?

一、 背景描述
在跨國性企業日常經營過程中,經常會遇到專業性較強的文檔翻譯的需求,例如法律文書、商務合同、技術文檔等;以往遇到此類場景,企業內部往往需要指派專人投入數小時甚至數天來整理和翻譯,效率低下,嚴重影響了企業日常經營和生產。如何利用自動化工具來自動化批量處理專業文檔翻譯的工作,使員工更加專注于業務創新,成為擺在企業面前的重要課題。
隨著機器學習和大語言模型等技術的飛速發展,專業文檔翻譯的自動化成為了可能。客戶希望構建一個地理領域專業文檔的翻譯方案,使其通過大語言模型進行翻譯,并且提出如下幾點要求:
-
自動識別文檔的語言種類,自動進行中翻英或者英翻中;
-
翻譯后的文檔盡可能地保留 Microsoft Office Word 文檔中的格式;
-
盡可能地使用地理專業領域的術語,支持客戶的術語表并可以用簡單的方式擴展;
-
避免中式英語,符合英文的語序和表達習慣。
二、 方案概述
根據客戶需求,我們進行了方案的概念模型設計:
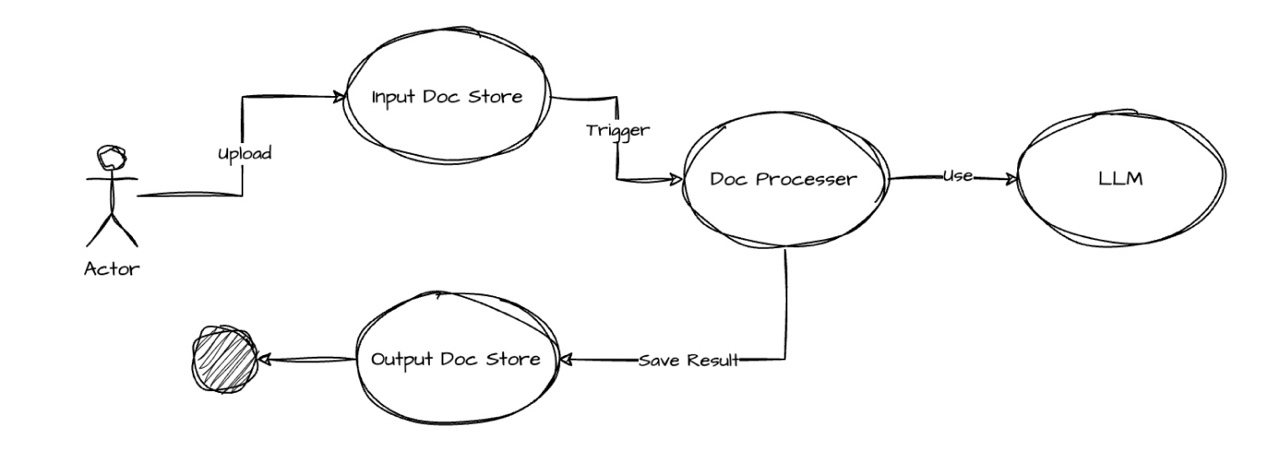
方案執行的流程如下:
-
用戶上傳中文/英文文檔到“輸入文檔存儲”;
-
上傳完成的動作,觸發文檔翻譯的處理作業,該作業會調用大語言模型;
-
翻譯作業完成后,生成對應的英文/中文文檔,結果保存到“輸出文檔存儲”。
基于以上概念模型和流程設計,我們形成了如下的方案組件選型:
-
文檔存儲,包括原始輸入文檔存儲和翻譯后的輸出文檔存儲,我們選用 Amazon S3,因為該服務支持事件通知,可以觸發無服務器資源例如 Amazon Lambda 進行處理;
-
文檔處理,也就是具體的文檔翻譯作業,我們選擇使用 Lambda,并在代碼中調用 Amazon Bedrock 上的大模型來實現;
-
日志記錄,開啟 Amazon CloudWatch Logs 記錄 Lambda 執行過程,方便故障排查和代碼調試。
方案部署架構設計如下:
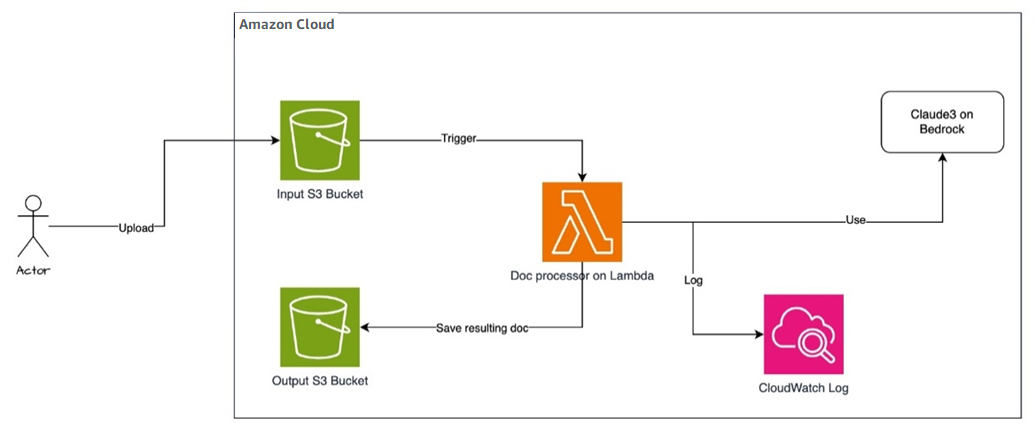
具體執行過程如下:
-
用戶通過亞馬遜云科技控制臺上傳原始文檔到 Amazon S3 Input 存儲桶;
-
S3 對象上傳成功的通知,觸發 Amazon Lambda 調用 Amazon Bedrock 上的大模型執行文檔翻譯;
-
Lambda 執行完成后,翻譯后的文檔自動保存到 S3 Output 存儲桶;
用戶可以在 Amazon CloudWatch Logs 中查看 Lambda 執行記錄。
三、 核心代碼實現
-
語種檢測
本方案使用 Amazon Bedrock 上的大模型對用戶上傳的文檔,實現了自動化識別其語種是英語還是中文,如果是中文自動翻譯成英文,如果是英文則翻譯成中文。以下是語種檢測部分的代碼:
def language_detector(query):print("debug")model_id = '<you-model-id>'print(<you-model-id>')response = bedrock.invoke_model(body=_get_complete_lang_detect_prompt(query), modelId=model_id)print('<< call <you-model-id>')response_body = json.loads(response.get('body').read())print(response_body)match = re.search(r'<lang>([\s\S]*?)</lang>', response_body['content'][0]['text'])print(f"response_body:{ response_body['content'][0]['text']}")if match:final_response = match.group(1)print(f"> in: {query}")print(f"> Language detected: {final_response}")return final_responseelse:# print(f"> in: {query}")print(f"< out: BR ERROR in language detect!!!")
另外,在調用 Amazon Bedrock 上的大模型時,需要按照其格式提供提示詞模版,語種檢測提示詞模板部分的代碼如下:def _get_complete_lang_detect_prompt(query, domain='None'):system_prompt = f"""You need to detect the language in the given text. If the text contains characters from different languages, then you should respond the major ONE language that is used. Your output will be processed by a program so no explaintaion is needed.NOTE: You are detecting the language in the given text, not the topic it is telling about.