文章目錄
- 七、常見數據轉換
- 7.1 逆透視
- 7.1.1 逆透視操作
- 7.1.2 重建透視表,更新數據
- 7.1.3 三種逆透視方式(逆透視列等價于逆透視其他列)
- 7.2 透視
- 7.3 拆分列
- 7.3.1 將列拆分為多列
- 7.3.2 將列拆分為多行
- 7.3.3 拆分到列后逆透視(保留列標題信息) vs 拆分到行
- 7.4 篩選和排序
- 7.4.1 按特定值進行篩選(手動創建篩選器)
- 7.4.2 按上下文篩選
- 7.4.3 數據排序
- 7.5 數據分組
- 八、縱向追加數據
- 8.1 追加外部文件的數據
- 8.1.1 導入數據
- 8.1.2 選擇合適的追加方式
- 8.1.3 追加列標題不同的數據
- 8.2 在當前文件中追加表或區域
- 8.2.1 合并Excel表中的所有表(Table)
- 8.2.2 合并Excel表中的所有區域(Range)或工作表(sheet)
- 8.3 思考
- 十、橫向合并數據
- 10.1 基礎合并
- 10.2 復合鍵
- 10.3 連接類型
- 10.3.1 左外連接:左表所有行+右表匹配行
- 10.3.2 右外連接:右表所有行+左表匹配行
- 10.3.3 完全外部連接(并集):查看數據不一致情況
- 10.3.4 內部連接(交集,僅限匹配行)
- 10.3.5 左反連接、右反連接:只返回不匹配記錄(左表或右表)
- 10.3.6 全反連接:合并左反連接與右反連接
- 10.3.7 左半連接(左表的匹配行)與右半連接(右表的匹配行)
- 10.3 笛卡爾積(交叉連接)
- 10.3.1 實現方式
- 10.3.2 笛卡爾積風險
- 10.4 近似匹配(查找價格區間)
- 10.5 模糊匹配
- 10.5.1 基本模糊匹配方法
- 10.5.2 使用轉換表
- 10.5.3 降低相似度閾值
- 10.5.4 總結
- 十三、轉換表格數據
- 13.1透視
- 13.1.1 一維表透視(單列數據)
- 13.1.2 二維表透視(以行分組)
- 13.1.3 二維表透視(以列分組)
- 13.2 逆透視
- 13.2.1 多層行標題
- 13.2.2 性能優化
- 13.2.3 保留 null 值 (null->占位符->null)
- 13.3 分組
- 13.3.1 占總計的百分比
- 13.3.2 數據排名
- 13.3.2.1 順序排序
- 13.3.2.2 競爭排序(數值相同排名并列)
- 13.3.2.3 密集排序(數值相同排名不同)
- 13.3.3 分組編號(在每個分組級內添加序號)
- 十四、條件判斷
- 14.1 if表達式 與 非空數據的判斷
- 14.2 基礎條件邏輯(引發錯誤,篩選數據)
- 14.3 使用 try...otherwise 表達式簡化步驟
- 14.3.1 try...otherwise 表達式
- 14.3.2 簡化步驟
- 14.3.3 總結
- 14.4 多條件判斷
- 14.5 與上下行進行比較
- 14.6 使用示例列自動提取數據
- 十八、處理日期時間
- 18.1 日期表的邊界日期
- 18.1.1 計算邊界日期
- 18.1.2 處理非標準財年日期(結束日期不是12月31日)
- 18.1.3 處理非標準財年日期(每年364天)
- 18.2 原子日期表(每日)
- 18.2.1 標準財年
- 18.2.2 非標準財年(結束日期不是12月31日)
- 18.2.3 非標準財年(每年364天)
- 18.2.4 示例文件介紹
- 18.3 日期時間填充
- 18.3.1 日期級別填充
- 18.3.2 小時級別填充
- 18.3.3 帶時間間隔的填充
- 18.4 按日期分攤
- 18.4.1 起止日內按日分攤
- 18.4.2 起止日內按月分攤
- 18.4.3 起點日后按月分攤(15日規則)
全文參考《精通 Power Query》, 點此下載本文所有示例文件。
七、常見數據轉換
7.1 逆透視
??逆透視是將數據從透視表格式轉換回標準表格格式的過程,這種轉換在數據分析中非常常見,因為透視表格式的數據在某些情況下不便于進一步分析。比如下面這種已經透視過的表,難以進行進一步分析。

7.1.1 逆透視操作
??以第 07 章 示例文件 UnPivot.xlsx為例,演示【逆透視】過程。右擊數據表中有數據的任意單元格,選擇從表格/區域獲取數據:

- 刪除“Changed Type”步驟。Power Query使用硬編碼方式進行類型轉換,不利于維護,直接將其刪除。
- 刪除Total”列(合計列),因為后續很容易重建它
- 右擊“Sales Category”列,選擇【逆透視其他列】
- 將“屬性”列和“值”列分別重命名為“Date”和“Units”
- 將“Sales Category”、“Date”和“Units”的數據類型設置為【文本】、【日期】和【整數】
- 將查詢重命名為“Sales”

- 上載數據:轉到【主頁】,選擇【關閉并上載至】【表】【新工作表】,將“Sales”加載到一個新的工作表中。
7.1.2 重建透視表,更新數據
- 重新創建數據透視表:選擇“Sales”表中的任意一個單元格,【插入】【數據透視表】【現有工作表】,在【位置】中輸入F1;然后將行字段設為“Sales Category”,列字段設為“Date”,值設為“Units”

- 創建另一個數據透視表:在工作表的“F11”位置插入另一個數據透視表,將行字段設為“Sales Category”和“Date”,值設為“Units”。右擊“F12”單元格,折疊“Sales Category”字段。

- 更新數據:如果用戶更新了源數據,比如在Total列之后新增了2021-01-08這一天的數據,以及一個新的類別,Power Query可以自動適應這些變化,并正確刷新數據。

??轉到“Sales”工作表,分別單擊【全部刷新】【刷新】按鈕(第一個用于刷新查詢,第二用于刷新【數據透視表】),結果是:

7.1.3 三種逆透視方式(逆透視列等價于逆透視其他列)
??Power Query中有三個逆透視功能:逆透視列、逆透視其他列和僅逆透視選定列,它們主要區別在于如何處理未被選中的列。
- 逆透視其他列:Power Query會自動逆透視除這些列之外的所有其他列。當數據源中添加新列時,Power Query能夠正常處理這些新數據。
- 逆透視列:等價于逆透視其他列。
- Power Query會檢查數據集中的所有列,并確定哪些列沒有被選中。然后,它會根據這些未選中的列建立一個“逆透視其他列”步驟,而不是“逆透視列”步驟,所以二者其實是等價的。
- 還是以上個示例為例,選擇“2014-01-01”到“2014-01-07”的所有日期列,然后使用“逆透視列”命令,可以看到這一步的代碼還是
= Table.UnpivotOtherColumns(#"Removed Columns", {"Sales Category"}, "屬性", "值"),與選中Sales Category列之后選擇逆透其它列的公式相同。所以當添加 1 月 8 日的數據后,查詢能正確刷新。
- 僅逆透視選定列:如果用戶希望鎖定特定的逆透視操作,使得新添加的列不會被逆透視,他們可以使用“僅逆透視選定列”命令,指定將來要逆透視的唯一列。
建議使用 “逆透視其他列”或“僅逆透視選定列”命令,因為逆透視列步驟有一定的誤導性。
7.2 透視
以第 07 章 示例文件“/Pivot.xlsx”文件為例,其內容為:

- 導入數據:右擊表格任意單元格,選擇從表格/區域獲取數據
- 更改“Date”列為日期類型,將查詢重命名為“Sales”
- 選擇“Measure”列,選項【轉換】選項卡下的【透視列】選項,彈出以下對話框。


7.3 拆分列
??拆分列是數據清洗中常用的操作,特別是在從平面文件(如CSV或TXT文件)導入數據時,Power Query提供了多種選項來完成這個工作。以第 07 章示例文件 Splitting Data.txt為例,導入之后結果為:

7.3.1 將列拆分為多列
??右擊“Cooks: Grill/Prep/Line”列,選擇按分隔符拆分,Power Query 會掃描它認為是分隔符的內容(這里自動選擇了/),并且在大多數情況下,會得到正確的結果。拆分后,將新生成的列重命名為“Grill”,“Prep”和“Line”。

7.3.2 將列拆分為多行
??“Days”列中包含了一周中的多個天,需要將其拆分。一種方法是將每天拆分成新的列,然后對這些列使用【逆透視列】功能 ;更好的辦法是直接將“Days”列拆分到行。
- 使用“拆分列” -> “按分隔符”,Power Query自動選擇了換行符。
- 默認情況下,【按分隔符拆分列】功能會將數據將分成幾列,這里選擇拆分為行
- 由于換行的存在,【使用特殊字符進行拆分】的選項被自動選中。如果還需要其它特殊的字符,比如【Tab】、【回車】、【換行】或【不間斷空格】,都可以在【插入特殊字符】下拉列表選項中僅選擇。


7.3.3 拆分到列后逆透視(保留列標題信息) vs 拆分到行
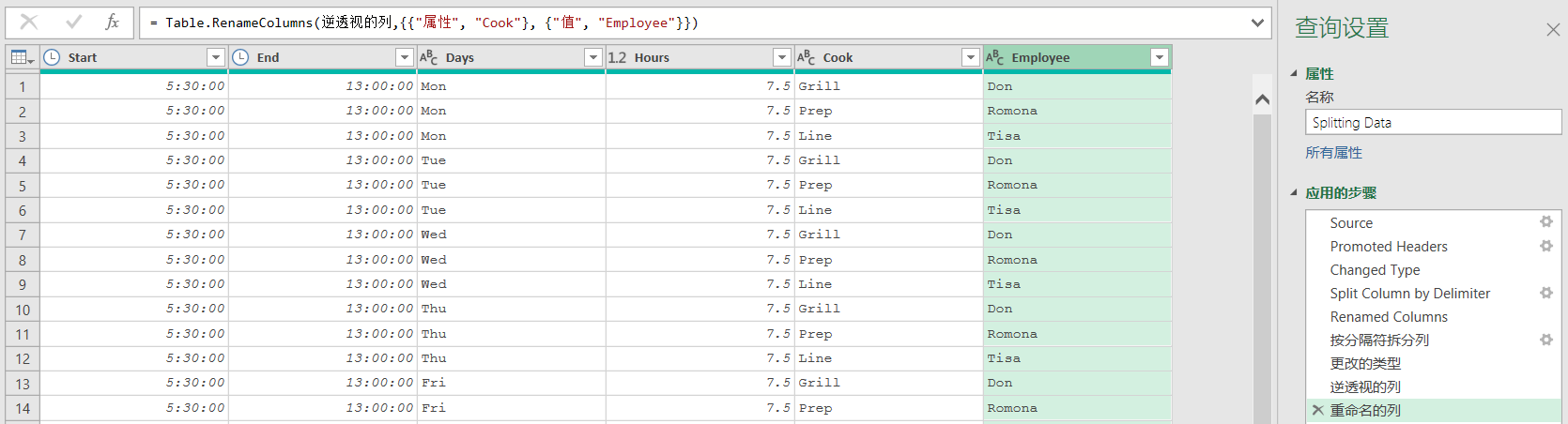
??假設用戶不希望“Cook”列中的數據以當前的透視形式出現,可以接著選擇“Grill”到“Line”這幾列,點擊“逆透視列”,然后將得到的“屬性”列和“值”列重命名為“Cook”和“Employee”:
??為了簡化整個過程,是否可以在一開始直接將“Cooks: Grill/Prep/Line”列拆分為多行來實現呢?我們刪除之前的步驟,先將“Days”列拆分到行,再將“Cooks: Grill/Prep/Line”列拆分到行:
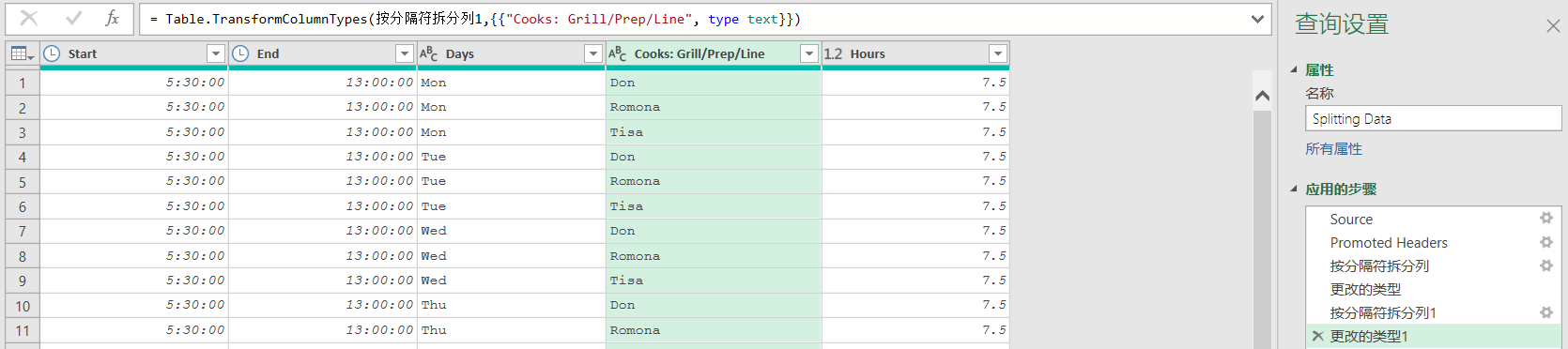
??可以看到這樣做會丟失關鍵信息:廚師的類型(Grill/Prep/Line,燒烤預備流水線),原因在于,廚師的類型信息只包含在列標題中,而不在數據內容中。如果直接拆分為行,每一行只會顯示員工的名字,而不會顯示他們具體的職位類型。
如果每個人職位是固定的,添加一個自定義列也行啊。
??所以,在這種情況下,選擇“拆分列”為列是正確的,因為它允許用戶將列標題(如“Type Of Cook”)轉換為數據的一部分,然后通過“逆透視列”選項將其帶入數據中。
??上述步驟假設“廚師”的職位總是以正確的順序輸入。如果順序可能不正確,可能需要采取不同的方法,例如先將員工拆分為幾行,然后通過與另一個表的合并來檢索他們的位置。
7.4 篩選和排序
??本節以第 07 章 示例文件 "FilterSort.csv”文件為例,由于此文件是以美國格式編寫的“日期”和“值”的格式,所以導入之后需要將“Date”和“Sales”列以【英語(美國)】區域進行設置,分別設置為日期和貨幣類型;Quantity”列設為整數類型。
7.4.1 按特定值進行篩選(手動創建篩選器)
??通過點擊列標題的下拉箭頭,可以篩選特定值;或者使用搜索框輸入部分項目名稱(不接受通配符和數學運算符)進行篩選。如果使用后者,Power Query會添加一個新的步驟來應用此篩選器。

??處理大數據集的挑戰:Power Query默認只預覽部分數據,用戶可能會看到“列表可能不完整”的提示。點擊“加載更多”會掃描更多數據,直到它掃描達到 1000 個唯一值為止(下拉列表最多顯示1000個唯一值)。

