
<------最重要的是訂閱“魯班模錘”------>
當我們看到一張照片時,大腦會自動分析其中的空間關系——哪個物體在前,哪個在后,左邊是什么,右邊是什么。但對于當今最先進的AI系統來說,這種看似簡單的空間理解卻是一個巨大的挑戰。Meta FAIR和香港中文大學的研究團隊最近發布的Multi-SpatialMLLM項目,正在試圖解決這個根本性問題。
現有的多模態大語言模型雖然在圖像識別和文本理解方面表現出色,但在空間推理上卻存在嚴重缺陷。這些模型往往連最基本的左右區分都會出錯,更不用說理解復雜的3D空間關系了。造成這種現象的根本原因在于,絕大多數AI訓練都基于單張圖像,就像讓一個人只通過一扇窗戶觀察整個世界一樣,視野必然受限。
隨著AI在機器人技術、自動駕駛、增強現實等領域的應用需求日益增長,空間理解能力的缺失成為了制約其發展的關鍵瓶頸。機器人需要準確理解環境中物體的位置關系才能有效執行任務,自動駕駛系統必須精確判斷道路、車輛和行人的空間分布才能安全行駛。

空間理解的技術突破
Multi-SpatialMLLM的核心創新在于將AI的視覺理解從單張圖像擴展到多張圖像的協同分析。這種方法模仿了人類的視覺系統——我們通過雙眼產生立體視覺,通過頭部和身體的移動獲得不同視角,然后大腦整合這些信息形成完整的空間認知。
-
深度感知(Depth Perception):理解物體離鏡頭的遠近;
-
視覺對應(Visual Correspondence):識別同一物體在不同圖像中的位置對應;
-
動態感知(Dynamic Perception):推斷相機或物體的運動方向和幅度。
研究團隊設計了一個包含三個核心組件的框架:深度感知、視覺對應和動態感知。深度感知讓AI能夠判斷物體距離的遠近,視覺對應使AI能在不同視角間建立像素點的對應關系,動態感知則賦予AI捕捉相機和物體運動信息的能力。這三個組件的協同工作,使AI首次具備了真正的多幀空間理解能力。

MultiSPA
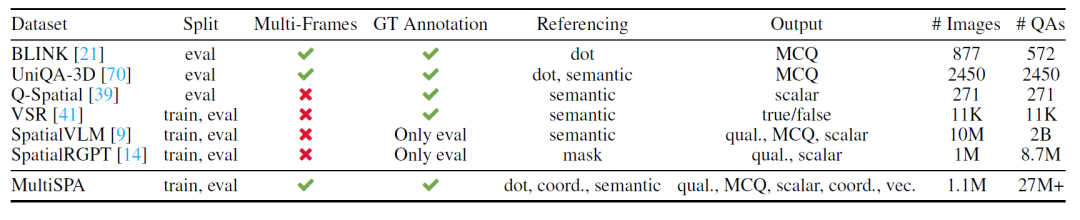
為了訓練AI系統,團隊構建了MultiSPA數據集,這是一個包含超過2700萬樣本的大規模空間理解數據集。數據集的構建過程體現了研究團隊的匠心獨運。
-
數據來自真實世界的3D/4D圖像集,不是合成或模擬數據;
-
自動采樣圖像對,確保畫面有足夠重疊與變化;
-
利用點云反投影技術建立像素級別的對應關系,實現空間和時間的精準對齊;
-
借助GPT-4o自動生成問題與答案模板,涵蓋定性描述與定量坐標、向量等多種形式;
-
支持用像素點、語義標簽、坐標等多種方式描述問題答案。
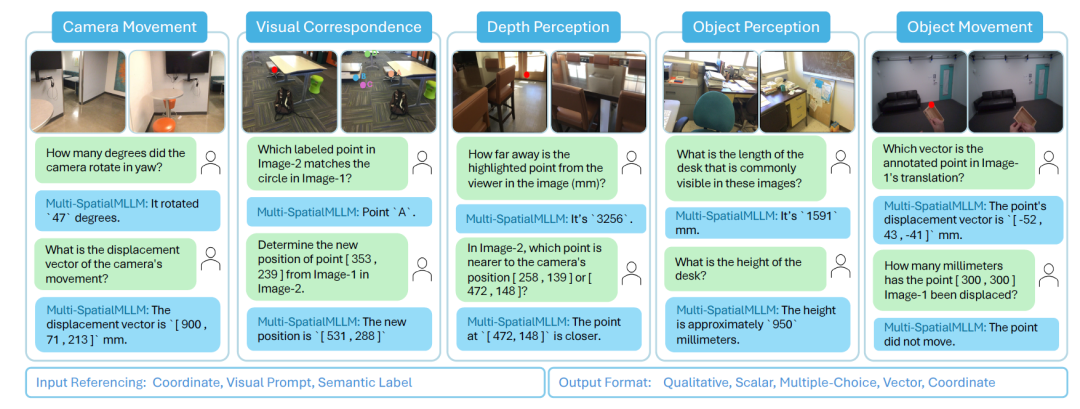
相機運動感知任務設計了從粗粒度到細粒度的九種不同難度級別,從簡單的方向判斷到復雜的位移向量預測。物體運動感知任務則要求AI跟蹤特定物體在不同幀間的運動軌跡。最具挑戰性的物體尺寸感知任務需要AI整合多張圖像的信息來推斷物體的真實尺寸。
數據生成過程充分利用了真實世界的3D場景數據,包括室內場景數據集ScanNet和動態場景數據集ADT、Panoptic Studio等。通過精密的3D-2D投影算法,研究團隊確保生成的訓練數據符合真實的幾何約束。他們還設計了巧妙的圖像對選擇策略,選擇重疊度在6%到35%之間的圖像對進行訓練,既保證了足夠的空間關聯性,又維持了視角的多樣性。

