目錄
一,對比式自監督學習
1.1 簡介
1.2 常見算法
1.2.1?SimCLR (2020)
1.2.2?MoCo (2020)
1.2.3?BYOL (2021)
1.2.4?SimSiam (2021)
1.2.5?CLIP (2021)
1.2.6?DINO (2021)
1.2.7?SwAV (2020)
二,代碼邏輯分析
2.1?整體目標與流程
2.2??數據增強:生成 “雙胞胎” 圖像
2.3 編碼器:從圖像到 “特征描述”
2.4 對比損失:讓 “雙胞胎” 特征靠近
2.5?訓練過程:反復練習 “找不同”
2.6?線性評估:用學到的特征 “考試”
三,測試結果
3.1 對比學習結果
3.2 總結
四,完整代碼
一,對比式自監督學習
1.1 簡介
????????對比式自監督學習是一種通過構造 “正樣本對”(同一數據的不同增強視圖)和 “負樣本對”(不同數據的視圖)來迫使模型學習數據本質特征的無監督學習方法。其核心流程包括數據增強生成正樣本、編碼器提取特征、對比損失函數拉近正樣本 / 推遠負樣本,最終將預訓練特征遷移到下游任務。該方法無需人工標注,能有效利用海量無標注數據,學習到對視角、光照等變化魯棒的通用特征,廣泛應用于圖像、文本等領域,代表算法有 SimCLR、MoCo、CLIP 等,為解決數據標注成本高、特征泛化性不足等問題提供了高效方案。
1.2 常見算法
1.2.1?SimCLR (2020)
核心思想:通過多樣化數據增強和大規模對比學習學習圖像特征。
(假設你在動物園觀察動物,SimCLR 讓你從不同角度(正面、側面、背面)、不同光線(白天、黑夜)觀察同一只動物,然后告訴你:“這些都是同一只動物,要記住它的本質特征!”同時,給你看其他動物的照片,告訴你:“這些和前面的不是同一種,要區分開來!”)
特點:
????????數據增強組合:隨機裁剪、翻轉、顏色抖動、高斯模糊等。(對同一張圖片做各種 “變形”(裁剪、翻轉、變色),生成很多版本。)
????????非線性投影頭:使用 MLP 將特征映射到對比空間。
????????NT-Xent 損失:溫度縮放的交叉熵損失,增大正負樣本區分度。
????????大批量訓練:需 8192 樣本 /batch 才能達到最佳效果。(每次訓練看大量圖片,強行記住 “哪些是同類,哪些不是”。)
應用場景:圖像分類、目標檢測、語義分割的預訓練。
1.2.2?MoCo (2020)
核心思想:通過動量編碼器和動態負樣本隊列解決對比學習中的負樣本數量限制。(你在動物園遇到一個 “記憶助手”,它會幫你記住之前看過的動物特征。當你看到新動物時,它會提醒你:“這只和之前看到的老虎很像嗎?不像?那就是新物種!”)
特點:
????????動量更新:使用指數移動平均 (EMA) 緩慢更新編碼器參數,保持負樣本特征穩定性。
????????隊列機制:維護一個固定大小的負樣本特征隊列,突破 batch size 限制。(維護一個 “動物特征庫”,不斷更新和比對。不需要一次性看所有圖片,用 “老照片” 當負樣本。)
????????端到端訓練:無需多機并行即可處理大規模負樣本。
應用場景:小批量訓練、視頻理解(利用時序信息構建隊列)。算力有限,但想利用歷史經驗的情況。
1.2.3?BYOL (2021)
核心思想:無需負樣本,通過 “自舉” 機制學習特征。(你照鏡子,鏡子里的 “你” 就是目標。你需要調整自己的姿勢、表情,讓鏡子里的 “你” 和真實的你越來越像。只關注 “自己和自己的一致性”,不關心別人長什么樣。)
特點:
????????孿生網絡架構:在線網絡 (online network) 和目標網絡 (target network)。
????????預測頭:在線網絡增加預測頭,預測目標網絡生成的特征。
????????無負樣本:僅通過正樣本對 (同一圖像的不同視圖) 訓練,避免模型坍塌。
應用場景:計算資源有限場景、半監督學習。快速訓練、資源緊張的場景。
1.2.4?SimSiam (2021)
核心思想:證明對比學習無需負樣本,甚至無需孿生網絡權重共享。(你有兩個 “克隆人”,一個負責觀察動物(編碼器),另一個負責猜測觀察結果(預測頭)。兩個克隆人互相學習,但不共享記憶。)
特點:
????????停止梯度:預測頭的梯度不回傳到編碼器,防止模型坍塌。(兩個克隆人獨立學習,避免 “作弊”(模型坍塌)。)
????????極簡架構:僅需一個編碼器和預測頭,訓練速度快。(結構簡單,訓練高效,效果還不錯。)
????????無需負樣本隊列:依賴 “預測 - 編碼” 結構學習不變特征。
應用場景:輕量級預訓練、快速迭代實驗,快速實驗、不想折騰復雜模型的情況。
1.2.5?CLIP (2021)
核心思想:跨模態對比學習,對齊圖像與文本的語義空間。(你同時學習 “文字描述” 和 “圖片”,比如看到 “一只貓在沙發上” 的文字,就去找對應的圖片。時間久了,你能直接根據文字找到圖片,或者根據圖片寫出描述。)
特點:
????????多模態輸入:同時處理圖像和文本,學習圖文關聯。(同時學習圖像和文字,建立兩者的聯系。)
