文章目錄
- 前言
- style transfer原理
- 原理解析
- 損失函數
- style transfer代碼
- 效果圖
- fast style transfer 代碼
- 效果圖
前言
本篇來帶大家看看VGG的實戰篇,這次來帶大家看看計算機視覺中一個有趣的小任務,圖像風格遷移。
可運行代碼位于: Style_transfer (可直接下載運行)
我們所進行的圖像風格遷移是基于VGG實現的哦,如果對VGG網絡還不太了解的,可以先去看看這邊文章:【深度學習基礎】:VGG原理篇-CSDN博客
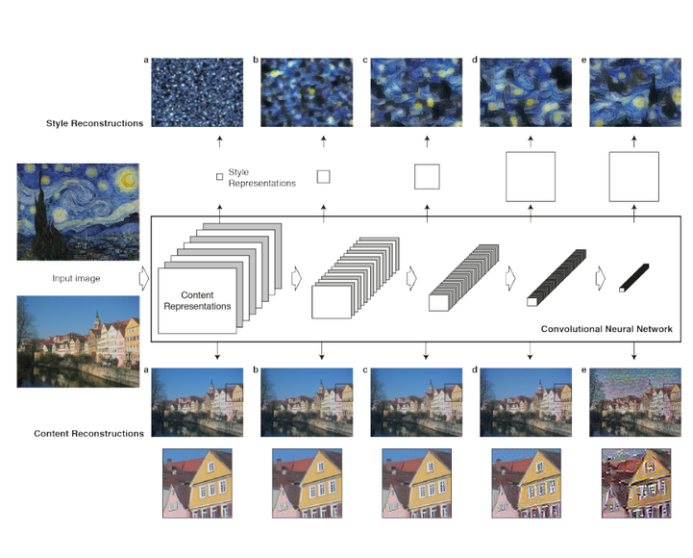
style transfer原理
原理解析
圖像風格遷移是一種通過將一張圖像的風格應用到另一張圖像的內容上,從而生成一張新圖像的技術。這種技術通常基于深度學習模型,特別是卷積神經網絡(CNN)。
實現步驟:
- 首先,我們需要兩張圖像:內容圖像和風格圖像。內容圖像是我們想要保持內容的圖像,而風格圖像是我們想要應用到內容圖像上的風格的圖像。接下來,我們通過使用預訓練的卷積神經網絡(如VGG19)來提取圖像的特征。
- 在提取特征之后,我們計算內容損失和風格損失。內容損失度量生成圖像與內容圖像在內容上的差異,通常通過比較兩個圖像在淺層特征上的差異來計算。風格損失度量生成圖像與風格圖像在風格上的差異,風格通常通過計算圖像特征之間的相關性來表示,即風格圖像的特征圖之間的gram矩陣。(這個等會會詳細講述)
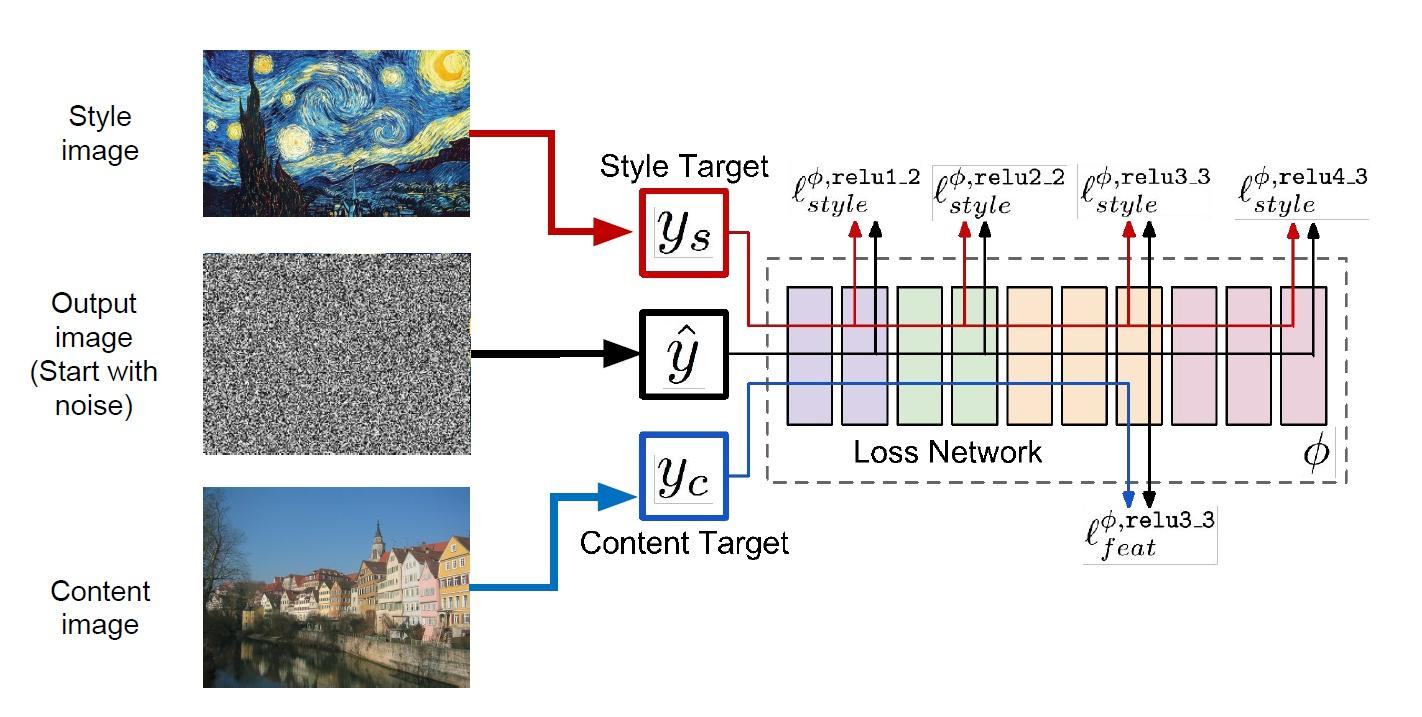
其實圖像風格遷移的核心是一個優化問題,目標是生成一張圖像,使得內容損失和風格損失都最小化。我們初始化一張隨機生成的圖像。然后,我們使用卷積神經網絡提取這張圖像的特征,并計算內容損失和風格損失。接著,我們計算總損失,并進行反向傳播和優化,以更新生成圖像的像素值。這個過程會重復進行多次,直到生成圖像在內容和風格上都接近目標圖像。
損失函數
好,其實大概的原理基本上都清楚了,但是我們來看,我們是該如何去保證圖片的內容是我們所選的內容圖片,但是風格確實我們所選的風格圖片呢?
首先來看內容函數的損失函數,其是這個還是很好理解的,我們所使用的就是平方差損失函數,我們希望我們的生成圖片能夠和內容圖片具有相同的內容,所以最小化兩者的差距即可。但是這里有個細節,我們該選擇那個層的輸出作為我們的標準呢?其實看最上面的圖也能看出,我們的網絡越深,提取到的內容圖片損失的細節就會越多,所以我們會更多的選擇淺層的內容圖片特征作為標準。
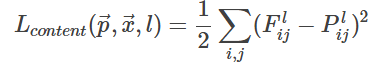
def calculate_content_loss(original_feat, generated_feat) -> torch.Tensor:"""計算內容損失,即生成特征圖與標準特征圖的規范化誤差平方和"""b, c, h, w = original_feat.shapex = 2. * c * h * w # 規范化系數return torch.sum((generated_feat - original_feat) ** 2) / x
然后我們在來看風格損失函數,其實風格損失函數的關鍵在于gram矩陣。那么我們回到最初,我們為什么能夠提取出來圖像的風格特征呢?其實就是依靠Gram矩陣了,其用于捕捉圖像中不同通道之間的相關性,這些相關性可以反映出圖像的紋理、顏色分布等風格特征。通俗說就是出現尖尖的形狀的時候邊上應該出現些什么。
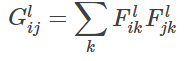
然后風格損失函數如下,同樣的我們會選擇深層的風格圖像特征作為我們的標準,因為深層網絡提取出來的更多的是抽象的語義信息,能夠代表其本質的特征,抽象的特征。
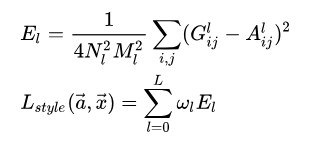
