BaseInfo
| Title | SAM2 for Image and Video Segmentation: A Comprehensive Survey |
| Adress | https://arxiv.org/abs/2503.12781 |
| Journal/Time | 2503 |
| Author | 四川大學,北京大學 |
1. Introduction
圖像分割專注于識別單個圖像中的目標、邊界或紋理,而視頻分割則將這一過程擴展到時間維度,旨在分割連續的視頻幀,同時確保時空一致性。
大規模基礎模型的出現徹底改變了人工智能研究領域,展現出卓越的零樣本和少樣本學習能力 。
首先,由于 SAM 的預訓練主要依賴自然圖像 ,它難以有效地適應其他領域,從而導致準確率降低。其次,SAM 主要在 2D 圖像上進行訓練,這限制了其在處理 3D 醫學圖像和其他復雜數據類型時的性能 。最后,SAM 在處理視頻分割任務時遇到困難,因為視頻數據中的時間連續性和動態特征與靜態圖像的要求有很大差異 。
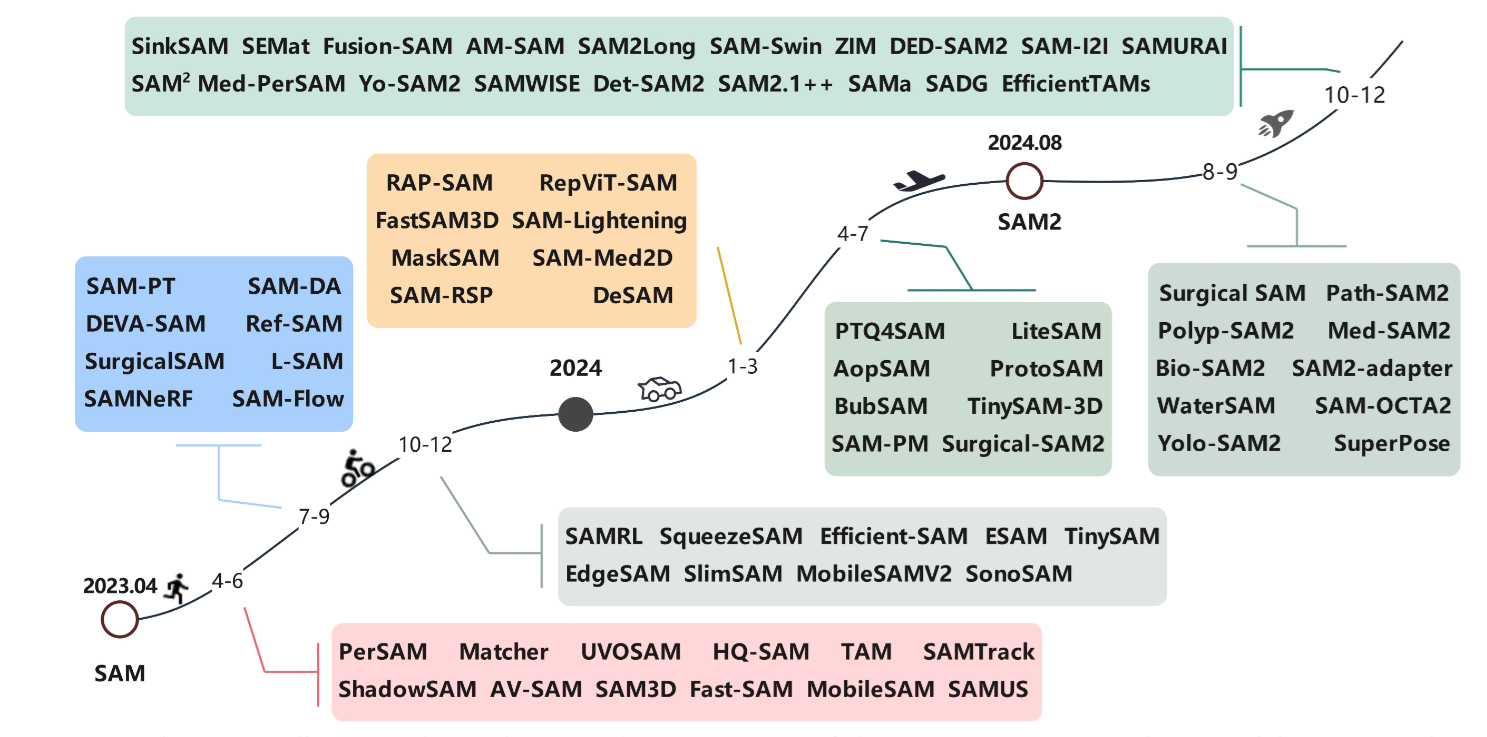
- 全面回顧了分割的基礎概念、基礎模型的概念與分類,以及 SAM 和 SAM2 的技術特點。我們還討論了將 SAM/SAM2 拓展到其他領域的努力。
- 總結當前的研究進展,并在視頻和靜態圖像這兩個主要方面評估 SAM2 的分割性能。在分析其在自然圖像上的性能時,我們特別強調其在醫學專業領域的應用,因為其他專業領域的研究仍然有限。
- 總結 SAM2 在圖像和視頻分割中的特點,討論當前的技術挑戰,并探索未來的發展方向。
2. 預備知識
- 圖像分割:被定義為用語義標簽對像素進行分類的任務(語義分割),將單個對象(實例分割)進行劃分,或同時處理這兩項任務(全景分割)。交互式分割使用戶能夠通過提供輸入和反饋,參與分割過程。
- 視頻分割:視頻對象分割(VOS)分離視頻中的特定對象,而無需詳細的語義標注 ,視頻語義分割(VSS)每個像素分配預定義的語義類別(如 “人” 或 “車”),同時確保幀間的標簽一致性。
零樣本學習在幾乎沒有訓練樣本的情況下執行分割任務,而少樣本學習僅使用少量標記樣本就能使模型有效訓練。
2.2 基礎模型 FMs
在大規模數據集上進行預訓練、在特定任務中表現良好的機器學習模型 。大規模預訓練、泛化能力和可遷移性。
- 視覺基礎模型:統一處理各種視覺任務。這些模型通常在大規模數據集上進行預訓練,通過多任務微調學習豐富的視覺特征,從而增強其在多個領域的性能 。CLIP 、ViT
- 通用分割模型:旨在處理各種類型的圖像分割任務,能夠有效地應對不同的輸入和任務類型 。SAM、 SAM2