精妙的技術架構
Multi-SpatialMLLM基于InternVL2-8B模型構建,這個選擇經過了仔細考量。相比其他流行的多模態模型,InternVL2在遵從指令方面表現更為出色,為后續的空間理解訓練奠定了良好基礎。
訓練策略采用了高效的LoRA(Low-Rank Adaptation)微調方法,只更新語言模型骨干網絡的參數,而保持圖像編碼器和投影層凍結。這種設計既減少了訓練成本,又避免了災難性遺忘問題,確保模型在獲得空間理解能力的同時保持原有的通用視覺理解能力。
數據格式遵循標準的多模態大語言模型訓練范式,采用問答對的形式。為了處理多樣化的輸出格式,團隊設計了統一的答案提取機制,支持從定性描述到精確坐標的各種回答類型。像素坐標的歸一化處理解決了不同分辨率圖像的兼容性問題,確保模型能夠處理各種尺寸的輸入圖像。
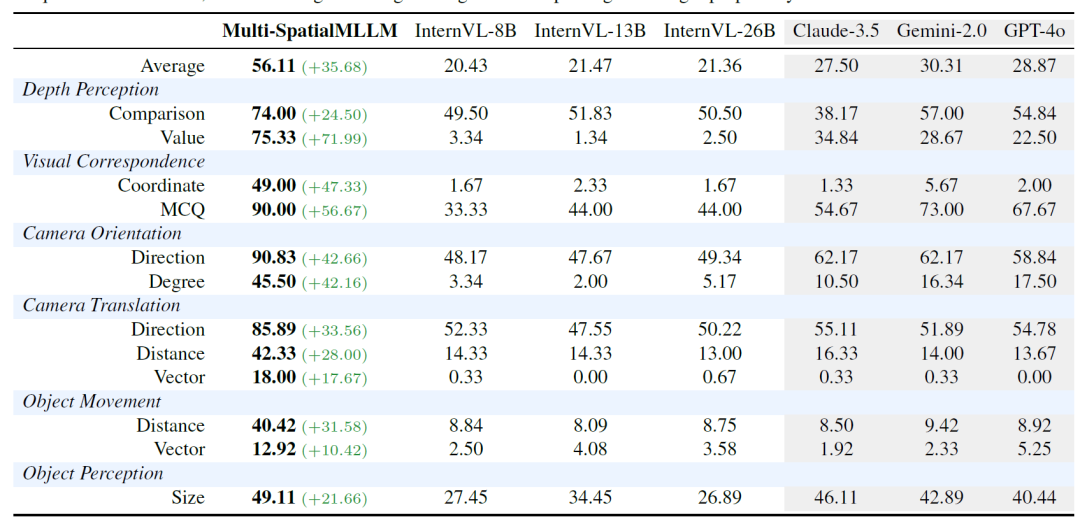
Multi-SpatialMLLM在MultiSPA基準測試中展現出了令人矚目的性能提升。相比基礎模型,該系統在所有空間理解任務上都實現了顯著改進,平均準確率提升了36%。在相對簡單的定性任務上,模型達到了80-90%的準確率,而基礎模型僅能達到50%左右。
更為重要的是,在極具挑戰性的相機運動向量預測任務上,Multi-SpatialMLLM達到了18%的準確率,而其他基線模型的表現幾乎為零。這種定量的空間推理能力對于實際應用具有重要意義,為機器人導航、自動駕駛等應用提供了技術基礎。
為了驗證模型的泛化能力,研究團隊在外部基準BLINK上進行了零樣本評估。結果顯示,Multi-SpatialMLLM在從未見過的數據上仍然保持了優異性能,平均準確率比基礎模型提升26.4%,甚至超越了GPT-4o、Claude-3.5等大型商業模型。這表明模型學到的空間理解能力具有良好的可遷移性。
同時,在標準的視覺問答基準測試中,Multi-SpatialMLLM保持了與原始模型相當的性能,證明專業化訓練并沒有損害模型的通用能力。這種平衡對于實際部署至關重要,用戶既需要專業的空間理解能力,也需要保持AI助手的全面性。

