Transformers without Normalization
- 文章概括
- Abstract
- 1 引言
- 2 背景:歸一化層
- 3 歸一化層做什么?
- 4 動態 Tanh (Dynamic Tanh (DyT))
- 5 實驗
- 6 分析
- 7 α 的初始化
- 8 相關工作
- 9 限制
- 10 結論
- 附錄
- 附錄 A 實驗設置
- 附錄 B 超參數
- 附錄 C 用 DyT 替換批量歸一化
文章概括
引用:
@article{zhu2025transformers,title={Transformers without normalization},author={Zhu, Jiachen and Chen, Xinlei and He, Kaiming and LeCun, Yann and Liu, Zhuang},journal={arXiv preprint arXiv:2503.10622},year={2025}
}
Zhu, J., Chen, X., He, K., LeCun, Y. and Liu, Z., 2025. Transformers without normalization. arXiv preprint arXiv:2503.10622.
主頁:https://jiachenzhu.github.io/DyT/
原文: https://arxiv.org/abs/2503.10622
代碼、數據和視頻:
系列文章:
請在 《 《 《文章 》 》 》 專欄中查找
宇宙聲明!
引用解析部分屬于自我理解補充,如有錯誤可以評論討論然后改正!
Abstract
歸一化層在現代神經網絡中無處不在,并且長期以來被認為是必不可少的。本工作表明,通過一種非常簡單的技術,不使用歸一化的Transformer也能達到相同或更好的性能。我們提出了動態Tanh (Dynamic Tanh——DyT),一種逐元素操作 DyT ( x ) = tanh ? ( α x ) \text{DyT}(x)=\tanh(\alpha x) DyT(x)=tanh(αx),可作為Transformer中歸一化層的直接替代。 DyT \text{DyT} DyT的靈感來源于觀察到Transformer中的層歸一化通常會產生類似tanh的“S型”輸入輸出映射。通過引入 DyT \text{DyT} DyT,不使用歸一化的Transformer在大多數情況下無需調整超參數即可匹配或超越其歸一化版本的性能。我們在多種場景下驗證了采用 DyT \text{DyT} DyT的Transformer的有效性,涵蓋了從識別到生成、從監督學習到自監督學習,以及從計算機視覺到語言模型等多種任務。這些發現挑戰了歸一化層在現代神經網絡中不可或缺的傳統認知,并為其在深度網絡中的作用提供了新的見解。
1 引言
在過去的十年中,歸一化層已鞏固了它們作為現代神經網絡中最基礎組件之一的地位。這一切都源自2015年批歸一化(Batch Normalization)的發明(Ioffe 和 Szegedy,2015),它使視覺識別模型的收斂速度大幅加快且性能顯著提升,并在隨后的幾年中迅速流行起來。自那以后,為不同網絡架構或領域提出了許多歸一化層的變體(Ba 等,2016;Ulyanov 等,2016;Wu 和 He,2018;Zhang 和 Sennrich,2019)。如今,幾乎所有現代網絡都使用歸一化層,其中層歸一化(Layer Norm,或 LN)(Ba 等,2016)是最流行的一種,尤其是在主導性的 Transformer 架構中(Vaswani 等,2017;Dosovitskiy 等,2020)。
歸一化層的廣泛采用在很大程度上源于它們在優化中的經驗性優勢(Santurkar 等,2018;Bjorck 等,2018)。除了能獲得更好的效果之外,它們還能加速并穩定收斂過程。隨著神經網絡變得更寬更深,這一需求也變得愈發關鍵(Brock 等,2021a;Huang 等,2023)。因此,歸一化層被普遍認為是深度網絡有效訓練的關鍵,甚至是必不可少的。這一觀點的一個微妙體現是,近年來的新穎架構常常試圖用新的模塊取代注意力或卷積層(Tolstikhin 等,2021;Gu 和 Dao,2023;Sun 等,2024;Feng 等,2024),但幾乎總是保留歸一化層。
本文通過引入一種簡單的 Transformer 歸一化層替代方案,對這一觀點提出挑戰。我們的研究始于這樣一個觀察:層歸一化(LN)會將輸入 映射為類似 tanh 的 S 型曲線,對輸入激活進行縮放,同時壓縮極端值。受到這一啟發,我們提出了一種稱為動態Tanh (Dynamic Tanh——DyT) 的逐元素操作,定義為: DyT ( x ) = tanh ? ( α x ) \text{DyT}(x)=\tanh(\alpha x) DyT(x)=tanh(αx),其中α是可學習參數。該操作旨在通過學習合適的縮放因子α并利用有界的tanh函數壓縮極端值,以模擬LN的行為。值得注意的是,與歸一化層不同, DyT \text{DyT} DyT 無需計算激活統計量即可實現上述兩種效果。
如圖1所示,使用DyT非常簡單:我們直接在視覺和語言Transformer等架構中將現有的歸一化層替換為DyT。我們通過實驗證明,采用DyT的模型能夠在多種設置下穩定訓練并取得較高的最終性能。它通常無需對原始架構的訓練超參數進行調整。我們的工作挑戰了歸一化層在現代神經網絡訓練中不可或缺的觀點,并為歸一化層的屬性提供了實證見解。此外,初步測量表明DyT能夠提高訓練和推理速度,使其成為面向高效性網絡設計的候選方案。
 圖1 左:原始 Transformer 塊。右:包含我們提出的動態 Tanh(DyT)層的塊。DyT 是對常用的層歸一化(Layer Norm)(Ba 等,2016)(在某些情況下為 RMSNorm(Zhang 和 Sennrich,2019))層的直接替換。采用 DyT 的 Transformer 在性能上能夠匹配或超過其歸一化版本。
圖1 左:原始 Transformer 塊。右:包含我們提出的動態 Tanh(DyT)層的塊。DyT 是對常用的層歸一化(Layer Norm)(Ba 等,2016)(在某些情況下為 RMSNorm(Zhang 和 Sennrich,2019))層的直接替換。采用 DyT 的 Transformer 在性能上能夠匹配或超過其歸一化版本。
2 背景:歸一化層
我們首先回顧歸一化層。大多數歸一化層共享一個通用的公式。給定一個形狀為 ( B , T , C ) (B,T,C) (B,T,C)的輸入 x x x,其中 B B B是批量大小, T T T是token數, C C C是每個token的嵌入維度,輸出通常計算為:
normalization ( x ) = γ ? ( x ? μ σ 2 + ? ) + β ( 1 ) \text{normalization}(x)=\gamma*\big(\frac{x-\mu}{\sqrt{\sigma^2+\epsilon}}\big)+\beta \quad (1) normalization(x)=γ?(σ2+??x?μ?)+β(1)
