目錄
前言
題1 長度最小的子數組:
思考:
參考代碼1:
參考代碼2:
題2 無重復字符的最長子串:
思考:
參考代碼1:
參考代碼2:
題3 最大連續1的個數 III:
思考:
參考代碼:
題4 將 x 減到 0 的最小操作數:
思考:
參考代碼:
題5 水果成籃:
思考;
參考代碼1:
參考代碼2:
參考代碼3:
題6 找到字符串中所有字母異位詞:
思考:
參考代碼1:
參考代碼2:
題 7 串聯所有單詞的子串:
思考:
參考代碼:
題8?最小覆蓋子串 :
思考:
參考代碼1:
參考代碼2:
總結
前言
路漫漫其修遠兮,吾將上下而求索;
以下是滑窗口問題leetcode 集,大家可以先自己做做看:
- 209.?長度最小的子數組
- 3.?無重復字符的最長子串
- 1004.?最大連續1的個數 III
- 1658.?將 x 減到 0 的最小操作數
- 904.?水果成籃
- 438.?找到字符串中所有字母異位詞
- 30.?串聯所有單詞的子串
- 76.?最小覆蓋子串
題1 長度最小的子數組:
209. 長度最小的子數組 - 力扣(LeetCode)
題干:
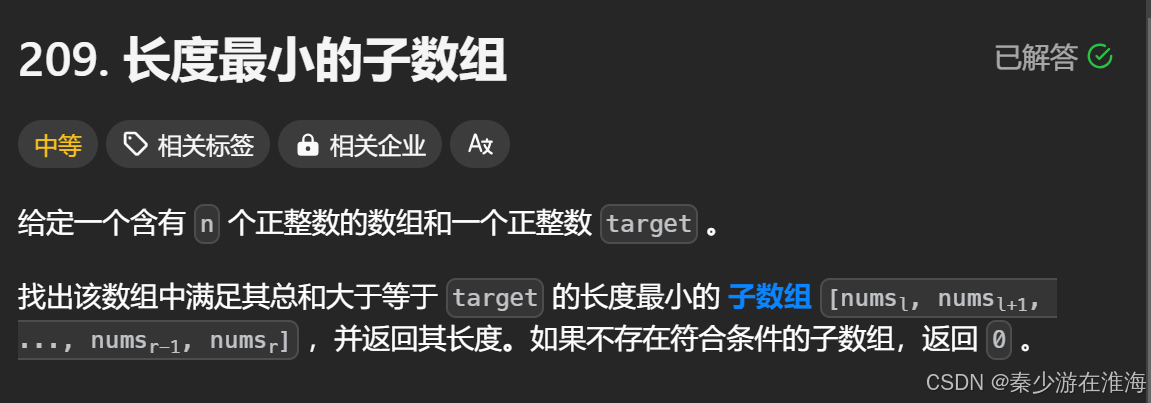
數據范圍:
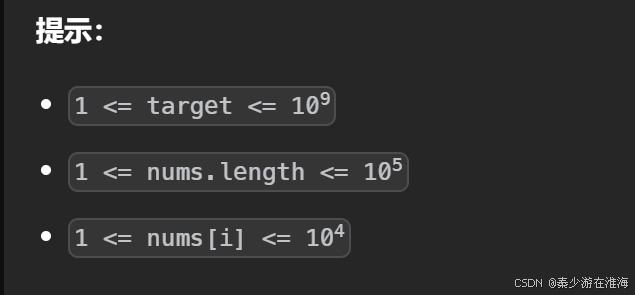
例子:

思考:
子數組:連續的數據
解法一:暴力枚舉出所有子數組的情況,然后將其中的數據相加判斷和是否大于target ;
這樣的話,時間復雜度為O(N^3),并且本題的數據量不少,單純地用暴力解決一定會超時;可以在暴力解法的基礎上進行優化嗎?無非就是在優化枚舉所有子數組,計算該子數組的和這兩點上進行優化;
由于數組中的數據均是正整數,正整數做加法有這樣的性質:加的數越多,和就越大(利用了數據的單調性);
和前一篇“雙指針題集”有相同之處,此處也可以利用數據的單調性來優化枚舉所有子數組,而且還順便可以優化計算其和:
- 假設我們兩個指針(假設為left right, 這兩個指針是同向走的)指向的區間中的數據為sum ,當sum 剛好大于target 的時候,可以再用一個變量記錄此時子數組的長度;此時sum 已經大于target 了,那么可以讓left++ ,減去前面較小的數看sum 是否還大于target ,如果還大于left 可以繼續++,如果小于了就讓right ++;(整體思路很像雙指針)
稍微粗略的分析覺得可行之后,我們可以更加細節地分析:
優化計算子數字的和:固定左區間,再定義一個變量來一直計算,這樣就不用每遇到一個區間就從頭到尾依次計算,圖解如下:(下圖的target 為 7)