- 專用模型專注于特定任務,而基礎模型可以處理更廣泛的任務范圍,無論是在單個領域還是跨多個學科 。
2.3 圖像分割的演變

- SAM主要由三個主要組件構成:圖像編碼器、掩碼解碼器和提示編碼器。圖像編碼器對 MAE預訓練的視覺 Transformer(ViT) 進行了最小程度的調整,以處理高分辨率輸入。提示編碼器通過納入位置編碼來處理各種用戶輸入,如點、框或文本,從而引導分割過程。它將這些提示編碼為與圖像特征空間對齊的特征,以便在分割過程中實現無縫集成和有效引導。掩碼解碼器使用經過修改的 Transformer 解碼器模塊,隨后是動態掩碼預測頭,以生成將分割掩碼與提示嵌入有效結合的嵌入。
- SAM2 是一種先進的視覺分割模型,它在其前身 SAM 的基礎上進行構建,通過納入基于 Transformer 的架構與流式記憶組件相結合。這一增強功能使 SAM2 能夠支持實時視頻分割和對象跟蹤,以應對移動場景帶來的動態挑戰。SAM2 的架構針對實時視頻分割和對象跟蹤進行了優化,分層圖像編碼器對每一幀執行初始特征提取,生成未編碼的特征,并在每次交互后運行內存表示。記憶注意力模塊通過將當前幀特征與過去幀的特征以及任何新提示進行對比,利用高效的自注意力和交叉注意力機制,從過去幀中調節時間上下文。為處理用戶輸入,提示編碼器(與 SAM 相同)將提示(如點、框或掩碼點擊)作為正或負信號進行包圍。然后,掩碼解碼器(類似于 SAM)使用分割頭將這些信號與圖像特征相結合,生成最終的分割掩碼,保持了 SAM 方法的連續性。記憶編碼器通過對輸出掩碼進行下采樣并將其與無條件層嵌入相結合來優化記憶特征,通過輕量級卷積層實現。最后,memory bank 存儲預測結果,提高準確性并減少用戶輸入。
- SAM 和 SAM2 在適用范圍、架構以及實際應用場景方面存在顯著差異。SAM2 增加了 a streaming memory component,包括 圖像編碼器、記憶注意力模塊和memory bank。SAM 通常用于單幀分割任務,如對象識別,而 SAM2 支持跨視頻序列的對象跟蹤,使其特別適用于需要時間連續性的場景,如視頻編輯和動態對象檢測,尤其是在自動駕駛領域。在適用范圍方面,SAM 主要針對靜態圖像分割任務,如對象分割、單幀圖像分析(如醫學圖像分析)或衛星圖像分割等領域。另一方面,SAM2 進一步擴展到視頻分割和動態場景,專注于實時處理,使其非常適合連續幀任務,如自動駕駛和視頻監控。
3. SAM2 for Image
3.1 Networks
圖像分割網絡的近期進展進行了梳理,依據基礎架構對方法分類,突出各方法獨特特征與目標應用,重點關注基于 SAM 和 SAM2 方法的演變及能力.
