一、樹
樹型結構是一類重要的非線性數據結構。其中以樹和二叉樹最為常用,直觀看來,樹是以分支關系定義的層次結構。把它叫做“樹”是因為它常看起來像一棵倒掛的樹,也就是說它常是根朝上,而葉朝下的。
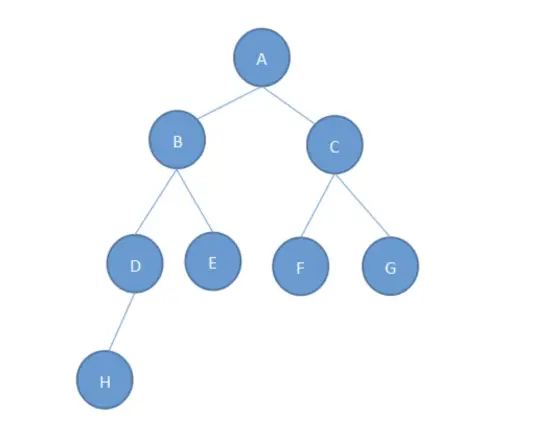
1.樹的定義:
樹是 N(N≥ 0) 個結點的有限集。當 N=0 時,稱為空樹。在任意一棵樹非空樹中應滿足:
(1) 有且僅有一個特定的稱為根 (root) 的結點;
(2) 當 N > 1?時,其余結點可分為 M(M>0)個互不相交的有限集T1,T2,T3...Tm,其中每一個集合本身又是一顆樹,并且稱為根的子樹(SubTree) 。
2.樹的基本概念:
1. 結點:包含一個數據元素及若干指向其子樹的分支;
2.結點的度:一個結點擁有的子樹的數目;
3.葉子或終端結點:度為0的結點;
4.非終端結點或分支結點:度不為0的結點;
5.樹的度:樹內各結點的度的最大值;
6.孩子結點或子結點:結點的子樹的根稱為該結點的孩子結點或子結點;
7.雙親結點或父結點:若一個結點含有子結點,則這個結點稱為其子結點的雙親結點或父結點;
8.兄弟結點:同一個雙親的孩子之間互稱兄弟;
9.祖先結點:從根到該結點所經分支上的所有結點;
10.子孫結點:以某結點為根的子樹中任一結點都稱為該結點的子孫;
11.堂兄弟結點:其雙親在同一層的結點互為堂兄弟;
12.結點的層次:從根開始定義起,根為第一層,根的孩子為第二層。若某結點在第層.則其子樹的根就在第層;
13.樹的深度或高度:樹中結點的最大層次;
14.森林:由M(M>0)棵互不相交的樹的集合稱為森林;