????????零樣本學習:通過文本描述直接分類圖像,無需訓練數據。(沒見過的東西也能分類,比如看到 “獨角獸” 的描述,能從圖片中找出獨角獸(即使沒見過)。)
????????大規模預訓練:在 4 億圖文對上訓練,泛化能力強。
應用場景:圖像檢索、多模態生成、零樣本任務遷移,多語言任務(文字描述可以是任何語言)
1.2.6?DINO (2021)
核心思想:通過自蒸餾學習視覺特征,無需標簽或對比對。(你是一個美術生,老師給你一張 “半成品” 的動物畫(教師網絡),讓你照著畫完(學生網絡)。通過不斷模仿老師的風格,你學會了如何畫動物的細節(如眼睛、毛發)。)
特點:
????????教師 - 學生架構:教師網絡生成偽標簽,指導學生網絡學習。(用 “教師模型” 指導 “學生模型”,不需要標簽。)
????????無監督注意力:自動發現圖像中的語義區域(如物體輪廓)。(自動關注圖像中的重要部分(如動物輪廓)。)
????????ViT 友好:特別適合 Vision Transformer 架構。
應用場景:目標檢測、實例分割的預訓練。基于 Transformer 的模型(如 ViT),擅長捕捉圖像的局部細節。
1.2.7?SwAV (2020)
核心思想:將對比學習與聚類相結合,無需負樣本隊列。(你在整理照片,把相似的動物照片放在同一個相冊(聚類)。然后,你用一個相冊的照片去猜測另一個相冊的分類,不斷調整分類規則。)
特點:
????????對比聚類:動態分配樣本到聚類中心,強制特征對齊。(先聚類,再對比,不需要顯式的負樣本。)
????????交換預測:用一個視圖的特征預測另一個視圖的聚類分配。(不需要維護大規模隊列,適合處理高維數據。)
????????內存高效:無需維護大規模負樣本隊列。
應用場景:高維特征學習、大規模圖像檢索、高維特征分析(如圖像的像素級特征)。
1.2.8 算法對比表
| 算法 | 負樣本需求 | 關鍵創新點 | 計算效率 | 應用領域 |
|---|---|---|---|---|
| SimCLR | 顯式需要 | 多樣化增強 + NT-Xent 損失 | 低 | 圖像基礎任務 |
| MoCo | 隊列機制 | 動量編碼器 + 動態隊列 | 中 | 小批量訓練、視頻 |
| BYOL | 無需 | 自舉機制 + 孿生網絡 | 高 | 資源受限場景 |
| SimSiam | 無需 | 停止梯度 + 極簡架構 | 高 | 快速實驗 |
| CLIP | 跨模態 | 圖文對齊 + 零樣本學習 | 極高 | 多模態任務 |
| DINO | 無對比對 | 自蒸餾 + 注意力機制 | 中 | 基于 ViT 的檢測 / 分割 |
| SwAV | 隱式對比 | 對比聚類 + 交換預測 | 中 | 高維特征學習 |
計算資源充足:優先使用 SimCLR 或 MoCo,利用大規模負樣本提升性能。
輕量級場景:選擇 BYOL 或 SimSiam,無需負樣本,訓練更高效。
多模態任務:使用 CLIP,支持圖文聯合推理。
基于 ViT 的模型:考慮 DINO,專為 Transformer 設計。
高維特征需求:嘗試 SwAV,結合聚類優化特征結構。
二,代碼邏輯分析
2.1?整體目標與流程
通俗解釋:
我們要讓模型在沒有標簽的情況下學習圖像的特征,就像小孩通過觀察不同角度的玩具來理解 “這是同一個東西”。然后用學到的特征完成分類任務(如識別 FashionMNIST 中的衣服類型)。
def main():# 1. 加載數據(無需標簽)train_loader = DataLoader(FashionMNIST(...))# 2. 預訓練:通過對比學習提取特征encoder = train_contrastive(encoder, projection_head, train_loader, ...)# 3. 測試:用線性分類器驗證特征質量linear_evaluation(encoder, train_loader, test_loader)2.2??數據增強:生成 “雙胞胎” 圖像
通俗解釋:
對同一張圖像做不同的 “變形”(裁剪、翻轉、變色等),生成一對 “雙胞胎”。模型需要學會:雖然外觀不同,但它們本質是同一個東西。
def get_transform():return transforms.Compose([transforms.RandomResizedCrop(28), # 隨機裁剪transforms.RandomHorizontalFlip(), # 隨機翻轉transforms.ColorJitter(0.4, 0.4, 0.4), # 顏色抖動transforms.GaussianBlur(3), # 模糊transforms.Normalize(...) # 歸一化])# 訓練時對每個圖像生成兩個視圖
view1 = get_transform()(image)
view2 = get_transform()(image)2.3 編碼器:從圖像到 “特征描述”
通俗解釋:
編碼器就像一個 “翻譯器”,把圖像(像素矩陣)轉化為計算機能理解的 “特征描述”(數字向量)。例如,把 “貓的圖片” 轉化為 “耳朵尖、眼睛圓、有胡須” 這樣的描述。
class ResNet18Encoder(nn.Module):def __init__(self, pretrained=False):super().__init__()# 加載預訓練的ResNet18并修改輸入通道resnet = models.resnet18(pretrained=pretrained)# 修改第一層卷積以適應單通道輸入(原輸入通道為3)resnet.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)# 移除最后的全連接層,保留特征提取部分self.features = nn.Sequential(*list(resnet.children())[:-1])self.projection_dim = 512 # ResNet18的輸出維度def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)return x2.4 對比損失:讓 “雙胞胎” 特征靠近
通俗解釋:
對比損失就像一個 “裁判”,它告訴模型:同一圖像的兩個視圖(雙胞胎)特征要相似,不同圖像的特征要遠離。
def contrastive_loss(z1, z2, temperature=0.1):# 計算所有樣本對的相似度sim_matrix = torch.matmul(z1, z2.T) / temperature# 標簽:正樣本對是對角線上的元素labels = torch.arange(batch_size).to(device)# 目標:最大化正樣本對的相似度,最小化負樣本對的相似度loss = F.cross_entropy(sim_matrix, labels)return loss2.5?訓練過程:反復練習 “找不同”
通俗解釋:
模型反復看大量圖像對,不斷調整自己的 “特征提取方式”,直到能準確區分 “雙胞胎” 和 “陌生人”。
def train_contrastive(encoder, projection_head, dataloader, optimizer, epochs=30):for epoch in range(epochs):for images, _ in dataloader: # 無需標簽!# 生成兩個視圖view1 = torch.stack([get_transform()(img) for img in images])view2 = torch.stack([get_transform()(img) for img in images])# 提取特征并計算損失z1 = projection_head(encoder(view1))z2 = projection_head(encoder(view2))loss = contrastive_loss(z1, z2)# 優化模型:調整參數,讓損失變小optimizer.zero_grad()loss.backward()optimizer.step()2.6?線性評估:用學到的特征 “考試”
通俗解釋:
凍結訓練好的編碼器(固定 “特征提取方式”),只訓練一個簡單的線性分類器(類似 “填空題”)。如果分類準確率高,說明編碼器學到的特征確實有用。
def linear_evaluation(encoder, train_loader, test_loader, epochs=15):encoder.eval() # 凍結編碼器,不再更新classifier = nn.Linear(256, 10).to(device) # 簡單線性分類器for epoch in range(epochs):for images, labels in train_loader:# 用編碼器提取特征(固定不變)with torch.no_grad():features = encoder(images)# 僅訓練分類器:將特征映射到類別logits = classifier(features)loss = F.cross_entropy(logits, labels)optimizer.zero_grad()loss.backward()optimizer.step()三,測試結果
3.1 對比學習結果
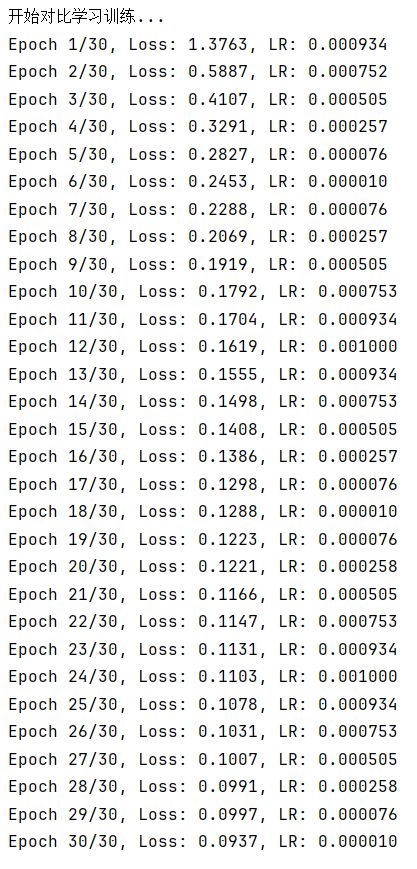
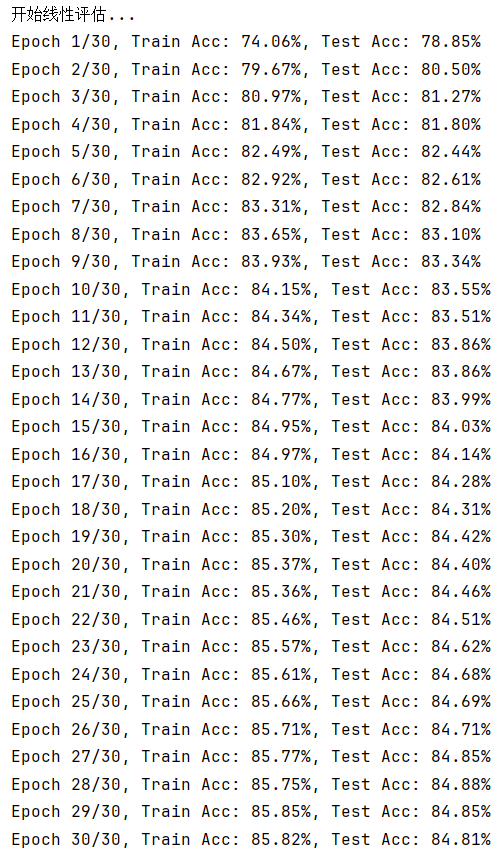
3.2 總結
????????相比使用更為簡單的判別式自監督學習,更復雜的對比式自監督學習的準確度反而下降了,SimCLR 的對比訓練就像是一場 “找相同與找不同” 的游戲。在這個游戲里,它先對同一張圖片施展 “變形魔法”,通過裁剪、旋轉、改變顏色等數據增強手段,變出多個 “長得不一樣但本質相同” 的視圖,把這些視圖配成對,就是正樣本對;而其他圖片的視圖,不管來自哪張圖,都被當作負樣本對。接著,對比損失函數就像一個 “裁判”,時刻盯著模型,要是模型把正樣本對的特征分得太開,或者把負樣本對的特征靠得太近,就要 “扣分”(增加損失值)。在不斷 “扣分” 和調整的過程中,模型慢慢學會把正樣本對的特征在 “特征空間” 里拉近,把負樣本對的特征推遠,最終掌握了提取通用特征的能力。