其中 ? \epsilon ?是一個小常數, γ \gamma γ和 β \beta β是形狀為 ( C , ) (C,) (C,)的可學習向量參數。它們是“縮放”和“平移”仿射參數,允許輸出落在任意范圍內。術語 μ \mu μ和 σ 2 \sigma^2 σ2分別表示輸入的均值和方差。不同方法主要區別在于這兩個統計量的計算方式不同。這導致 μ \mu μ和 σ 2 \sigma^2 σ2具有不同的維度,并在計算過程中應用廣播。
批量歸一化(Batch Normalization,BN)(Ioffe 和 Szegedy,2015)是第一個現代歸一化層,主要用于ConvNet模型(Szegedy 等,2016;He 等,2016;Xie 等,2017)。它的引入代表了深度學習架構設計的一個重要里程碑。BN在批量和token維度上同時計算均值和方差,具體為: μ k = 1 B T ∑ i , j x i j k \mu_k=\frac{1}{BT}\sum_{i,j}x_{ijk} μk?=BT1?∑i,j?xijk? 和 σ k 2 = 1 B T ∑ i , j ( x i j k ? μ k ) 2 \sigma_k^2=\frac{1}{BT}\sum_{i,j}(x_{ijk}-\mu_k)^2 σk2?=BT1?∑i,j?(xijk??μk?)2。 在ConvNet中流行的其他歸一化層,比如組歸一化(Group Normalization)(Wu 和 He,2018)和實例歸一化(Instance Normalization)(Ulyanov 等,2016),最初是為目標檢測和圖像風格化等專用任務提出的。它們具有相同的總體公式,但統計量的計算軸和范圍不同。
層歸一化(Layer Normalization,LN)(Ba 等,2016)和均方根歸一化(RMSNorm)(Zhang 和 Sennrich,2019)是Transformer架構中使用的兩類主要歸一化層。LN對每個樣本中每個token獨立計算這些統計量,其中 μ i j = 1 C ∑ k x i j k \mu_{ij}=\frac{1}{C}\sum_{k}x_{ijk} μij?=C1?∑k?xijk? 且 σ i j 2 = 1 C ∑ k ( x i j k ? μ i j ) 2 \sigma_{ij}^2=\frac{1}{C}\sum_{k}(x_{ijk}-\mu_{ij})^2 σij2?=C1?∑k?(xijk??μij?)2。RMSNorm(Zhang 和 Sennrich,2019)通過刪除去中心化步驟簡化了LN,并將輸入歸一化為 μ i j = 0 \mu_{ij}=0 μij?=0 且 σ i j 2 = 1 C ∑ k x i j k 2 \sigma_{ij}^2=\frac{1}{C}\sum_{k}x_{ijk}^2 σij2?=C1?∑k?xijk2?。 如今,大多數現代神經網絡因其簡單性和通用性而使用LN。 最近,RMSNorm在語言模型中越來越受歡迎,尤其是在T5(Raffel 等,2020)、LLaMA(Touvron 等,2023a,b;Dubey 等,2024)、Mistral(Jiang 等,2023)、Qwen(Bai 等,2023;Yang 等,2024)、InternLM(Zhang 等,2024;Cai 等,2024)和DeepSeek(Liu 等,2024;Guo 等,2025)等模型中。我們在本文中研究的Transformer均使用LN,唯一例外是LLaMA使用RMSNorm。
3 歸一化層做什么?
分析設置。
我們首先在已訓練網絡中對歸一化層的行為進行實證研究。為此分析,我們選用一個在 ImageNet-1K (Deng 等, 2009) 上訓練的 Vision Transformer 模型 (ViT-B) (Dosovitskiy 等, 2020)、一個在 LibriSpeech (Panayotov 等, 2015) 上訓練的 wav2vec 2.0 大型 Transformer 模型 (Baevski 等, 2020),以及一個在 ImageNet-1K 上訓練的 Diffusion Transformer (DiT-XL) (Peebles 和 Xie, 2023)。在所有情況下,層歸一化(LN)都應用于每個 Transformer 塊及最終線性投影之前。對于這三個已訓練網絡,我們對一個小批量樣本進行前向傳播。然后,我們測量歸一化層的輸入和輸出,即在可學習仿射變換之前、歸一化操作前后緊接的張量。因為 LN 保持輸入張量的維度不變,我們可以在輸入和輸出張量元素之間建立一一對應,從而可以直接可視化它們的關系。我們將所得映射繪制在圖2中。
 圖2:Vision Transformer(ViT)(Dosovitskiy 等,2020)、wav2vec 2.0(用于語音的 Transformer 模型)(Baevski 等,2020)和 Diffusion Transformer(DiT)(Peebles 和 Xie,2023)中選定層歸一化(LN)層的輸出與輸入關系。我們采樣一個小批量樣本,并繪制每個模型中四個 LN 層的輸入/輸出值。這些輸出是在 LN 的仿射變換之前的值。S 型曲線與 tanh ? \tanh tanh函數的形狀高度相似(見圖 3)。在較早的層中,更線性的形狀也可以用 tanh ? \tanh tanh曲線的中心部分來刻畫。這激發了我們提出動態 Tanh(DyT)作為替代,其帶有可學習的縮放因子 α α α以適應 x 軸上不同的尺度。
圖2:Vision Transformer(ViT)(Dosovitskiy 等,2020)、wav2vec 2.0(用于語音的 Transformer 模型)(Baevski 等,2020)和 Diffusion Transformer(DiT)(Peebles 和 Xie,2023)中選定層歸一化(LN)層的輸出與輸入關系。我們采樣一個小批量樣本,并繪制每個模型中四個 LN 層的輸入/輸出值。這些輸出是在 LN 的仿射變換之前的值。S 型曲線與 tanh ? \tanh tanh函數的形狀高度相似(見圖 3)。在較早的層中,更線性的形狀也可以用 tanh ? \tanh tanh曲線的中心部分來刻畫。這激發了我們提出動態 Tanh(DyT)作為替代,其帶有可學習的縮放因子 α α α以適應 x 軸上不同的尺度。
具有層歸一化的類似 tanh 的映射。
對于這三種模型,在較早的 LN 層(圖 2 的第一列)中,我們發現這種輸入—輸出關系大多是線性的,類似于 x-y 圖中的一條直線。然而,在更深的 LN 層中,我們觀察到了更有趣的現象。
在這些更深層中,一個顯著的觀察是,大多數曲線的形狀與由 tanh ? \tanh tanh 函數表示的完整或部分 S 型曲線高度相似(見圖 3)。