??如果需要篩選的值不在前1000行內,也不在此列前 1000 個唯一值之內,此時無法通過篩選器窗格進行篩選,但可通過手動創建篩選器來解決。
- 創建篩選器:選擇“文本篩選器”->“包含”
- 設置篩選條件:設置以下篩選條件
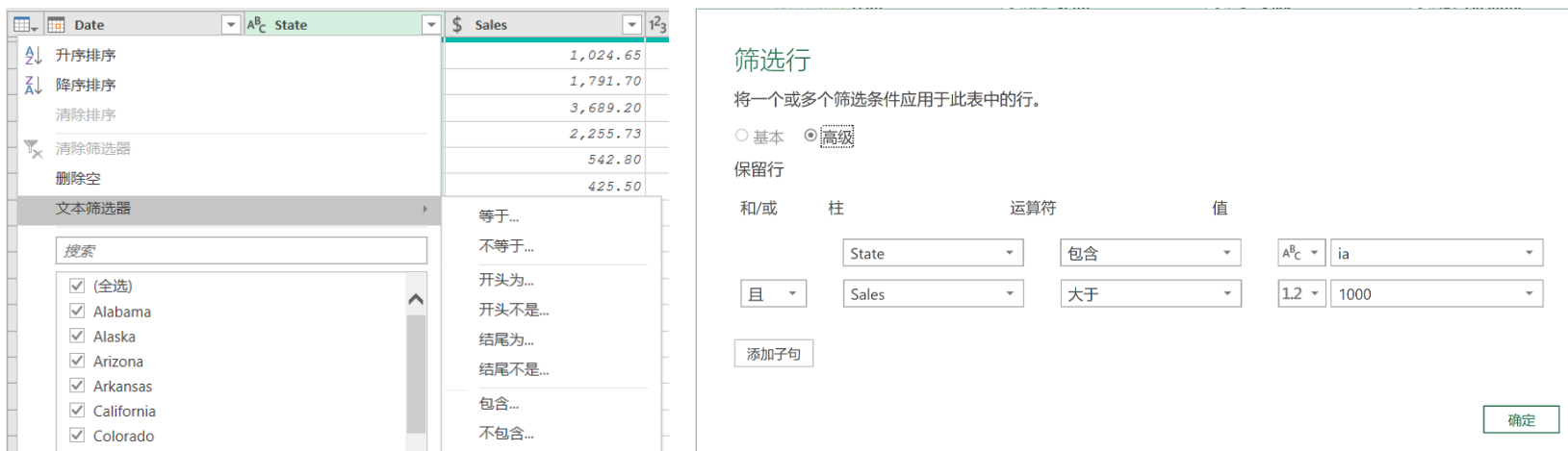
??當用戶不能在篩選器列表中看到數據時,或者需要為篩選器配置一些更復雜的條件,如【且】和【或】條件時,【篩選行】對話框的這個視圖非常有用。高級視圖允許用戶一次將篩選器應用于多個列,并添加更多的篩選層(通過【添加子句】按鈕)。點擊子句右側的【…】可以刪除或重新排序【子句】。
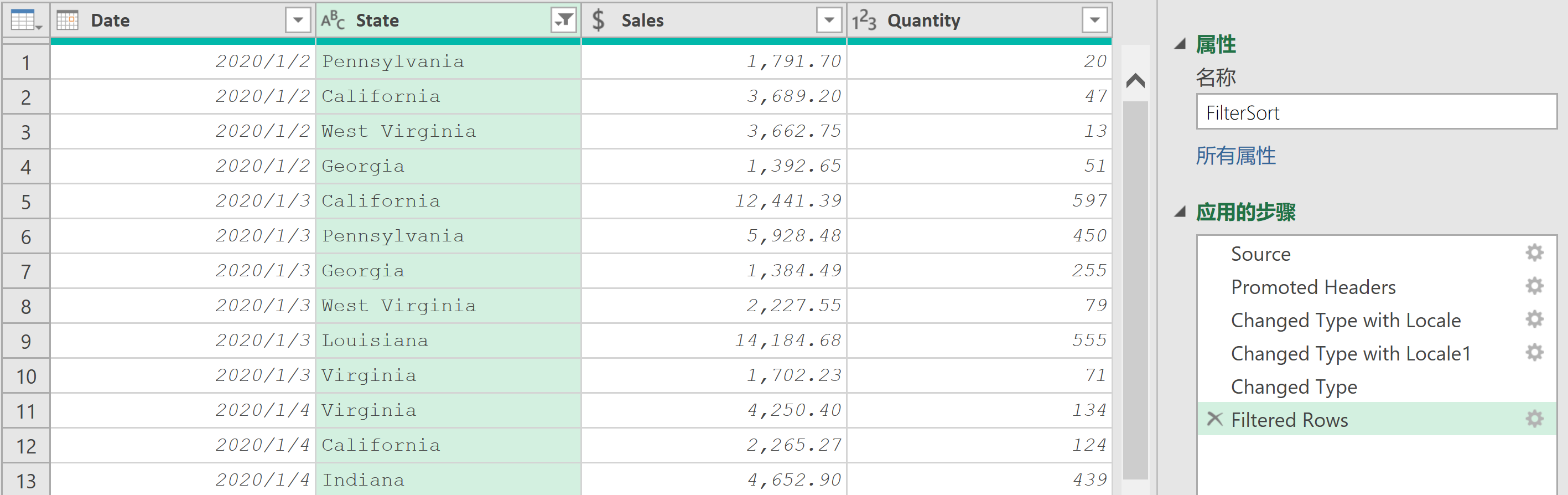
7.4.2 按上下文篩選
??根據列的數據類型,篩選器的選項會有所不同。
- 【文本篩選器】,它包含【等于】、【開頭為】 、【結尾為】 、【包含】等過濾器,以及其中每一種的“不”版本。
- 【數字篩選器】包含【等于】,【不等于】、【大于】,【大于或等于】,【小于】,【小于或等于】,以及【介于】。
- 日期篩選器則提供了更多的選項,其中的“當前”、“過去”和“接下來”是相對于系統中的當前日期/時間的。
7.4.3 數據排序
??連續排序(也叫層疊排序或多級排序):用戶可以按“State”列的升序對數據進行排序,然后按日期進行升序排序。
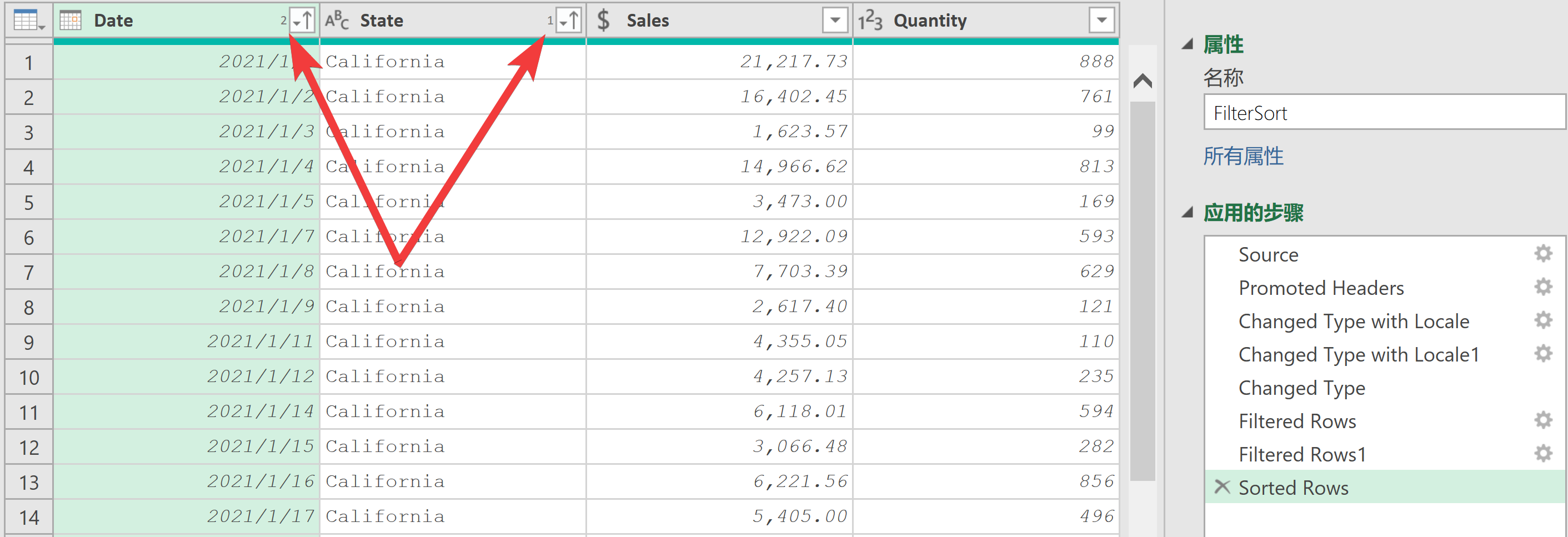
??需要注意的是,排序可能會影響性能,用戶應考慮是否真的需要對數據進行排序,比如使用數據模型以制作透視表,那么對輸出進行排序是不必要的。更好的做法是將數據加載到Excel或Power BI中,在展示層再進行排序。
7.5 數據分組
??當數據量過大時,比如FilterSort.csv示例文件包含大量的交易數據(53,513行),涵蓋7年和48個州。如果用戶只需要按年份查看總銷售額和總數量,那么其實沒必要將所有的源數據都輸入到【數據透視表】或可視化矩陣中。Power Query允許在轉換過程中對行進行分組,可以按所需粒度導入數據。
這段文字主要介紹了如何在Power Query中使用數據分組功能來減少導入數據的量,從而提高數據處理的效率和性能。以下是對這段文字的詳細解析:
- 導入數據:從
FilterSort.csv文件導入數據,刪除默認的“Changed Type”步驟,設置“Date”列和“Sales”列分別為【英語(美國)】的日期類型和貨幣類型,“Quantity”列為整數類型 - 轉換日期列:將“Date”列轉換為年份,因為用戶只需要按年份查看總銷售額和總數量。
- 分組數據:選擇“Date”列,單擊【轉換】下的【分組依據】選項,單擊【高級】按鈕,選擇按年份分組數據,并計算總銷售額和總銷售數量。


- 將“Date”列重命名為“Year”,將查詢重命名為“Grouping”。
- 關閉并加載數據到目標位置
注意事項:
- 沒有包括在分組或聚合區域的數據列會被刪除;
- 分組依據列不能在分組對話框中重命名,需要在分組前或分組后進行
- 聚合操作包括求和、平均值、中值、最小值、最大值、計數等
??建議在數據導入階段就盡量減少數據量,只保留對分析有用的列和行(通過分組篩選和聚合),以提高性能、簡化分析、節省存儲空間。
八、縱向追加數據
??在數據處理領域,我們常常需要將多個數據集合并成一個統一的數據表,以便進行更全面的分析。這一過程在技術上被稱為 “縱向追加數據”。考慮以下場景:用戶每個月從中央數據庫中提取對應月份的數據文件(例如,2 月份提取 1 月份的數據,3 月份提取 2 月份的數據,依此類推),分析師需要將這些數據合并到一起進行分析。
8.1 追加外部文件的數據
8.1.1 導入數據
以第 08 章 示例文件 "Jan 2008.csv"、"Feb 2008.csv"和"Mar 2008.csv"為例,逐個導入文件,并進行以下處理:
- 刪除"Changed Type"步驟。
- 更改"Date"列和"Amount"的數據類型分別為【日期】和【貨幣】,且【使用區域設置】,設為【英語(美國)】;更改"Account"列和"Dept"列的數據類型為【整數】
- 將三個查詢都設為僅限連接(在 Power BI 中可以通過右擊查詢取消勾選 “啟用加載” 復選框來實現;在 Excel 中則需要通過 “關閉并上載至” 選擇 “僅創建連接”)。

8.1.2 選擇合適的追加方式
- 在查詢 & 連接窗格中進行追加:用戶可以通過 Excel 的 查詢 & 連接窗格 右擊查詢選擇 “追加” 來合并所有的表,但不推薦這種方法,因為它在 Power BI 中不可用,并且會將所有合并的表合并到一個 “Source” 步驟中,使得檢查困難。

- 直接追加查詢:在 Power Query 編輯器中選擇"Jan 2008"查詢,然后選擇【主頁】【將查詢追加為新查詢】的方式,直接從 Excel 用戶界面【追加】查詢。這種方式操作的步驟比較少,但是也不太推薦,因為只有單擊"Source"步驟并閱讀公式欄,才知道數據源是怎么來的。
- 引用查詢后追加(推薦):推薦的方法是在 Power Query 編輯器引用第一個表(如 “Jan 2008” 查詢),然后再執行追加操作。
- 引用查詢:右擊"Jan 2008"查詢,選擇【引用】,得到的新查詢重命名為"Transactions"
- 追加查詢:轉到【主頁】【追加查詢】,在【要追加的表】中選擇"Feb 2008"
- 驗證追加數據:Power Query 編輯器中顯示的是數據預覽,并不會加載全部數據,所以需要將數據加載到工作表中進行驗證,比如查看 “查詢 & 連接” 窗格中的行數來確認數據量;或者通過創建數據透視表來查看:

第三種方式的好處是:
- 不使用【查詢 & 連接】窗格,不存在跨平臺兼容性問題(Power BI );
- 查詢步驟的可理解性與可維護性更好。
在 Power Query 編輯器中對第一個表進行【引用】,然后依次追加其他表的方法,會為每個被追加的表記錄一個不同的 “Appended Query(追加的查詢)” 步驟,這樣在檢查查詢時會更加容易,可以清楚地看到每個表是如何被逐步追加到查詢中的。
- 對于有多個表進行追加的情況,如果覺得逐個追加的方式步驟太長,可以編輯現有的 “Appended Query” 步驟一次性追加完;如果希望追加路徑更清晰,可以逐個追加。
- 雖然每月手動編輯文件來添加和轉換新的數據源然后追加到 “Transactions” 查詢中的方法可行,但隨著數據量的增加,這種方法會變得過時,后續章節將介紹更簡便的方法。
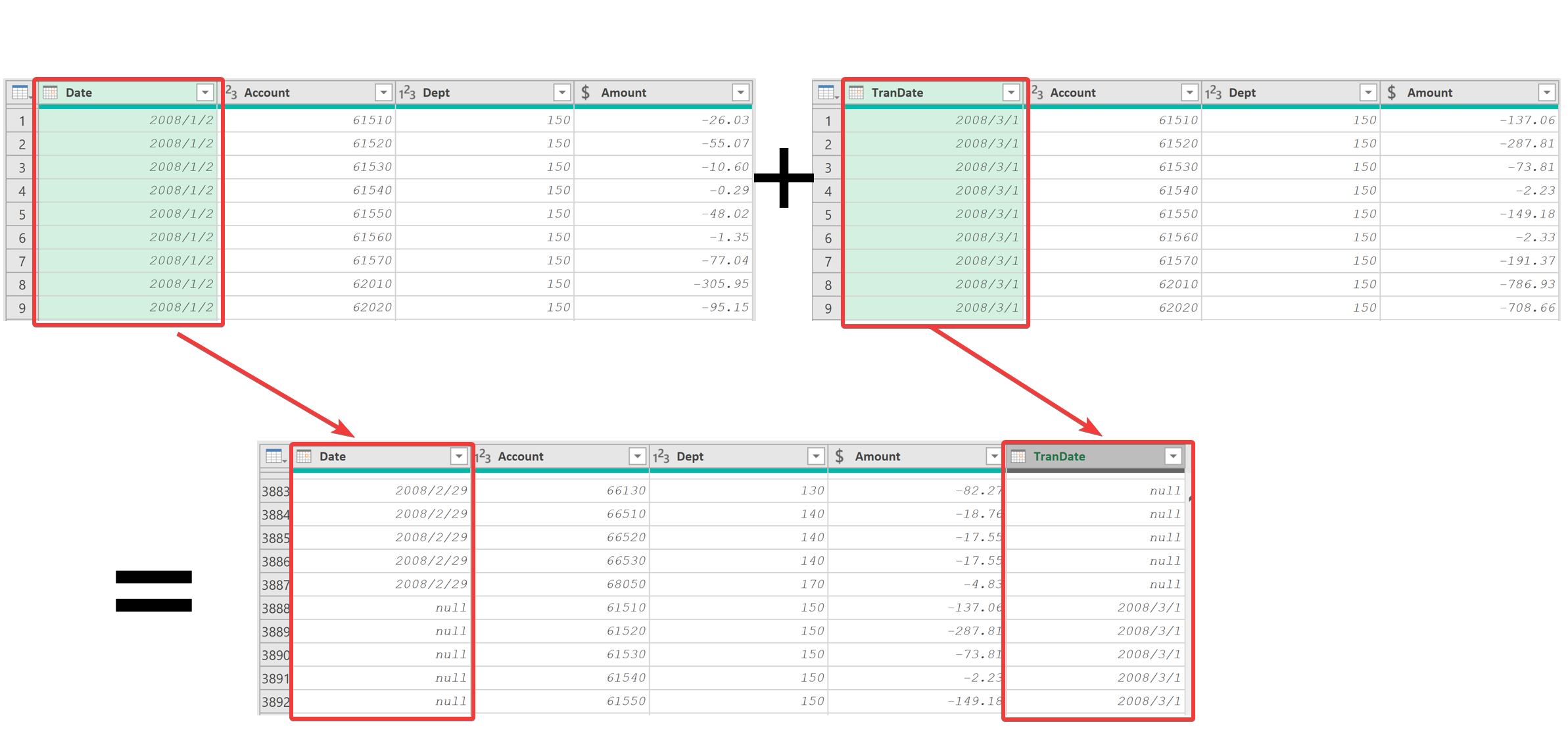
8.1.3 追加列標題不同的數據
??當追加的查詢中存在列標題不一致的情況時,Power Query 會自動添加新列并填充 “null” 值,比如"Mar 2008"查詢的"Date"列名稱變成"TranDate"。解決方法是對源查詢進行編輯,將列標題統一,然后更新目標查詢。
8.2 在當前文件中追加表或區域
??另一個常見場景是,Excel 用戶常需要將同一工作簿中的多個數據表進行追加合并,將Excel 像一個準數據庫一樣進行預處理。比如,某水療中心的記錄員,每月創建一個新表來記錄禮品券的交易信息(第 08 章 示例文件,Append Tables.xlsx),每個表格也是以年和月命名(例如 Jan_2008,表格名稱中不能有空格,在公式-名稱管理器中可以看到):
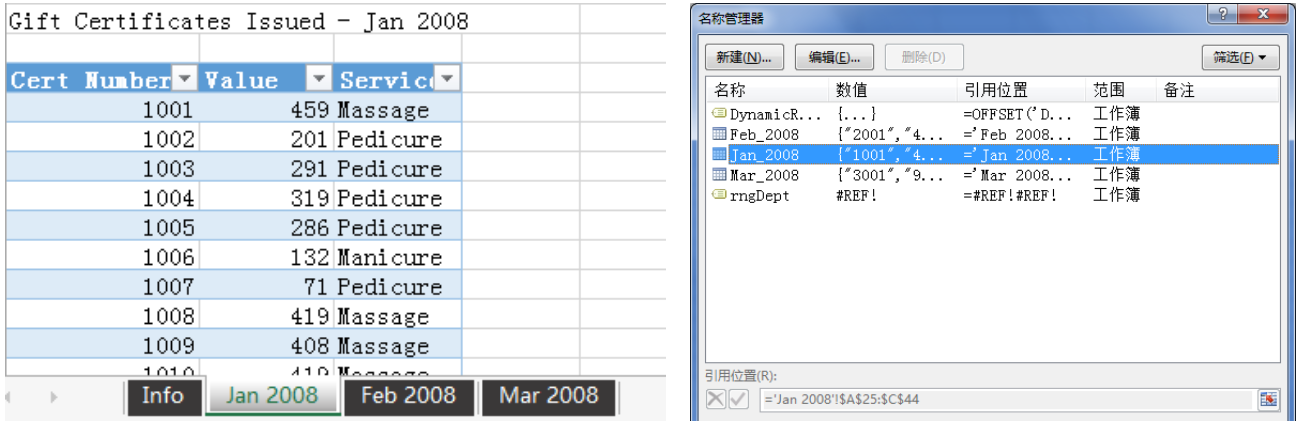
??那么,如何才能建立一個解決方案,使它自動包含記賬員添加的所有新表,而不是手動調整查詢,也就不必教記賬員如何編輯 Power Query。方法就是使用Excel.CurrentWorkbook 函數,來自動合并同一工作簿中的多個數據表。
8.2.1 合并Excel表中的所有表(Table)
- 創建空白查詢(【數據】【獲取數據】【自其他源】【空白查詢】),將其重命名為
"Certificates"; - 導入整個Excel表的數據:在公式欄中輸入
=Excel.CurrentWorkbook()來獲取工作簿中的所有表格(第6章的技巧)。