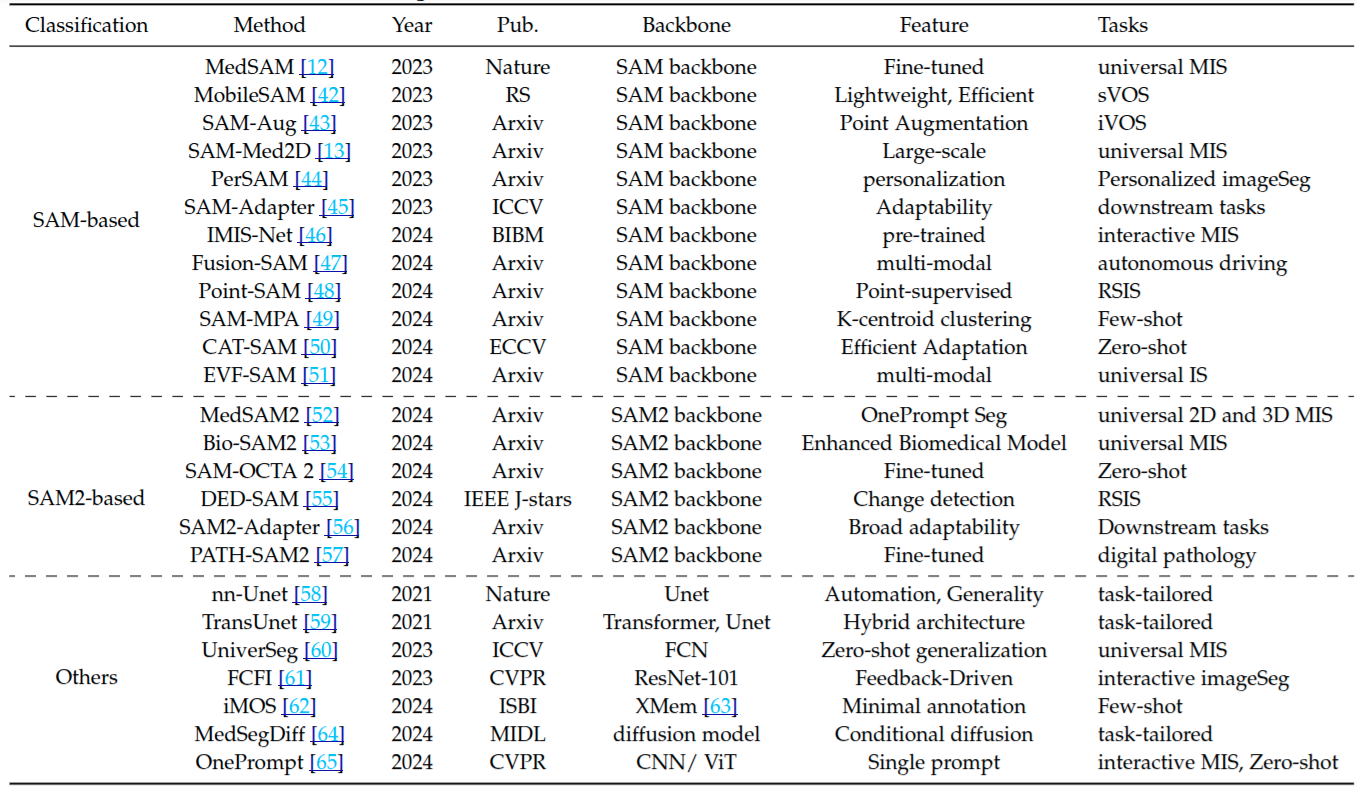
3.2 Datasets
關于自然圖像數據集的,詳細說明了類別、數據集名稱、描述、掩碼類型、采樣圖像數量、采樣掩碼數量以及發布來源

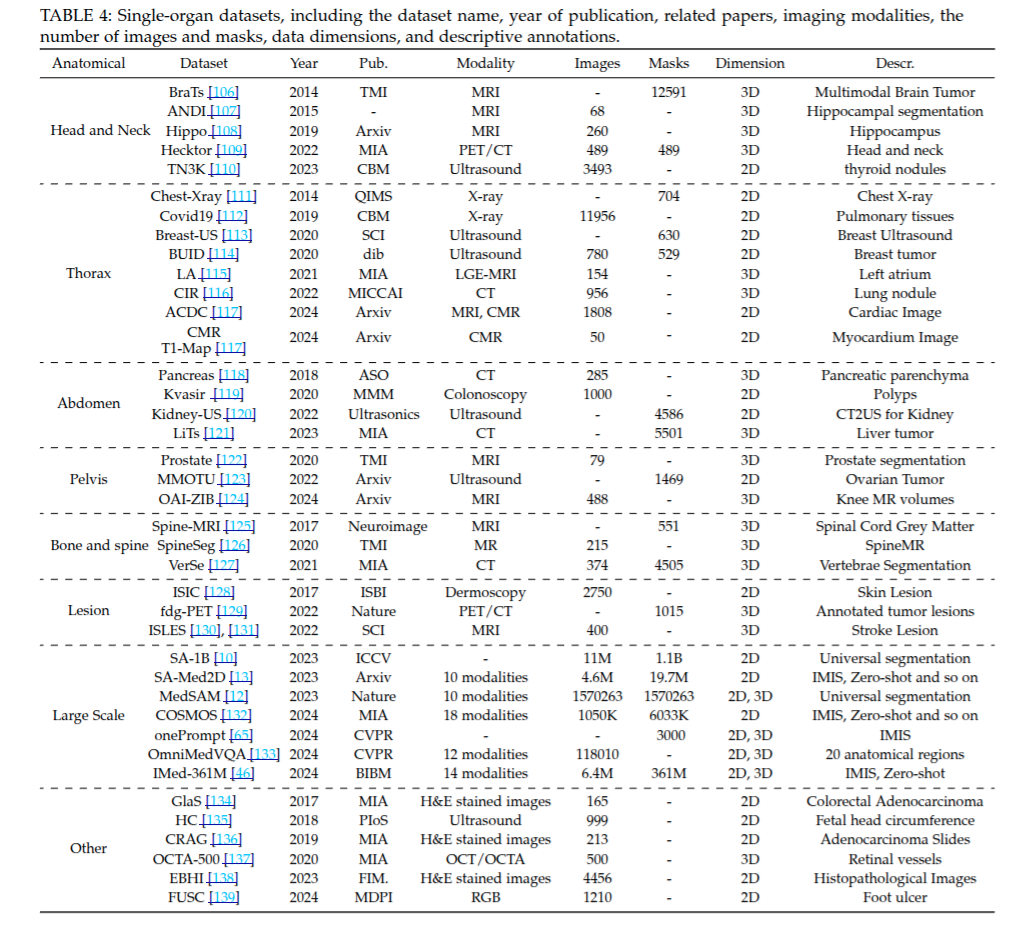
關于醫學的單器官數據集的信息匯總,包含數據集名稱、發布年份、發表出處、成像模態、圖像數量、掩碼數量、數據維度以及描述性注釋
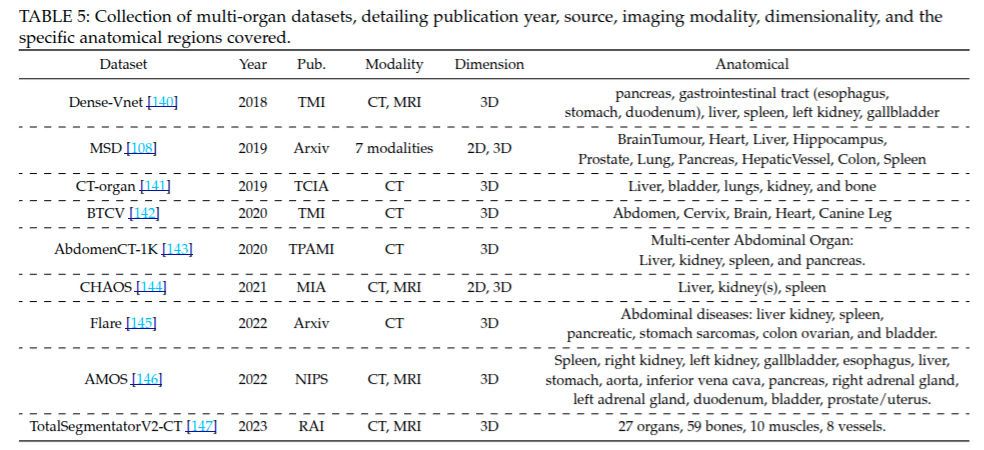
多器官數據集的匯總,詳細列出了數據集的發布年份、來源、成像模態、維度以及涵蓋的特定解剖區域