可擴展性與頓悟現象
研究團隊通過系統性實驗驗證了Multi-SpatialMLLM的可擴展性。隨著訓練數據從50萬樣本增加到250萬樣本,26B參數模型在相機運動向量預測任務上的準確率從0.67%大幅提升至44%。這種線性的性能提升表明,更大規模的數據訓練有望帶來進一步的性能改進。

更有趣的是,研究發現了類似大語言模型的頓悟現象。在多選視覺對應任務中,只有26B參數的大型模型能夠有效學習困難樣本,而8B和13B的模型即使在困難樣本上訓練也無法獲得提升。這種現象表明,某些高級的空間推理能力可能需要足夠大的模型容量才能頓悟。
多任務學習的協同效應也得到了驗證。當將相機運動任務與其他任務的數據混合訓練時,模型在相機運動預測上的表現從9.3%提升到18%。類似地,物體運動預測任務在加入其他任務數據后,準確率從17.5%提升到22.04%。這種跨任務的正向遷移表明,不同類型的空間理解能力之間存在內在聯系,多樣化的訓練任務能夠相互促進。

真實世界應用驗證
研究團隊通過實際的機器人場景驗證了Multi-SpatialMLLM的實用性。

在一個涉及機械臂堆疊積木的任務中,當被問及靜態藍色積木的移動情況時,GPT-4o和基礎模型都給出了錯誤答案,而Multi-SpatialMLLM準確識別出積木并未移動。這種準確的空間感知能力對于機器人的安全操作至關重要。
Multi-SpatialMLLM的成功不僅僅是一個技術指標的提升,更代表了AI理解世界方式的根本性變革。Multi-SpatialMLLM通過多幀協同分析,實現了從"看圖識物"到"立體思維"的跨越。這種技術突破的意義在于,它首次讓AI具備了類似人類的空間認知能力。人類的視覺系統天然具備整合多視角信息的能力,這種能力是我們在3D世界中導航和操作的基礎。
Multi-SpatialMLLM通過技術手段復現了這種能力,為AI在現實世界的廣泛應用鋪平了道路。在自動駕駛領域,這種多幀空間理解能力對于環境感知和路徑規劃具有重要價值。傳統的自動駕駛系統主要依賴激光雷達等專用傳感器獲取3D信息,而Multi-SpatialMLLM展示了僅通過攝像頭就能實現復雜空間理解的可能性,有望降低自動駕駛系統的成本和復雜度。
在增強現實和虛擬現實應用中,精確的空間理解能力是實現自然交互的關鍵。Multi-SpatialMLLM能夠幫助AR系統更準確地在現實場景中放置虛擬物體,為VR系統提供更真實的空間感知。
醫療影像領域也是一個重要的應用方向。Multi-SpatialMLLM的多視角整合能力可以幫助醫生從多個2D影像重建3D解剖結構,為手術規劃和導航提供更精確的空間信息。

更多專欄請看:
-
LLM背后的基礎模型
-
如何優雅的談論大模型
-
體系化的通識大模型




)













)