15.有序樹和無序樹:樹中結點的各子樹從左到右是有次序的,不能互換,稱該樹為有序樹,否則稱為無序樹;
16.路徑和路徑長度:路徑是由樹中的兩個結點之間的結點序列構成的。而路徑長度是路徑上所經過的邊的個數。
二、二叉樹
1.二叉樹定義:
二叉樹?(Binary Tree)的特點是每個結點至多只有兩棵子樹 (即二叉樹中不存在度大于2的結點),分別稱為左子樹和右子樹。二叉樹是一種遞歸的數據結構,可以是空樹(即沒有任何結點),或者是由根結點及其左右子樹組成。并且,二叉樹的子樹有左右之分,其次序不能任意顛倒。
2.二叉樹的特點:
(1)每個結點最多有兩個子結點,分別稱為左子結點和右子結點。
(2)左子樹和右子樹都是二叉樹,它們本身也可以是空樹。
(3)二叉樹的結點結構包含一個數據元素和指向左右子樹的指針。
3.?二叉樹有多種類型:
? ? ?包括:二叉排序樹、完全二叉樹、滿二叉樹、平衡二叉樹等。
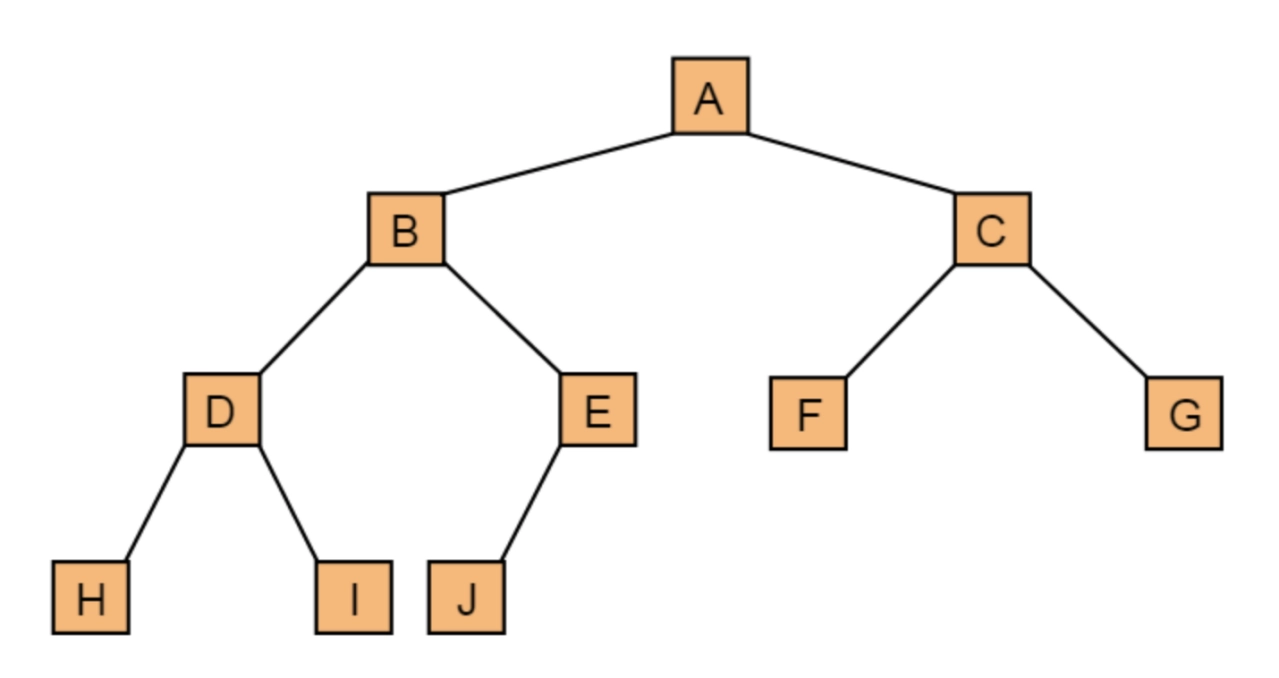
?二叉樹示例
三、二叉排序樹(二叉搜索樹)
1、定義:
二叉排序樹(Binary Sort Tree),也稱為二叉查找樹或二叉搜索樹。其或者是一棵空樹;或者是具有下列性質的二叉樹?[5]:
(1)若它的左子樹不空,則左子樹上所有結點的值均小于它的根結點的值;
(2)若它的右子樹不空,則右子樹上所有結點的值均大于它的根結點的值;
(3)它的左、右子樹也分別為二叉排序樹。
其中葉結點除外的所有結點均含有兩個子樹的樹被稱為滿二叉樹。除最后一層外,所有層都是滿結點,且最后一層缺右邊連續結點的二叉樹稱為完全二叉樹。
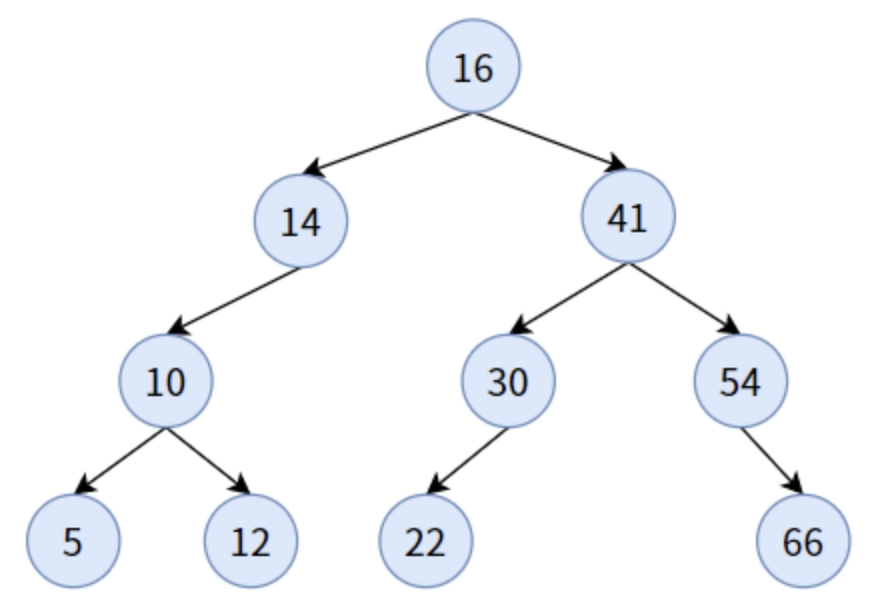
二叉搜索樹?