- 擴展表:單擊"Content"列的右上角圖標(兩個反向指向的箭頭標志,用于展開每一個表),展開"Content"列,取消勾選【使用原始列名作為前綴】的復選框。

- 將"Name"列轉換為有效的月末日期列:由于"Jan_2008"不是一個有效的日期,需要要用一個小技巧來實現。
- 右擊"Name"列【替換值】,將"_“字符替換為” 1 "(空格1空格)
- 選擇所有列【轉換】【檢測數據類型】

- 選擇"Name"列,轉到【轉換】標簽【日期】【月份】【月份結束值】
- 雙擊"Name"列【重命名】
"Month End"

- 上載數據:選擇【關閉并上載】,將新生成的"Certificates"工作表移動到工作簿的最后,會發現Certificates查詢出發了錯誤。再次編輯Certificates查詢,會發現"Source"步驟的結果比之前多了一個
Certificates表,這是因為當使用"=Excel.CurrentWorkbook()"來列舉表或范圍時,輸出的查詢在刷新時也會被識別:

- 處理錯誤:檢查Replaced Value和Changed Types步驟,會發現產生錯誤是因為Certificates不能被轉換為日期,所以只需要右擊"Name"列,選擇刪除錯誤就行。


8.2.2 合并Excel表中的所有區域(Range)或工作表(sheet)
??如果Excel中不是一個個構建好的表(Table),而是包含原始數據的工作表(sheet),此時可通過定義"打印區域"來指定要讀取的數據范圍
??正如第 6 章所提到的,沒有內置函數可以從活動工作簿中的工作表中讀取數據,因為excel無法確定整個sheet中哪些是需要的數據,所以需要通過定義打印區域的方式進行明確的指定。
-
定義打印區域:繼續選擇上一章節處理完成的
Append Tables表 ,選擇"Jan 2008"工作表,點擊【頁面布局】選項卡【打印標題】,在【打印區域】框中輸入:“A:D”。對"Feb 2008"和"Mar 2008"工作表重復這一過程。

-
創建空白查詢,重命名為"FromWorksheets"。
-
導入數據:在公式欄中輸入
= Excel.CurrentWorkbook(),將會看到所有的表格和命名范圍的列表,包括"打印區域"。

-
篩選出打印區域數據:選擇"Name"列,在搜索框輸入"Print_Area"
-
將"Name"列中的
'!Print_Area文字替換為空(不輸入任何東西);將'替換為空

-
展開"Content"列(取消勾選【使用原始列名作為前綴】復選框)

-
清洗數據:接下來就是清洗數據了。在這種場景中將第一行提升為標題是有風險的,推薦手動重命名列。
-
刪除"Column4",將其余列重命名為"Certificate"、“Value”、“Service"和"Month End”
-
右擊"Month End"列【替換值】,將單個空格替換為文本
"1," -
設置"Certificate"列、"Value"列、Service"列、"Month End"列數據類型分別是【整數】、【整數】、【文本】、【日期】

-
選擇所有列,刪除錯誤行,然后清除含有null值的行。
-
選擇"Month End"列【轉換】【日期】【月份】【月份結束值】
-
-
上載數據
8.3 思考
??Excel.CurrentWorkbook 函數會讀取當前 Excel 文件中的所有對象,包括表格、命名范圍、查詢等。如果生成的新查詢也被保存在同一個工作簿中,這就可能導致遞歸效應,即查詢在刷新時會嘗試加載自身,從而在輸出中重復數據。處理的方式包括:
- 篩選關鍵列上的錯誤:通過篩選掉包含錯誤的行,可以避免將無效數據或重復數據納入最終結果。
- 使用標準命名:為輸入和輸出列使用統一的標準命名規范,這樣可以更容易地識別和篩選出不需要的列,防止它們被錯誤地包含在合并結果中。
??本章介紹了用外部數據源的手動追加、合并當前工作簿中的所有表格或區域兩種方式。與傳統的復制粘貼方式相比,Power Query 的追加功能大幅縮短了工作時間,并且避免了因手動操作可能導致的數據重復等錯誤,同時保證了數據的一致性。無論用戶選擇哪種方法,請確保在將其發布到生產環境之前通過刷新進行多次測試。
??最后,有沒有可能把這些合并起來,創建一個系統,可以合并整個文件夾中的所有文件,而無需在 Power Query 中手動添加每個文件,答案是肯定的,下一章會介紹具體的方法。
十、橫向合并數據
10.1 基礎合并
??在數據處理領域,將多個數據表進行合并是常見的需求。假設我們有一個銷售交易表"Sales"和一個包含產品細節的"Inventory"表。這兩個表需要通過"SKU"列進行連接,以獲取完整的產品信息:

- 創建暫存查詢:創建一個新的查詢,連接到"第 10 章 示例文件/Merging Basics.xlsx"文件中的兩個表,將每個查詢保存為"暫存"查詢(PoweBI中右擊查詢設置【禁用加載】;Excel中設置為【僅限連接】)
- 引用查詢:右擊
Sales查詢選擇【引用】,將其重命名為Transaction; - 選擇【合并查詢】(不是【將查詢合并為新查詢】),選擇要合并的表和連接字段,默認的連接類型是左外部連接。在本例中,通過
"SKU"列將Sales表和Inventory表合并。

- 和【追加】查詢一樣,在Excel 中可以通過右擊【查詢 & 連接】窗格中的"Sales"查詢來【合并】查詢,但是不建議這么做,詳見8.1.2章節。
- 在執行合并之前,始終要確保各個表中,用于連接的列的數據類型是一樣的。
- 擴展表格:單擊
"Inventory"列標題的右側的擴展圖標,不選擇"SKU"列和"Brand"列,并取消勾選【使用原始列名作為前綴】的復選框。

10.2 復合鍵
??在數據合并中,有時需要結合多個字段來形成一個唯一的"復合鍵",進行連接,比如合并下面兩個表,需要以"Account"字段和"Dept"字段的組合作為復合鍵。

??雖然可以通過使用分隔符將這兩列合并為唯一的標識符,但實際上沒有必要這樣做。在合并時按住Ctrl鍵同時選中"Account"字段和"Dept"字段就可以了。

- 連接字段的選擇順序:當選擇多個字段作為連接鍵時,Power Query會按照用戶選擇的順序對這些字段進行編號(如"1"、"2"等)。即使字段在兩個表中的位置不一樣,但只要選擇字段的順序一致,Power Query也能正確匹配數據。
- 隱含的分隔符:雖然在操作界面上沒有明確顯示這些字段是如何組合的,但實際上Power Query會使用隱含的分隔符來連接這些字段。例如,如果"Account"字段的值是
"64010","Dept"字段的值是"150",那么Power Query會將它們視為"64010-150"這樣的組合鍵。 - 預覽匹配問題:合并界面的底部會根據 Power Query 的數據預覽,給出一個預估匹配情況。由于Power Query的預覽功能一般只顯示前1000行,所以這個預估值不一定準。在實際執行合并操作時,Power Query會處理整個數據集,保證完全匹配。
10.3 連接類型
??仔細觀察可以看到,在左側Chart of Accounts"表中不存在某些組合(“64015-150"和"64010-350”),右側"Transaction"表中也沒有"Special"或"Pull Chart"賬戶。就這一問題而言,又分為不同的情況,其問題嚴重性也不同。
- 如果"Chart of Accounts"表中存在從未被使用的賬戶,這通常不是一個大問題,因為它們可能只是備用賬戶。
- 如果"Transaction"表中的交易被記入了不存在的賬戶或部門組合,這是一個嚴重的問題,因為它可能導致數據錯誤或財務混亂。
??任何需要在兩個列表之間進行匹配、比較或調整的場景,例如:客戶與信用額度,銷售人員與訂單,零件與價格,都需要考慮這個問題,所以選擇合適的連接方式非常重要,避免出現業務邏輯錯誤。
??合并查詢使用的是Table.NestedJoin函數,其中參數JoinKind.Type控制其聯接方式,共有8種。前6種可以在合并查詢界面下拉菜單選擇,最后兩種只能使用公式。


10.3.1 左外連接:左表所有行+右表匹配行
??打開"第 10 章 示例文件/Join Types.xlsx"文件,其中已經包含了"Transactions"表和"COA"表(即"Chart of Accounts"表)兩個"暫存"查詢。
- 【引用】左表(此示例中為"Transaction"表),將查詢【重命名】為"Left Outer"
- 轉到【主頁】選項卡【合并查詢】,選擇"右"表,即"COA"表,連接方式選擇左外

- 展開Name列,取消勾選【使用原始列名作為前綴】的復選框。

10.3.2 右外連接:右表所有行+左表匹配行
- 【引用】左表(此示例中為"Transaction"表),將查詢【重命名】為"Right Outer"
- 【合并查詢】,連接方式選擇右外
- 展開數據:這一次,“COA"列都填入了數值,但是由于"Special"和"Pull Cart”(顯示在第 5 行和第 7 行)沒有交易被匹配,所以這些列顯示為空值。

10.3.3 完全外部連接(并集):查看數據不一致情況
- 將引用的合并查詢重命名為"Full Outer"
- 將【連接種類】選擇為【完全外部】
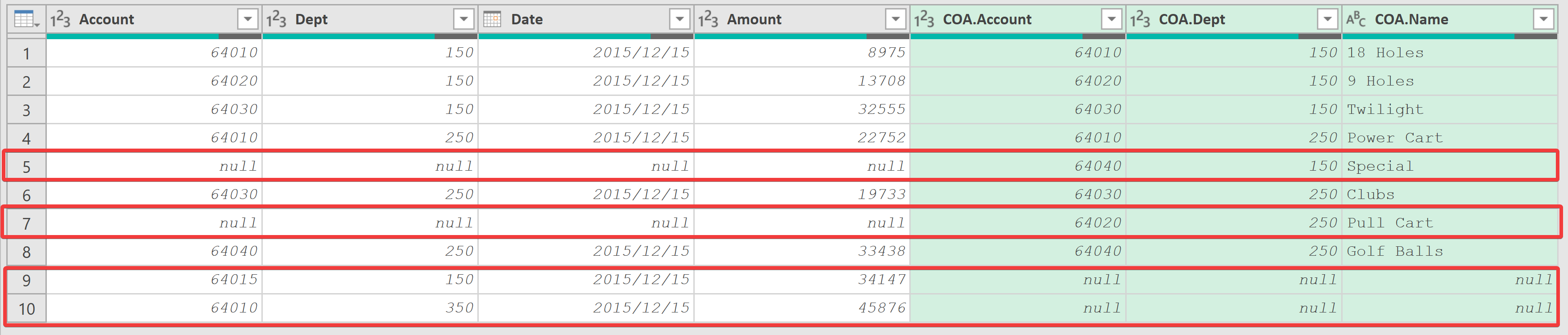
??可以看到合并結構中返回兩個表中的所有記錄,包括匹配和不匹配的記錄。當試圖了解兩表的差異時,這種方式可以非常方便查看到數據不一致的地方。
10.3.4 內部連接(交集,僅限匹配行)

10.3.5 左反連接、右反連接:只返回不匹配記錄(左表或右表)
??到目前為止,所探討的連接主要是針對匹配的數據。當對比兩個數據列表的差異時,人們實際上更關心不匹配的數據。使用和之前一樣的步驟,連接方式選擇左反,將返回只在左表出現的數據:

??如果唯一的目標是識別左表中沒有在右表中匹配的記錄,就沒有必要展開右表的合并的結果。而且可以直接刪除右邊的列,因為無只會返回空值。
連接方式選擇右反:

10.3.6 全反連接:合并左反連接與右反連接
??另一種非常有用的連接類型是"完全反"連接,特別是試圖識別兩個列表之間不匹配的項時,只需要合并左反連接與右反連接就可以了:

10.3.7 左半連接(左表的匹配行)與右半連接(右表的匹配行)
??連接方式的下拉菜單中沒有此選項,只能通過修改M公式來完成。可以先創建左外查詢,然后將連接類型JoinKind.LeftOuter改為 JoinKind.LeftSemi即為左半查詢,結果是左表的匹配行,右表全為null,所以叫左半(不如叫左內)。

改為JoinKind.RightSemi即為右半連接:

10.3 笛卡爾積(交叉連接)
10.3.1 實現方式
??笛卡爾積是一種特殊的連接類型,用于創建兩個表中所有可能的組合。在Power Query中,可以通過添加一個公共的"MergeKey"列(通常為常量值1),然后基于此列進行左外部連接來實現。

打開"第 10 章 示例文件\Cartesian Products.xlsx",本例的目標是獲取一個包含固定每月費用的表:

- 導入數據:右擊數據表中任意單元格,選擇"從表格/區域獲取數據",創建Months表和Expenses表兩個查詢:

- 添加自定義列:在
Expenses查詢和Months查詢中,添加"MergeKey"列,公式為=1 - 合并查詢:使用"合并查詢",以
"MergeKey"列為基礎,將Months表與Expenses表合并 - 后處理:刪除
"MergeKey"列,展開"Months"列中除合并鍵之外的所有列,取消勾選【使用原始列名作為前綴】的復選框,生成最終的預算表,包含每個月的費用類別:

10.3.2 笛卡爾積風險
??如果在"Months"表中不小心添加了重復的月份(如2021年1月出現兩次),刷新后會導致每個費用類別都重復出現兩次。解決方法是在"Months"表右擊"Month"列并選擇【刪除重復項】。
??但是,在【合并】之前【刪除重復項】也應謹慎。比如在本章的第一個示例中,嘗試基于"Brand"列合并"Sales"和"Inventory"表將創建笛卡爾"Product":

??生成的結果中,Sales列會匹配到多個行,這是因為"Inventory"表中的"Brand"列有重復項。但此時在"Inventory"表中刪除"Brand"列的重復項是不可取的,因為這將刪除兩種產品中的一種。

??為了避免意外生成笛卡爾積,可以使用視圖-列分析工具來檢查:如果用于連接的列(鍵列)的"非重復值"和"唯一值"數量匹配,說明該列中的每個值都是唯一的,沒有重復。這種情況下,可以安全地使用該列作為連接鍵,而不會產生意外的笛卡爾積(如SKU"列);否則將會面臨產生笛卡爾積的風險(如"Brand"列)

10.4 近似匹配(查找價格區間)
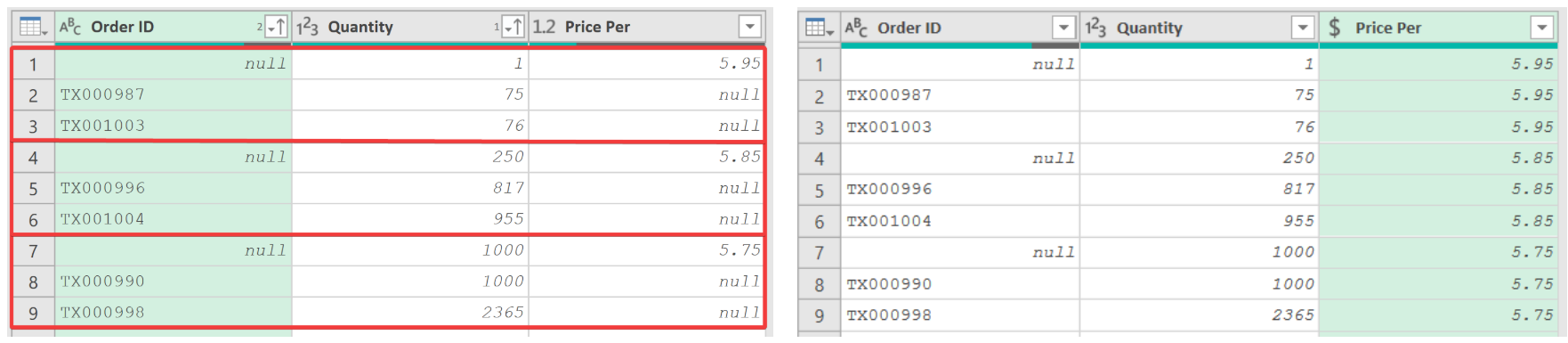
??在某些情況下,需要查找并返回等于或介于兩個數據點之間的值。比如以下示例中,購買者下的訂單越多,價格就越優惠。對于源表中訂單量為2755的情況,查找表沒有這個數據,但其價格應該按訂單量2500處理。

- 連接數據表: 打開
Approximate Match.xlsx,連接到"源表Prices和"查找表"Orders; - 清洗數據:將
Prices表的"Units"列重命名為"Quantity",使鍵列名稱一致; - 追加查詢:引用
Prices表,選擇追加查詢 - 填充空白數據:
- 先對
"Quantity"列升排列,再對"Order ID"列升序排列,確保每個區間查找表的"Quantity"在最上方 - 選擇"Price Per"列,右擊選擇【填充】【向下】,將自動匹配達到條件的優惠價格:
- 先對
- 清除
"Order ID"列的null值
注意事項:
- 列名一致性:確保源表和查找表中的"Key"列名稱一致。
- 排序順序:先對"Key"列排序,再對"ID"列排序,以確保查找表的行始終位于源表的行之前。
- 數據量限制:即使源表長度超過1000行,方法仍然有效,盡管數據預覽可能無法顯示完整內容。
10.5 模糊匹配
10.5.1 基本模糊匹配方法
??在將人工輸入的數據與計算機生成的數據進行匹配時,常常會遇到拼寫錯誤、大小寫不一致、縮寫、符號差異等問題,導致無法使用傳統的精確匹配方法。比如在"Product"表和"Price"表中,由于數據輸入的不一致性(如"laptop"與"Laptop"、"Screen"與"Monitor"等),標準的左外部連接只能匹配到部分數據,此時就需要使用模糊匹配。