def gram_matrix(feature):"""計算特征圖的格萊姆矩陣,作為風格特征表示:param feature: 輸入特征圖:return: 格萊姆矩陣"""b, c, h, w = feature.size()feature = feature.view(b, c, h * w) # 拉平空間維度G = torch.bmm(feature, feature.transpose(1, 2))return Gdef calculate_style_loss(style_feat, generated_feat) -> torch.Tensor:"""計算風格損失,即生成特征圖與標準特征圖的格拉姆矩陣的規范化誤差平方和"""b, c, h, w = style_feat.shapeG = gram_matrix(generated_feat)A = gram_matrix(style_feat)x = 4. * ((h * w) ** 2) * (c ** 2) # 規范化系數return torch.sum((G - A) ** 2) / x
所以最終的損失函數就是風格損失和內容損失的和,其中會乘上不同的系數。

style transfer代碼
這里只展現了部分的核心代碼,所有代碼位于Style_transfer ,下載可直接使用。
我們通過處理目標圖片,其一開始就是一張白噪聲圖,然后通過網絡損失不斷修改其像素,使得目標圖片內容與內容圖片相近,風格與風格圖片相近。
import argparse
import os
import torch
import torch.optim as optim
from tqdm import tqdmfrom models import VGG
from utils import make_transform, load_image, save_image, calculate_style_loss, calculate_content_lossdef parse_args():parser = argparse.ArgumentParser(description='Style Transfer=')parser.add_argument('--content_image', type=str, default='./data/content1.jpg', help='Path to the content image')parser.add_argument('--style_image', type=str, default='./data/style2.jpg', help='Path to the style image')parser.add_argument('--output_dir', type=str, default='./output/iterative_style_transfer', help='Output directory')parser.add_argument('--image_size', type=int, nargs=2, default=[300, 450], help='Image size (height, width)')parser.add_argument('--content_weight', type=float, default=1, help='Content weight')parser.add_argument('--style_weight', type=float, default=15, help='Style weight')parser.add_argument('--epochs', type=int, default=20, help='Number of training epochs')parser.add_argument('--steps_per_epoch', type=int, default=100, help='Number of steps per epoch')parser.add_argument('--learning_rate', type=float, default=0.03, help='Learning rate')return parser.parse_args()if __name__ == "__main__":args = parse_args()# 檢查文件路徑assert os.path.exists(args.content_image), f"content image is not exist: {args.content_image}"assert os.path.exists(args.style_image), f"style image is not exist: {args.style_image}"# 內容特征層及loss加權系數content_layers = {'5': 0.5, '10': 0.5}# 風格特征層及loss加權系數style_layers = {'0': 0.2, '5': 0.2, '10': 0.2, '19': 0.2, '28': 0.2}# ----------------訓練即推理過程----------------device = torch.device("cuda" if torch.cuda.is_available() else "cpu")transform = make_transform(args.image_size, normalize=True)content_img = load_image(args.content_image, transform).to(device)style_img = load_image(args.style_image, transform).to(device)# 用小隨機噪聲初始化圖像(避免標準正態分布過大震蕩)generated_img = torch.rand_like(content_img).mul(0.1).requires_grad_().to(device)save_image(generated_img, args.output_dir, 'noise_init.jpg')vgg_model = VGG(content_layers, style_layers).to(device).eval()# 關閉梯度追蹤,節省顯存with torch.no_grad():content_features, _ = vgg_model(content_img)_, style_features = vgg_model(style_img)optimizer = optim.Adam([generated_img], lr=args.learning_rate)for epoch in range(args.epochs):p_bar = tqdm(range(args.steps_per_epoch), desc=f'Epoch {epoch + 1}/{args.epochs}')for step in p_bar:generated_content, generated_style = vgg_model(generated_img)content_loss = sum(args.content_weight * content_layers[name] * calculate_content_loss(content_features[name], gen_content)for name, gen_content in generated_content.items())style_loss = sum(args.style_weight * style_layers[name] * calculate_style_loss(style_features[name], gen_style)for name, gen_style in generated_style.items())total_loss = style_loss + content_lossoptimizer.zero_grad()total_loss.backward()# 梯度裁剪(可選但穩健)torch.nn.utils.clip_grad_norm_([generated_img], max_norm=1.0)optimizer.step()p_bar.set_postfix(style_loss=style_loss.item(), content_loss=content_loss.item(), total_loss=total_loss.item())# 保存中間結果save_image(generated_img, args.output_dir, f'generated_epoch_{epoch + 1}.jpg')效果圖

fast style transfer 代碼
剛才我們看了基于迭代的圖像風格遷移,那么能不能有個方法,我們訓練一個專用于一種風格的圖像遷移的網絡,其網絡訓練好之后,我們就不再需要老是輸入風格圖像,這個訓練好的網絡可以處理所有輸入的圖像輸出其已經訓練好的風格。所以fast style transfer 來了。其不僅可以處理圖片,同樣可以處理視頻哦!
