目錄
一、使用sklearn轉換器處理數據
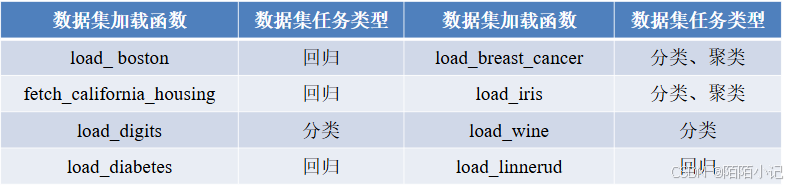
(一)、加載datasets模塊中的數據集
(二)、將數據集劃分為訓練集和測試集?
?編輯?train_test_spli
(三)、使用sklearn轉換器進行數據預處理與降維?
PCA?
二、 構建并評價聚類模型
(一)、使用sklearn估計器構建聚類模型
?(二)、使用sklearn轉換器進行數據預處理與降維
TSNE類
(三)、評價聚類模型
一、使用sklearn轉換器處理數據
(一)、加載datasets模塊中的數據集
sklearn庫的datasets模塊集成了部分數據分析的經典數據集,讀者可以使用這些數據集進行數據預處理、建 模等操作,以及熟悉sklearn的數據處理流程和建模流程。
datasets模塊常用數據集的加載函數及其解釋,如下表所示。
 使用sklearn進行數據預處理需要用到sklearn提供的統一接口——轉換器(Transformer)。
使用sklearn進行數據預處理需要用到sklearn提供的統一接口——轉換器(Transformer)。
如果需要加載某個數據集,那么可以將對應的函數賦值給某個變量。加載diabetes數據集,如以下代碼
 ?
?
(二)、將數據集劃分為訓練集和測試集?

 ?train_test_spli
?train_test_spli
?在sklearn的model_selection模塊中提供了train_test_split函數,可實現對數據集進行拆分,train_test_split函數 的基本使用格式如下。
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
train_test_split函數是最常用的數據劃分方法,在model_selection模塊中還提供了其他數據集劃分的函數,如PredefinedSplit函數、ShuffleSplit函數等。讀者可以通過查看官方文檔學習其使用方法。?
| 數值型數據類型 | 說明 |
| *arrays | 接收list、numpy數組、scipy-sparse矩陣、Pandas數據幀。表示需要劃分的數據集。若為分類回歸,則分別傳入數據和標簽;若為聚類,則傳入數據。無默認值 |
| test_size | 接收float、int。表示測試集的大小。若傳入為float型參數值,則應介于0~1之間,表示測試集在總數據集中的占比;若傳入為int型參數值,則表示測試樣本的絕對數量。默認為None |
| train_size | 接收float、int。表示訓練集的大小,傳入的參數值說明與test_size參數的參數值說明相似。默認為None |
| random_state | 接收int。表示用于隨機抽樣的偽隨機數發生器的狀態。默認為None |
| shuffle | 接收bool。表示在拆分數據集前是否對數據進行混洗。默認為True |
| stratify | 接收array。表示用于保持拆分前類的分布平衡。默認為None |
?train_test_split函數可分別將傳入的數據集劃分為訓練集和測試集。
如果傳入的是一組數據集,那么生成的就是這一組數據集隨機劃分后的訓練集和測試集,總共兩組。
如果傳入的是兩組數據集,則生成的訓練集和測試集分別兩組,總共4組。
將breast_cancer數據集劃分為訓練集和測試集,如以下代碼。

(三)、使用sklearn轉換器進行數據預處理與降維?
為了幫助用戶實現大量的特征處理相關操作,sklearn將相關的功能封裝為轉換器。 轉換器主要包括3個方法:fit()、transform()和fit_transform()。轉換器的3種方法及其說明如下表所示。
| 方法名稱 | 方法說明 |
| fit() | 主要通過分析特征和目標值提取有價值的信息,這些信息可以是統計量、權值系數等。fit()?方法用于從數據中學習參數,不進行實際的數據轉換。 |
| transform() | 主要用于對特征進行轉換。transform()?方法使用已經學習到的參數對數據進行轉換,因此在調用?transform()?之前必須先調用?fit()。 |
| fit_transform() | 即先調用fit()方法,然后調用transform()方法 |

sklearn除了提供離差標準化函數MinMaxScaler外,還提供了一系列數據預處理函數,如下表所示。
| 函數名稱 | 函數說明 |
| StandardScaler | 對特征進行標準差標準化 |
| Normalizer | 對特征進行歸一化 |
| Binarizer | 對定量特征進行二值化處理 |
| OneHotEncoder | 對定性特征進行獨熱編碼處理 |
| FunctionTransformer | 對特征進行自定義函數變換 |
PCA?
sklearn除了提供基本的特征變換函數外,還提供了降維算法、特征選擇算法,這些算法的使用也是通過轉換器的方式進行的。
sklearn的decomposition模塊中提供了PCA類,可實現對數據集進行PCA降維,PCA類的基本使用格式如下。?