- 打開"第10 章 示例數據\Fuzzy Match.xlsx",在創建常規連接時,勾選【使用模糊匹配執行合并】

Power Query 將使用 Jaccard 相似性算法 來度量文本之間的相似性,默認將相似度得分達到80%或以上 的內容標記為匹配項。

- 一般來說,在使用模糊匹配時,單詞越長,擁有的字符越相似,返回精確匹配的可能性就越大
- 【使用模糊匹配執行合并】功能僅在文本列上的操作上受支持。如果出于任何原因需要對使用不同數據類型的列執行模糊匹配,則需要首先將數據類型轉換為【文本】。
10.5.2 使用轉換表
??雖然基本的模糊匹配解決了一些問題,但有兩個記錄仍然無法生成匹配:“Mice"與"Mouse”、“Screen"與"Monitor”,因為它們的相似度很低。解決方案是創建一個 轉換表,將一個術語映射到另一個術語,然后選擇將其作為轉換表:

??此表的名稱并不重要,但它必須包含"From"列和"To"列,以便正確映射和轉換術語,最終所以數據都被正確匹配:

10.5.3 降低相似度閾值
??默認情況下,Power Query 的模糊匹配要求相似度達到80%。如果需要更寬松的匹配,可以在模糊匹配設置中,降低相似度閾值。比如下面的而數據數據,相似度最高才0.67(比如"北京"和"北京市"),所以默認匹配時全部沒有匹配成功。而"新疆"和"新疆維吾爾自治區"的相似度更低,只有0.25,所以為了都能匹配成功,我們把這個閾值調到0.25:
??降低相似度閾值可能導致誤匹配(假陽性)和意外的笛卡爾積。比如對于下面的數據,將相似度閾值從80%降低到50%,可以匹配"Don A"和"Donald A",但是產生了7行記錄,多了一行。


模糊匹配可能導致數據維護困難,尤其是在數據不斷刷新的情況下,建議:
- 預處理數據:在合并數據之前,替換已知的錯誤字符或模式;
如果知道查找表中地址字段從不包含"#“符號,但源表中可能包含這種寫法(如”#123 Main St"),可以在合并之前,右擊該列,將所有"#"符號替換為空。 - 創建異常表:使用完全反連接模式(10.3.6),在每次刷新后生成一個包含所有未匹配的項的異常表;
- 監控異常項:使用 Excel 或 DAX 公式計算異常表中未知項的數量,并將其顯示在報表頁面上進行監控;
- 更新轉換表:當發現異常表中有未知項時,將異常項及其映射關系添加到轉換表中;
- 逐步完善:隨著數據的不斷刷新,逐步完善轉換表,減少不匹配項的數量。
模糊匹配算法不僅用于合并操作,還可能出現在其他特性中,如分組特征和聚類值。
10.5.4 總結
- 模糊匹配 是一種強大的工具,可以解決數據匹配中的拼寫錯誤和不一致性問題。
- 基本模糊匹配 通過 Jaccard 相似性算法實現,但可能無法解決所有問題。
- 轉換表 可以解決更復雜的術語替換問題。
- 降低相似度閾值 可以放寬匹配條件,但需要謹慎使用以避免誤匹配。
- 維護策略 包括預處理數據、監控異常項和逐步完善轉換表,以確保數據的準確性和可維護性。
十三、轉換表格數據
13.1透視
13.1.1 一維表透視(單列數據)
??一維表透視適用于將具有重復格式的單列多行數據轉換為表格格式。以在第 13 章 示例文件"Stacked Data.txt"為例,存儲了信用卡交易數據。除了第一行顯示為標題外,數據格式非常一致,都是“日期”、“供應商”、“金額”、“空白”。忽略標題,每個記錄有 4 行。

如果用戶在數據中看到此重復格式,則將其展開為表格格式的標準步驟為:
-
導入數據:創建新查詢(【獲取數據】)【從文本/CSV】選擇“第 13 章 示例文件\Stacked Data.txt”,然后將第一行提為標題。
-
添加索引列,將數據分組 :從0開始添加索引列,添加整數除法和取模運算,根據記錄行數確定確定除數,這樣就將記錄進行了分組和組內索引。
- 選擇“索引”列【添加列】【標準】【除(整數)】彈出的對話框【值】輸入“4”【確定】
- 選擇“索引”列【轉換】【標準】【取模】彈出的對話框【值】輸入“4”【確定】

-
透視列 :選擇 “索引” 列,執行透視操作,設置 “值” 列字段為目標數據列(本例中是“Transactions”),展開【高級選項】并選擇 “不要聚合”。
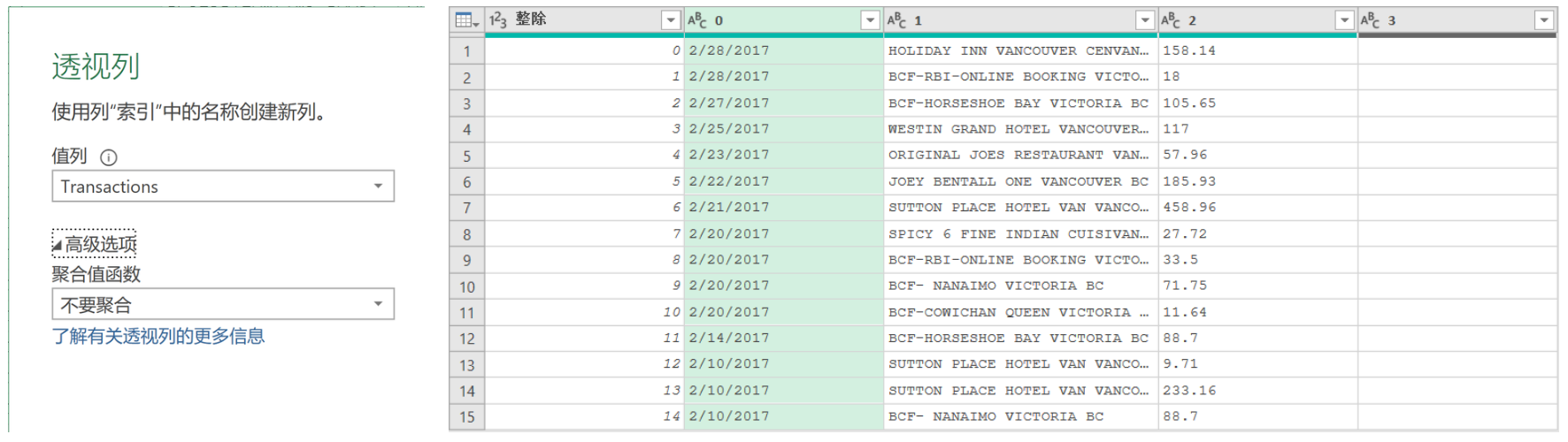
可以看到索引列元素成了列標題,第一列是“整除”列,“Transactions”列被正確透視 -
清理數據 :刪除多余的“整除”列和空白列,重命名新創建的列(“Date”、“Vendor”、“Amount”),設置數據類型。
??在處理包含重復空白行的數據集時,建議先執行透視操作,然后再刪除空白列。這是因為如果在透視操作前刪除空白行,可能會誤刪包含重要數據的行(例如供應商名稱為空的行)
13.1.2 二維表透視(以行分組)
??在第 13 章 示例文件"Vertical Sets – Begin.xlsx”中,每N行一組數據,每組數據都有多個列,需要將這個二維表進行透視。

??實現的方式有多種,這里只用Power Query界面進行操作,先將二維表轉為一維表,再按上一節的標準步驟進行操作。
-
導入數據
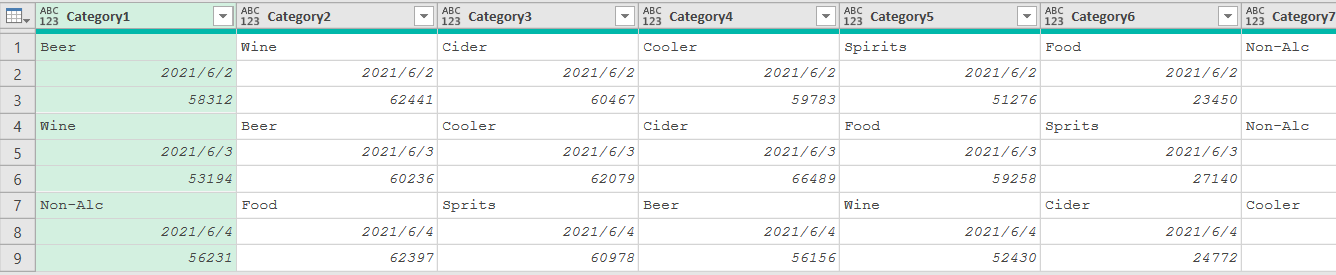
-
轉置數據 :轉到【轉換】選項卡,單擊【轉置】,對數據進行轉置操作。

-
添加索引列 :從0添加索引列。
-
逆透視其他列 :右擊“索引”列,【逆透視其他列】。這里的一個關鍵技巧是在【逆透視其他列】之前對數據進行了【轉置】。于是得到了擁有多列值的一維表,接下來和上一節操作類似。

-
刪除列:刪除"值"列之外的其它列
-
一維表透視的標準步驟 :對得到的數據再次執行透視操作,添加索引列、整數除法與取模運算(除數為3)、透視列等步驟,完成數據轉換。

13.1.3 二維表透視(以列分組)
??在第 13 章 示例文件"CourseSchedule.csv”中,每N列一組數據,透視時還需要將行ID也寫入數據中。這種表格只需要將行 ID 之外的其它列進行逆透視,就可以轉換為第二種情形(以列分組->以行分組)。

以下總結了標準的操作步驟,根據實際數據集的不同結構進行調整。
-
準備數據 :導入數據集,避免提升標題行,然后根據是否有行 ID 列進行操作。
- 是:選擇行 ID 列并右擊列標題【逆透視其他列】
- 否:選擇所有列,右擊列標題【逆透視列】
- 逆透視完之后,刪除“屬性”列

-
標準透視操作:接下來就可以使用二維表透視(以行分組)標準步驟,聚合【值】列。包括添加索引列,執行整數除法和取模運算,非聚合方式透視列等等。

-
清理數據 :提升標題行、刪除多余行、重命名列、設置數據類型、清除空白行(本例中 是清除“Date”列中的空白行)。
由于刪除了“Promoted Headers”步驟,標題信息仍然保留在數據中,從而產生了現在在數據中看到的三行列標題。所以現在選擇【將第一行用作標題】,轉到【主頁】【刪除行】【刪除最前面幾行】,輸入行數“2”。

根據導入的數據源,用戶可能看不到上圖中顯示的兩個空行。在這種情況下,Power Query 將空白記錄解釋為空文本字符串,因此在透視操作時會保留它們。如果在初始導入時這些值被解釋為空值(null),那么在透視操作過程中會被消除掉。
13.2 逆透視
??之前所述的每一個逆透視示例都相對簡單,因為它們都只有一個級別的標題。在這一節中,將使用多個級別的標題透視數據。
13.2.1 多層行標題
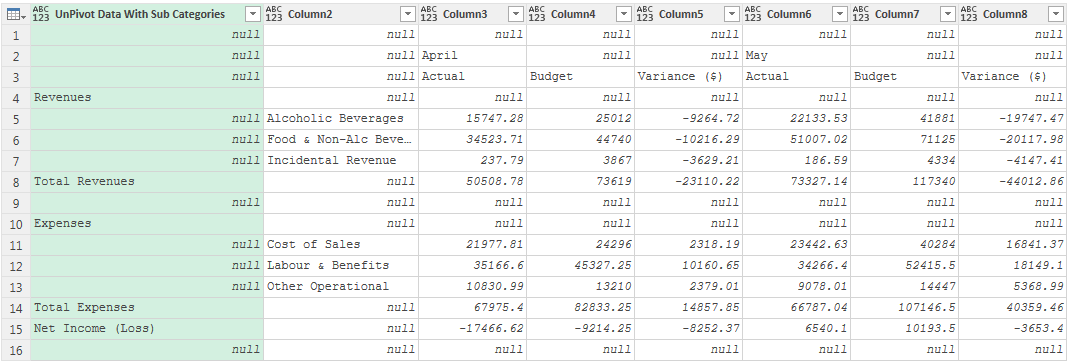
??當本節提到子類別數據時,指的是具有多個標題行的數據集,比如第 13 章 示例文件"Financial Statement.xlsx”需要做如下轉換:

??這個數據集的棘手之處在于 Power Query 只支持一個標題行。這個數據集中不僅有兩個標題行,而且還需要將第一個標題行的值“April”和“May”分配給下一行中的三列。首先導入數據然后進行檢查,確保數據集的每個標題行都在數據預覽區域中,而不是在列標題中。
接下來按照標準步驟對此類子類別數據進行逆透視:
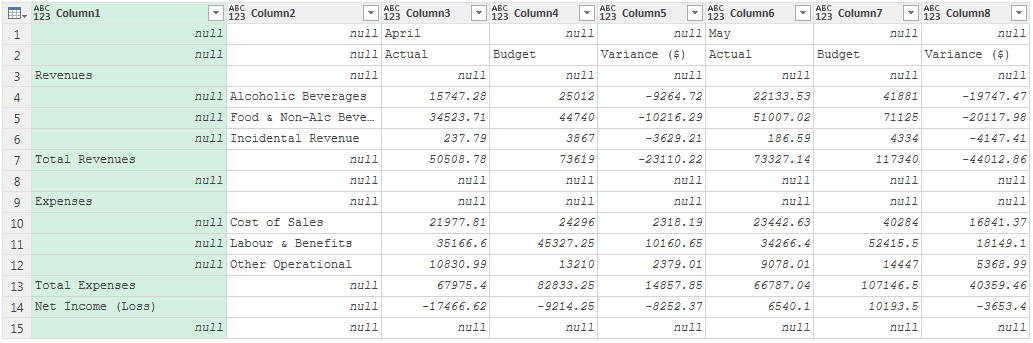
- 降級標題 :將標題降級到數據中(如果需要),分兩種情況:
- 數據集包含標題:此時 Power Query 將自動沿用這些列名作為標題,不會有“Promoted Headers”步驟,此時用戶需要將標題“降級”到數據中;
- 數據集不包含標題:此時需要刪除自動生成的“Promoted Headers”和“Changed Type”步驟。本例中還需要刪除前2行(第3行和第4行才是數據表中的兩個標題行)。
- 轉置數據 :轉置之后,才有可能將原先的第一個標題行向下填充
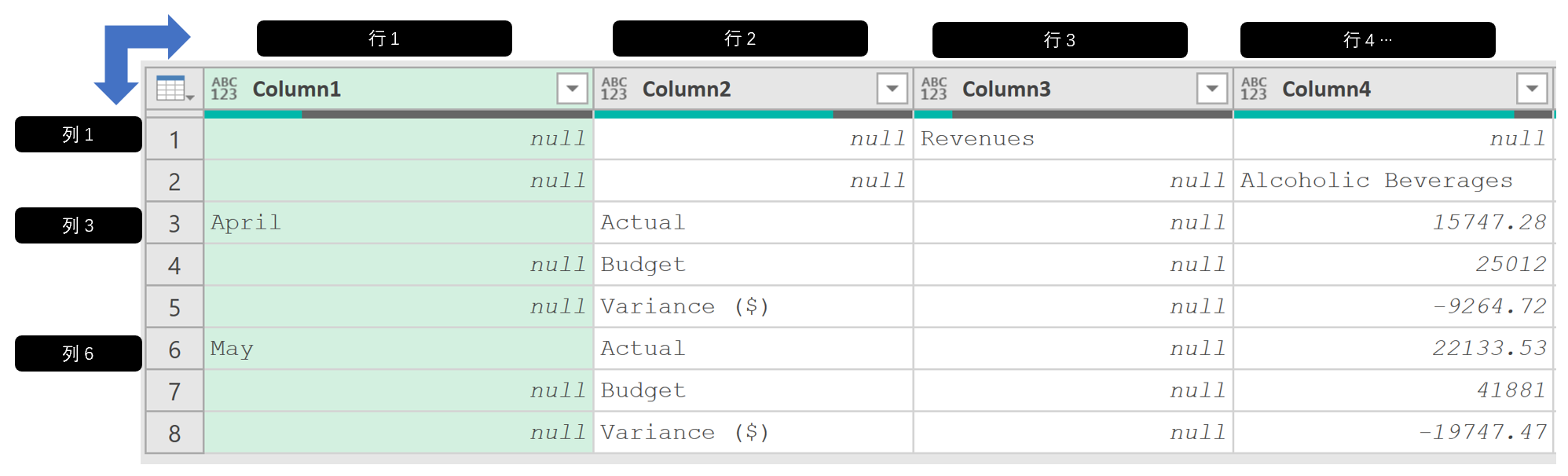
- 填充數據 :根據需要向上或向下填充數據。本例中,右擊“Column1”列【填充】【向下】

【填充】命令可用于向上或向下填充,但僅在填充為
“null”值時有效。如果單元格顯示為空格,則需要先將空格替換為“null”。
- 合并原始表的多級標題 :使用分隔符將原數據集中的標題進行合并。注意選擇一個數據集中沒有出現過的字符作為分隔符。本例中,使用
|合并“Column1”和“Column2”。 - 轉置數據 :將數據轉置回原始形式。到了這一步,可以看到原先的兩級標題已經合并到一起,且第一級標題的值
“April”和“May”已經分配到數據中。
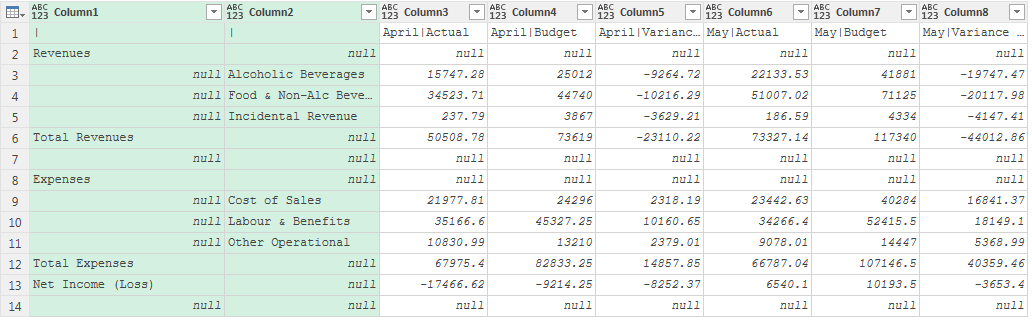
- 設置標題行 :
“Column1”和“Column2”列第一行還顯示為分隔符,將其分別替換為標題"Class”和“Category”。
- 將第 1 行提升為標題,去除自動應用的
“Changed Type”步驟(因為后面逆透視,數據類型又要變)。

