note
- 當前的 MoE 架構就是一個用顯存換訓練時長/推理延遲的架構
- MoE 目前的架構基本集中在于將原先 GPT 每層的 FFN 復制多份作為 n 個 expert,并增加一個 router,用來計算每個 token 對應到哪個 FFN(一般采用每個 token 固定指派 n 個 expert 的方案),也就是類似 Mixtral 7x8B 的結構。
- 之后 deepspeed 和 qwen 都陸續采用了更細的 granularity,也就是在不改變參數數量的情況下,將單個 FFN 變窄,FFN 數量變多,以及采用了 shared expert+,也就是所有 token 都會共享一部分 FFN 的方案。
文章目錄
- note
- 一、相關綜述和MOE介紹
- 相關MOE大模型
- 二、MOE模型的重要模塊
- 基礎回顧
- 路由模塊
- 負載均衡
- 借助Switch Transformer簡化MoE
- 三、MOE原理
- 1. 現狀
- 2. 算法層面
- 3. 工程層面
- 四、Deepseek MoE代碼
- 五、視覺模型中的混合專家
- 六、MOE和dense模型的對比
- Mixtral 8x7B的活躍參數與稀疏參數
- 七、常見問題
- 第一個問題:MoE 為什么能夠實現在低成本下訓練更大的模型。
- 第二個問題:MoE 如何解決訓練穩定性問題?
- 第三個問題:MoE 如何解決 Fine-Tuning 過程中的過擬合問題?
- Reference
一、相關綜述和MOE介紹
Cai, W., Jiang, J., Wang, F., Tang, J., Kim, S., & Huang, J. (2024).
A Survey on Mixture of Experts.
arXiv preprint arXiv:2407.06204v2.
Retrieved from https://arxiv.org/abs/2407.06204
MoE基于Transformer架構,主要由兩部分組成:
- 稀疏 MoE 層:MoE層代替了傳統 Transformer 模型中的前饋網絡 (FFN) 層。MoE 層包含若干“專家”模型,每個專家本身是一個獨立的神經網絡。在實際應用中,這些專家通常是前饋網絡 (FFN),但它們也可以是更復雜的網絡結構。
- 門控網絡或路由: 這個部分用于決定哪些 token 被發送到哪個專家。例如,在上圖中,“More”這個 token 可能被發送到第二個專家,而“Parameters”這個 token 被發送到第一個專家。同時,一個 token 也可以被發送到多個專家。token 的路由方式是 MoE 使用中的一個關鍵點,因為路由器由學習的參數組成,并且與網絡的其他部分一同進行預訓練。
MoE 的一個顯著優勢是它們能夠在遠少于 Dense 模型所需的計算資源下進行有效的預訓練。這意味著在相同的計算預算條件下,您可以顯著擴大模型或數據集的規模。特別是在預訓練階段,與稠密模型相比,混合專家模型通常能夠更快地達到相同的質量水平。例如Google的Switch Transformer,模型大小是T5-XXL的15倍,在相同計算資源下,Switch Transformer模型在達到固定困惑度 PPL 時,比T5-XXL模型快4倍。
國內的團隊DeepSeek 開源了國內首個 MoE 大模型 DeepSeekMoE。DeepSeekMoE 2B可接近2B Dense,僅用了17.5%計算量。DeepSeekMoE 16B性能比肩 LLaMA2 7B 的同時,僅用了40%計算量。 DeepSeekMoE 145B 優于Google 的MoE大模型GShard,而且僅用 28.5%計算量即可匹配 67B Dense 模型的性能。
此外,MoE大模型的優點還有:
- 訓練速度更快,效果更好。
- 相同參數,推理成本低。
- 擴展能力強,允許模型在保持計算成本不變的情況下增加參數數量,這使得它能夠擴展到非常大的模型規模,如萬億參數模型。
- 多任務學習能力,MoE在多任務學習中具備很好的性能。