?class sklearn.decomposition.PCA(n_components=None, *, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None)
| 參數名稱 | 參數說明 |
| n_components | 接收int、float、'mle'。表示降維后要保留的特征緯度數目。若未指定參數值,則表示所有特征均會被保留下來;若傳入為int型參數值,則表示將原始數據降低到n個維度;若傳入為float型參數值,則將根據樣本特征方差來決定降維后的維度數;若賦值為“mle”,則將會使用MLE算法來根據特征的方差分布情況自動選擇一定數量的主成分特征來降維。默認為None |
| copy | 接收bool。表示是否在運行算法時將原始訓練數據進行復制。若為True,則運行算法后原始訓練數據的值不會有任何改變;若為False,則運行算法后原始訓練數據的值將會發生改變。默認為True |
| whiten | 接收bool。表示對降維后的特征進行標準化處理,使得具有相同的方差。默認為False |
| svd_solver | 接收str。表示使用的SVD算法,可選randomized、full、arpack、auto。randomized一般適用于數據量大,數據維度多,同時主成分數目比例又較低的PCA降維。full是使用SciPy庫實現的傳統SVD算法。arpack和randomized的適用場景類似,區別在于,randomized使用的是sklearn自己的SVD實現,而arpack直接使用了SciPy庫的sparse?SVD實現。auto則代表PCA類會自動在上述3種算法中去權衡,選擇一個合適的SVD算法來降維。默認為auto |
二、 構建并評價聚類模型
(一)、使用sklearn估計器構建聚類模型
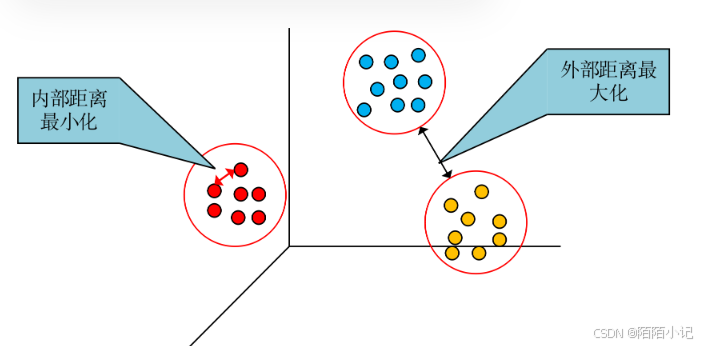
聚類的輸入是一組未被標記的樣本,聚類根據數據自身的距離或相似度將它們劃分為若干組,劃分的原則是組內(內部)距離最小化,而組間(外部)距離最大化,如圖所示。
常用的聚類算法及其類別如下表所示。
| 算法類別 | 包括的主要算法 |
| 劃分(分裂)方法 | K-Means算法(K-平均)、K-MEDOIDS算法(K-中心點)和CLARANS算法(基于選擇的算法) |
| 層次分析方法 | BIRCH算法(平衡迭代規約和聚類)、CURE算法(代表點聚類)和CHAMELEON算法(動態模型) |
| 基于密度的方法 | DBSCAN算法(基于高密度連接區域)、DENCLUE算法(密度分布函數)和OPTICS算法(對象排序識別) |
| 基于網格的方法 | STING算法(統計信息網絡)、CLIOUE算法(聚類高維空間)和WAVE-CLUSTER算法(小波變換) |