<text> + {query} + </text>The result should be in the tag of <lang></lang>. No explanation is needed. <lang>Respond only within these tags and do not provide any additional text outside the tags.</lang>. E.G. <lang>English</lang> or <lang>Chinese</lang>."""user_message = {"role": "user", "content": query}messages = [user_message]return json.dumps({"anthropic_version": "bedrock-2023-05-31","max_tokens": 80960,"system": system_prompt,"messages": messages})
-
文檔翻譯
本方案中文檔翻譯使用了 Amazon Bedrock 上的大模型,核心代碼如下:
def agent_bedrock(query, to_language, domain="None"):model_id = <you-model-id>'response = bedrock.invoke_model(body=_get_complete_prompt(query, to_language, domain), modelId=model_id)response_body = json.loads(response.get('body').read())match = re.search(r'<TRANSLATED>([\s\S]*?)</TRANSLATED>', response_body['content'][0]['text'])if match:final_response = match.group(1)# print(f"> in: {query}")# print(f"< out: {final_response}")return final_responseelse:# print(f"> in: {query}")print(f"< out: BR ERROR!!!")return query
文檔翻譯對應的提示詞如下:
def _get_complete_prompt(query, to_language='English', domain='None'):system_prompt = f"""You are a helpful and honest AI assistant, now I want you to help in translation for the give text. you will translate the given text to its {to_language} version. The following are the rules to follow during the translation.* The input will be in <TO_TRANSLATE> tag. they can be words, numbers, or single character, Sometimes they are already in the target language, then only respond the original text into the <TRANSLATED> tag.* it is OK if you don't very confident to translate, in such cases, you can give the best translate you can, because we will have human review later on.* Your output will be put to <TRANSLATED></TRANSLATED> tag. * So, in summary, <TRANSLATED> tag should contain translated or original text, <error> tag should contain the reason why you cannot translate.* The given content is in the {domain} domain, so you should use the professional terms if applicable.* If it is the Chinese-to-English translation, please be aware that the order of terms may very different between the two language. Use the order of Englishto make it flow better. * the following is the terms for you to follow up: {_geo_terms}"""user_message = {"role": "user", "content": "<TO_TRANSLATE>" + query + "</TO_TRANSLATE>"}messages = [user_message]return json.dumps({"anthropic_version": "bedrock-2023-05-31","max_tokens": 80960,"system": system_prompt,"messages": messages})