MoE結合大模型屬于老樹發新芽,MOE大模型的崛起是因為大模型的發展已經到了一個瓶頸期,包括大模型的“幻覺”問題、邏輯理解能力、數學推理能力等,想要解決這些問題就不得不繼續增加模型的復雜度。隨著應用場景的復雜化和細分化,垂直領域應用更加碎片化,想要一個模型既能回答通識問題,又能解決專業領域問題,尤其在多模態大模型的發展浪潮之下,每個數據集可能完全不同,有來自文本的數據、圖像的數據、語音的數據等,數據特征可能非常不同,MoE是一種性價比更高的選擇。
相關MOE大模型
MOE中文MOE模型匯總:
DeepSeekMoE-16B:https://sota.jiqizhixin.com/project/deepseek-moe
XVERSE-MoE-A4.2B:https://sota.jiqizhixin.com/project/xverse-moe
Qwen1.5-MoE-A2.7B:https://sota.jiqizhixin.com/project/qwen1-5
Qwen3系列模型
其他:Mixtral 8x7B模型(MoE)
[1] Mixtral 8x7B是一款改變游戲規則的AI模型
[2] https://arxiv.org/abs/2401.04088
[3] 被OpenAI、Mistral AI帶火的MoE是怎么回事?一文貫通專家混合架構部署
二、MOE模型的重要模塊
基礎回顧
稍微復習下decocde only LLM里在LN層歸一化后,一般會加上Feedforward Neural Network (FFNN)前饋網絡:

路由模塊
模型如何知道使用哪些專家呢:可以在專家層之前添加一個路由(也稱為門控網絡),它是專門訓練用來選擇針對特定詞元的專家。
路由:路由(或門控網絡)也是一個前饋神經網絡(FFNN),用于根據特定輸入選擇專家。它可以輸出概率,用于選擇最匹配的專家:

路由與專家(其中只有少數被選擇)共同構成MoE層:

負載均衡
我們希望在訓練和推理期間讓專家之間保持均等的重要性,這稱為負載均衡。這樣可以防止對同一專家的過度擬合。
對路由進行負載均衡的一種方式是借助"KeepTopK"(https://arxiv.org/pdf/1701.06538)直接擴展。通過引入可訓練的(高斯)噪聲,可以避免重復選擇相同的專家。

平衡專家利用率(Balancing Expert Utilization):
論文指出,門控網絡傾向于收玫到一種狀態,總是為相同的幾個專家產生大的權重。這種不平衡是自我強化的,因為受到青睞的專家訓練得更快,因此被門控網絡更多地選擇。這種不平衡可能導致訓練效率低下,因為某些專家可能從未被使用過。
為了解決這個問題,論文提出了一種軟約束方法。作者定義了專家相對于一批訓練樣本的重要性 Importance( X \boldsymbol{X} X ),就是該專家在這批樣本中門控值的總和。然后,他們定義了一個額外的損失函數 L importance? ( X ) L_{\text {importance }}(\boldsymbol{X}) Limportance??(X) ,這個損失函數被添加到模型的整體損失函數中。這個損失函數等于重要性值集合的CV(coefficient of variation)平方,乘以一個手動調整的縮放因子 w importance? w_{\text {importance }} wimportance?? 。這個額外的損失鼓勵所有專家具有相等的重要性,具體計算公式如下所示:
Importance? ( X ) = ∑ x ∈ X G ( x ) L importance? ( X ) = w importance? ? C V ( Importance? ( X ) ) 2 \begin{gathered} \text { Importance }(\boldsymbol{X})=\sum_{\boldsymbol{x} \in \boldsymbol{X}} G(\boldsymbol{x}) \\ L_{\text {importance }}(\boldsymbol{X})=w_{\text {importance }} \cdot C V(\text { Importance }(\boldsymbol{X}))^2 \end{gathered} ?Importance?(X)=x∈X∑?G(x)Limportance??(X)=wimportance???CV(?Importance?(X))2?