- 數據清理 :在進行最終的逆透視操作之前,執行必要的數據清理操作。
在本示例中,則需要對“Class”列的空值進行向下填充,并篩選掉不屬于規范化數據集的總計行和小計行(通過去除“Category”列中的null值)。

- 逆透視列 :對數據進行逆透視操作。本例中,選擇
“Class”列和“Category”列,右擊列標題選擇【逆透視其他列】。

- 拆分屬性列 :按上面使用的分隔符拆分 “屬性” 列。
- 最終清理 :完成最終的數據清理。比如將拆分后的“屬性.1”列和屬性.2”列分別重命名為
“Month”和“Measure”(也可修改上一步M公式完成);轉換所有列的數據類型

13.2.2 性能優化
??對于小型數據集,上一節的方法非常有效。但在處理大型數據集時,逆透視操作可能會導致運行緩慢,并且轉置后數據可能只顯示幾行,用戶無法判斷是否需要填充,原因在于:
- Power Query 更適合處理長而窄的表,而不是短而寬的表。
- 轉置數據計算成本高,且需要進行兩次。
??由于兩次轉置主要是為了解決原始數據中的多級標題行問題,所以可以把標題行數據取出來單獨處理,再與數據行進行合并,這樣即使數據集有100萬條數據,也只需要轉置標題行就行。為了做到這一點,這里將標準步驟分解為四個不同的查詢,試驗證明這會大大加快處理速度。

查詢優化如下(見示例文件:Unpivoting Subcategories - Complete.xlsx):
-
Raw Data:創建查詢,導入數據,重命名為Raw Data查詢,并將其設為僅限連接;

-
Data:引用Raw Data查詢,將其中第3行之后的數據行提取為Data查詢,并將其設為僅限連接; -
Headers:引用Raw Data查詢,將其中前兩行提取為Headers查詢,然后執行步驟2到6,也將其設為僅限連接;

-
Output:將Data查詢與Headers查詢進行合并(追加查詢)
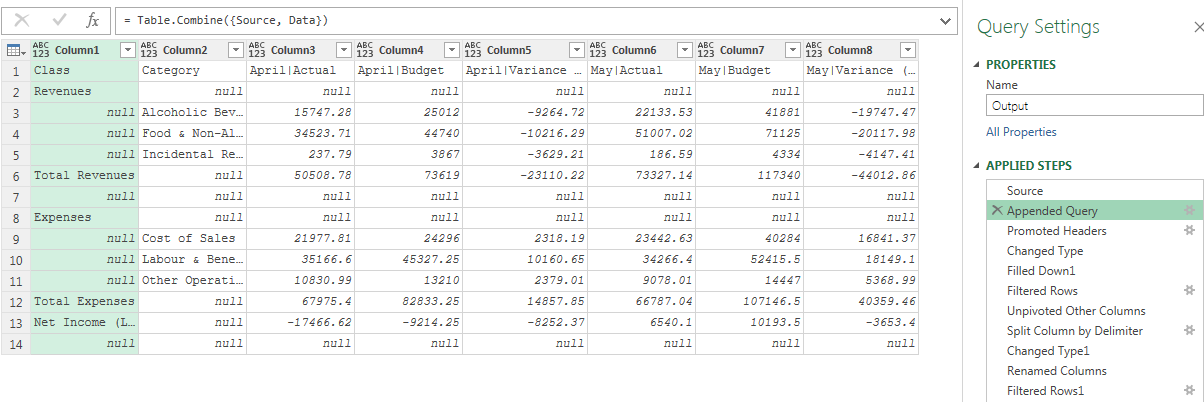
接著執行后續的步驟就行。
??如果事先預計到了此性能問題,可在初始設計時將標準步驟分解為四個不同的查詢;如果未預見,也可重構現有查詢。
13.2.3 保留 null 值 (null->占位符->null)
??在逆透視操作中,通常會自動去除包含“null”值的記錄。這在大多數情況下是用戶期望的結果,但在某些場景下,用戶可能需要保留這些“null”值。比如下圖中(示例文件Preserving Nulls - Complete.xlsx),對“Product”列進行逆透視操作,可導致某些包含“null”值的記錄(“Mango”)丟失。

??在逆透視操作中保留 null 值的方法很簡單,就是先將其替換為一個數據集中不存在的占位符,逆透視完畢之后再替換回null就行。
??選擇占位符是因為其比較特殊,很容易找到數據集中 沒有的占位符,比如|。由于占位符是文本類型,如果要處理的列是數字或日期等其他類型,可以先將其轉為文本類型再使用占位符。以下是具體的演示:
-
替換 null 值 :選擇含有null值的列,將null替換為一個占位符。此示例中,右擊“In Stock”列,將
null替換為|。

-
逆透視列 :選擇“Product”列,【逆透視其他列】。

-
還原占位符值 :將占位符值還原為 null 值。
-
還原標題 :將“屬性”列和“值”列重命名為原先的列名。

13.3 分組
??分組操作用于對數據進行聚合和排序,下面使用第 13 章 示例文件BeerSales.txt,介紹其簡單應用。

13.3.1 占總計的百分比
- 數據分組 :
-
啟動分組操作:轉到【轉換】選項卡【分組依據】【高級】
-
刪除分組依據中自動填入的 “Class” 列:將鼠標懸停在“Class”列上,單擊它右邊出現的“…”按鈕,選擇【刪除】)
-
配置分組操作:對Sales”列進行求和操作,列名設為 “Total Sales” ;對所有行進行聚合,列名設為 “Data” 。
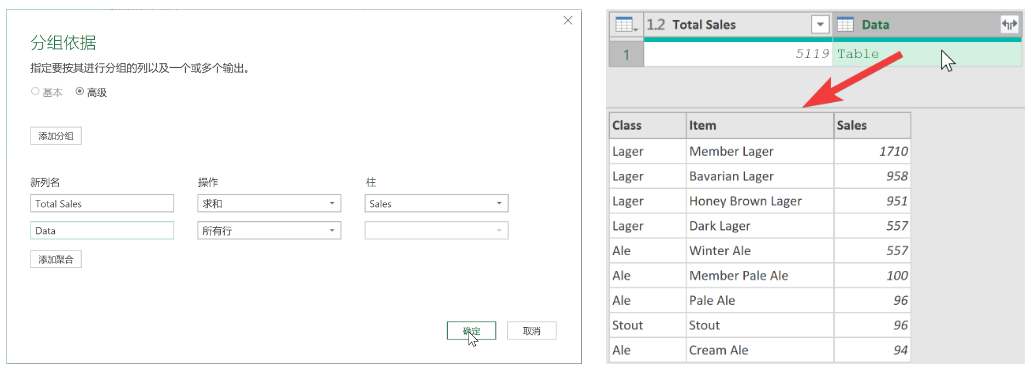
使用聚合所有行的方式得到Data列,后續直接展開,否則還需要進行連接操作。
- 展開數據 :展開 “Data” 列,獲取原始數據行。
- 計算百分比 :將 “Sales” 列除以 “Total Sales” 列,得到 “% of Total Sales” 列。
- 更換數據類型

-
??最好是使用數據透視表或 DAX 度量值生成
“% of Total Sales”,但是用戶也可以使用 Power Query在源數據級別執行此占比計算操作
13.3.2 數據排名
| 排名方法 | 并列值處理 | 排名序號特點 | 示例 |
|---|---|---|---|
| 順序排序 | 并列值獲得連續的序號 | 每個項目都有唯一的排名,序號是連續的 | 1, 2, 3, 4 |
| 標準競爭排序 | 并列值獲得相同的排名 | 后續排名跳過并列項的數量 | 1, 2, 2, 5 |
| 密集排序 | 并列值獲得相同的排名 | 后續排名不跳過并列項的數量 | 1, 2, 2, 3 |
13.3.2.1 順序排序
??按照銷售額降序排列;如果銷售額相同,則按項目名稱排列,這樣即使銷售額相同,也會有不同的排名,所以叫順序排列。
- 對 “Sales” 列降序排序,對 “Item” 列升序排序
- 添加索引列(從 1 開始),并將其重命名為 “Rank-Ordinal”。

13.3.2.2 競爭排序(數值相同排名并列)
- 數據分組:對“Sales” 列進行分組操作,選擇【高級】,按如下方式進行配置
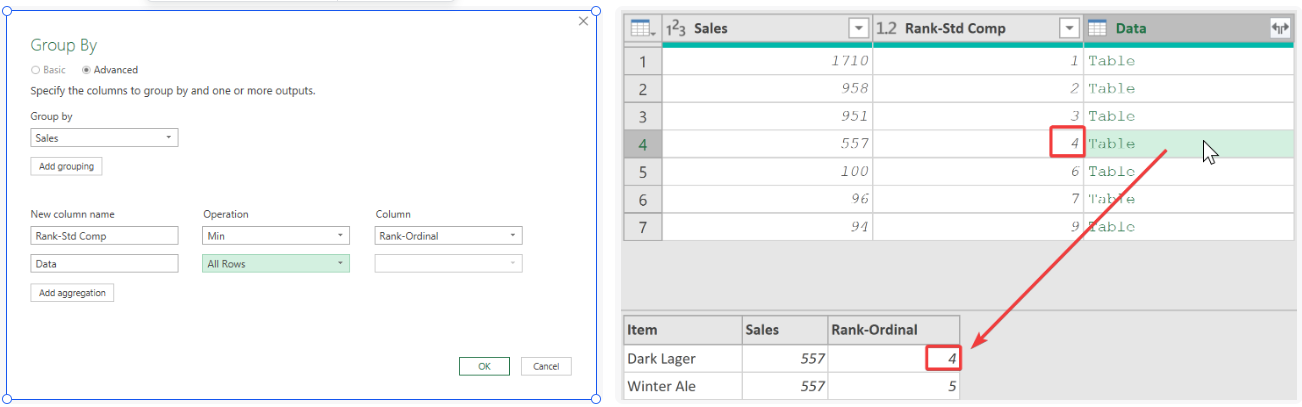
- 展開原數據:這里僅展開“Data”表中的“Item”列和“Rank-Ordinal”列查看結果

13.3.2.3 密集排序(數值相同排名不同)
- 數據分組:對“Sales” 列進行分組操作,選擇【高級】,按如下方式進行配置
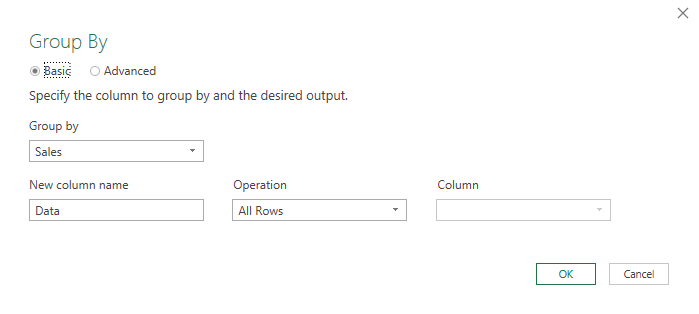
- 從1開始添加索引列,并將其重命名為 “Rank-Dense”
- 展開“Data”列查看結果

13.3.3 分組編號(在每個分組級內添加序號)

-
準備數據 :對 “Class” 列升序排序,對 “Sales” 列降序排序,對 “Item” 列升序排序。
-
數據分組 :選擇 “Class” 列,添加 “Data” 列(所有行操作)。此時,應該有三行數據,其中有一列表值包含每個組中所有行的詳細信息。

-
添加編號 :使用公式
=Table.AddIndexColumn([Data], "Group Rank", 1, 1)添加自定義列,生成每個分組內的序號(通過用戶界面做到這一點)。

-
展開數據 :刪除自定義列之外的其它列,展開自定義列,獲取最終結果。

十四、條件判斷
14.1 if表達式 與 非空數據的判斷
if 表達式用于根據條件選擇兩個表達式中的一個。例如:
if 2 > 1 then2 + 2
else1 + 1
??對于簡單的條件判斷,可以通過添加條件列來實現。比如有以下成績表,通過添加條件列,可以實現評級結果:


其M公式為嵌套的if 語句:
if [科目一] >= 90
then "優秀" else if [科目一] >= 75 then "良好" else if [科目一] >= 60 then "及格" else "不及格"
??如果有兩列數據,需要多個判斷條件來判定,就無法直接通過添加條件列來實現,而要用IF語句來完成(用 and/or 來連接多個條件)。另外,對于非空數據的判斷,還可以用??來簡化多重條件的判斷。
??假設有以下產品銷量數據,有些產品是從第一年就有數據,有些產品是從后面的某一年才產生業務,如何添加一列,來顯示每個產品首年業務數據呢?

??這是一種很常見的需求,從上面的表格直觀來看,就是如何找出第一個非空的數據。普通的做法可以通過IF嵌套判斷,比如在PowerQuery中可以這樣添加自定義列:
第一個非空數據=
if [2020]=null and [2021]=null and [2022]=null
then [2023]else if [2020]=null and [2021]=nullthen [2022]else if [2020]=nullthen [2021]else [2020]
還有一種更簡單的寫法:
=[2020]??[2021]??[2022]??[2023]
??雙問號??是一種非空運算符,它會嘗試返回符號前面的數據,如果前面的是空值,則返回后面的數據。

如果要同時獲得首年的年份(非空列名),可以添加以下自定義列:

14.2 基礎條件邏輯(引發錯誤,篩選數據)
??以第14章示例文件timesheet.txt為例,記錄了每位員工兩周之內的上班天數和上班時間。

??文件中每條記錄以標題行開始,包含工作人員的全名(分布在“Work Date”和“Out”兩列)和“Worker ID”。記錄以總計行結束,包含記錄數量和總小時數。現在要將其轉為如下的標準格式,使工作人員信息能正確關聯到相關行。

??棘手的是,沒有明顯的數據點可以用來提取所需信息。不能依賴“Hrs”列中的值(因為“Worker ID”可能與有效小時數混淆),也不能依賴記錄的數量(因為不同員工的記錄數量可能不同)。那么,該如何完成任務呢?
-
連接到數據
- 在 Excel 或 Power BI 中,通過“獲取數據”功能導入
timesheet.txt文件。 - 刪除前 4 行,將第一行用作標題。
- 將查詢設置為“暫存”查詢,命名為“Raw Data – Timesheet”,并作為“僅限連接”加載。
- 引用該查詢并重命名為“Basics”,以便后續操作。

- 在 Excel 或 Power BI 中,通過“獲取數據”功能導入
-
通過界面操作(添加條件列)的方式,創建條件邏輯
-
使用逗號合并“Work Date”和“Out”列,得到完整的員工姓名。
-
將“Work Date”列的數據類型設置為“日期”,“Out”列設置為“時間”,故意觸發數據類型錯誤(標題列的姓名是文本值,無法轉為日期或時間格式)。

-
替換“Work Date”列和“Out”列錯誤值為“null”(主要是下一步判斷條件中,如法使用Error)。
-
添加如下條件列“Worker”。


-
向下填充“Worker”列的“null”值,去除Worker Date”列中的null行
-
刪除不必要的“已合并”列,設置所有列的數據類型

-
??處理以上數據的主要邏輯是:利用數據類型轉換錯誤來識別和分離工作人員姓名和其它數據,然后通過條件邏輯將工作人員姓名正確關聯到每一行數據中。關鍵點在于通過故意觸發錯誤并替換為“null”值,可以基于數據類型創建條件邏輯規則。
14.3 使用 try…otherwise 表達式簡化步驟
14.3.1 try…otherwise 表達式
??在Power Query中,沒有類似DAX那樣直接的 IFERROR 函數,但可以通過 try...otherwise 語法實現類似的功能。 try 表達式一般用于捕獲和處理Error,例如:
let Sales = [Revenue = 2000,Units = 0,UnitPrice = if Units = 0 then error "No Units" else Revenue / Units
]
in try Sales[UnitPrice]
??上面的代碼表示如果 Units = 0,則返回一個錯誤 error "No Units",否則,計算 Revenue / Units。try 表達式捕獲到 Sales[UnitPrice] 的錯誤,并將其轉換為一個包含錯誤信息的記錄。

