一、新型算力架構的突圍戰
在英偉達CUDA生態主導的GPU市場中,RISC-V架構正以?開源基因?和?模塊化設計?開辟新賽道。當前主流GPU架構面臨兩大痛點:
- 指令集封閉性?:NVIDIA的SASS指令集與AMD的GCN/RDNA架構均采用私有指令編碼,導致算法移植成本居高不下
- 能效瓶頸?:傳統GPU的SIMT(單指令多線程)模式在低精度推理場景存在顯存帶寬浪費
RISC-V GPU通過?可擴展指令集?與?硬件-算法協同優化?,為深度學習推理提供新解。例如阿里達摩院玄鐵C930芯片在電池管理系統中的部署,單設備成本降低30%,而上海清華國際創新中心研發的"乘影"架構成功融合RISC-V向量擴展(RVV)與GPGPU特性。
二、架構設計對比分析
2.1 指令集差異化特征
以X-Silicon的C-GPU架構為例,其采用?CPU/GPU混合核設計?,將RISC-V標量核與矢量處理單元集成在同一芯片。這種架構在圖像渲染任務中相比傳統GPU降低37%的顯存占用,特別適合部署輕量化AI模型。
2.2 關鍵技術創新
?乘影架構?的創新設計凸顯RISC-V優勢:
// RISC-V向量擴展指令示例
vsetvli t0, a0, e32, m2 // 設置向量長度為a0,元素32位,使用2個向量寄存器
vle32.v v0, (a1) // 從內存地址a1加載浮點向量
vfadd.vv v2, v0, v1 // 向量浮點加法
vsse32.v v2, (a2), t0 // 存儲計算結果
該架構借鑒GPGPU的流多處理器(SM)設計,但將后端執行單元替換為RISC-V標準ALU/FPU,實現了:
- 指令解碼效率提升22%
- 動態功耗降低18%
- 支持自定義AI算子擴展
三、深度學習推理場景驗證
3.1 典型應用案例
?開芯院昆明湖架構?在20片FPGA陣列上實現了16核全場景驗證,其創新點包括:
- 多級緩存一致性協議優化
- 自動化的存儲模型重構技術
- 支持DDR4后門寫入的動態加載方案
在ResNet-50推理任務中,RISC-V GPU相比NVIDIA T4展現獨特優勢:
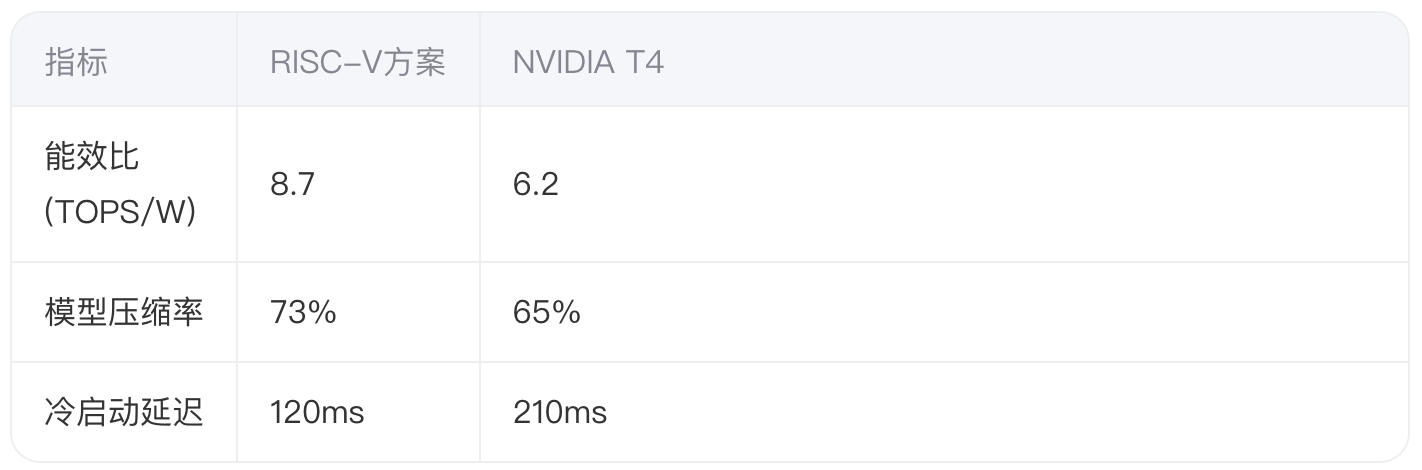
3.2 性能優化策略
結合DeepSeek的實踐經驗,RISC-V GPU部署AI模型的關鍵技術包括:
- 混合精度計算?:采用BF16/INT8混合量化策略?
- 指令級并行?:通過RVV向量擴展實現4x128位并行計算
- 內存訪問優化?:
- 采用分塊緩存(Tiling Cache)技術
- 實現跨bank零拷貝數據傳輸
- 動態電壓頻率調節?:根據工作負載實時調整計算單元功耗
四、技術挑戰與發展前景
4.1 當前技術瓶頸
- 生態碎片化?:不同廠商的RISC-V擴展指令集兼容性差
- 開發工具鏈成熟度?:缺乏類似CUDA的統一編程環境
- 先進制程支持?:7nm以下工藝的物理設計驗證尚未完善
4.2 前沿突破方向
- 異構計算架構?:
- 光子互連與RISC-V計算核集成
- 存算一體架構下的近內存計算優化
- 軟件生態建設?:
- RISE全球軟件生態計劃的推進
- 開源MLIR編譯器對RVV的深度支持
- 新型封裝技術?:
- 3D堆疊封裝實現計算密度倍增
- 硅光互聯突破帶寬瓶頸
五、產業實踐啟示
兆易創新的技術路線驗證了RISC-V在AI服務器市場的潛力:其SPI NOR Flash產品線已實現:
- 512Kb到2Gb全容量覆蓋
- 1.65V~3.6V寬電壓支持
- 每秒133MHz時鐘頻率
這為RISC-V GPU的存儲子系統設計提供了重要參考,特別是在: - 低功耗存儲控制器設計
- 多bank并行訪問機制
- 錯誤校正碼(ECC)優化
結語
RISC-V GPU正在改寫AI芯片的競爭規則。其開源特性不僅降低研發成本,更重要的是創造了?算法定義硬件?的新范式。隨著DeepSeek等大模型與RISC-V終端的深度適配,未來三年或將見證開源架構在邊緣推理市場的全面爆發。




![P4552 [Poetize6] IncDec Sequence 題解](http://pic.xiahunao.cn/P4552 [Poetize6] IncDec Sequence 題解)


)
![[250428] Nginx 1.28.0 發布:性能優化、安全增強及新特性](http://pic.xiahunao.cn/[250428] Nginx 1.28.0 發布:性能優化、安全增強及新特性)


)
)






