大模型學習筆記------Llama 3模型架構之分組查詢注意力(GQA)
- 1、分組查詢注意力(GQA)的動機
- 2、 多頭注意力(Multi-Head Attention, MHA)
- 3、 多查詢注意力 (Multi-Query Attention,MQA)
- 4、 分組查詢注意力(Grouped-Query Attention, GQA)
- 5、 多頭注意力 (MHA) 、多查詢注意力 (MQA)、分組查詢注意力 (GQA)對比
????上文簡單介紹了 Llama 3模型架構的旋轉位置編碼(Rotary Position Embedding,RoPE)。本文介紹Llama 3模型的最后一個網絡結構相關知識:Llama 3模型架構之分組查詢注意力(Grouped-Query Attention, GQA)。實際上。在Llama 2就已經使用GQA注意力機制了。GQA是Transformer模型注意力機制的重要改進,旨在平衡計算效率與模型表現。其核心設計理念可概括為:“分組共享鍵值對,獨立保留查詢向量”。
1、分組查詢注意力(GQA)的動機
????Llama 3為什么采用GQA注意力機制呢?其實道理很簡單,在大模型訓練與推理過程中需要在保障準確率的基礎上盡可能的減少計算量,減少參數數量,提高效率。這個怎樣理解呢?論文里其實也提到了這個問題。主要是對比了多頭注意力(Multi-Head Attention, MHA)和多查詢注意力 (Multi-Query Attention,MQA)。具體三中方式的結構如下圖所示:

2、 多頭注意力(Multi-Head Attention, MHA)
????多頭注意力(Multi-Head Attention, MHA)是一種在Transformer架構中廣泛使用的注意力機制,具體結構如上圖A。它通過并行地使用多個注意力頭來捕捉輸入序列中不同的特征,增強模型的表達能力。多頭注意力的基本思想是將輸入的查詢(Query,Q)、鍵(Key,K)和值(Value,V)向量通過多個注意力頭進行并行處理,然后將結果拼接在一起,得到最終的輸出。每個注意力頭在不同的子空間中學習數據的不同特征,使得模型能夠更好地理解復雜的輸入。具體原理如下所示:
????1)查詢(Query,Q)、鍵(Key,K)和值(Value,V)的向量表示:

其中, 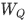 、
、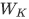 和
和 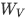 分別是查詢、鍵和值的投影矩陣。
分別是查詢、鍵和值的投影矩陣。
????2)自注意力計算:

其中, 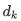 為查詢和鍵向量的維度。
為查詢和鍵向量的維度。
????3)多頭組合:


????通過多個注意力頭并行處理,MHA能夠從不同角度關注輸入數據中的信息,捕捉到更豐富的上下文關系。MHA的設計使得可以在硬件加速上,同時計算多個關注頭,提高了計算效率。
3、 多查詢注意力 (Multi-Query Attention,MQA)
????多查詢注意力(Multi-Query Attention, MQA)旨在提高注意力的效率并降低計算復雜度。相較于傳統的多頭注意力(Multi-Head Attention, MHA),MQA的設計采用了多個查詢頭,但共享相同的鍵和值,這使得計算更為高效,具體結構如上圖B。具體計算原理如下步驟:
????1)查詢向量:

????2)共享的鍵和值向量:

????3)自注意力計算:

????4)組合:

4、 分組查詢注意力(Grouped-Query Attention, GQA)
????分組查詢注意力(Grouped-Query Attention, GQA)旨在通過將查詢分組來提升計算效率并增強模型的能力。與多頭注意力和多查詢注意力相比,GQA通過將查詢分成多個組并為每組獨立計算注意力來優化注意力計算過程。具體結構如上圖C,計算步驟如下所示:
1)查詢向量:

2)分組的鍵和值向量:
將總計N個注意力頭劃分為G組,每組共享相同的鍵和值投影:

3)組內自注意力計算:

4)組合:

5、 多頭注意力 (MHA) 、多查詢注意力 (MQA)、分組查詢注意力 (GQA)對比
????這幾種注意力機制有各自的特點,具體如下所示:
| 維度 | 多頭注意力 (MHA) | 多查詢注意力 (MQA) | 分組查詢注意力 (GQA) |
|---|---|---|---|
| 查詢數量 | 多個獨立的查詢 | 多個共享查詢 | 分組查詢,部分獨立 |
| 鍵和值 | 每個頭獨立的鍵和值 | 共享相同的鍵和值 | 共享或獨立的鍵值 |
| 計算復雜度 | 較高 | 較低 | 靈活調節,適中 |
| 應用場景 | 廣泛 | 小查詢任務 | 大規模模型優化 |






,源碼可白嫖!)


)
)

)
)

:子游戲集成與服務器調度機制全解)

(算法競賽進階指南學習筆記))