????????這種對比訓練在樣本超級多的數據集里特別 “如魚得水”。想象一下,如果數據集里只有寥寥幾張圖片,模型很容易被圖片里一些偶然出現的相似點誤導,比如兩張不同類別的圖片剛好都有一塊紅色區域,模型可能就錯誤地把它們歸為相似的。但當數據集里有成千上萬、甚至幾十萬上百萬張圖片時,同類圖片的數量足夠多,模型就能從大量同類樣本里總結出真正的共性特征,比如從海量貓的圖片里學到貓有尖耳朵、長胡須這些關鍵特點,而不是被某張圖片里貓身上的裝飾誤導。同時,豐富的負樣本也能讓模型見識到各種各樣不相似的情況,更好地區分不同類別,就像見過了所有動物,才能更準確地分辨出貓和狗。最終,模型構建出的特征空間,能讓相似的樣本自然地聚集在一起,不相似的樣本遠遠分開,為后續的圖像分類、檢索等任務,打下了堅實又可靠的基礎 。
? ? ? ? 對于fashionmnist數據集來說,其數據規模還遠小于需要使用simCLR算法的程度,在實際使用中,這種不太合適的算法選擇往往會事倍功半。
基于FashionMnist數據集的自監督學習(判別式自監督學習)-CSDN博客
四,完整代碼
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
from torch.optim.lr_scheduler import CosineAnnealingLR# 設置設備:優先使用GPU,否則使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# ----------------------
# 1. 數據增強(增強多樣性)
# ----------------------
def get_transform():"""創建一系列隨機變換,用于生成同一張圖片的不同視圖"""return transforms.Compose([transforms.RandomResizedCrop(28, scale=(0.7, 1.0)), # 隨機裁剪并調整大小,模擬不同視角transforms.RandomHorizontalFlip(), # 隨機水平翻轉transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8), # 隨機改變顏色transforms.RandomGrayscale(p=0.2), # 20%概率轉為灰度圖transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)), # 隨機高斯模糊,模擬模糊場景transforms.Normalize((0.1307,), (0.3081,)) # 標準化,確保數據分布一致])# ----------------------
# 2. 簡單編碼器(卷積網絡)
# ----------------------
class Encoder(nn.Module):"""將圖片轉換為特征向量的神經網絡"""def __init__(self):super().__init__()# 三層卷積提取特征,逐步增加通道數self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1) # 輸入通道1(灰度圖),輸出32self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) # 通道從32增加到64self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1) # 通道從64增加到128self.pool = nn.MaxPool2d(2, 2) # 最大池化層,降低空間尺寸self.fc = nn.Linear(128 * 3 * 3, 256) # 全連接層,將特征展平為256維向量def forward(self, x):# 卷積+激活+池化的三層處理x = self.pool(F.relu(self.conv1(x))) # 尺寸從28x28變為14x14x = self.pool(F.relu(self.conv2(x))) # 尺寸從14x14變為7x7x = self.pool(F.relu(self.conv3(x))) # 尺寸從7x7變為3x3x = x.view(-1, 128 * 3 * 3) # 將特征圖展平為一維向量x = self.fc(x) # 最后通過全連接層生成256維特征向量return x# ----------------------
