1 分析器概述
????????在文本處理中,分析器是將原始文本轉換為結構化可搜索格式的關鍵組件。每個分析器通常由兩個核心部件組成:標記器和過濾器。它們共同將輸入文本轉換為標記,完善這些標記,并為高效索引和檢索做好準備。
????????在 Milvus 中,創建 Collections 時,將VARCHAR?字段添加到 Collections Schema 時,會對分析器進行配置。分析器生成的標記可用于建立關鍵字匹配索引,或轉換為稀疏嵌入以進行全文檢索。
????????使用分析器可能會影響性能:
-
全文搜索:對于全文搜索,數據節點和查詢節點通道消耗數據的速度更慢,因為它們必須等待標記化完成。因此,新輸入的數據需要更長的時間才能用于搜索。
-
關鍵詞匹配:對于關鍵字匹配,索引創建速度也較慢,因為標記化需要在索引建立之前完成。
1.1?分析器剖析
????????Milvus 的分析器由一個標記化器和零個或多個過濾器組成。
-
標記化器:標記器將輸入文本分解為稱為標記的離散單元。根據標記符類型的不同,這些標記符可以是單詞或短語。
-
過濾器:可以對標記符進行過濾,進一步細化標記符,例如將標記符變成小寫或刪除常用詞。
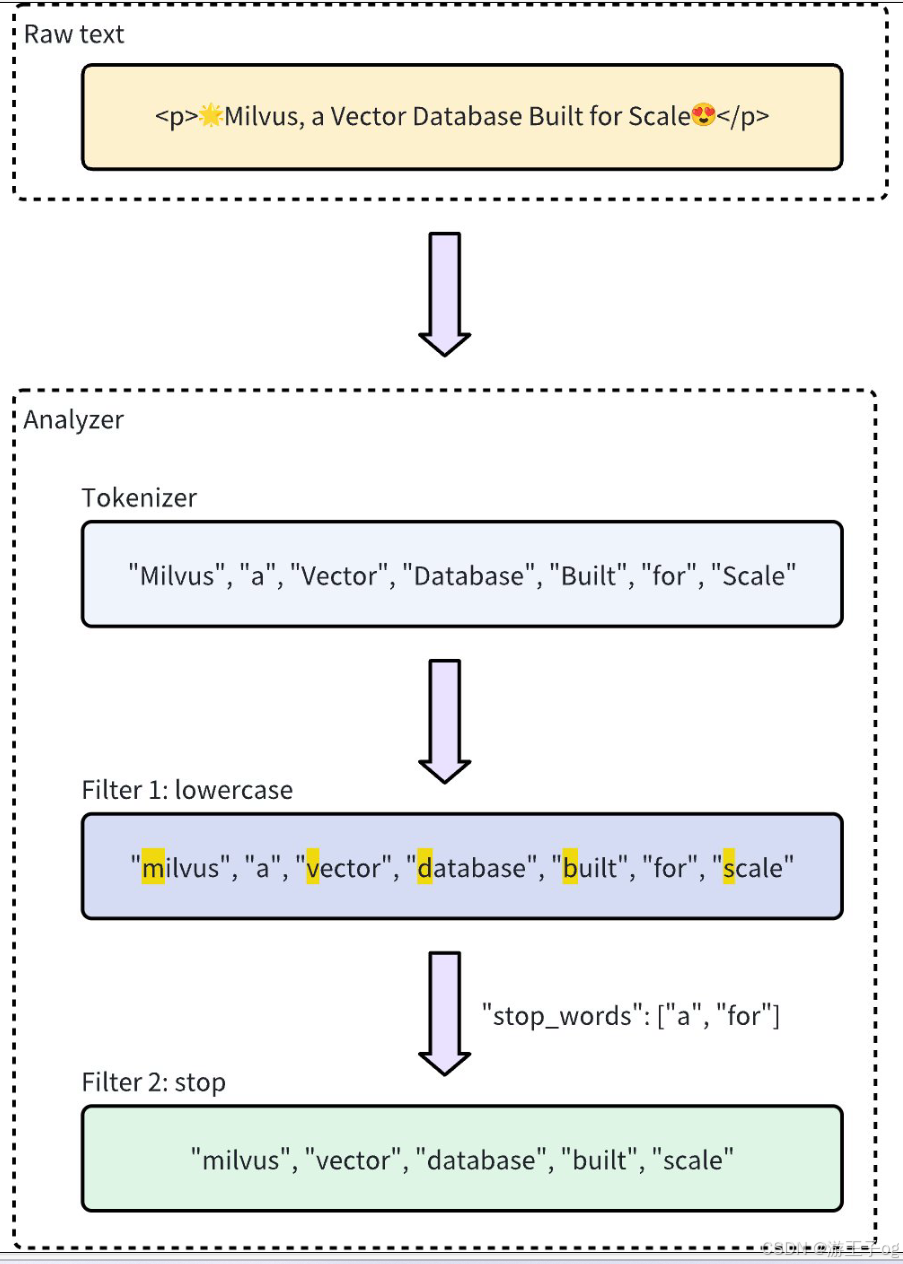
????????標記符僅支持 UTF-8 格式。未來版本將增加對其他格式的支持。下面的工作流程顯示了分析器如何處理文本。
1.2?分析器類型
????????Milvus 提供兩種類型的分析器,以滿足不同的文本處理需求:
-
內置分析器:這些是預定義配置,只需最少的設置即可完成常見的文本處理任務。內置分析器不需要復雜的配置,是通用搜索的理想選擇。
-
自定義分析器:對于更高級的需求,自定義分析器允許你通過指定標記器和零個或多個過濾器來定義自己的配置。這種自定義級別對于需要精確控制文本處理的特殊用例尤其有用。
????????如果在創建 Collections 時省略了分析器配置,Milvus 默認使用standard?分析器進行所有文本處理。
1.2.1?內置分析器
