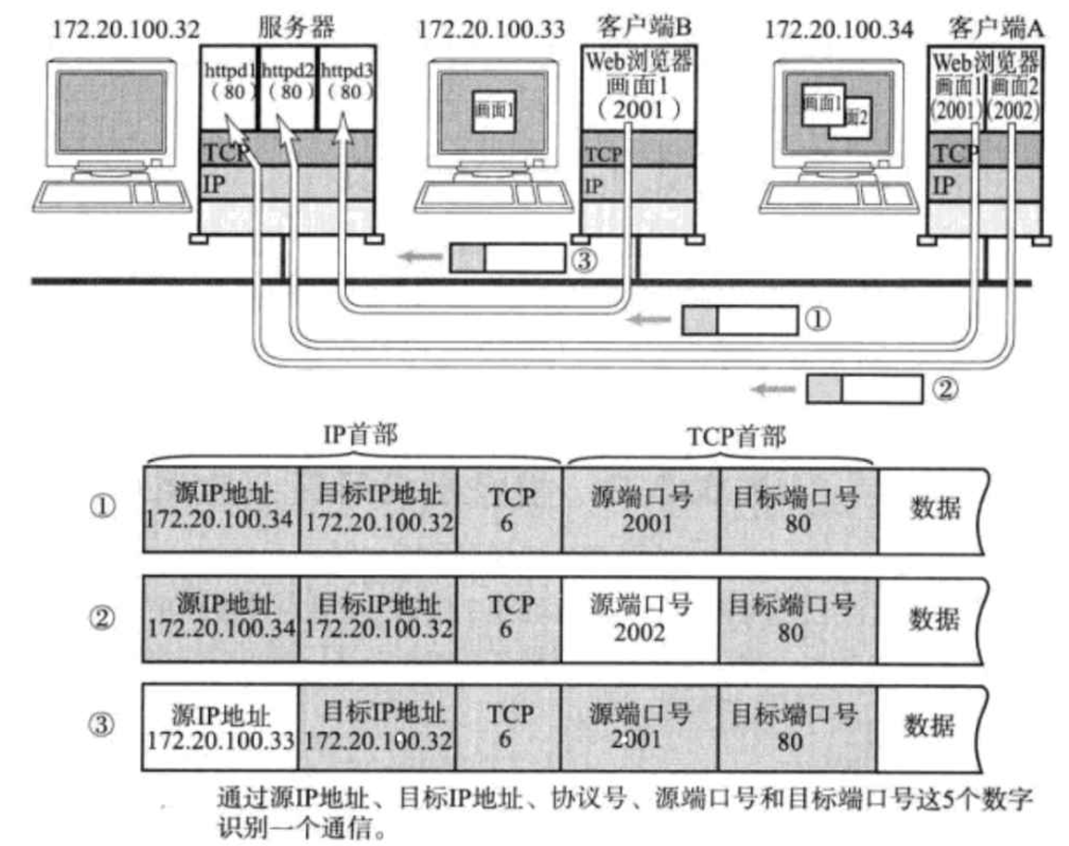
端口號的范圍劃分:
0~1023:是一些知名端口號,HTTP,FTP,SSH等這些廣為使用的服務器,他們的端口號是固定的。
1024~65535:操作系統動態分配的端口號。我們前面在網絡編程中,客戶端程序的端口號,就是由操作系統在這個范圍內分配的。
知名端口號:
SSH服務器:22;
FTP服務器:21;
telnet服務器:23;
HTTP服務器:80;
HTTPS服務器:443;
我們在寫程序使用端口號時,需要避開這些知名端口號。
UDP協議
前面我們已經提到過,UDP協議的四個特點:無連接,不可靠傳輸,面向數據報,全雙工。
研究一個協議,我們主要研究報文格式,基于報文格式,來了解這個協議的特性。
UDP數據報 = 報頭(重點)+載荷(應用層數據包)
UDP協議格式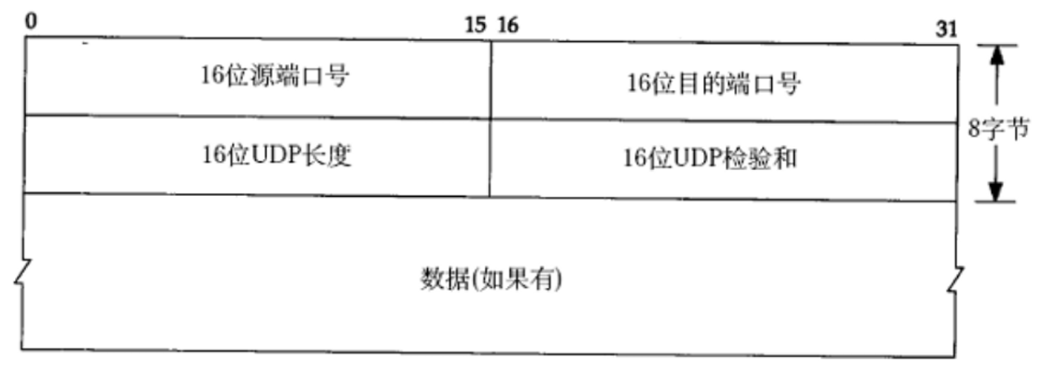
實際上的UDP數據報是這樣的: ?UDP的報頭中,一個有4個字段,每個字段2個字節(一共8個字節)。
?UDP的報頭中,一個有4個字段,每個字段2個字節(一共8個字節)。
由于UDP中使用2個字節(16位)來識別端口號,端口號的取值范圍就是0~65535,同理數據報的最大長度也是65535(64KB),一旦數據超出64KB,數據就有可能會出現截斷(64KB后面的數據就沒有了)。
總的數據報最大長度是64KB,載荷部分實際的最大長度應該是64KB-8KB(報頭長度)
為了解決數據被截斷問題,有兩個方案:
方案1:在應用層,把數據報進行拆分,之前一個數據報,表示N個頁面,拆分成每一個頁面占用一個UDP數據報,甚至可以進一步拆分成,一個頁面對應多個UDP數據報(開發和測試成本很大)。
方案2:使用TCP代替UDP,TCP沒有長度限制。
那為什么不對UDP的長度進行擴展呢?技術上是很容易實現,但要改就要所有就得所有的系統一起改,如果一方改了,另一方不改,相互之間就無法進行通信了。
校驗和:驗證數據在傳輸的過程中是否正確。
數據在網絡傳輸的過程中是可能出錯的。網絡數據傳輸的過程中是使用光信號/電信號/電磁波進行傳輸的,上述信號都是很容易收到干擾的。
比如,使用高低電平來表示0 1 ,此時外界如果加上一個磁場,就可能把高電平變為低電平,低電平變為高電平,此時,0->1,1->0,就出現了比特翻轉。現代的傳輸體系,會有一系列的保護機制,來減少外界的干擾。