# 3. 投影頭(增加歸一化)
# ----------------------
class ProjectionHead(nn.Module):"""將編碼器輸出的特征映射到對比學習的目標空間"""def __init__(self):super().__init__()self.fc1 = nn.Linear(256, 512) # 第一個全連接層,擴展到512維self.ln1 = nn.LayerNorm(512) # 層歸一化,加速訓練并提高穩定性self.relu = nn.ReLU() # 激活函數,引入非線性self.fc2 = nn.Linear(512, 128) # 第二個全連接層,壓縮到128維self.ln2 = nn.LayerNorm(128) # 層歸一化def forward(self, x):x = self.relu(self.ln1(self.fc1(x))) # 第一層處理x = self.ln2(self.fc2(x)) # 第二層處理,輸出128維向量return x# ----------------------
# 4. 對比損失函數(InfoNCE)
# ----------------------
def contrastive_loss(z1, z2, temperature=0.07):"""計算兩個特征向量之間的對比損失,使正樣本對更接近,負樣本對更遠離"""batch_size = z1.shape[0]z1 = F.normalize(z1, dim=1) # 歸一化特征向量,便于計算相似度z2 = F.normalize(z2, dim=1) # 歸一化特征向量# 構建正樣本對標簽:每個z1的正樣本是對應的z2,反之亦然positive = torch.cat([torch.arange(batch_size), torch.arange(batch_size)], dim=0).to(device)# 計算所有樣本對之間的相似度(點積),并除以溫度參數logits = torch.cat([torch.matmul(z1, z2.T), torch.matmul(z2, z1.T)], dim=0) / temperature# 使用交叉熵損失:目標是讓正樣本對的相似度得分最高loss = F.cross_entropy(logits, positive)return loss# ----------------------
# 5. 訓練函數(對比學習)
# ----------------------
def train_contrastive(encoder, projection_head, dataloader, optimizer, scheduler, epochs=30):"""對比學習的訓練主循環"""encoder.train()projection_head.train()for epoch in range(epochs):total_loss = 0for images, _ in dataloader: # 注意:這里只使用圖片,不使用標簽(自監督)images = images.to(device)# 對同一批圖片應用兩次不同的數據增強,生成兩個視圖view1 = torch.stack([get_transform()(img) for img in images])view2 = torch.stack([get_transform()(img) for img in images])view1, view2 = view1.to(device), view2.to(device)# 通過編碼器和投影頭處理兩個視圖h1 = encoder(view1) # 提取特征h2 = encoder(view2) # 提取特征z1 = projection_head(h1) # 投影到對比學習空間z2 = projection_head(h2) # 投影到對比學習空間# 計算對比損失loss = contrastive_loss(z1, z2)# 反向傳播和優化optimizer.zero_grad()loss.backward()optimizer.step()scheduler.step() # 更新學習率(余弦退火策略)total_loss += loss.item()# 打印每個epoch的平均損失和當前學習率avg_loss = total_loss / len(dataloader)print(f"Epoch {epoch + 1}/{epochs}, Loss: {avg_loss:.4f}, LR: {scheduler.get_last_lr()[0]:.6f}")return encoder# ----------------------