??常見的情況是使用默認值替換錯誤。 otherwise 子句允許你在捕獲錯誤時直接提供一個默認值,而不是返回一個包含錯誤信息的記錄。
try error "negative unit count" otherwise 42
error是一個關鍵字,用于顯式地拋出錯誤,并提供錯誤消息 “negative unit count”。- 如果計算過程中引發錯誤,則返回 otherwise 子句中指定的默認值
42
使用場景:
# 處理文本轉換錯誤
try Number.FromText("abc") otherwise null
# 除零錯誤
try 10 / 0 otherwise 0
14.3.2 簡化步驟
-
復制查詢:右擊“Raw Data - Timesheets”查詢,選擇“引用”,并重命名為“IFError”。
-
添加自定義列:添加自定義列“Worker”,公式為:
// 嘗試將Out列轉換為時間,如果失敗則返回null try Time.From([Out]) otherwise null
??從一種數據類型到另一種數據類型的轉換可以通過在
“Time.from”,“Date.from”,“Number.from”等函數中輸入數據類型,后跟“.from([ Column ])”來完成。在這里選擇使用時間格式而不是日期,以避免處理潛在的日期區域設置問題的復雜性。??上述公式返回的“null”值并不是用戶期望的結果,我們期望的是用員工姓名代替上述“null”值,用“null”值代替所有日期。所以正確的做法是將 try 語句包裝在條件邏輯中。
- 如果是“null”,說明轉換失敗,此行是標題行,應該返回“Work Date”和“Out”列的合并值(工作人員姓名)
- 如果不是“null”,說明轉換成功,此行是日期行,應該返回“null”。
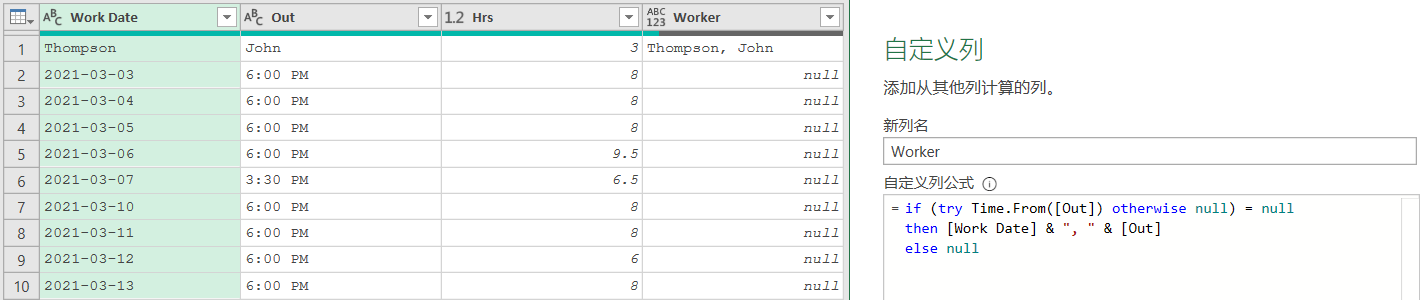
-
完成數據清理:后續步驟不變,最終從9個步驟簡化到了5個步驟。
14.3.3 總結
- Power Query 中沒有直接的
IFERROR函數,但可以通過try...otherwise語法實現類似功能:try語句嘗試執行某個操作,失敗時返回備用結果。 - 將
try語句嵌入條件邏輯中,可以根據轉換結果動態返回不同的值,減少數據清理的步驟,提高效率。
14.4 多條件判斷
??當需要對多個列進行條件判斷,或者判斷的值類似[A]-8這種需要包含列植表達式時,無法通過【條件列】對話框進行構建,而需要手動書寫if表達式。比如在第 14 章 示例文件DuesList.txt中,Member Type列用于判斷具體的繳費情況,只有同時繳納高爾夫費(Golf Dues)和冰壺費(Curling Dues)的會員才會獲得“All Access”通行證;Pays Options列用于判斷會員是否繳納了其中任何一種費用。

-
數據準備
- 創建新查詢,從文本/CSV文件導入“DuesList.txt”,將查詢重命名為“Dues List”。
- 將第一行用作標題,替換空單元格為“null”,完成數據準備工作。

-
構建“Member Type”列:新建條件列,根據高爾夫費和冰壺費的繳納情況,判斷會員類型。其公式為:
if [Golf Dues] <> null and [Curling Dues] <> null then "All Access" else "Not sure yet..."
現在優化此公式,區分只交了一種費用的情況,即將原先的"Not sure yet..."替換為新的邏輯:if [Golf Dues] <> null and [Curling Dues] <> null then "All Access" else if [Golf Dues] <> null then "Golf Course" else if [Curling Dues] <> null then "Curling Club" else "None"
-
創建“Pays Dues”列:判斷會員是否支付了任何可選費用,公式為:
if [Golf Option 1]<> null or [Golf Option 2] <> null then "Yes" else "No"
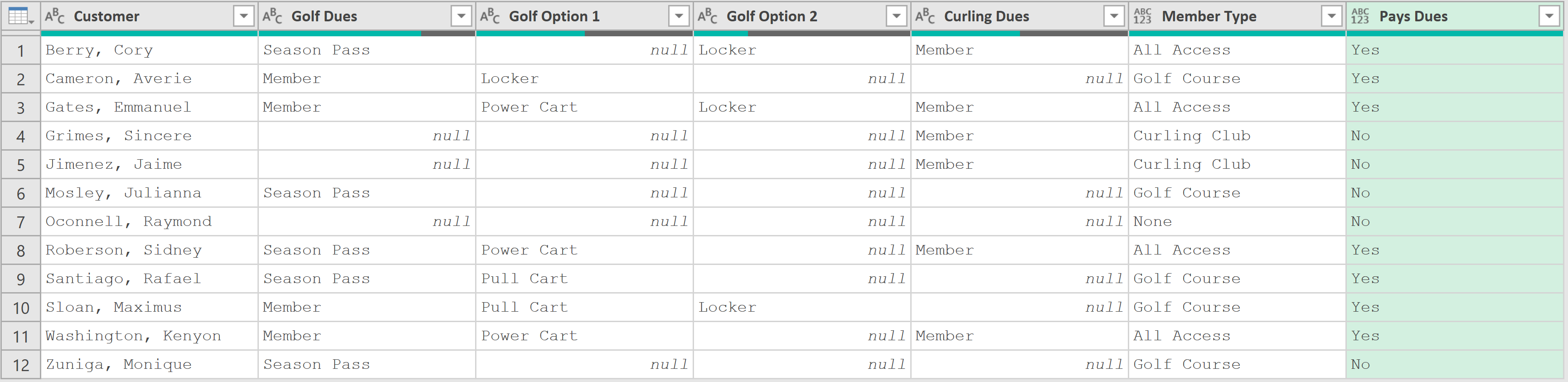
- 轉換數據類型,并上載數據
這段話是在解釋 Power Query 中使用邏輯運算符 and 的方式,以及如何在 Power Query 中構建復雜的條件邏輯。下面是對這段話的詳細解釋:
注意事項:
-
與 Excel 和 DAX 的區別
在 Excel 和 DAX(數據分析表達式)中,邏輯運算符通常使用大寫字母,并且位于要測試的項目之前,例如AND([Condition1], [Condition2])。 而在 Power Query 中,邏輯運算符使用小寫字母,并且位于邏輯測試之間,例如<test 1> and <test 2>。 -
使用括號:當使用 多個 運算符進行嵌套測試或多個條件測試時,可能需要將邏輯測試用括號括起來,以確保邏輯運算的優先級和順序正確,避免邏輯錯誤
-
逐步構建公式:如果用戶不能夠一次性寫出完美的公式,可以分步驟進行。首先創建一個新的自定義列來構建每一部分的邏輯,然后逐步剪切和復制這些邏輯,最后將它們合并。在這個過程中,用戶可以刪除任何不再需要的步驟,以簡化最終的公式。
14.5 與上下行進行比較
??使用 Power Query 時的一大挑戰是,沒有簡單的方法訪問前一行或后一行,下面介紹一種技巧,通過合并查詢來實現與上下行數據的比較。

-
導入數據:導入第 14 章 示例文件
"Sales.txt",將第一行用作標題,替換所有空單元格為“null”,以便統一處理。

-
添加索引列: 添加兩個索引列,一個從1開始,另一個從0開始。
-
合并查詢:將查詢合并到自身,通過索引列的匹配來創建行之間的關聯,實現與前一行的比較。

-
展開并排序,將“Qty”列的值移到下一行
- 展開合并結果中的“Qty”列,取消勾選【使用原始列名作為前綴】復選框,將前一行的值移動到當前行
- 將“索引”列按升序重新排序,確保數據的邏輯順序正確

-
創建自定義列:創建一個名為“Category”的新自定義列,用于提取類別值,公式為:
if [Qty.1] = "---" then [Sales Item] else null -
數據填充與清洗:
- 右擊“Category”列向上填充
- 篩選掉“Qty.1”列中的“—”項。
- 刪除不再需要的索引列和“Qty.1”列。
- 篩選掉“Sales Item”列中的“null”值。
- 轉換所有列的數據類型

關鍵點:
- 使用索引列和合并查詢來實現與上下行的比較,或者根據前一行的數據提取類別值,從而實現復雜的數據處理邏輯。
- 合并查詢對話框中,與前一行進行比較時,“索引.1”列在上“索引”列在下;與下一行比較時“索引.1”列在下“索引”列在上(反轉選擇)
- 與前一行比較時,展開合并結果會導致數據亂序,而與下一行比較則不會
- 無論是將一個列或多個列的值移動到另一行,還是將值與其他行的值進行比較,此方法都是有效的(比如比較每個股票的當天與前一天的收盤價,以確定價格是上漲、下跌還是持平)
14.6 使用示例列自動提取數據
??Power Query 還有一個功能叫“示例中的列”,它利用 Power Query 的智能分析能力,根據用戶輸入的示例自動生成和調整數據處理邏輯,使得用戶即使不具備深入的 Power Query 知識,也能有效地處理復雜的數據轉換任務。
??為了演示【示例中的列】的強大功能,假設有一個非常復雜的數據集(“第 14 章 示例文件 FireEpisodes.txt),Power Query 無法輕松導入。我們強制將其作為單列數據來導入處理,最終我們需要提取每一行文本中的劇集名和劇集號。
-
使用固定寬度分隔符導入數據:導入文件時,將【分隔符】更改為【–固定寬度–】并將寬度設置為“0”,強制 Power Query 將整個文件內容作為單一列導入。

-
啟動【示例中的列】功能:轉到【添加列】【示例中的列】,啟動此功能。啟動后,通過輸入期望的輸出示例,可以讓 Power Query 自動生成提取邏輯。

-
提取劇集名和劇集號:在列1中,先輸入前兩行數據
“Pilot, Episode 1”和“Mon Amour, Episode 2”,Power Query 生成正確的提取公式,填充整個列。
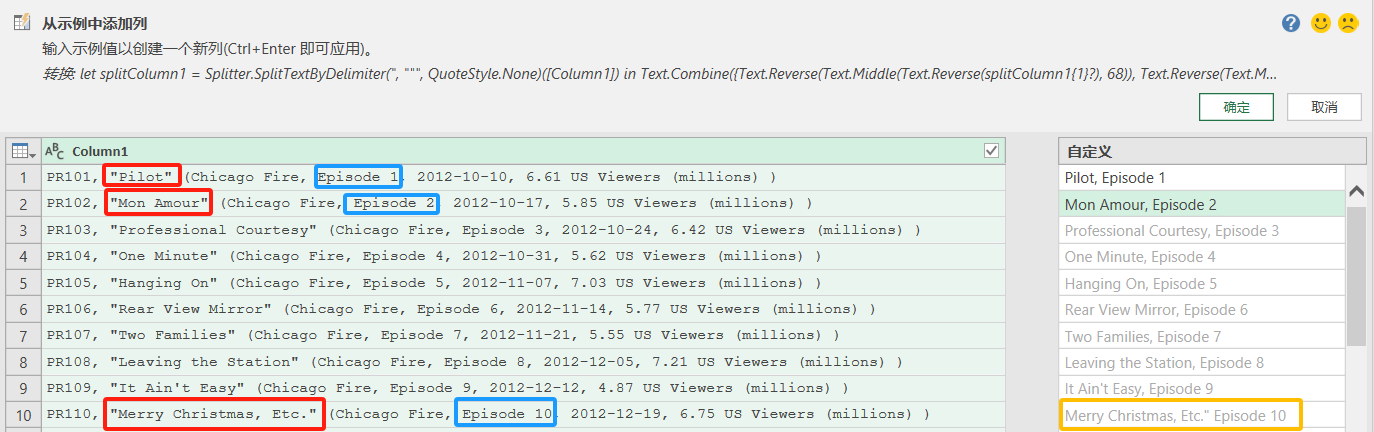
-
調整示例值,優化劇集名提取邏輯:可以看到在第10行數據中有一個多余的引號,所以需要繼續優化
- 優化1:更改錯誤示例:直接在在第十行輸入
“Merry Christmas, Etc., Episode 10”,此時其它行都變成空值,表示這三行示例使得提取邏輯太過復雜,結果公式直接變成了if語句(除這三行之外全為空值)。
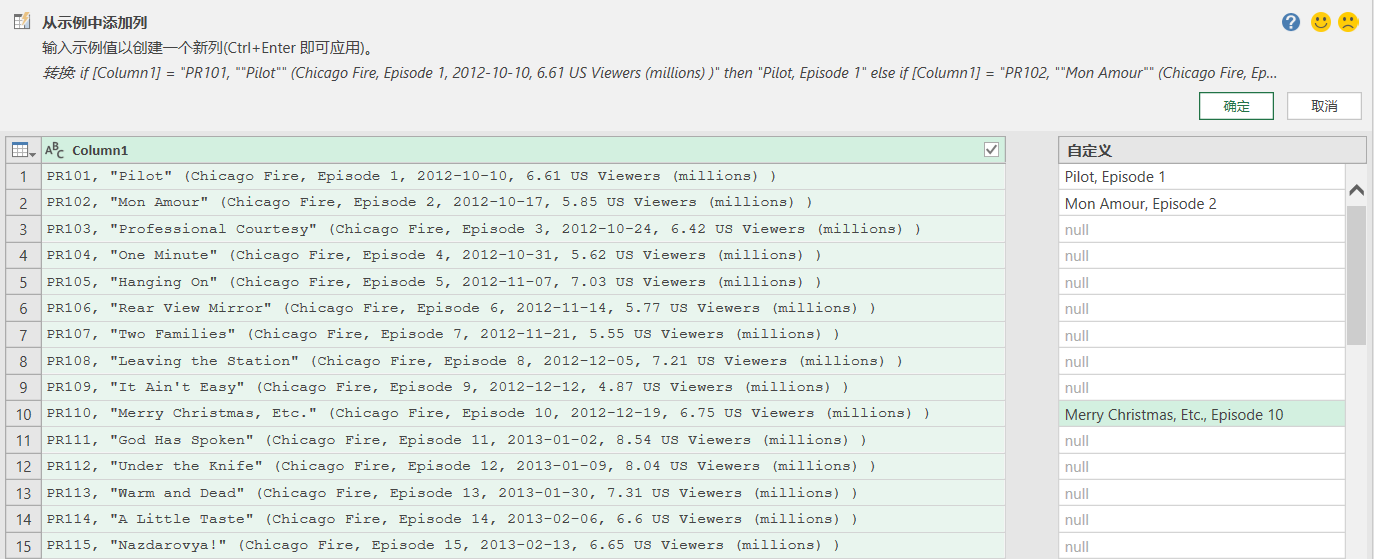
- 優化2:簡化提取邏輯:清除之前手動輸入的所有示例值,只提取劇集名。在第一行輸入劇集名稱“Pilot”,第二行輸入劇集名稱“Mon Amour”,此時Power Query自動使用
Text.BetweenDelimiters函數從文本中提取劇集名稱。然后將列名更改為“Episode Name”。

- 優化1:更改錯誤示例:直接在在第十行輸入
-
提取劇集號:再次使用“示例中的列”功能,輸入劇集編號“Episode 1”和“Episode 2”;對于特殊劇集(自動提取結果為“Merry Christmas”),手動輸入正確的編號“Episode 10”。最后將列名更改為
“Episode Nbr”。

-
自動合并列:再次啟用【示例中的列】功能,在第一行輸入“Pilot, Episode 1”,Power Query自動使用逗號合并Episode Name和Episode Nbr兩列的值!