2、特點:
二叉排序樹的特性使得在其中進行搜索、插入和刪除操作時具有較高的效率。
四、滿二叉樹
1、定義:
對于一個二叉樹,如果每一個層的結點數都達到最大值,則這個二叉樹就是滿二叉樹。也就是說,如果一個二叉樹的層數為 h? ,且結點總數是??-1 ,則它就就是滿二叉樹?。
?葉結點除外的所有結點均含有兩個子樹的樹被稱為滿二叉樹?。
2、滿二叉樹特點:
可以對滿二叉樹按層序編號:約定編號從根結點(根結點編號為1)起,自上而下,自左向右。這樣,每個結點對應一個編號,對于編號為 i? 的結點,若有雙親,則其雙親為 i/2 ,若有左孩子,則左孩子為 2i?,若有右孩子,則右孩子為 2i+1?。滿二叉樹示例,如下圖所示:

五、完全二叉樹
1、定義:
對于二叉排序樹, 除最后一層外,所有層都是滿結點,且最后一層缺右邊連續結點的二叉樹稱為完全二叉樹。
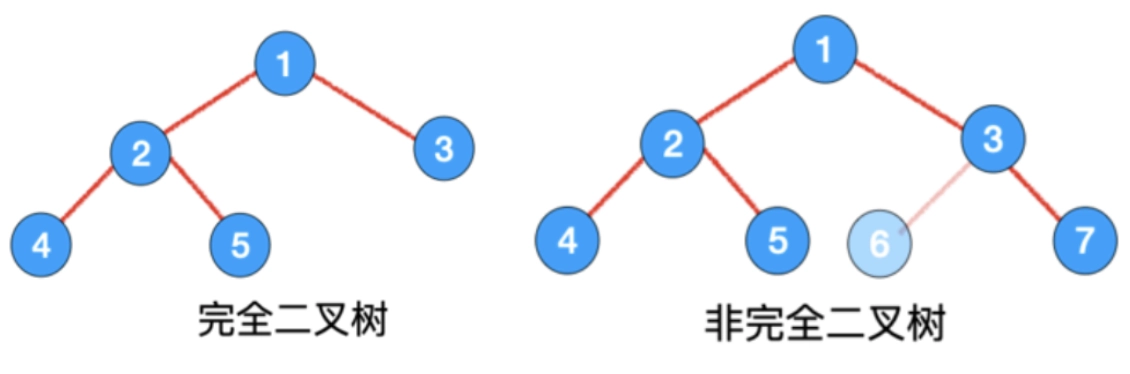
2、完全二叉樹特點
- 如果樹的深度為k ;
- 則至少有
?個節點;
- 最多具有?
?個節點。
六、平衡二叉樹
1、定義:
平衡二叉樹(Balanced Binary Tree 或 Height-Balanced Tree)又稱AVL樹。它或者是一棵空樹,或者是具有下列性質的二叉樹:它的任意結點的左子樹和右子樹都是平衡二叉樹,且左子樹和右子樹的深度之差的絕對值不超過1。