????????Milvus 中的內置分析器預先配置了特定的標記符號化器和過濾器,使你可以立即使用它們,而無需自己定義這些組件。每個內置分析器都是一個模板,包括預設的標記化器和過濾器,以及用于自定義的可選參數。
????????例如,要使用standard?內置分析器,只需將其名稱standard?指定為type?,并可選擇包含該分析器類型特有的額外配置,如stop_words?:
analyzer_params = {"type": "standard", # 使用標準的內置分析器"stop_words": ["a", "an", "for"] # 定義要從標記化中排除的常用單詞(停止詞)列表
}????????上述standard?內置分析器的配置等同于使用以下參數設置自定義分析器,其中tokenizer?和filter?選項是為實現類似功能而明確定義的:
analyzer_params = {"tokenizer": "standard","filter": ["lowercase",{"type": "stop","stop_words": ["a", "an", "for"]}]
}
????????Milvus 提供以下內置分析器,每個分析器都是為特定文本處理需求而設計的:
standard:適用于通用文本處理,應用標準標記化和小寫過濾。english:針對英語文本進行了優化,支持英語停止詞。chinese:專門用于處理中文文本,包括針對中文語言結構的標記化。
1.2.2?自定義分析器
????????對于更高級的文本處理,Milvus 中的自定義分析器允許您通過指定標記化器和過濾器來構建定制的文本處理管道。這種設置非常適合需要精確控制的特殊用例。
????????標記化器是自定義分析器的必備組件,它通過將輸入文本分解為離散單元或標記來啟動分析器管道。標記化遵循特定的規則,例如根據標記化器的類型用空白或標點符號分割。這一過程可以更精確、更獨立地處理每個單詞或短語。
????????例如,標記化器會將文本"Vector Database Built for Scale"?轉換為單獨的標記:
["Vector", "Database", "Built", "for", "Scale"]????????指定標記符的示例:?