借助Switch Transformer簡化MoE
首批解決了基于Transformer的MoE(例如負載均衡等)訓練不穩定性問題的模型之一是Switch Transformer
三、MOE原理
1. 現狀
MoE 目前的架構基本集中在于將原先 GPT 每層的 FFN 復制多份作為 n 個 expert,并增加一個 router,用來計算每個 token 對應到哪個 FFN(一般采用每個 token 固定指派 n 個 expert 的方案),也就是類似 Mixtral 7x8B 的結構。
之后 deepspeed 和 qwen 都陸續采用了更細的 granularity,也就是在不改變參數數量的情況下,將單個 FFN 變窄,FFN 數量變多,以及采用了 shared expert+,也就是所有 token 都會共享一部分 FFN 的方案。這方面推薦閱讀 deepspeed 的這篇論文:《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》
論文:https://arxiv.org/abs/2401.06066
2. 算法層面
目前已有的開源模型普遍有這樣的一個特點,就是當使用相同的預訓練數據從零訓練時,一個參數量為 N 的 dense 模型與一個參數量在 2N,激活參數量在 0.4N 的 MoE 模型能力基本相仿。這里的能力主要指在常規 benchmark,如 MMLU、C-Eval 上的分數。這種對比在 Qwen-1.5-MoE-A2.7B 和 Qwen2-57B-A14B 中最為明顯。在一些小規模經驗中,也基本看到了這樣的結論。
https://huggingface.co/Qwen/Qwen1.5-MoE-A2.7B
https://huggingface.co/Qwen/Qwen2-57B-A14B
那么我們可以認為當前的 MoE 架構就是一個用顯存換訓練時長/推理延遲的架構。而對于非端側模型,這樣的 trade off 無疑是很值得的。所以我認為在算法層面上,對現階段有指導價值的工作是圍繞這個 trade off 的 Pareto 曲線,類似于如果我們可以對標一個 7B dense 模型,那么激活參數數多少的 MoE 需要多少參數,vice versa。這樣的指標對于 LLM 的實際應用會很有幫助。
3. 工程層面
主要是需要實現更高效的 MoE 訓練/推理基建。我對推理不太熟,主要說下訓練方向,我認為主要是分 2 個方向。
一塊是如何優化高稀疏度、高 granularity 的 grouped matmul kernel,讓 MoE 訓練的端到端速度逐步追趕同激活參數數的 dense 模型。這方面可能還是要看 cutlass 官方的一些進展,如這里:hopper_grouped_gemm。如果想自己上手的話,可以考慮類似 together.ai 的這篇博文:Supercharging NVIDIA H200 and H100 GPU Cluster Performance With Together Kernel Collection,
或者看 flash attention 3 的流水的方式來整體優化一下 FFN。這里完全對齊 dense 應該是很難的,畢竟存多了,但從經驗來看,如果稀疏度不是太離譜,估計做到 dense 端到端的 80%-90% 還是很常規的。
https://github.com/NVIDIA/cutlass/tree/main/examples/57_hopper_grouped_gemmhttps://www.together.ai/blog/nvidia-h200-and-h100-gpu-cluster-performance-together-kernel-collectionhttps://tridao.me/blog/2024/flash3/
四、Deepseek MoE代碼
一個demo例子:
- 定義expert類:由線性層和激活函數構成
- 定義MOE類:
- self.num_experts:專家的數量,也就是上面提到的“并列線性層”的個數,訓練后的每個專家的權重都是不同的,代表它們所掌握的“知識”是不同的。
- self.top_k:每個輸入token激活的專家數量。
- self.expert_capacity:代表計算每組token時,每個專家能被選擇的最多次數。
- self.gate:路由網絡,一般是一個線性層,用來計算每個專家被選擇的概率。
- self.experts:實例化Expert類,生成多個專家。