?sklearn常用的聚類算法模塊cluster提供的聚類算法及其適用范圍如下表所示。
| 算法名稱 | 參數 | 適用范圍 | 距離度量 |
| K-Means | 簇數 | 可用于樣本數目很大、聚類數目中等的場景 | 點之間的距離 |
| Spectral?clustering | 簇數 | 可用于樣本數目中等、聚類數目較小的場景 | 圖距離 |
| Ward?hierarchical?clustering | 簇數 | 可用于樣本數目較大、聚類數目較大的場景 | 點之間的距離 |
| Agglomerative?clustering | 簇數、鏈接類型、距離 | 可用于樣本數目較大、聚類數目較大的場景 | 任意成對點線圖間的距離 |
聚類算法模塊cluster提供的聚類算法及其適用范圍續表。
| 算法名稱 | 參數 | 適用范圍 | 距離度量 |
| DBSCAN | 半徑大小、最低成員數目 | 可用于樣本數目很大、聚類數目中等的場景 | 最近的點之間的距離 |
| Birch | 分支因子、閾值、可選全局集群 | 可用于樣本數目很大、聚類數目較大的場景 | 點之間的歐式距離 |
聚類算法實現需要使用sklearn估計器(estimator)。
sklearn估計器擁有fit()和predict()兩個方法,其說明如下表所示。
| 方法名稱 | 方法說明 |
| fit() | fit()方法主要用于訓練算法。該方法可接收用于有監督學習的訓練集及其標簽兩個參數,也可以接收用于無監督學習的數據 |
| predict() | predict()方法用于預測有監督學習的測試集標簽,亦可以用于劃分傳入數據的類別 |
?(二)、使用sklearn轉換器進行數據預處理與降維
TSNE類
使用customer數據集,通過sklearn估計器構建K-Means聚類模型,對客戶群體進行劃分。
并使用sklearn的manifold模塊中的TSNE類可實現多維數據的可視化展現功能,查看聚類效果,TSNE類的基本使用格式如下。
class sklearn.manifold.TSNE(n_components=2, *, perplexity=30.0, early_exaggeration=12.0, learning_rate=200.0, n_iter=1000, n_iter_without_progress=300, min_grad_norm=1e-07, metric='euclidean', init='random', verbose=0, random_state=None, method='barnes_hut', angle=0.5, n_jobs=None, square_distances='legacy')
import pandas as pd