3.3 Evaluate Metrics
主要集中于分割結果的準確性和模型的穩健性。
- IoU 是一種用于衡量預測分割區域與真實區域之間重疊程度的指標。oU 值越高,表示分割準確性越好。 I o U = ∣ A ∩ B ∣ ∣ A ∪ B ∣ IoU = \frac{|A \cap B|}{|A \cup B|} IoU=∣A∪B∣∣A∩B∣?其中,A 是預測分割區域,B 是真實區域。
- Dice 當目標區域較小或不規則時(這在醫學圖像分割中很常見),它特別適用于評估兩個集合之間的相似度。$Dice = \frac{2 \cdot |A \cap B|}{|A| + |B|}$
- mIoU 是多類別分割任務中所有類別的平均 IoU。 m I o U = 1 N ∑ i = 1 N ∣ A i ∩ B i ∣ ∣ A i ∪ B i ∣ mIoU = \frac{1}{N}\sum_{i = 1}^{N}\frac{|A_{i} \cap B_{i}|}{|A_{i} \cup B_{i}|} mIoU=N1?∑i=1N?∣Ai?∪Bi?∣∣Ai?∩Bi?∣? N 為類別總數。
- PA 像素準確率衡量正確預測的像素數占總像素數的比例。可用于評估模型的整體性能,但在類別不平衡的情況下可能無法反映真實性能。 