# 6. 線性評估函數
# ----------------------
def linear_evaluation(encoder, train_loader, test_loader, epochs=30):"""評估對比學習得到的編碼器性能:固定編碼器,訓練一個線性分類器"""encoder.eval() # 凍結編碼器,只訓練線性分類器classifier = nn.Linear(256, 10).to(device) # 創建一個線性分類器(256維特征到10個類別)optimizer = optim.Adam(classifier.parameters(), lr=1e-3, weight_decay=1e-4)criterion = nn.CrossEntropyLoss()for epoch in range(epochs):# 訓練階段classifier.train()train_loss = 0correct = 0total = 0for images, labels in train_loader:images, labels = images.to(device), labels.to(device)with torch.no_grad():features = encoder(images) # 使用編碼器提取特征(固定不變)outputs = classifier(features) # 通過線性分類器預測類別loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()correct += (outputs.argmax(1) == labels).sum().item()total += labels.size(0)# 測試階段classifier.eval()test_correct = 0test_total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)features = encoder(images)test_correct += (classifier(features).argmax(1) == labels).sum().item()test_total += labels.size(0)# 打印訓練和測試準確率train_acc = 100 * correct / totaltest_acc = 100 * test_correct / test_totalprint(f"Epoch {epoch + 1}/{epochs}, Train Acc: {train_acc:.2f}%, Test Acc: {test_acc:.2f}%")return test_acc# ----------------------
# 7. 主函數
# ----------------------
def main():"""程序入口:加載數據,訓練模型,評估性能"""# 加載FashionMNIST數據集train_dataset = datasets.FashionMNIST(root='./data',train=True,download=True,transform=transforms.ToTensor() # 僅轉換為張量,不使用其他增強(訓練時單獨處理))test_dataset = datasets.FashionMNIST(root='./data',train=False,download=True,transform=transforms.ToTensor())train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True, num_workers=4) # 大批次加速訓練test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False, num_workers=4)# 初始化模型encoder = Encoder().to(device)projection_head = ProjectionHead().to(device)# 優化器與學習率調度器optimizer = optim.Adam(list(encoder.parameters()) + list(projection_head.parameters()),lr=1e-3, # 學習率weight_decay=1e-5 # 權重衰減,防止過擬合)# 余弦退火學習率調度:先增大后減小,幫助跳出局部最優scheduler = CosineAnnealingLR(optimizer, T_max=30, eta_min=1e-5)# 對比學習訓練print("開始對比學習訓練...")encoder = train_contrastive(encoder, projection_head, train_loader, optimizer, scheduler, epochs=30)# 線性評估:測試編碼器學到的特征質量print("\n開始線性評估...")linear_evaluation(encoder, train_loader, test_loader, epochs=30)if __name__ == "__main__":main()與權限)
入門學習筆記)
)








)
)




深度解析:國產分布式數據庫的旗艦之作)
)