-
清理數據:將合并的列將此列重命名為
Episode,右擊新的“Episode”列【刪除其他列】 -
上載數據
總結:
- 【示例中的列】功能允許用戶在不了解 Power Query 函數的情況下,通過輸入示例值來指導 Power Query 自動生成數據處理邏輯,比如找不到或記不起某個命令。
- 用戶可以通過取消勾選不需要參考的列來提升推導效率。
十八、處理日期時間
??在數據分析中,日期表是組織和分析時間序列數據的關鍵工具,比如在構建分析報告時,需要按日期來篩選和切片數據。傳統方法是手動創建硬編碼日期表,但這種方法在財年結束時需要手動修改,效率低下且容易出錯。本章中將研究如何構建完整日期表,以及基于已有數據自動生成與之匹配的日期表的方法。
??直接從公司數據庫中獲取日期表是更好的方法,本文討論的是無法公司數據中獲得日期表的情況,比如只有手頭的一大堆 Excel 或文本文件。
18.1 日期表的邊界日期
??在構建日期表時,需要考慮兩個重要部分:日期表的邊界日期(開始日期和結束日期) 以及所需的 “顆粒度”(即日期的明細程度,比如每日記錄、每周記錄、每月記錄)。
??每個日期表都有明確的邊界,這些邊界決定了日期表的時間范圍,是構建日期表的基礎。日期表的邊界可以通過以下三種方式生成:
- 參數:直接在Power Query中設置固定的開始日期和結束日期。
- 動態參數表:通過動態參數表生成邊界日期,這種方法更加靈活。
- 從數據集動態生成:根據實際數據動態計算邊界日期,這種方法能夠確保日期表始終與數據匹配。
??對于Excel 來說,動態參數表更好;對于數據集來說,從數據集動態生成日期更好,下面給出具體的操作思路,具體操作步驟可見“第 18 章 示例文件\Calendar Tables.xlsx”文件,其內容數據如下(銷售表從2018-1-1到2019-12-31;預算表從2018-1-31到2019-12-31):

18.1.1 計算邊界日期
在具體的操作之前,先給出需要遵守的規則。
- 強烈建議構建的日期表涵蓋整個財年數據
- 考慮所有的表來獲取日期。例如從具有最早日期的表(比如銷售表)中獲取起始日期;從具有最晚日期的表(比如預算表)中獲取結束日期。
鑒于上述情況,創建日期表的邊界日期方法如下(假設日期列名為“Date”):
| 步驟 | 獲取開始日期的流程 | 獲取結束日期的流程 |
|---|---|---|
| 1 | 直接引用包含最早日期的表(如銷售表) | 直接引用包含最晚日期的表(如預算表) |
| 2 | 刪除除“Date”列以外的所有內容 | 刪除除“Date”列以外的所有內容 |
| 3 | 篩選“Date”列中的最早日期(日期篩選器->最早) | 篩選“Date”列中的最晚日期 |
| 4 | 刪除重復值 | 刪除重復值 |
| 5 | 轉換為年份開始值(轉換->日期->年->年份開始值) | 轉換為年份結束值(如12月31日) |
| 6 | 可選:調整非標準財年日期 | 可選:調整非標準財年日期 |
| 7 | 將數據類型更改為“日期” | 將數據類型更改為“日期” |
| 8 | 右擊日期單元格(而不是列標題)->深化,鉆取日期值 | 鉆取日期值 |
| 9 | 將查詢重命名為“StartDate” | 將查詢重命名為“EndDate” |
| 10 | 加載為“僅限連接” | 加載為“僅限連接” |
- 請注意,此標準步驟將破壞查詢折疊。同樣,如果用戶的公司 IT 在 SQL 數據庫中為用戶提供了日期表,那么用戶應該使用它。這個標準步驟是為那些不能做到這一點,只能自行完成他們工作的用戶準備的。
- 日期將根據用戶本機的默認日期格式顯示,因此可能與本書所展示的格式有所區別
關鍵點解析:
- 步驟6:對于以12月31日結束的財年,可以跳過此步驟。如果財年結束日期不是12月31日,則需要調整日期。
- 步驟7:定義日期數據類型是為了確保步驟8中使用“{0}”格式可以正確地鉆取數據(右擊深化)。

18.1.2 處理非標準財年日期(結束日期不是12月31日)
??許多公司的財年并不以結束,而是以其他月份結束(如9月30日)。為了適應這種情況,文章建議創建一個“YEMonth”查詢作為參數變量,用于定義財年的最后一個月。創建“YEMonth”查詢的步驟:
- 創建新的空白查詢, 并將其重命名為“YEMonth”。
- 在公式欄中輸入財年最后一個月的數值(如9表示9月30日)。
- 將查詢加載為“僅限連接”。

調整開始日期和結束日期的步驟:
| 步驟 | 開始日期的標準流程 | 結束日期的標準流程 |
|---|---|---|
| 6A | 轉到“添加列”->“自定義列” | 轉到“添加列”->“自定義列” |
| 6B | 將列命名為“Custom”,并使用公式: = Date.AddMonths([Date], YEMonth - 12) | 將列命名為“Custom”,并使用公式: = Date.AddMonths([Date], YEMonth) |
| 6C | 右擊“Custom”列刪除其他列 | 右擊“Custom”列刪除其他列 |
| 6D | 將“Custom”列重命名為“Date” | 將“Custom”列重命名為“Date” |
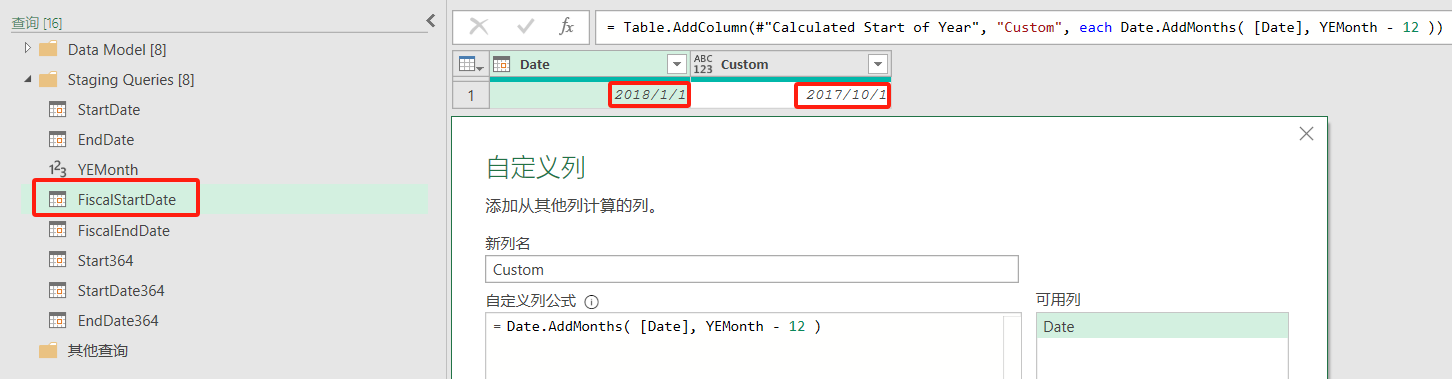
??如果開始日期是2018年1月1日,而財年以9月30日結束,那么調整后的財年開始日期將是2017年10月1日,結束日期將是2018年9月30日。
18.1.3 處理非標準財年日期(每年364天)
??除了常見的12個月日期結構,還有一種流行的日期結構是364天日期結構,包括“4-4-5”、“4-5-4”、“5-4-4”和“13 x 4”周。這些日期結構每年跨越364天,年終日期每年不同。
| 日期結構類型 | 每個季度分布 | 每年總周數 |
|---|---|---|
| 4-4-5 | 4周 + 4周 + 5周 | 52周(364天) |
| 4-5-4 | 4周 + 5周 + 4周 | 52周(364天) |
| 5-4-4 | 5周 + 4周 + 4周 | 52周(364天) |
| 13 x 4 | 52周(364天) |
為了使這一過程盡可能簡單,建議創建一個新的查詢來完成這個任務。
- 創建新的空白查詢,并將其重命名為“Start364”。
- 在公式欄中輸入任何會計年度第一天的日期。
假設公司會計年度開始于 2017-01-01、2017-12-31 和 2018-12-30(每個日期都是星期日),可以在“Start364”查詢中使用其中任何一個值 - 將查詢加載為“僅限連接”。

調整開始日期和結束日期的步驟:
| 步驟 | 開始日期的標準流程 | 結束日期的標準流程 |
|---|---|---|
| 6A | 轉到“添加列”->“自定義列” | 轉到“添加列”->“自定義列” |
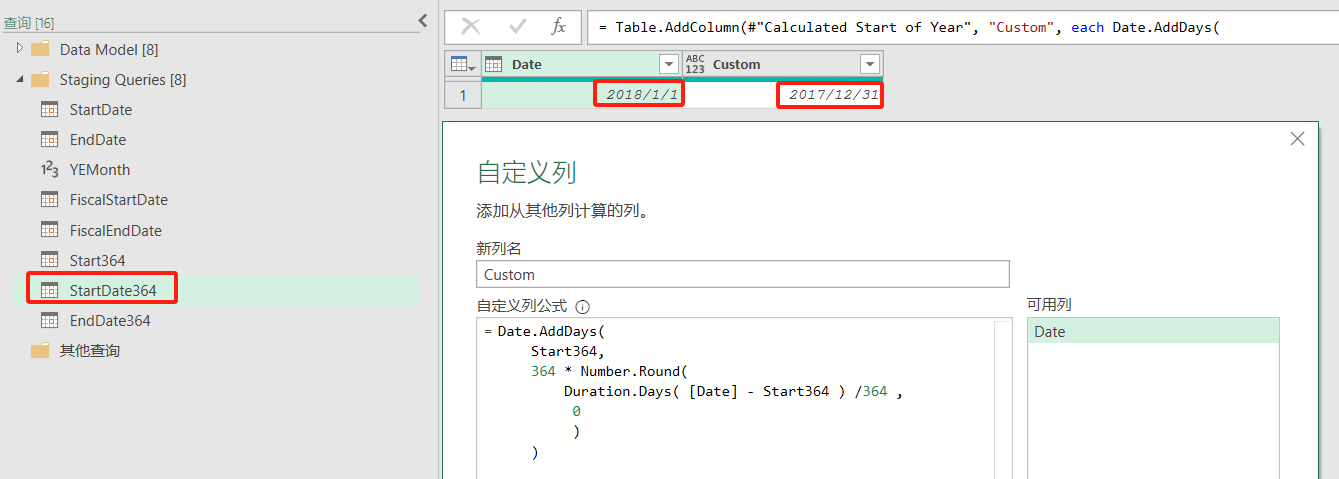
| 6B | 將列命名為“Custom”,并使用公式: =Date.AddDays(Start364, 364 * Number.Round(Duration.Days([Date] - Start364) / 364, 0)) | 將列命名為“Custom”,并使用公式: =Date.AddDays(Start364, 364 * Number.RoundUp(Duration.Days([Date] - Start364) / 364, 0) - 1) |
| 6C | 右擊“Custom”列刪除其他列 | 右擊“Custom”列刪除其他列 |
| 6D | 將“Custom”列重命名為“Date” | 將“Custom”列重命名為“Date” |
Duration.Days([Date] - Start364)計算從會計年度第一天到當前日期的天數。Number.Round(...)和Number.RoundUp(...)用于計算完整的364天周期。- 如果開始日期是2018年1月1日,而財年開始日期是2017年1月1日,財年是364天,那么調整后的開始日期將是2017年12月31日,結束日期將是2018年12月29日。
18.2 原子日期表(每日)
18.2.1 標準財年
原子日期表是最基礎的日期表,它包含了從開始日期到結束日期的每一天。構建原子日期表的步驟如下:
-
創建新的空白查詢,并將其重命名為“Calendar”;
-
創建開始日期到結束日期的列表:在公式欄輸入
= { Number.From( StartDate ) .. Number.From( EndDate ) }
-
使用【列表工具】【轉換】【到表】工具,將列表轉換為表,然后重命名為“Date”列;
-
將“Date”列的數據類型更改為【日期】
-
增強日期表:按業務需要,可使用【添加列】【日期】功能,添加需要的日期類型數據

18.2.2 非標準財年(結束日期不是12月31日)
??對于非標準財年(如以9月30日為財年結束),可用以下公式來計算財政日期列。其中,YEMonth是財年結束的月份(如9表示9月30日)。
| 列名 | 需要的列 | 公式 |
|---|---|---|
| Fiscal Year | “Date” | Date.Year(Date.AddMonths([Date],12-YEMonth)) |
| Fiscal Month | “Date” | Date.Month(Date.AddMonths([Date],-YEMonth)) |
| Fiscal Quarter | “Fiscal Month” | Number.RoundUp([Fiscal Month]/3) |
| Fiscal Month of Quarter | “Fiscal Month” | if Number.Mod([Fiscal Month],3) = 0 then 3 else Number.Mod([Fiscal Month],3) |
| End of Fiscal Year | “Date”、“Fiscal Month” | Date.EndOfMonth(Date.AddMonths([Date], 12-[Fiscal Month])) |
| End of Fiscal Quarter | “Date”、“Fiscal Month Quarter” | Date.EndOfMonth(Date.AddMonths([Date], 3-[Fiscal Month of Quarter] ) ) |

18.2.3 非標準財年(每年364天)
??構建364天日期表的最大難點在于其周期劃分方式與傳統日期結構不同,需要特殊的列來支持其獨特的日期邏輯和報告周期。
- 創建“DayID”列:創建從1開始的索引列,并將其重命名為“DayID”
- 創建“PeriodID”列:使用以下公式創建各種PeriodID”列。注意:對于不同的日期結構,“MonthID”公式將不同
| 列名 | 需要的列 | 公式 |
|---|---|---|
| WeekID | “DayID” | Number.RoundUp([DayID]/7) |
| MonthID (4-4-5) | “DayID” | Number.RoundDown([DayID]/91)*3+ ( if Number.Mod([DayID],91)=0 then 0 else if Number.Mod([DayID],91)<= 28 then 1 else if Number.Mod([DayID],91)<= 56 then 2 else 3 ) |
| MonthID (4-5-4) | “DayID” | Number.RoundDown([DayID]/91)*3+ ( if Number.Mod([DayID],91)=0 then 0 else if Number.Mod([DayID],91)<= 28 then 1 else if Number.Mod([DayID],91)<= 63 then 2 else 3 ) |
| MonthID (5-4-4) | “DayID” | Number.RoundDown([DayID]/91)*3+ ( if Number.Mod([DayID],91)=0 then 0 else if Number.Mod([DayID],91)<= 35 then 1 else if Number.Mod([DayID],91)<= 63 then 2 else 3 ) |
| MonthID (for 13x4 Calendars) | Number.RoundUp([DayID]/28) | |
| QuarterID | “DayID” | Number.RoundUp([DayID]/91) |
| YearID | “DayID” | Number.RoundUp([DayID]/364) |
| Fiscal Year | “YearID” | Date.Year(Date.From(StartDate))+[YearID],例如2018 |

| 列名 | 需要的列 | 年份和周期組合的公式,可能需要在最終結果中加上或減去 1 |
|---|---|---|
| Quarter of Year | [QuarterID] | Number.Mod([QuarterID]-1,4)+1 |
| Month of Year | [MonthID] | Number.Mod([MonthID]-1,12)+1 |
| Week of Year | [WeekID] | Number.Mod([WeekID]-1,52)+1 |
| Day of Year | [DayID] | Number.Mod([DayID]-1,364)+1 |
| 列名 | 需要的列 | x 季度,x 月和 x 周的列公式 |
|---|---|---|
| Month of Quarter | “Month of Year” | Number.Mod([Month of Year]-1,3)+1 |
| Week of Quarter | “Week of Year” | Number.Mod([Week of Year]-1,13)+1 |
| Day of Quarter | “Day of Year” | Number.Mod([Day of Year]-1,91)+1 |
| Day of Month (4-4-5) | “Day of Quarter”、 “Month of Quarter” | if [Month of Quarter] = 1 then [Day of Quarter] else if [Month of Quarter] = 2 then [Day of Quarter] - 28 else [Day of Quarter] - 35 |
| Day of Month (4-5-4) | “Day of Quarter”、 “Month of Quarter” | if [Month of Quarter] = 1 then [Day of Quarter] else if [Month of Quarter] = 2 then [Day of Quarter] - 28 else [Day of Quarter] - 63 |
| Day of Month (5-4-4) | “Day of Quarter”、 “Month of Quarter” | if [Month of Quarter] = 1 then [Day of Quarter] else if [Month of Quarter] = 2 then [Day of Quarter] - 35 else [Day of Quarter] - 63 |
| Week of Month | “Day of Month” | Number.RoundUp([Day of Month]/7) |
| Day of Week | “Day of Year” | Number.Mod([Day of Year]-1,7)+1 |
| 列名 | 需要的列 | x列的天數公式 |
|---|---|---|
| Days in Year | N/A | 364 |
| Days in Quarter | N/A | 91 |
| Days in Month (4-4-5) | “Week of Quarter” | if [Week of Quarter] > 8 then 35 else 28 |
| Days in Month (4-5-4) | “Week of Quarter” | if [Week of Quarter]>4 and [Week of Quarter]<10 then 35 else 28 |
| Days in Month (5-4-4) | “Week of Quarter” | if [Week of Quarter] < 5 then 35 else 28 |
| Days in Week | N/A | 7 |
| 列名 | 需要的列 | x 列開始或者 x 列結束的公式 |
|---|---|---|
| Start of Week | “Date”、“Day of Week” | Date.AddDays([Date],-([Day of Week]-1)) |
| End of Week | “Start of Week” | Date.AddDays([Start of Week],6) |
| Start of Month | “Date”、“Day of Month” | Date.AddDays([Date],-([Day of Month]-1)) |
| End of Month | “Start of Month”、“Days in Month” | Date.AddDays([Start of Month],[Days in Month]-1) |
| Start of Quarter | “Date”、“Day of Quarter” | Date.AddDays([Date],-([Day of Quarter]-1)) |
| End of Quarter | “Start of Quarter” | Date.AddDays([Start of Quarter],91-1) |
| Start of Year | “Date”、“Day of Year” | Date.AddDays([Date],-([Day of Year]-1)) |
| End of Year | “Start of Year” | Date.AddDays([Start of Year],364-1) |
18.2.4 示例文件介紹
示例文件中包含了以下幾種日期表:
- Calendar:標準的12個月日期表,每年12月31日結束。
- Calendar-Sep30:12個月日期表,會計年度結束日期為每年9月30日。
- Calendar-445:使用“4-4-5”周模式的364天日期表。
- Calendar-454:使用“4-5-4”周模式的364天日期表。
- Calendar-544:使用“5-4-4”周模式的364天日期表。
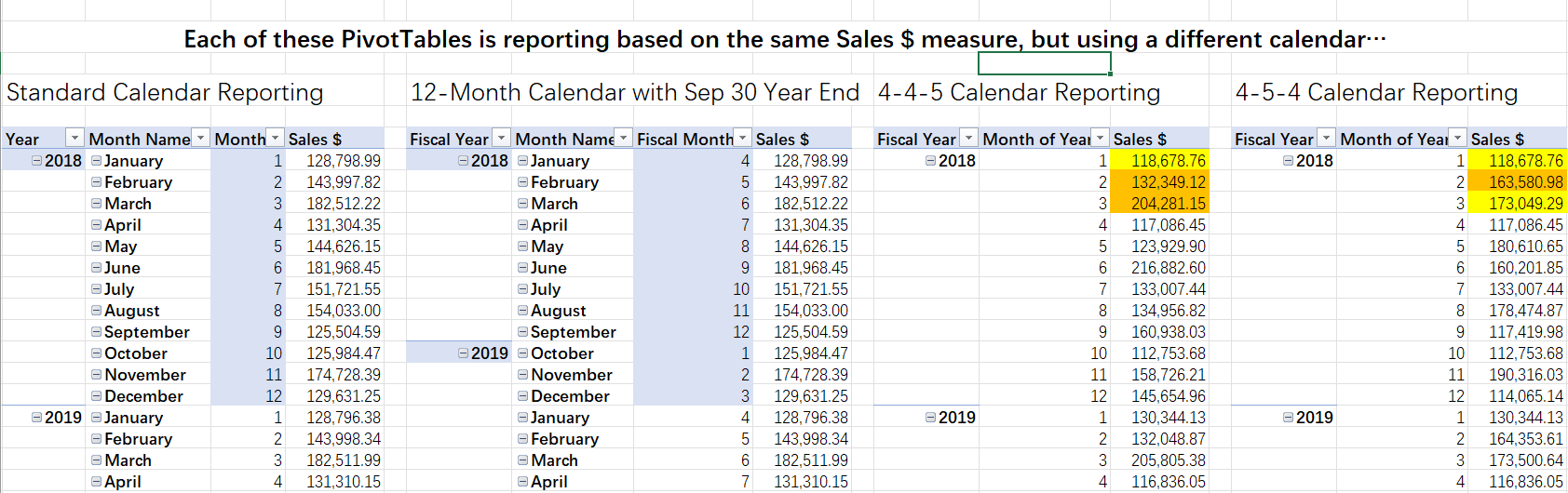
下圖顯示了每個表都加載到數據模型中,并通過日期列連接到“Sales”表和“Budgets”表:

??數據模型中還創建了“Sales $”和“Budget $”度量,并在Comparisons工作簿中構建透視表進行不同財年統計結果的比較,可以直觀地發現日期報告數據的方式之間的異同。
以下是對https://www.excel120.com/#/pq/c-18中18.3章節“日期時間填充”的詳細總結:
18.3 日期時間填充
??上述解決方案展示了如何在兩個特定日期之間填充日期,但是如果只知道開始日期以及持續時間,該怎么填充日期呢?
18.3.1 日期級別填充
??以“第 18 章 示例文件\Fill Dates-Begin.xlsx”文件為例,只知道每位訪客的開始訪問日期,以及訪問持續天數,此時可使用List.Dates函數來生成每個人的訪問日期表。

-
導入數據:創建一個新查詢,從“Visitors”表中讀取開始日期和持續天數;
-
填充日期列表:使用以下公式添加自定義列,并重命名為“Pass Date”。
// 三個參數分別是開始日期、天數(列表元素個數)以及日期間隔 // duration的四個參數分別表示天、小時、分鐘、秒。 =List.Dates([Arrival], [Days on Site], #duration(1,0,0,0))
-
數據清洗:
- 保留“Pass Date”列和相關的主列(如“Visitor”列),刪除其它不必要的列
- 擴展“Pass Date”列,選擇【擴展到新行】,將列表中的每個日期展開為單獨的行。
- 轉換所有列的數據類型,將該查詢重命名為Pass List

??不推薦使用
List.Dates函數生成完整的日期表,因為它無法直接表示“月”的持續時間(每個月的實際天數都不同,計算起來較為復雜),而是應該使用上兩節介紹的方式。
18.3.2 小時級別填充
??如果需要以小時為單位進行日期時間填充,比如從每天上午 9:00 開始添加 8 個小時的訪問記錄,可以使用List.Times函數來完成,其語法和List.Dates是一樣的。
- 導入數據:復制上一個查詢,并將其命名為“Pass Times”。
- 填充日期時間列表:使用以下公式添加自定義列,并重命名為““Hour””。
=List.Times( #time(9,0,0), 8, #duration(0,1,0,0) ) - 將“Hour”列擴展到新行,最后設置數據類型
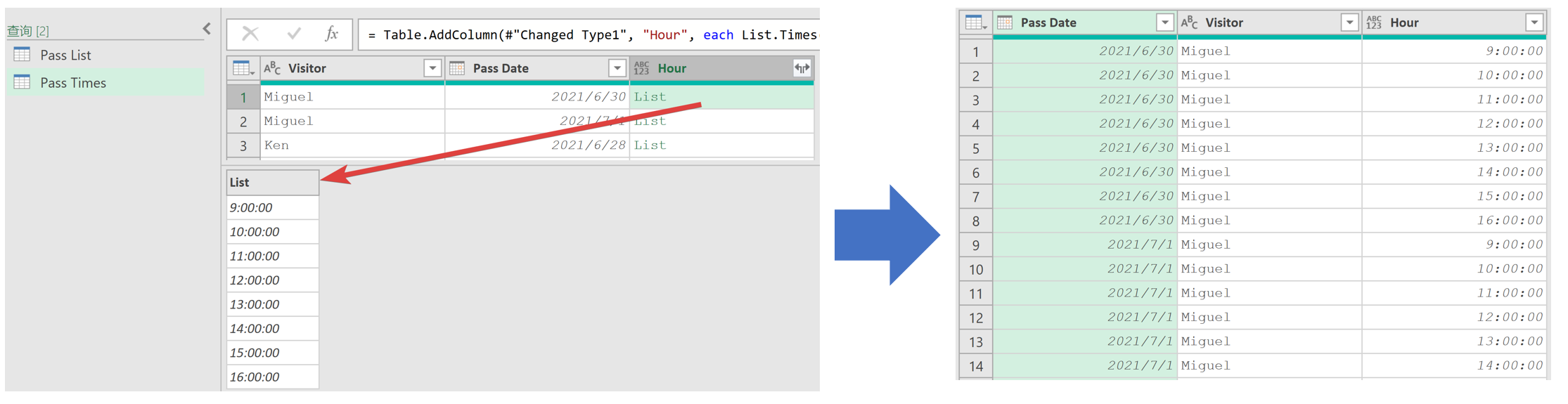
- 持續時間值的三個參數是小時、分鐘、秒,且依賴于24小時制的時間。
- 如果需要在日期和時間之間進行轉換,可以使用
#datetime函數。
18.3.3 帶時間間隔的填充
??如果需要生成一個以一定間隔(Frequency)重復特定次數(Check Ins)的日期表,可以通過修改List.Dates函數的最后一個參數來實現。

- 打開
Fill Every x Dates-Begin.xlsx文件,創建一個查詢,連接到Contracts表。 - 添加自定義列“Follow Up”,其公式為:
// Duration.From(days)函數會返回一個持續時間為days天的值。 =List.Dates([Contract Start], [Check Ins], Duration.From([Frequency]))
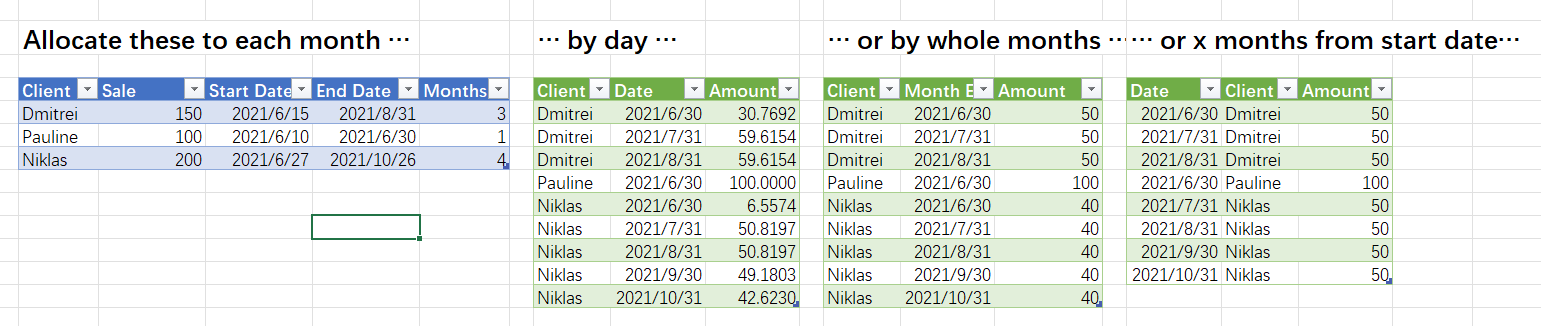
18.4 按日期分攤
??在財務和業務分析中,經常需要將收入或支出按日期分攤到不同期間,比如按實際天數分攤、按月數平均分攤(每個月有幾天不重要)、 按特定規則(如15日規則)分攤:
??首先創建“Raw Data”查詢:使用= Excel.CurrentWorkbook()公式獲取當前Excel表的所有表,然后導航到其中的Sales數據表,并將查詢加載為【僅創建連接】。

18.4.1 起止日內按日分攤

-
導入數據: 引用“Raw Data”查詢,刪除不必要的“Month”列;
-
計算每日分攤金額: 添加自定義列“Amount”,公式為
=[Sale] / (Number.From([End Date]) - Number.From([Start Date]) + 1),計算每天的分攤金額。

-
生成日期列表并展開:
- 添加自定義列“Date”,公式為
={Number.From([Start Date]) .. Number.From([End Date])},生成從開始日期到結束日期的日期列表。 - 將“Date”列擴展到新行,然后將數據類型更改為日期。

- 添加自定義列“Date”,公式為
-
數據清洗
- 如果希望數據處于這種日期粒度級別,那么只需刪除“Sale”、“Start Date”和“End Date”列并設置數據類型,然后就可以加載數據了。
- 如果需要按月匯總分攤金額,那么執行以下步驟
- 將“Date”列轉換為月末值。
- 按“以下方式進行分組,并對“Amount”列求和,匯總每個月的分攤金額。
- 刪除不必要的列,設置數據類型。
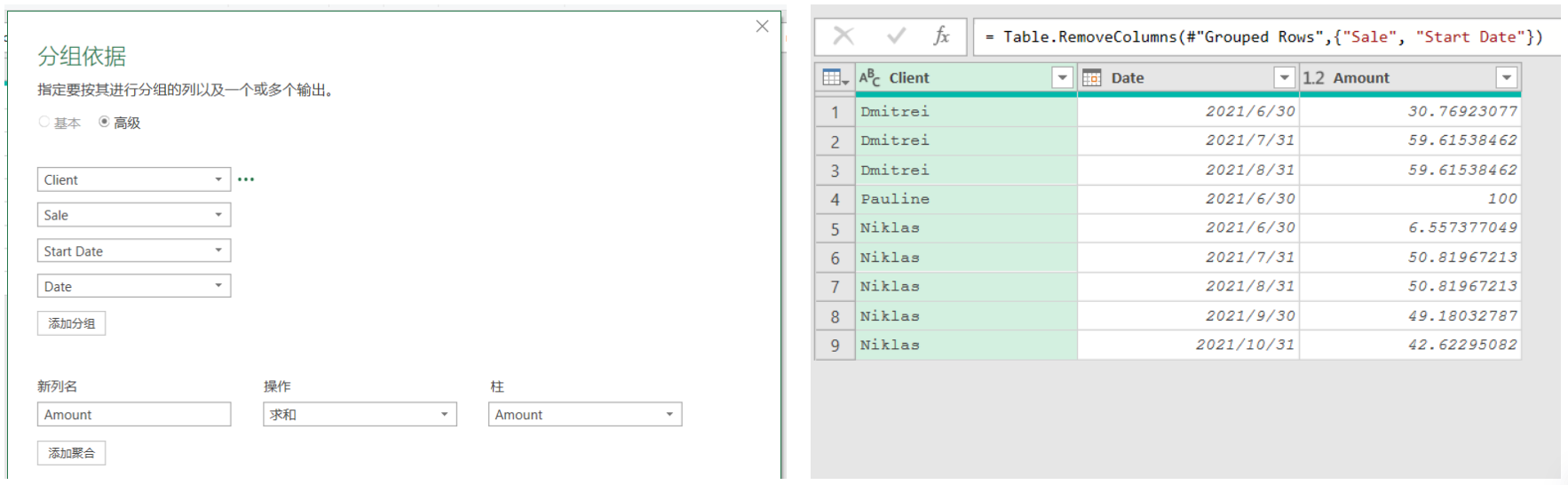
- 計算日期差時需要加1,以確保包括起止日期在內的所有天數都被計算。
- 分攤金額時未進行四舍五入,以避免舍入誤差累積;如果需要,建議在最后一部進行舍入。
18.4.2 起止日內按月分攤

??Power Query 沒有一個可以根據起始日期創建月末日期列表的函數,所以第一步是先自定義一個函數來實現此功能。
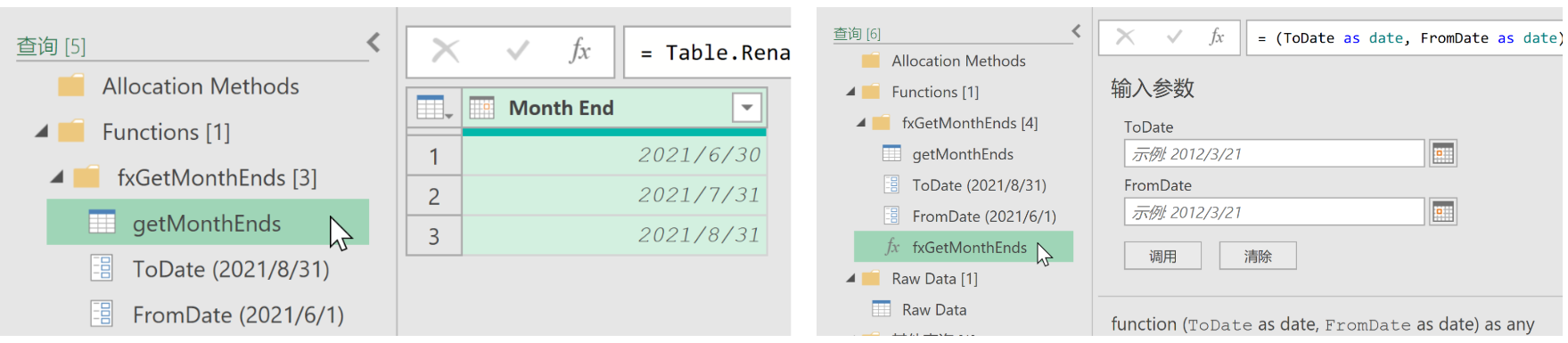
-
創建自定義函數生成月末日期列表:
- 創建兩個日期類型參數“FromDate”和“ToDate”,當前值分別為“2021-06-01”和“2021-08-31”
- 創建空白查詢“getMonthEnds”,參考18.1.1章節,生成從“FromDate”到“ToDate”之間的月末日期列表。
- 將該查詢轉換為函數
fxGetMonthEnds。
-
計算每月分攤金額:
- 引用“Raw Data”查詢,刪除不必要的“Months”列
- 調用自定義函數
fxGetMonthEnds,【FromDate】選擇“Start Date”列,【ToDate】選擇“End Date”列,生成月末日期列表。 - 添加自定義列“Amount”,公式為
=[Sale] / Table.RowCount([fxGetMonthEnds]),計算每月的分攤金額。
-
展開并整理數據:
- 選擇“Client”、“fxGetMonthEnds”和“Amount”列【刪除其他列】
- 展開“fxGetMonthEnds”列,將月末日期展開為單獨的行。
- 設置數據類型。

- 自定義函數
fxGetMonthEnds可以重復使用,適用于任何需要生成月末日期列表的場景。- 使用
Table.RowCount函數統計月末日期的數量,從而計算每月分攤金額。
18.4.3 起點日后按月分攤(15日規則)
本質上還是按月分攤,但是需要根據開始日期是否在當月15日之前或之后來決定是否從當月開始分攤:

-
計算每月分攤金額:
- 引用“Raw Data”查詢,刪除不必要的EndDate”列;
- 添加自定義列“Amount”,公式為
=[Sale] / [Months],計算每月的分攤金額。

-
生成月份偏移量列表:
- 使用以下公式添加自定義列“Custom”,根據開始日期的天數生成偏移量列表。
=if Date.Day([Start Date]) <= 15 then {0 .. [Months] - 1} else {1 .. [Months]} - 將“Custom”列展開為新行
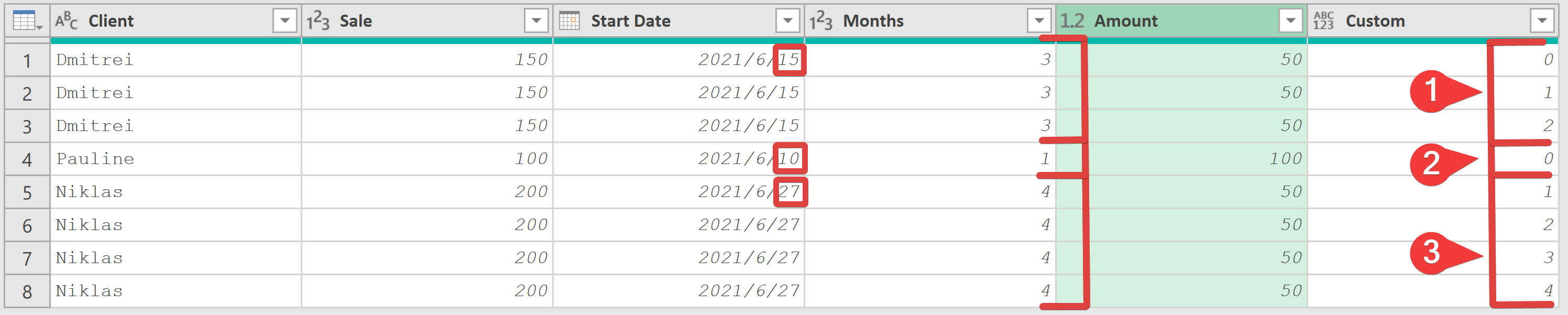
- 使用以下公式添加自定義列“Custom”,根據開始日期的天數生成偏移量列表。
-
計算分攤日期:
- 創建一個名為“Date”的新【自定義列】,該列使用以下公式,根據偏移量計算分攤的月末日期。
= Date.EndOfMonth( Date.AddMonths( [Start Date], [Custom] ) ) - 選擇“Date”、“Client”和“Amount”列【刪除其他列】,設置數據類型。
- 創建一個名為“Date”的新【自定義列】,該列使用以下公式,根據偏移量計算分攤的月末日期。
- 條件公式
if Date.Day([Start Date]) <= 15用于判斷是否從當月開始分攤。- 使用
Date.AddMonths函數根據偏移量計算分攤日期,如果不需要將分攤日期設置為月末,可以刪除Date.EndOfMonth函數。

)
![[250428] Nginx 1.28.0 發布:性能優化、安全增強及新特性](http://pic.xiahunao.cn/[250428] Nginx 1.28.0 發布:性能優化、安全增強及新特性)


)
)









)