P A = 1 N ∑ i = 1 N ( y ^ i = y i ) PA = \frac{1}{N}\sum_{i = 1}^{N}(\hat{y}_{i} = y_{i}) PA=N1?∑i=1N?(y^?i?=yi?)
4. SAM2 FOR VIDEO
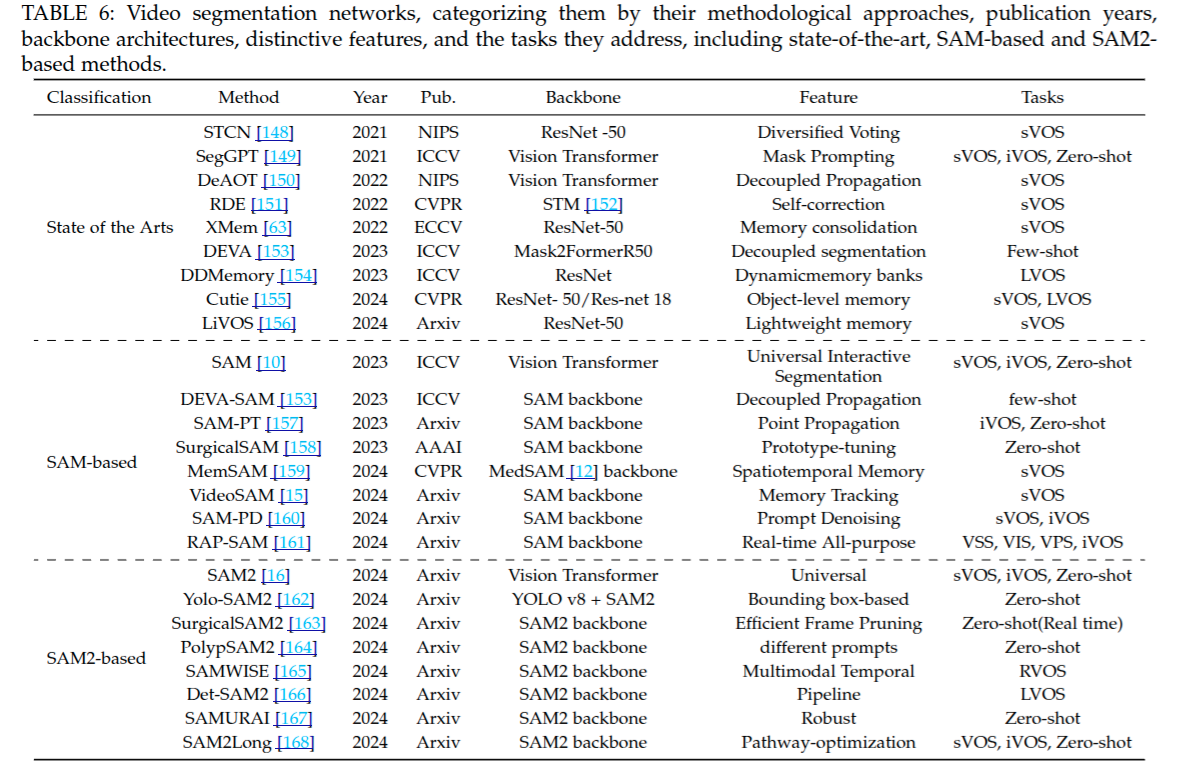
對視頻分割網絡進行了分類梳理,依據方法、發表年份、骨干架構、獨特特征以及處理任務來劃分,涵蓋前沿方法、基于 SAM 和基于 SAM2 的方法.
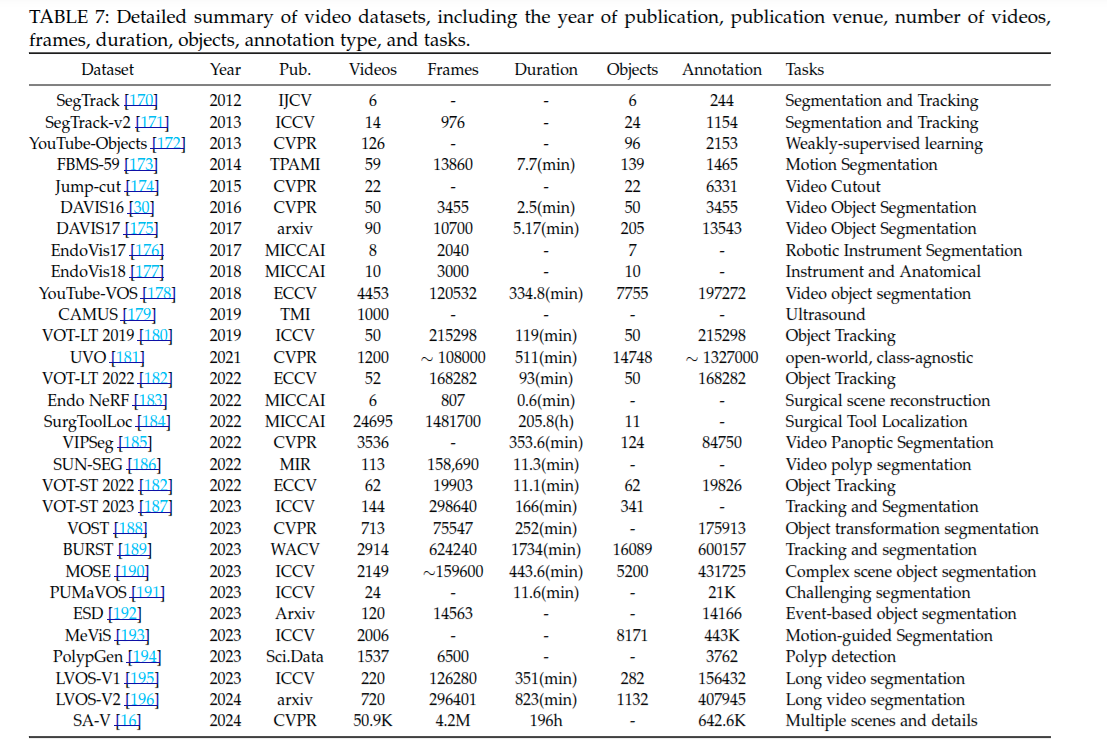
對視頻數據集的詳細總結,包含了數據集的發布年份、發表出處、視頻數量、幀數、時長、對象數量、注釋類型以及相關任務.