當sum 已經大于target 的時候,此時left 和 right 的區間就已經為較小子數組長度下的和,right 也沒有必要繼續向前走了;
優化:當sum 已經大于target 的時候,讓變量記錄一下該子數組的長度,然后讓left ++ ,再讓right 回到left 指向的位置上,如下:
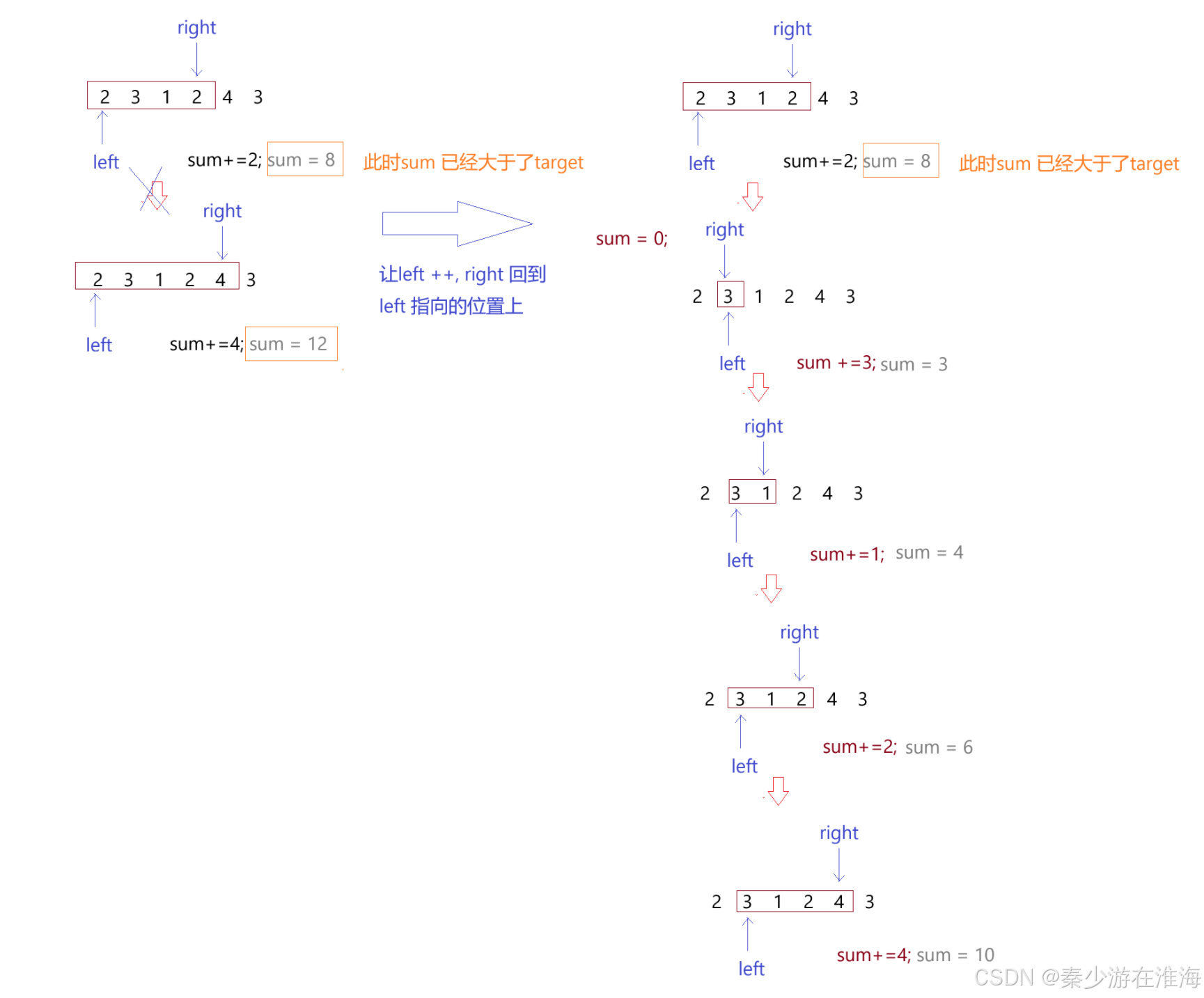
倘若當我們找到一個符合要求的區間之后讓left 自增,然后再讓right 指向left 指向的字符,那么就會需要將sum 置為0,然后一個一個地再遍歷,計算該子數組中數據中的和;時間復雜度為O(N^2);實際上,還可以繼續優化:當left 和 right 指向的區間中的數據和大于target 的時候,left ++ ,但是right 并不回到left 指向的位置處,而是讓right 不動,sum 減去left 之前所指向的數據,再判斷sum 和 target 的大小關系,如果sum 還是大于target ,left 繼續++ ,sum 再減去left 之前所指向的數,然后再判斷sum 和 target 的大小關系……如果sum小于target ,right 就++……優化二如下圖:
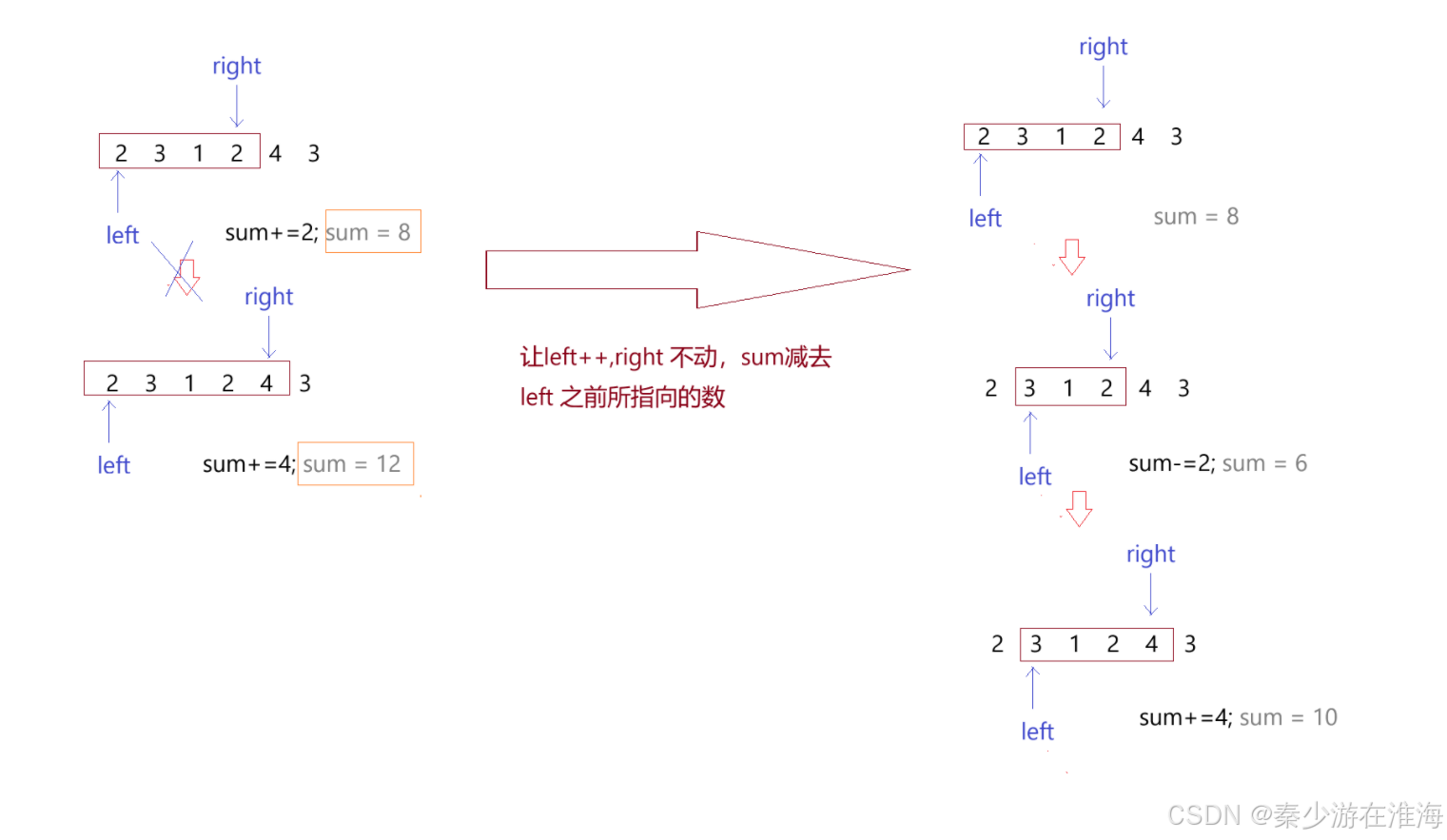
對于優化2的操作,本質上就是滑動窗口的理念,即利用單調性,并且使用同向雙指針;利用滑動窗口一般是來維護一個區間;
思路總結:
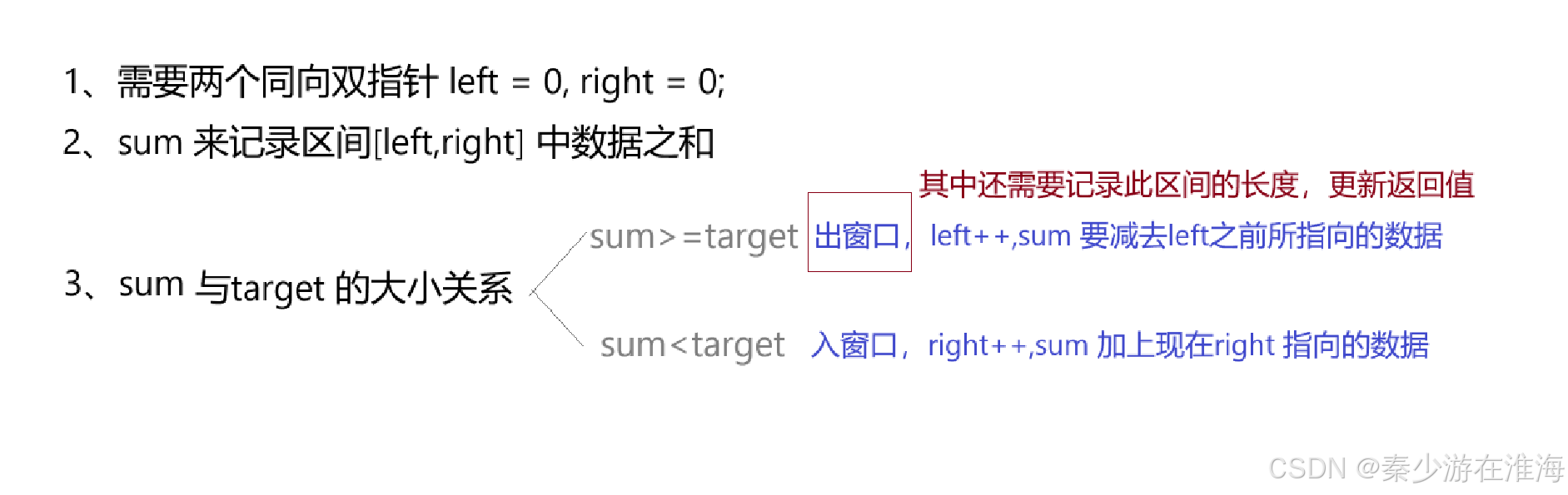
按照上面的思路寫代碼,我們會發現:

在出窗口的位置要寫成循環:
參考代碼1:
(while?循環版本)
int minSubArrayLen(int target, vector<int>& nums) {int n = nums.size();//單調性 + 同向雙指針int left = 0, right = 0;int sum = 0, retlen = INT_MAX;while(right < n){//當sum 小于target 就入窗口sum+=nums[right];while(sum >= target){//此時sum >= target ,滿足題干條件,可以更新結果,并且出窗口retlen = min(retlen , right-left+1);sum-=nums[left++];}right++;}return retlen==INT_MAX?0:retlen;}Q:為什么right++ 放在出窗口后面?不應該是先入窗口然后再出窗口嗎?
- 最初left == right 的時候(left ==0 , right == 0),實際上是將第一個數入窗口,相當于right天然地就已經自增了;所以將right++,放在最后,每次right向后走一步就入窗口,是合理的;
基于此,我們還可以寫成for 循環版本的:
參考代碼2:
(for 循環版本)
int minSubArrayLen(int target, vector<int>& nums) {int n = nums.size();//單調性 + 同向雙指針int sum = 0, retlen = INT_MAX;for(int left = 0, right = 0;right <n;right++){//當sum 小于target 就入窗口sum+=nums[right];//更新數據 + 出窗口 while(sum >= target){//此時sum >= target ,滿足題干條件,可以更新結果,并且出窗口retlen = min(retlen , right-left+1);sum-=nums[left++];}}return retlen==INT_MAX?0:retlen;}題2 無重復字符的最長子串:
3. 無重復字符的最長子串 - 力扣(LeetCode)
題干:
數據范圍:

例子:

思考:
子串:連續的字符構成的串
要求:不重復的最長子串
解法一:暴力解法
列舉出所有的子串的情況,再判斷這每一個子串是否是不重復的子串,然后找到一個最長的就可以了;其中枚舉所有子串的情況:固定每一個有可能的起始位置,然后依次向后擴展,直到擴展到不能再擴展為止;而判斷這個子串是否重復:利用哈希表;
即暴力解法就是:暴力枚舉 + 哈希表判斷;
此處就不演示暴力解法是否能通過,我們需要做的是能否在暴力解法的基礎上進行優化:這道題其實和上一道題有異曲同工之妙,只不過上一道題出窗口的條件是:當sum >= target, 而本題出窗口的條件:窗口[left,right] 之中有重復的字符,圖解如下:
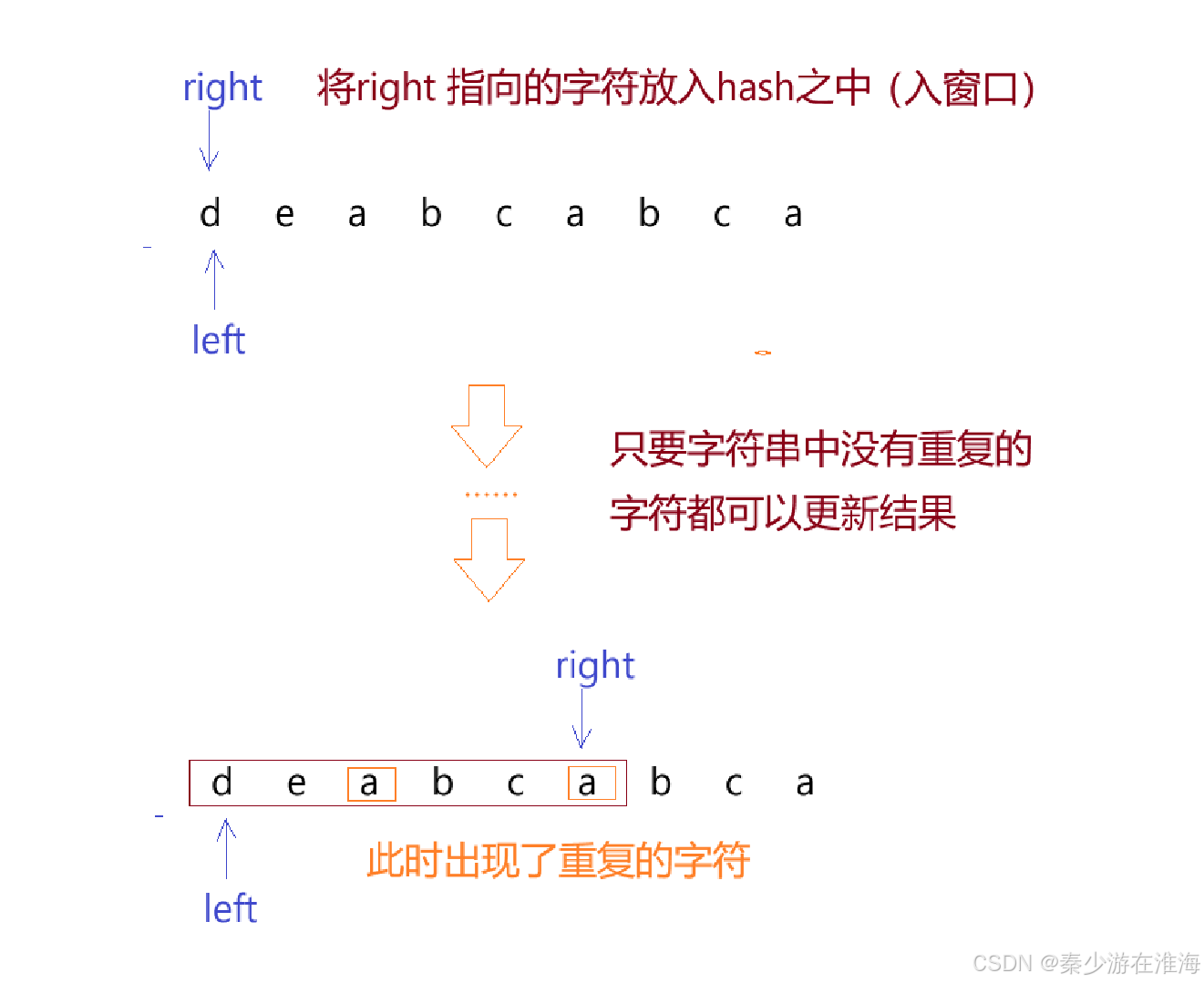
我們需要想清楚的是,當hash 之中出現了重復的字符的時候我們要怎么做?
方法一:根據暴力枚舉的想法,left ++,然后right 指向left 指向的位置;
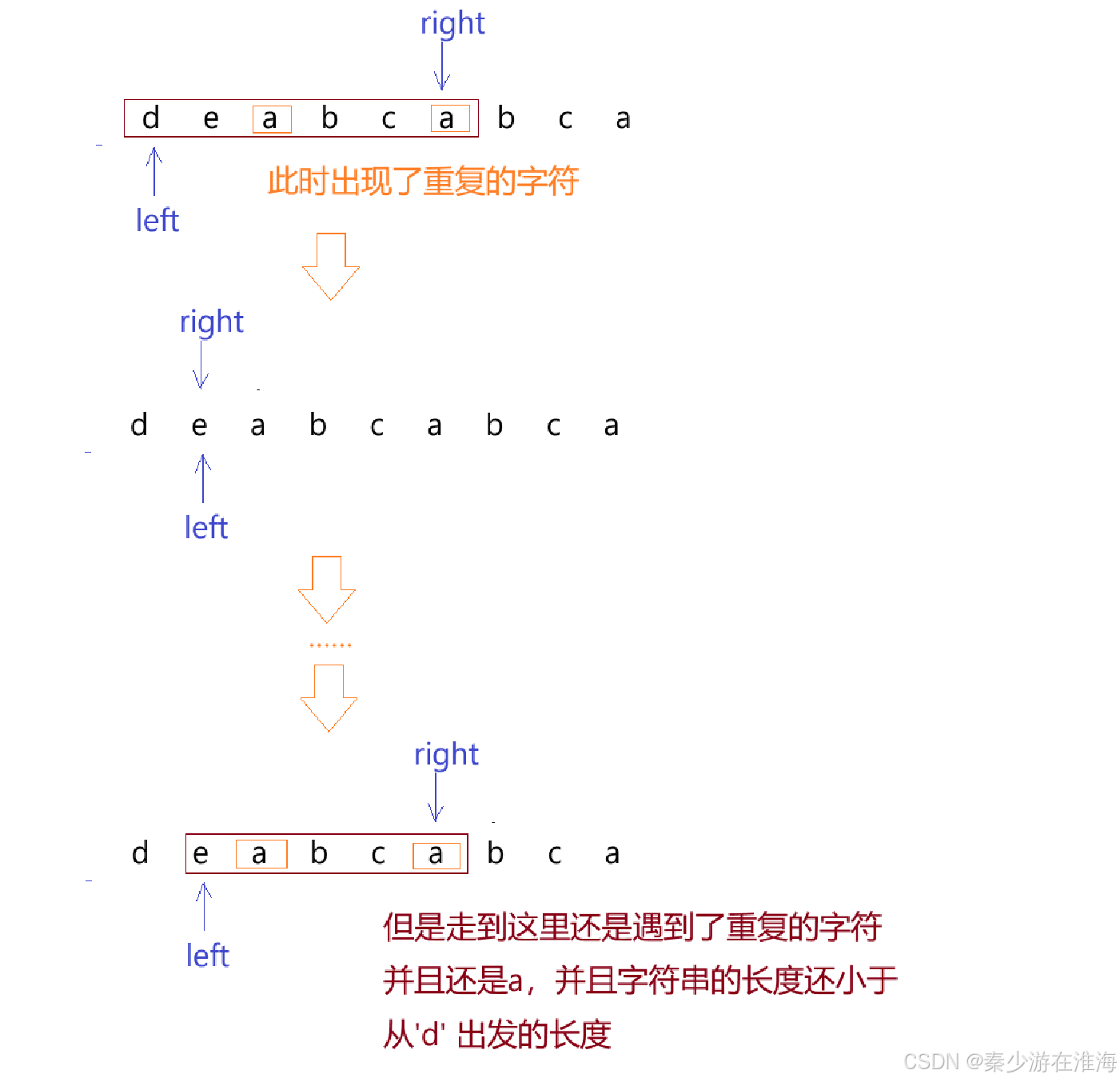
顯然這種方式處理出現重復的字符的情況,不僅會有無效情況的加入,還要清空hash表重新記錄,時間復雜度仍是O(N^2)
方法二:既然從方法一我們已經得知,當遇到重復的字符時,left++,right 回到left 指向的位置,還是沒有解決重復字符的問題,只有越過這個重復的字符才能從根源上解決問題;
如何越過呢?
- left一直向前走,每走一步都要判斷hash 之中是否還存在重復的字符,直到hash 之中沒有重復的字符了,left 才停止向前走,此時出窗口結束,并且需要更新結果,圖解如下:
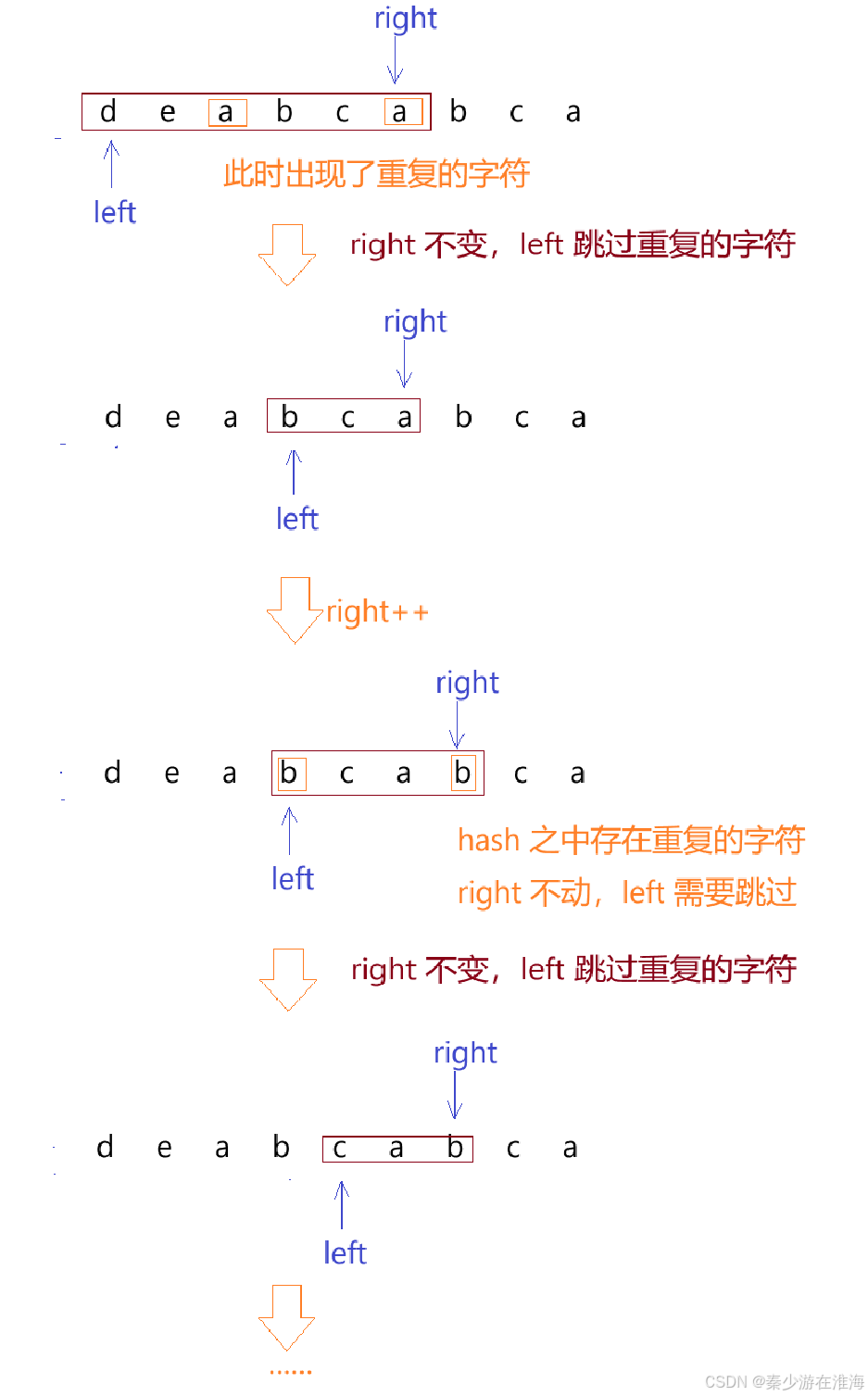
參考代碼1:
int lengthOfLongestSubstring(string s) {int n = s.size(),retlen = INT_MIN;//同向雙指針 + hash判斷窗口中是否有重復的數據unordered_map<char,int> hash;for(int left = 0 , right = 0;right < n;right++){//入窗口if(hash[s[right]] == 0) hash[s[right]] = 1;else{hash[s[right]]++;//出窗口while(hash[s[right]]==2){hash[s[left++]]--;}} //更新結果 - 走到這里就意味著沒有重復字符retlen = max(retlen , right-left+1);}return retlen==INT_MIN?0:retlen;}由于題干說了字符串s 由英文字母、數字、符號和空格組成,所以在實現hash 的時候可以不用容器unordered_map ,可以使用128大小的整形數組,用下標來映射字符;參考代碼2換成while 循環來實現,并且可以優化其代碼邏輯,right 指向的字符每要入一次都要檢查,那么同一個字符出現的個數最大為2,可以直接入窗口,然后再判斷出窗口,走到了此處,此時窗口[left,right] 中的字符一定不會重復,所以可以更新數據,如下:
參考代碼2:
int lengthOfLongestSubstring(string s) {int n = s.size(),retlen = INT_MIN;//同向雙指針 + hash判斷窗口中是否有重復的數據//可以使用大小為128的字符數組來實現hashint hash[128] ={0};int left = 0 , right = 0;while(right < n){//入窗口hash[s[right]]++;//判斷 - 出窗口while(hash[s[right]]==2){hash[s[left++]]--;}//更新結果 - 走到這里就意味著沒有重復字符retlen = max(retlen , right-left+1);right++;}return retlen==INT_MIN?0:retlen;}這兩個參考代碼的時間復雜度均為O(N);
題3 最大連續1的個數 III:
1004. 最大連續1的個數 III - 力扣(LeetCode)
題干:

數據范圍:
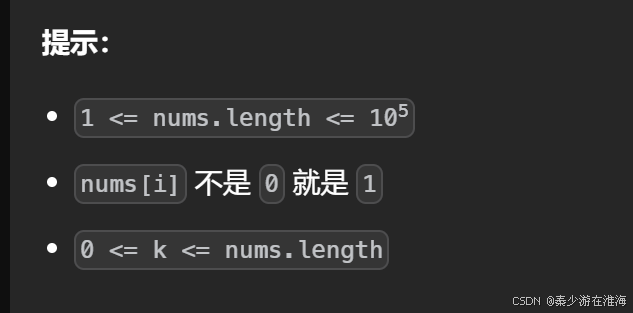
例子:

思考:
題干意思就是一個數組中只有0和1,可以將k個0變成1,求連續1的最長連續長度;
那么首先想到的肯定是暴力解法,枚舉出所有的子數組,然后將子數組中k個0全部變為1,再求最長的子數組的長度;即枚舉 + 判斷,經過前面兩道題的練習不難想到,想要高效地枚舉,可以利用同向雙指針來解決;而至于判斷窗口中將k 個0變為1能否構成全1,可以借助于窗口的總數與數據個數的關系,例如:假設窗口中的數據有5個,k為3,那么該窗口中的數據總和的范圍為[2,5] ,即[n-k,n] 一旦不在這個范圍就一定不能構成連續1的子數組;那這樣的話,時間復雜度依舊是O(N^2),因為沒有實質性地解決枚舉的消耗高的問題,需要砍掉一些可能性來降低時間復雜度;那么就得從k 入手,當窗口中的0的個數大于k個的時候,出窗口,圖解如下:


思路總結:

參考代碼:
int longestOnes(vector<int>& nums, int k) {int n = nums.size(),count = 0, retlen = INT_MIN;//同向雙指針 + 一個變量來記錄窗口中0的個數for(int left =0 , right = 0; right < n;right++){//入窗口if(nums[right]==0) count++;while(count>k){if(nums[left]==0) count--;left++;}//此時窗口中0的個數一定合法,可以更新數據retlen = max(right-left+1, retlen);}return retlen;//因為數組中至少有一個數據,所以不用判斷retlen 是否會為INT_MIN}可以再簡潔該代碼,如下:
int longestOnes(vector<int>& nums, int k) {int n = nums.size(),retlen = INT_MIN;//同向雙指針 + 一個變量來記錄窗口中0的個數for(int left =0 , right = 0,count = 0; right < n;right++){//入窗口if(nums[right]==0) count++;while(count>k)if(nums[left++]==0) count--;//此時窗口中0的個數一定合法,可以更新數據retlen = max(right-left+1, retlen);}return retlen;//因為數組中至少有一個數據,所以不用判斷retlen 是否會為INT_MIN}題4 將 x 減到 0 的最小操作數:
1658. 將 x 減到 0 的最小操作數 - 力扣(LeetCode)
題干:

數據范圍:
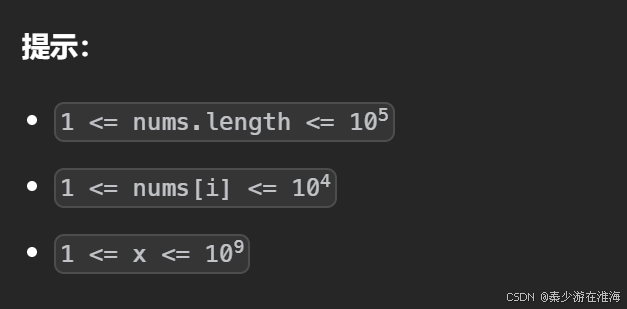
例子:

思考:
從nums 的最左邊或者最右邊選擇一個數據,讓x 減去,求讓x 減為0的最少選數次數;
我們先來思考一下如何才可以讓x減去一些數之后值為0?
- 顯然這些數相加要為x。
那么最少的操作次數呢?
- 用最少的數相加為x;
那么每次只能選最左邊或者最右邊的數據該如何解決呢?
- 首先我們想到的是在左右兩邊均設置一個指針,一個一個地試。
但是選這個數的時候我們怎么知道這個數合不合適呢?
顯然這是非常矛盾的;畫圖再分析一下:
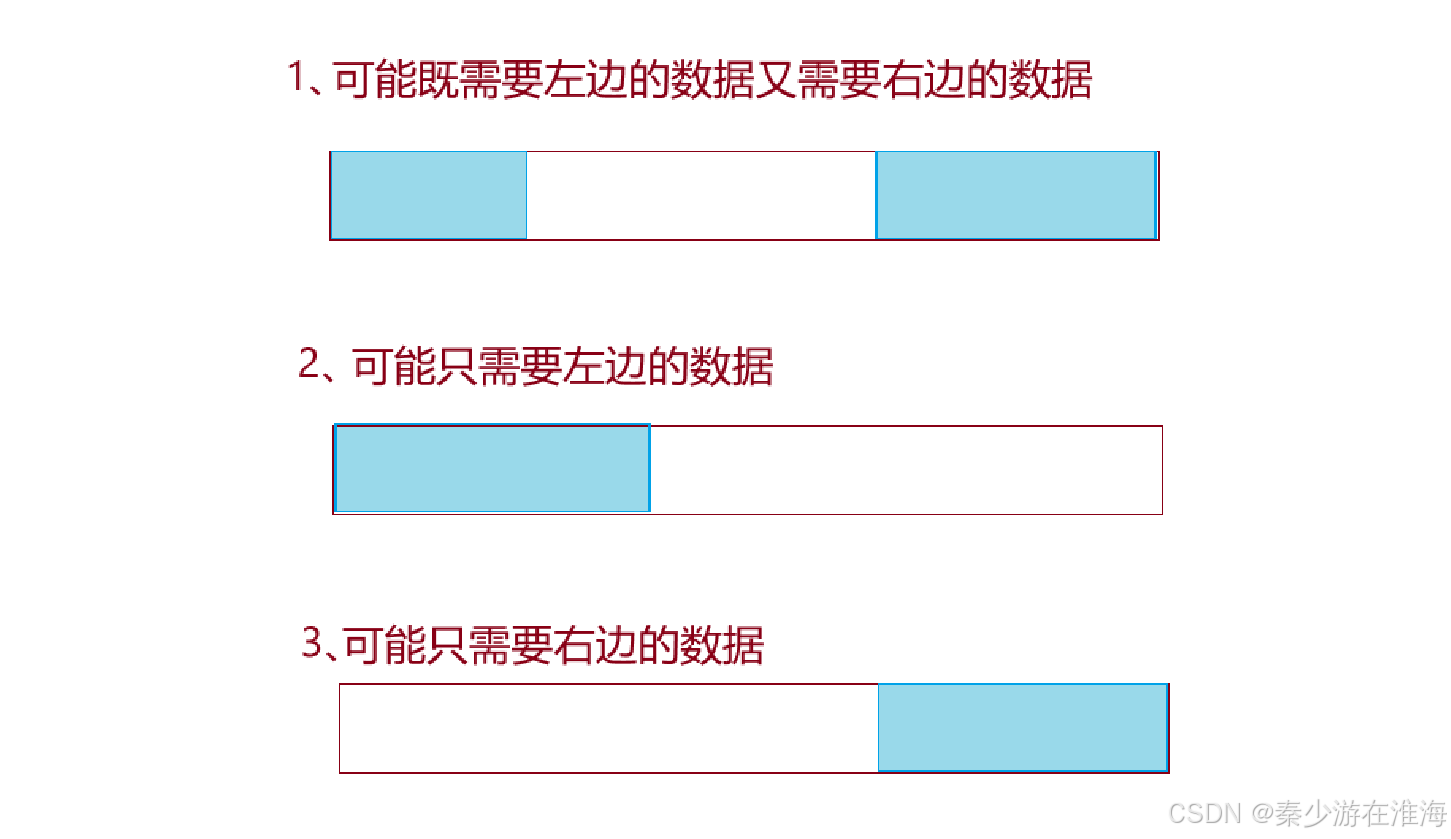
所得到的結果無非就是這三種情況中的一個,其共同點都是需要藍色區域中的數據相加和為x ,并且求該區域中數據的最少個數,那么空白區域中數據的和為 sum-x ,則反過來就是求空白區域的最多數據個數;
而,空白區域無論在哪一個情況下均是連續的區域,我們是否可以將題干中的意思進行轉換?換一個角度解決問題?
題干轉換:找出nums中最長的和為(sum-x) 的子數組的長度;
解法一:暴力解法 + 計算和
枚舉出所有子數組的情況,并計算其和是否等于 (sum-x) ,并且求出最長的和為 (sum-x)的 子數組的長度;
解法一一定是首先就能想到的解法,但是經過前面三道題的訓練,應該可以敏感地感知,此處還可以用同向雙指針進行優化,即解法二;
解法二:根據暴力解法進行優化
由題干中的信息可以知道,nums 中的數據均為正整數,所以數據就已經有了天然的單調性-> 數據的個數越多,其和越大;可以利用同向雙指針來解決,假設同向雙指針為left ,right ,范圍[left,right] 中的數據總和為sum ,當sum > target 的時候,就要減少窗口中的數據個數來以此減小sum,即在left 窗口,出窗口可能會多次操作,故而應該用循環解決;當sum < target ,應該增加窗口中的數據個數來增大sum ,所以從right 處入窗口;當sum == target 的時候,就是我們的目標情況,此時需要更新數據;其中target 在本題中為nums 的總和減去x;
思路總結:
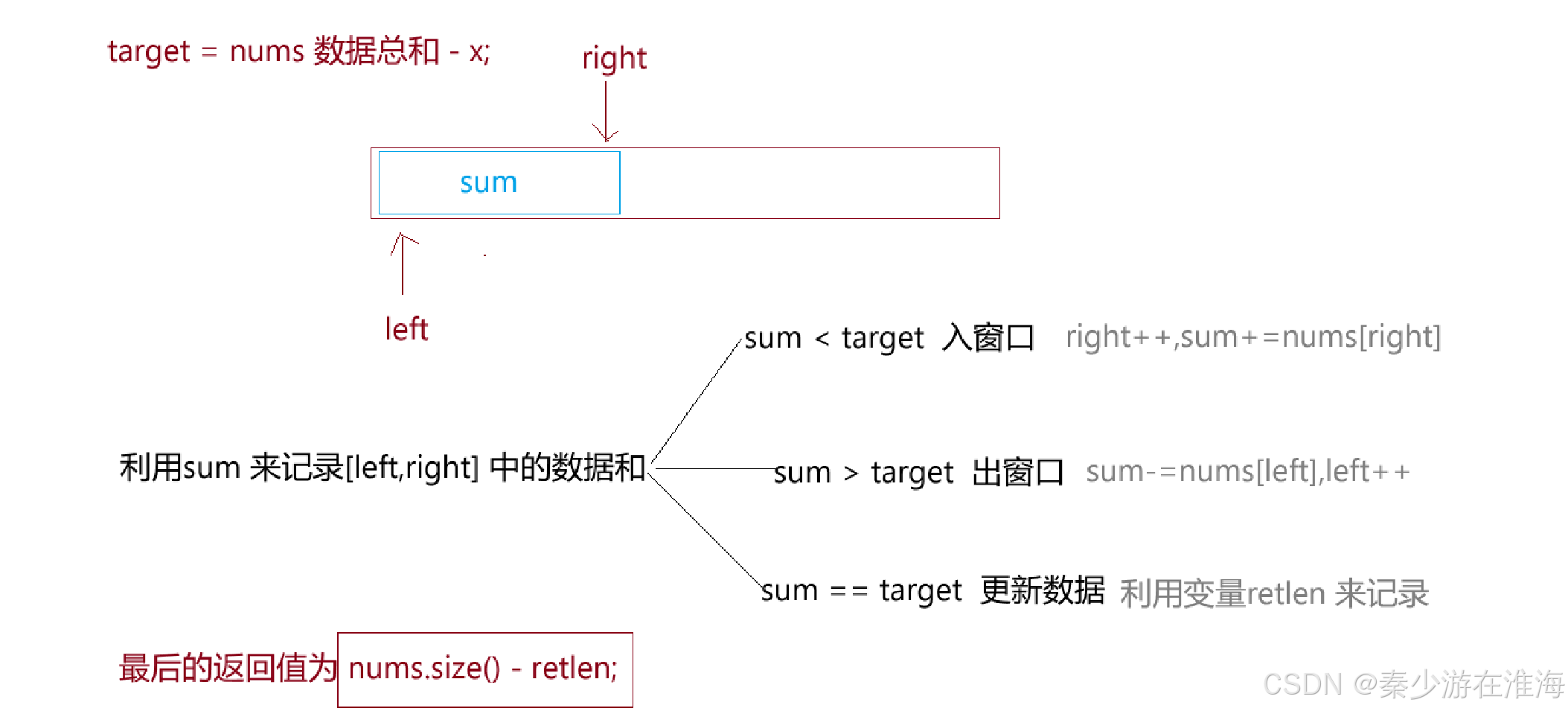
還有一個細節的地方,如果題干所要求的x 本身就大于nums 中的數據總和,那么是一定在nums 中找不到數據相加結果為x , 直接返回-1即可;
參考代碼:
int minOperations(vector<int>& nums, int x) {//轉換題意:t:nums總和-x ,尋找和為t 的最多數據個數的子數組int sumnums = 0, n = nums.size();for(auto e: nums) sumnums+=e;int target = sumnums - x;//如果x大于nums中左右數據的總和是一定找到不的;if(target < 0) return -1;int left = 0, right = 0, sum = 0 , retlen = INT_MIN;//同向雙指針while(right < n){//入窗口sum += nums[right];//判斷sum 與 target 的大小關系,決定是否要出窗口while(sum > target){sum-=nums[left++];}//如果sum == target 就更新數據if(sum == target) retlen = max(retlen , right-left+1);right++;}//retlen 可能還是為INT_MIN,就說明沒有找到if(retlen == INT_MIN) return -1;else return n - retlen;}題5 水果成籃:
904. 水果成籃 - 力扣(LeetCode)
題干:

數據范圍:
例子:

思考;
題干的意思可以提煉為:從正整數數組nums的任意一個位置開始,向右連續地選數,只能選兩種數,求最多地數據個數,窗口[left,right] 中只能有兩種數字;
注:此處的nums 表示題干中的數組fruits,用nums 來解釋比較好理解,下文的闡述中也是用nums 代表 fruits 來闡述的;
解法一:暴力解法:
枚舉出所有的子數組,判斷該子數組中是否只存在兩種數字,并且求滿足條件的最長的子數組長度;枚舉就不用多說,固定一個位置挨個枚舉即可;如何判斷一個區間中的數據種類?利用哈希表來解決;根據數據范圍可以得知,數組nums 中最大的數值為99999,可以是開辟大小為100001的數組當作哈希表,也可以利用容器unordered_map 來解決;
看到連續的子數組的題目,我們肯定可以聯想到為可以利用同向雙指針來解決,從暴力解法上進行優化;
解法二:同向雙指針 - 滑動窗口
需要利用變量kinds統計窗口中的數據種類,當kinds 小于等于2 的時候繼續入窗口,當kinds大于2的時候出窗口,kinds 合法的時候就要更新數據;其實很像本博文中的題2? 無重復字符的最長子串,只不過兩個判斷出窗口時的條件不同;
此處就不贅述了,思想真的一模一樣;
參考代碼1:
int totalFruit(vector<int>& fruits) {int n= fruits.size();//hashunordered_map<int,int> hash;int left = 0, right = 0, retlen = INT_MIN, kinds = 0;while(right < n){//入窗口hash[fruits[right]]++;if(hash[fruits[right]] == 1) kinds++;//判斷是否要出窗口while(kinds>2){hash[fruits[left]]--;if(hash[fruits[left]]==0) kinds--;left++;}//到了此處的kinds一定合法,更新數據retlen = max(retlen , right - left +1);right++;}//因為fruits 中至少有一個數,直接范圍即可不用進行判斷return retlen;}實際上我們利用unordered_map容器來實現哈希表就可以不使用變量來記錄窗口中的數據種類,直接使用接口函數 size() 、erase() 等來實現就可以了,如下:
參考代碼2:
int totalFruit(vector<int>& fruits) {int n= fruits.size();//hashunordered_map<int,int> hash;int left = 0, right = 0, retlen = INT_MIN;while(right < n){//入窗口hash[fruits[right]]++;//判斷是否要出窗口while(hash.size()>2){hash[fruits[left]]--;if(hash[fruits[left]]==0) hash.erase(fruits[left]);left++;}//到了此處的kinds一定合法,更新數據retlen = max(retlen , right - left +1);right++;}//因為fruits 中至少有一個數,直接范圍即可不用進行判斷return retlen;}實際上在unordered_map 中頻繁地插入、刪除,效率十分低下,可以這么說,參考代碼2的效率沒有參考代碼1 的高,此處還有一種寫法,就是hash 用數組來實現,用空間換時間,直接開辟大小為100001的空間,最終代碼與參考代碼1如出一轍,只不過是hash 實現的不同罷了;
參考代碼3:
int totalFruit(vector<int>& fruits) {int n= fruits.size();//hashint hash[100001] = {0};int left = 0, right = 0, retlen = INT_MIN, kinds = 0;while(right < n){//入窗口hash[fruits[right]]++;if(hash[fruits[right]] == 1) kinds++;//判斷是否要出窗口while(kinds>2){hash[fruits[left]]--;if(hash[fruits[left]]==0) kinds--;left++;}//到了此處的kinds一定合法,更新數據retlen = max(retlen , right - left +1);right++;}//因為fruits 中至少有一個數,直接范圍即可不用進行判斷return retlen;}題6 找到字符串中所有字母異位詞:
438. 找到字符串中所有字母異位詞 - 力扣(LeetCode)
題干:
數據范圍:
例子:

思考:
即在字符串s 中找有字符串p 中字符構成的子串,返回首字母的下標;
Q:如何判斷兩個字符串是否為”異位詞“?
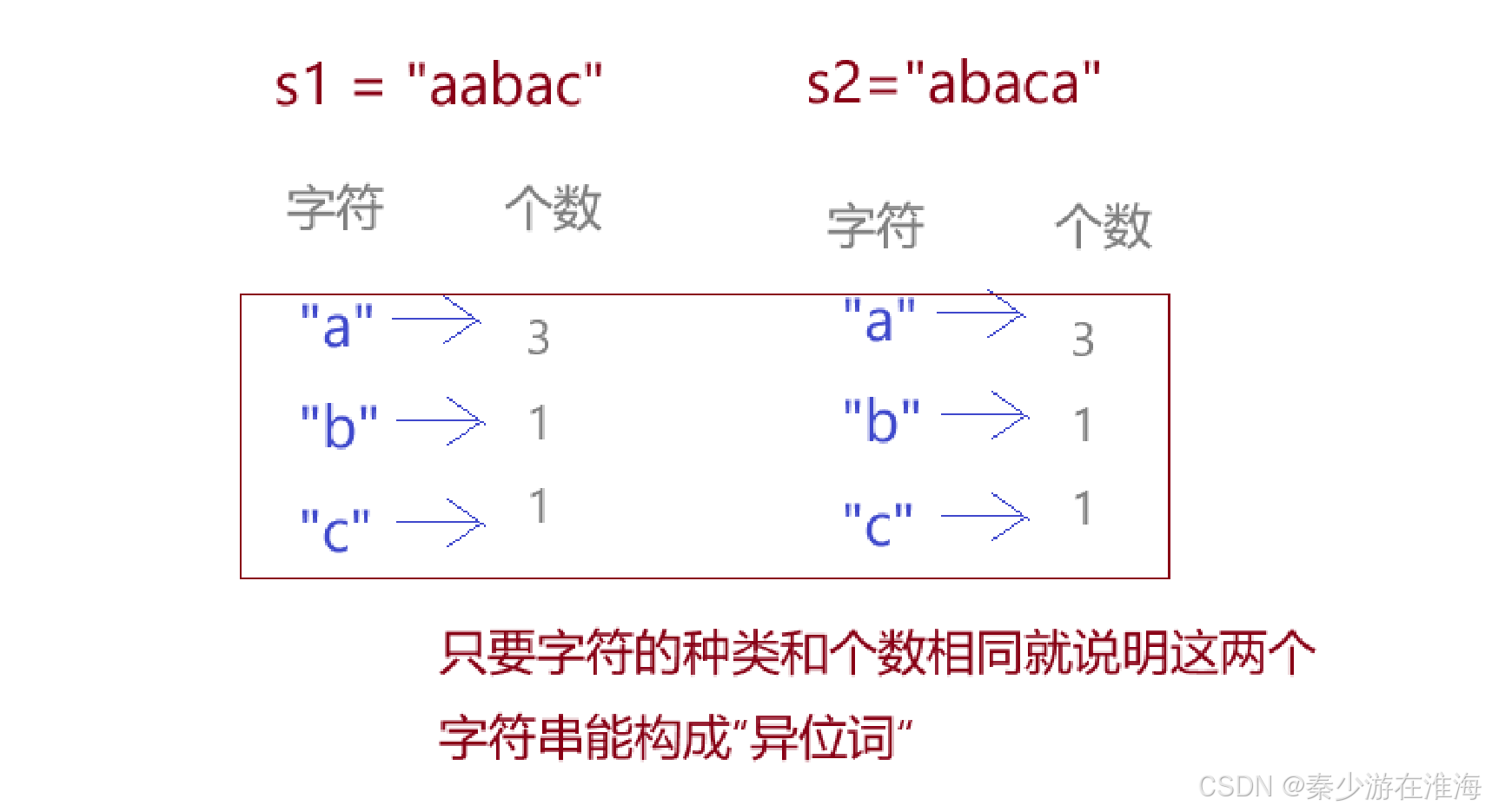
eg: s1 = "aabac"? , s2="abaca"
方法一:先為這兩個字符串排序,然后利用兩個指針對其內容進行一一比對;時間復雜度為O(Nlogn+N),如下:

方法二:不考慮每個字符串中的字符的順序怎么樣,只是判斷這兩個字符串中的字符種類與個數是否相同即可,如下:
而至于如何判斷,我們可以借助于哈希表來實現;
解法一:暴力解法
暴力枚舉出字符串s 中所有子串的情況,然后利用hash表來判斷列舉出來的子串是否與字符串p構成”異位詞“;
創建兩個哈希表 hash1 與 hash2? , 先將字符串p 中的字符放入hash2?之中,然后再將列舉出來的子串放入hash1?之中,最后再比較hash1 與 hash2是否相等即可;相等的,便可以將該子串的首字符下標放入返回的數組之中;
我們現在思考的是能否在暴力解法的基礎上進行優化?首先是枚舉出所有的子串,實際上有些子串根本就沒有枚舉的必要,例如已知這個子串中出現了非字符串p 中的字符;基于這點,如果哈希表是用容器unordered_map 實現的話,就可以使用接口函數 count() 來查找hash2?中是否有這個字符;而維護一段連續的區域,我們不難想到會使用同向雙指針來解決;
解法二:同向雙指針 + hash
Q:如何比較兩個哈希表是否相同??
因為題干說了字符串中的字符全為小寫字符,所以還可以使用大小為26 的數組來實現hash;
解決方法一:直接比較,若哈希表用數組實現的話,比較26次就可以了;
如若哈希表用unordered_map 實現的話,就需要設置一個變量來統計窗口中有效數據的個數,并且在統計的時候還需要結合hash2與hash1 字符的個數來實現;那么同樣的,再增加一個變量記錄窗口中有效數據的個數就可以了;
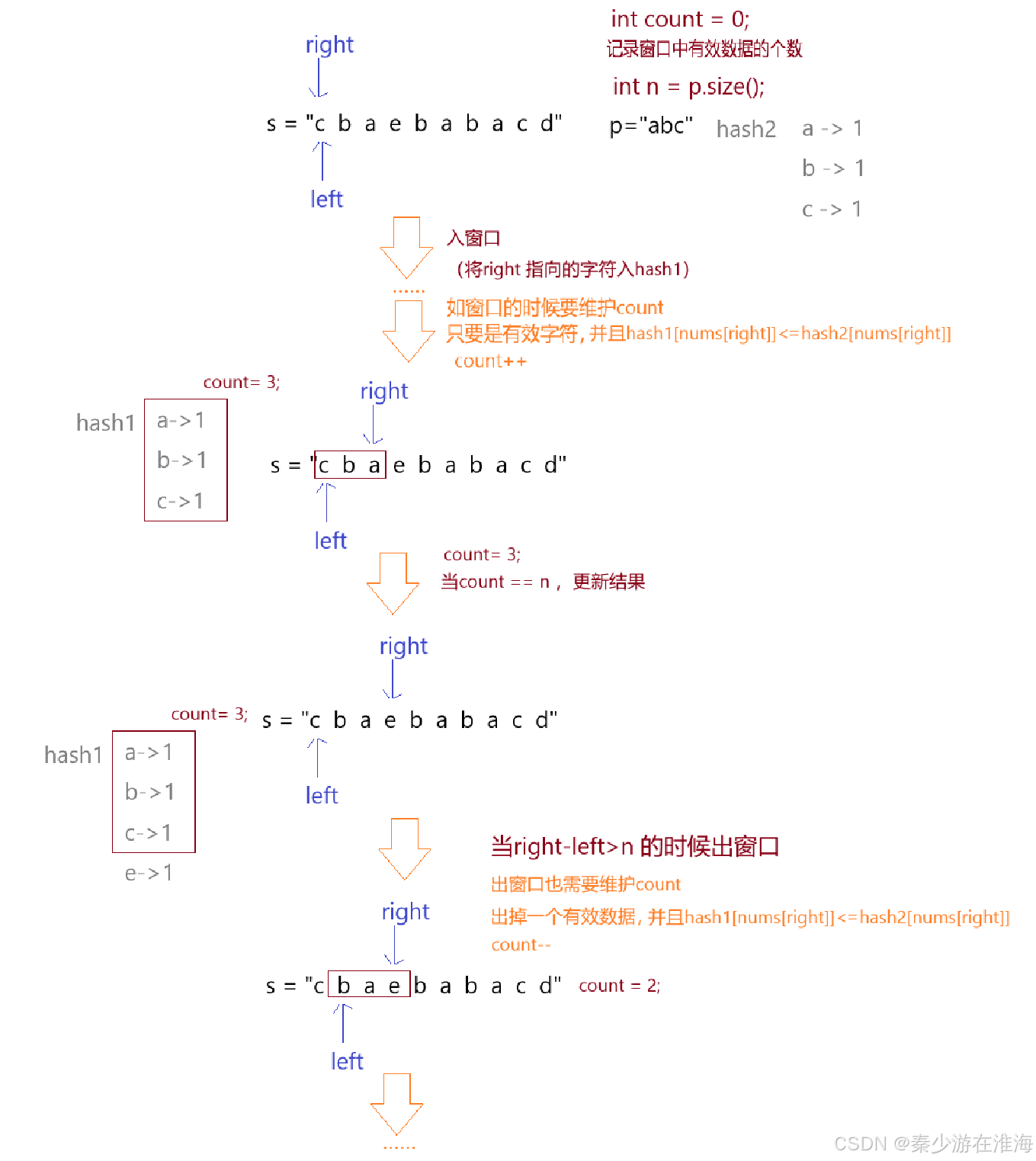
思路總結:

參考代碼1:
vector<int> findAnagrams(string s, string p) {int m = s.size(), n = p.size();unordered_map<char , int> hash1,hash2;//將字符串p 中的字符均放入hash表中for(auto e : p) hash2[e]++;int left = 0, right = 0, count = 0;vector<int> ret;while(right < m){//入窗口char in = s[right];hash1[in]++;if(hash2.count(in) && hash1[in] <= hash2[in]) count++;//判斷是否要出窗口//因為一定只會執行一次,所以可以寫成if 判斷語句if(right - left + 1 > n){char out = s[left];//維護countif(hash2.count(out) && hash1[out] <= hash2[out]) count--;hash1[out]--;left++;}//更新結果 - 窗口中的數一定是小于等于n 的if(count == n) ret.push_back(left);right++;}return ret;}如果用變量記錄有效數據個數的,還可以用數組實現的hash代替unordered_map ,但是需要注意下標的映射關系,如下:
參考代碼2:
vector<int> findAnagrams(string s, string p) {int m = s.size(), n = p.size();int hash1[26] = {0};int hash2[26] = {0};//將字符串p 中的字符均放入hash表中for(auto e : p) hash2[e - 'a']++;int left = 0, right = 0, count = 0;vector<int> ret;while(right < m){//入窗口char in = s[right];hash1[in - 'a']++;if(hash1[in - 'a'] <= hash2[in - 'a']) count++;//判斷是否要出窗口//因為一定只會執行一次,所以可以寫成if 判斷語句if(right - left + 1 > n){char out = s[left];//維護countif( hash1[out - 'a'] <= hash2[out - 'a']) count--;hash1[out - 'a']--;left++;}//更新結果 - 窗口中的數一定是小于等于n 的if(count == n) ret.push_back(left);right++;}return ret;}還可以對代碼進行簡化,如下:
vector<int> findAnagrams(string s, string p) {int m = s.size(), n = p.size();int hash1[26] = {0};int hash2[26] = {0};//將字符串p 中的字符均放入hash表中for(auto e : p) hash2[e - 'a']++;int left = 0, right = 0, count = 0;vector<int> ret;while(right < m){//入窗口char in = s[right];if( ++ hash1[in - 'a'] <= hash2[in - 'a']) count++;//判斷是否要出窗口//因為一定只會執行一次,所以可以寫成if 判斷語句if(right - left + 1 > n){char out = s[left++];//維護countif( hash1[out - 'a']-- <= hash2[out - 'a']) count--;}//更新結果 - 窗口中的數一定是小于等于n 的if(count == n) ret.push_back(left);right++;}return ret;}題 7 串聯所有單詞的子串:
30. 串聯所有單詞的子串 - 力扣(LeetCode)
題干:

數據范圍:
例子:

思考:
結合題干我們可以得知,s 中的字符均是words?中所有字符串以任意順序拼接而成的;其實這道題跟上一道題很像,只不過上道題是處理字符,而本題是處理字符串;
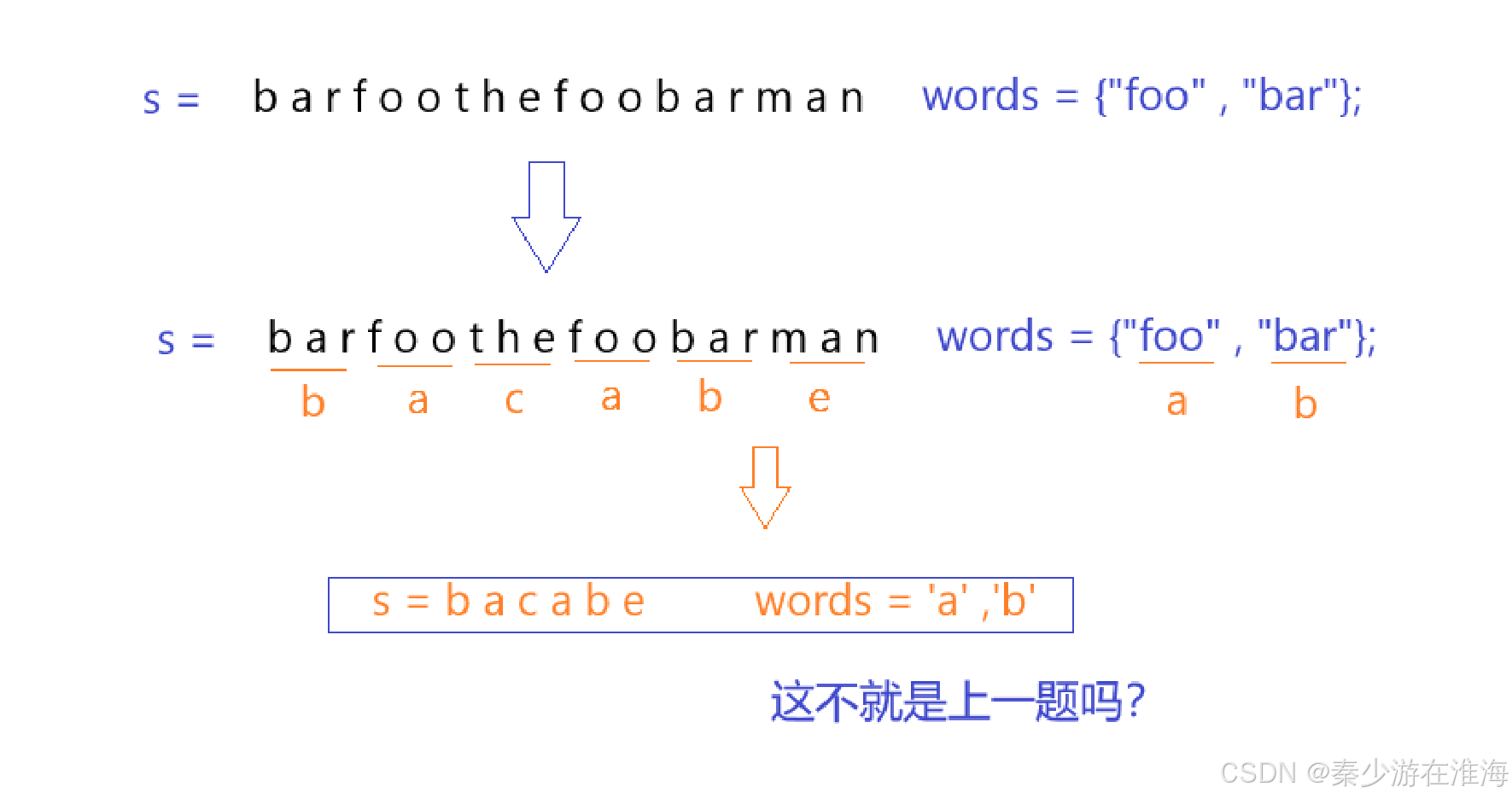
可見本題和上一題的思路大差不差,不過是在細節層面有所區別;
解法:同向雙指針 + 哈希表
在上題中,因為是對字符進行操作,所以其中的哈希表可以用數組實現也可以用容器unordered_map 來實現哈希表,但是本題中是要對字符串進行處理,所以哈希表最好就不要使用數組實現,而是用容器unordered_map 來實現;
因為words 中的字符串的長度都一樣,而每一次移動需要指向下一個字符串,也就是說同向雙指針的移動不能是一個位置一個位置地移動,而其一次移動地距離由words 中字符串的長度決定;算法邏輯跟上一題如出一轍,此處就不再過多贅述;
還需要注意的是,s 字符串中的劃分不會像我們上圖那樣words 中的字符串長度為多長其余的單詞也為多長,此處為了不漏,需要在外層再套一個循環:從哪個位置開始向后找,由words 中字符串的長度決定;
參考代碼:
vector<int> findSubstring(string s, vector<string>& words) {int n = s.size() , m = words.size() , len = words[0].size();vector<int> ret;unordered_map<string,int> hash1;for(auto&e: words) hash1[e]++;//執行m次for(int i = 0; i<len;i++){int left = i, right = i , count = 0;unordered_map<string,int> hash2;//滑動窗口while(right <= n - len)//此處是一個細節{//入窗口string in = s.substr(right , len);hash2[in]++;//維護countif(hash1.count(in) && hash2[in] <= hash1[in]) count++;//判斷 - 出窗口if(right-left+1 > m*len) {string out = s.substr(left , len);//出窗口前維護countif(hash1.count(out) && hash2[out] <= hash1[out]) count--;hash2[out]--;left+=len;}//更新數據if(count == m) ret.push_back(left);right+=len;}}return ret;}題8?最小覆蓋子串 :
76. 最小覆蓋子串 - 力扣(LeetCode)
題干:
數據范圍:

例子:

思考:
本題跟題6也很相似,只不過本題求的是當窗口中均包含了 t 中的字符的時候,窗口中的最小長度,并且返回窗口中的字符;此處可以用兩個變量來記錄,一個記錄窗口中字符串的最小長度,一個來記錄最小長度的內容或者是一個記錄窗口中字符串最小長度的起始下標,一個記錄窗口中字符串的最小長度;
如何才能讓窗口中的字符個數最小?當然窗口的最左邊和最右邊都是所要求的字符(t 中的字符),那么這就是出窗口的判斷,判斷left 指向的是否是t 中的字符;同樣地,與題6相似,需要用到hash 表來統計窗口中、t 中的字符,并且需要一個變量來維護窗口中有效字符的個數;
完整邏輯講解:
解法一:暴力解法+哈希表
枚舉出所有子串的情況,然后后找到符合題干的最短的子串返回即可;同樣的,想要知道枚舉出來的子串是否覆蓋t 中的字符,與題6一樣,需要借助于哈希表來實現;
我們需要優化暴力枚舉的過程:
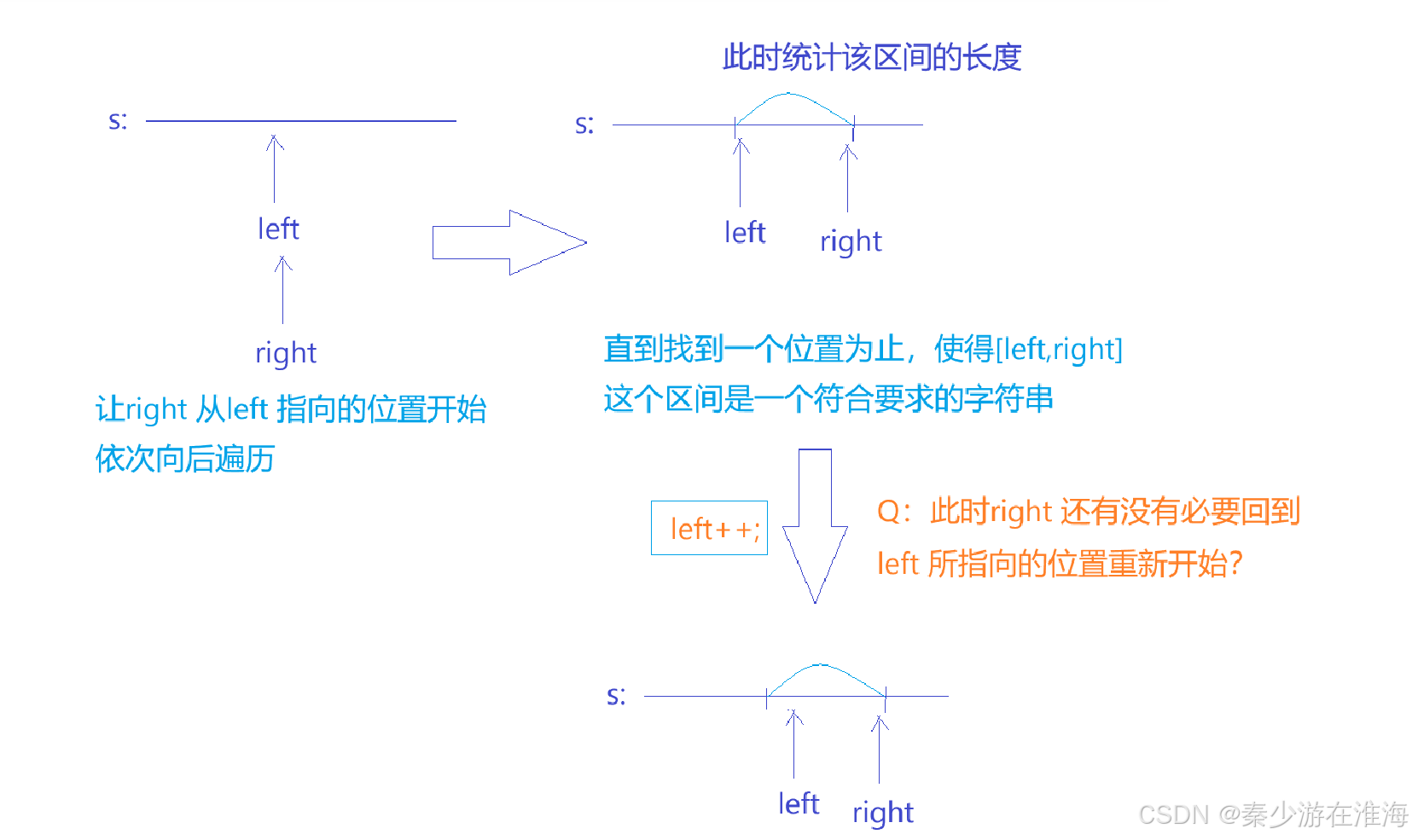
我們定義了兩個指針left right , right 進行查找,當區間[left,right] 中的字符串符合題干規定的時候,就可以計算此區間的長度;然后left ++,right 回到left 指向的地方,right 繼續往后找……這是暴力枚舉的做法;我們需要思考的是,right 是否有必要重新回到left 指向的地方?
沒必要;因為我們需要維護[left,right] 之中包含所有t 中的字符就行了;所以我們就需要討論,left自增之后,[left,right] 中的情況,如下:

顯然,此處的優化就是用滑動窗口來解決;在實現代碼之前,我們需要弄清楚,入窗口、出窗口、更新數據如何操作;
解法二:同向雙指針(滑動窗口) + 哈希表
因為s 與 t 中的字符全為英文字符,所以我們哈希表的實現可以是用 大小為128 的數組實現,也可以是用容器unordered_map 來實現;?
首先是要將 t 中的字符全部放入hash1 之中,然后是入窗口,將right 指向的字符放入hash2 之中。按照前面幾道題的做題邏輯,此時我們應該判斷是否要出窗口。如何出窗口呢?當[left,right] 區間中給的字符符合要求,暴力枚舉的思想是:left++,right 回到left 指向的地方;但是符合要求了不統計就直接left++?顯然本題就需要先更新數據然后再判斷是否要出窗口;
還需要注意的一個點是,想要判斷hash2 中是否都有hsah1 中的字符與個數時,無論是用數組實現的哈希表還是利用容器unordered_map 實現的哈希表均要一個遍歷比較,有點消耗效率;此處可以參考前幾道題用過的策略來進行優化:利用變量來記錄[left,right] 中有效數據的個數;
思路總結:

參考代碼1:
此處使用unordered_map 實現的
string minWindow(string s, string t) {int n = s.size() , m = t.size();unordered_map<char , int> hash1,hash2;for(auto ch : t) hash1[ch]++;int left = 0, right = 0, count = 0 , retlen = INT_MAX, begin = -1;while(right < n){//入窗口char in = s[right];hash2[in]++;//統計窗口中有效數據的個數if(hash1[in] && hash2[in] <= hash1[in]) count++;//更新數據while(count == m){int len = right - left +1;if(len < retlen){retlen = len;begin = left;}char out = s[left];//維護countif(hash1[out] && hash2[out]<=hash1[out]) count--;hash2[out]--;left++;}right++;}if(begin == -1) return "";//直接返回空字符串return s.substr(begin , retlen);}參考代碼2:
代碼二的哈希表就用數組實現并且簡化代碼的書寫:
string minWindow(string s, string t) {int n = s.size() , m = t.size();int hash1[128] = {0};int hash2[128] = {0};for(auto ch : t) hash1[ch]++;int left = 0, right = 0, count = 0 , retlen = INT_MAX, begin = -1;while(right < n){//入窗口char in = s[right];//統計窗口中有效數據的個數if(hash1[in] && ++hash2[in] <= hash1[in]) count++;//更新數據while(count == m){int len = right - left +1;if(len < retlen){retlen = len;begin = left;}char out = s[left++];//維護countif(hash1[out] && hash2[out]-- <= hash1[out]) count--;}right++;}if(begin == -1) return "";//直接返回空字符串return s.substr(begin , retlen);}總結
既然看到這里了,那就把這些題再做一遍吧~
- 209.?長度最小的子數組
- 3.?無重復字符的最長子串
- 1004.?最大連續1的個數 III
- 1658.?將 x 減到 0 的最小操作數
- 904.?水果成籃
- 438.?找到字符串中所有字母異位詞
- 30.?串聯所有單詞的子串
- 76.?最小覆蓋子串
滑動窗口,無非就是利用兩個同向雙指針,根據題干的要求設置入窗口的條件、出窗口的條件以及什么時候更新結果;需要注意的是,更新結果的地方是不確定的,可能是在入窗口后更新結果,也有可能是在出窗口之后才更新結果,需要根據具體的題意定奪;

)





)





)




——應用 源碼)
)