 圖 3:具有三個不同 α α α 值的 tanh ? ( α x ) \tanh(αx) tanh(αx) 曲線。
圖 3:具有三個不同 α α α 值的 tanh ? ( α x ) \tanh(αx) tanh(αx) 曲線。
人們可能會認為 LN 層會線性地變換輸入張量,因為減去均值和除以標準差都是線性操作。LN 以逐 token 的方式進行歸一化,僅線性地變換每個 token 的激活值。由于不同 token 的均值和標準差各不相同,這種線性特性不再整體適用于輸入張量的所有激活值。盡管如此,實際上這種非線性變換與縮放后的 tanh ? \tanh tanh 函數高度相似,這仍令我們感到驚訝。
對于這樣的 S 型曲線,我們注意到其中心部分(即 x x x 值接近零的點)仍主要呈現線性形狀。大多數點(約 99%)都落在該線性區間內。然而,仍有許多點明顯超出該范圍,被視為“極端”值,例如在 ViT 模型中 x x x 大于 50 或小于 ?50 的點。對于這些極端值,歸一化層的主要作用是將它們壓縮為更不極端的值,使其與大多數點更加一致。這里正是歸一化層無法被簡單的仿射變換層所逼近的原因。我們假設,歸一化層對極端值的這種非線性且不成比例的壓縮效果,正是它們重要且不可或缺的原因。
Vision Transformer(ViT)是一種將 Transformer 架構直接應用于計算機視覺任務的模型架構
Ni 等(2024)的最新研究也同樣強調了 LN 層引入的強非線性,展示了這種非線性如何增強模型的表征能力。此外,這種壓縮行為與生物神經元在大輸入下的飽和特性相似,該現象最早于約一個世紀前被觀測到(Adrian, 1926;Adrian 和 Zotterman, 1926a,b)。
按 token 和通道進行歸一化。
LN 層如何對每個 token 執行線性變換,同時又以如此非線性方式壓縮極端值?為了解其原理,我們分別對按 token 和通道分組的點進行可視化。此操作如圖 4 所示,選取圖 2 中 ViT 的第二和第三子圖,并對點集進行抽樣以提高清晰度。在選擇要繪制的通道時,我們確保包含具有極端值的通道。
在圖 4 的左兩幅圖中,我們使用相同顏色可視化每個 token 的激活值。我們觀察到,任何單個 token 的所有點確實形成了一條直線。然而,由于每個 token 的方差不同,直線的斜率也各不相同。 x x x 范圍較小的 token 往往具有較小的方差,歸一化層會用較小的標準差除以它們的激活值,因此在線性直線中生成更大的斜率。整體來看,這些直線共同構成了一個類似 tanh ? \tanh tanh 函數的 S 型曲線。
在右兩幅圖中,我們使用相同顏色為每個通道的激活值著色。我們發現,不同通道的輸入范圍往往差異巨大,只有少數通道(如紅色、綠色和粉色)表現出較大的極端值。這些通道是被歸一化層壓縮最嚴重的通道。

圖 4:兩個 LN 層的輸出與輸入關系,張量元素按不同的通道和 token 維度著色。輸入張量的形狀為(樣本數, token 數, 通道數),通過對相同 token(左兩幅圖)和相同通道(右兩幅圖)賦予一致的顏色來可視化元素。左兩幅圖:表示相同 token(相同顏色)的點在不同通道上形成直線,因為 LN 對每個 token 在通道維度上進行線性操作。有趣的是,當這些直線一起繪制時,它們形成了非線性的 tanh 形曲線。右兩幅圖:每個通道的輸入在 x 軸上跨度不同,為整體 tanh 形曲線貢獻了不同的片段。某些通道(例如紅色、綠色和粉色)的 x 值更為極端,這些極端值會被 LN 壓縮。
4 動態 Tanh (Dynamic Tanh (DyT))
受到歸一化層形狀與縮放 tanh 函數相似性的啟發,我們提出了動態 Tanh(DyT)作為歸一化層的直接替代。給定輸入張量 x x x, DyT \text{DyT} DyT 層定義如下:
DyT ( x ) = γ ? tanh ? ( α x ) + β ( 2 ) \text{DyT}(x)=\gamma*\tanh(\alpha x)+\beta \quad (2) DyT(x)=γ?tanh(αx)+β(2)
其中 α \alpha α 是可學習的標量參數,可根據輸入范圍對 x x x 進行不同程度的縮放,以適應不同的 x x x 取值尺度(見圖 2)。這也是我們稱之為“動態” Tanh 的原因。 γ \gamma γ和 β \beta β是可學習的按通道向量參數,與所有歸一化層中使用的參數相同——它們允許輸出重新縮放到任意尺度。有時它們被視為單獨的仿射層;但在本研究中,我們將它們視為 DyT \text{DyT} DyT 層的一部分,正如歸一化層也包含它們一樣。有關 DyT \text{DyT} DyT 在類 PyTorch 偽代碼中的實現,請參見算法 1。

圖2:Vision Transformer(ViT)(Dosovitskiy 等,2020)、wav2vec 2.0(用于語音的 Transformer 模型)(Baevski 等,2020)和 Diffusion Transformer(DiT)(Peebles 和 Xie,2023)中選定層歸一化(LN)層的輸出與輸入關系。我們采樣一個小批量樣本,并繪制每個模型中四個 LN 層的輸入/輸出值。這些輸出是在 LN 的仿射變換之前的值。S 型曲線與 tanh ? \tanh tanh函數的形狀高度相似(見圖 3)。在較早的層中,更線性的形狀也可以用 tanh ? \tanh tanh曲線的中心部分來刻畫。這激發了我們提出動態 Tanh(DyT)作為替代,其帶有可學習的縮放因子 α α α以適應 x 軸上不同的尺度。
將 DyT \text{DyT} DyT 層集成到現有架構中非常簡單:用一個 DyT \text{DyT} DyT 層替換一個歸一化層(見圖 1)。這適用于注意力模塊、前饋網絡(FFN)模塊以及最終的歸一化層中的歸一化操作。盡管 DyT \text{DyT} DyT 看起來或可被認為是一種激活函數,但本研究僅將其用于替換歸一化層,而不修改原始架構中的任何激活函數部分(如 GELU 或 ReLU)。網絡的其他部分保持不變。我們還觀察到,DyT 在大多數情況下無需調整原始架構的超參數即可達到良好性能。
關于縮放參數。
我們遵循歸一化層的初始化慣例,將 γ \gamma γ初始化為全 1 向量,將 β \beta β初始化為全 0 向量。對于縮放參數 α \alpha α,默認將其初始化為 0.5 通常足夠,除非在大型語言模型(LLM)訓練中有特殊需求。有關 α \alpha α初始化的詳細分析,請參見第 7 節。除非另有說明,在后續實驗中我們均將 α \alpha α初始化為 0.5。
備注。
DyT \text{DyT} DyT 并不是一種新的歸一化層,因為它在前向傳遞中對張量的每個輸入元素獨立操作,不計算統計量或其他類型的聚合。然而,它保留了歸一化層以非線性方式壓縮極端值的效果,同時對輸入的中心部分幾乎呈線性變換。
5 實驗