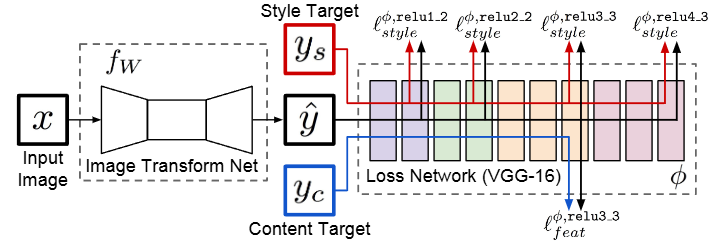
這里只展現了部分的核心代碼,所有代碼位于Style_transfer ,下載可直接使用。
import argparse
import os
from datetime import datetime, timedelta
from typing import List, Iterablefrom PIL import Imageimport torch
from torch.utils.data import DataLoader
from torchvision import transforms
from tqdm import tqdm
import cv2
import numpy as npfrom models import VGG, TransNet
from datasets import ImageDataset
from utils import load_image, save_image, make_transform, save_model, calculate_style_loss, calculate_content_loss, \denormalizedef parse_args():parser = argparse.ArgumentParser(description='Fast Style Transfer')parser.add_argument('--mode', type=str, choices=['train', 'image', 'video'], default='train',help='Operation mode: train, image, video')parser.add_argument('--image_size', type=int, nargs=2, default=[300, 450], help='Image size (height, width)')parser.add_argument('--style_image', type=str, default='./data/style3.jpg', help='Style image path (training mode only)')# The directory data/train2017/default_class contains several images. Due to the format required by ImageFolder, we need to use a class folder to contain the images, even though the class label is not used.parser.add_argument('--content_dataset', type=str, default='data/train2014', help='Content image dataset path (training mode only)')parser.add_argument('--content_weight', type=float, default=1., help='Content weight (training mode only)')parser.add_argument('--style_weight', type=float, default=15., help='Style weight (training mode only)')parser.add_argument('--model_save_path', type=str, default=f'./checkpoint/style2.pth', help='Model save path (training mode)')parser.add_argument('--pretrained_model_path', type=str, help='Pretrained model load path (training mode only)')parser.add_argument('--epochs', type=int, default=100, help='Number of training epochs (training mode)')parser.add_argument('--save_interval', type=int, default=120, help='Save interval (seconds) (training mode)')parser.add_argument('--learning_rate', type=float, default=0.001, help='Learning rate (training mode)')parser.add_argument('--output_dir', type=str, default='./output/realtime_transfer', help='Output directory (training mode)')parser.add_argument('--model_path', type=str, default='./checkpoint/style1.pth', help='Model load path (image and video mode)')parser.add_argument('--input_images_dir', type=str, help='Input images root directory (image mode only)')parser.add_argument('--output_images_dir', type=str, default='./output/fast_style_transfer/image_generated.jpg',help='Output images root directory (image mode only)')parser.add_argument('--video_input', type=str, default='data/maigua.mp4', help='Input video path (video mode only)')parser.add_argument('--video_output', type=str, default='output/videos/maigua.mp4',help='Output video path (video mode only)')parser.add_argument('--batch_size', type=int, default=4, help='Batch size')return parser.parse_args()def train(model,vgg,lr, epochs, batch_size, style_weight, content_weight, style_layers, content_layers,device, transform,image_style,content_dataset_root,save_path, output_dir,save_interval=timedelta(seconds=120)):optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 對目標網絡進行優化dataset = ImageDataset(content_dataset_root, transform=transform)dataloader = DataLoader(dataset, batch_size, shuffle=True)_, style_features = vgg(image_style)p_bar = tqdm(range(epochs))last_save_time = datetime.now() - save_intervalfor epoch in p_bar:running_content_loss, running_style_loss = 0.0, 0.0for i, content_img in enumerate(dataloader):content_img = content_img.to(device)image_generated = model(content_img) # 只使用內容圖像進行風格遷移generated_content, generated_style = vgg(image_generated)style_loss = sum(style_weight * style_layers[name] * calculate_style_loss(style_features[name], gen_style) forname, gen_style in generated_style.items())content_features, _ = vgg(content_img) # 計算內容圖的內容特征content_loss = sum(content_weight * content_layers[name] * calculate_content_loss(content_features[name], gen_content) forname, gen_content in generated_content.items())total_loss = style_loss + content_lossoptimizer.zero_grad()total_loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1) # 梯度裁剪optimizer.step()running_content_loss += content_loss.item()running_style_loss += style_loss.item()p_bar.set_postfix(progress=f'{(i + 1) / len(dataloader) * 