from sklearn.manifold import TSNE
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt# 讀取數據集
filepath = 'D:\Desktop\data\customer.csv'
customer = pd.read_csv(filepath, encoding='gbk')
customer_data = customer.iloc[:, :-1]
customer_target = customer.iloc[:, -1]
# Kmeans聚類
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=6,random_state=6).fit(customer_data)
# 使用TSNE進行數據降維,降成兩維
tsne = TSNE(n_components=2, init='random',random_state=2).fit(customer_data)
df = pd.DataFrame(tsne.embedding_) # 將原始數據轉
df['labels'] = kmeans.labels_ # 將聚類結果存儲進df
# 提取不同標簽的數據
df1 = df[df['labels'] == 0]
df2 = df[df['labels'] == 1]
df3 = df[df['labels'] == 2]
df4 = df[df['labels'] == 3]
df5 = df[df['labels'] == 4]
df6 = df[df['labels'] == 5]# 繪制圖形
fig = plt.figure(figsize=(9, 6)) # 設定空白畫布,為
# 用不同的顏色表示不同數據
plt.plot(df1[0], df1[1], 'bo', df2[0], df2[1], 'r*',df3[0], df3[1], 'gD', df4[0], df4[1], 'kD',df5[0], df5[1], 'ms', df6[0], df6[1], 'co' )
plt.show() # 顯示圖片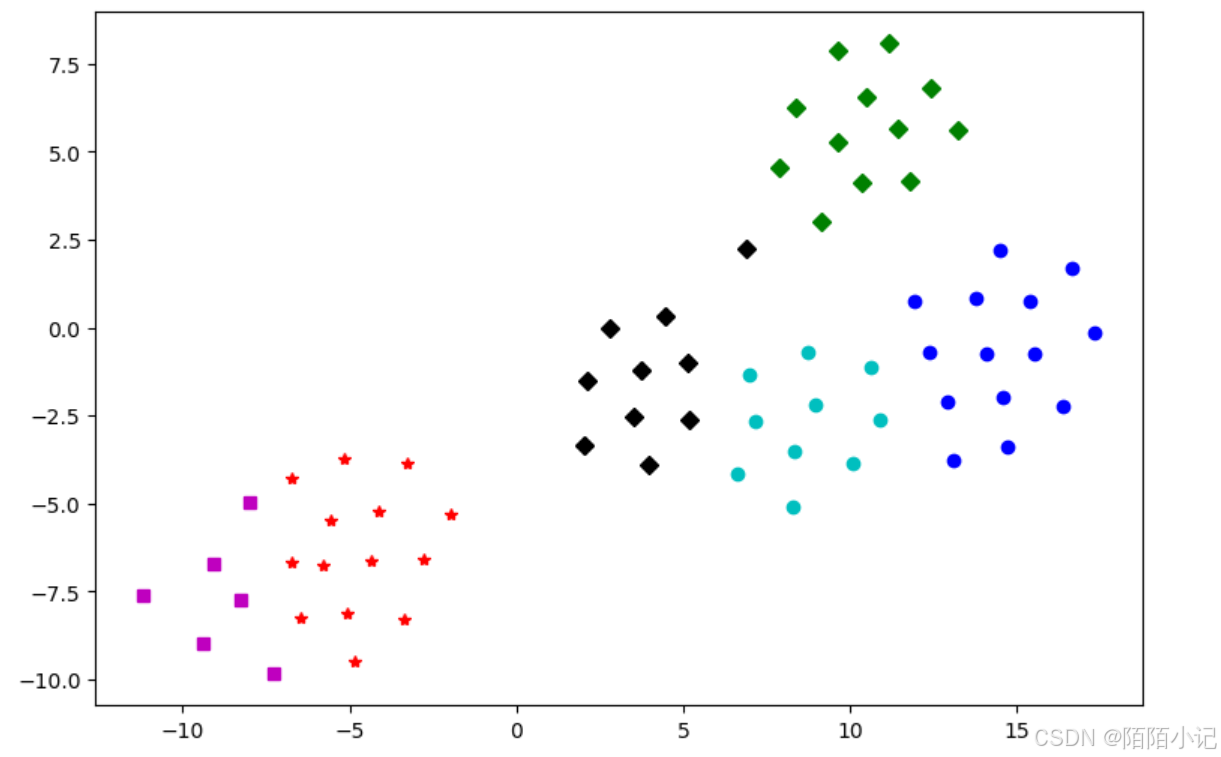
(三)、評價聚類模型
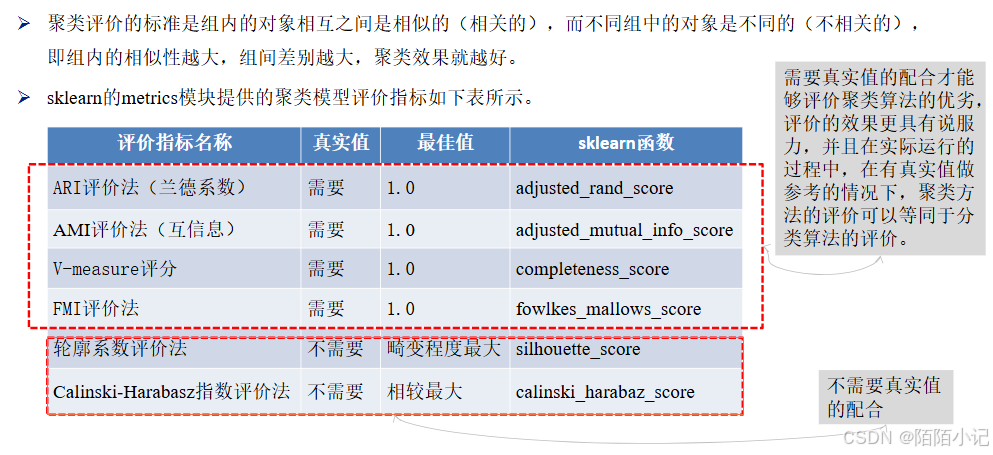
除了輪廓系數評價法以外的評價方法,在不考慮業務場景的情況下都是得分越高,其效果越好,最高分值為1。
而輪廓系數評價法則需要判斷不同類別數目情況下的輪廓系數的走勢,尋找最優的聚類數目。
綜合以上聚類評價方法,在真實值作為參考的情況下,幾種方法均可以很好地評估聚類模型。
在沒有真實值作為參考的時候,輪廓系數評價法和Calinski-Harabasz指數評價法可以結合使用。?