為了驗證 DyT \text{DyT} DyT 的有效性,我們在多種任務和領域中對 Transformers 以及其他幾種現代架構進行了實驗。在每個實驗中,我們將原始架構中的 LN 或 RMSNorm 替換為 DyT \text{DyT} DyT 層,并按照官方開源協議對兩種模型版本進行訓練和測試。在附錄 A 中提供了復現我們結果的詳細說明。值得注意的是,為了突顯 DyT \text{DyT} DyT 的適配簡易性,我們使用與歸一化版本完全相同的超參數。為了完整性,還在附錄 B 中提供了有關學習率調整和 α α α 初始值設置的附加實驗結果。
視覺領域中的監督學習
我們在 ImageNet-1K 分類任務(Deng 等,2009)上訓練了“Base”和“Large”兩種規模的 Vision Transformer(ViT)(Dosovitskiy 等,2020)和 ConvNeXt(Liu 等,2022)。之所以選擇這些模型,是因為它們的受歡迎程度及其不同的操作方式:ViT 中的注意力機制與 ConvNeXt 中的卷積操作。表 1 報告了 top-1 分類準確率。在兩種架構和不同規模模型中, DyT \text{DyT} DyT 的表現均略優于 LN。我們在圖 5 中進一步繪制了 ViT-B 和 ConvNeXt-B 的訓練損失曲線。曲線表明, DyT \text{DyT} DyT 與基于 LN 的模型在收斂行為上高度一致。
 圖 5 ViT-B 和 ConvNeXt-B 模型的訓練損失曲線。兩種模型在 LN 和 DyT \text{DyT} DyT 之間的損失曲線模式相似,這表明 LN 和 DyT \text{DyT} DyT 可能具有相似的學習動態。
圖 5 ViT-B 和 ConvNeXt-B 模型的訓練損失曲線。兩種模型在 LN 和 DyT \text{DyT} DyT 之間的損失曲線模式相似,這表明 LN 和 DyT \text{DyT} DyT 可能具有相似的學習動態。
 表 1 ImageNet-1K 上的監督分類準確率。在兩種架構和各模型規模中, DyT \text{DyT} DyT 的性能均優于或與 LN 相當。
表 1 ImageNet-1K 上的監督分類準確率。在兩種架構和各模型規模中, DyT \text{DyT} DyT 的性能均優于或與 LN 相當。
視覺領域的自監督學習
我們采用兩種流行的視覺自監督學習方法進行基準測試:掩碼自編碼器(MAE)(He 等,2022)和 DINO(Caron 等,2021)。兩者默認使用 Vision Transformers 作為骨干網絡,但訓練目標不同:MAE 使用重建損失進行訓練,DINO 使用聯合嵌入損失(LeCun,2022)。按照標準的自監督學習協議,我們首先在 ImageNet-1K 上對模型進行預訓練,不使用任何標簽;然后通過附加分類層并使用標簽對預訓練模型進行微調來進行測試。微調結果如表 2 所示。在自監督學習任務中, DyT \text{DyT} DyT 始終與 LN 表現相當。
 表 2 自監督學習在 ImageNet-1K 上的準確率。在不同預訓練方法和模型規模的自監督學習任務中, DyT \text{DyT} DyT 與 LN 的表現相當。
表 2 自監督學習在 ImageNet-1K 上的準確率。在不同預訓練方法和模型規模的自監督學習任務中, DyT \text{DyT} DyT 與 LN 的表現相當。
擴散模型。
我們在 ImageNet-1K(Deng 等,2009)上訓練了三種大小分別為 B、L 和 XL 的 Diffusion Transformer(DiT)模型(Peebles 和 Xie,2023)。它們的 patch 大小分別為 4、4 和 2。需要注意的是,在 DiT 中,LN 層的仿射參數被用于類別條件,我們在 DyT \text{DyT} DyT 實驗中繼續保留這一用法,僅將歸一化變換替換為 tanh ? ( α x ) \tanh(\alpha x) tanh(αx)函數。訓練完成后,我們使用標準的 ImageNet “參考批次”評估 Fréchet Inception Distance(FID)分數,如表 3 所示。 DyT \text{DyT} DyT 在 FID 分數上與 LN 相當或有所提升。
 表 3 ImageNet 上的圖像生成質量(FID,數值越低越好)。在各種 DiT 模型規模中, DyT \text{DyT} DyT 在 FID 分數上與 LN 相當或更優。
表 3 ImageNet 上的圖像生成質量(FID,數值越低越好)。在各種 DiT 模型規模中, DyT \text{DyT} DyT 在 FID 分數上與 LN 相當或更優。
大型語言模型。
我們預訓練了 LLaMA 7B、13B、34B 和 70B 模型(Touvron 等,2023a,b;Dubey 等,2024),以評估 DyT \text{DyT} DyT 相對于 LLaMA 中默認歸一化層 RMSNorm(Zhang 和 Sennrich,2019)的性能。這些模型在 The Pile 數據集(Gao 等,2020)上使用 2000 億 token 進行訓練,遵循 LLaMA(Touvron 等,2023b)中概述的原始流程。在 DyT \text{DyT} DyT 版 LLaMA 中,我們在初始嵌入層之后添加了一個可學習的標量參數,并根據第 7 節的詳細描述調整了 α α α 的初始值。我們報告了訓練結束后的 loss 值,并按照 OpenLLaMA(Geng 和 Liu,2023)的做法,在 lm-eval(Gao 等)提供的 15 個零樣本任務上對模型進行了基準測試。如表 4 所示,在所有四種模型規模上, DyT \text{DyT} DyT 的表現都與 RMSNorm 相當。圖 6 展示了 loss 曲線,表明在整個訓練過程中,所有模型規模的訓練損失都緊密對齊,并顯示出相似的趨勢。
 表 4 語言模型的訓練損失及在 15 個零樣本 lm-eval 任務上的平均表現。 DyT \text{DyT} DyT 在零樣本表現和訓練損失方面與 RMSNorm 相當。
表 4 語言模型的訓練損失及在 15 個零樣本 lm-eval 任務上的平均表現。 DyT \text{DyT} DyT 在零樣本表現和訓練損失方面與 RMSNorm 相當。
語音領域的自監督學習
我們在 LibriSpeech 數據集(Panayotov 等,2015)上預訓練了兩種 wav2vec 2.0 Transformer 模型(Baevski 等,2020)。我們在表 5 中報告了最終的驗證損失。
我們觀察到,在兩種模型規模上, DyT \text{DyT} DyT 的表現與 LN 相當。
 表 5 LibriSpeech 上語音預訓練的驗證損失。在兩種 wav2vec 2.0 模型中, DyT \text{DyT} DyT 的表現與 LN 相當。
表 5 LibriSpeech 上語音預訓練的驗證損失。在兩種 wav2vec 2.0 模型中, DyT \text{DyT} DyT 的表現與 LN 相當。