- 損失函數包含2部分:專家利用率均衡和樣本分配均衡。
import torch
import torch.nn as nn
import torch.nn.functional as F
# import torch_npu
# from torch_npu.contrib import transfer_to_npuclass Expert(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super().__init__()self.net = nn.Sequential(nn.Linear(input_dim, hidden_dim),nn.GELU(),nn.Linear(hidden_dim, output_dim))def forward(self, x):return self.net(x)class MoE(nn.Module):def __init__(self, input_dim, num_experts, top_k, expert_capacity, hidden_dim, output_dim):super().__init__()self.num_experts = num_expertsself.top_k = top_kself.expert_capacity = expert_capacity# 路由網絡self.gate = nn.Linear(input_dim, num_experts)# 專家集合self.experts = nn.ModuleList([Expert(input_dim, hidden_dim, output_dim) for _ in range(num_experts)])def forward(self, x):batch_size, input_dim = x.shapedevice = x.device# 路由計算logits = self.gate(x)probs = torch.softmax(logits, dim=-1)print("probs: ", probs)topk_probs, topk_indices = torch.topk(probs, self.top_k, dim=-1)print("topk_probs: ", topk_probs)print("topk_indices: ", topk_indices)# 輔助損失計算if self.training:# 重要性損失(專家利用率均衡):如果每個專家被選擇的概率相近,那么說明分配越均衡,損失函數越小importance = probs.sum(0)importance_loss = torch.var(importance) / (self.num_experts ** 2)# 負載均衡損失(樣本分配均衡)mask = torch.zeros_like(probs, dtype=torch.bool)mask.scatter_(1, topk_indices, True)routing_probs = probs * maskexpert_usage = mask.float().mean(0)routing_weights = routing_probs.mean(0)load_balance_loss = self.num_experts * (expert_usage * routing_weights).sum()aux_loss = importance_loss + load_balance_losselse:aux_loss = 0.0# 專家分配邏輯flat_indices = topk_indices.view(-1)flat_probs = topk_probs.view(-1)sample_indices = torch.arange(batch_size, device=device)[:, None]\.expand(-1, self.top_k).flatten()print("sample_indices: ", sample_indices)# 初始化輸出outputs = torch.zeros(batch_size, self.experts[0].net[-1].out_features, device=device)# 處理每個專家for expert_idx in range(self.num_experts):print("expert_idx: ", expert_idx)# 獲取分配給當前專家的樣本expert_mask = flat_indices == expert_idxprint("expert_mask: ", expert_mask)expert_samples = sample_indices[expert_mask]print("expert_samples: ", expert_samples)expert_weights = flat_probs[expert_mask]print("expert_weights: ", expert_weights)# 容量控制if len(expert_samples) > self.expert_capacity:expert_samples = expert_samples[:self.expert_capacity]expert_weights = expert_weights[:self.expert_capacity]if len(expert_samples) == 0:continue# 處理專家計算expert_input = x[expert_samples]print("expert_input: ", expert_input)expert_output = self.experts[expert_idx](expert_input)weighted_output = expert_output * expert_weights.unsqueeze(-1)# 累加輸出outputs.index_add_(0, expert_samples, weighted_output)return outputs, aux_loss# 測試示例
if __name__ == "__main__":input_dim = 5output_dim = 10num_experts = 8top_k = 3expert_capacity = 32hidden_dim = 512batch_size = 10# add# device = torch.device("npu:4" if torch.npu.is_available() else "cpu")device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")moe = MoE(input_dim, num_experts, top_k, expert_capacity, hidden_dim, output_dim).to(device)# x.shape: (batch_size, input_dim)x = torch.randn(batch_size, input_dim).to(device)moe.eval()output, _ = moe(x)print(f"Eval output shape: {output.shape}") # torch.Size([64, 256])
其他參考:
https://github.com/deepseek-ai/DeepSeek-MoE
通過對比不同配置下的Dense模型和MoE模型,我們清楚地看到了MoE架構在提升性能和優化計算資源方面的巨大潛力。MoE模型不僅在相同參數量下表現優異,更在激活參數減少的情況下依然保持了高效的訓練效果。特別是DeepSeek MoE模型,通過增加專家層數量和引入share expert的創新機制,大幅提升了計算效率和模型效果。DeepSeek MoE在使用更少激活參數的前提下,依然能夠達到與大型Dense模型相當的性能,展示了其在處理復雜任務中的獨特優勢。
參考:探索混合專家(MoE)模型預訓練:開源項目實操
五、視覺模型中的混合專家
圖片分patch切分,分別對應圖片token。

六、MOE和dense模型的對比
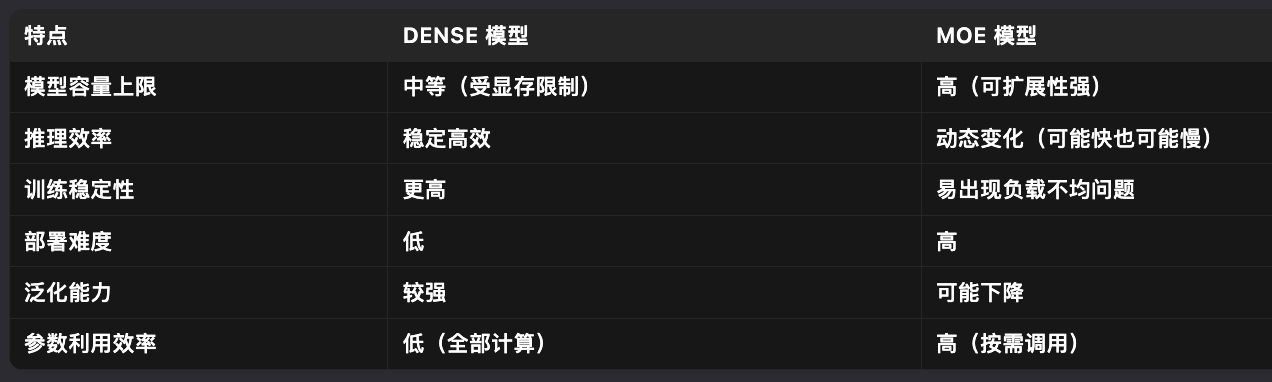
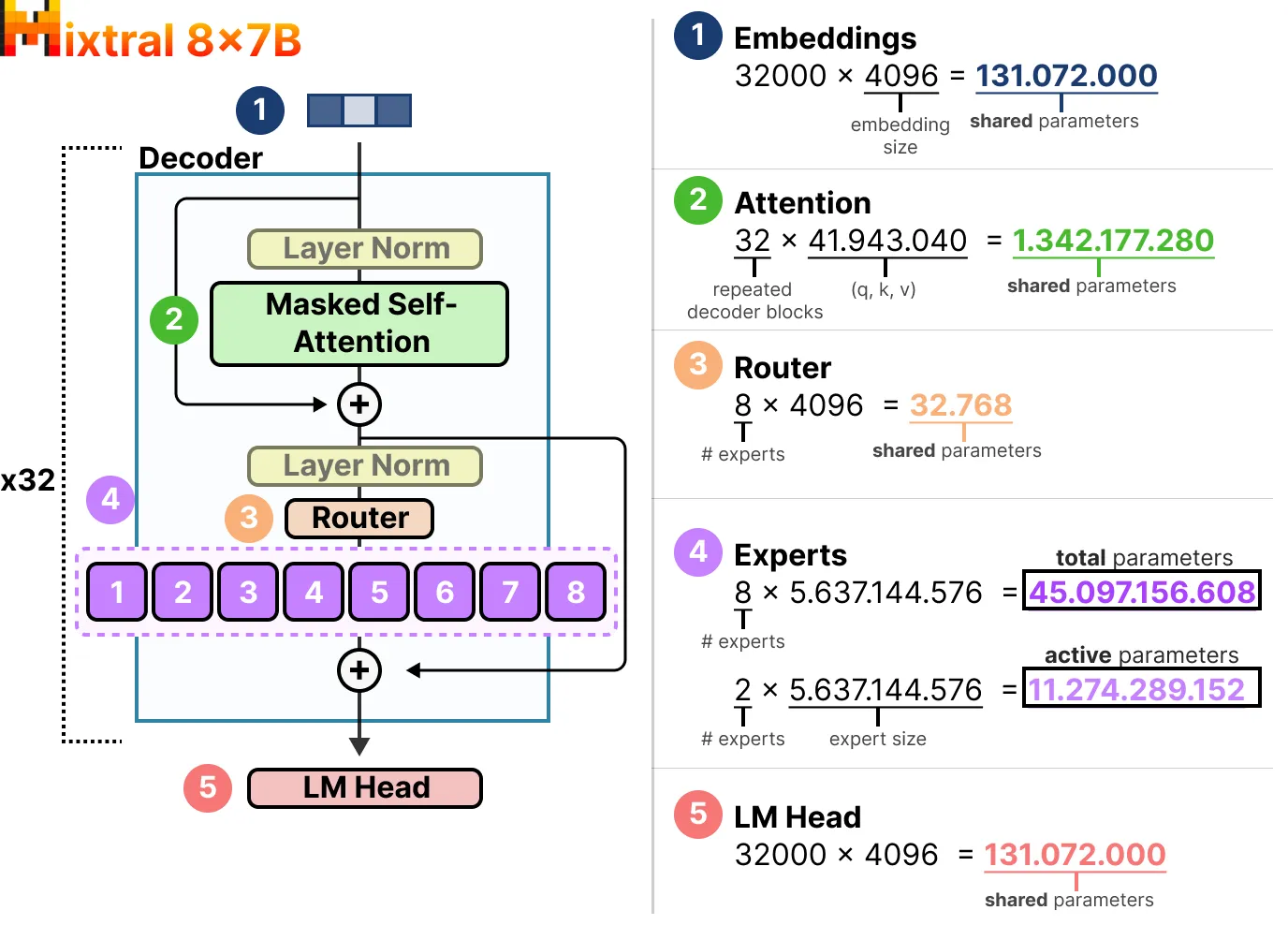
Mixtral 8x7B的活躍參數與稀疏參數
以Mixtral 8x7B來探討稀疏參數與活躍參數的數量:
七、常見問題
第一個問題:MoE 為什么能夠實現在低成本下訓練更大的模型。
這主要是因為稀疏路由的原因,每個 token 只會選擇 top-k 個專家進行計算。同時可以使用模型并行、專家并行和數據并行,優化 MoE 的訓練效率。而負載均衡損失可提升每個 device 的利用率。
第二個問題:MoE 如何解決訓練穩定性問題?