2、特點:
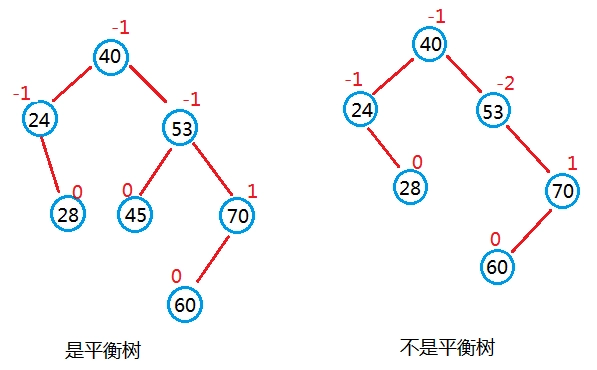
若將二叉樹上結點的平衡因子BF(Balance Factor)定義為該結點的左子樹的深度減去它的右子樹的深度,則平衡二叉樹上所有結點的平衡因子只可能是-1、0和1。只要二叉樹上有一個結點的平衡因子的絕對值大于1,則該二叉樹就是不平衡的[1]。平衡二叉樹示例,如下圖所示:
?七、紅黑樹
1、定義
為了保持平衡二叉樹(AVL樹)的平衡性,插入和刪除操作后,非常頻繁地調整全樹整體拓撲結構,代價較大。為此在AVL樹的平衡標準上進一步放寬條件,引入了紅黑樹(Red-Black Tree)的結構 。
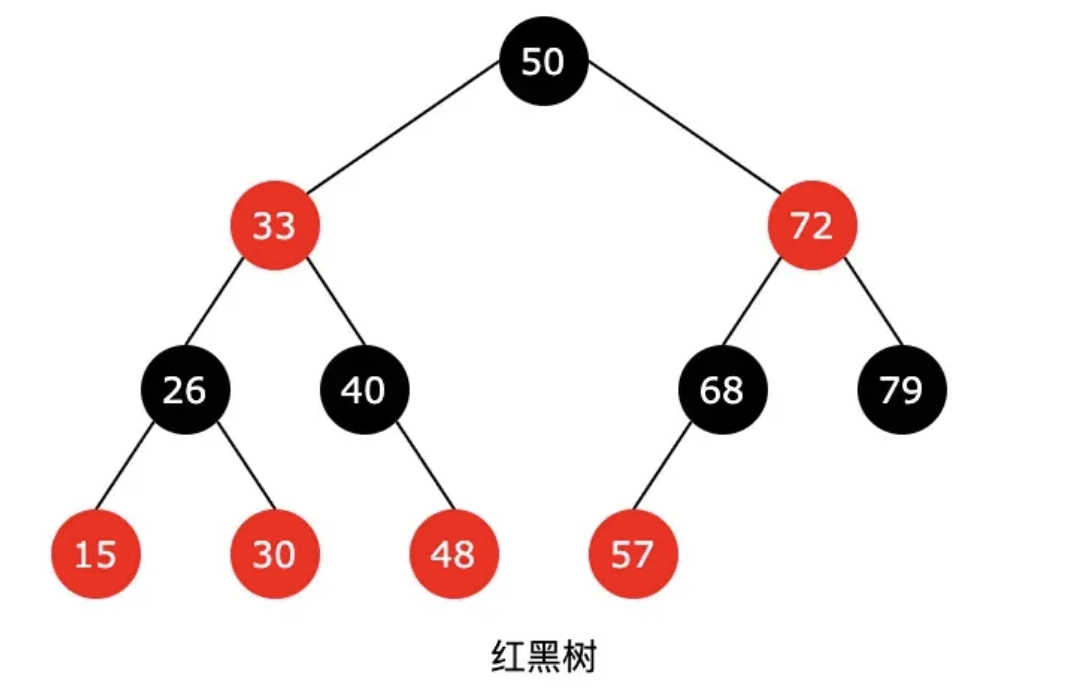
一棵紅黑樹是滿足如下紅黑性質的二叉排序樹 :
(1)每個結點是紅色,或是黑色的;
(2)根結點是黑色;
(3)葉子結點(虛構的外部結點、NULL結點)都是黑色的;
(4)不存在兩個相鄰的紅結點(即紅結點的父結點和孩子結點均是黑色的);
(5)對每個結點、從該結點到任一葉子結點的簡單路徑上,所含黑結點的數量相同。
如果插入和刪除操作較少,查找操作較多,采用AVL樹比較合適,否則使用紅黑樹更為合適。但由于維護這種高度平衡所付出的代價比獲得的收益大得多,因此紅黑樹的實際應用更廣泛,C++中的map和set(Java中TreeMap和TreeSet就是用紅黑樹實現的?[5])。紅黑樹示例,如下圖所示:
八、哈夫曼樹
1、定義:
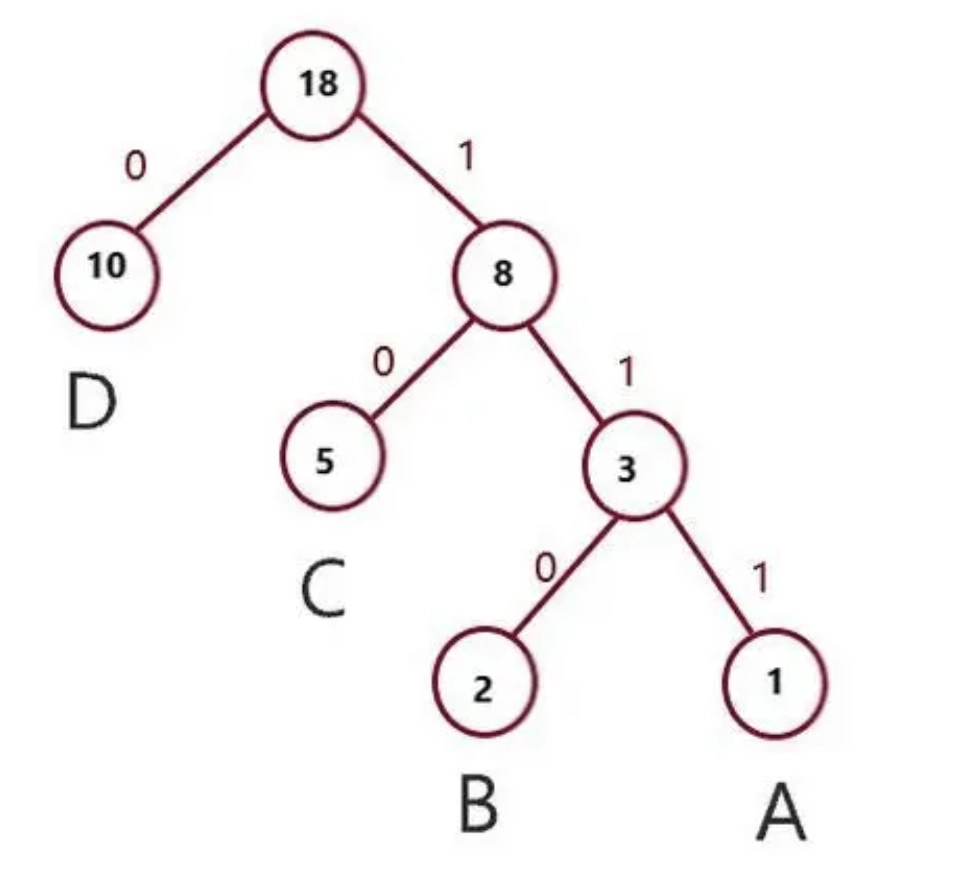
哈夫曼樹(Huffman Tree)是一種特殊的二叉樹,用于數據壓縮中的哈夫曼編碼(Huffman Coding)算法。哈夫曼樹的構建基于字符出現的頻率,通常用于壓縮數據,使得出現頻率高的字符使用較短的編碼,而出現頻率低的字符使用較長的編碼,從而達到壓縮數據的目的。
2、構建哈夫曼樹
構建哈夫曼樹的步驟包括:
(1)統計字符頻率:首先,統計待壓縮的數據中每個字符出現的頻率。
(2)構建哈夫曼樹:根據字符頻率構建一棵哈夫曼樹。構建的過程是通過將出現頻率最低的兩個結點合并為一個新結點,新結點的頻率為原結點頻率之和,并將新結點插入到樹中,重復這一過程直到只剩下一個根結點為止。
(3)生成編碼:對于哈夫曼樹中的每個字符,從根結點開始沿著路徑向下,每次移動到左子結點則表示該字符編碼中添加一個 0,每次移動到右子結點則表示添加一個 1,直到到達葉子結點。這樣,每個字符都可以對應一個唯一的編碼。
(4)數據壓縮:將原始數據中的每個字符替換為對應的哈夫曼編碼,從而實現數據的壓縮。
哈夫曼樹示例,如下圖所示:
九、B樹
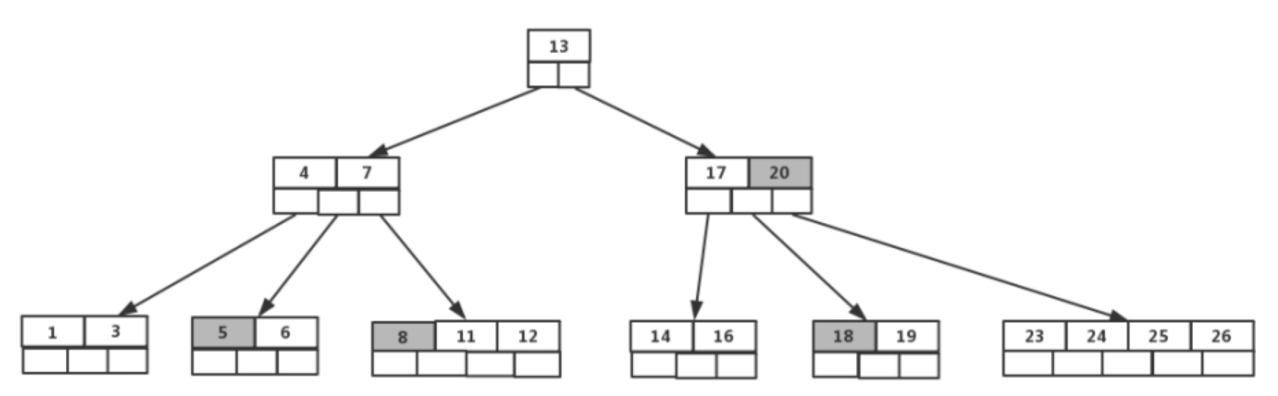