-
文檔解析
由于客戶提供的輸入文檔限定為 Microsoft Office Word 格式,因此本方案采用 Python 中的 docx 庫進行 Word 文檔解析,代碼參考如下:
import docx
def parse_doc_and_translate(input_file_name, output_file_name):"""Parse the document and translate the text"""doc = docx.Document(input_file_name)texts = []
-
專業術語翻譯
地理領域的專業術語,放在文本文件中(命名為 terms.txt),上傳到 Amazon S3 存儲桶;在翻譯的時候會先行從 S3 上讀取專有詞匯表,并自動將專有名詞注入到提示詞中。專有名詞的格式如下:
Airy Hypothesis 艾里假說;
alias 假頻;
amplitude spectrum 振幅譜;
antiroots 反山根;
Bouguer anomaly 布格異常;
Bouguer correction 布格改正;
continuation 延拓;
density 密度;
如果有新的專有詞匯需要加入,只需要更新 S3 上的詞匯表即可自動生效。在調用 Amazon Bedrock 上的大模型進行翻譯時,提示詞要求按照該術語表翻譯,這部分核心代碼如下:
import os
import boto3s3 = boto3.client('s3')S3_BUCKET = os.environ.get('APP_BUCKET_NAME', 'aaa-demo')
S3_TERMS_FILE = os.environ.get('S3_TERMS_FILE', 'terms.txt')def geo_terms():# Download the object content to a variableresponse = s3.get_object(Bucket=S3_BUCKET, Key=S3_TERMS_FILE)file_content = response['Body'].read().decode('utf-8')return file_contentif __name__ == '__main__':
print(geo_terms())# Amazon Bedrock 上的大模型的提示詞中引用該術語表
def _get_complete_prompt(query, to_language='English', domain='None'):
system_prompt = f"""
…
* the following is the terms for you to follow up: {_geo_terms}"""
-
并發配置和異常處理
本方案 Lambda 的并發配置如下:
CONCURRENT_FOR_BEDROCK_INVOCATION = os.environ.get('CONCURRENT_FOR_BEDROCK_INVOCATION', '3')
如果同時上傳多個文件,每個 Doc 會相應地啟動一個 Lambda 實例來進行翻譯工作;在執行翻譯的時候,文檔會被拆分成段落,并對每個段落進行翻譯。一個文檔可能會被拆分成 200~400 個片段,為了加快翻譯速度,我們加入了并發執行的邏輯,并發數由上面的“CONCURRENT_FOR_BEDROCK_INVOCATION”來控制。設置該參數時需要考慮亞馬遜云科技賬號中 Bedrock 上的大模型的最大并發數(一般是每分鐘 200 次),同時需要考慮并發的文檔數量。
四、總結與展望
本次我們采用亞馬遜云科技原生服務搭建了一套地理領域專業文檔翻譯的解決方案,該方案核心處理邏輯采用了亞馬遜云科技無服務器化服務 Amazon Lambda,翻譯處理完全基于事件觸發,對于用戶來說大幅降低使用成本,同時運維負擔小,用戶體驗友好。但客戶也提出了一些改進意見,例如希望提供獨立于亞馬遜云科技 Console 的 Web 頁面、對用戶進行權限劃分、專業術語表用戶可自行添加、翻譯任務狀態展示等,后續我們將聯合合作伙伴,對這些工程化和定制化功能繼續深入合作。
*前述特定亞馬遜云科技生成式人工智能相關的服務僅在亞馬遜云科技海外區域可用,亞馬遜云科技中國僅為幫助您了解行業前沿技術和發展海外業務選擇推介該服務。
本篇作者
本期最新實驗《多模一站通 —— Amazon Bedrock 上的基礎模型初體驗》
? 精心設計,旨在引導您深入探索Amazon Bedrock的模型選擇與調用、模型自動化評估以及安全圍欄(Guardrail)等重要功能。無需管理基礎設施,利用亞馬遜技術與生態,快速集成與部署生成式AI模型能力。
??[點擊進入實驗] 即刻開啟 ?AI 開發之旅
構建無限, 探索啟程!?

深入了解AVFoundation-采集:采集系統架構與 AVCaptureSession 全面梳理)
組件)
)
)






,源碼可白嫖!)


)
)

)
)