校驗和的作用就是用來識別出當前數據是否在傳輸過程中出現錯誤。
注意:網絡中的校驗和,并非是簡單的按照數據的長度或者數量來進行校驗的,一定是數據的內容會參與到其中。
嚴格來說,校驗和只能用來“證偽”,即只能證明數據是出錯了。沒辦法確保這個數據100%是正確的。但是出現這種情況的概率很小,實踐中可以近似地認為校驗和一致,數據就一致了。
UDP中的校驗和是使用比較簡單的算法——CRC算法(循環冗余校驗)實現的。
比如,要產生一個兩個字節的校驗和:
加的過程可能會有一些數據比較大,超出了short的范圍,其實也沒有關系,這里不用管。
UDP數據發送方,在發送數據之前,先計算一遍CRC,把計算好的CRC的值放到UDP數據報中(設這個CRC值為value1)
接下來,這個數據報會通過網絡傳輸到達接收端,接收端收到數據之后,也會使用同樣的算法,再算一遍CRC的值,得到的結果是value2。比較自己計算的value2和收到的value1的值是否一致。如果是一致的,那么數據大概率是沒有問題的。如果不一致,則傳輸過程中一定出現了錯誤。
為什么value1 == value2時,要說數據大概率是沒有問題呢?如果只有一個bit為位發生翻轉,那么CRC是100%能夠發現錯誤的。但是如果恰好有兩個/多個bit位發生翻轉,就有可能校驗和恰好和之前的一樣,這種情況出現的概率比較低,可以忽略不計,但如果需要有跟你廣告的檢查精度,就需要使用其他更為嚴格的校驗和算法了。
這里我們重點介紹md5/sha1算法 ,這兩個算法背后的數學公式大同小異,且研究起來比較困難,這里我們認識下他們的特點即可:
1、定長:無論原始數據有多長,算出來的md5的最終值始終都是一個固定長度(16位、32位、64位)。
2、分散:計算md5的過程中,原始數據,只要變化一點點,算出來的md5的值就會發生很大的變化。(這樣的特性,也使得md5可以作為一個字符的hash算法)
3、不可逆:給一個源字符串,計算md5值,過程非常簡單(比CRC難一點,但是整體比較簡單),但是如果給一個算好的md5值,還原為原始字符串,理論上是無法完成的。
原始字符串變為md5碼的過程會有很多信息量損失,無法進行還原,就像火腿腸無法還原成豬肉那樣。
修復漏洞)


)


)




)