DNA 序列建模
在長程 DNA 序列建模任務中,我們分別預訓練了 HyenaDNA 模型(Nguyen 等,2024)和 Caduceus 模型(Schiff 等,2024)。預訓練使用了人類參考基因組數據(GRCh38,2013),評估則在 GenomicBenchmarks(Gre?ová 等,2023)上進行。結果列于表 6。在該任務中, DyT \text{DyT} DyT 的表現與 LN 相當。
 表 6 GenomicBenchmarks 上的 DNA 分類準確率,取各數據集的平均值。 DyT \text{DyT} DyT 的表現與 LN 相當。
表 6 GenomicBenchmarks 上的 DNA 分類準確率,取各數據集的平均值。 DyT \text{DyT} DyT 的表現與 LN 相當。
6 分析
我們對 DyT \text{DyT} DyT 的若干重要屬性進行了分析。我們首先評估其計算效率,接著進行兩項研究,考察 tanh \text{tanh} tanh 函數和可學習縮放因子 α α α的作用。最后,我們將其與以往旨在移除歸一化層的方法進行比較。
6.1 DyT \text{DyT} DyT 的效率
我們以 LLaMA 7B 模型為基準,比較其使用 RMSNorm 或 DyT \text{DyT} DyT 時的性能——通過測量在單條 4096 token 序列上進行 100 次前向推理(inference)和 100 次前向-反向傳遞(training)所需的總時間。表 7 列出了在 Nvidia H100 GPU(BF16 精度)上運行時,僅 RMSNorm 或 DyT 層與整個模型所需的時間。與 RMSNorm 層相比, DyT \text{DyT} DyT 層顯著減少了計算時間,在 FP32 精度下也表現出類似趨勢。 DyT \text{DyT} DyT 可能是面向高效網絡設計的有力候選方案。
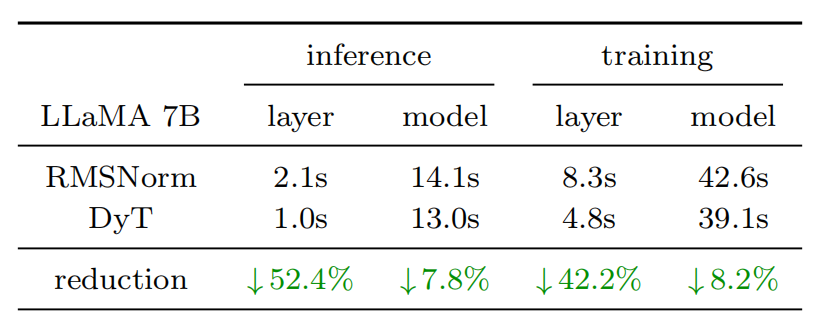
表 7 在 Nvidia H100 GPU(BF16 精度)上,RMSNorm/DyT 層及整個 LLaMA 7B 模型在 100×前向和 100×前向-反向傳遞上的耗時(單位:毫秒)。
6.2 tanh \text{tanh} tanh 和 α α α 的消融實驗
為了進一步研究 tanh \text{tanh} tanh 和 α α α 在 DyT \text{DyT} DyT 中的作用,我們進行了實驗,評估在更改或移除這些組件時模型性能。
替換和移除 tanh \text{tanh} tanh。
我們在 DyT \text{DyT} DyT 層中用其他壓縮函數(具體為 hardtanh 和 sigmoid,見圖 7)替換 tanh \text{tanh} tanh,同時保留可學習縮放因子 α α α。此外,我們還評估了完全移除 tanh \text{tanh} tanh 的情況,即將其替換為恒等函數(identity function),但仍保留 α α α。如表 8 所示,壓縮函數對于穩定訓練至關重要。使用恒等函數會導致訓練不穩定并最終發散,而使用任何壓縮函數都能實現穩定訓練。在三種壓縮函數中, tanh \text{tanh} tanh 的表現最佳,這可能歸因于其平滑性和以零為中心的特性。
 圖7 三種壓縮函數的曲線: tanh \text{tanh} tanh 、 hardtanh \text{hardtanh} hardtanh 和 sigmoid \text{sigmoid} sigmoid。所有三種函數都將輸入壓縮到有界范圍,但當在 DyT \text{DyT} DyT 層中使用時, tanh ( x ) \text{tanh}(x) tanh(x) 實現了最佳性能。我們懷疑這是由于它的平滑性和零均值特性。
圖7 三種壓縮函數的曲線: tanh \text{tanh} tanh 、 hardtanh \text{hardtanh} hardtanh 和 sigmoid \text{sigmoid} sigmoid。所有三種函數都將輸入壓縮到有界范圍,但當在 DyT \text{DyT} DyT 層中使用時, tanh ( x ) \text{tanh}(x) tanh(x) 實現了最佳性能。我們懷疑這是由于它的平滑性和零均值特性。
 表 8 ImageNet-1K 分類準確率與不同壓縮函數。所有實驗均遵循與原始基于 LN 的模型相同的訓練流程。壓縮函數在防止訓練發散中起關鍵作用,其中 tanh \text{tanh} tanh 在三種函數中取得了最高性能。“→ failed” 表示訓練在達到一定準確率后出現發散,箭頭前的數字為發散前達到的最高準確率。
表 8 ImageNet-1K 分類準確率與不同壓縮函數。所有實驗均遵循與原始基于 LN 的模型相同的訓練流程。壓縮函數在防止訓練發散中起關鍵作用,其中 tanh \text{tanh} tanh 在三種函數中取得了最高性能。“→ failed” 表示訓練在達到一定準確率后出現發散,箭頭前的數字為發散前達到的最高準確率。
移除 α α α。
接下來,我們評估在保留壓縮函數( tanh \text{tanh} tanh 、 hardtanh \text{hardtanh} hardtanh 和 sigmoid \text{sigmoid} sigmoid)的情況下移除可學習參數 α α α的影響。如表9所示,移除 α α α會導致所有壓縮函數的性能下降,凸顯了 α α α對模型整體性能的關鍵作用。
 表9 ViT-B在ImageNet-1K上的分類準確率。所有實驗均遵循原始基于LN模型的相同訓練流程。可學習的 α α α對于提升模型性能至關重要。
表9 ViT-B在ImageNet-1K上的分類準確率。所有實驗均遵循原始基于LN模型的相同訓練流程。可學習的 α α α對于提升模型性能至關重要。
6.3 α α α 的取值
訓練過程中。 我們的分析表明, α α α 在整個訓練過程中緊密跟蹤激活值的 1 / s t d 1/\mathrm{std} 1/std。如圖 8 左側所示, α α α 在訓練初期先下降后上升,但始終與輸入激活的標準差保持一致波動。這支持了 α α α 在將激活保持在合適范圍內,從而實現穩定且高效訓練中的重要作用。
 圖 8 左:對于 ViT-B 模型中兩個選定的 DyT 層,我們在每個 epoch 結束時跟蹤激活的標準差倒數( 1 / s t d 1/\mathrm{std} 1/std)和 α α α,觀察到它們在訓練過程中同步變化。 圖 8 右:我們將兩個訓練完成的模型(ViT-B 和 ConvNeXt-B)的最終 α α α值與輸入激活的標準差倒數( 1 / s t d 1/\mathrm{std} 1/std)繪制在同一坐標系中,展示了兩者之間的強相關性。
