說明:這是一個機器學習實戰項目(附帶數據+代碼+文檔+視頻講解),如需數據+代碼+文檔+視頻講解可以直接到文章最后關注獲取。

1.項目背景
心血管疾病是全球范圍內導致死亡的主要原因之一,每年有數百萬人因此失去生命。在眾多的心臟病中,冠心病尤為常見,它是由向心臟供血的冠狀動脈發生硬化或阻塞所引起的。早期發現心臟病的風險因素并進行有效干預對于降低發病率和死亡率至關重要。然而,由于心臟病的發生受到多種復雜因素的影響,包括但不限于年齡、性別、血壓、膽固醇水平等,傳統的診斷方法往往存在一定的局限性。基于此,利用先進的數據分析技術,特別是邏輯回歸模型,對心臟病風險進行預測成為了研究熱點之一。
邏輯回歸作為一種廣泛應用于醫學領域的統計分析方法,能夠有效地處理二分類問題,并通過概率形式輸出結果,非常適合用于心臟病風險評估。通過收集患者的各種生理指標數據,如年齡、性別、體重指數(BMI)、血壓、血糖水平等,邏輯回歸模型可以學習到這些特征與心臟病發作之間的關系,從而幫助醫生更準確地識別高危人群。此外,隨著機器學習解釋性的日益重視,SHAP(Shapley Additive exPlanations)值作為一種新興的解釋工具,能夠為每個預測提供詳細的貢獻度分析,使得模型不僅限于預測,還能解釋為何做出這樣的預測,這對于醫療決策支持系統尤為重要。
本項目旨在利用R語言實現一個基于邏輯回歸的心臟病檢測模型,并采用SHAP值來解釋模型的預測結果。首先,我們將從公開的數據集中獲取心臟病相關的多維度數據,然后進行必要的數據清洗和預處理工作,以確保數據的質量和一致性。接著,使用邏輯回歸模型訓練數據,并評估其性能。最后,借助SHAP值深入分析各特征對心臟病預測的重要性及其影響方向,進而提升模型的透明度和可解釋性。通過這一系列步驟,我們期望不僅能提高心臟病預測的準確性,還能為臨床醫生提供有價值的參考信息,輔助制定個性化的治療方案。
本項目通過R基于邏輯回歸模型實現心臟病檢測及SHAP值解釋項目實戰。 ????????????
2.數據獲取
本次建模數據來源于網絡(本項目撰寫人整理而成),數據項統計如下:
| 編號 | 變量名稱 | 描述 |
| 1 | age | 病人的年齡(以年為單位) |
| 2 | sex | 病人性別 (1 = 男, 0 = 女) |
| 3 | cp | 胸痛類型 (1: 典型心絞痛, 2: 非典型心絞痛, 3: 無心絞痛, 4: 無癥狀) |
| 4 | trestbps | 入院時的靜息血壓(毫米汞柱) |
| 5 | chol | 血清中的膽固醇含量(毫克/分升) |
| 6 | fbs | 空腹血糖水平 (> 120 mg/dl 為 1, 否則為 0) |
| 7 | restecg | 靜息心電圖結果 (0: 正常, 1: ST-T 波異常, 2: 可能或肯定的左室肥大) |
| 8 | thalach | 達到的最大心率 |
| 9 | exang | 運動誘發的心絞痛 (1 = 是, 0 = 否) |
| 10 | oldpeak | 相對于休息的舊峰 ST 抑制(連續值) |
| 11 | slope | 峰值運動 ST 段的斜率 (1: 上坡, 2: 平坦, 3: 下坡) |
| 12 | ca | 通過熒光透視顯示的主要血管數目(0-3) |
| 13 | thal | 心肌灌注顯像的結果 (3 = 正常, 6 = 固定缺陷, 7 = 可逆缺陷) |
| 14 | y | 0 = 沒有心臟病病,1 = 有心臟病 |
數據詳情如下(部分展示):

3.數據預處理
3.1?查看數據
使用head()方法查看前五行數據:

關鍵代碼:
![]()
3.2數據缺失查看
使用colSums方法統計數據缺失信息:

從上圖可以看到,總共有14個變量,數據中無缺失值。
關鍵代碼:

3.3數據描述性統計
通過summary方法來查看數據的平均值、最小值、分位數、最大值。
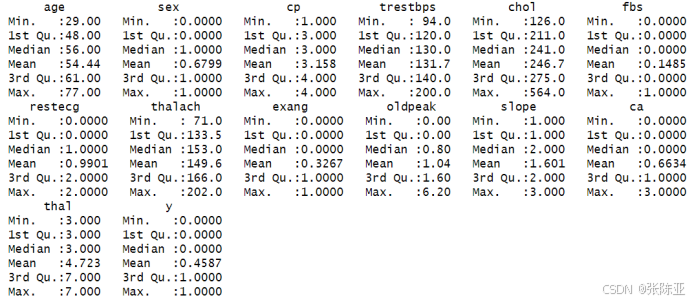
關鍵代碼如下: ?