analyzer_params = {"tokenizer": "whitespace",
}????????過濾器是可選組件,用于處理標記化器生成的標記,并根據需要對其進行轉換或細化。例如,在對標記化術語["Vector", "Database", "Built", "for", "Scale"]?應用lowercase?過濾器后,結果可能是:
["vector", "database", "built", "for", "scale"]????????自定義分析器中的過濾器可以是內置的,也可以是自定義的,具體取決于配置需求。
-
內置過濾器:由 Milvus 預先配置,只需最少的設置。您只需指定過濾器的名稱,就能立即使用這些過濾器。以下是可直接使用的內置過濾器:
-
lowercase:將文本轉換為小寫,確保不區分大小寫進行匹配。 -
asciifolding:將非 ASCII 字符轉換為 ASCII 對應字符,簡化多語言文本處理。 -
alphanumonly:只保留字母數字字符,刪除其他字符。 -
cnalphanumonly:刪除包含除漢字、英文字母或數字以外的任何字符的標記。 -
cncharonly:刪除包含任何非漢字的標記。
-
????????使用內置過濾器的示例:
analyzer_params = {"tokenizer": "standard", # 必選:指定標記器"filter": ["lowercase"], # 可選:內置過濾器,將文本轉換為小寫
}????????自定義過濾器:自定義過濾器允許進行專門配置。您可以通過選擇有效的過濾器類型 (filter.type) 并為每種過濾器類型添加特定設置來定義自定義過濾器。支持自定義的過濾器類型示例:
-
stop:通過設置停止詞列表(如"stop_words": ["of", "to"]?)刪除指定的常用詞。 -
length:根據長度標準(如設置最大標記長度)排除標記。 -
stemmer:將單詞還原為詞根形式,以便更靈活地進行匹配。
????????配置自定義過濾器的示例:
analyzer_params = {"tokenizer": "standard", # 必選:指定標記器"filter": [{"type": "stop", # 指定‘stop’作為過濾器類型"stop_words": ["of", "to"], # 指定‘stop’作為過濾器類型}]
}1.3?使用示例
????????在本示例中,您將創建一個 Collections Schema,其中包括:
-
一個用于嵌入的向量字段。
-
兩個
VARCHAR?字段,用于文本處理:-
一個字段使用內置分析器。
-
其他使用自定義分析器。
-
1.3.1?初始化 MilvusClient 并創建 Schema
????????首先設置 Milvus 客戶端并創建新的 Schema。
from pymilvus import MilvusClient, DataType# 設置一個Milvus客戶端
client = MilvusClient(uri="http://localhost:19530")# 創建一個新模式
schema = client.create_schema(auto_id=True, enable_dynamic_field=False)1.3.2?定義和驗證分析儀配置
????????配置并驗證內置分析器(english):定義內置英文分析器的分析器參數。
# 內置分析器配置,用于英文文本處理
analyzer_params_built_in = {"type": "english"
}????????配置并驗證自定義分析器:定義自定義分析器,該分析器使用標準標記符號生成器、內置小寫過濾器以及標記符號長度和停用詞自定義過濾器。
# 自定義分析器配置與標準標記器和自定義過濾器
analyzer_params_custom = {"tokenizer": "standard","filter": ["lowercase", # 內置過濾器:將令牌轉換為小寫{"type": "length", # 自定義過濾器:限制令牌長度"max": 40},{"type": "stop", # 自定義過濾:刪除指定的停止詞"stop_words": ["of", "for"]}]
}
1.3.3?向 Schema 添加字段
????????在驗證了分析器配置后,請將其添加到 Schema 字段中:
# 使用內置分析器配置添加VARCHAR字段‘title_en’
schema.add_field(field_name='title_en',datatype=DataType.VARCHAR,max_length=1000,enable_analyzer=True,analyzer_params=analyzer_params_built_in,enable_match=True,
)# 使用自定義分析器配置添加VARCHAR字段“title”
schema.add_field(field_name='title',datatype=DataType.VARCHAR,max_length=1000,enable_analyzer=True,analyzer_params=analyzer_params_custom,enable_match=True,
)# 為嵌入添加矢量場
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)# 添加主鍵字段
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)1.3.4?準備索引參數并創建 Collections
# 為矢量場設置索引參數
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")# 使用已定義的模式和索引參數創建集合
client.create_collection(collection_name="my_collection",schema=schema,index_params=index_params
)2 內置分析器
2.1 標準
? ?standard?分析器是 Milvus 的默認分析器,如果沒有指定分析器,它將自動應用于文本字段。它使用基于語法的標記化,對大多數語言都很有效。
2.1.1?定義
? ?standard?分析器包括
- 標記化器:使用