圖 8 左:對于 ViT-B 模型中兩個選定的 DyT 層,我們在每個 epoch 結束時跟蹤激活的標準差倒數( 1 / s t d 1/\mathrm{std} 1/std)和 α α α,觀察到它們在訓練過程中同步變化。 圖 8 右:我們將兩個訓練完成的模型(ViT-B 和 ConvNeXt-B)的最終 α α α值與輸入激活的標準差倒數( 1 / s t d 1/\mathrm{std} 1/std)繪制在同一坐標系中,展示了兩者之間的強相關性。
訓練后。 對訓練完畢網絡中 α α α 的最終取值進一步分析發現,其與輸入激活的 1 / s t d 1/\mathrm{std} 1/std 存在強相關性。如圖 8 右側所示,較高的 1 / s t d 1/\mathrm{std} 1/std 值通常對應較大的 α α α 值,反之亦然。此外,我們觀察到越深的層其激活標準差越大。該趨勢與深度 ResNet(Brock 等,2021a)和 Transformer(Sun 等,2025)的研究結果一致。這兩項分析表明, α α α 部分地充當了歸一化機制,通過學習近似輸入激活 1 / s t d 1/\mathrm{std} 1/std 的值來整體歸一化輸入激活。與按 token 歸一化激活的 Layer Norm 不同, α α α 對整個輸入張量共同歸一化。因此,僅有 α α α 無法以非線性方式抑制極端值。
6.4 與其他方法的比較
為了進一步評估 DyT 的有效性,我們將其與其他能夠在缺少歸一化層的情況下訓練 Transformer 的方法進行比較。這些方法大致可分為基于初始化的方法和基于權重歸一化的方法。我們考慮了兩種流行的基于初始化的方法:Fixup (Zhang 等, 2019;Huang 等, 2020) 和 SkipInit (De 和 Smith, 2020;Bachlechner 等, 2021)。這兩種方法都旨在通過調整初始參數值來緩解訓練不穩定性,防止在訓練開始時出現過大的梯度和激活值,從而無需歸一化層即可實現穩定學習。相比之下,基于權重歸一化的方法通過在整個訓練過程中對網絡權重施加約束,以在沒有歸一化層時維持穩定的學習動態。我們包含了一種此類方法—— σ σ σReparam (Zhai 等, 2023),它通過控制權重的譜范數來促進穩定學習。
表 10 總結了兩個基于 ViT 任務的結果。我們嚴格遵循各自論文中概述的原始協議。然而,我們發現兩種基于初始化的方法——Fixup 和 SkipInit——為了防止訓練發散,需要顯著更低的學習率。為確保公平比較,我們對包括 DyT 在內的所有方法進行了簡單的學習率搜索。這得到的結果與第 5 節中報告的結果不同,第 5 節未對任何超參數進行調整。總體而言,結果顯示在不同配置下,DyT 始終優于所有其他測試方法。
 表 10 ImageNet-1K 上的分類準確率。在所有方法中,DyT 始終取得了優越的性能。
表 10 ImageNet-1K 上的分類準確率。在所有方法中,DyT 始終取得了優越的性能。
7 α 的初始化
我們發現調整 α α α 的初始化(記為 α 0 α_0 α0?)很少會帶來顯著的性能提升。唯一例外是 LLM 訓練,在該場景下精心調整 α 0 α_0 α0? 可獲得明顯的性能提升。在本節中,我們詳細說明 α α α 初始化的影響。
7.1 非 LLM 模型的 α α α 初始化
非 LLM 模型對 α 0 α_0 α0? 的敏感性較低。
圖 9 顯示了在不同任務中改變 α 0 α_0 α0? 對驗證性能的影響。所有實驗均遵循各自流程的原始設置和超參數。我們觀察到性能在廣泛的 α 0 α_0 α0? 值范圍內保持穩定,通常在 0.5 到 1.2 之間的值可獲得較好結果。我們還發現,調整 α 0 α_0 α0? 主要影響訓練曲線的早期階段。主要例外是監督訓練的 ViT-L 實驗,當 α 0 α_0 α0? 超過 0.6 時訓練變得不穩定并出現發散。在此情況下,降低學習率可恢復穩定性,詳情如下所述。
 圖 9 不同 α 0 α_0 α0? 值下各任務的性能表現。我們對第 5 節中使用的所有非 LLM 任務進行了基于不同初始 α 0 α_0 α0? 值的基準測試。性能在廣泛的 α 0 α_0 α0? 范圍內保持穩定。唯一的例外是監督訓練的 ViT-L 模型(右上圖),當 α 0 α_0 α0? 值大于 0.6 時會出現訓練發散。
圖 9 不同 α 0 α_0 α0? 值下各任務的性能表現。我們對第 5 節中使用的所有非 LLM 任務進行了基于不同初始 α 0 α_0 α0? 值的基準測試。性能在廣泛的 α 0 α_0 α0? 范圍內保持穩定。唯一的例外是監督訓練的 ViT-L 模型(右上圖),當 α 0 α_0 α0? 值大于 0.6 時會出現訓練發散。
更小的 α 0 α_0 α0? 可帶來更穩定的訓練。
基于之前的觀察,我們進一步分析了導致訓練不穩定的因素。我們的發現表明,增大模型規模或學習率都需要降低 α 0 α_0 α0? 以確保訓練穩定。反之,較高的 α 0 α_0 α0? 則需要更低的學習率來緩解訓練不穩定。圖 10 顯示了在 ImageNet-1K 數據集上對監督訓練的 ViT 模型的訓練穩定性消融實驗,其中我們改變了學習率、模型規模和 α 0 α_0 α0? 值。訓練更大的模型更容易失敗,需要更小的 α 0 α_0 α0? 值或學習率來實現穩定訓練。在相似條件下,基于 LN 的模型也觀察到類似的不穩定模式,而設置 α 0 = 0.5 α_0=0.5 α0?=0.5 則可獲得與 LN 相似的穩定性。
 圖 10:在不同 α 0 α0 α0 值、學習率和模型規模下的穩定性。我們在 ImageNet-1K 數據集上訓練監督 ViT 模型,觀察到無論是 LN 還是 DyT 模型,較大模型都更易出現不穩定現象。降低學習率或減小 α 0 α0 α0 可提高穩定性。LN 在 α 0 = 0.5 α0=0.5 α0=0.5 時表現出與 DyT 相似的穩定性。
圖 10:在不同 α 0 α0 α0 值、學習率和模型規模下的穩定性。我們在 ImageNet-1K 數據集上訓練監督 ViT 模型,觀察到無論是 LN 還是 DyT 模型,較大模型都更易出現不穩定現象。降低學習率或減小 α 0 α0 α0 可提高穩定性。LN 在 α 0 = 0.5 α0=0.5 α0=0.5 時表現出與 DyT 相似的穩定性。
將 α 0 = 0.5 α_0=0.5 α0?=0.5 作為默認值。
根據我們的研究結果,我們將 α 0 = 0.5 α0=0.5 α0=0.5 設為所有非 LLM 模型的默認值。此設置可提供與 LN 相當的訓練穩定性,同時保持強勁的性能。
7.2 LLM 的 α α α 初始化
調整 α 0 α_0 α0? 可以提升 LLM 性能。
正如前文討論, α 0 = 0.5 α_0=0.5 α0?=0.5 的默認設置通常在大多數任務中表現良好。然而,我們發現調整 α 0 α_0 α0? 能顯著提升 LLM 的性能。我們通過在 LLaMA 各模型上用 300 億 token 進行預訓練并比較其訓練損失,對 α 0 α_0 α0? 進行調優。表 11 匯總了每個模型的最佳 α 0 α_0 α0? 值。得出兩個關鍵發現:
- 較大的模型需要更小的 α 0 α_0 α0? 值。
在較小模型的最佳 α 0 α_0 α0? 確定后,可據此縮小對較大模型的搜索空間。 - 對注意力模塊使用更高的 α 0 α_0 α0? 值可提高性能。
我們發現,在注意力模塊中的 DyT 層初始化較高的 α 0 α_0 α0?,而在其他位置(即 FFN 模塊內或最終線性投影前)的 DyT 層初始化較低的 α 0 α_0 α0?,能夠提升性能。
 表 11 不同 LLaMA 模型的最佳 α 0 α_0 α0?。 較大模型需要更小的 α 0 α_0 α0? 值。我們發現,在(1)注意力模塊(“attention”)與(2)FFN 模塊及輸出前的最終 DyT 層(“other”)中對 α 0 α_0 α0? 進行差異化初始化非常重要。注意力模塊中的 α 0 α_0 α0? 需要設置為更大的值。
表 11 不同 LLaMA 模型的最佳 α 0 α_0 α0?。 較大模型需要更小的 α 0 α_0 α0? 值。我們發現,在(1)注意力模塊(“attention”)與(2)FFN 模塊及輸出前的最終 DyT 層(“other”)中對 α 0 α_0 α0? 進行差異化初始化非常重要。注意力模塊中的 α 0 α_0 α0? 需要設置為更大的值。
為了進一步說明 α 0 α_0 α0? 調整的影響,圖 11 展示了兩個 LLaMA 模型的損失值熱圖。兩個模型都在注意力模塊中使用更高的 α 0 α_0 α0? 時受益,表現為訓練損失的降低。
 圖 11:不同 α 0 α_0 α0? 設置下,兩個 LLaMA 模型在 300 億 tokens 訓練時的損失值熱圖。兩種模型在注意力模塊中提高 α 0 α_0 α0? 時均受益。
圖 11:不同 α 0 α_0 α0? 設置下,兩個 LLaMA 模型在 300 億 tokens 訓練時的損失值熱圖。兩種模型在注意力模塊中提高 α 0 α_0 α0? 時均受益。
模型寬度主要決定 α 0 α_0 α0? 的選擇。
我們還研究了模型寬度和深度對最優 α 0 α_0 α0? 的影響。我們發現模型寬度在決定最優 α 0 α_0 α0? 時至關重要,而模型深度的影響則微乎其微。表 12 展示了不同寬度和深度下的最優 α 0 α_0 α0? 值,顯示更寬的網絡在最優性能時需要更小的 α 0 α_0 α0?。另一方面,模型深度對 α 0 α_0 α0? 的選擇影響不顯著。
正如表 12 所示,網絡越寬,“attention”和“other”之間的初始化差異就需要越大。我們假設 LLM 的 α α α 初始化敏感性與其相比其他模型過大的寬度有關。
 表 12 LLaMA 訓練中,不同模型寬度和深度下的最優 α 0 α0 α0(“attention”/“other”)。模型寬度顯著影響 α 0 α0 α0 的選擇,網絡越寬需要越小的值;相比之下,模型深度影響甚微。
表 12 LLaMA 訓練中,不同模型寬度和深度下的最優 α 0 α0 α0(“attention”/“other”)。模型寬度顯著影響 α 0 α0 α0 的選擇,網絡越寬需要越小的值;相比之下,模型深度影響甚微。
8 相關工作
歸一化層的機制。 大量研究探討了歸一化層通過多種機制提升模型性能的作用。這些機制包括在訓練過程中穩定梯度流(Balduzzi 等,2017;Daneshmand 等,2020;Lubana 等,2021)、降低對權重初始化的敏感性(Zhang 等,2019;De 和 Smith,2020;Shao 等,2020)、調節異常特征值(Bjorck 等,2018;Karakida 等,2019)、自動調節學習率(Arora 等,2018;Tanaka 和 Kunin,2021)以及平滑損失面以獲得更穩定的優化(Santurkar 等,2018)。這些早期工作主要聚焦于批歸一化。最近的研究(Lyu 等,2022;Dai 等,2024;Mueller 等,2024)進一步強調了歸一化層與減少損失面銳度之間的聯系,而損失面銳度的降低有助于更好的泛化性能。
Transformer 中的歸一化。 隨著 Transformer(Vaswani 等,2017)的興起,研究者愈加關注層歸一化(Layer Norm)(Ba 等,2016),其已被證明對自然語言任務中的序列數據尤為有效(Nguyen 和 Salazar,2019;Xu 等,2019;Xiong 等,2020)。近期工作(Ni 等,2024)揭示了層歸一化引入的強非線性如何增強模型的表征能力。此外,研究(Loshchilov 等,2024;Li 等,2024)表明,通過調整 Transformer 中歸一化層的位置,可以改善收斂特性。
移除歸一化。 許多研究探討了如何在沒有歸一化層的情況下訓練深度模型。一些工作(Zhang 等,2019;De 和 Smith,2020;Bachlechner 等,2021)探索了替代的權重初始化方案以穩定訓練。Brock 等(2021a,b)的開創性工作表明,通過結合初始化技術(De 和 Smith,2020)、權重歸一化(Salimans 和 Kingma,2016;Huang 等,2017;Qiao 等,2019)和自適應梯度裁剪(Brock 等,2021b),高性能的 ResNet 可在無歸一化層的情況下訓練(Smith 等,2023)。此外,他們的訓練策略融合了廣泛的數據增強(Cubuk 等,2020)和正則化(Srivastava 等,2014;Huang 等,2016)。上述研究主要基于各類 ConvNet 模型。
在 Transformer 架構中,He 和 Hofmann(2023)探索了修改 Transformer 塊以減少對歸一化層和跳躍連接依賴的方法。另一種思路由 Heimersheim(2024)提出,通過在移除每個歸一化層后對預訓練網絡進行微調,逐步移除層歸一化。與以往方法不同,DyT 只需對架構和訓練流程做最小修改,盡管其方法簡單,卻能實現穩定訓練并達到可比性能。
9 限制
我們在使用 LN 或 RMSNorm 的網絡上進行實驗,因為它們在 Transformer 及其他現代架構中非常流行。初步實驗(見附錄 C)表明,DyT 在經典網絡如 ResNet 中直接替換 BN 時表現不佳。尚需深入研究 DyT 是否以及如何適應使用其他類型歸一化層的模型。
10 結論
在本工作中,我們展示了現代神經網絡,尤其是 Transformer,可以在沒有歸一化層的情況下進行訓練。我們提出的動態 Tanh(DyT)是一種對傳統歸一化層的簡單替代方法。它通過可學習的縮放因子 α α α 調整輸入激活范圍,然后通過 S 型 tanh ? \tanh tanh 函數壓縮極端值。盡管該函數更為簡單,但它有效地捕捉了歸一化層的行為。在各種設置下,采用 DyT 的模型的性能能夠匹配或超越其歸一化版本。這些發現挑戰了歸一化層在訓練現代神經網絡中的必要性這一傳統認知。本研究還為理解歸一化層這一深度神經網絡中最基礎構建模塊的機制做出了貢獻。
附錄
附錄 A 實驗設置
監督圖像分類。