4.探索性數據分析
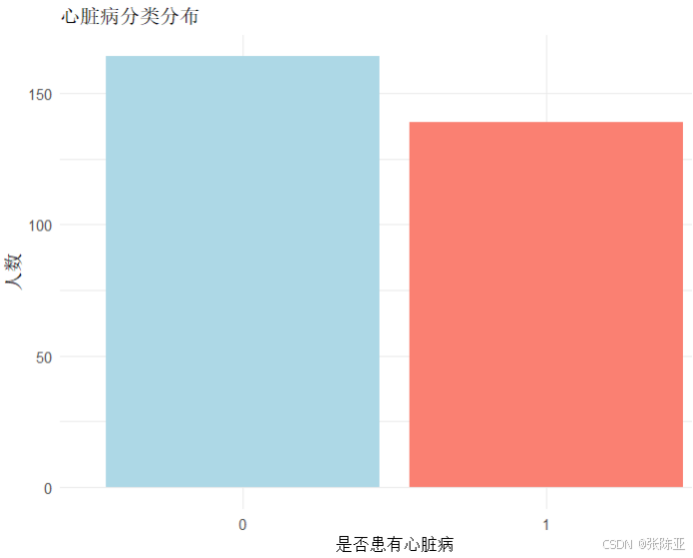
4.1?因變量柱狀圖
用ggplot工具繪制柱狀圖:
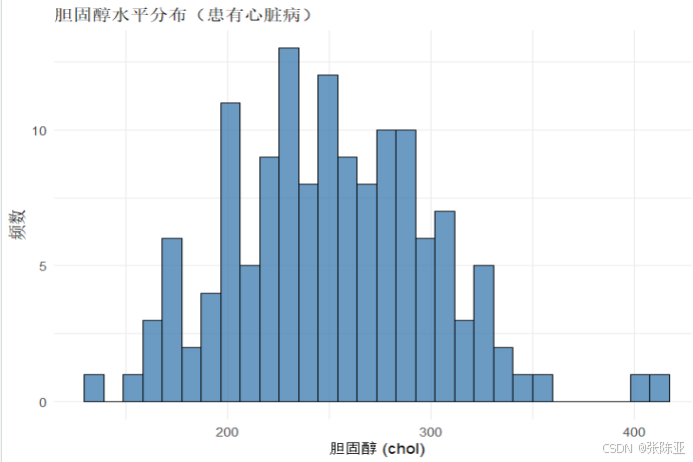
4.2 y=1樣本chol變量分布直方圖
用ggplot工具繪制直方圖:
4.3 相關性分析
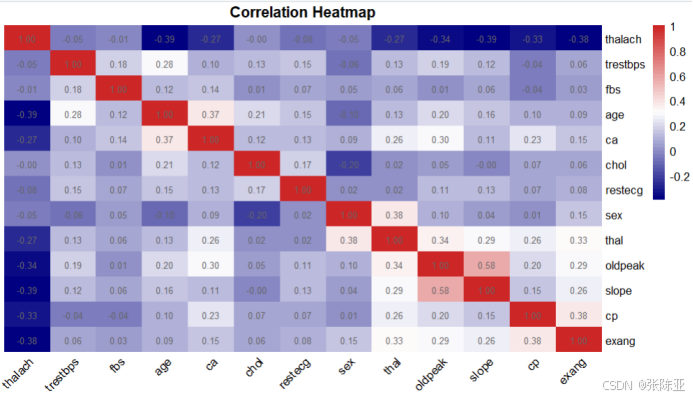
從上圖中可以看到,數值越大相關性越強,正值是正相關、負值是負相關。
5.特征工程
5.1 啞特征處理
啞特征處理,即將類別型變量轉換為若干二進制變量,以利于統計模型中使用,有效提高模型準確性與解釋力。
關鍵代碼如下:
![]()
處理結果部分展示:
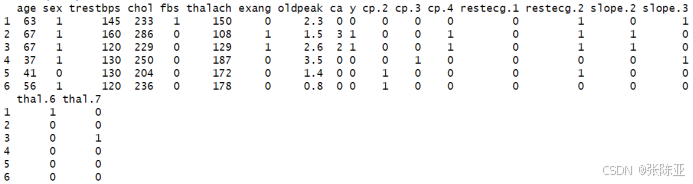
5.2?數據集拆分
通過subset方法按照80%訓練集、20%驗證集進行劃分,關鍵代碼如下:

6.構建邏輯回歸分類模型?
主要通過R基于邏輯回歸模型實現心臟病檢測,用于目標分類。 ??????????
6.1 構建模型
| 模型名稱 | 模型參數 |
| 邏輯回歸分類模型???? | y ~ . |
| data = data | |
| family = binomial(link = 'logit') |
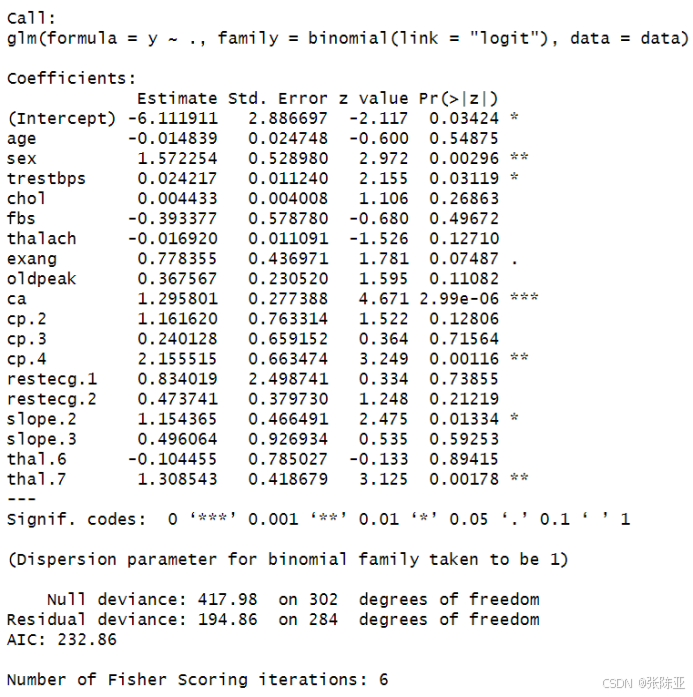
6.2 模型摘要信息
7.模型評估
7.1評估指標及結果
評估指標主要包括準確率、查準率、查全率、F1分值等等。
| 模型名稱 | 指標名稱 | 指標值 |
| 測試集 | ||
| 邏輯回歸分類模型?? | 準確率 | 0.8360656 |
| 查準率 | 0.8285714 | |
| 查全率 | 0.8787879 | |
| F1分值? | 0.8529412 | |
從上表可以看出,F1分值為0.8529,說明邏輯回歸模型效果良好。 ??????????????
關鍵代碼如下:

7.2 混淆矩陣
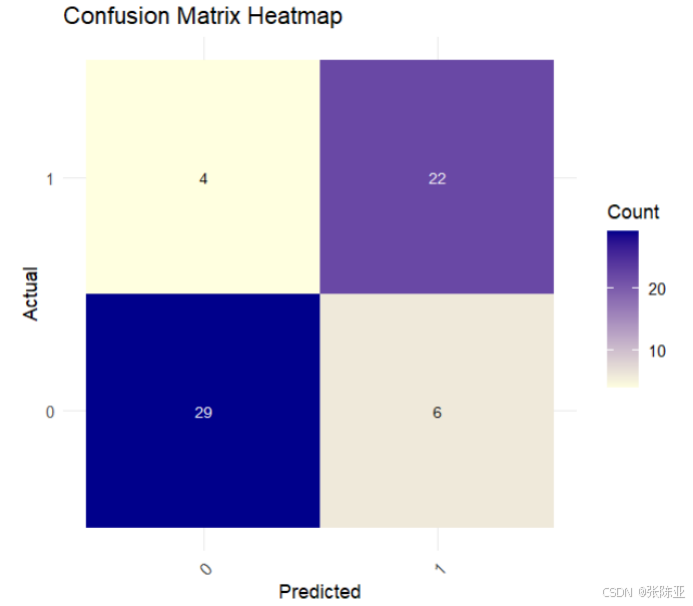
從上圖可以看出,實際為0預測不為0的 有6個樣本,實際為1預測不為1的 有4個樣本,模型效果良好。 ???
7.3 SHAP解釋圖
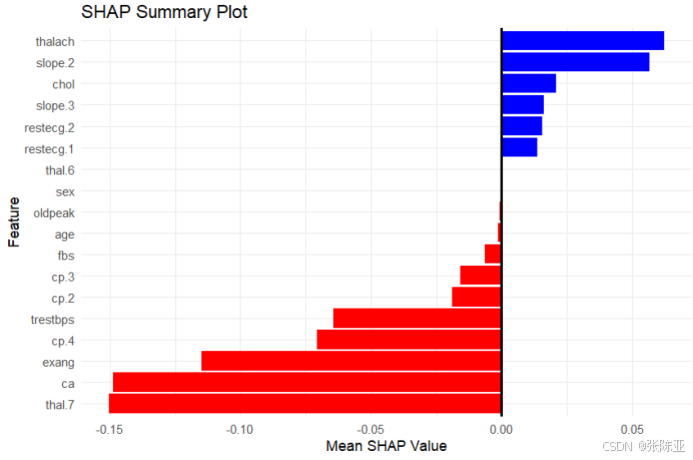
SHAP圖通常用來展示特征對模型預測的貢獻程度,從上圖可以看出,藍色代表正向影響,紅色代表負向影響, SHAP值越大對模型的貢獻越大。
8.結論與展望
綜上所述,本文采用了通過邏輯回歸分類算法來構建分類模型,最終證明了我們提出的模型效果良好。此模型可用于日常產品的建模工作。



游記)


)





)



)
與權限)
入門學習筆記)
)