可以通過混合精度訓練、更小的參數初始化,以及 Router z-loss 提升訓練的穩定性。
第三個問題:MoE 如何解決 Fine-Tuning 過程中的過擬合問題?
可以通過更大的 dropout (主要針對 expert)、更大的學習率、更小的 batch size。目前看到的主要是預訓練的優化,針對 Fine-Tuning 的優化主要是一些常規的手段。
Reference
[1] Qwen1.5-MoE模型:2.7B的激活參數量達到7B模型的性能
[2] 開源MOE再添一員:通義團隊Qwen1.5 MOE A2.7B大模型
[3] https://qwenlm.github.io/blog/qwen-moe/
[4] AIR學術|微軟副總裁高劍峰:Brain-inspired Efficient AI Modeling
[5] 某乎:朱小霖:https://www.zhihu.com/question/664040671/answer/3655141787
[6] MoE模型的前世今生
[7] Cai, W., Jiang, J., Wang, F., Tang, J., Kim, S., & Huang, J. (2024). A Survey on Mixture of Experts. arXiv preprint arXiv:2407.06204v2. Retrieved from https://arxiv.org/abs/2407.06204
[8] 圖解MOE:https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts
[9] 群魔亂舞:MoE大模型詳解
其他中文reference:
快速了解MOE架構!多專家大模型如何實現效果最佳
【論文】混合專家模型(MoE)綜述
專題解讀 | 混合專家模型在大模型微調領域進展.北郵
為什么最新的LLM采用 MoE(混合專家)架構?
探索混合專家(MoE)模型預訓練:開源項目實操
從ACL 2024錄用論文看混合專家模型(MoE)最新研究進展
50張圖,直觀理解混合專家(MoE)大模型
大模型:混合專家模型(MoE)概述
稀疏大模型一覽:從MoE、Sparse Attention到GLaM
DeepSeek模型MOE結構代碼詳解
其他英文reference:
[1] Zoph, Barret, et al. “St-moe: Designing stable and transferable sparse expert models. arXiv 2022.” arXiv preprint arXiv:2202.08906.
[2] Shazeer, Noam, et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.” arXiv preprint arXiv:1701.06538 (2017).
[3] Shazeer, Noam, et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.” arXiv preprint arXiv:1701.06538 (2017).
[4] Lepikhin, Dmitry, et al. “Gshard: Scaling giant models with conditional computation and automatic sharding.” arXiv preprint arXiv:2006.16668 (2020).
[5] Fedus, William, Barret Zoph, and Noam Shazeer. “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.” Journal of Machine Learning Research 23.120 (2022): 1-39.
[6] Dosovitskiy, Alexey. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[7] Riquelme, Carlos, et al. “Scaling vision with sparse mixture of experts.” Advances in Neural Information Processing Systems 34 (2021): 8583-8595.
[8] Puigcerver, Joan, et al. “From sparse to soft mixtures of experts.” arXiv preprint arXiv:2308.00951 (2023).
[9] Jiang, Albert Q., et al. “Mixtral of experts.” arXiv preprint arXiv:2401.04088 (2024).
)
:概述)






)

Transformers without Normalization)
)