對于 ImageNet-1K 上的所有監督分類實驗,我們遵循 ConvNeXt(Meta Research,a)中的訓練流程。在 ConvNeXt-B 和 ConvNeXt-L 中,我們使用原始超參數且不做任何修改。ViT-B 和 ViT-L 模型使用與 ConvNeXt-B 完全相同的超參數;唯一區別是對于 ViT-L,AdamW 的 beta 參數設置為(0.9,0.95),而隨機深度率在 ViT-B 中設為0.1,在 ViT-L 中設為0.4。
擴散模型。
我們使用官方實現(Meta Research,c)訓練所有 DiT 模型。我們發現默認學習率對于本文所用模型并非最佳。為此,我們在使用 LN 的模型上進行了簡單的學習率搜索,并將調優后的學習率直接應用于 DyT 模型。我們還觀察到,零初始化會對 DyT 模型的性能產生負面影響。因此,我們對 LN 模型保留零初始化,但對 DyT 模型移除零初始化。
大型語言模型。
在我們使用 DyT 實現的 LLaMA 模型(Touvron et al.,2023a,b;Dubey et al.,2024)中,我們在嵌入層之后、任何 Transformer 塊之前,添加了一個可學習標量參數。我們將其初始化為模型嵌入維度 d d d的平方根,即 d \sqrt{d} d?。如果不添加該縮放標量,我們發現訓練初期模型激活值過小,訓練難以推進。加入這一可學習標量后,該問題得以緩解,模型能夠正常收斂。該設計與原始 Transformer(Vaswani et al.,2017)中在相同位置使用固定標量的做法相似。
我們在 Pile 數據集(Gao et al.,2020)上訓練所有 LLaMA 模型。所用代碼庫為 FMS-FSDP(Foundation Model Stack),其為7B模型提供了一個與 LLaMA 2 論文(Touvron et al.,2023b)幾乎一致的默認訓練流程。我們將學習率保持在7B和13B模型的默認3e-4,以及34B和70B模型的1.5e-4,與 LLaMA 2 保持一致。批量大小設置為4M tokens,每個模型總共訓練200B tokens。
評估。
我們在 lm-eval(Gao et al.)提供的15個零樣本常識推理任務上測試預訓練模型,任務包括 anli_r1、anli_r2、anli_r3、arc_challenge、arc_easy、boolq、hellaswag、openbookqa、piqa、record、rte、truthfulqa_mc1、truthfulqa_mc2、wic 和 winogrande。任務選擇緊隨 OpenLLaMA(Geng 和 Liu,2023)。我們報告所有任務的平均表現。
語音領域的自監督學習。
對于兩種 wav2vec 2.0 模型,我們保留原始架構中的第一個組歸一化層,因為它主要作為數據歸一化以處理未歸一化的輸入。我們使用官方實現(Meta Research,e),且不修改 Base 和 Large 模型的超參數。我們報告最終的驗證損失。
其他任務。
對于 MAE(He et al.,2022)、DINO(Caron et al.,2021)、HyenaDNA(Nguyen et al.,2024)和 Caduceus(Schiff et al.,2024)等所有其他任務,我們直接使用公開發布的代碼(Meta Research,d,b;HazyResearch;Kuleshov Group),不做超參數調整,分別訓練 LN 和 DyT 兩種模型。
附錄 B 超參數
我們給出了額外實驗,以評估超參數調優的影響,特別關注所有非 LLM 模型的學習率和 α 0 α_0 α0? 初始化。
調優學習率。表 13 匯總了使用原始學習率與調優后學習率訓練的模型性能對比。結果表明,調優學習率僅為 DyT 模型帶來有限的性能提升。這表明最初為 LN 模型優化的默認超參數已同樣適用于 DyT 模型。這一觀察強調了 DyT 模型與 LN 模型之間的內在相似性。
調優 α 0 α_0 α0? 初始值。我們還研究了對 DyT 模型優化 α 0 α0 α0 的效果,結果如表 14 所示。發現對 α 0 α0 α0 進行調優僅為部分模型帶來輕微的性能提升,表明默認初始值( α 0 = 0.5 α_0=0.5 α0?=0.5)通常已能實現近乎最優的性能。
 表 13 LN 和 DyT 模型在原始與調優學習率下的性能對比。結果顯示,調優學習率僅為 DyT 模型帶來有限的性能提升,表明為 LN 模型優化的默認超參數已同樣適用于 DyT 模型。標有“–”的條目表示相對于原始學習率無性能提升。括號內的數值為所用學習率。
表 13 LN 和 DyT 模型在原始與調優學習率下的性能對比。結果顯示,調優學習率僅為 DyT 模型帶來有限的性能提升,表明為 LN 模型優化的默認超參數已同樣適用于 DyT 模型。標有“–”的條目表示相對于原始學習率無性能提升。括號內的數值為所用學習率。
 表 14 調優 α 0 α0 α0 對 DyT 模型的影響。將 α 0 α0 α0 從默認值( α 0 = 0.5 α_0=0.5 α0?=0.5)調優,僅為部分 DyT 模型帶來小幅性能提升,暗示默認初始化已實現近乎最優的性能。標有“–”的條目表示相對于默認 α 0 α_0 α0? 無性能提升。
表 14 調優 α 0 α0 α0 對 DyT 模型的影響。將 α 0 α0 α0 從默認值( α 0 = 0.5 α_0=0.5 α0?=0.5)調優,僅為部分 DyT 模型帶來小幅性能提升,暗示默認初始化已實現近乎最優的性能。標有“–”的條目表示相對于默認 α 0 α_0 α0? 無性能提升。
附錄 C 用 DyT 替換批量歸一化
我們在經典的 ConvNet(如 ResNet-50(He 等,2016)和 VGG19(Simonyan 和 Zisserman,2014))中研究了用 DyT 替換 BN 的可行性。兩種模型均在 ImageNet-1K(Deng 等,2009)數據集上訓練,并使用 torchvision 提供的訓練流程。DyT 模型使用與其 BN 對應模型相同的超參數進行訓練。
結果匯總在表 15 中。用 DyT 替換 BN 導致兩個模型的分類準確率顯著下降。這些發現表明,DyT 在這些經典 ConvNet 中尚無法完全替代 BN。我們推測,這可能與 BN 在這些 ConvNet 中的出現頻率更高有關——在每個權重層后都會出現一次 BN,而在 Transformer 中,LN 僅在若干權重層后出現一次。
 表 15 ImageNet-1K 上使用 BN 和 DyT 的分類準確率。在 ResNet-50 和 VGG19 中,用 DyT 替換 BN 會導致性能下降,表明 DyT 無法在這些架構中完全替代 BN。
表 15 ImageNet-1K 上使用 BN 和 DyT 的分類準確率。在 ResNet-50 和 VGG19 中,用 DyT 替換 BN 會導致性能下降,表明 DyT 無法在這些架構中完全替代 BN。
)


