B樹是為磁盤或其他直接存取的輔助存儲設備而設計的一種平衡搜素樹 。B樹類似于紅黑樹,但它們在降低磁盤 I/0操作數方面要更好一些。許多數據庫系統使用B樹或者B樹的變種來存儲信息?。
B樹與紅黑樹的不同之處在于B樹的結點可以有很多孩子,從數個到數千個,能夠保持較低的高度并且保持數據的有序性,從而提高了數據的檢索效率和存儲效率 。
B樹示例,如下圖所示:
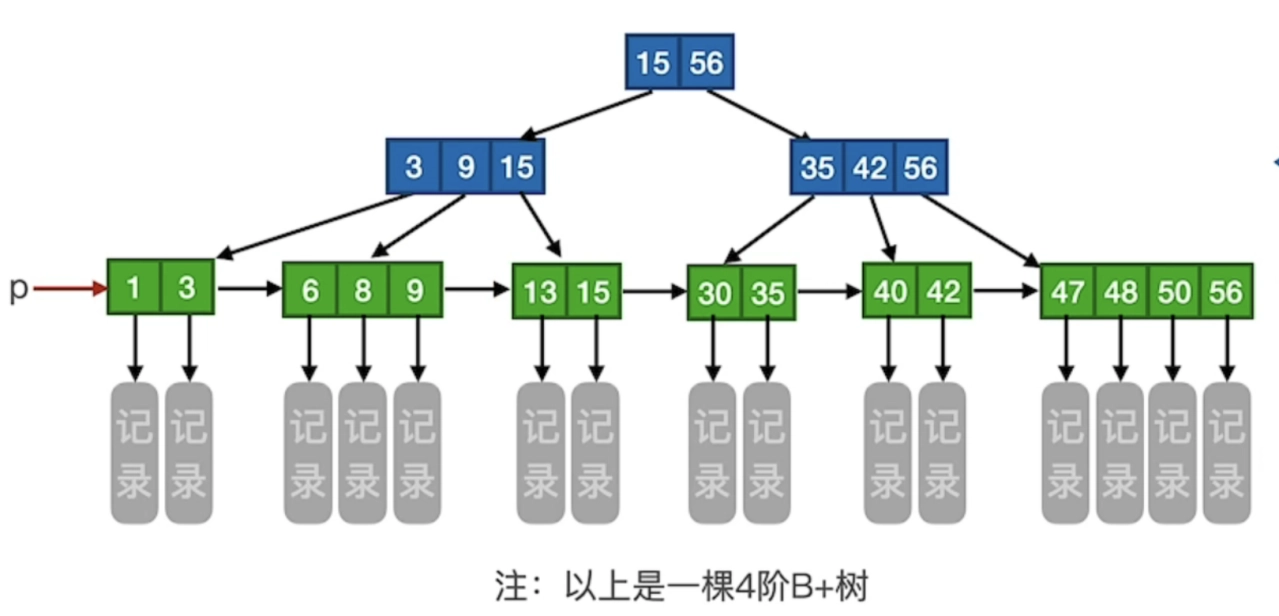
十、B+樹
?1、定義
B+樹是一種常見的B樹變種,類似于B樹,但在某些方面有所不同。例如:B+樹的非葉子結點只包含鍵值,不存儲實際數據。相比之下,B樹的非葉子結點不僅包含鍵值,還包含對應的數據;由于B+樹的葉子結點是通過指針相連的有序鏈表,因此范圍查詢的性能更好。相比之下,B樹需要進行中序遍歷來查找范圍內的鍵值。
B+樹通常用于數據庫系統和文件系統中,特別是用于實現索引結構 。
B+樹示例,如下圖所示:









:String接口實踐+底層的模擬實現(中篇))


![題海拾貝:P1208 [USACO1.3] 混合牛奶 Mixing Milk](http://pic.xiahunao.cn/題海拾貝:P1208 [USACO1.3] 混合牛奶 Mixing Milk)
)





)