from sklearn.metrics import fowlkes_mallows_score
for i in range(1, 7):# 構建并訓練模型kmeans = KMeans(n_clusters=i, random_state=6).fit(customer_data) score = fowlkes_mallows_score(customer_target, kmeans.labels_)print('customer數據聚%d類FMI評價分值為:%f' % (i, score))from sklearn.metrics import silhouette_score
silhouettteScore = []
for i in range(2, 10):# 構建并訓練模型kmeans = KMeans(n_clusters=i,random_state=6).fit(customer_data) score = silhouette_score(customer_data, kmeans.labels_)silhouettteScore.append(score)
plt.figure(figsize=(10, 6))
plt.plot(range(2, 10), silhouettteScore,
linewidth=1.5, linestyle='-')plt.show()?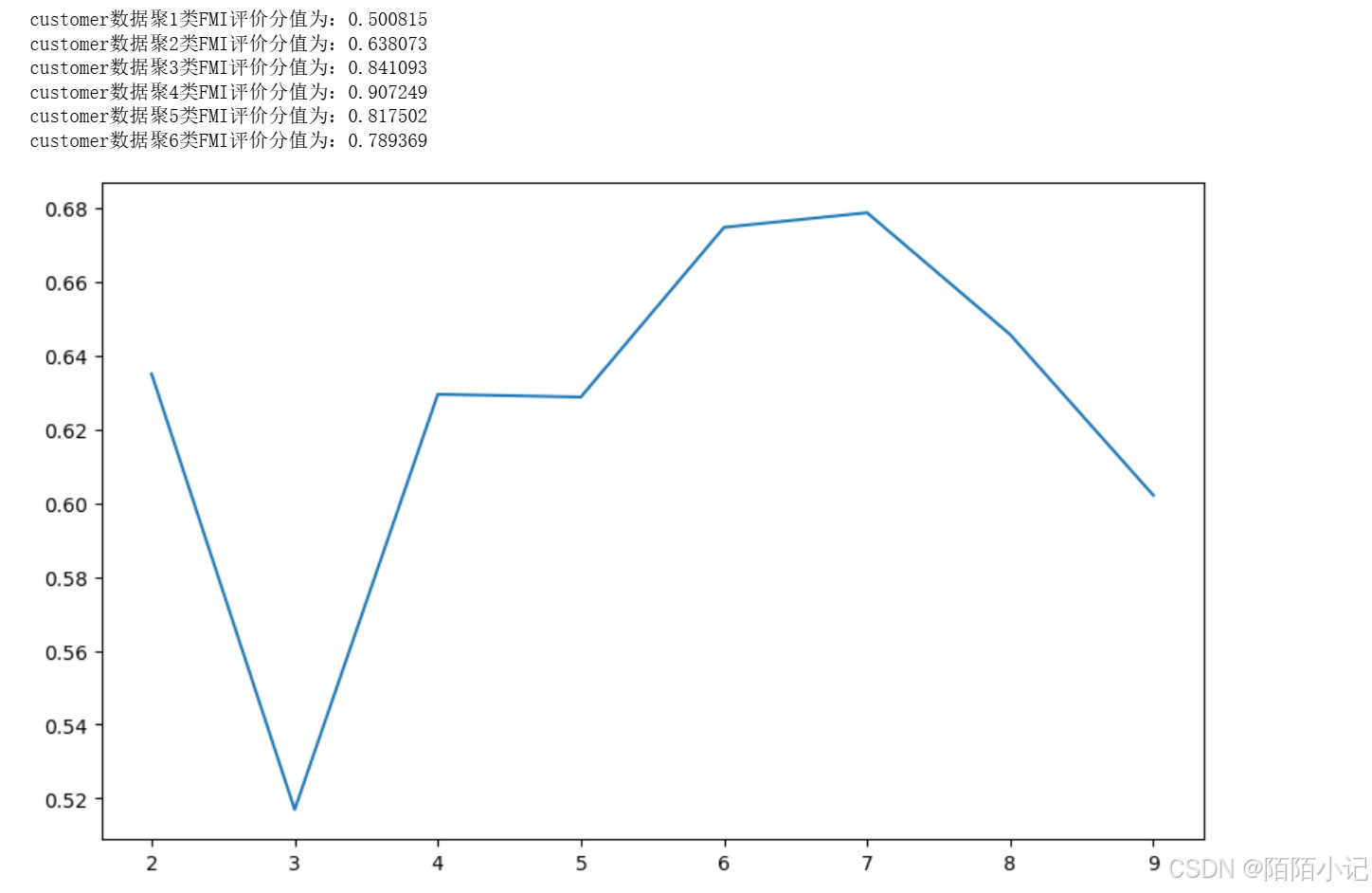



:String接口實踐+底層的模擬實現(中篇))


![題海拾貝:P1208 [USACO1.3] 混合牛奶 Mixing Milk](http://pic.xiahunao.cn/題海拾貝:P1208 [USACO1.3] 混合牛奶 Mixing Milk)
)





)