4.3 Evaluate Metrics
在時間分析方面,對分割的穩定性、一致性和單個分割幀的連續性提出了更高要求。在視頻分割中,分割掩碼必須同時確保空間分割精度和時間一致性,避免出現如對象跳躍或跨幀漂移等問題。因此,在評估視頻分割模型時,除了使用如 IoU 和 Dice 等圖像分割指標外,還必須考慮時間維度,以全面評估分割結果在空間和時間方面的性能。
- 區域相似度 J 和輪廓精度 F
給定預測分割掩碼 J ∈ { 0 , 1 } H × W J \in \{0, 1\}^{H \times W} J∈{0,1}H×W 和真實掩碼 M ∈ { 0 , 1 } H × W M \in \{0, 1\}^{H \times W} M∈{0,1}H×W,M 和 J 之間的區域相似度(交并比,IoU)為:
J = J ∩ M J ∪ M J = \frac{J \cap M}{J \cup M} J=J∪MJ∩M?為評估 M 的輪廓質量,我們使用比特圖匹配計算輪廓召回率 R c R_c Rc? 和輪廓精度 P c P_c Pc?,然后通過調和平均數計算輪廓準確率 F:
F = 2 P c R c P c + R c F = \frac{2P_cR_c}{P_c + R_c} F=Pc?+Rc?2Pc?Rc??該指標量化了預測掩碼的輪廓與真實掩碼的輪廓緊密匹配的程度。對于多個對象,我們對所有對象取該指標的平均值。最后,通過計算區域相似度和輪廓準確率的算術平均值來衡量整體性能,即聯合度量 J & F J\&F J&F:
J & F = J + F 2 J\&F = \frac{J + F}{2} J&F=2J+F? - 全局準確率Global Accuracy 預測分割中正確分類的像素數與總像素數的比例。
- 時間指標:幀率(FPS)視頻分割或分析系統在一秒內處理的幀數,反映了系統在實時應用中的穩定性和速度。更高的 FPS 表示模型能夠更快地處理視頻數據,使其適合實時任務。
5. DISCUSSION
5.1 Current Challenges
- 域適應限制(Domain Adaptation Limitations ):SAM2 在零樣本任務表現尚可,但在醫學影像、遙感等特定領域,需專門微調才能達最佳性能。因常依賴復雜上下文信息且缺乏針對性數據,模型泛化能力受限。微調還面臨計算成本高、數據標注不足等問題,凸顯高效域適應技術和高質量標注數據集的迫切需求。
- 多模態集成(Multimodal Integration ):將 SAM2 與多模態模型高效集成頗具挑戰。雖 SAM2 有結合文本描述處理多模態數據的潛力,但有效融合多模態數據復雜,需處理數據對齊、模態特異性差異,且要維持各模態性能。未來需提升模型多模態交互融合能力,以處理復雜多模態數據流。
- 推理速度與資源需求(Inference Speed and Resource Requirements ):SAM2 規模大且復雜,用于實時應用(如自動駕駛、視頻分析)時,因尺寸大,推理速度慢、資源消耗高,影響部署。處理多幀分割等任務,需兼顧速度與準確性,降低計算開銷并維持性能,高效資源管理是關鍵。
5.2 Future Works
- 特定領域微調(Fine - Tuning for Specialized Field ):開發更高效針對特定領域(醫學影像、遙感等)的微調策略,提升模型適應性和性能,使其能更好處理實際應用任務,提高分割精度。
- 輕量化優化(Lightweight Optimization ):運用模型剪枝、知識蒸餾等技術,降低模型計算開銷,提升推理效率,優化架構確保在資源受限實時應用中仍有高性能。
- 增強多模態交互(Enhanced Multimodal Interaction ):深入研究 SAM2 與多模態模型集成,探索文本與視覺信息互補性,用于復雜多樣任務(智能問答、圖像文本分析)。
- 提高穩健性(Improving Robustness ):訓練時納入更多復雜多樣數據集,使模型適應遮擋、目標重現等復雜場景,提升穩定性和適應性。
References
這個的 17-22 參考文獻都是 SAM 或 SAM2 的綜述



)

:dos2unix)
細節補充)


:閱讀與注釋單選框這個類型的按鈕 QRadioButton,及各種屬性驗證,)






![P4552 [Poetize6] IncDec Sequence 題解](http://pic.xiahunao.cn/P4552 [Poetize6] IncDec Sequence 題解)


)