100:.3f}%',style_loss=f"{style_loss.item():.3f}",content_loss=f"{content_loss.item():.3f}",last_save_time=last_save_time)if datetime.now() - last_save_time > save_interval:last_save_time = datetime.now()#writer.add_images('image_generated', denormalize(image_generated), epoch * len(dataloader) + i)save_model(model, save_path) # 'fast_style_transfer.pth'save_image(torch.cat((image_generated, content_img), 3), output_dir, f'{epoch}_{i}.jpg')def process_images(images: Iterable[Image.Image], transform, model, device) -> List[Image.Image]:images = torch.stack([transform(image) for image in images]).to(device)model.to(device)batch_generated = model(images)batch_generated = denormalize(batch_generated).detach().cpu()batch_generated = [transforms.ToPILImage()(image) for image in batch_generated]return batch_generateddef process_video(video_path, output_path, transform, model, device, batch_size=4):# 打開視頻文件cap = cv2.VideoCapture(video_path)output_dir, filename = os.path.split(output_path)if output_dir and not os.path.exists(output_dir):os.makedirs(output_dir)# 獲取視頻屬性frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))fps = cap.get(cv2.CAP_PROP_FPS)total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))# 定義視頻編碼器和創建 VideoWriter 對象fourcc = cv2.VideoWriter_fourcc(*'mp4v')out = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height))# 初始化 tqdm 進度條pbar = tqdm(total=total_frames, desc="Processing Video")# 讀取視頻并批量處理frames = []while True:ret, frame = cap.read()if not ret:breakframes.append(Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)))if len(frames) == batch_size:batch_generated = process_images(frames, transform, model, device)for gen_frame in batch_generated:gen = cv2.cvtColor(np.array(gen_frame), cv2.COLOR_RGB2BGR)cv2.imshow("output", gen)gen = cv2.resize(gen, (frame_width, frame_height))out.write(gen)if cv2.waitKey(1) & 0xFF == ord('s'):breakframes.clear()pbar.update(batch_size)if frames:batch_generated = process_images(frames, transform, model, device)for gen_frame in batch_generated:out.write(cv2.cvtColor(np.array(gen_frame), cv2.COLOR_RGB2BGR))pbar.update(len(frames))print(f'video successfully saved to: {output_path}')pbar.close()cap.release()out.release()if __name__ == '__main__':args = parse_args()# print(args)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# ----------------路徑參數----------------# 內容特征層及loss加權系數content_layers = {'5': 0.5, '10': 0.5} # 使用vgg的較淺層特征作為內容特征,保證生成圖片內容結構相似性# 風格特征層及loss加權系數style_layers = {'0': 0.2, '5': 0.2, '10': 0.2, '19': 0.2, '28': 0.2} # 使用vgg不同深度的風格特征,生成風格更加層次豐富transform = make_transform(size=args.image_size, normalize=True) # 圖像變換image_style = load_image(args.style_image, transform=transform).to(device) # 風格圖像vgg = VGG(content_layers, style_layers).to(device) # 特征提取網絡,只用來提取特征,不進行訓練model = TransNet(input_size=args.image_size).to(device) # 內容生成網絡,用于生成風格圖片,進行訓練if args.mode != 'train' and getattr(args, 'model_path'):if not os.path.exists(args.model_path):raise FileNotFoundError(f'{args.model_path}不存在!')model.load_state_dict(torch.load(args.model_path))elif args.mode == 'train' and getattr(args, 'pretrained_model_path') and os.path.exists(args.pretrained_model_path):if not os.path.exists(args.pretrained_model_path):raise FileNotFoundError(f'{args.pretrained_model_path}不存在!')model.load_state_dict(torch.load(args.pretrained_model_path))if args.mode == 'train':# 訓練模式# 使用大規模內容圖像數據訓練快速圖像風格遷移網絡,比如COCO2017數據集train(model, vgg, args.learning_rate, args.epochs, args.batch_size, args.style_weight, args.content_weight,style_layers,content_layers, device, transform, image_style, args.content_dataset, args.model_save_path,args.output_dir,save_interval=timedelta(seconds=args.save_interval))elif args.mode == 'image':# 使用訓練好的風格遷移模型演示批量處理圖片if not os.path.exists(args.output_images_dir):os.makedirs(args.output_images_dir)for filename in tqdm(os.listdir(args.input_images_dir), desc='Processing Images'):try:filepath = os.path.join(args.input_images_dir, filename)images_generated = process_images([Image.open(filepath)], transform, model, device)images_generated[0].save(os.path.join(args.output_images_dir, filename))except Exception as e:passelif args.mode == 'video':# 視頻處理模式process_video(args.video_input, args.video_output, transform, model, device,batch_size=args.batch_size)else:raise ValueError("未知的運行模式")
效果圖





![[特殊字符] 如何在比賽前調整到最佳狀態:科學與策略結合的優化指](http://pic.xiahunao.cn/[特殊字符] 如何在比賽前調整到最佳狀態:科學與策略結合的優化指)

)
book-management)
、LSH、K-means)