standard?標記符號化器,根據語法規則將文本分割成離散的單詞單位。 - 過濾器:使用
lowercase?過濾器將所有標記轉換為小寫,從而實現不區分大小寫的搜索。
? ?standard?分析器的功能相當于以下自定義分析器配置:
analyzer_params = {"tokenizer": "standard","filter": ["lowercase"]
}2.1.2?配置
????????要將standard?分析器應用到一個字段,只需在analyzer_params?中將type?設置為standard?,并根據需要加入可選參數即可。
analyzer_params = {"type": "standard", # 指定標準分析器類型
}? ?standard?分析器接受以下可選參數:
| 參數 | 說明 |
|---|---|
|
| 一個數組,包含將從標記化中刪除的停用詞列表。默認為 |
????????自定義停止詞配置示例:
analyzer_params = {"type": "standard", # 指定標準分析器類型"stop_words", ["of"] # 可選:要從標記化中排除的單詞列表analyzerParams = map[string]any{"type": "standard", "stop_words": []string{"of"}}????????定義analyzer_params?后,您可以在定義 Collections Schema 時將其應用到VARCHAR?字段。這樣,Milvus 就能使用指定的分析器處理該字段中的文本,從而實現高效的標記化和過濾。
2.1.3 示例
????????分析器配置
analyzer_params = {"type": "standard", # 標準分析儀配置"stop_words": ["for"] # 可選:自定義停止詞參數
}????????預期輸出
Standard analyzer output: ['the', 'milvus', 'vector', 'database', 'is', 'built', 'scale']2.2?英語
????????Milvus 中的english?分析器旨在處理英文文本,應用特定語言規則進行標記化和過濾。
2.2.1 定義
? ?english?分析器使用以下組件:
-
標記化器:使用
standard?標記化器將文本分割成離散的單詞單位。 -
過濾器:包括多個過濾器,用于全面處理文本:
-
lowercase:將所有標記轉換為小寫,從而實現不區分大小寫的搜索。 -
stemmer:將單詞還原為詞根形式,以支持更廣泛的匹配(例如,"running "變為 "run")。 -
stop_words:刪除常見的英文停止詞,以便集中搜索文本中的關鍵詞語。
-
? ?english?分析器的功能相當于以下自定義分析器配置:
analyzer_params = {"tokenizer": "standard","filter": ["lowercase",{"type": "stemmer","language": "english"}, {"type": "stop","stop_words": "_english_"}]
}2.2.2?配置
????????要將english?分析器應用到一個字段,只需在analyzer_params?中將type?設置為english?,并根據需要加入可選參數即可。
analyzer_params = {"type": "english",
}? ?english?分析器接受以下可選參數:
| 參數 | 說明 |
|---|---|
|
| 一個數組,包含將從標記化中刪除的停用詞列表。默認為 |
????????自定義停止詞配置示例:
analyzer_params = {"type": "english","stop_words": ["a", "an", "the"]
}????????定義analyzer_params?后,您可以在定義 Collections Schema 時將其應用到VARCHAR?字段。這樣,Milvus 就能使用指定的分析器處理該字段中的文本,以實現高效的標記化和過濾。
2.2.3?示例
????????分析器配置
analyzer_params = {"type": "english","stop_words": ["a", "an", "the"]
}????????預期輸出
English analyzer output: ['milvus', 'vector', 'databas', 'built', 'scale']2.3?中文
? ? chinese?分析器專為處理中文文本而設計,提供有效的分段和標記化功能。
2.3.1 定義
? ?chinese?分析器包括
- 標記化器:使用
jieba?標記化器,根據詞匯和上下文將中文文本分割成標記。 - 過濾器:使用
cnalphanumonly?過濾器刪除包含任何非漢字的標記。
? ?chinese?分析器的功能相當于以下自定義分析器配置:
analyzer_params = {"tokenizer": "jieba","filter": ["cnalphanumonly"]
}2.3.2 配置
????????要將chinese?分析器應用到一個字段,只需在analyzer_params?中將type?設置為chinese?即可。chinese?分析器不接受任何可選參數。
analyzer_params = {"type": "chinese",
}2.3.3?示例
????????分析器配置
analyzer_params = {"type": "chinese",
}????????預期輸出
Chinese analyzer output: ['Milvus', '是', '一個', '高性', '性能', '高性能', '可', '擴展', '的', '向量', '數據', '據庫', '數據庫'])


)







![[Survey]SAM2 for Image and Video Segmentation: A Comprehensive Survey](http://pic.xiahunao.cn/[Survey]SAM2 for Image and Video Segmentation: A Comprehensive Survey)



)

:dos2unix)
細節補充)
